Best AI tools for< Middleware Engineer >
Infographic
2 - AI tool Sites
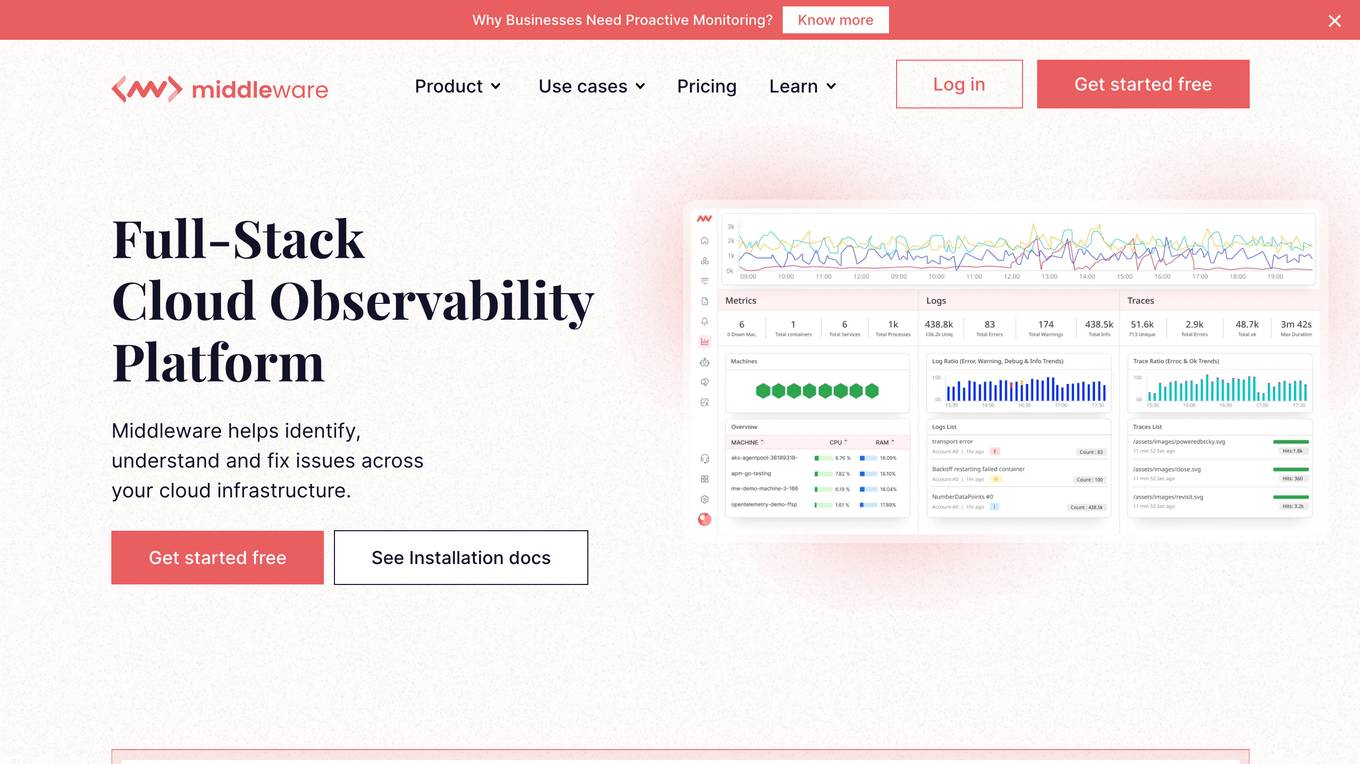
Cloud Observability Middleware
The website provides Full-Stack Cloud Observability services with a focus on Middleware. It offers comprehensive monitoring and analysis tools to help businesses optimize their cloud infrastructure performance. The platform enables users to gain insights into their middleware applications, identify bottlenecks, and improve overall system efficiency.

Rozie AI
Rozie AI is an AI partner that helps create personalized experiences at scale for leading brands. The platform offers a middleware solution, agentic AI capabilities, and pre-built experience kits to manage the entire process from ideation to implementation. Rozie AI specializes in experience design, digital engagement, and applying artificial intelligence to future-proof product experiences. The company empowers clients to own their experiences while off-loading the tech stack maintenance. With customizable solutions, Rozie AI delivers speed, scalability, and control for innovative CX solutions.
1 - Open Source Tools
EDDI
E.D.D.I (Enhanced Dialog Driven Interface) is an enterprise-certified chatbot middleware that offers advanced prompt and conversation management for Conversational AI APIs. Developed in Java using Quarkus, it is lean, RESTful, scalable, and cloud-native. E.D.D.I is highly scalable and designed to efficiently manage conversations in AI-driven applications, with seamless API integration capabilities. Notable features include configurable NLP and Behavior rules, support for multiple chatbots running concurrently, and integration with MongoDB, OAuth 2.0, and HTML/CSS/JavaScript for UI. The project requires Java 21, Maven 3.8.4, and MongoDB >= 5.0 to run. It can be built as a Docker image and deployed using Docker or Kubernetes, with additional support for integration testing and monitoring through Prometheus and Kubernetes endpoints.
2 - OpenAI Gpts


Code Architect for Nuxt
Nuxt coding assistant, with knowledge of the latest Nuxt documentation