Best AI tools for< Evaluate Changes >
20 - AI tool Sites
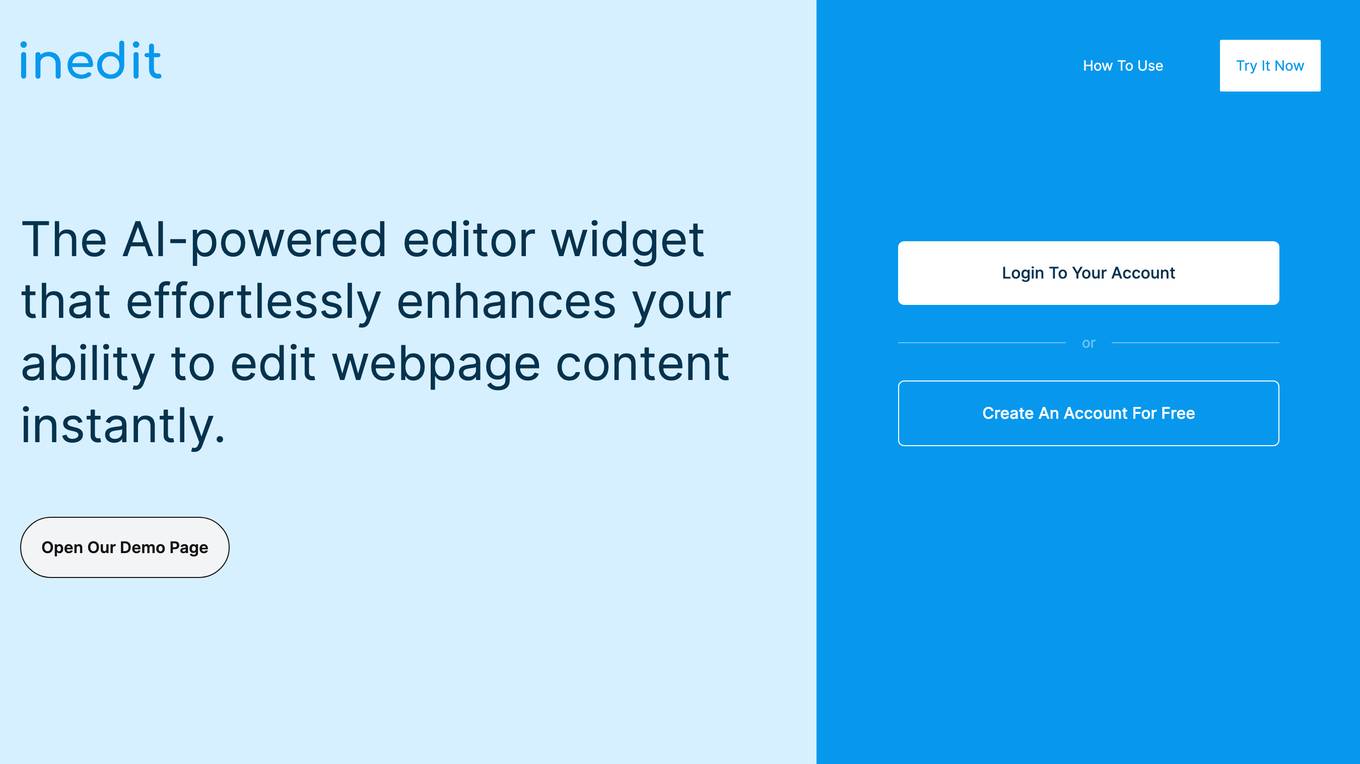
Inedit
The website offers an AI-powered editor widget that allows users to make real-time edits directly on their website. It leverages advanced AI technology from OpenAI to streamline content editing and enhance productivity. Users can choose between GPT-3 and GPT-4 models for editing tasks. The tool also provides manual editing options for correcting errors in AI-generated content. Additionally, users can effortlessly edit multiple elements simultaneously, inspect deeper structures of webpages, and evaluate and publish content with control over what is visible to clients.
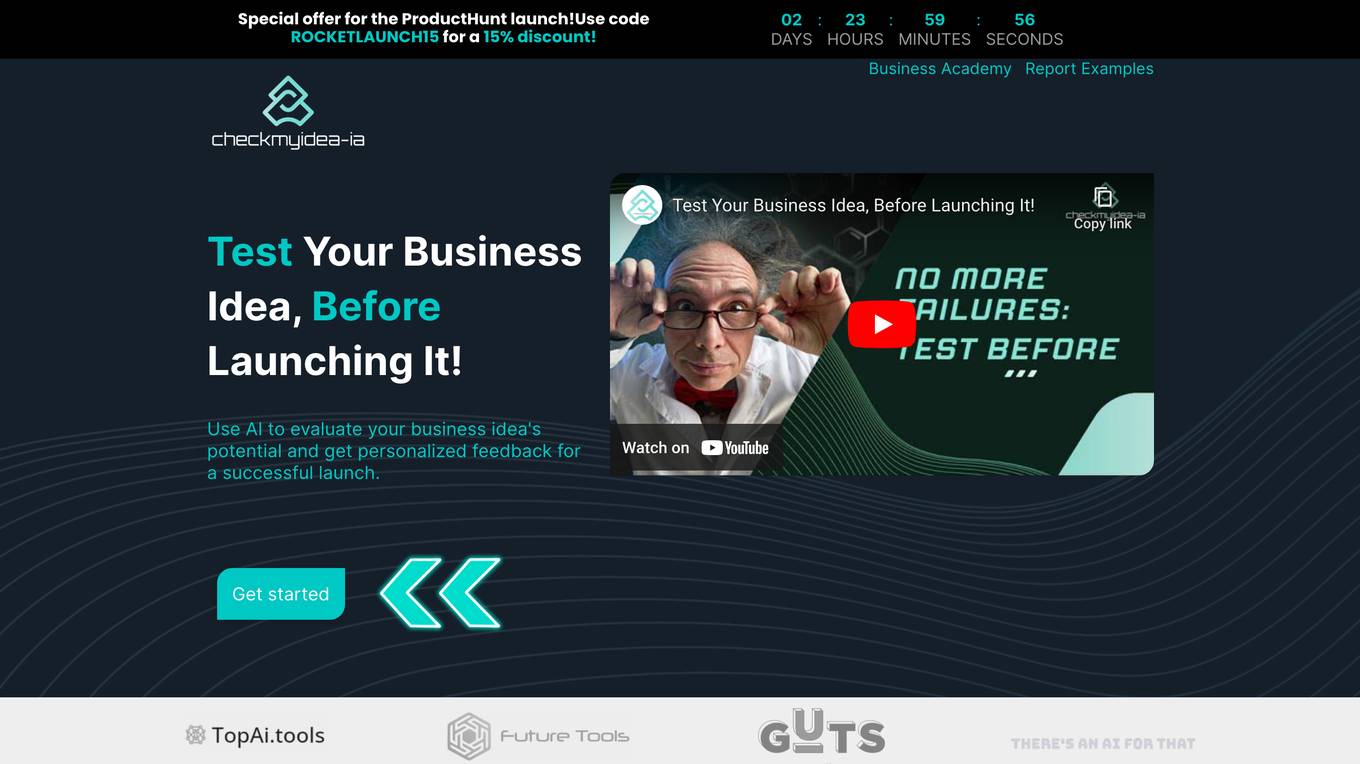
Checkmyidea-IA
Checkmyidea-IA is an AI-powered tool that helps entrepreneurs and businesses evaluate their business ideas before launching them. It uses a variety of factors, such as customer interest, uniqueness, initial product development, and launch strategy, to provide users with a comprehensive review of their idea's potential for success. Checkmyidea-IA can help users save time, increase their chances of success, reduce risk, and improve their decision-making.

GenInnov
GenInnov is a generative innovation fund that provides a platform for investors seeking to be at the forefront of technological advancement. The fund invests in companies driving transformative change across multiple sectors and geographies, prioritizing material innovations with demonstrable profitability and global reach. GenInnov operates with a research-driven approach, focusing on investing in material innovations that are monetizable, profitable, and transformative, rather than incremental. The fund looks at various domains such as technology, robotics, consumer electronics, biotech, healthcare, mobility, and clean tech, aiming to amplify human creativity through machine intelligence.
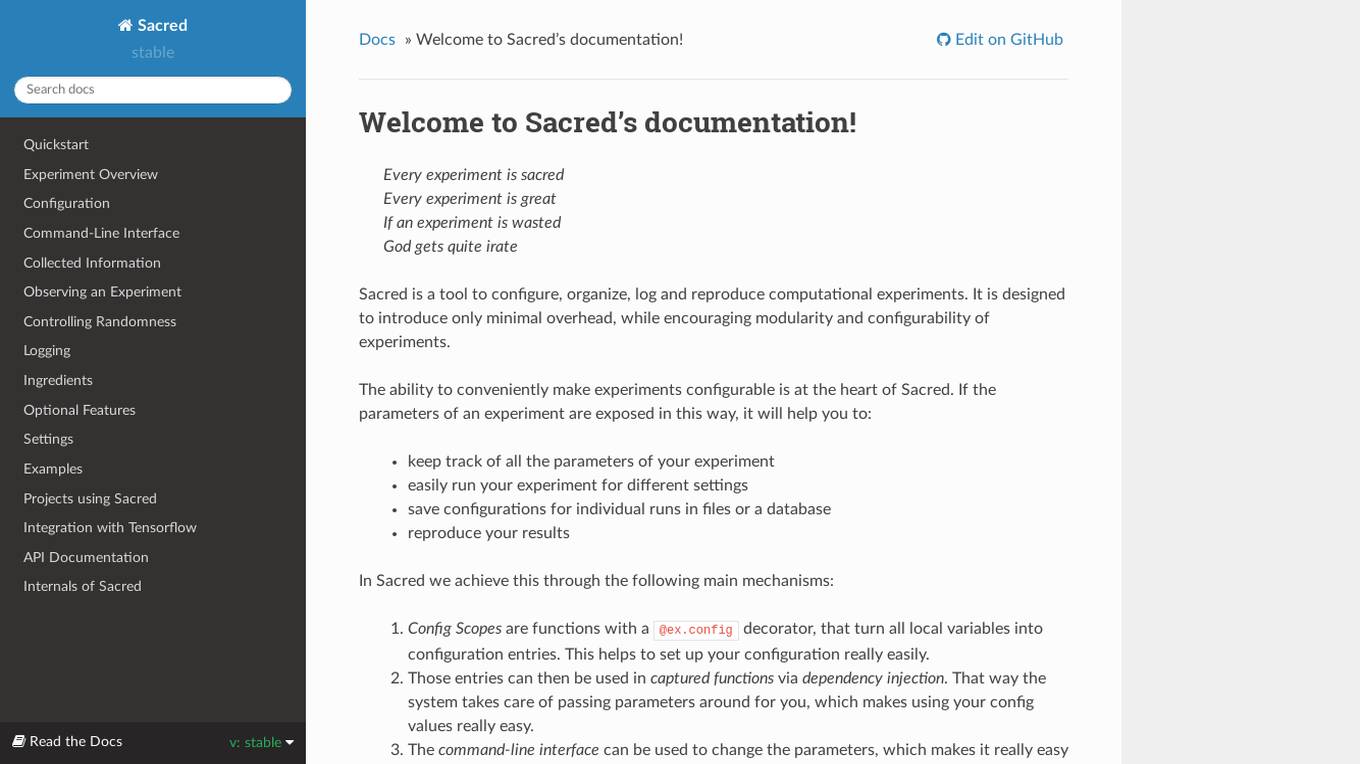
Sacred
Sacred is a tool to configure, organize, log and reproduce computational experiments. It is designed to introduce only minimal overhead, while encouraging modularity and configurability of experiments. The ability to conveniently make experiments configurable is at the heart of Sacred. If the parameters of an experiment are exposed in this way, it will help you to: keep track of all the parameters of your experiment easily run your experiment for different settings save configurations for individual runs in files or a database reproduce your results In Sacred we achieve this through the following main mechanisms: Config Scopes are functions with a @ex.config decorator, that turn all local variables into configuration entries. This helps to set up your configuration really easily. Those entries can then be used in captured functions via dependency injection. That way the system takes care of passing parameters around for you, which makes using your config values really easy. The command-line interface can be used to change the parameters, which makes it really easy to run your experiment with modified parameters. Observers log every information about your experiment and the configuration you used, and saves them for example to a Database. This helps to keep track of all your experiments. Automatic seeding helps controlling the randomness in your experiments, such that they stay reproducible.
Edelman
Edelman is an AI tool that focuses on enterprise marketing communications. It offers generative AI solutions to help marcom teams enhance decision-making, boost insights, and drive results. The tool provides key strategy elements for successful change management, evaluates analytics and social listening tools, and explores large language models for marketing and communications teams.

Resume Roaster AI
The website offers a service where users can have their resumes analyzed by an AI system. Users can submit their resumes to receive feedback and suggestions for improvement. The AI tool evaluates various aspects of the resume, such as formatting, content, and relevance to the job market. It aims to help users enhance their resumes to increase their chances of landing job interviews.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.

RebeccAi
RebeccAi is an AI-powered business idea evaluation and validation tool that uses AI technology to provide accurate insights into the potential of users' ideas. It helps users refine and improve their ideas quickly and intelligently, serving as a one-person team for business dreamers. The platform assists in turning ideas into reality, from business concepts to creative projects, by leveraging the latest AI tools and technologies to innovate faster and smarter.
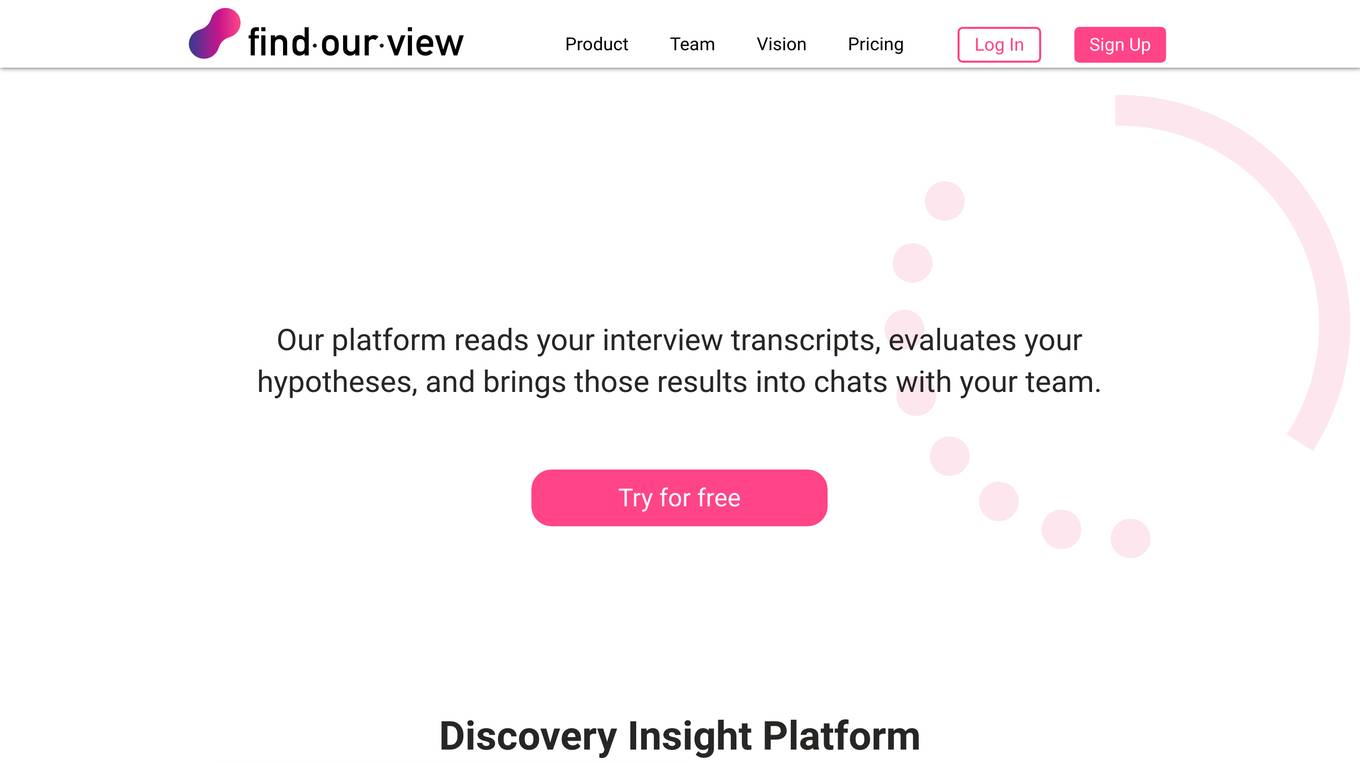
FindOurView
FindOurView is an AI-powered Discovery Insight Platform that provides instant discovery synthesis for teams. The platform reads interview transcripts, evaluates hypotheses, and facilitates discussions within teams. It enables users to evaluate hypotheses without the need for tags, extract relevant quotes, and make data-driven decisions. FindOurView aims to empower users with the collective intelligence of humans and AI to drive empathic conversations and confident decisions.

Codei
Codei is an AI-powered platform designed to help individuals land their dream software engineering job. It offers features such as application tracking, question generation, and code evaluation to assist users in honing their technical skills and preparing for interviews. Codei aims to provide personalized support and insights to help users succeed in the tech industry.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.
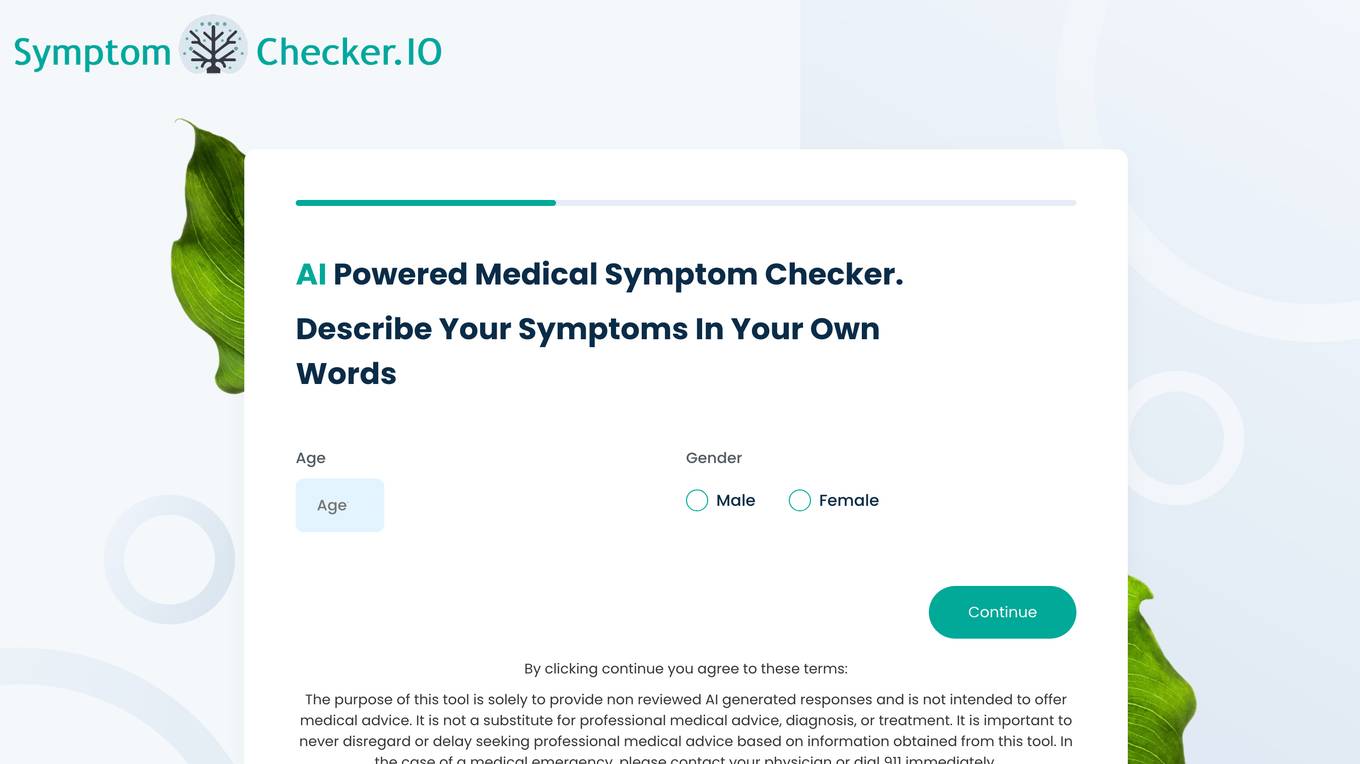
SymptomChecker.io
SymptomChecker.io is an AI-powered medical symptom checker that allows users to describe their symptoms in their own words and receive non-reviewed AI-generated responses. It is important to note that this tool is not intended to offer medical advice, diagnosis, or treatment and should not be used as a substitute for professional medical advice. In the case of a medical emergency, please contact your physician or dial 911 immediately.
ELSA
ELSA is an AI-powered English speaking coach that helps you improve your pronunciation, fluency, and confidence. With ELSA, you can practice speaking English in short, fun dialogues and get instant feedback from our proprietary artificial intelligence technology. ELSA also offers a variety of other features, such as personalized lesson plans, progress tracking, and games to help you stay motivated.
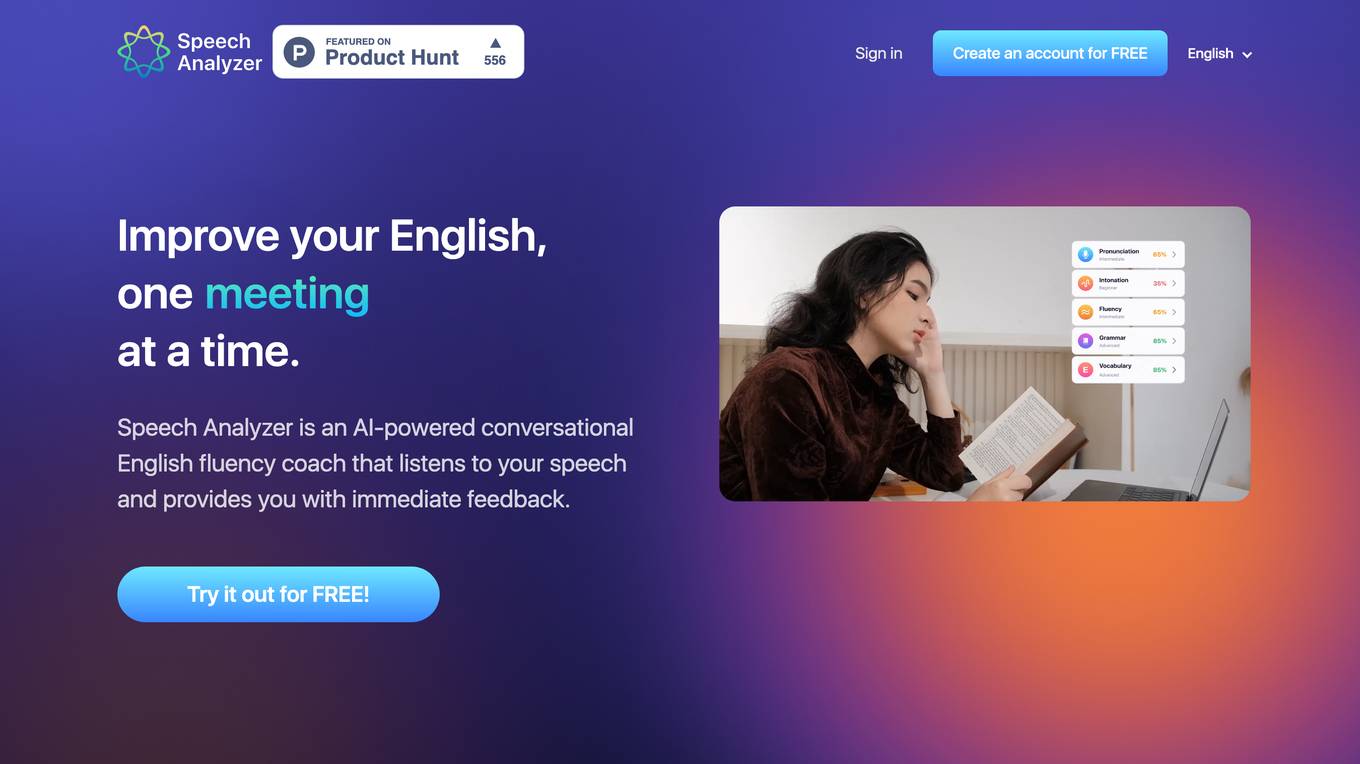
ELSA Speech Analyzer
ELSA Speech Analyzer is an AI-powered conversational English fluency coach that provides instant, personalized feedback on speech. It helps users improve pronunciation, intonation, grammar, and fluency through real-time analysis. The tool is designed for individuals, professionals, students, and organizations to enhance English speaking skills and communication abilities.
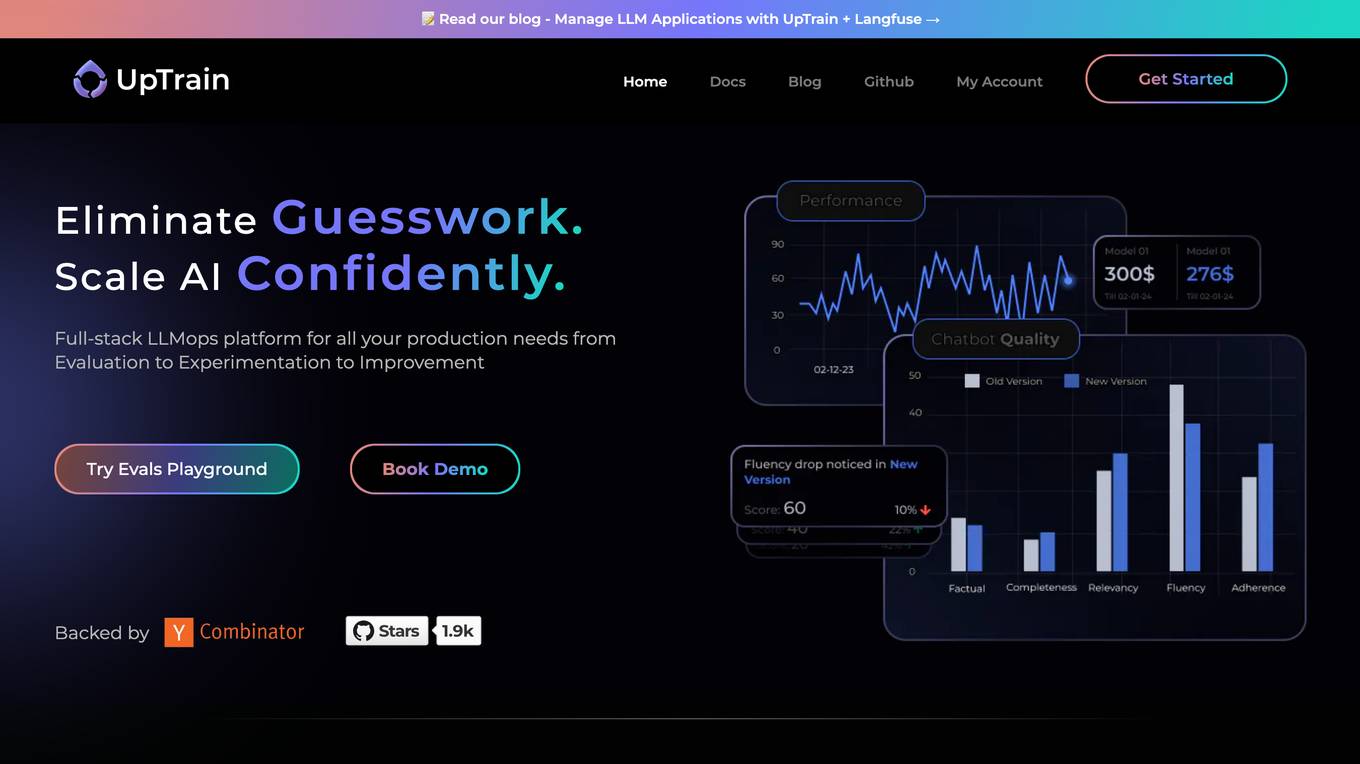
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users with all their production needs, from evaluation to experimentation to improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and precision metrics to enhance the development of LLM applications. UpTrain is built for developers, by developers, and is compliant with data governance needs. It provides cost efficiency, reliability, and open-source core evaluation framework. The platform is suitable for developers, product managers, and business leaders looking to enhance their LLM applications.
20 - Open Source AI Tools

phoenix
Phoenix is a tool that provides MLOps and LLMOps insights at lightning speed with zero-config observability. It offers a notebook-first experience for monitoring models and LLM Applications by providing LLM Traces, LLM Evals, Embedding Analysis, RAG Analysis, and Structured Data Analysis. Users can trace through the execution of LLM Applications, evaluate generative models, explore embedding point-clouds, visualize generative application's search and retrieval process, and statistically analyze structured data. Phoenix is designed to help users troubleshoot problems related to retrieval, tool execution, relevance, toxicity, drift, and performance degradation.
ragas
Ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM’s context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where Ragas (RAG Assessment) comes in. Ragas provides you with the tools based on the latest research for evaluating LLM-generated text to give you insights about your RAG pipeline. Ragas can be integrated with your CI/CD to provide continuous checks to ensure performance.

tonic_validate
Tonic Validate is a framework for the evaluation of LLM outputs, such as Retrieval Augmented Generation (RAG) pipelines. Validate makes it easy to evaluate, track, and monitor your LLM and RAG applications. Validate allows you to evaluate your LLM outputs through the use of our provided metrics which measure everything from answer correctness to LLM hallucination. Additionally, Validate has an optional UI to visualize your evaluation results for easy tracking and monitoring.
uptrain
UpTrain is an open-source unified platform to evaluate and improve Generative AI applications. We provide grades for 20+ preconfigured evaluations (covering language, code, embedding use cases), perform root cause analysis on failure cases and give insights on how to resolve them.
llm-colosseum
llm-colosseum is a tool designed to evaluate Language Model Models (LLMs) in real-time by making them fight each other in Street Fighter III. The tool assesses LLMs based on speed, strategic thinking, adaptability, out-of-the-box thinking, and resilience. It provides a benchmark for LLMs to understand their environment and take context-based actions. Users can analyze the performance of different LLMs through ELO rankings and win rate matrices. The tool allows users to run experiments, test different LLM models, and customize prompts for LLM interactions. It offers installation instructions, test mode options, logging configurations, and the ability to run the tool with local models. Users can also contribute their own LLM models for evaluation and ranking.
contoso-chat
Contoso Chat is a Python sample demonstrating how to build, evaluate, and deploy a retail copilot application with Azure AI Studio using Promptflow with Prompty assets. The sample implements a Retrieval Augmented Generation approach to answer customer queries based on the company's product catalog and customer purchase history. It utilizes Azure AI Search, Azure Cosmos DB, Azure OpenAI, text-embeddings-ada-002, and GPT models for vectorizing user queries, AI-assisted evaluation, and generating chat responses. By exploring this sample, users can learn to build a retail copilot application, define prompts using Prompty, design, run & evaluate a copilot using Promptflow, provision and deploy the solution to Azure using the Azure Developer CLI, and understand Responsible AI practices for evaluation and content safety.
simpletransformers
Simple Transformers is a library based on the Transformers library by HuggingFace, allowing users to quickly train and evaluate Transformer models with only 3 lines of code. It supports various tasks such as Information Retrieval, Language Models, Encoder Model Training, Sequence Classification, Token Classification, Question Answering, Language Generation, T5 Model, Seq2Seq Tasks, Multi-Modal Classification, and Conversational AI.

MiniCheck
MiniCheck is an efficient fact-checking tool designed to verify claims against grounding documents using large language models. It provides a sentence-level fact-checking model that can be used to evaluate the consistency of claims with the provided documents. MiniCheck offers different models, including Bespoke-MiniCheck-7B, which is the state-of-the-art and commercially usable. The tool enables users to fact-check multi-sentence claims by breaking them down into individual sentences for optimal performance. It also supports automatic prefix caching for faster inference when repeatedly fact-checking the same document with different claims.
yet-another-applied-llm-benchmark
Yet Another Applied LLM Benchmark is a collection of diverse tests designed to evaluate the capabilities of language models in performing real-world tasks. The benchmark includes tests such as converting code, decompiling bytecode, explaining minified JavaScript, identifying encoding formats, writing parsers, and generating SQL queries. It features a dataflow domain-specific language for easily adding new tests and has nearly 100 tests based on actual scenarios encountered when working with language models. The benchmark aims to assess whether models can effectively handle tasks that users genuinely care about.
skpro
skpro is a library for supervised probabilistic prediction in python. It provides `scikit-learn`-like, `scikit-base` compatible interfaces to: * tabular **supervised regressors for probabilistic prediction** \- interval, quantile and distribution predictions * tabular **probabilistic time-to-event and survival prediction** \- instance-individual survival distributions * **metrics to evaluate probabilistic predictions** , e.g., pinball loss, empirical coverage, CRPS, survival losses * **reductions** to turn `scikit-learn` regressors into probabilistic `skpro` regressors, such as bootstrap or conformal * building **pipelines and composite models** , including tuning via probabilistic performance metrics * symbolic **probability distributions** with value domain of `pandas.DataFrame`-s and `pandas`-like interface

llm-foundry
LLM Foundry is a codebase for training, finetuning, evaluating, and deploying LLMs for inference with Composer and the MosaicML platform. It is designed to be easy-to-use, efficient _and_ flexible, enabling rapid experimentation with the latest techniques. You'll find in this repo: * `llmfoundry/` - source code for models, datasets, callbacks, utilities, etc. * `scripts/` - scripts to run LLM workloads * `data_prep/` - convert text data from original sources to StreamingDataset format * `train/` - train or finetune HuggingFace and MPT models from 125M - 70B parameters * `train/benchmarking` - profile training throughput and MFU * `inference/` - convert models to HuggingFace or ONNX format, and generate responses * `inference/benchmarking` - profile inference latency and throughput * `eval/` - evaluate LLMs on academic (or custom) in-context-learning tasks * `mcli/` - launch any of these workloads using MCLI and the MosaicML platform * `TUTORIAL.md` - a deeper dive into the repo, example workflows, and FAQs

premsql
PremSQL is an open-source library designed to help developers create secure, fully local Text-to-SQL solutions using small language models. It provides essential tools for building and deploying end-to-end Text-to-SQL pipelines with customizable components, ideal for secure, autonomous AI-powered data analysis. The library offers features like Local-First approach, Customizable Datasets, Robust Executors and Evaluators, Advanced Generators, Error Handling and Self-Correction, Fine-Tuning Support, and End-to-End Pipelines. Users can fine-tune models, generate SQL queries from natural language inputs, handle errors, and evaluate model performance against predefined metrics. PremSQL is extendible for customization and private data usage.

fiftyone
FiftyOne is an open-source tool designed for building high-quality datasets and computer vision models. It supercharges machine learning workflows by enabling users to visualize datasets, interpret models faster, and improve efficiency. With FiftyOne, users can explore scenarios, identify failure modes, visualize complex labels, evaluate models, find annotation mistakes, and much more. The tool aims to streamline the process of improving machine learning models by providing a comprehensive set of features for data analysis and model interpretation.

Qwen
Qwen is a series of large language models developed by Alibaba DAMO Academy. It outperforms the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen models outperform the baseline models of similar model sizes on a series of benchmark datasets, e.g., MMLU, C-Eval, GSM8K, MATH, HumanEval, MBPP, BBH, etc., which evaluate the models’ capabilities on natural language understanding, mathematic problem solving, coding, etc. Qwen-72B achieves better performance than LLaMA2-70B on all tasks and outperforms GPT-3.5 on 7 out of 10 tasks.
pixeltable
Pixeltable is a Python library designed for ML Engineers and Data Scientists to focus on exploration, modeling, and app development without the need to handle data plumbing. It provides a declarative interface for working with text, images, embeddings, and video, enabling users to store, transform, index, and iterate on data within a single table interface. Pixeltable is persistent, acting as a database unlike in-memory Python libraries such as Pandas. It offers features like data storage and versioning, combined data and model lineage, indexing, orchestration of multimodal workloads, incremental updates, and automatic production-ready code generation. The tool emphasizes transparency, reproducibility, cost-saving through incremental data changes, and seamless integration with existing Python code and libraries.

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.

ai-rag-chat-evaluator
This repository contains scripts and tools for evaluating a chat app that uses the RAG architecture. It provides parameters to assess the quality and style of answers generated by the chat app, including system prompt, search parameters, and GPT model parameters. The tools facilitate running evaluations, with examples of evaluations on a sample chat app. The repo also offers guidance on cost estimation, setting up the project, deploying a GPT-4 model, generating ground truth data, running evaluations, and measuring the app's ability to say 'I don't know'. Users can customize evaluations, view results, and compare runs using provided tools.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.
langcheck
LangCheck is a Python library that provides a suite of metrics and tools for evaluating the quality of text generated by large language models (LLMs). It includes metrics for evaluating text fluency, sentiment, toxicity, factual consistency, and more. LangCheck also provides tools for visualizing metrics, augmenting data, and writing unit tests for LLM applications. With LangCheck, you can quickly and easily assess the quality of LLM-generated text and identify areas for improvement.

WildBench
WildBench is a tool designed for benchmarking Large Language Models (LLMs) with challenging tasks sourced from real users in the wild. It provides a platform for evaluating the performance of various models on a range of tasks. Users can easily add new models to the benchmark by following the provided guidelines. The tool supports models from Hugging Face and other APIs, allowing for comprehensive evaluation and comparison. WildBench facilitates running inference and evaluation scripts, enabling users to contribute to the benchmark and collaborate on improving model performance.
20 - OpenAI Gpts
Policy Communication Advisor
Communicates policy processes and changes effectively within the organization.
Lead Change Like a Gardener
Explore my book 'Gardeners not Mechanics: How to Cultivate Change at Work"'
Ready for Transformation
Assess your company's real appetite for new technologies or new ways of working methods

Project Benefit Realization Advisor
Advises on maximizing project benefits post-project closure.
Organization & Team Effectiveness Advisor
Guides organizational effectiveness via team-focused strategies and learning.
Environmental Disaster Analyst
Simulates and analyzes potential environmental disaster scenarios for preparedness.

Green Mind Economist
AI expert in renewable energy economics, advising on sustainable practices.
Email Proofreader
Copy and paste your email draft to be proofread by GPT without changing their content. Optionally, write 'Verbose = True' on the line before pasting your draft if you would like GPT to explain how it evaluated and changed your text after proofreading.

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model


WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms