
diffbot-kg-chatbot
Knowledge graph construction and RAG demo using Diffbot and Neo4j
Stars: 101
This project is an end-to-end pipeline for constructing knowledge graphs from news articles using Neo4j and Diffbot. It also utilizes OpenAI LLMs to generate questions based on the knowledge graph. The application offers news monitoring capabilities, data extraction from text, and organization/personal information enrichment. Users can interact with the chatbot interface to ask questions and receive answers based on the knowledge graph.
README:
This project is designed to show an end-to-end pipeline for constructing knowledge graphs from news articles, analyzing them through various visualizations, and finally, allowing LLM to generate questions based on the information provided from the knowledge graph.
The project uses Neo4j, a graph database, to store the knowledge graph and Diffbot as the data provider. Diffbot offers various data integrations on its platform, such as:
- Latest or relevant news about a specific topic or company
- Extracting graph information from text
- Enriching organization or personal information
Lastly, the project uses OpenAI LLMs to provide a chat interface, which can answer questions based on the provided information from the knowledge graph.
-
Set environment variables in
.env. You can find the template in.env.template -
Start the docker containers with
docker compose up
- Open you favorite browser on
localhost:3000
Any contributions are welcomed through GitHub issues or pull requests.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for diffbot-kg-chatbot
Similar Open Source Tools
diffbot-kg-chatbot
This project is an end-to-end pipeline for constructing knowledge graphs from news articles using Neo4j and Diffbot. It also utilizes OpenAI LLMs to generate questions based on the knowledge graph. The application offers news monitoring capabilities, data extraction from text, and organization/personal information enrichment. Users can interact with the chatbot interface to ask questions and receive answers based on the knowledge graph.
aihub
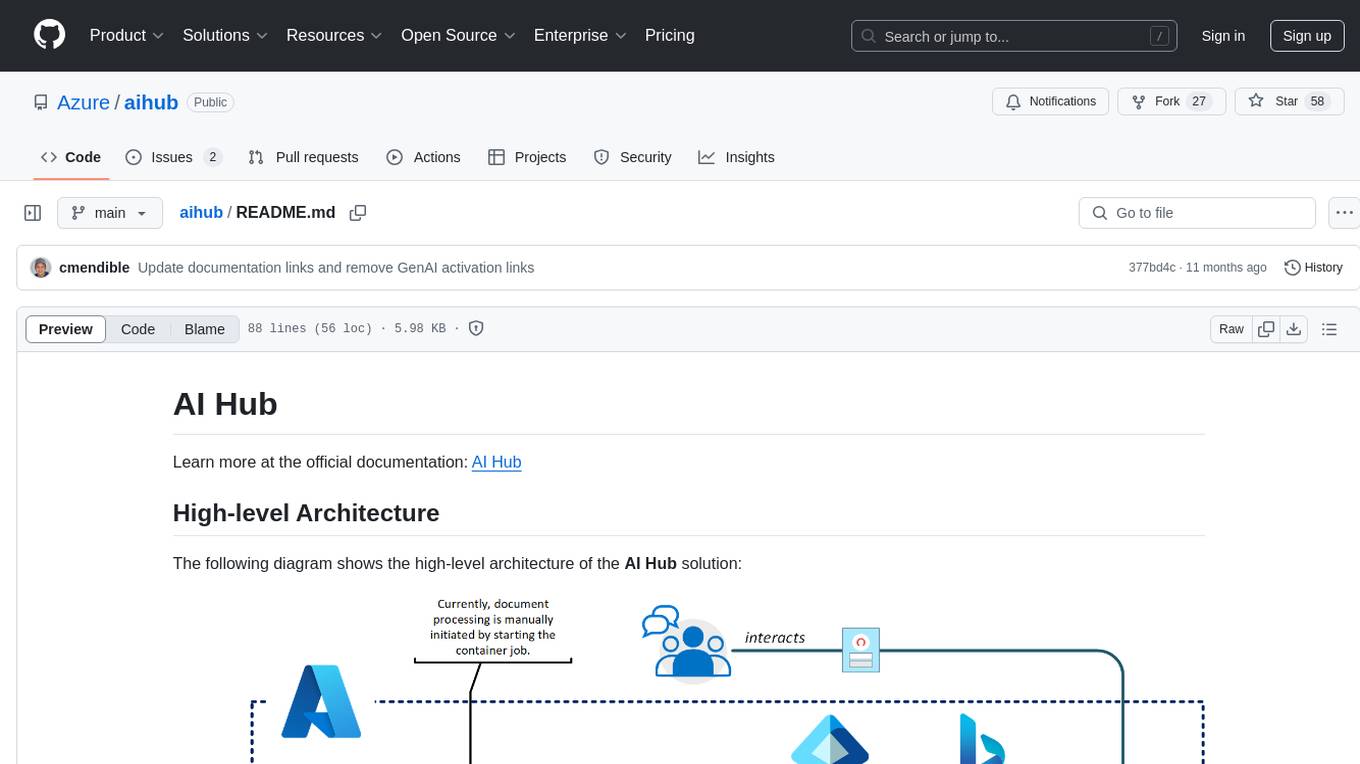
AI Hub is a comprehensive solution that leverages artificial intelligence and cloud computing to provide functionalities such as document search and retrieval, call center analytics, image analysis, brand reputation analysis, form analysis, document comparison, and content safety moderation. It integrates various Azure services like Cognitive Search, ChatGPT, Azure Vision Services, and Azure Document Intelligence to offer scalable, extensible, and secure AI-powered capabilities for different use cases and scenarios.
OpenAIWorkshop
Azure OpenAI Service provides REST API access to OpenAI's powerful language models including GPT-3, Codex and Embeddings. Users can easily adapt models for content generation, summarization, semantic search, and natural language to code translation. The workshop covers basics, prompt engineering, common NLP tasks, generative tasks, conversational dialog, and learning methods. It guides users to build applications with PowerApp, query SQL data, create data pipelines, and work with proprietary datasets. Target audience includes Power Users, Software Engineers, Data Scientists, and AI architects and Managers.
Document-Knowledge-Mining-Solution-Accelerator
The Document Knowledge Mining Solution Accelerator leverages Azure OpenAI and Azure AI Document Intelligence to ingest, extract, and classify content from various assets, enabling chat-based insight discovery, analysis, and prompt guidance. It uses OCR and multi-modal LLM to extract information from documents like text, handwritten text, charts, graphs, tables, and form fields. Users can customize the technical architecture and data processing workflow. Key features include ingesting and extracting real-world entities, chat-based insights discovery, text and document data analysis, prompt suggestion guidance, and multi-modal information processing.
chat-with-your-data-solution-accelerator
Chat with your data using OpenAI and AI Search. This solution accelerator uses an Azure OpenAI GPT model and an Azure AI Search index generated from your data, which is integrated into a web application to provide a natural language interface, including speech-to-text functionality, for search queries. Users can drag and drop files, point to storage, and take care of technical setup to transform documents. There is a web app that users can create in their own subscription with security and authentication.
generative-ai-amazon-bedrock-langchain-agent-example
This repository provides a sample solution for building generative AI agents using Amazon Bedrock, Amazon DynamoDB, Amazon Kendra, Amazon Lex, and LangChain. The solution creates a generative AI financial services agent capable of assisting users with account information, loan applications, and answering natural language questions. It serves as a launchpad for developers to create personalized conversational agents for applications like chatbots and virtual assistants.
oci-data-science-ai-samples
The Oracle Cloud Infrastructure Data Science and AI services Examples repository provides demos, tutorials, and code examples showcasing various features of the OCI Data Science service and AI services. It offers tools for data scientists to develop and deploy machine learning models efficiently, with features like Accelerated Data Science SDK, distributed training, batch processing, and machine learning pipelines. Whether you're a beginner or an experienced practitioner, OCI Data Science Services provide the resources needed to build, train, and deploy models easily.

SuperKnowa
SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.
Build-Modern-AI-Apps
This repository serves as a hub for Microsoft Official Build & Modernize AI Applications reference solutions and content. It provides access to projects demonstrating how to build Generative AI applications using Azure services like Azure OpenAI, Azure Container Apps, Azure Kubernetes, and Azure Cosmos DB. The solutions include Vector Search & AI Assistant, Real-Time Payment and Transaction Processing, and Medical Claims Processing. Additionally, there are workshops like the Intelligent App Workshop for Microsoft Copilot Stack, focusing on infusing intelligence into traditional software systems using foundation models and design thinking.
AI-Resume-Analyzer-and-LinkedIn-Scraper-using-Generative-AI
Developed an advanced AI application that utilizes LLM and OpenAI for comprehensive resume analysis. It excels at summarizing the resume, evaluating strengths, identifying weaknesses, and offering personalized improvement suggestions, while also recommending the perfect job titles. Additionally, it seamlessly employs Selenium to extract vital LinkedIn data, encompassing company names, job titles, locations, job URLs, and detailed job descriptions. This application simplifies the job-seeking journey by equipping users with comprehensive insights to elevate their career opportunities.
farmvibes-ai
FarmVibes.AI is a repository focused on developing multi-modal geospatial machine learning models for agriculture and sustainability. It enables users to fuse various geospatial and spatiotemporal datasets, such as satellite imagery, drone imagery, and weather data, to generate robust insights for agriculture-related problems. The repository provides fusion workflows, data preparation tools, model training notebooks, and an inference engine to facilitate the creation of geospatial models tailored for agriculture and farming. Users can interact with the tools via a local cluster, REST API, or a Python client, and the repository includes documentation and notebook examples to guide users in utilizing FarmVibes.AI for tasks like harvest date detection, climate impact estimation, micro climate prediction, and crop identification.
ai-powered-search
AI-Powered Search provides code examples for the book 'AI-Powered Search' by Trey Grainger, Doug Turnbull, and Max Irwin. The book teaches modern machine learning techniques for building search engines that continuously learn from users and content to deliver more intelligent and domain-aware search experiences. It covers semantic search, retrieval augmented generation, question answering, summarization, fine-tuning transformer-based models, personalized search, machine-learned ranking, click models, and more. The code examples are in Python, leveraging PySpark for data processing and Apache Solr as the default search engine. The repository is open source under the Apache License, Version 2.0.

text-to-sql-bedrock-workshop
This repository focuses on utilizing generative AI to bridge the gap between natural language questions and SQL queries, aiming to improve data consumption in enterprise data warehouses. It addresses challenges in SQL query generation, such as foreign key relationships and table joins, and highlights the importance of accuracy metrics like Execution Accuracy (EX) and Exact Set Match Accuracy (EM). The workshop content covers advanced prompt engineering, Retrieval Augmented Generation (RAG), fine-tuning models, and security measures against prompt and SQL injections.
TI-Mindmap-GPT
TI MINDMAP GPT is an AI-powered tool designed to assist cyber threat intelligence teams in quickly synthesizing and visualizing key information from various Threat Intelligence sources. The tool utilizes Large Language Models (LLMs) to transform lengthy content into concise, actionable summaries, going beyond mere text reduction to provide insightful encapsulations of crucial points and themes. Users can leverage their own LLM keys for personalized and efficient information processing, streamlining data analysis and enabling teams to focus on strategic decision-making.
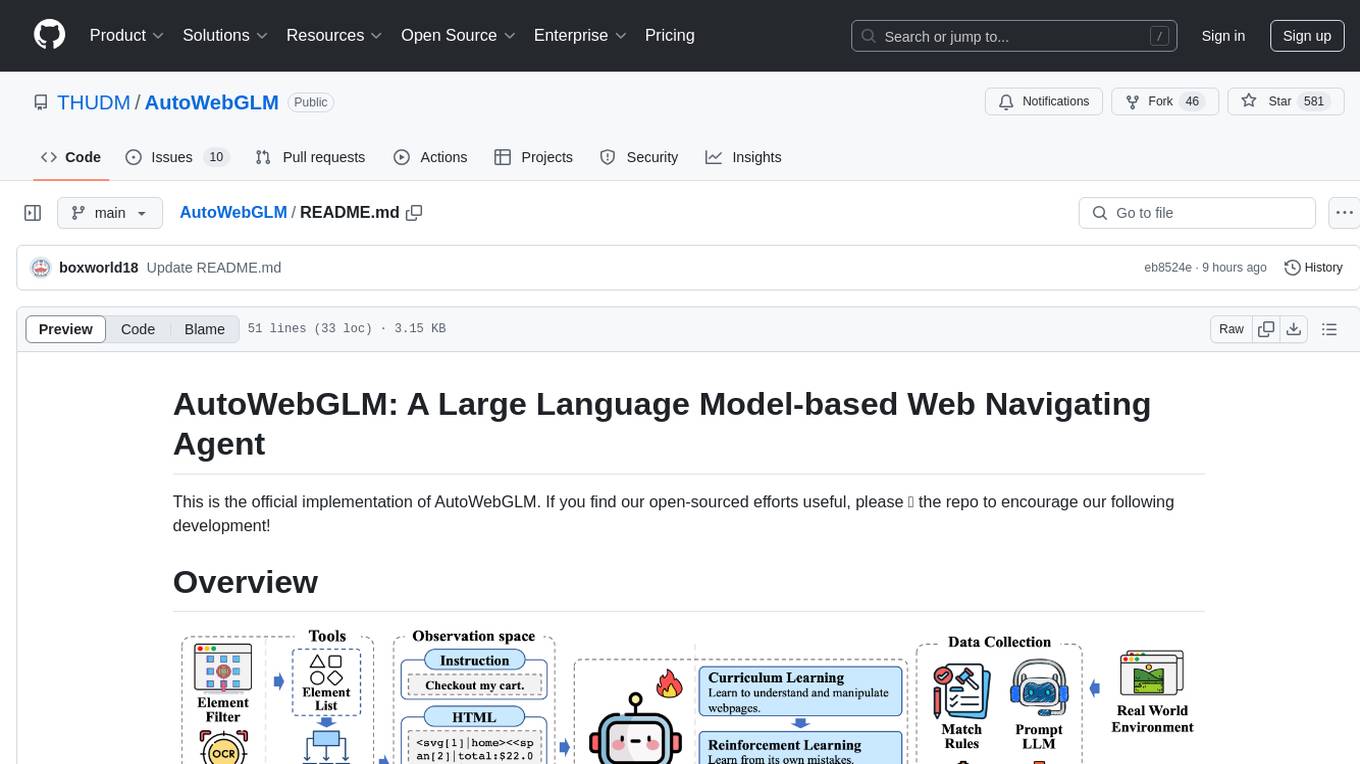
AutoWebGLM
AutoWebGLM is a project focused on developing a language model-driven automated web navigation agent. It extends the capabilities of the ChatGLM3-6B model to navigate the web more efficiently and address real-world browsing challenges. The project includes features such as an HTML simplification algorithm, hybrid human-AI training, reinforcement learning, rejection sampling, and a bilingual web navigation benchmark for testing AI web navigation agents.
AI-Resume-Analyzer-and-LinkedIn-Scraper-using-LLM
Developed an advanced AI application that utilizes LLM and OpenAI for comprehensive resume analysis. It excels at summarizing the resume, evaluating strengths, identifying weaknesses, and offering personalized improvement suggestions, while also recommending the perfect job titles. Additionally, it seamlessly employs Selenium to extract vital LinkedIn data, encompassing company names, job titles, locations, job URLs, and detailed job descriptions. This application simplifies the job-seeking journey by equipping users with comprehensive insights to elevate their career opportunities.
For similar tasks

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

sorrentum
Sorrentum is an open-source project that aims to combine open-source development, startups, and brilliant students to build machine learning, AI, and Web3 / DeFi protocols geared towards finance and economics. The project provides opportunities for internships, research assistantships, and development grants, as well as the chance to work on cutting-edge problems, learn about startups, write academic papers, and get internships and full-time positions at companies working on Sorrentum applications.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

zep-python
Zep is an open-source platform for building and deploying large language model (LLM) applications. It provides a suite of tools and services that make it easy to integrate LLMs into your applications, including chat history memory, embedding, vector search, and data enrichment. Zep is designed to be scalable, reliable, and easy to use, making it a great choice for developers who want to build LLM-powered applications quickly and easily.

telemetry-airflow
This repository codifies the Airflow cluster that is deployed at workflow.telemetry.mozilla.org (behind SSO) and commonly referred to as "WTMO" or simply "Airflow". Some links relevant to users and developers of WTMO: * The `dags` directory in this repository contains some custom DAG definitions * Many of the DAGs registered with WTMO don't live in this repository, but are instead generated from ETL task definitions in bigquery-etl * The Data SRE team maintains a WTMO Developer Guide (behind SSO)

mojo
Mojo is a new programming language that bridges the gap between research and production by combining Python syntax and ecosystem with systems programming and metaprogramming features. Mojo is still young, but it is designed to become a superset of Python over time.

pandas-ai
PandasAI is a Python library that makes it easy to ask questions to your data in natural language. It helps you to explore, clean, and analyze your data using generative AI.

databend
Databend is an open-source cloud data warehouse that serves as a cost-effective alternative to Snowflake. With its focus on fast query execution and data ingestion, it's designed for complex analysis of the world's largest datasets.
For similar jobs

sweep
Sweep is an AI junior developer that turns bugs and feature requests into code changes. It automatically handles developer experience improvements like adding type hints and improving test coverage.

teams-ai
The Teams AI Library is a software development kit (SDK) that helps developers create bots that can interact with Teams and Microsoft 365 applications. It is built on top of the Bot Framework SDK and simplifies the process of developing bots that interact with Teams' artificial intelligence capabilities. The SDK is available for JavaScript/TypeScript, .NET, and Python.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

classifai
Supercharge WordPress Content Workflows and Engagement with Artificial Intelligence. Tap into leading cloud-based services like OpenAI, Microsoft Azure AI, Google Gemini and IBM Watson to augment your WordPress-powered websites. Publish content faster while improving SEO performance and increasing audience engagement. ClassifAI integrates Artificial Intelligence and Machine Learning technologies to lighten your workload and eliminate tedious tasks, giving you more time to create original content that matters.

chatbot-ui
Chatbot UI is an open-source AI chat app that allows users to create and deploy their own AI chatbots. It is easy to use and can be customized to fit any need. Chatbot UI is perfect for businesses, developers, and anyone who wants to create a chatbot.

BricksLLM
BricksLLM is a cloud native AI gateway written in Go. Currently, it provides native support for OpenAI, Anthropic, Azure OpenAI and vLLM. BricksLLM aims to provide enterprise level infrastructure that can power any LLM production use cases. Here are some use cases for BricksLLM: * Set LLM usage limits for users on different pricing tiers * Track LLM usage on a per user and per organization basis * Block or redact requests containing PIIs * Improve LLM reliability with failovers, retries and caching * Distribute API keys with rate limits and cost limits for internal development/production use cases * Distribute API keys with rate limits and cost limits for students

uAgents
uAgents is a Python library developed by Fetch.ai that allows for the creation of autonomous AI agents. These agents can perform various tasks on a schedule or take action on various events. uAgents are easy to create and manage, and they are connected to a fast-growing network of other uAgents. They are also secure, with cryptographically secured messages and wallets.

griptape
Griptape is a modular Python framework for building AI-powered applications that securely connect to your enterprise data and APIs. It offers developers the ability to maintain control and flexibility at every step. Griptape's core components include Structures (Agents, Pipelines, and Workflows), Tasks, Tools, Memory (Conversation Memory, Task Memory, and Meta Memory), Drivers (Prompt and Embedding Drivers, Vector Store Drivers, Image Generation Drivers, Image Query Drivers, SQL Drivers, Web Scraper Drivers, and Conversation Memory Drivers), Engines (Query Engines, Extraction Engines, Summary Engines, Image Generation Engines, and Image Query Engines), and additional components (Rulesets, Loaders, Artifacts, Chunkers, and Tokenizers). Griptape enables developers to create AI-powered applications with ease and efficiency.