Best AI tools for< deploy loras >
20 - AI tool Sites
Empower
Empower is a serverless fine-tuned LLM hosting platform that provides cost-effective LoRA serving without compromising performance. It is compatible with any PEFT-based LoRAs, allowing users to train their models anywhere and deploy them on Empower effortlessly. Empower's technology ensures a sub-second code start time for LoRAs, eliminating cold starts. Users only pay for what they use, with no expensive dedicated instance fees.
Predibase
Predibase is a platform for fine-tuning and serving Large Language Models (LLMs). It provides a cost-effective and efficient way to train and deploy LLMs for a variety of tasks, including classification, information extraction, customer sentiment analysis, customer support, code generation, and named entity recognition. Predibase is built on proven open-source technology, including LoRAX, Ludwig, and Horovod.
Seldon
Seldon is an MLOps platform that helps enterprises deploy, monitor, and manage machine learning models at scale. It provides a range of features to help organizations accelerate model deployment, optimize infrastructure resource allocation, and manage models and risk. Seldon is trusted by the world's leading MLOps teams and has been used to install and manage over 10 million ML models. With Seldon, organizations can reduce deployment time from months to minutes, increase efficiency, and reduce infrastructure and cloud costs.

OnOut
OnOut is a platform that allows users to deploy web3 apps to their own domain. It offers a variety of tools for developers, including an admin panel, dashboard, and deployment tools. OnOut also offers a revenue share model, which allows users to earn commissions on the apps they deploy. The platform is easy to use and does not require any coding skills. It is a great option for developers who want to quickly and easily deploy web3 apps to their own domain.

PoplarML
PoplarML is a platform that enables the deployment of production-ready, scalable ML systems with minimal engineering effort. It offers one-click deploys, real-time inference, and framework agnostic support. With PoplarML, users can seamlessly deploy ML models using a CLI tool to a fleet of GPUs and invoke their models through a REST API endpoint. The platform supports Tensorflow, Pytorch, and JAX models.
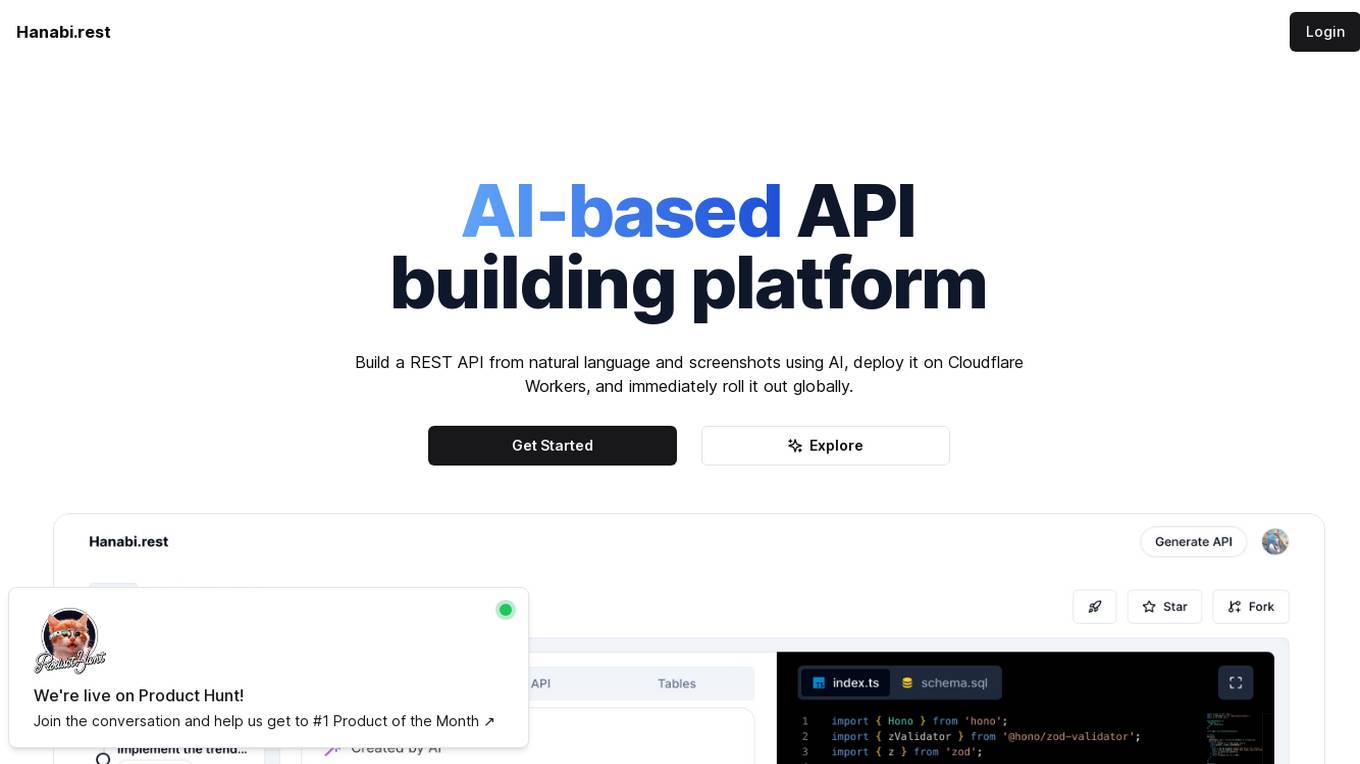
Hanabi.rest
Hanabi.rest is an AI-based API building platform that allows users to create REST APIs from natural language and screenshots using AI technology. Users can deploy the APIs on Cloudflare Workers and roll them out globally. The platform offers a live editor for testing database access and API endpoints, generates code compatible with various runtimes, and provides features like sharing APIs via URL, npm package integration, and CLI dump functionality. Hanabi.rest simplifies API design and deployment by leveraging natural language processing, image recognition, and v0.dev components.

Superflows
Superflows is a tool that allows you to add an AI Copilot to your SaaS product. This AI Copilot can answer questions and perform tasks for users via chat. It is designed to be easy to set up and configure, and it can be integrated into your codebase with just a few lines of code. Superflows is a great way to improve the user experience of your SaaS product and help users get the most out of your software.
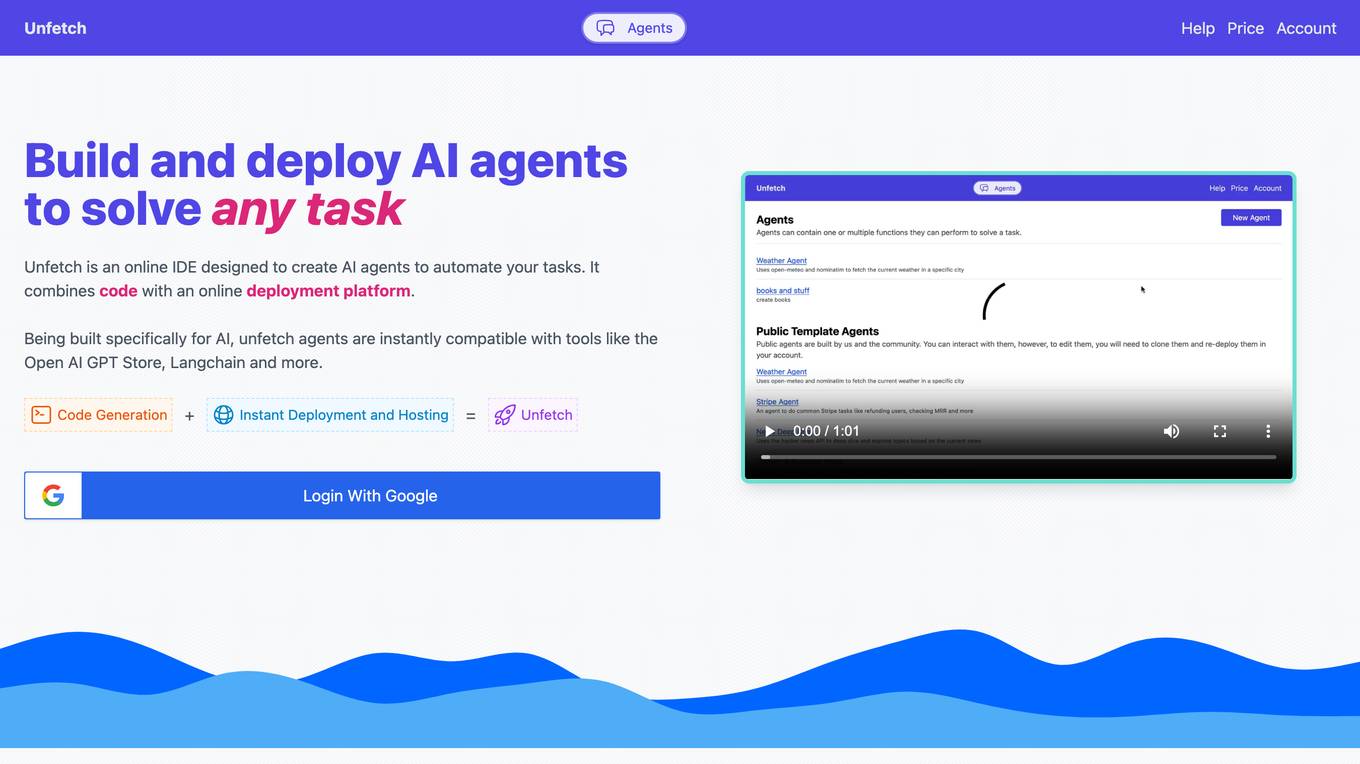
Unfetch
Unfetch is an online integrated development environment (IDE) designed to create AI agents to automate tasks. It combines code with an online deployment platform. Being built specifically for AI, Unfetch agents are instantly compatible with tools like the Open AI GPT Store, Langchain, and more.
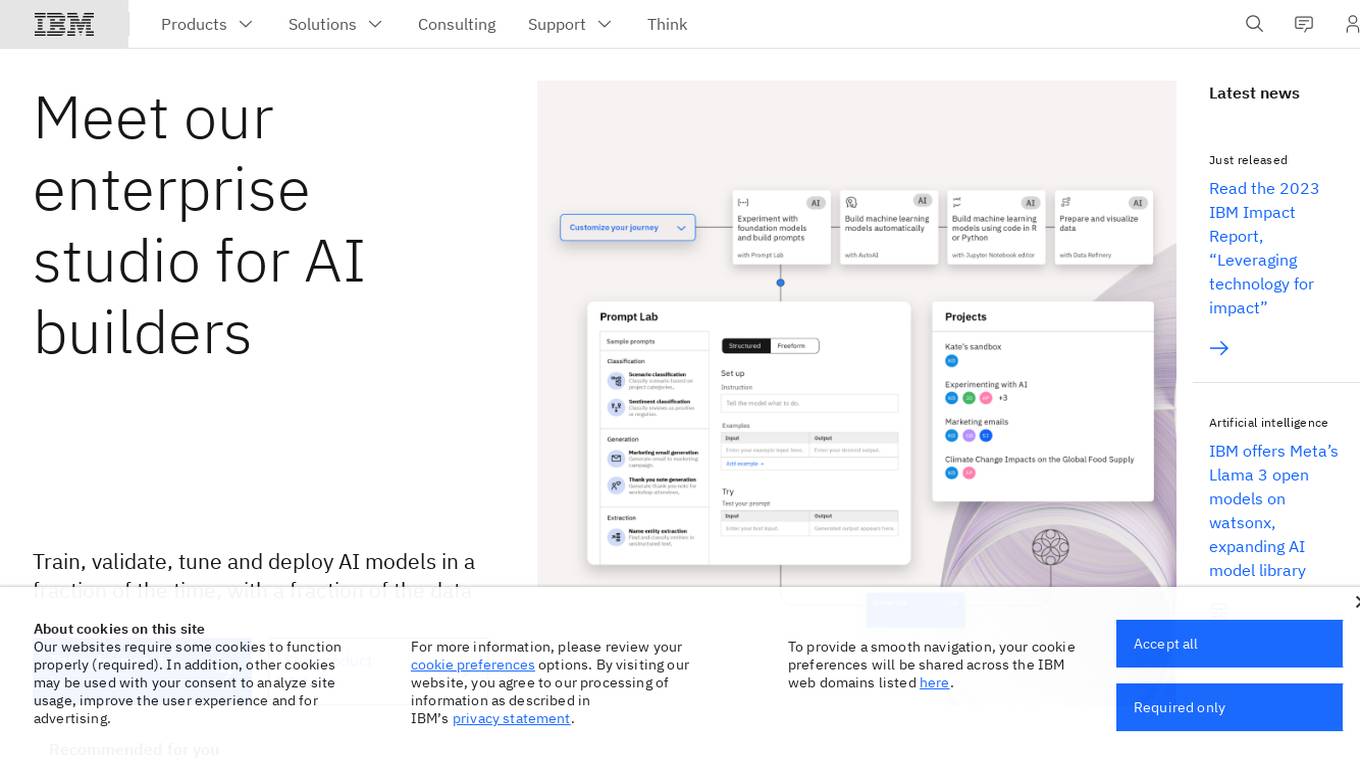
IBM Watsonx
IBM Watsonx is an enterprise studio for AI builders. It provides a platform to train, validate, tune, and deploy AI models quickly and efficiently. With Watsonx, users can access a library of pre-trained AI models, build their own models, and deploy them to the cloud or on-premises. Watsonx also offers a range of tools and services to help users manage and monitor their AI models.
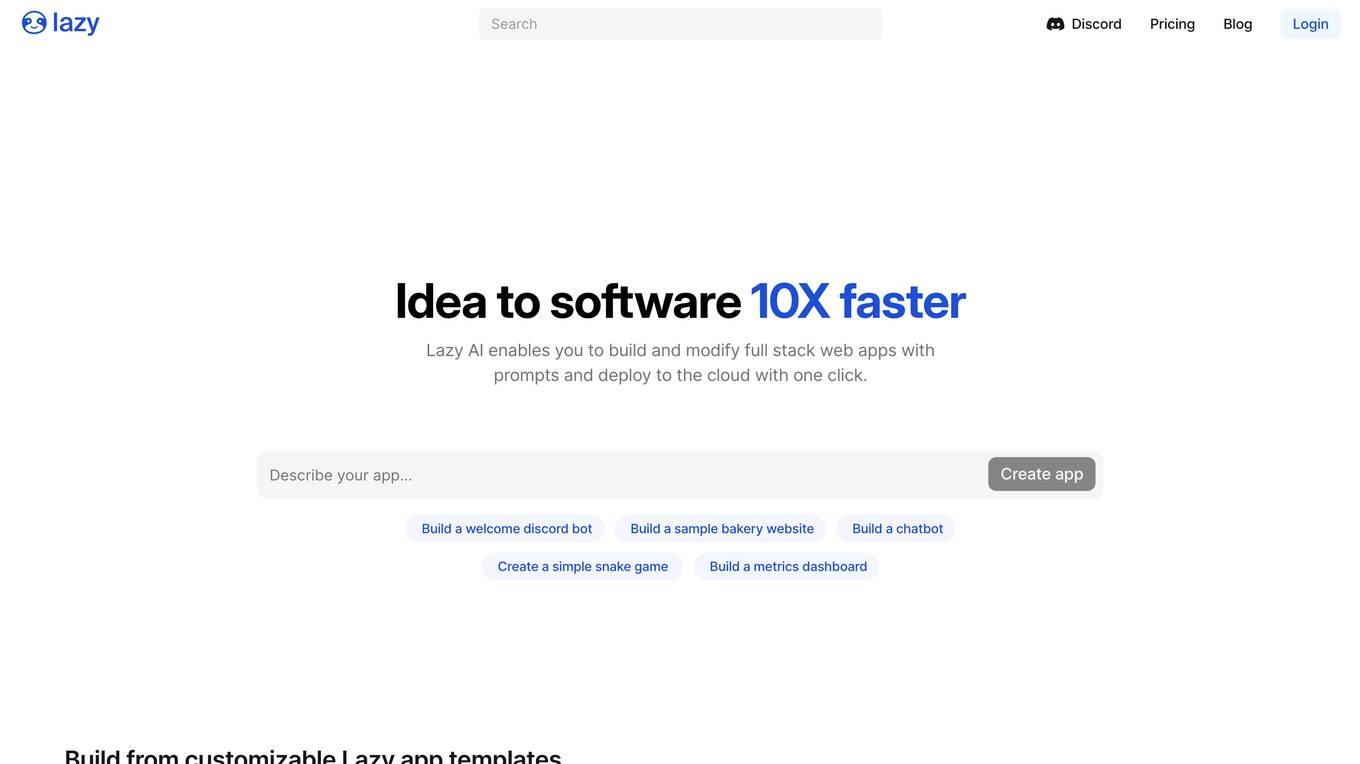
Lazy AI
Lazy AI is a platform that allows users to create full stack web applications with prompts and deploy them to the cloud with just one click. Users can build and modify web apps, AI agents, automations, chatbots, and more using AI technology. The platform offers a variety of tools and templates to streamline the app development process, making it easy and fun for users to bring their ideas to life.
Lazy AI
Lazy AI is a platform that enables users to build full stack web applications 10 times faster by utilizing AI technology. Users can create and modify web apps with prompts and deploy them to the cloud with just one click. The platform offers a variety of features including AI Component Builder, eCommerce store creation, Crypto Arbitrage Scraper, Text to Speech Converter, Lazy Image to Video generation, PDF Chatbot, and more. Lazy AI aims to streamline the app development process and empower users to leverage AI for various tasks.
PixieBrix
PixieBrix is an AI engagement platform that allows users to build, deploy, and manage internal AI tools to drive team productivity. It unifies AI landscapes with oversight and governance for enterprise scale. The platform is enterprise-ready and fully customizable to meet unique needs, and can be deployed on any site, making it easy to integrate into existing systems. PixieBrix leverages the power of AI and automation to harness the latest technology to streamline workflows and take productivity to new heights.
Datature
Datature is an all-in-one platform for building and deploying computer vision models. It provides tools for data management, annotation, training, and deployment, making it easy to develop and implement computer vision solutions. Datature is used by a variety of industries, including healthcare, retail, manufacturing, and agriculture.

Amazon Bedrock
Amazon Bedrock is a cloud-based platform that enables developers to build, deploy, and manage serverless applications. It provides a fully managed environment that takes care of the infrastructure and operations, so developers can focus on writing code. Bedrock also offers a variety of tools and services to help developers build and deploy their applications, including a code editor, a debugger, and a deployment pipeline.
Workflos.ai
Workflos.ai is an AI-powered SaaS finder and manager that helps users discover and deploy over 20,000 built-in SaaS products. It offers seamless deployment with integrated Single Sign-On, Identity Provisioning, and various workflow templates. Users can manage both internal and external apps on the platform, solving Shadow IT problems and enhancing security and compliance. Workflos.ai also enables users to build enterprise-ready apps with authentication, authorization, directory, and audit logging capabilities. Additionally, the platform assists in selling apps by targeting customers effectively at a lower cost.
TitanML
TitanML is a platform that provides tools and services for deploying and scaling Generative AI applications. Their flagship product, the Titan Takeoff Inference Server, helps machine learning engineers build, deploy, and run Generative AI models in secure environments. TitanML's platform is designed to make it easy for businesses to adopt and use Generative AI, without having to worry about the underlying infrastructure. With TitanML, businesses can focus on building great products and solving real business problems.
Unified DevOps platform to build AI applications
This is a unified DevOps platform to build AI applications. It provides a comprehensive set of tools and services to help developers build, deploy, and manage AI applications. The platform includes a variety of features such as a code editor, a debugger, a profiler, and a deployment manager. It also provides access to a variety of AI services, such as natural language processing, machine learning, and computer vision.
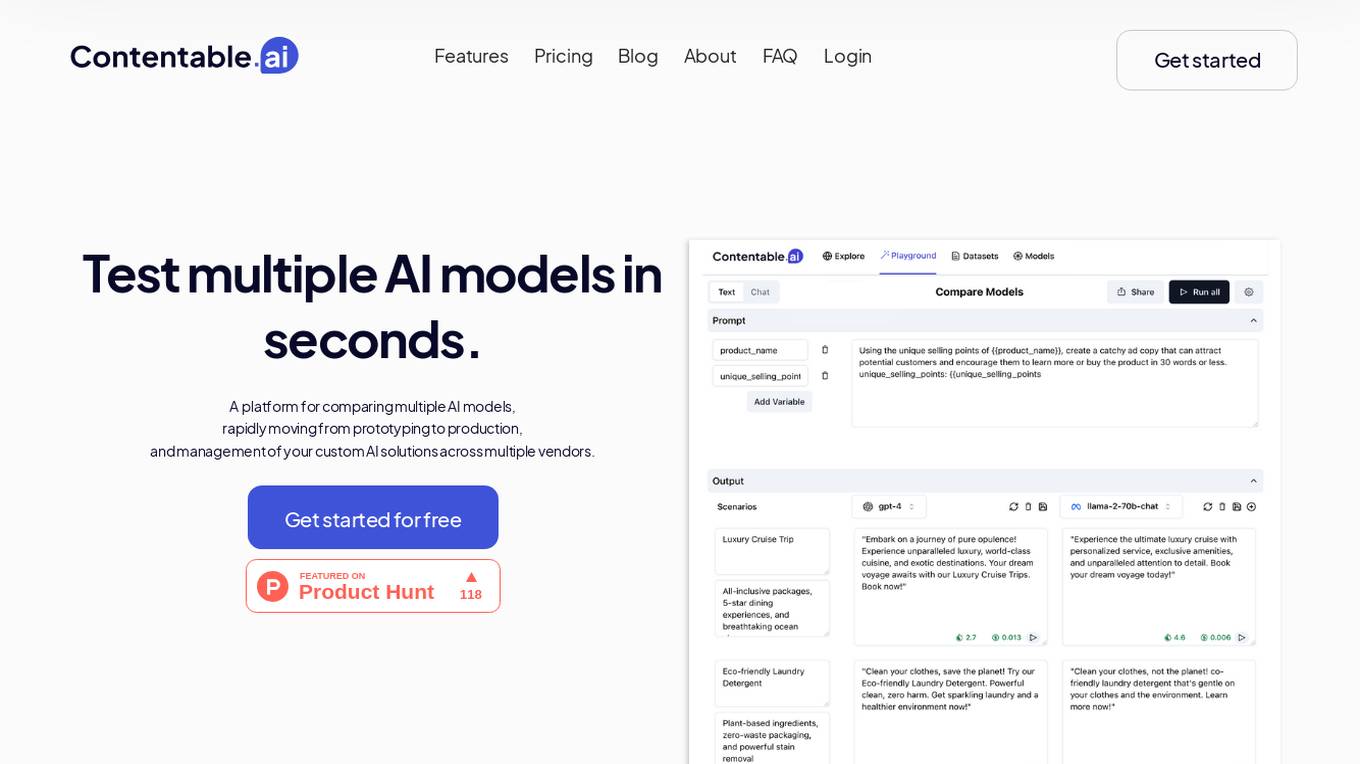
Contentable.ai
Contentable.ai is a platform for comparing multiple AI models, rapidly moving from prototyping to production, and management of your custom AI solutions across multiple vendors. It allows users to test multiple AI models in seconds, compare models side-by-side across top AI providers, collaborate on AI models with their team seamlessly, design complex AI workflows without coding, and pay as they go.
Plumb
Plumb is a no-code, node-based builder that empowers product, design, and engineering teams to create AI features together. It enables users to build, test, and deploy AI features with confidence, fostering collaboration across different disciplines. With Plumb, teams can ship prototypes directly to production, ensuring that the best prompts from the playground are the exact versions that go to production. It goes beyond automation, allowing users to build complex multi-tenant pipelines, transform data, and leverage validated JSON schema to create reliable, high-quality AI features that deliver real value to users. Plumb also makes it easy to compare prompt and model performance, enabling users to spot degradations, debug them, and ship fixes quickly. It is designed for SaaS teams, helping ambitious product teams collaborate to deliver state-of-the-art AI-powered experiences to their users at scale.
Baseten
Baseten is a machine learning infrastructure that provides a unified platform for data scientists and engineers to build, train, and deploy machine learning models. It offers a range of features to simplify the ML lifecycle, including data preparation, model training, and deployment. Baseten also provides a marketplace of pre-built models and components that can be used to accelerate the development of ML applications.
20 - Open Source AI Tools

BentoML
BentoML is an open-source model serving library for building performant and scalable AI applications with Python. It comes with everything you need for serving optimization, model packaging, and production deployment.
RWKV-Runner
RWKV Runner is a project designed to simplify the usage of large language models by automating various processes. It provides a lightweight executable program and is compatible with the OpenAI API. Users can deploy the backend on a server and use the program as a client. The project offers features like model management, VRAM configurations, user-friendly chat interface, WebUI option, parameter configuration, model conversion tool, download management, LoRA Finetune, and multilingual localization. It can be used for various tasks such as chat, completion, composition, and model inspection.

inference
Xorbits Inference (Xinference) is a powerful and versatile library designed to serve language, speech recognition, and multimodal models. With Xorbits Inference, you can effortlessly deploy and serve your or state-of-the-art built-in models using just a single command. Whether you are a researcher, developer, or data scientist, Xorbits Inference empowers you to unleash the full potential of cutting-edge AI models.
worker-vllm
The worker-vLLM repository provides a serverless endpoint for deploying OpenAI-compatible vLLM models with blazing-fast performance. It supports deploying various model architectures, such as Aquila, Baichuan, BLOOM, ChatGLM, Command-R, DBRX, DeciLM, Falcon, Gemma, GPT-2, GPT BigCode, GPT-J, GPT-NeoX, InternLM, Jais, LLaMA, MiniCPM, Mistral, Mixtral, MPT, OLMo, OPT, Orion, Phi, Phi-3, Qwen, Qwen2, Qwen2MoE, StableLM, Starcoder2, Xverse, and Yi. Users can deploy models using pre-built Docker images or build custom images with specified arguments. The repository also supports OpenAI compatibility for chat completions, completions, and models, with customizable input parameters. Users can modify their OpenAI codebase to use the deployed vLLM worker and access a list of available models for deployment.

mLoRA
mLoRA (Multi-LoRA Fine-Tune) is an open-source framework for efficient fine-tuning of multiple Large Language Models (LLMs) using LoRA and its variants. It allows concurrent fine-tuning of multiple LoRA adapters with a shared base model, efficient pipeline parallelism algorithm, support for various LoRA variant algorithms, and reinforcement learning preference alignment algorithms. mLoRA helps save computational and memory resources when training multiple adapters simultaneously, achieving high performance on consumer hardware.
llm-x
LLM X is a ChatGPT-style UI for the niche group of folks who run Ollama (think of this like an offline chat gpt server) locally. It supports sending and receiving images and text and works offline through PWA (Progressive Web App) standards. The project utilizes React, Typescript, Lodash, Mobx State Tree, Tailwind css, DaisyUI, NextUI, Highlight.js, React Markdown, kbar, Yet Another React Lightbox, Vite, and Vite PWA plugin. It is inspired by ollama-ui's project and Perplexity.ai's UI advancements in the LLM UI space. The project is still under development, but it is already a great way to get started with building your own LLM UI.
GenerativeAIExamples
NVIDIA Generative AI Examples are state-of-the-art examples that are easy to deploy, test, and extend. All examples run on the high performance NVIDIA CUDA-X software stack and NVIDIA GPUs. These examples showcase the capabilities of NVIDIA's Generative AI platform, which includes tools, frameworks, and models for building and deploying generative AI applications.

litgpt
LitGPT is a command-line tool designed to easily finetune, pretrain, evaluate, and deploy 20+ LLMs **on your own data**. It features highly-optimized training recipes for the world's most powerful open-source large-language-models (LLMs).

LLaMA-Factory
LLaMA Factory is a unified framework for fine-tuning 100+ large language models (LLMs) with various methods, including pre-training, supervised fine-tuning, reward modeling, PPO, DPO and ORPO. It features integrated algorithms like GaLore, BAdam, DoRA, LongLoRA, LLaMA Pro, LoRA+, LoftQ and Agent tuning, as well as practical tricks like FlashAttention-2, Unsloth, RoPE scaling, NEFTune and rsLoRA. LLaMA Factory provides experiment monitors like LlamaBoard, TensorBoard, Wandb, MLflow, etc., and supports faster inference with OpenAI-style API, Gradio UI and CLI with vLLM worker. Compared to ChatGLM's P-Tuning, LLaMA Factory's LoRA tuning offers up to 3.7 times faster training speed with a better Rouge score on the advertising text generation task. By leveraging 4-bit quantization technique, LLaMA Factory's QLoRA further improves the efficiency regarding the GPU memory.

swift
SWIFT (Scalable lightWeight Infrastructure for Fine-Tuning) supports training, inference, evaluation and deployment of nearly **200 LLMs and MLLMs** (multimodal large models). Developers can directly apply our framework to their own research and production environments to realize the complete workflow from model training and evaluation to application. In addition to supporting the lightweight training solutions provided by [PEFT](https://github.com/huggingface/peft), we also provide a complete **Adapters library** to support the latest training techniques such as NEFTune, LoRA+, LLaMA-PRO, etc. This adapter library can be used directly in your own custom workflow without our training scripts. To facilitate use by users unfamiliar with deep learning, we provide a Gradio web-ui for controlling training and inference, as well as accompanying deep learning courses and best practices for beginners. Additionally, we are expanding capabilities for other modalities. Currently, we support full-parameter training and LoRA training for AnimateDiff.

xtuner
XTuner is an efficient, flexible, and full-featured toolkit for fine-tuning large models. It supports various LLMs (InternLM, Mixtral-8x7B, Llama 2, ChatGLM, Qwen, Baichuan, ...), VLMs (LLaVA), and various training algorithms (QLoRA, LoRA, full-parameter fine-tune). XTuner also provides tools for chatting with pretrained / fine-tuned LLMs and deploying fine-tuned LLMs with any other framework, such as LMDeploy.

UMOE-Scaling-Unified-Multimodal-LLMs
Uni-MoE is a MoE-based unified multimodal model that can handle diverse modalities including audio, speech, image, text, and video. The project focuses on scaling Unified Multimodal LLMs with a Mixture of Experts framework. It offers enhanced functionality for training across multiple nodes and GPUs, as well as parallel processing at both the expert and modality levels. The model architecture involves three training stages: building connectors for multimodal understanding, developing modality-specific experts, and incorporating multiple trained experts into LLMs using the LoRA technique on mixed multimodal data. The tool provides instructions for installation, weights organization, inference, training, and evaluation on various datasets.
argilla
Argilla is a collaboration platform for AI engineers and domain experts that require high-quality outputs, full data ownership, and overall efficiency. It helps users improve AI output quality through data quality, take control of their data and models, and improve efficiency by quickly iterating on the right data and models. Argilla is an open-source community-driven project that provides tools for achieving and maintaining high-quality data standards, with a focus on NLP and LLMs. It is used by AI teams from companies like the Red Cross, Loris.ai, and Prolific to improve the quality and efficiency of AI projects.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.

llm-finetuning
llm-finetuning is a repository that provides a serverless twist to the popular axolotl fine-tuning library using Modal's serverless infrastructure. It allows users to quickly fine-tune any LLM model with state-of-the-art optimizations like Deepspeed ZeRO, LoRA adapters, Flash attention, and Gradient checkpointing. The repository simplifies the fine-tuning process by not exposing all CLI arguments, instead allowing users to specify options in a config file. It supports efficient training and scaling across multiple GPUs, making it suitable for production-ready fine-tuning jobs.

AutoGPTQ
AutoGPTQ is an easy-to-use LLM quantization package with user-friendly APIs, based on GPTQ algorithm (weight-only quantization). It provides a simple and efficient way to quantize large language models (LLMs) to reduce their size and computational cost while maintaining their performance. AutoGPTQ supports a wide range of LLM models, including GPT-2, GPT-J, OPT, and BLOOM. It also supports various evaluation tasks, such as language modeling, sequence classification, and text summarization. With AutoGPTQ, users can easily quantize their LLM models and deploy them on resource-constrained devices, such as mobile phones and embedded systems.
clarity-upscaler
Clarity AI is a free and open-source AI image upscaler and enhancer, providing an alternative to Magnific. It offers various features such as multi-step upscaling, resemblance fixing, speed improvements, support for custom safetensors checkpoints, anime upscaling, LoRa support, pre-downscaling, and fractality. Users can access the tool through the ClarityAI.co app, ComfyUI manager, API, or by deploying and running locally or in the cloud with cog or A1111 webUI. The tool aims to enhance image quality and resolution using advanced AI algorithms and models.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.
20 - OpenAI Gpts
Frontend Developer
AI front-end developer expert in coding React, Nextjs, Vue, Svelte, Typescript, Gatsby, Angular, HTML, CSS, JavaScript & advanced in Flexbox, Tailwind & Material Design. Mentors in coding & debugging for junior, intermediate & senior front-end developers alike. Let’s code, build & deploy a SaaS app.





Azure Arc Expert
Azure Arc expert providing guidance on architecture, deployment, and management.

Instructor GCP ML
Formador para la certificación de ML Engineer en GCP, con respuestas y explicaciones detalladas.

Docker and Docker Swarm Assistant
Expert in Docker and Docker Swarm solutions and troubleshooting.



Cloudwise Consultant
Expert in cloud-native solutions, provides tailored tech advice and cost estimates.


HuggingFace Helper
A witty yet succinct guide for HuggingFace, offering technical assistance on using the platform - based on their Learning Hub