
caddy-defender
Caddy module to block or manipulate requests originating from AIs or cloud services trying to train on your websites
Stars: 432
The Caddy Defender plugin is a middleware for Caddy that allows you to block or manipulate requests based on the client's IP address. It provides features such as IP range filtering, predefined IP ranges for popular AI services, custom IP ranges configuration, and multiple responder backends for different actions like blocking, custom responses, dropping connections, returning garbage data, redirecting, and tarpitting to stall bots. The plugin can be easily installed using Docker or built with `xcaddy`. Configuration is done through the Caddyfile syntax with various options for responders, IP ranges, custom messages, and URLs.
README:
The Caddy Defender plugin is a middleware for Caddy that allows you to block or manipulate requests based on the client's IP address. It is particularly useful for preventing unwanted traffic or polluting AI training data by returning garbage responses.
- IP Range Filtering: Block or manipulate requests from specific IP ranges.
- Embedded IP Ranges: Predefined IP ranges for popular AI services (e.g., OpenAI, DeepSeek, GitHub Copilot).
- Custom IP Ranges: Add your own IP ranges via Caddyfile configuration.
-
Multiple Responder Backends:
-
Block: Return a
403 Forbiddenresponse. - Custom: Return a custom message.
- Drop: Drops the connection.
- Garbage: Return garbage data to pollute AI training.
-
Redirect: Return a
308 Permanent Redirectresponse with a custom URL. - Ratelimit: Ratelimit requests, configurable via caddy-ratelimit.
- Tarpit: Stream data at a slow, but configurable rate to stall bots and pollute AI training.
-
Block: Return a
The easiest way to use the Caddy Defender plugin is by using the pre-built Docker image.
-
Pull the Docker Image:
docker pull ghcr.io/jasonlovesdoggo/caddy-defender:latest
-
Run the Container: Use the following command to run the container with your
Caddyfile:docker run -d \ --name caddy \ -v /path/to/Caddyfile:/etc/caddy/Caddyfile \ -p 80:80 -p 443:443 \ ghcr.io/jasonlovesdoggo/caddy-defender:latest
Replace
/path/to/Caddyfilewith the path to yourCaddyfile.
Please see the online documentation for other methods of installation.
The defender directive is used to configure the Caddy Defender plugin. It has the following syntax:
defender <responder> {
message <custom message>
ranges <ip_ranges...>
url <url>
}-
<responder>: The responder backend to use. Supported values are:-
block: Returns a403 Forbiddenresponse. -
custom: Returns a custom message (requiresmessage). -
drop: Drops the connection. -
garbage: Returns garbage data to pollute AI training. -
redirect: Returns a308 Permanent Redirectresponse (requiresurl). -
ratelimit: Marks requests for rate limiting (requires Caddy-Ratelimit to be installed as well ). -
tarpit: Stream data at a slow, but configurable rate to stall bots and pollute AI training.
-
-
<ip_ranges...>: An optional list of CIDR ranges or predefined range keys to match against the client's IP. Defaults toaws azurepubliccloud deepseek gcloud githubcopilot openai. -
<custom message>: A custom message to return when using thecustomresponder. -
<url>: The URI that theredirectresponder would redirect to.
For more information about the configuration, refer to the configuration page on the website.
The documentation website has info that includes the configurations of the plugin, code examples, and more.
For a quick start, follow the Getting Started guide to protect your server using the Caddy Defender Plugin.
For examples, check out docs/examples.md
The plugin includes predefined IP ranges for popular AI services. These ranges are embedded in the binary and can be used without additional configuration.
| Service | Key | IP Ranges |
|---|---|---|
| Alibaba Cloud | aliyun | aliyun.go |
| VPNs | vpn | vpn.go |
| AWS | aws | aws.go |
| AWS Region | aws-us-east-1, aws-us-west-1, aws-eu-west-1 | aws_region.go |
| DeepSeek | deepseek | deepseek.go |
| GitHub Copilot | githubcopilot | github.go |
| Google Cloud Platform | gcloud | gcloud.go |
| Oracle Cloud Infrastructure | oci | oracle.go |
| Microsoft Azure | azurepubliccloud | azure.go |
| OpenAI | openai | openai.go |
| Mistral | mistral | mistral.go |
| Vultr | vultr | vultr.go |
| Cloudflare | cloudflare | cloudflare.go |
| Digital Ocean | digitalocean | digitalocean.go |
| Linode | linode | linode.go |
| Private | private | private.go |
| All IP addresses | all | all.go |
| Service | Key | IP Ranges |
|---|---|---|
| Tor Exit Nodes | tor | tor.go |
| ASN (Autonomous System Numbers) | asn | asn.go |
More are welcome! for a precompiled list, see the embedded results
We welcome contributions! To get started, see CONTRIBUTING.md.
This project is licensed under the MIT License. See the LICENSE file for details.
- The inspiration for this project.
- bart - Karl Gaissmaier's efficient routing table implementation (Balanced ART adaptation) enabling our high-performance IP matching
- Built with ❤️ using Caddy.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for caddy-defender
Similar Open Source Tools
caddy-defender
The Caddy Defender plugin is a middleware for Caddy that allows you to block or manipulate requests based on the client's IP address. It provides features such as IP range filtering, predefined IP ranges for popular AI services, custom IP ranges configuration, and multiple responder backends for different actions like blocking, custom responses, dropping connections, returning garbage data, redirecting, and tarpitting to stall bots. The plugin can be easily installed using Docker or built with `xcaddy`. Configuration is done through the Caddyfile syntax with various options for responders, IP ranges, custom messages, and URLs.


airunner
AI Runner is a multi-modal AI interface that allows users to run open-source large language models and AI image generators on their own hardware. The tool provides features such as voice-based chatbot conversations, text-to-speech, speech-to-text, vision-to-text, text generation with large language models, image generation capabilities, image manipulation tools, utility functions, and more. It aims to provide a stable and user-friendly experience with security updates, a new UI, and a streamlined installation process. The application is designed to run offline on users' hardware without relying on a web server, offering a smooth and responsive user experience.
mcp-rubber-duck
MCP Rubber Duck is a Model Context Protocol server that acts as a bridge to query multiple LLMs, including OpenAI-compatible HTTP APIs and CLI coding agents. Users can explain their problems to various AI 'ducks' to get different perspectives. The tool offers features like universal OpenAI compatibility, CLI agent support, conversation management, multi-duck querying, consensus voting, LLM-as-Judge evaluation, structured debates, health monitoring, usage tracking, and more. It supports various HTTP providers like OpenAI, Google Gemini, Anthropic, Groq, Together AI, Perplexity, and CLI providers like Claude Code, Codex, Gemini CLI, Grok, Aider, and custom agents. Users can install the tool globally, configure it using environment variables, and access interactive UIs for comparing ducks, voting, debating, and usage statistics. The tool provides multiple tools for asking questions, chatting, clearing conversations, listing ducks, comparing responses, voting, judging, iterating, debating, and more. It also offers prompt templates for different analysis purposes and extensive documentation for setup, configuration, tools, prompts, CLI providers, MCP Bridge, guardrails, Docker deployment, troubleshooting, contributing, license, acknowledgments, changelog, registry & directory, and support.
google_workspace_mcp
The Google Workspace MCP Server is a production-ready server that integrates major Google Workspace services with AI assistants. It supports single-user and multi-user authentication via OAuth 2.1, making it a powerful backend for custom applications. Built with FastMCP for optimal performance, it features advanced authentication handling, service caching, and streamlined development patterns. The server provides full natural language control over Google Calendar, Drive, Gmail, Docs, Sheets, Slides, Forms, Tasks, and Chat through all MCP clients, AI assistants, and developer tools. It supports free Google accounts and Google Workspace plans with expanded app options like Chat & Spaces. The server also offers private cloud instance options.
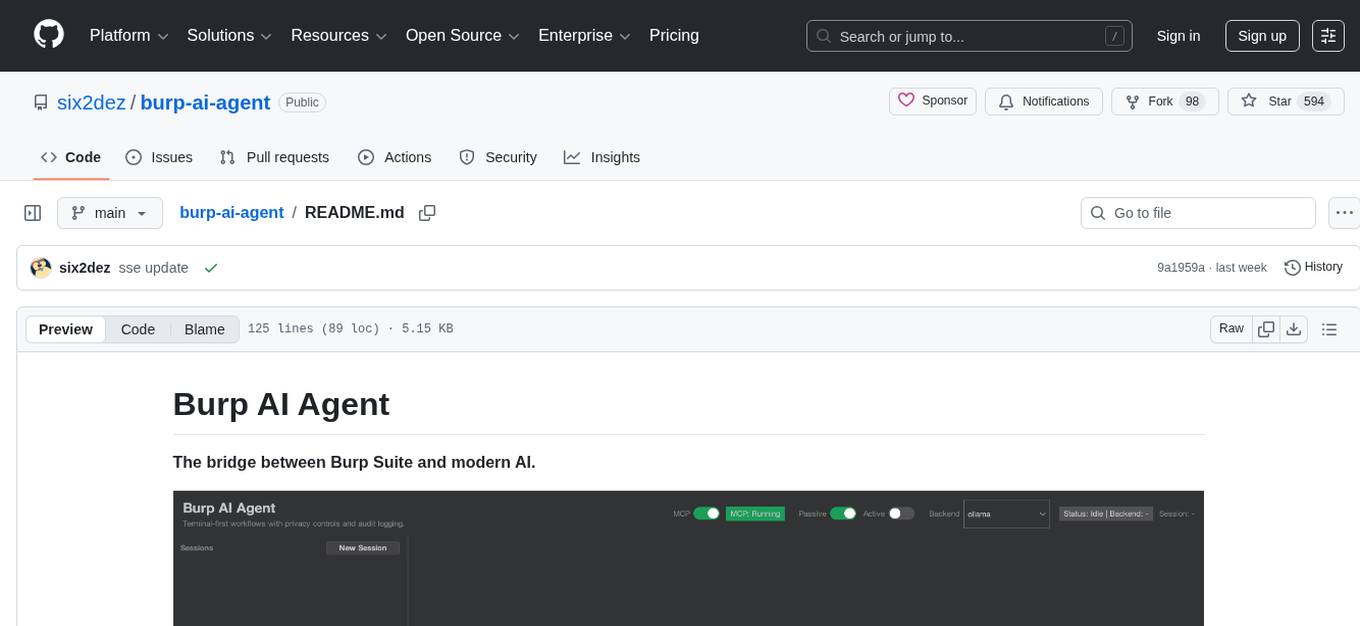
burp-ai-agent
Burp AI Agent is an extension for Burp Suite that integrates AI into your security workflow. It provides 7 AI backends, 53+ MCP tools, and 62 vulnerability classes. Users can configure privacy modes, perform audit logging, and connect external AI agents via MCP. The tool allows passive and active AI scanners to find vulnerabilities while users focus on manual testing. It requires Burp Suite, Java 21, and at least one AI backend configured.
pocketpaw
PocketPaw is a lightweight and user-friendly tool designed for managing and organizing your digital assets. It provides a simple interface for users to easily categorize, tag, and search for files across different platforms. With PocketPaw, you can efficiently organize your photos, documents, and other files in a centralized location, making it easier to access and share them. Whether you are a student looking to organize your study materials, a professional managing project files, or a casual user wanting to declutter your digital space, PocketPaw is the perfect solution for all your file management needs.
airflow-client-python
The Apache Airflow Python Client provides a range of REST API endpoints for managing Airflow metadata objects. It supports CRUD operations for resources, with endpoints accepting and returning JSON. Users can create, read, update, and delete resources. The API design follows conventions with consistent naming and field formats. Update mask is available for patch endpoints to specify fields for update. API versioning is not synchronized with Airflow releases, and changes go through a deprecation phase. The tool supports various authentication methods and error responses follow RFC 7807 format.

handit.ai
Handit.ai is an autonomous engineer tool designed to fix AI failures 24/7. It catches failures, writes fixes, tests them, and ships PRs automatically. It monitors AI applications, detects issues, generates fixes, tests them against real data, and ships them as pull requests—all automatically. Users can write JavaScript, TypeScript, Python, and more, and the tool automates what used to require manual debugging and firefighting.
explain-openclaw
Explain OpenClaw is a comprehensive documentation repository for the OpenClaw framework, a self-hosted AI assistant platform. It covers various aspects such as plain English explanations, technical architecture, deployment scenarios, privacy and safety measures, security audits, worst-case security scenarios, optimizations, and AI model comparisons. The repository serves as a living knowledge base with beginner-friendly explanations and detailed technical insights for contributors.
gpt-load
GPT-Load is a high-performance, enterprise-grade AI API transparent proxy service designed for enterprises and developers needing to integrate multiple AI services. Built with Go, it features intelligent key management, load balancing, and comprehensive monitoring capabilities for high-concurrency production environments. The tool serves as a transparent proxy service, preserving native API formats of various AI service providers like OpenAI, Google Gemini, and Anthropic Claude. It supports dynamic configuration, distributed leader-follower deployment, and a Vue 3-based web management interface. GPT-Load is production-ready with features like dual authentication, graceful shutdown, and error recovery.
agentsys
AgentSys is a modular runtime and orchestration system for AI agents, with 13 plugins, 42 agents, and 28 skills that compose into structured pipelines for software development. It handles task selection, branch management, code review, artifact cleanup, CI, PR comments, and deployment. The system runs on Claude Code, OpenCode, and Codex CLI, providing a functional software suite and runtime for AI agent orchestration.
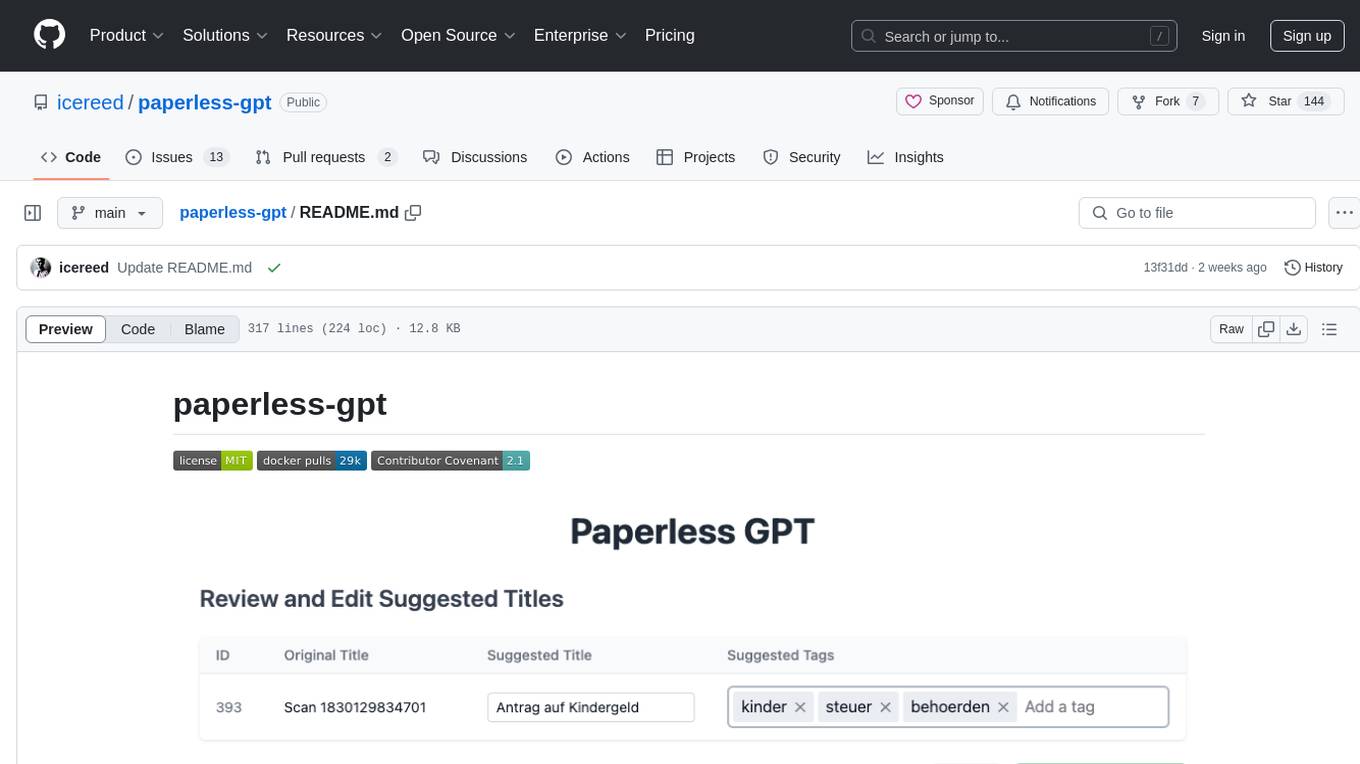
paperless-gpt
paperless-gpt is a tool designed to generate accurate and meaningful document titles and tags for paperless-ngx using Large Language Models (LLMs). It supports multiple LLM providers, including OpenAI and Ollama. With paperless-gpt, you can streamline your document management by automatically suggesting appropriate titles and tags based on the content of your scanned documents. The tool offers features like multiple LLM support, customizable prompts, easy integration with paperless-ngx, user-friendly interface for reviewing and applying suggestions, dockerized deployment, automatic document processing, and an experimental OCR feature.
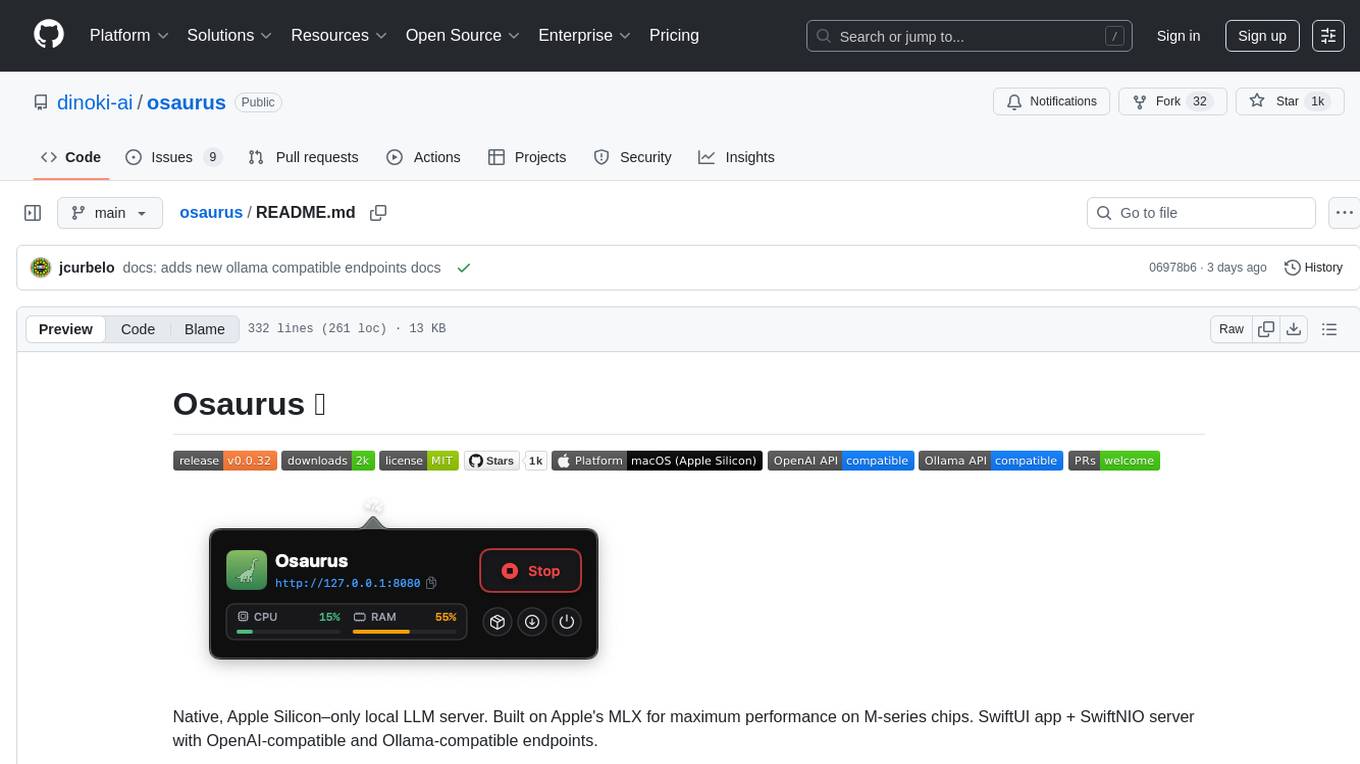
osaurus
Osaurus is a native, Apple Silicon-only local LLM server built on Apple's MLX for maximum performance on M‑series chips. It is a SwiftUI app + SwiftNIO server with OpenAI‑compatible and Ollama‑compatible endpoints. The tool supports native MLX text generation, model management, streaming and non‑streaming chat completions, OpenAI‑compatible function calling, real-time system resource monitoring, and path normalization for API compatibility. Osaurus is designed for macOS 15.5+ and Apple Silicon (M1 or newer) with Xcode 16.4+ required for building from source.

llamafarm
LlamaFarm is a comprehensive AI framework that empowers users to build powerful AI applications locally, with full control over costs and deployment options. It provides modular components for RAG systems, vector databases, model management, prompt engineering, and fine-tuning. Users can create differentiated AI products without needing extensive ML expertise, using simple CLI commands and YAML configs. The framework supports local-first development, production-ready components, strategy-based configuration, and deployment anywhere from laptops to the cloud.
mcp-devtools
MCP DevTools is a high-performance server written in Go that replaces multiple Node.js and Python-based servers. It provides access to essential developer tools through a unified, modular interface. The server is efficient, with minimal memory footprint and fast response times. It offers a comprehensive tool suite for agentic coding, including 20+ essential developer agent tools. The tool registry allows for easy addition of new tools. The server supports multiple transport modes, including STDIO, HTTP, and SSE. It includes a security framework for multi-layered protection and a plugin system for adding new tools.
For similar tasks
caddy-defender
The Caddy Defender plugin is a middleware for Caddy that allows you to block or manipulate requests based on the client's IP address. It provides features such as IP range filtering, predefined IP ranges for popular AI services, custom IP ranges configuration, and multiple responder backends for different actions like blocking, custom responses, dropping connections, returning garbage data, redirecting, and tarpitting to stall bots. The plugin can be easily installed using Docker or built with `xcaddy`. Configuration is done through the Caddyfile syntax with various options for responders, IP ranges, custom messages, and URLs.
For similar jobs

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

ai-on-gke
This repository contains assets related to AI/ML workloads on Google Kubernetes Engine (GKE). Run optimized AI/ML workloads with Google Kubernetes Engine (GKE) platform orchestration capabilities. A robust AI/ML platform considers the following layers: Infrastructure orchestration that support GPUs and TPUs for training and serving workloads at scale Flexible integration with distributed computing and data processing frameworks Support for multiple teams on the same infrastructure to maximize utilization of resources

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

nvidia_gpu_exporter
Nvidia GPU exporter for prometheus, using `nvidia-smi` binary to gather metrics.

tracecat
Tracecat is an open-source automation platform for security teams. It's designed to be simple but powerful, with a focus on AI features and a practitioner-obsessed UI/UX. Tracecat can be used to automate a variety of tasks, including phishing email investigation, evidence collection, and remediation plan generation.

openinference
OpenInference is a set of conventions and plugins that complement OpenTelemetry to enable tracing of AI applications. It provides a way to capture and analyze the performance and behavior of AI models, including their interactions with other components of the application. OpenInference is designed to be language-agnostic and can be used with any OpenTelemetry-compatible backend. It includes a set of instrumentations for popular machine learning SDKs and frameworks, making it easy to add tracing to your AI applications.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

kong
Kong, or Kong API Gateway, is a cloud-native, platform-agnostic, scalable API Gateway distinguished for its high performance and extensibility via plugins. It also provides advanced AI capabilities with multi-LLM support. By providing functionality for proxying, routing, load balancing, health checking, authentication (and more), Kong serves as the central layer for orchestrating microservices or conventional API traffic with ease. Kong runs natively on Kubernetes thanks to its official Kubernetes Ingress Controller.