Best AI tools for< data mining >
20 - AI tool Sites
Data Hivemind
Data Hivemind is a company that provides automation services to businesses. They help businesses automate tasks such as lead generation, project management, recruiting, and CRM setup. Data Hivemind uses a variety of tools to automate tasks, including Zapier, Make.Com, Alteryx, N8N, Python, and others. They also offer a variety of services, including onboarding, weekly consultations, and documentation with every project.
InfraNodus
InfraNodus is a text network visualization tool that helps users generate insights from any discourse by representing it as a network. It uses AI-powered algorithms to identify structural gaps in the text and suggest ways to bridge them. InfraNodus can be used for a variety of purposes, including research, creative writing, marketing, and SEO.
RTutor
RTutor is an AI-powered application that allows users to interact with their data using natural language. Users can upload a dataset and ask questions or request analyses in plain English. RTutor will then generate and run R code to answer the question and provide plots and numeric results. RTutor is designed to help people with some R experience to learn R or be more productive. It can be used to quickly speed up the coding process using R and provides a draft code to test and refine. RTutor is not a replacement for statisticians or data scientists, but it can make them more efficient. It is important to be aware that the generated code can be wrong, so it is important to double-check the results and be mindful of this experimental technology.

Julius AI
Julius AI is a data analytics platform that uses artificial intelligence to help businesses make better decisions. It provides a variety of features, including data visualization, data mining, and predictive analytics. Julius AI is designed to be easy to use, even for non-technical users.

Komodo Health
Komodo Health is a healthcare technology company that provides software applications to enable users to deliver exceptional value to their customers, colleagues, and patients. The company's Healthcare Map is the industry's most precise view of the U.S. healthcare system, and it combines the world's most comprehensive view of patient-encounters with innovative algorithms and decades of clinical expertise. Komodo Health's software applications are used by life sciences companies, payers, providers, and consultancies to improve the certainty of pre-launch plans, calculate Rx-based ROI for digital marketing, find patients with complicated or rare conditions, and more.
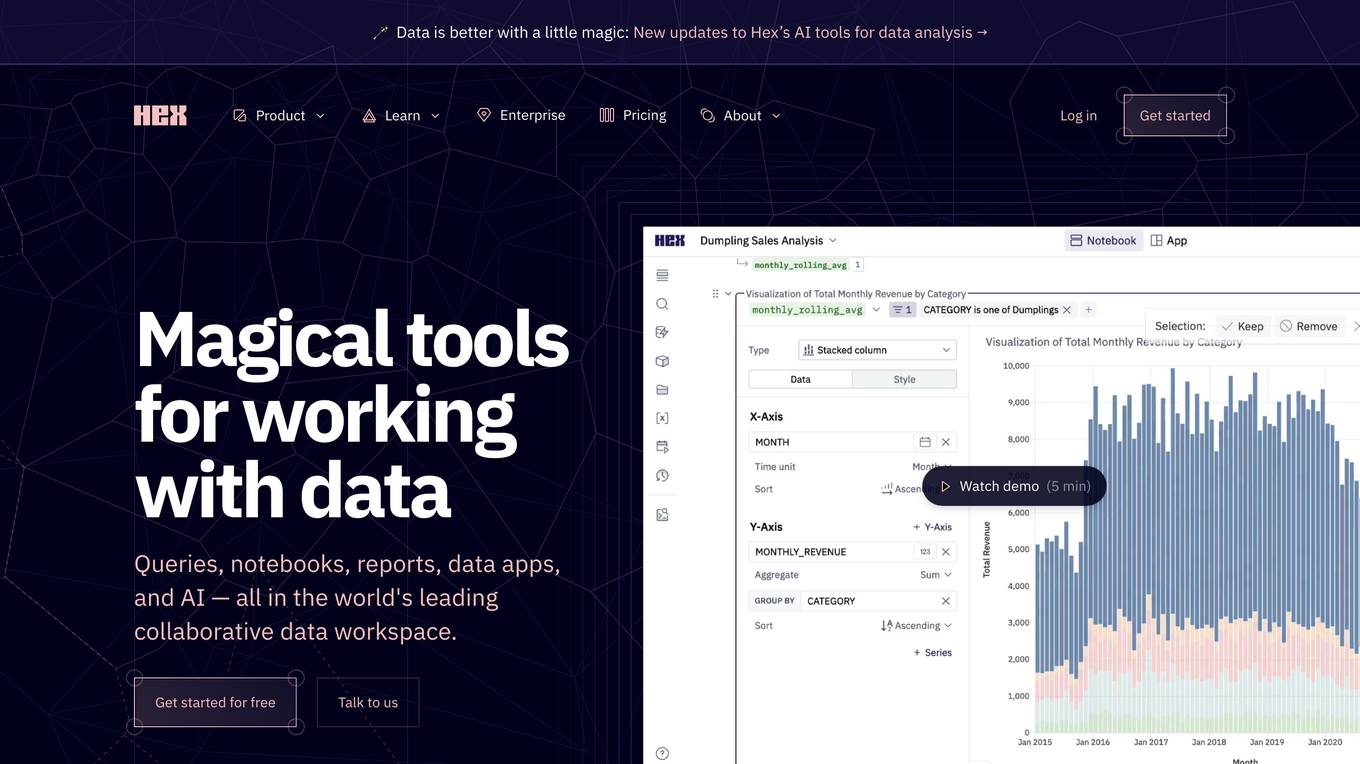
Hex
Hex is a collaborative data workspace that provides a variety of tools for working with data, including queries, notebooks, reports, data apps, and AI. It is designed to be easy to use for people of all technical skill levels, and it integrates with a variety of other tools and services. Hex is a powerful tool for data exploration, analysis, and visualization.
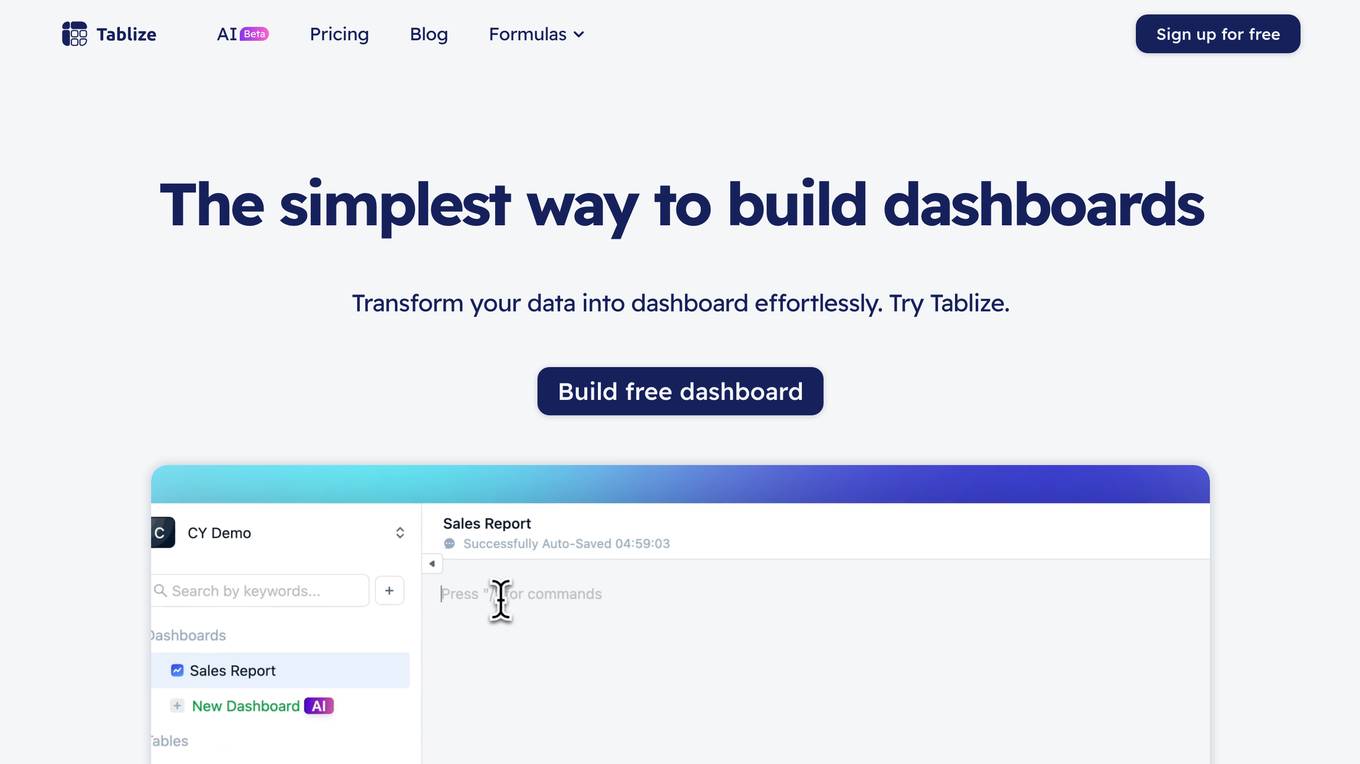
Tablize
Tablize is a powerful data extraction tool that helps you turn unstructured data into structured, tabular format. With Tablize, you can easily extract data from PDFs, images, and websites, and export it to Excel, CSV, or JSON. Tablize uses artificial intelligence to automate the data extraction process, making it fast and easy to get the data you need.
Becoming Human: Artificial Intelligence Magazine
Becoming Human is an Artificial Intelligence Magazine that explores the realm of artificial intelligence and its impact on humanity. The platform offers a wide range of content, including consulting services, tutorials, article submissions, and community engagement. Users can access downloadable cheat sheets for AI, neural networks, machine learning, deep learning, and data science. The magazine covers topics such as AI transformation, quality inspection in automotive, consciousness types, data mining, chatbots, and more.
DrugCard
DrugCard is an AI-enabled data intelligence platform that streamlines drug safety routines. It automates local literature screening, making it faster, more accurate, and more comprehensive. DrugCard supports over 100 languages and covers over 400 local journals, providing global coverage of drug safety information. The platform is designed for CROs, MAHs, and freelancers, helping them save time, improve compliance, and reduce costs.

Tradytics
Tradytics is a financial data and analytics platform that provides traders with access to a wide range of tools and data, including options flow, market news, and AI-powered trade ideas. The platform is designed to help traders of all levels make more informed decisions and improve their trading performance.

Reworkd
Reworkd is a web data extraction tool that uses AI to generate and repair web extractors on the fly. It allows users to retrieve data from hundreds of websites without the need for developers. Reworkd is used by businesses in a variety of industries, including manufacturing, e-commerce, recruiting, lead generation, and real estate.
Softbuilder
Softbuilder is a software development company focused on creating innovative database tools. Their products include ERBuilder Data Modeler, AbstraLinx, and SB Data Generator. ERBuilder Data Modeler is an easy-to-use database modeling software for high-quality data models. AbstraLinx is a powerful metadata discovery tool for Salesforce. SB Data Generator is a simple and powerful tool to generate and populate selected tables or entire databases with realistic test data.

Hillda
Hillda is an AI-driven intelligent assistant that elevates customer service through advanced AI technology, immersive 3D avatars, and seamless language translation. It allows users to train their AI by adding data sources, customize their chatbot's appearance, and create a unique avatar reflecting their brand's voice. Hillda leverages AI and immersive technology for superior customer support, sophisticated data mining, dynamic knowledge base management, advanced language translation, and immersive 3D avatars to enhance customer interactions. It ensures robust security and data integrity through encryption and secure data management protocols.
Leadflow
Leadflow is a real estate lead generation software that uses artificial intelligence to help investors find the best deals. It provides access to a database of over 150 million properties, and its filtering tools allow users to narrow down their search to find the most motivated leads. Leadflow also offers a variety of marketing tools to help investors reach their target audience. With its user-friendly interface and powerful features, Leadflow is a valuable tool for any real estate investor.
Crustdata
Crustdata is an AI-powered company and competitor search engine that provides the most accurate results using free text search. With a proprietary database of millions of companies, 100+ metrics, and billions of data points updated weekly, Crustdata enables users to find companies and competitors based on any descriptors and metrics. The platform offers real-time hiring and employee growth metrics, job listing tracking, and executive hire information. Crustdata is designed to help businesses discover outperforming companies, benchmark against competitors, and gain an edge in the market.
AcademicID
AcademicID is an AI-powered platform that helps students and researchers discover and access academic resources. It provides a comprehensive database of academic papers, journals, and other resources, as well as tools to help users organize and manage their research. AcademicID also offers a variety of features to help users collaborate with others and share their research findings.
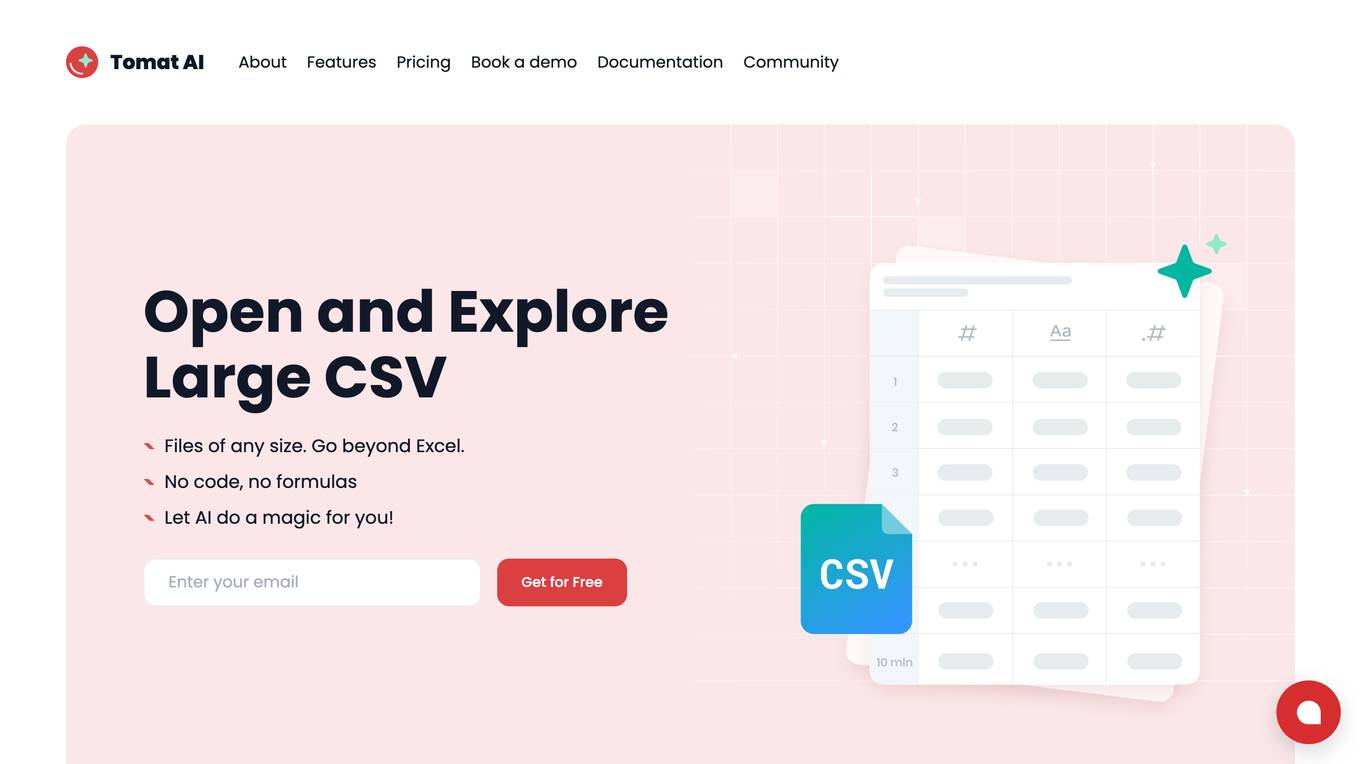
Tomat AI
Tomat AI is a powerful tool that allows you to open and explore large CSV files without the need for code or formulas. With its intuitive drag-and-drop interface, you can easily filter, sort, and group rows, as well as merge multiple files into a single table. Tomat AI also includes a built-in AI assistant that can help you enrich, translate, analyze, and clean up your data. Whether you're a data analyst, a researcher, or a business user, Tomat AI can help you get the most out of your data.

Parlay Analyzer
Parlay Analyzer is a sports analytics tool that provides users with a variety of features to help them make informed decisions about their bets. With Parlay Analyzer, users can look up complex stats with plain English, visualize shot charts for players, check the odds of their parlay and see how many times it hit in the last several games, and compare player props and game lines from all major bookmakers.

Lumina
Lumina is a research tool that uses artificial intelligence to help researchers find and analyze information more quickly and easily. It can be used to search for articles, books, and other resources, and it can also be used to analyze data and create visualizations. Lumina is designed to make research more efficient and productive.
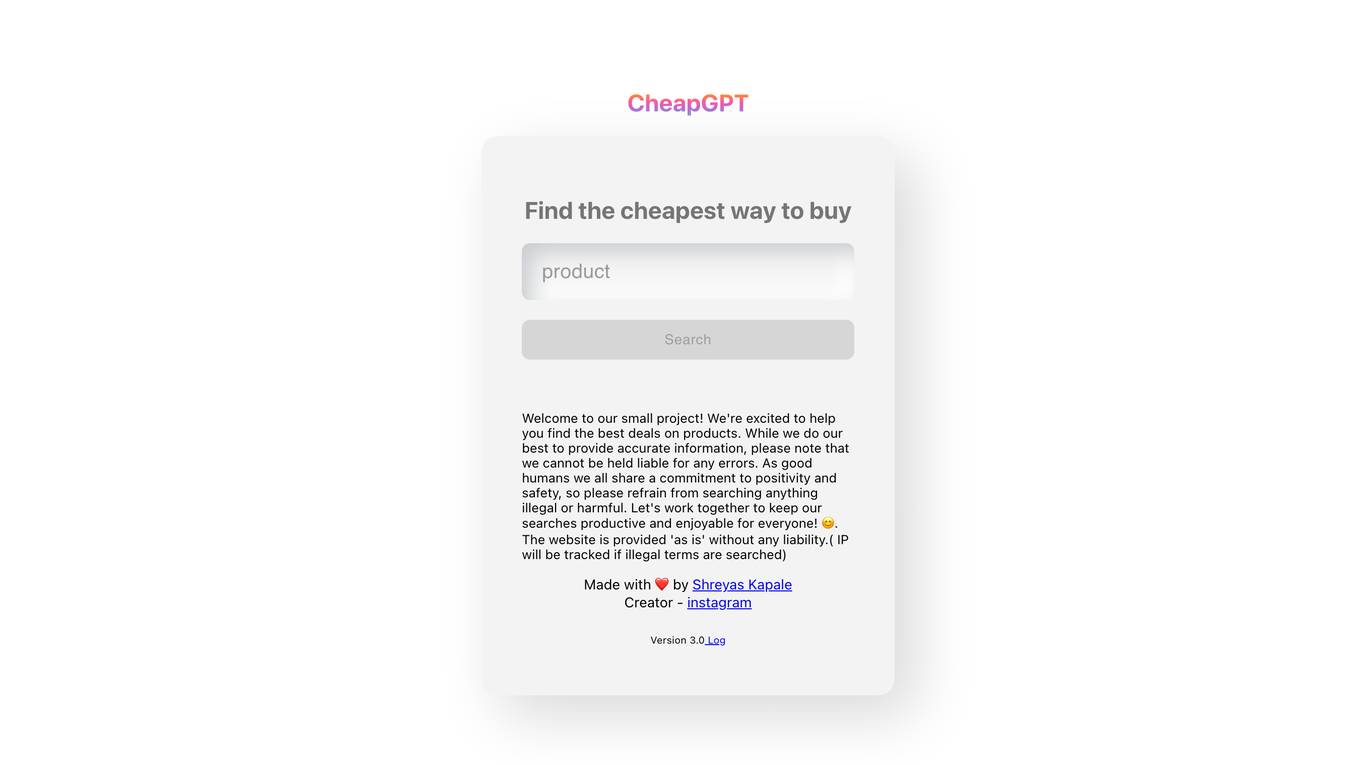
CheapGPT
CheapGPT is a search engine that helps users find the best deals on products. It is a small project that is still in development, but it has already helped many people save money. CheapGPT is committed to providing accurate information and keeping searches productive and enjoyable for everyone.
20 - Open Source AI Tools
CoML
CoML (formerly MLCopilot) is an interactive coding assistant for data scientists and machine learning developers, empowered on large language models. It offers an out-of-the-box interactive natural language programming interface for data mining and machine learning tasks, integration with Jupyter lab and Jupyter notebook, and a built-in large knowledge base of machine learning to enhance the ability to solve complex tasks. The tool is designed to assist users in coding tasks related to data analysis and machine learning using natural language commands within Jupyter environments.
AI-Notes
AI-Notes is a repository dedicated to practical applications of artificial intelligence and deep learning. It covers concepts such as data mining, machine learning, natural language processing, and AI. The repository contains Jupyter Notebook examples for hands-on learning and experimentation. It explores the development stages of AI, from narrow artificial intelligence to general artificial intelligence and superintelligence. The content delves into machine learning algorithms, deep learning techniques, and the impact of AI on various industries like autonomous driving and healthcare. The repository aims to provide a comprehensive understanding of AI technologies and their real-world applications.
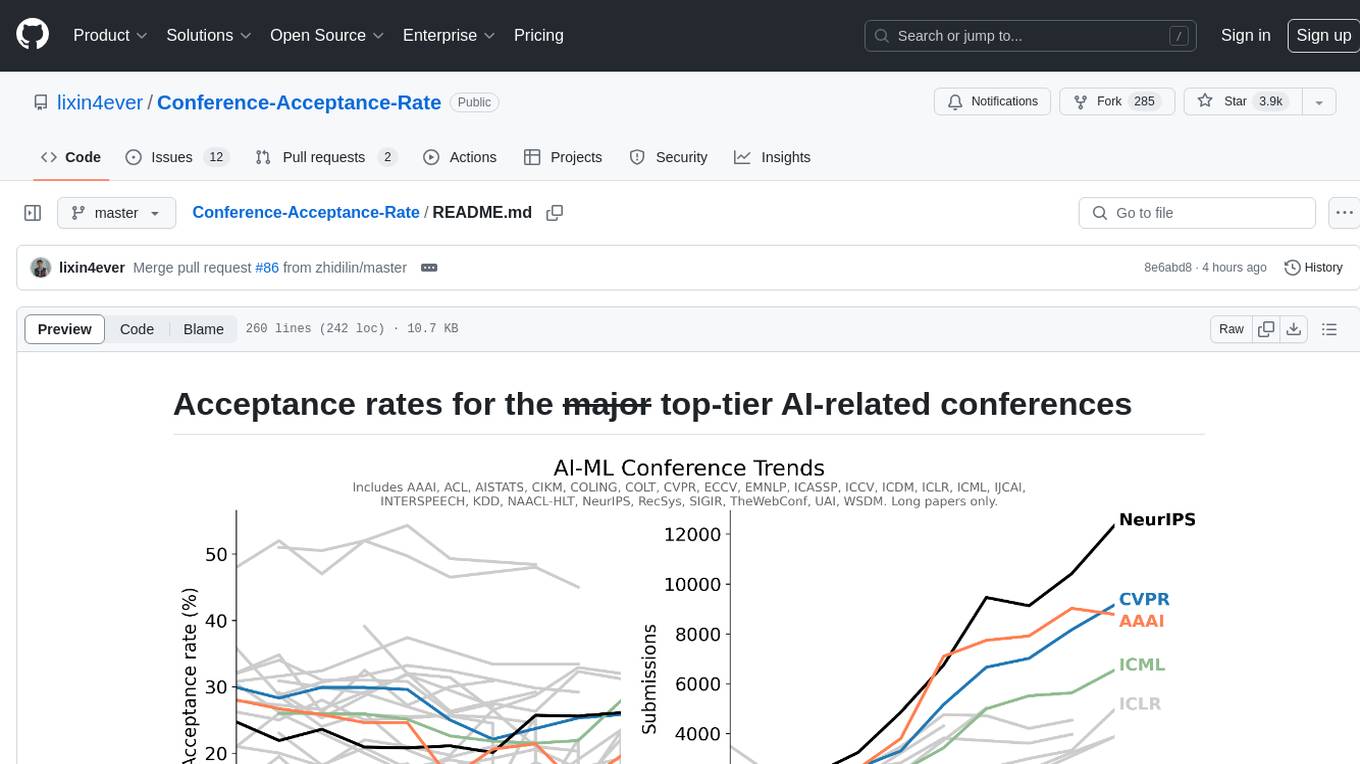
Conference-Acceptance-Rate
The 'Conference-Acceptance-Rate' repository provides acceptance rates for top-tier AI-related conferences in the fields of Natural Language Processing, Computational Linguistics, Computer Vision, Pattern Recognition, Machine Learning, Learning Theory, Artificial Intelligence, Data Mining, Information Retrieval, Speech Processing, and Signal Processing. The data includes acceptance rates for long papers and short papers over several years for each conference, allowing researchers to track trends and make informed decisions about where to submit their work.

llm-datasets
LLM Datasets is a repository containing high-quality datasets, tools, and concepts for LLM fine-tuning. It provides datasets with characteristics like accuracy, diversity, and complexity to train large language models for various tasks. The repository includes datasets for general-purpose, math & logic, code, conversation & role-play, and agent & function calling domains. It also offers guidance on creating high-quality datasets through data deduplication, data quality assessment, data exploration, and data generation techniques.
Efficient-LLMs-Survey
This repository provides a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from **model-centric** , **data-centric** , and **framework-centric** perspective, respectively. We hope our survey and this GitHub repository can serve as valuable resources to help researchers and practitioners gain a systematic understanding of the research developments in efficient LLMs and inspire them to contribute to this important and exciting field.
cuvs
cuVS is a library that contains state-of-the-art implementations of several algorithms for running approximate nearest neighbors and clustering on the GPU. It can be used directly or through the various databases and other libraries that have integrated it. The primary goal of cuVS is to simplify the use of GPUs for vector similarity search and clustering.
interpret
InterpretML is an open-source package that incorporates state-of-the-art machine learning interpretability techniques under one roof. With this package, you can train interpretable glassbox models and explain blackbox systems. InterpretML helps you understand your model's global behavior, or understand the reasons behind individual predictions. Interpretability is essential for: - Model debugging - Why did my model make this mistake? - Feature Engineering - How can I improve my model? - Detecting fairness issues - Does my model discriminate? - Human-AI cooperation - How can I understand and trust the model's decisions? - Regulatory compliance - Does my model satisfy legal requirements? - High-risk applications - Healthcare, finance, judicial, ...
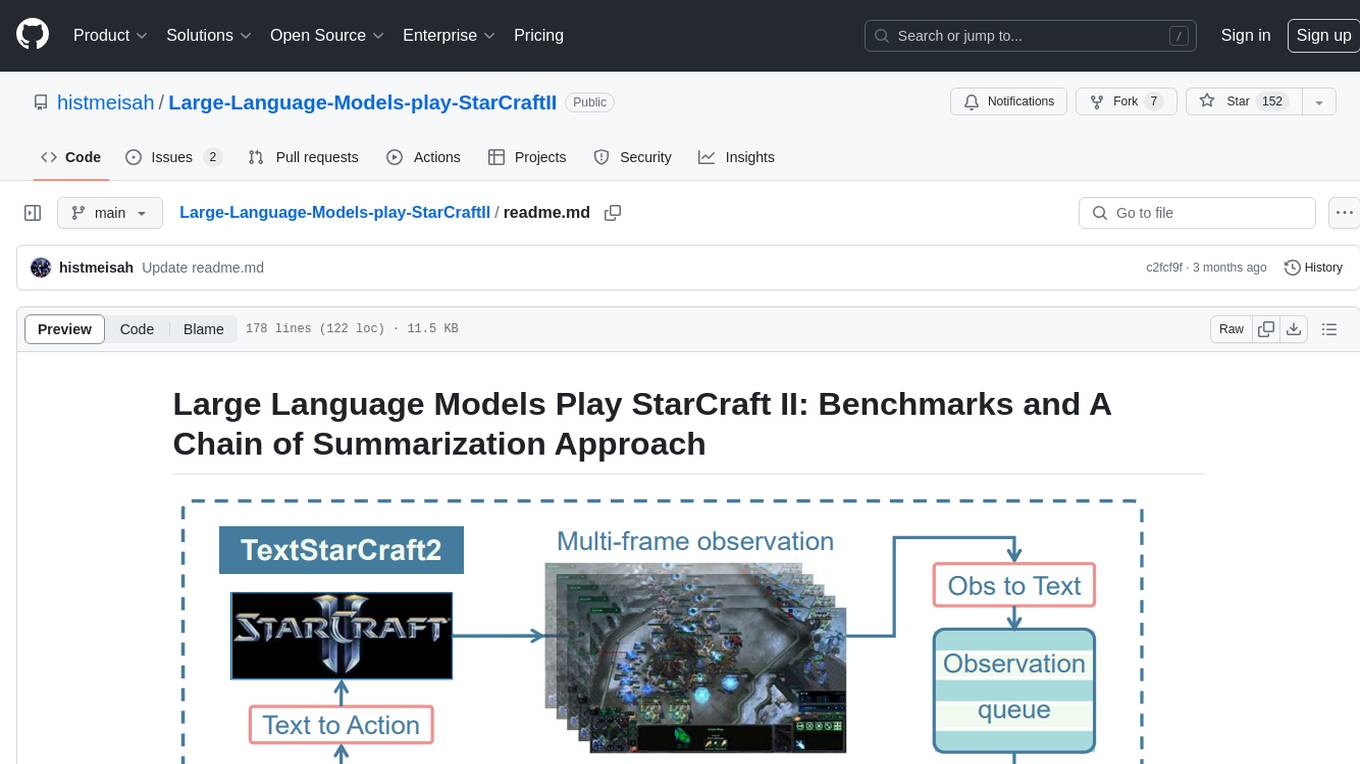
Large-Language-Models-play-StarCraftII
Large Language Models Play StarCraft II is a project that explores the capabilities of large language models (LLMs) in playing the game StarCraft II. The project introduces TextStarCraft II, a textual environment for the game, and a Chain of Summarization method for analyzing game information and making strategic decisions. Through experiments, the project demonstrates that LLM agents can defeat the built-in AI at a challenging difficulty level. The project provides benchmarks and a summarization approach to enhance strategic planning and interpretability in StarCraft II gameplay.
SLR-FC
This repository provides a comprehensive collection of AI tools and resources to enhance literature reviews. It includes a curated list of AI tools for various tasks, such as identifying research gaps, discovering relevant papers, visualizing paper content, and summarizing text. Additionally, the repository offers materials on generative AI, effective prompts, copywriting, image creation, and showcases of AI capabilities. By leveraging these tools and resources, researchers can streamline their literature review process, gain deeper insights from scholarly literature, and improve the quality of their research outputs.
DataFrame
DataFrame is a C++ analytical library designed for data analysis similar to libraries in Python and R. It allows you to slice, join, merge, group-by, and perform various statistical, summarization, financial, and ML algorithms on your data. DataFrame also includes a large collection of analytical algorithms in form of visitors, ranging from basic stats to more involved analysis. You can easily add your own algorithms as well. DataFrame employs extensive multithreading in almost all its APIs, making it suitable for analyzing large datasets. Key principles followed in the library include supporting any type without needing new code, avoiding pointer chasing, having all column data in contiguous memory space, minimizing space usage, avoiding data copying, using multi-threading judiciously, and not protecting the user against garbage in, garbage out.
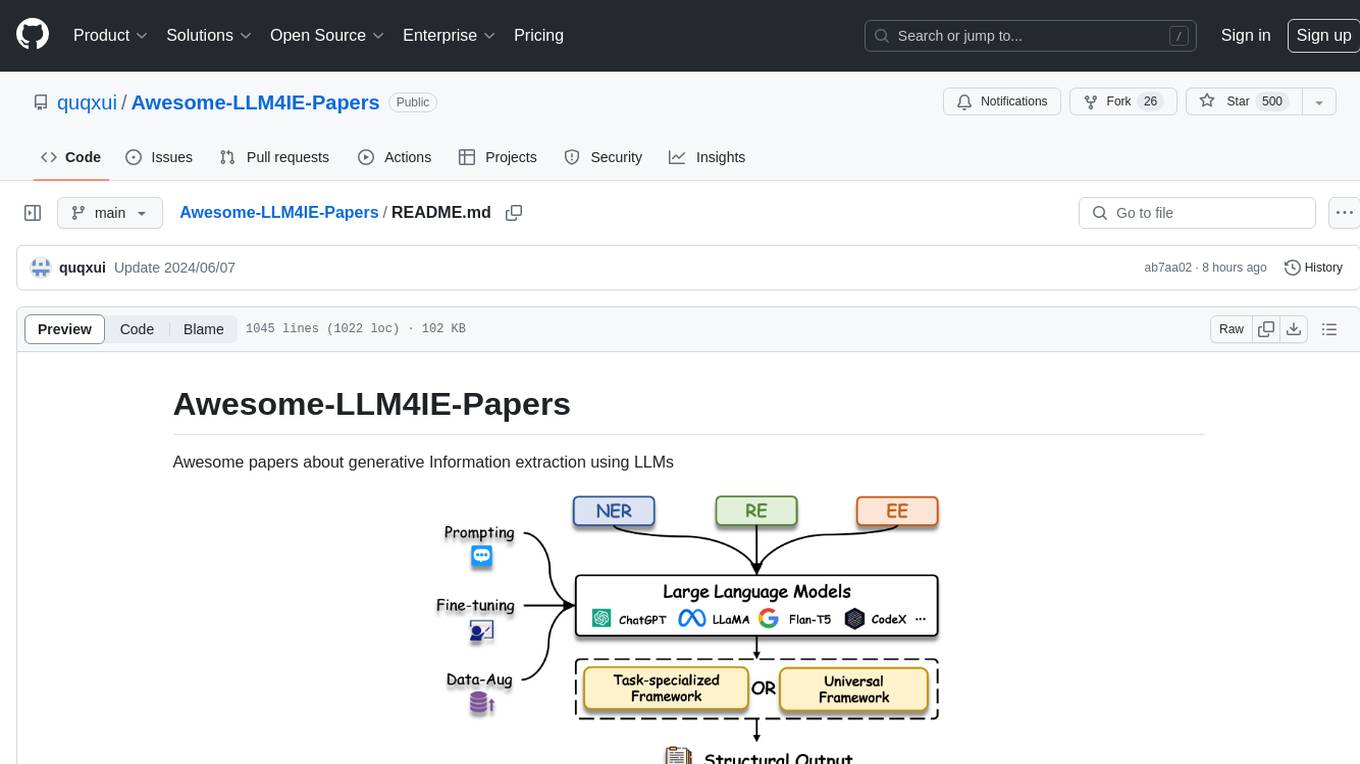

deepdoctection
**deep** doctection is a Python library that orchestrates document extraction and document layout analysis tasks using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models. For more specific text processing tasks use one of the many other great NLP libraries. **deep** doctection focuses on applications and is made for those who want to solve real world problems related to document extraction from PDFs or scans in various image formats. **deep** doctection provides model wrappers of supported libraries for various tasks to be integrated into pipelines. Its core function does not depend on any specific deep learning library. Selected models for the following tasks are currently supported: * Document layout analysis including table recognition in Tensorflow with **Tensorpack**, or PyTorch with **Detectron2**, * OCR with support of **Tesseract**, **DocTr** (Tensorflow and PyTorch implementations available) and a wrapper to an API for a commercial solution, * Text mining for native PDFs with **pdfplumber**, * Language detection with **fastText**, * Deskewing and rotating images with **jdeskew**. * Document and token classification with all LayoutLM models provided by the **Transformer library**. (Yes, you can use any LayoutLM-model with any of the provided OCR-or pdfplumber tools straight away!). * Table detection and table structure recognition with **table-transformer**. * There is a small dataset for token classification available and a lot of new tutorials to show, how to train and evaluate this dataset using LayoutLMv1, LayoutLMv2, LayoutXLM and LayoutLMv3. * Comprehensive configuration of **analyzer** like choosing different models, output parsing, OCR selection. Check this notebook or the docs for more infos. * Document layout analysis and table recognition now runs with **Torchscript** (CPU) as well and **Detectron2** is not required anymore for basic inference. * [**new**] More angle predictors for determining the rotation of a document based on **Tesseract** and **DocTr** (not contained in the built-in Analyzer). * [**new**] Token classification with **LiLT** via **transformers**. We have added a model wrapper for token classification with LiLT and added a some LiLT models to the model catalog that seem to look promising, especially if you want to train a model on non-english data. The training script for LayoutLM can be used for LiLT as well and we will be providing a notebook on how to train a model on a custom dataset soon. **deep** doctection provides on top of that methods for pre-processing inputs to models like cropping or resizing and to post-process results, like validating duplicate outputs, relating words to detected layout segments or ordering words into contiguous text. You will get an output in JSON format that you can customize even further by yourself. Have a look at the **introduction notebook** in the notebook repo for an easy start. Check the **release notes** for recent updates. **deep** doctection or its support libraries provide pre-trained models that are in most of the cases available at the **Hugging Face Model Hub** or that will be automatically downloaded once requested. For instance, you can find pre-trained object detection models from the Tensorpack or Detectron2 framework for coarse layout analysis, table cell detection and table recognition. Training is a substantial part to get pipelines ready on some specific domain, let it be document layout analysis, document classification or NER. **deep** doctection provides training scripts for models that are based on trainers developed from the library that hosts the model code. Moreover, **deep** doctection hosts code to some well established datasets like **Publaynet** that makes it easy to experiment. It also contains mappings from widely used data formats like COCO and it has a dataset framework (akin to **datasets** so that setting up training on a custom dataset becomes very easy. **This notebook** shows you how to do this. **deep** doctection comes equipped with a framework that allows you to evaluate predictions of a single or multiple models in a pipeline against some ground truth. Check again **here** how it is done. Having set up a pipeline it takes you a few lines of code to instantiate the pipeline and after a for loop all pages will be processed through the pipeline.
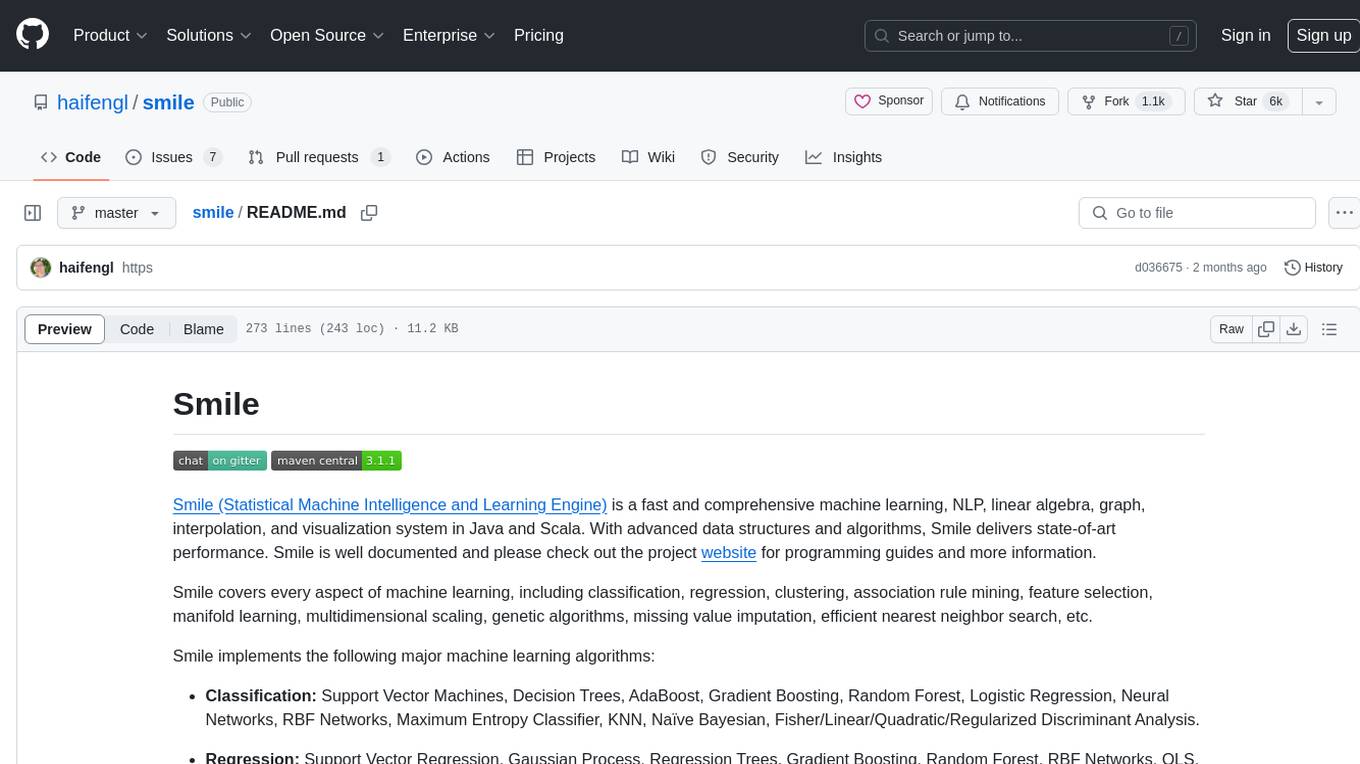
smile
Smile (Statistical Machine Intelligence and Learning Engine) is a comprehensive machine learning, NLP, linear algebra, graph, interpolation, and visualization system in Java and Scala. It covers every aspect of machine learning, including classification, regression, clustering, association rule mining, feature selection, manifold learning, multidimensional scaling, genetic algorithms, missing value imputation, efficient nearest neighbor search, etc. Smile implements major machine learning algorithms and provides interactive shells for Java, Scala, and Kotlin. It supports model serialization, data visualization using SmilePlot and declarative approach, and offers a gallery showcasing various algorithms and visualizations.

data-scientist-roadmap2024
The Data Scientist Roadmap2024 provides a comprehensive guide to mastering essential tools for data science success. It includes programming languages, machine learning libraries, cloud platforms, and concepts categorized by difficulty. The roadmap covers a wide range of topics from programming languages to machine learning techniques, data visualization tools, and DevOps/MLOps tools. It also includes web development frameworks and specific concepts like supervised and unsupervised learning, NLP, deep learning, reinforcement learning, and statistics. Additionally, it delves into DevOps tools like Airflow and MLFlow, data visualization tools like Tableau and Matplotlib, and other topics such as ETL processes, optimization algorithms, and financial modeling.
mslearn-knowledge-mining
The mslearn-knowledge-mining repository contains lab files for Azure AI Knowledge Mining modules. It provides resources for learning and implementing knowledge mining techniques using Azure AI services. The repository is designed to help users explore and understand how to leverage AI for knowledge mining purposes within the Azure ecosystem.
trickPrompt-engine
This repository contains a vulnerability mining engine based on GPT technology. The engine is designed to identify logic vulnerabilities in code by utilizing task-driven prompts. It does not require prior knowledge or fine-tuning and focuses on prompt design rather than model design. The tool is effective in real-world projects and should not be used for academic vulnerability testing. It supports scanning projects in various languages, with current support for Solidity. The engine is configured through prompts and environment settings, enabling users to scan for vulnerabilities in their codebase. Future updates aim to optimize code structure, add more language support, and enhance usability through command line mode. The tool has received a significant audit bounty of $50,000+ as of May 2024.

Awesome-Segment-Anything
Awesome-Segment-Anything is a powerful tool for segmenting and extracting information from various types of data. It provides a user-friendly interface to easily define segmentation rules and apply them to text, images, and other data formats. The tool supports both supervised and unsupervised segmentation methods, allowing users to customize the segmentation process based on their specific needs. With its versatile functionality and intuitive design, Awesome-Segment-Anything is ideal for data analysts, researchers, content creators, and anyone looking to efficiently extract valuable insights from complex datasets.
finagg
finagg is a Python package that provides implementations of popular and free financial APIs, tools for aggregating historical data from those APIs into SQL databases, and tools for transforming aggregated data into features useful for analysis and AI/ML. It offers documentation, installation instructions, and basic usage examples for exploring various financial APIs and features. Users can install recommended datasets from 3rd party APIs into a local SQL database, access Bureau of Economic Analysis (BEA) data, Federal Reserve Economic Data (FRED), Securities and Exchange Commission (SEC) filings, and more. The package also allows users to explore raw data features, install refined data features, and perform refined aggregations of raw data. Configuration options for API keys, user agents, and data locations are provided, along with information on dependencies and related projects.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.
20 - OpenAI Gpts



AI OSINT
Your AI OSINT assistant. Our tool helps you find the data needle in the internet haystack.

(Unofficial) GNoME Materials Discovery AI
Explore, render, and ask questions about materials discovered in the GNoME project


CryptoCalc
Calculates crypto earnings for Ghosts of Tabor based on GPUs and Intel room level

Your Business Data Optimizer Pro
A chatbot expert in business data analysis and optimization.
Data Dynamo
A friendly data science coach offering practical, useful, and accurate advice.