Best AI tools for< Yaml Analyst >
Infographic
5 - AI tool Sites
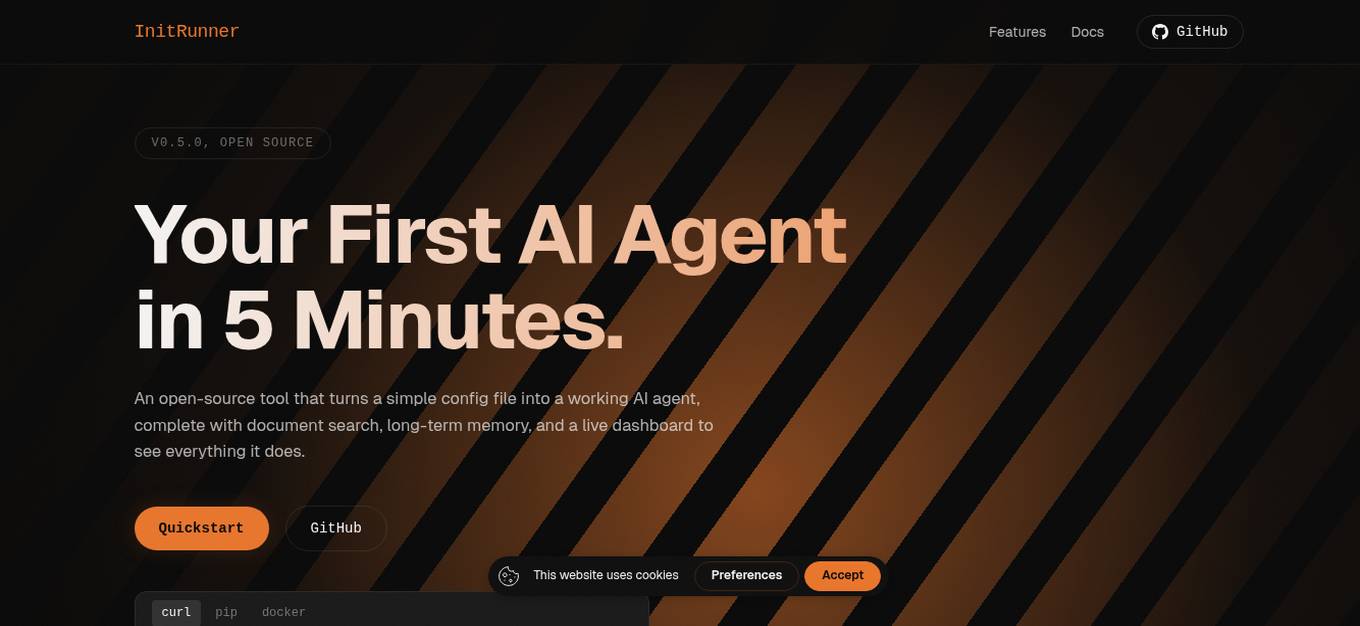
InitRunner
InitRunner is an open-source AI tool that allows users to create AI agents quickly by converting a simple config file into a functional AI agent. It offers features such as document search, long-term memory, and a live dashboard. Users can define agent roles, tools, and behaviors in YAML format without the need to learn a specific framework. The tool provides full auditability with every decision logged in an immutable SQLite log. It enables users to swap providers easily, schedule tasks, and integrate custom tools. InitRunner also supports autonomous planning, execution, and adaptation of multi-step tasks. The platform includes built-in capabilities like RAG, memory, reusable skills, and an OpenAI-compatible API server, all configurable in YAML without external services required.
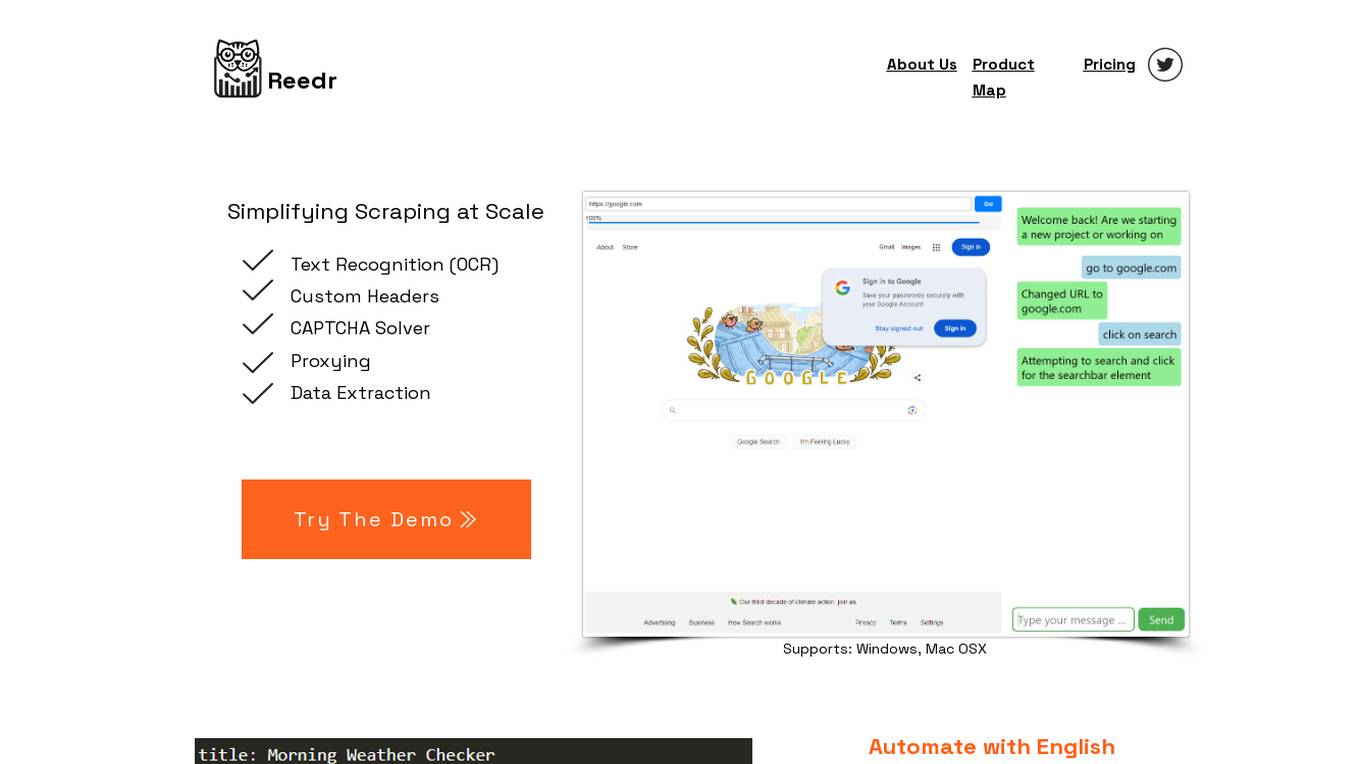
Reedr
Reedr is an AI-powered browser automation tool that simplifies scraping at scale. It offers features such as text recognition (OCR), custom headers, CAPTCHA solver, and proxying for efficient data extraction. With Reedr, users can automate tasks, generate reports, and monitor running tasks in real-time. The tool utilizes AI capabilities to convert visible text and images on web pages into formatted data, supporting various data processing needs. Additionally, Reedr provides customized real-time reporting with API endpoints for different reporting teams, enabling data export in formats like CSV, XLSX, JSON, and YAML. The tool prioritizes industry-leading compliance, adhering to data protection laws and privacy regulations like GDPR.
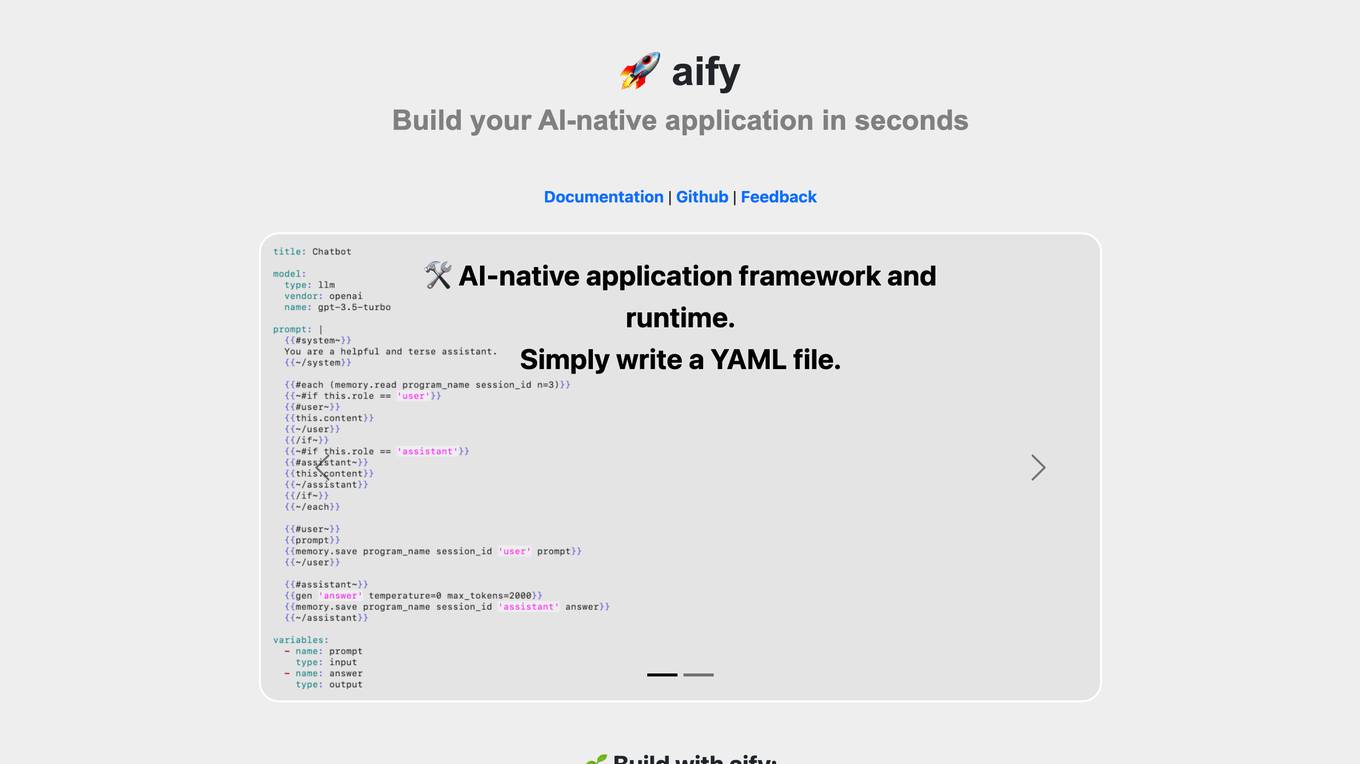
aify
aify is an AI-native application framework and runtime that allows users to build AI-native applications quickly and easily. With aify, users can create applications by simply writing a YAML file. The platform also offers a ready-to-use AI chatbot UI for seamless integration. Additionally, aify provides features such as Emoji express for searching emojis by semantics. The framework is open source under the MIT license, making it accessible to developers of all levels.
Pulumi
Pulumi is an AI-powered infrastructure as code tool that allows engineers to manage cloud infrastructure using various programming languages like Node.js, Python, Go, .NET, Java, and YAML. It offers features such as generative AI-powered cloud management, security enforcement through policies, automated deployment workflows, asset management, compliance remediation, and AI insights over the cloud. Pulumi helps teams provision, automate, and evolve cloud infrastructure, centralize and secure secrets management, and gain security, compliance, and cost insights across all cloud assets.
Modal
Modal is a high-performance cloud platform designed for developers, AI data, and ML teams. It offers a serverless environment for running generative AI models, large-scale batch jobs, job queues, and more. With Modal, users can bring their own code and leverage the platform's optimized container file system for fast cold boots and seamless autoscaling. The platform is engineered for large-scale workloads, allowing users to scale to hundreds of GPUs, pay only for what they use, and deploy functions to the cloud in seconds without the need for YAML or Dockerfiles. Modal also provides features for job scheduling, web endpoints, observability, and security compliance.
0 - Open Source Tools
7 - OpenAI Gpts



Interactive Spring API Creator
Pass in the attributes of Pojo entity class objects, generate corresponding addition, deletion, modification, and pagination query functions, including generating database connection configuration files yaml and database script files, as well as XML dynamic SQL concatenation statements.

Octorate Code Companion
I help developers understand and use APIs, referencing a YAML model.
IAC Code Guardian
Introducing IAC Code Guardian: Your Trusted IaC Security Expert in Scanning Opentofu, Terrform, AWS Cloudformation, Pulumi, K8s Yaml & Dockerfile