AI tools for parsera
Related Tools:

Robo Rat
Robo Rat is an AI-powered tool designed for business document digitization. It offers a smart and affordable resume parsing API that supports over 50 languages, enabling quick conversion of resumes into actionable data. The tool aims to simplify the hiring process by providing speed and accuracy in parsing resumes. With advanced AI capabilities, Robo Rat delivers highly accurate and intelligent resume parsing solutions, making it a valuable asset for businesses of all sizes.
Airparser
Airparser is an AI-powered email and document parser tool that revolutionizes data extraction by utilizing the GPT parser engine. It allows users to automate the extraction of structured data from various sources such as emails, PDFs, documents, and handwritten texts. With features like automatic extraction, export to multiple platforms, and support for multiple languages, Airparser simplifies data extraction processes for individuals and businesses. The tool ensures data security and offers seamless integration with other applications through APIs and webhooks.
AI Resume Tailor
AI Resume Tailor is an AI-powered application designed to help job seekers create customized resumes tailored to each job description. It offers features such as resume parsing, AI-powered resume building, PDF formatting, privacy protection, and ATS-friendly templates. The platform ensures that users can easily create professional resumes that stand out to potential employers, increasing their chances of getting hired.
AI Resume Screening & CV Scanning
The AI Resume Screening & CV Scanning platform is a cutting-edge tool designed to streamline the recruitment process by automating the initial screening of resumes and matching candidates with job requirements. By leveraging artificial intelligence algorithms, the platform efficiently analyzes resumes, identifies key qualifications, and matches candidates with suitable job openings. This innovative solution helps recruiters save time, improve efficiency, and enhance the overall hiring process.
Parseur
Parseur is an AI data extraction software that uses artificial intelligence to extract structured data from various types of documents such as PDFs, emails, and scanned documents. It offers features like template-based data extraction, OCR software for character recognition, and dynamic OCR for extracting fields that move or change size. Parseur is trusted by businesses in finance, tech, logistics, healthcare, real estate, e-commerce, marketing, and human resources industries to automate data extraction processes, saving time and reducing manual errors.
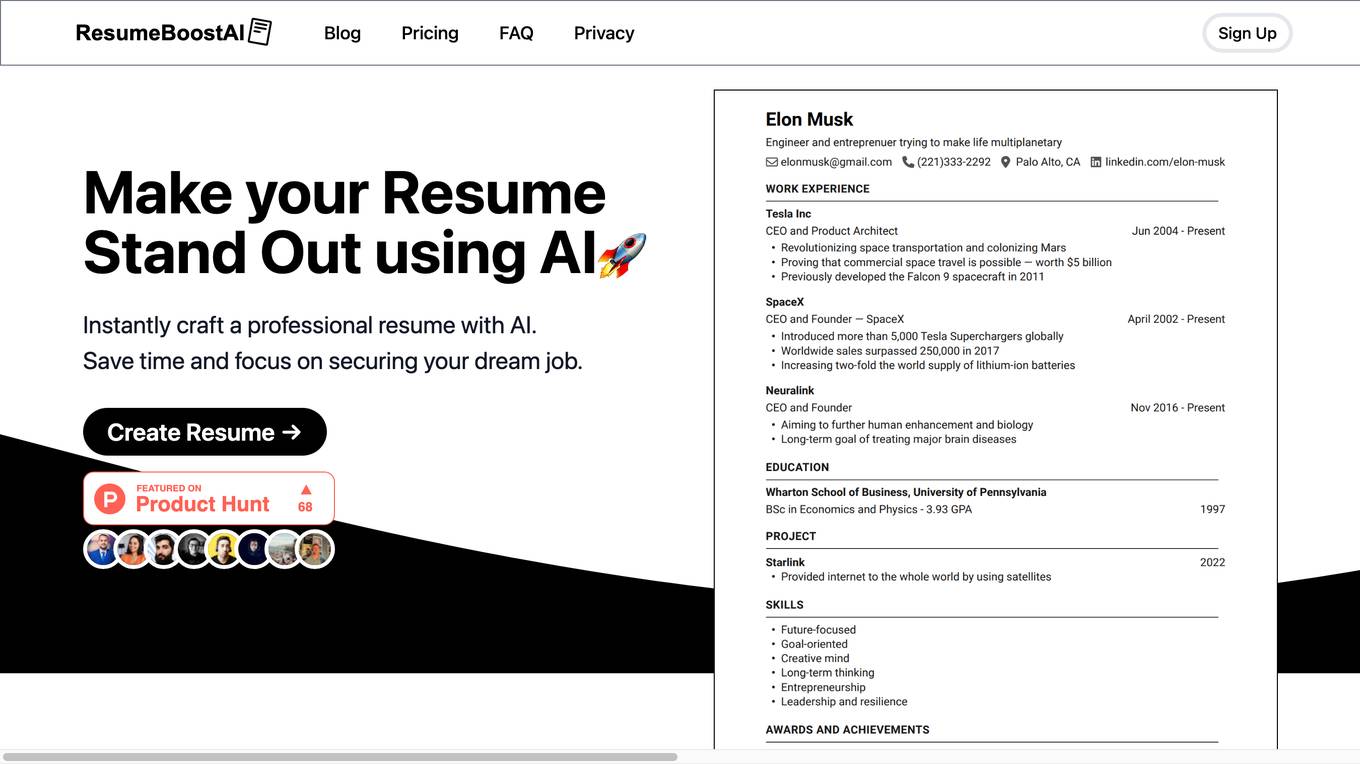
ResumeBoostAI
ResumeBoostAI is a free AI resume builder that helps job seekers create professional resumes and cover letters quickly and efficiently. With AI-powered features like resume summary generator, bullet point generator, cover letter generator, and ATS-friendly templates, users can save time and land their dream jobs. The platform offers privacy-first services, PDF format downloads, resume parsing, and compatibility with Applicant Tracking Systems (ATS). ResumeBoostAI is trusted by top professionals and loved by over 22,000 job seekers for its intuitive interface and time-saving capabilities.
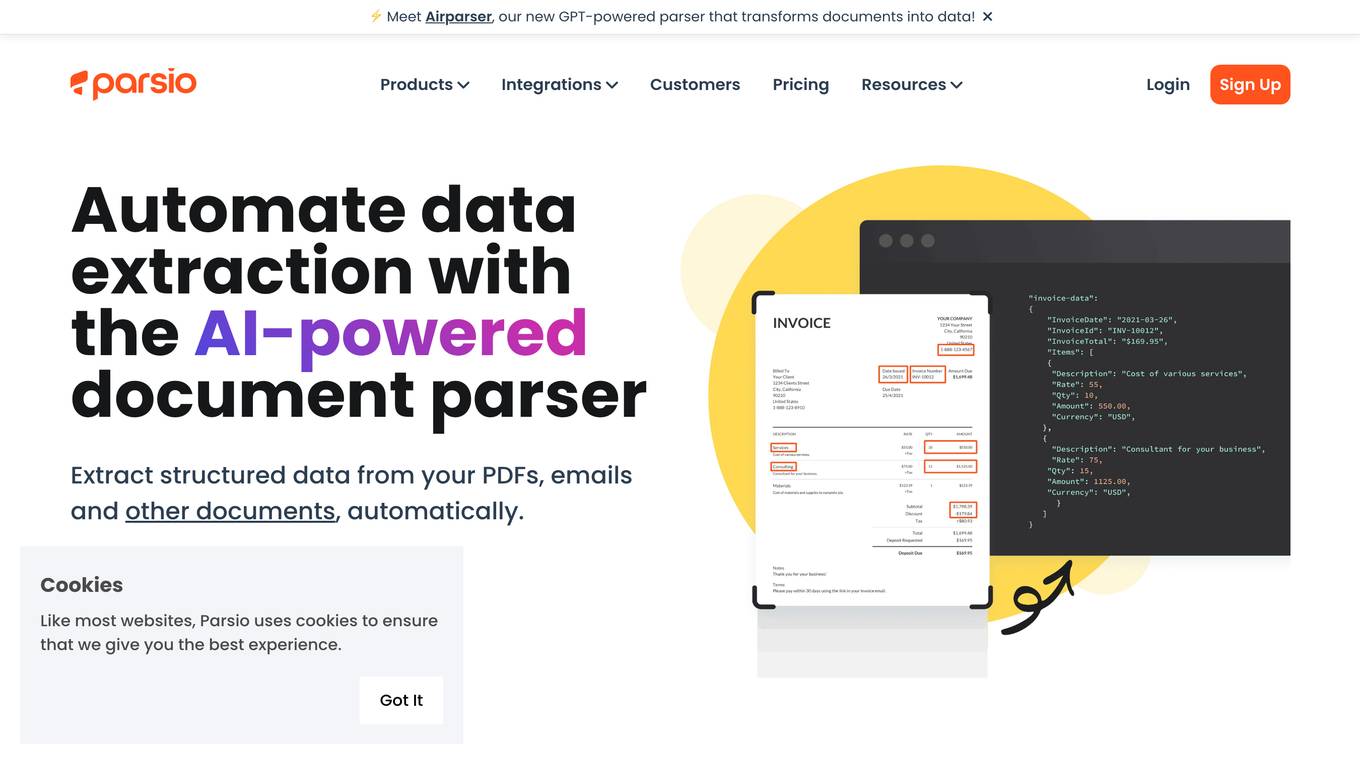
Parsio
Parsio is an AI-powered document parser that can extract structured data from PDFs, emails, and other documents. It uses natural language processing to understand the context of the document and identify the relevant data points. Parsio can be used to automate a variety of tasks, such as extracting data from invoices, receipts, and emails.
Skillate
Skillate is an AI Recruitment Platform that offers advanced decision-making engine to make hiring easy, fast, and transparent. It provides solutions such as AI Powered Matching Engine, Chatbot Screening, Resume Parser, Auto Interview Scheduler, and more to automate and improve the recruitment process. Skillate helps in intelligent hiring, enhancing candidate experience, utilizing people analytics, and promoting diversity and inclusion in recruitment practices.
Senseloaf Platform
Senseloaf Platform is an AI-powered platform designed to streamline the recruiting process by offering features such as Dynamic Matching, Conversational AI, Talent Discovery, and Resume Parser. It aims to provide a seamless and efficient experience for both recruiters and candidates, leveraging AI technology to personalize engagement, accelerate hiring productivity, and make insightful decisions. The platform offers end-to-end automation for recruiting teams, enabling them to consolidate, configure, automate, and control the recruitment process. With a focus on intelligent recruiting, Senseloaf Platform helps recruiters engage with top candidates, personalize candidate engagement, and boost hiring productivity with intelligence.
CVViZ
CVViZ is a modern AI Recruiting Software that automates candidate sourcing, matches candidates to jobs, provides hiring insights, and enhances the quality of hire. It offers features like resume screening, applicant tracking system, recruitment CRM, candidate sourcing, resume parser integration, and employee referral. With AI technology, CVViZ simplifies the hiring process in three steps: posting jobs to multiple job sites, screening candidates using AI algorithms, and engaging and hiring the best candidates. It helps in finding the right candidates for the right job through AI-powered resume screening and automates workflows with recruitment automation. CVViZ also offers recruitment analytics, GDPR compliance, and video interviewing for a seamless hiring experience.
Textkernel
Textkernel is an AI-powered recruitment and workforce solution provider offering a range of products and services to streamline talent acquisition, enhance candidate matches, and provide valuable insights for data-driven decision-making. With a focus on responsible AI and innovation, Textkernel empowers organizations to connect people and jobs more effectively through cutting-edge technologies and industry-leading expertise.
Flipped.ai
Flipped.ai is an AI-powered talent intelligence platform that helps businesses find, evaluate, and hire top talent faster and more efficiently. With its advanced features, Flipped.ai streamlines the recruitment process, making it easier for HR teams to connect with the perfect candidates. The platform offers a range of tools, including AI-powered job description and screening question generators, candidate recommendations, and seamless integrations with job boards and ATSs. Flipped.ai's mission is to make hiring more efficient, affordable, and effective for businesses of all sizes.

Parsers VC - Weekly Venture Report
A detailed report on funding rounds over the past week with information about startups and investors. The most interesting news from the Venture market.

Table to JSON
我們經常在看 REST API 參考文件,文件中呈現 Request/Response 參數通常都是用表格的形式,開發人員都要手動轉換成 JSON 結構,有點小麻煩,但透過這個 GPT 只要上傳截圖就可以自動產生 JSON 範例與 JSON Schema 結構。
parsera
Parsera is a lightweight Python library designed for scraping websites using LLMs. It offers simplicity and efficiency by minimizing token usage, enhancing speed, and reducing costs. Users can easily set up and run the tool to extract specific elements from web pages, generating JSON output with relevant data. Additionally, Parsera supports integration with various chat models, such as Azure, expanding its functionality and customization options for web scraping tasks.

awesome-LLM-resourses
A comprehensive repository of resources for Chinese large language models (LLMs), including data processing tools, fine-tuning frameworks, inference libraries, evaluation platforms, RAG engines, agent frameworks, books, courses, tutorials, and tips. The repository covers a wide range of tools and resources for working with LLMs, from data labeling and processing to model fine-tuning, inference, evaluation, and application development. It also includes resources for learning about LLMs through books, courses, and tutorials, as well as insights and strategies from building with LLMs.
awesome-LLM-resources
This repository is a curated list of resources for learning and working with Large Language Models (LLMs). It includes a collection of articles, tutorials, tools, datasets, and research papers related to LLMs such as GPT-3, BERT, and Transformer models. Whether you are a researcher, developer, or enthusiast interested in natural language processing and artificial intelligence, this repository provides valuable resources to help you understand, implement, and experiment with LLMs.

parseable
Parseable is a full stack observability platform designed to ingest, analyze, and extract insights from various types of telemetry data. It can be run locally, in the cloud, or as a managed service. The platform offers features like high availability, smart cache, alerts, role-based access control, OAuth2 support, and OpenTelemetry integration. Users can easily ingest data, query logs, and access the dashboard to monitor and analyze data. Parseable provides a seamless experience for observability and monitoring tasks.
sec-parser
The `sec-parser` project simplifies extracting meaningful information from SEC EDGAR HTML documents by organizing them into semantic elements and a tree structure. It helps in parsing SEC filings for financial and regulatory analysis, analytics and data science, AI and machine learning, causal AI, and large language models. The tool is especially beneficial for AI, ML, and LLM applications by streamlining data pre-processing and feature extraction.
any-parser
AnyParser provides an API to accurately extract unstructured data (e.g., PDFs, images, charts) into a structured format. Users can set up their API key, run synchronous and asynchronous extractions, and perform batch extraction. The tool is useful for extracting text, numbers, and symbols from various sources like PDFs and images. It offers flexibility in processing data and provides immediate results for synchronous extraction while allowing users to fetch results later for asynchronous and batch extraction. AnyParser is designed to simplify data extraction tasks and enhance data processing efficiency.
lego-ai-parser
Lego AI Parser is an open-source application that uses OpenAI to parse visible text of HTML elements. It is built on top of FastAPI, ready to set up as a server, and make calls from any language. It supports preset parsers for Google Local Results, Amazon Listings, Etsy Listings, Wayfair Listings, BestBuy Listings, Costco Listings, Macy's Listings, and Nordstrom Listings. Users can also design custom parsers by providing prompts, examples, and details about the OpenAI model under the classifier key.
partial-json-parser-js
Partial JSON Parser is a lightweight and customizable library for parsing partial JSON strings. It allows users to parse incomplete JSON data and stream it to the user. The library provides options to specify what types of partialness are allowed during parsing, such as strings, objects, arrays, special values, and more. It helps handle malformed JSON and returns the parsed JavaScript value. Partial JSON Parser is implemented purely in JavaScript and offers both commonjs and esm builds.

open-parse
Open Parse is a Python library for visually discerning document layouts and chunking them effectively. It is designed to fill the gap in open-source libraries for handling complex documents. Unlike text splitting, which converts a file to raw text and slices it up, Open Parse visually analyzes documents for superior LLM input. It also supports basic markdown for parsing headings, bold, and italics, and has high-precision table support, extracting tables into clean Markdown formats with accuracy that surpasses traditional tools. Open Parse is extensible, allowing users to easily implement their own post-processing steps. It is also intuitive, with great editor support and completion everywhere, making it easy to use and learn.

MegaParse
MegaParse is a powerful and versatile parser designed to handle various types of documents such as text, PDFs, Powerpoint presentations, and Word documents with no information loss. It is fast, efficient, and open source, supporting a wide range of file formats. MegaParse ensures compatibility with tables, table of contents, headers, footers, and images, making it a comprehensive solution for document parsing.

vision-parse
Vision Parse is a tool that leverages Vision Language Models to parse PDF documents into beautifully formatted markdown content. It offers smart content extraction, content formatting, multi-LLM support, PDF document support, and local model hosting using Ollama. Users can easily convert PDFs to markdown with high precision and preserve document hierarchy and styling. The tool supports multiple Vision LLM providers like OpenAI, LLama, and Gemini for accuracy and speed, making document processing efficient and effortless.
stakgraph
Stakgraph is a source code parser that utilizes treesitter, LSP, and neo4j to create software knowledge graphs for AI agents. It supports various languages such as Golang, React, Ruby on Rails, Typescript, Python, Swift, Kotlin, Rust, Java, Angular, and Svelte. Users can parse repositories, link endpoints, requests, and E2E tests, and ingest data to generate comprehensive graphs. The tool leverages the Language Server Protocol for node connections in the graph, enabling seamless integration and analysis of codebases.
partialjson
PartialJson is a Python library that allows users to parse partial and incomplete JSON data with ease. With just 3 lines of Python code, users can parse JSON data that may be missing key elements or contain errors. The library provides a simple solution for handling JSON data that may not be well-formed or complete, making it a valuable tool for data processing and manipulation tasks.
json_repair
This simple package can be used to fix an invalid json string. To know all cases in which this package will work, check out the unit test. Inspired by https://github.com/josdejong/jsonrepair Motivation Some LLMs are a bit iffy when it comes to returning well formed JSON data, sometimes they skip a parentheses and sometimes they add some words in it, because that's what an LLM does. Luckily, the mistakes LLMs make are simple enough to be fixed without destroying the content. I searched for a lightweight python package that was able to reliably fix this problem but couldn't find any. So I wrote one How to use from json_repair import repair_json good_json_string = repair_json(bad_json_string) # If the string was super broken this will return an empty string You can use this library to completely replace `json.loads()`: import json_repair decoded_object = json_repair.loads(json_string) or just import json_repair decoded_object = json_repair.repair_json(json_string, return_objects=True) Read json from a file or file descriptor JSON repair provides also a drop-in replacement for `json.load()`: import json_repair try: file_descriptor = open(fname, 'rb') except OSError: ... with file_descriptor: decoded_object = json_repair.load(file_descriptor) and another method to read from a file: import json_repair try: decoded_object = json_repair.from_file(json_file) except OSError: ... except IOError: ... Keep in mind that the library will not catch any IO-related exception and those will need to be managed by you Performance considerations If you find this library too slow because is using `json.loads()` you can skip that by passing `skip_json_loads=True` to `repair_json`. Like: from json_repair import repair_json good_json_string = repair_json(bad_json_string, skip_json_loads=True) I made a choice of not using any fast json library to avoid having any external dependency, so that anybody can use it regardless of their stack. Some rules of thumb to use: - Setting `return_objects=True` will always be faster because the parser returns an object already and it doesn't have serialize that object to JSON - `skip_json_loads` is faster only if you 100% know that the string is not a valid JSON - If you are having issues with escaping pass the string as **raw** string like: `r"string with escaping\"" Adding to requirements Please pin this library only on the major version! We use TDD and strict semantic versioning, there will be frequent updates and no breaking changes in minor and patch versions. To ensure that you only pin the major version of this library in your `requirements.txt`, specify the package name followed by the major version and a wildcard for minor and patch versions. For example: json_repair==0.* In this example, any version that starts with `0.` will be acceptable, allowing for updates on minor and patch versions. How it works This module will parse the JSON file following the BNF definition: <json> ::= <primitive> | <container> <primitive> ::= <number> | <string> | <boolean> ; Where: ; <number> is a valid real number expressed in one of a number of given formats ; <string> is a string of valid characters enclosed in quotes ; <boolean> is one of the literal strings 'true', 'false', or 'null' (unquoted) <container> ::= <object> | <array> <array> ::= '[' [ <json> *(', ' <json>) ] ']' ; A sequence of JSON values separated by commas <object> ::= '{' [ <member> *(', ' <member>) ] '}' ; A sequence of 'members' <member> ::= <string> ': ' <json> ; A pair consisting of a name, and a JSON value If something is wrong (a missing parantheses or quotes for example) it will use a few simple heuristics to fix the JSON string: - Add the missing parentheses if the parser believes that the array or object should be closed - Quote strings or add missing single quotes - Adjust whitespaces and remove line breaks I am sure some corner cases will be missing, if you have examples please open an issue or even better push a PR How to develop Just create a virtual environment with `requirements.txt`, the setup uses pre-commit to make sure all tests are run. Make sure that the Github Actions running after pushing a new commit don't fail as well. How to release You will need owner access to this repository - Edit `pyproject.toml` and update the version number appropriately using `semver` notation - **Commit and push all changes to the repository before continuing or the next steps will fail** - Run `python -m build` - Create a new release in Github, making sure to tag all the issues solved and contributors. Create the new tag, same as the one in the build configuration - Once the release is created, a new Github Actions workflow will start to publish on Pypi, make sure it didn't fail Bonus Content If you need some good Custom Instructions (System Message) to improve your chatbot responses try https://gist.github.com/mangiucugna/7ec015c4266df11be8aa510be0110fe4 Star History [Star History Chart](https://api.star-history.com/svg?repos=mangiucugna/json_repair&type=Date)

strictjson
Strict JSON is a framework designed to handle JSON outputs with complex structures, fixing issues that standard json.loads() cannot resolve. It provides functionalities for parsing LLM outputs into dictionaries, supporting various data types, type forcing, and error correction. The tool allows easy integration with OpenAI JSON Mode and offers community support through tutorials and discussions. Users can download the package via pip, set up API keys, and import functions for usage. The tool works by extracting JSON values using regex, matching output values to literals, and ensuring all JSON fields are output by LLM with optional type checking. It also supports LLM-based checks for type enforcement and error correction loops.
gguf-tools
GGUF tools is a library designed to manipulate GGUF files commonly used in machine learning projects. The main goal of this library is to provide accessible code that documents GGUF files for the llama.cpp project. The utility implements subcommands to show detailed info about GGUF files, compare two LLMs, inspect tensor weights, and extract models from Mixtral 7B MoE. The library is under active development with well-commented code and a simple API. However, it has limitations in handling quantization formats.
simba
Simba is an open source, portable Knowledge Management System (KMS) designed to seamlessly integrate with any Retrieval-Augmented Generation (RAG) system. It features a modern UI and modular architecture, allowing developers to focus on building advanced AI solutions without the complexities of knowledge management. Simba offers a user-friendly interface to visualize and modify document chunks, supports various vector stores and embedding models, and simplifies knowledge management for developers. It is community-driven, extensible, and aims to enhance AI functionality by providing a seamless integration with RAG-based systems.

unstructured
The `unstructured` library provides open-source components for ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more. The use cases of `unstructured` revolve around streamlining and optimizing the data processing workflow for LLMs. `unstructured` modular functions and connectors form a cohesive system that simplifies data ingestion and pre-processing, making it adaptable to different platforms and efficient in transforming unstructured data into structured outputs.

syncode
SynCode is a novel framework for the grammar-guided generation of Large Language Models (LLMs) that ensures syntactically valid output with respect to defined Context-Free Grammar (CFG) rules. It supports general-purpose programming languages like Python, Go, SQL, JSON, and more, allowing users to define custom grammars using EBNF syntax. The tool compares favorably to other constrained decoders and offers features like fast grammar-guided generation, compatibility with HuggingFace Language Models, and the ability to work with various decoding strategies.
yet-another-applied-llm-benchmark
Yet Another Applied LLM Benchmark is a collection of diverse tests designed to evaluate the capabilities of language models in performing real-world tasks. The benchmark includes tests such as converting code, decompiling bytecode, explaining minified JavaScript, identifying encoding formats, writing parsers, and generating SQL queries. It features a dataflow domain-specific language for easily adding new tests and has nearly 100 tests based on actual scenarios encountered when working with language models. The benchmark aims to assess whether models can effectively handle tasks that users genuinely care about.