
agentic-qe
Agentic QE Fleet is an open-source AI-powered quality engineering platform designed for use with Claude Code, featuring specialized agents and skills to support testing activities for a product at any stage of the SDLC. Free to use, fork, build, and contribute. Based on the Agentic QE Framework created by Dragan Spiridonov.
Stars: 178
Agentic Quality Engineering Fleet (Agentic QE) is a comprehensive tool designed for quality engineering tasks. It offers a Domain-Driven Design architecture with 13 bounded contexts and 60 specialized QE agents. The tool includes features like TinyDancer intelligent model routing, ReasoningBank learning with Dream cycles, HNSW vector search, Coherence Verification, and integration with other tools like Claude Flow and Agentic Flow. It provides capabilities for test generation, coverage analysis, quality assessment, defect intelligence, requirements validation, code intelligence, security compliance, contract testing, visual accessibility, chaos resilience, learning optimization, and enterprise integration. The tool supports various protocols, LLM providers, and offers a vast library of QE skills for different testing scenarios.
README:


V3 (Main) | V2 Documentation | Release Notes | Changelog | Contributors | Issues | Discussions
V3 brings Domain-Driven Design architecture, 13 bounded contexts, 60 specialized QE agents, TinyDancer intelligent model routing, ReasoningBank learning with Dream cycles, HNSW vector search, mathematical Coherence verification, full MinCut/Consensus integration across all 13 domains, and deep integration with Claude Flow and Agentic Flow.
🏗️ DDD Architecture | 🧠 ReasoningBank + Dream Cycles | 🎯 TinyDancer Model Routing | 🔍 HNSW Vector Search | 👑 Queen Coordinator | 📊 O(log n) Coverage | 🔗 Claude Flow Integration | 🎯 13 Bounded Contexts | 📚 75 QE Skills | 🧬 Coherence Verification | ✅ Trust Tiers | 🛡️ Governance
# Install globally
npm install -g agentic-qe
# Initialize your project
cd your-project
aqe init --wizard
# Or with auto-configuration
aqe init --auto
# Start MCP server (agent-agnostic)
aqe-mcp
# Or without global install
npx agentic-qe mcpAQE is exposed as an MCP server and can be used from any client that supports MCP tool connections.
# 1) Start MCP server
npx agentic-qe mcp
# 2) Register/connect from your MCP-capable client
# (Claude Code, Codex-compatible client, or other MCP hosts)
# 3) Ask the client to invoke AQE agents/tools, e.g.:
# - qe-test-architect for test generation
# - qe-queen-coordinator for orchestration
# - qe-flaky-hunter for flaky analysisFor client-specific setup examples, see docs/integration/mcp-clients.md.
What V3 provides:
- ✅ 13 DDD Bounded Contexts: Organized by business domain (test-generation, coverage-analysis, security-compliance, enterprise-integration, etc.)
- ✅ 60 QE Agents: Including Queen Coordinator for hierarchical orchestration (53 main + 7 TDD subagents)
- ✅ TinyDancer Model Routing: 3-tier intelligent routing (Haiku/Sonnet/Opus) for cost optimization
- ✅ ReasoningBank Learning: HNSW-indexed pattern storage with experience replay
- ✅ O(log n) Coverage Analysis: Sublinear algorithms for efficient gap detection
- ✅ Claude Flow Integration: Deep integration with MCP tools and swarm orchestration
- ✅ Memory Coordination: Cross-agent communication via
aqe/v3/*namespaces - ✅ Coherence Verification (v3.3.0): Mathematical proof of belief consistency using WASM engines
- ✅ V2 Backward Compatibility: All V2 agents map to V3 equivalents
- ✅ 75 QE Skills: 46 Tier 3 verified + 29 additional QE skills (QCSD swarms, n8n testing, enterprise integration, qe-* domains)
# 1. Install
npm install -g agentic-qe
# 2. Initialize (auto-detects your project, enables all 13 domains)
cd your-project && aqe init --auto
# 3. Start AQE MCP server
npx agentic-qe mcp
# 4. Use your MCP-capable client to run test generation and quality assessment
# (see docs/integration/mcp-clients.md)What happens:
- Auto-configuration detects your tech stack (TypeScript/JS, testing framework, CI setup)
- All 13 DDD domains enabled automatically - no "No factory registered" errors
- Pattern learning kicks in - your project's test patterns are learned and reused
- AI agents generate tests, analyze coverage, and provide actionable recommendations
| Problem | AQE Solution |
|---|---|
| Writing comprehensive tests is tedious and time-consuming | AI agents generate tests automatically with pattern reuse across projects |
| Test suites become slow and expensive at scale | Sublinear O(log n) algorithms for coverage analysis and intelligent test selection |
| Flaky tests waste developer time debugging false failures | ML-powered detection with root cause analysis and fix recommendations |
| AI testing tools are expensive | TinyDancer 3-tier model routing reduces costs by matching task complexity to appropriate model |
| No memory between test runs—every analysis starts from scratch | ReasoningBank remembers patterns, strategies, and what works for your codebase |
| Agents waste tokens reading irrelevant code | Code Intelligence provides token reduction with semantic search and knowledge graphs |
| Quality engineering requires complex coordination | Queen Coordinator orchestrates 60 agents across 13 domains with consensus and MinCut topology |
| Tools don't understand your testing frameworks | Works with Jest, Cypress, Playwright, Vitest, Mocha, Jasmine, AVA |
V3 is built on 13 DDD Bounded Contexts, each with dedicated agents and clear responsibilities:
| Domain | Purpose | Key Agents |
|---|---|---|
| test-generation | AI-powered test creation | qe-test-architect, qe-tdd-specialist |
| test-execution | Parallel execution & retry | qe-parallel-executor, qe-retry-handler |
| coverage-analysis | O(log n) gap detection | qe-coverage-specialist, qe-gap-detector |
| quality-assessment | Quality gates & decisions | qe-quality-gate, qe-risk-assessor |
| defect-intelligence | Prediction & root cause | qe-defect-predictor, qe-root-cause-analyzer |
| requirements-validation | BDD & testability | qe-requirements-validator, qe-bdd-generator |
| code-intelligence | Knowledge graph & search | qe-code-intelligence, qe-kg-builder |
| security-compliance | SAST/DAST & audit | qe-security-scanner, qe-security-auditor |
| contract-testing | API contracts & GraphQL | qe-contract-validator, qe-graphql-tester |
| visual-accessibility | Visual regression & a11y | qe-visual-tester, qe-accessibility-auditor |
| chaos-resilience | Chaos engineering & load | qe-chaos-engineer, qe-load-tester |
| learning-optimization | Cross-domain learning | qe-learning-coordinator, qe-pattern-learner |
| enterprise-integration | SOAP, SAP, ESB, OData | qe-soap-tester, qe-sap-rfc-tester, qe-sod-analyzer |
AQE includes 75 QE skills (46 Tier 3 verified + 29 additional). Trust tiers apply to core QE skills:
| Tier | Badge | Count | Description |
|---|---|---|---|
| Tier 3 - Verified | 46 | Full evaluation test suite | |
| Tier 2 - Validated | 7 | Has executable validator | |
| Tier 1 - Structured | 5 | Has JSON output schema | |
| Tier 0 - Advisory | 5 | SKILL.md guidance only |
Tier 3 Skills are recommended for production use - they have:
- JSON Schema validation for output structure
- Executable validator scripts for correctness
- Evaluation test suites with multi-model testing
# Check skill trust tier
aqe eval status --skill security-testing
# Run skill evaluation
aqe eval run --skill security-testing --model claude-sonnet-4
# View all trust tiers
cat .claude/skills/TRUST-TIERS.md[Full documentation: docs/guides/skill-validation.md]
V3.1.0 adds full browser automation support via @claude-flow/browser integration:
| Component | Description |
|---|---|
| BrowserSwarmCoordinator | Parallel multi-viewport testing (4x faster) |
| BrowserSecurityScanner | URL validation, PII detection with auto-masking |
| 9 Workflow Templates | YAML-based reusable browser workflows |
| TrajectoryAdapter | SONA learning integration with HNSW indexing |
Available Workflow Templates:
-
login-flow,oauth-flow- Authentication testing -
form-validation,navigation-flow- User journey testing -
visual-regression,accessibility-audit- Quality validation -
performance-audit,api-integration,scraping-workflow- Advanced workflows
# Use browser automation from Claude Code
claude "Use security-visual-testing skill to test https://example.com across mobile, tablet, desktop viewports"
# Load and execute a workflow template
aqe workflow load login-flow --vars '{"username": "test", "password": "secret"}'The qe-queen-coordinator manages the entire fleet with intelligent task distribution:
qe-queen-coordinator
(Queen)
|
+--------------------+--------------------+
| | |
TEST DOMAIN QUALITY DOMAIN LEARNING DOMAIN
(test-generation) (quality-assessment) (learning-optimization)
| | |
- test-architect - quality-gate - learning-coordinator
- tdd-specialist - risk-assessor - pattern-learner
- integration-tester - deployment-advisor - transfer-specialist
Capabilities:
- Orchestrate 60 QE agents concurrently across 13 domains
- TinyDancer 3-tier model routing (Haiku/Sonnet/Opus) with confidence-based decisions
- Byzantine fault-tolerant consensus for critical quality decisions
- MinCut graph-based topology optimization for self-healing coordination
- Memory-backed cross-agent communication with HNSW vector search
- Work stealing with adaptive load balancing (3-5x throughput improvement)
claude "Use qe-queen-coordinator to orchestrate release validation for v2.1.0 with 90% coverage target"The Queen Coordinator is extended with Agent Teams (ADR-064) for hybrid fleet communication:
| Feature | Description |
|---|---|
| Mailbox Messaging | Direct agent-to-agent and domain-scoped broadcast messaging |
| Distributed Tracing | TraceContext propagation across messages for end-to-end task visibility |
| Dynamic Scaling | Workload-based auto-scaling with configurable policies and cooldowns |
| Competing Hypotheses | Multi-agent root cause investigation with evidence scoring, auto-triggered on critical failures |
| Federation | Cross-service routing with health monitoring and service discovery |
| Circuit Breakers | Per-domain fault isolation with automatic recovery |
| Task DAG | Topological ordering with cycle detection for multi-step workflows |
Fleet Tiers — Activate the level of coordination your project needs:
| Tier | Agents | Best For |
|---|---|---|
| Lite | 1-4 | Small projects, focused tasks |
| Standard | 5-10 | Team projects, multi-domain coordination |
| Full | 11-15 | Enterprise, cross-fleet federation |
claude "Use qe-queen-coordinator with agent teams to investigate flaky test failures across test-execution and defect-intelligence domains"V3 agents learn and improve through the ReasoningBank pattern storage:
| Component | Description |
|---|---|
| Experience Storage | Store successful patterns with confidence scores |
| HNSW Indexing | Fast O(log n) similarity search for pattern matching |
| Experience Replay | Learn from past successes and failures |
| Cross-Project Transfer | Share patterns between projects |
# Check what agents have learned
aqe memory search --query "test patterns" --namespace learning
# View learning metrics
aqe hooks metrics --v3-dashboardV3 introduces Dream cycles for neural consolidation and continuous improvement:
| Feature | Description |
|---|---|
| Dream Cycles | Background neural consolidation (30s max) with spreading activation |
| 9 RL Algorithms | Q-Learning, SARSA, DQN, PPO, A2C, DDPG, Actor-Critic, Policy Gradient, Decision Transformer |
| SONA Integration | Self-Optimizing Neural Architecture with <0.05ms adaptation |
| Novelty Scoring | Prioritize learning from novel patterns |
| Concept Graphs | Build semantic connections between quality patterns |
# Trigger dream cycle for pattern consolidation
aqe hooks intelligence --mode dream --consolidate
# View learning trajectory
aqe hooks intelligence trajectory-start --task "optimize coverage"TinyDancer (ADR-026) provides 3-tier intelligent model routing for cost optimization:
| Complexity Score | Model | Use Cases |
|---|---|---|
| 0-20 (Simple) | Haiku | Syntax fixes, type additions, simple refactors |
| 20-70 (Moderate) | Sonnet | Bug fixes, test generation, code review |
| 70+ (Critical) | Opus | Architecture, security, complex reasoning |
Routing Features:
- Confidence-based decisions: Routes based on task complexity analysis
- Automatic escalation: Escalates to higher-tier model if confidence is low
- Learning from outcomes: Improves routing based on success/failure patterns
- Token budget optimization: Minimizes cost while maintaining quality
# Check model routing for a task
aqe hooks model-route --task "fix type errors in user-service.ts"
# View routing statistics
aqe hooks model-statsV3.3.5 unifies cross-phase feedback loops with UnifiedMemoryManager:
-
Single SQLite Backend: All QCSD signals stored in
.agentic-qe/memory.db -
Namespace-Based Storage:
qcsd/strategic,qcsd/tactical,qcsd/operational,qcsd/quality-criteria - Automatic TTL: 30-90 day expiration per signal type
- No File-Based Storage: Eliminated JSON file storage for cross-phase memory
- Full Hook Integration: Pre/post hooks for cross-phase signal injection
V3.4.0 adds support for industry-standard agent communication protocols:
| Protocol | Standard | Purpose |
|---|---|---|
| AG-UI | Anthropic | Agent-to-User streaming interface with lifecycle events |
| A2A | Agent-to-Agent interoperability with task/artifact exchange | |
| A2UI | Hybrid | Unified UI components combining streaming + events |
Programmatic usage:
import { AGUIAdapter, A2AAdapter } from 'agentic-qe';
// AG-UI: Stream test generation progress to UI
const agui = new AGUIAdapter();
await agui.streamTask({
type: 'test-generation',
onProgress: (event) => updateProgressBar(event.progress),
onArtifact: (test) => displayGeneratedTest(test),
});
// A2A: Inter-agent task delegation
const a2a = new A2AAdapter();
await a2a.sendTask({
from: 'qe-test-architect',
to: 'qe-security-scanner',
task: { type: 'review-tests', files: generatedTests },
});Benefits:
- Streaming feedback - Real-time progress instead of waiting for completion
- Agent interoperability - Standard protocols for multi-agent coordination
- Framework integration - Works with React, Vue, or any UI framework
V3.3.3 achieves full MinCut/Consensus integration across all 13 domains:
| Feature | Description |
|---|---|
| Byzantine Consensus | Fault-tolerant voting for critical quality decisions |
| MinCut Topology | Graph-based self-healing agent coordination |
| Multi-Model Voting | Aggregate decisions from multiple model tiers |
| Claim Verification | Cryptographic verification of agent work claims |
| 13/13 Domain Integration | All domains use verifyFinding() for consensus |
| Topology-Aware Routing | Routes tasks avoiding weak network vertices |
| Self-Healing Triggers |
shouldPauseOperations() for automatic recovery |
# View consensus status
aqe coordination consensus --status
# Check topology health
aqe coordination topology --optimizeV3.3.0 introduces mathematical coherence verification using Prime Radiant WASM engines:
| Feature | Description |
|---|---|
| Contradiction Detection | Sheaf cohomology identifies conflicting requirements before test generation |
| Collapse Prediction | Spectral analysis predicts swarm failures before they happen |
| Causal Verification | Distinguishes true causation from spurious correlations |
| Auto-Tuning Thresholds | EMA-based calibration adapts to your codebase |
Compute Lanes - Automatic routing based on coherence energy:
| Coherence Energy | Action | Latency |
|---|---|---|
| < 0.1 (Reflex) | Execute immediately | <1ms |
| 0.1-0.4 (Retrieval) | Fetch more context | ~10ms |
| 0.4-0.7 (Heavy) | Deep analysis | ~100ms |
| > 0.7 (Human) | Escalate to Queen | Async |
Benefits:
- Prevents contradictory test generation
- Detects swarm drift 10x faster
- Mathematical proof instead of statistical confidence
- "Coherence Verified" CI/CD badges
# Check coherence of beliefs
aqe coherence check --beliefs "requirement1,requirement2"
# Audit memory for contradictions
aqe coherence audit --namespace learningEfficient coverage gap detection using Johnson-Lindenstrauss algorithms:
- Sublinear complexity: Analyze large codebases in logarithmic time
- Risk-weighted gaps: Prioritize coverage by business impact
- Intelligent test selection: Minimal tests for maximum coverage
- Trend tracking: Monitor coverage changes over time
claude "Use qe-coverage-specialist to analyze gaps in src/ with risk scoring"V3 deeply integrates with Claude Flow for:
- MCP Server: All V3 tools available via Model Context Protocol
- Swarm Orchestration: Multi-agent coordination with hierarchical topology
-
Memory Sharing: Cross-agent state via
aqe/v3/*namespaces - Hooks System: Pre/post task learning and optimization
- Session Management: Persistent state across conversations
# Initialize swarm with Claude Flow
npx @claude-flow/cli@latest swarm init --topology hierarchical-mesh
# Spawn V3 agents
npx @claude-flow/cli@latest agent spawn -t qe-test-architect --name test-gen| Category | Count | Highlights |
|---|---|---|
| Main QE Agents | 53 | Test generation, coverage, security, performance, accessibility, enterprise integration, pentest validation |
| TDD Subagents | 7 | RED/GREEN/REFACTOR with code review |
V2 Backward Compatibility: All V2 agents map to V3 equivalents automatically.
📋 View All Main QE Agents (53)
| Agent | Domain | Purpose |
|---|---|---|
| qe-queen-coordinator | coordination | Hierarchical fleet orchestration |
| qe-test-architect | test-generation | AI-powered test creation |
| qe-tdd-specialist | test-generation | TDD workflow coordination |
| qe-parallel-executor | test-execution | Multi-worker test execution |
| qe-retry-handler | test-execution | Intelligent retry with backoff |
| qe-coverage-specialist | coverage-analysis | O(log n) coverage analysis |
| qe-gap-detector | coverage-analysis | Risk-weighted gap detection |
| qe-quality-gate | quality-assessment | Quality threshold validation |
| qe-risk-assessor | quality-assessment | Multi-factor risk scoring |
| qe-deployment-advisor | quality-assessment | Go/no-go deployment decisions |
| qe-defect-predictor | defect-intelligence | ML-powered defect prediction |
| qe-root-cause-analyzer | defect-intelligence | Systematic root cause analysis |
| qe-flaky-hunter | defect-intelligence | Flaky test detection & fix |
| qe-requirements-validator | requirements-validation | Testability analysis |
| qe-bdd-generator | requirements-validation | Gherkin scenario generation |
| qe-code-intelligence | code-intelligence | Semantic code search |
| qe-kg-builder | code-intelligence | Knowledge graph construction |
| qe-dependency-mapper | code-intelligence | Dependency analysis |
| qe-security-scanner | security-compliance | SAST/DAST scanning |
| qe-security-auditor | security-compliance | Security audit & compliance |
| qe-contract-validator | contract-testing | API contract validation |
| qe-graphql-tester | contract-testing | GraphQL testing |
| qe-visual-tester | visual-accessibility | Visual regression testing |
| qe-accessibility-auditor | visual-accessibility | WCAG compliance testing |
| qe-responsive-tester | visual-accessibility | Cross-viewport testing |
| qe-chaos-engineer | chaos-resilience | Controlled fault injection |
| qe-load-tester | chaos-resilience | Load & performance testing |
| qe-performance-tester | chaos-resilience | Performance validation |
| qe-learning-coordinator | learning-optimization | Fleet-wide learning |
| qe-pattern-learner | learning-optimization | Pattern discovery |
| qe-transfer-specialist | learning-optimization | Cross-project transfer |
| qe-metrics-optimizer | learning-optimization | Hyperparameter tuning |
| qe-integration-tester | test-execution | Component integration |
| qe-mutation-tester | test-generation | Test effectiveness validation |
| qe-property-tester | test-generation | Property-based testing |
| qe-regression-analyzer | defect-intelligence | Regression risk analysis |
| qe-impact-analyzer | code-intelligence | Change impact assessment |
| qe-code-complexity | code-intelligence | Complexity metrics |
| qe-qx-partner | quality-assessment | QA + UX collaboration |
| qe-fleet-commander | coordination | Large-scale orchestration |
| qe-integration-architect | code-intelligence | V3 integration design |
| qe-product-factors-assessor | quality-assessment | SFDIPOT product factors analysis |
| qe-test-idea-rewriter | test-generation | Transform passive tests to active actions |
| qe-quality-criteria-recommender | quality-assessment | HTSM v6.3 Quality Criteria analysis |
| qe-devils-advocate | quality-assessment | Adversarial review of agent outputs |
🔧 TDD Subagents (7)
| Subagent | Phase | Purpose |
|---|---|---|
| qe-tdd-red | RED | Write failing tests |
| qe-tdd-green | GREEN | Implement minimal code |
| qe-tdd-refactor | REFACTOR | Improve code quality |
| qe-code-reviewer | REVIEW | Code quality validation |
| qe-integration-reviewer | REVIEW | Integration review |
| qe-performance-reviewer | REVIEW | Performance review |
| qe-security-reviewer | REVIEW | Security review |
claude "Use qe-queen-coordinator to run full quality assessment:
1. Generate tests for src/services/*.ts
2. Execute tests with parallel workers
3. Analyze coverage gaps with risk scoring
4. Run security scan
5. Validate quality gate at 90% threshold
6. Provide deployment recommendation"What happens:
- Queen spawns domain coordinators for each task
- Agents execute in parallel across 5 domains
- Results aggregate through memory coordination
- Queen synthesizes final recommendation
claude "Use qe-test-architect to create tests for PaymentService with:
- Property-based testing for validation
- 95% coverage target
- Apply learned patterns from similar services"Output includes:
Generated 48 tests across 4 files
- unit/PaymentService.test.ts (32 unit tests)
- property/PaymentValidation.property.test.ts (8 property tests)
- integration/PaymentFlow.integration.test.ts (8 integration tests)
Coverage: 96.2%
Pattern reuse: 78% from learned patterns
Learning stored: "payment-validation-patterns" (confidence: 0.94)
claude "Use qe-tdd-specialist to implement UserAuthentication with full RED-GREEN-REFACTOR cycle"Workflow:
- qe-tdd-red: Writes failing tests defining behavior
- qe-tdd-green: Implements minimal code to pass
- qe-tdd-refactor: Improves code quality
- qe-code-reviewer: Validates standards
- qe-security-reviewer: Checks security concerns
claude "Coordinate security audit across the monorepo:
- qe-security-scanner for SAST/DAST
- qe-dependency-mapper for vulnerability scanning
- qe-contract-validator for API security
- qe-chaos-engineer for resilience testing"V3 agents automatically apply relevant skills from the comprehensive QE skill library.
View All 75 QE Skills
Core Testing & Methodologies (12)
- agentic-quality-engineering - Core PACT principles for AI-powered QE
- holistic-testing-pact - Evolved testing model with PACT integration
- context-driven-testing - Practices chosen based on project context
- tdd-london-chicago - Test-driven development with both school approaches
- xp-practices - Extreme programming practices for quality
- risk-based-testing - Focus testing effort on highest-risk areas
- test-automation-strategy - Strategic approach to automation
- refactoring-patterns - Safe code improvement patterns
- shift-left-testing - Early testing in development lifecycle
- shift-right-testing - Production testing and observability
- regression-testing - Strategic regression management
- verification-quality - Quality verification practices
Specialized Testing (13)
- accessibility-testing - WCAG 2.2 compliance and inclusive design
- mobile-testing - iOS and Android platform testing
- database-testing - Schema validation and data integrity
- contract-testing - Consumer-driven contract testing
- chaos-engineering-resilience - Fault injection and resilience testing
- visual-testing-advanced - Visual regression and UI testing
- security-visual-testing - Security-first visual testing with PII detection
- compliance-testing - Regulatory compliance (GDPR, HIPAA, SOC2)
- compatibility-testing - Cross-browser and platform testing
- localization-testing - i18n and l10n testing
- mutation-testing - Test suite effectiveness evaluation
- performance-testing - Load, stress, and scalability testing
- security-testing - OWASP and security vulnerability testing
V3 Domain Skills (14)
- qe-test-generation - AI-powered test synthesis
- qe-test-execution - Parallel execution and retry logic
- qe-coverage-analysis - O(log n) sublinear coverage
- qe-quality-assessment - Quality gates and deployment readiness
- qe-defect-intelligence - ML defect prediction and root cause
- qe-requirements-validation - BDD scenarios and acceptance criteria
- qe-code-intelligence - Knowledge graphs and token reduction
- qe-security-compliance - OWASP and CVE detection
- qe-contract-testing - Pact and schema validation
- qe-visual-accessibility - Visual regression and WCAG
- qe-chaos-resilience - Fault injection and resilience
- qe-learning-optimization - Transfer learning and self-improvement
- qe-iterative-loop - QE iteration patterns
- aqe-v2-v3-migration - Migration guide from v2 to v3
Strategic & Communication (8)
- six-thinking-hats - Edward de Bono's methodology for QE
- brutal-honesty-review - Unvarnished technical criticism
- sherlock-review - Evidence-based investigative code review
- cicd-pipeline-qe-orchestrator - CI/CD quality orchestration
- bug-reporting-excellence - High-quality bug reports
- consultancy-practices - QE consultancy workflows
- quality-metrics - Effective quality measurement
- pair-programming - AI-assisted pair programming
Testing Techniques & Management (9)
- exploratory-testing-advanced - SBTM and RST heuristics
- test-design-techniques - Test design methodologies
- test-data-management - Test data strategies
- test-environment-management - Environment configuration
- test-reporting-analytics - Quality dashboards and KPIs
- testability-scoring - Score code testability
- technical-writing - Documentation practices
- code-review-quality - Context-driven code reviews
- api-testing-patterns - REST and GraphQL testing
n8n Workflow Testing (5) (contributed by @fndlalit)
- n8n-workflow-testing-fundamentals - Execution lifecycle and data flow
- n8n-expression-testing - Expression validation and testing
- n8n-security-testing - Workflow security scanning
- n8n-trigger-testing-strategies - Webhook and event testing
- n8n-integration-testing-patterns - API contract testing for n8n
QCSD Swarms (4) - Quality Conscious Software Delivery lifecycle
- qcsd-ideation-swarm - Phase 1: HTSM v6.3, Risk Storming, Testability analysis
- qcsd-refinement-swarm - Phase 2: SFDIPOT analysis, BDD scenario generation
- qcsd-development-swarm - Phase 3: TDD, coverage, code quality gates (SHIP/CONDITIONAL/HOLD)
- qcsd-cicd-swarm - Phase 4: Pipeline quality gates (RELEASE/REMEDIATE/BLOCK)
Accessibility (2)
- a11y-ally - Comprehensive WCAG auditing with video captions and EU compliance
- accessibility-testing - WCAG 2.2 compliance and screen reader validation
V3 provides automatic backward compatibility with V2:
# Check migration status
aqe migrate status
# Run migration with backup
aqe migrate run --backup
# Validate migration
aqe migrate validateWhat gets migrated:
- ✅ Memory data (SQLite → AgentDB with HNSW indexing)
- ✅ Configuration files
- ✅ Learned patterns (→ ReasoningBank)
- ✅ Agent mappings (V2 names → V3 equivalents)
| V2 Agent | V3 Agent |
|---|---|
| qe-test-generator | qe-test-architect |
| qe-coverage-analyzer | qe-coverage-specialist |
| qe-quality-gate | qe-quality-gate |
| qe-security-scanner | qe-security-scanner |
| qe-coordinator | qe-queen-coordinator |
AQE V3 supports multiple LLM providers for maximum flexibility:
| Provider | Type | Cost | Best For |
|---|---|---|---|
| Ollama | Local | FREE | Privacy, offline |
| OpenRouter | Cloud | Varies | 300+ models |
| Groq | Cloud | FREE | High-speed |
| Claude API | Cloud | Paid | Highest quality |
| Google AI | Cloud | FREE | Gemini models |
# Configure provider
export GROQ_API_KEY="gsk_..."
aqe init --auto- V3 Migration Guide - Complete migration instructions
- V3 CLI Reference - All V3 commands
- DDD Architecture - Domain-driven design overview
- V2 README - Complete V2 documentation
- Quick Start Guide - V2 quick start
- User Guide - V2 workflows and examples
- Learning System Guide - ReasoningBank learning
- Pattern Management Guide - Cross-project patterns
- MCP Integration - Claude Code integration
- Test Generation - AI-powered test creation
- Coverage Analysis - O(log n) gap detection
- Quality Gates - Intelligent validation
agentic-qe/
├── v3/ # V3 DDD Implementation (Main Version)
│ ├── src/
│ │ ├── kernel/ # Shared kernel
│ │ ├── domains/ # 13 bounded contexts
│ │ │ ├── test-generation/
│ │ │ ├── coverage-analysis/
│ │ │ ├── quality-assessment/
│ │ │ └── ...
│ │ ├── routing/ # Agent routing & registry
│ │ ├── mcp/ # MCP server
│ │ └── cli/ # V3 CLI
│ ├── tests/ # 5,600+ tests
│ └── assets/agents/ # 60 QE agent definitions (53 main + 7 subagents)
├── v2/ # V2 Implementation (Legacy)
│ ├── src/ # V2 source code
│ ├── tests/ # V2 tests
│ └── docs/ # V2 documentation
├── .claude/
│ ├── agents/v3/ # V3 agent definitions (source)
│ └── skills/ # 15 QE-specific skills
├── docs/ # Shared documentation
│ ├── plans/ # Migration plans
│ ├── policies/ # Project policies
│ └── v3/ # V3 specific docs
├── package.json # Points to v3 (main version)
└── README.md # This file
# Clone repository
git clone https://github.com/proffesor-for-testing/agentic-qe.git
cd agentic-qe
# Install V3 dependencies
cd v3
npm install
# Build
npm run build
# Run tests
npm test -- --run| Script | Description |
|---|---|
npm run build |
Compile TypeScript |
npm test -- --run |
Run all tests |
npm run cli |
Run CLI in dev mode |
npm run mcp |
Start MCP server |
We welcome contributions! Please see CONTRIBUTING.md for details.
- Documentation: docs/
- Issues: GitHub Issues
- Discussions: GitHub Discussions
- Email: [email protected]
This project is licensed under the MIT License - see the LICENSE file for details.
Thanks to all the amazing people who have contributed to Agentic QE Fleet!
 @proffesor-for-testing Project Lead |
 @fndlalit QX Partner, Testability |
 @shaal Core Development |
 @mondweep Architecture |
|---|
View all contributors | Become a contributor
If you find Agentic QE Fleet valuable, consider supporting its development:
| Monthly | Annual (Save $10) | |
|---|---|---|
| Price | $5/month | $50/year |
| Benefits | Sponsor recognition, Priority support | All monthly + Featured in README, Roadmap input |
| Subscribe | Monthly | Annual |
V3 is built on the shoulders of giants:
- Claude Flow by @ruvnet - Multi-agent orchestration, MCP integration, swarm coordination
- Agentic Flow by @ruvnet - Agent patterns, learning systems, neural coordination
- Built with TypeScript, Node.js, and better-sqlite3
- HNSW indexing via hnswlib-node
- Inspired by Domain-Driven Design and swarm intelligence
- Integrates with Jest, Cypress, Playwright, k6, SonarQube, and more
- Compatible with Claude Code via Model Context Protocol (MCP)
Made with ❤️ by the Agentic QE Team
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for agentic-qe
Similar Open Source Tools
agentic-qe
Agentic Quality Engineering Fleet (Agentic QE) is a comprehensive tool designed for quality engineering tasks. It offers a Domain-Driven Design architecture with 13 bounded contexts and 60 specialized QE agents. The tool includes features like TinyDancer intelligent model routing, ReasoningBank learning with Dream cycles, HNSW vector search, Coherence Verification, and integration with other tools like Claude Flow and Agentic Flow. It provides capabilities for test generation, coverage analysis, quality assessment, defect intelligence, requirements validation, code intelligence, security compliance, contract testing, visual accessibility, chaos resilience, learning optimization, and enterprise integration. The tool supports various protocols, LLM providers, and offers a vast library of QE skills for different testing scenarios.
paiml-mcp-agent-toolkit
PAIML MCP Agent Toolkit (PMAT) is a zero-configuration AI context generation system with extreme quality enforcement and Toyota Way standards. It allows users to analyze any codebase instantly through CLI, MCP, or HTTP interfaces. The toolkit provides features such as technical debt analysis, advanced monitoring, metrics aggregation, performance profiling, bottleneck detection, alert system, multi-format export, storage flexibility, and more. It also offers AI-powered intelligence for smart recommendations, polyglot analysis, repository showcase, and integration points. PMAT enforces quality standards like complexity ≤20, zero SATD comments, test coverage >80%, no lint warnings, and synchronized documentation with commits. The toolkit follows Toyota Way development principles for iterative improvement, direct AST traversal, automated quality gates, and zero SATD policy.
azure-agentic-infraops
Agentic InfraOps is a multi-agent orchestration system for Azure infrastructure development that transforms how you build Azure infrastructure with AI agents. It provides a structured 7-step workflow that coordinates specialized AI agents through a complete infrastructure development cycle: Requirements → Architecture → Design → Plan → Code → Deploy → Documentation. The system enforces Azure Well-Architected Framework (WAF) alignment and Azure Verified Modules (AVM) at every phase, combining the speed of AI coding with best practices in cloud engineering.

pai-opencode
PAI-OpenCode is a complete port of Daniel Miessler's Personal AI Infrastructure (PAI) to OpenCode, an open-source, provider-agnostic AI coding assistant. It brings modular capabilities, dynamic multi-agent orchestration, session history, and lifecycle automation to personalize AI assistants for users. With support for 75+ AI providers, PAI-OpenCode offers dynamic per-task model routing, full PAI infrastructure, real-time session sharing, and multiple client options. The tool optimizes cost and quality with a 3-tier model strategy and a 3-tier research system, allowing users to switch presets for different routing strategies. PAI-OpenCode's architecture preserves PAI's design while adapting to OpenCode, documented through Architecture Decision Records (ADRs).
sf-skills
sf-skills is a collection of reusable skills for Agentic Salesforce Development, enabling AI-powered code generation, validation, testing, debugging, and deployment. It includes skills for development, quality, foundation, integration, AI & automation, DevOps & tooling. The installation process is newbie-friendly and includes an installer script for various CLIs. The skills are compatible with platforms like Claude Code, OpenCode, Codex, Gemini, Amp, Droid, Cursor, and Agentforce Vibes. The repository is community-driven and aims to strengthen the Salesforce ecosystem.
AReaL
AReaL (Ant Reasoning RL) is an open-source reinforcement learning system developed at the RL Lab, Ant Research. It is designed for training Large Reasoning Models (LRMs) in a fully open and inclusive manner. AReaL provides reproducible experiments for 1.5B and 7B LRMs, showcasing its scalability and performance across diverse computational budgets. The system follows an iterative training process to enhance model performance, with a focus on mathematical reasoning tasks. AReaL is equipped to adapt to different computational resource settings, enabling users to easily configure and launch training trials. Future plans include support for advanced models, optimizations for distributed training, and exploring research topics to enhance LRMs' reasoning capabilities.
axonhub
AxonHub is an all-in-one AI development platform that serves as an AI gateway allowing users to switch between model providers without changing any code. It provides features like vendor lock-in prevention, integration simplification, observability enhancement, and cost control. Users can access any model using any SDK with zero code changes. The platform offers full request tracing, enterprise RBAC, smart load balancing, and real-time cost tracking. AxonHub supports multiple databases, provides a unified API gateway, and offers flexible model management and API key creation for authentication. It also integrates with various AI coding tools and SDKs for seamless usage.

motia
Motia is an AI agent framework designed for software engineers to create, test, and deploy production-ready AI agents quickly. It provides a code-first approach, allowing developers to write agent logic in familiar languages and visualize execution in real-time. With Motia, developers can focus on business logic rather than infrastructure, offering zero infrastructure headaches, multi-language support, composable steps, built-in observability, instant APIs, and full control over AI logic. Ideal for building sophisticated agents and intelligent automations, Motia's event-driven architecture and modular steps enable the creation of GenAI-powered workflows, decision-making systems, and data processing pipelines.
new-api
New API is a next-generation large model gateway and AI asset management system that provides a wide range of features, including a new UI interface, multi-language support, online recharge function, key query for usage quota, compatibility with the original One API database, model charging by usage count, channel weighted randomization, data dashboard, token grouping and model restrictions, support for various authorization login methods, support for Rerank models, OpenAI Realtime API, Claude Messages format, reasoning effort setting, content reasoning, user-specific model rate limiting, request format conversion, cache billing support, and various model support such as gpts, Midjourney-Proxy, Suno API, custom channels, Rerank models, Claude Messages format, Dify, and more.
rag-web-ui
RAG Web UI is an intelligent dialogue system based on RAG (Retrieval-Augmented Generation) technology. It helps enterprises and individuals build intelligent Q&A systems based on their own knowledge bases. By combining document retrieval and large language models, it delivers accurate and reliable knowledge-based question-answering services. The system is designed with features like intelligent document management, advanced dialogue engine, and a robust architecture. It supports multiple document formats, async document processing, multi-turn contextual dialogue, and reference citations in conversations. The architecture includes a backend stack with Python FastAPI, MySQL + ChromaDB, MinIO, Langchain, JWT + OAuth2 for authentication, and a frontend stack with Next.js, TypeScript, Tailwind CSS, Shadcn/UI, and Vercel AI SDK for AI integration. Performance optimization includes incremental document processing, streaming responses, vector database performance tuning, and distributed task processing. The project is licensed under the Apache-2.0 License and is intended for learning and sharing RAG knowledge only, not for commercial purposes.
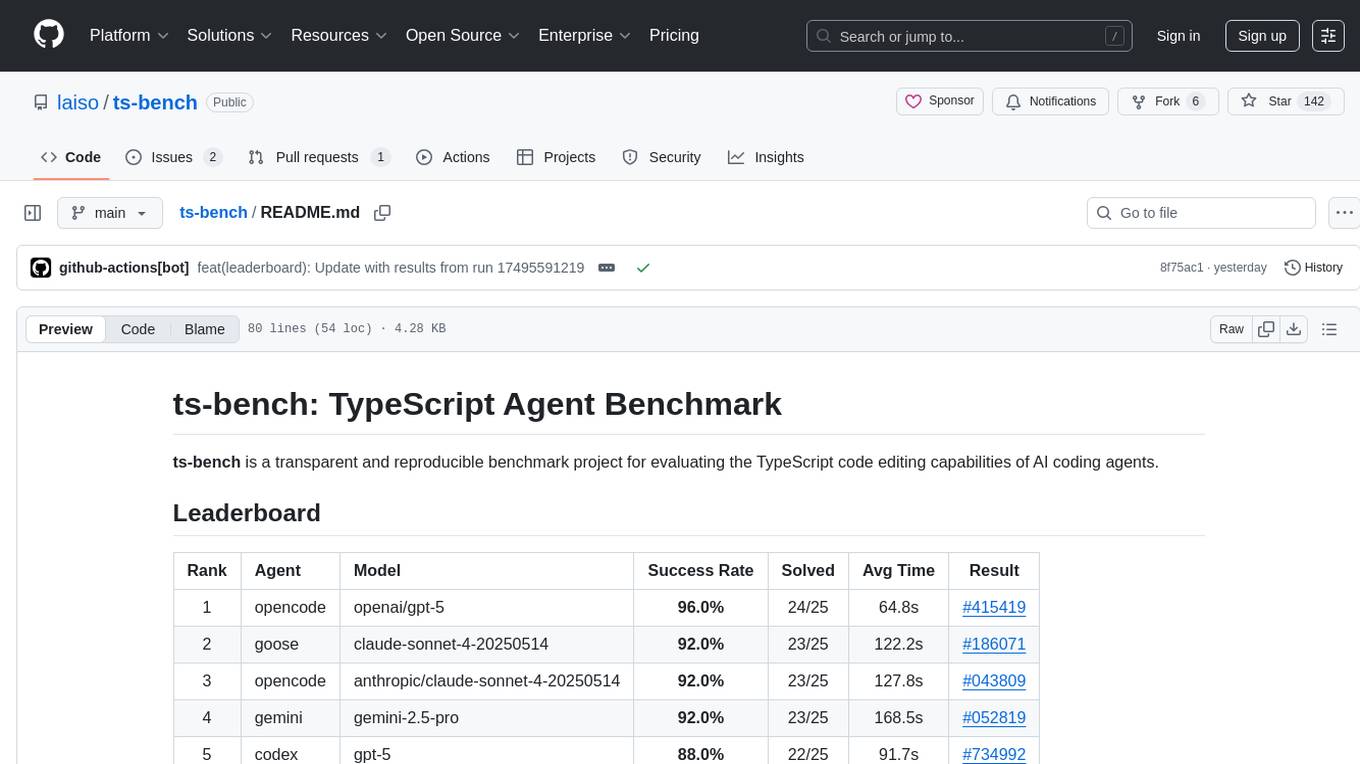
ts-bench
TS-Bench is a performance benchmarking tool for TypeScript projects. It provides detailed insights into the performance of TypeScript code, helping developers optimize their projects. With TS-Bench, users can measure and compare the execution time of different code snippets, functions, or modules. The tool offers a user-friendly interface for running benchmarks and analyzing the results. TS-Bench is a valuable asset for developers looking to enhance the performance of their TypeScript applications.


Curator
NeMo Curator is a Python library designed for fast and scalable data processing and curation for generative AI use cases. It accelerates data processing by leveraging GPUs with Dask and RAPIDS, providing customizable pipelines for text and image curation. The library offers pre-built pipelines for synthetic data generation, enabling users to train and customize generative AI models such as LLMs, VLMs, and WFMs.

UniCoT
Uni-CoT is a unified reasoning framework that extends Chain-of-Thought (CoT) principles to the multimodal domain, enabling Multimodal Large Language Models (MLLMs) to perform interpretable, step-by-step reasoning across both text and vision. It decomposes complex multimodal tasks into structured, manageable steps that can be executed sequentially or in parallel, allowing for more scalable and systematic reasoning.
cia
CIA is a powerful open-source tool designed for data analysis and visualization. It provides a user-friendly interface for processing large datasets and generating insightful reports. With CIA, users can easily explore data, perform statistical analysis, and create interactive visualizations to communicate findings effectively. Whether you are a data scientist, analyst, or researcher, CIA offers a comprehensive set of features to streamline your data analysis workflow and uncover valuable insights.
auto-dev
AutoDev Xiuper is an AI-native, multi-agent development platform built on Kotlin Multiplatform. It covers all seven phases of the software development lifecycle and runs on 8+ platforms. The platform provides a unified architecture for writing code once and running it anywhere, with specialized agents for each phase of development. It supports various devices including IntelliJ IDEA, VS Code, CLI, Web, Desktop, Android, iOS, and Server. The platform also offers features like Multi-LLM support, DevIns language for workflow automation, MCP Protocol for extensible tool ecosystem, and code intelligence for multiple programming languages.
For similar tasks
agentic-qe
Agentic Quality Engineering Fleet (Agentic QE) is a comprehensive tool designed for quality engineering tasks. It offers a Domain-Driven Design architecture with 13 bounded contexts and 60 specialized QE agents. The tool includes features like TinyDancer intelligent model routing, ReasoningBank learning with Dream cycles, HNSW vector search, Coherence Verification, and integration with other tools like Claude Flow and Agentic Flow. It provides capabilities for test generation, coverage analysis, quality assessment, defect intelligence, requirements validation, code intelligence, security compliance, contract testing, visual accessibility, chaos resilience, learning optimization, and enterprise integration. The tool supports various protocols, LLM providers, and offers a vast library of QE skills for different testing scenarios.
For similar jobs
aiscript
AiScript is a lightweight scripting language that runs on JavaScript. It supports arrays, objects, and functions as first-class citizens, and is easy to write without the need for semicolons or commas. AiScript runs in a secure sandbox environment, preventing infinite loops from freezing the host. It also allows for easy provision of variables and functions from the host.
askui
AskUI is a reliable, automated end-to-end automation tool that only depends on what is shown on your screen instead of the technology or platform you are running on.
bots
The 'bots' repository is a collection of guides, tools, and example bots for programming bots to play video games. It provides resources on running bots live, installing the BotLab client, debugging bots, testing bots in simulated environments, and more. The repository also includes example bots for games like EVE Online, Tribal Wars 2, and Elvenar. Users can learn about developing bots for specific games, syntax of the Elm programming language, and tools for memory reading development. Additionally, there are guides on bot programming, contributing to BotLab, and exploring Elm syntax and core library.
ain
Ain is a terminal HTTP API client designed for scripting input and processing output via pipes. It allows flexible organization of APIs using files and folders, supports shell-scripts and executables for common tasks, handles url-encoding, and enables sharing the resulting curl, wget, or httpie command-line. Users can put things that change in environment variables or .env-files, and pipe the API output for further processing. Ain targets users who work with many APIs using a simple file format and uses curl, wget, or httpie to make the actual calls.
LaVague
LaVague is an open-source Large Action Model framework that uses advanced AI techniques to compile natural language instructions into browser automation code. It leverages Selenium or Playwright for browser actions. Users can interact with LaVague through an interactive Gradio interface to automate web interactions. The tool requires an OpenAI API key for default examples and offers a Playwright integration guide. Contributors can help by working on outlined tasks, submitting PRs, and engaging with the community on Discord. The project roadmap is available to track progress, but users should exercise caution when executing LLM-generated code using 'exec'.
robocorp
Robocorp is a platform that allows users to create, deploy, and operate Python automations and AI actions. It provides an easy way to extend the capabilities of AI agents, assistants, and copilots with custom actions written in Python. Users can create and deploy tools, skills, loaders, and plugins that securely connect any AI Assistant platform to their data and applications. The Robocorp Action Server makes Python scripts compatible with ChatGPT and LangChain by automatically creating and exposing an API based on function declaration, type hints, and docstrings. It simplifies the process of developing and deploying AI actions, enabling users to interact with AI frameworks effortlessly.
Open-Interface
Open Interface is a self-driving software that automates computer tasks by sending user requests to a language model backend (e.g., GPT-4V) and simulating keyboard and mouse inputs to execute the steps. It course-corrects by sending current screenshots to the language models. The tool supports MacOS, Linux, and Windows, and requires setting up the OpenAI API key for access to GPT-4V. It can automate tasks like creating meal plans, setting up custom language model backends, and more. Open Interface is currently not efficient in accurate spatial reasoning, tracking itself in tabular contexts, and navigating complex GUI-rich applications. Future improvements aim to enhance the tool's capabilities with better models trained on video walkthroughs. The tool is cost-effective, with user requests priced between $0.05 - $0.20, and offers features like interrupting the app and primary display visibility in multi-monitor setups.
AI-Case-Sorter-CS7.1
AI-Case-Sorter-CS7.1 is a project focused on building a case sorter using machine vision and machine learning AI to sort cases by headstamp. The repository includes Arduino code and 3D models necessary for the project.