
parllama
TUI for Ollama and other LLM providers
Stars: 236
PAR LLAMA is a Text UI application for managing and using LLMs, designed with Textual and Rich and PAR AI Core. It runs on major OS's including Windows, Windows WSL, Mac, and Linux. Supports Dark and Light mode, custom themes, and various workflows like Ollama chat, image chat, and OpenAI provider chat. Offers features like custom prompts, themes, environment variables configuration, and remote instance connection. Suitable for managing and using LLMs efficiently.
README:
- About
- Prerequisites for running
- Prerequisites for dev
- Prerequisites for huggingface model quantization
- Installing using pipx
- Installing using uv
- Installing for dev mode
- Command line arguments
- Environment Variables
- Running PAR_LLAMA
- Running against a remote instance
- Running under Windows WSL
- Quick start Ollama chat workflow
- Quick start image chat workflow
- Quick start OpenAI provider chat workflow
- Custom Prompts
- Themes
- Screen Help
- Contributing
- FAQ
- Roadmap
- What's new




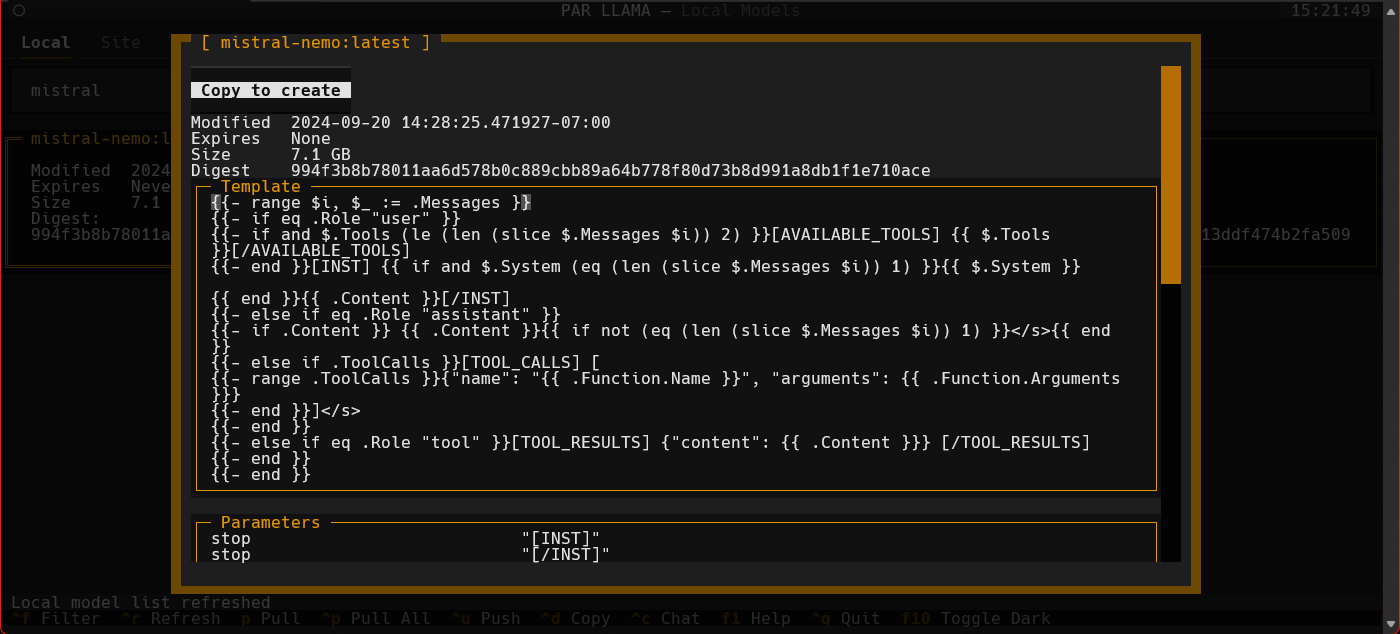
PAR LLAMA is a TUI (Text UI) application designed for easy management and use of Ollama based LLMs. (It also works with most major cloud provided LLMs) The application was built with Textual and Rich and my PAR AI Core. It runs on all major OS's including but not limited to Windows, Windows WSL, Mac, and Linux.

Supports Dark and Light mode as well as custom themes.
- Install and run Ollama
- Install Python 3.11 or newer
- https://www.python.org/downloads/ has installers for all versions of Python for all os's
- On Windows the Scoop tool makes it easy to install and manage things like python
- Install Scoop then do
scoop install python
- Install Scoop then do
- Install uv
- See the Using uv section
- Install GNU Compatible Make command
- On windows if you have scoop installed you can install make with
scoop install make
- On windows if you have scoop installed you can install make with
If you want to be able to quantize custom models from huggingface, download the following tool from the releases area: HuggingFaceModelDownloader
Install Docker Desktop
Pull the docker image ollama/quantize
docker pull ollama/quantizeIf you don't have uv installed you can run the following:
curl -LsSf https://astral.sh/uv/install.sh | shuv tool install parllamaTo upgrade an existing uv installation use the -U --force flags:
uv tool install parllama -U --forceuvx parllamauv tool install git+https://github.com/paulrobello/parllamaTo upgrade an existing installation use the --force flag:
uv tool install git+https://github.com/paulrobello/parllama -U --forceIf you don't have pipx installed you can run the following:
pip install pipx
pipx ensurepathpipx install parllamaTo upgrade an existing pipx installation use the --force flag:
pipx install parllama --forcepipx install git+https://github.com/paulrobello/parllamaTo upgrade an existing installation use the --force flag:
pipx install git+https://github.com/paulrobello/parllama --forceClone the repo and run the setup make target. Note uv is required for this.
git clone https://github.com/paulrobello/parllama
cd parllama
make setupusage: parllama [-h] [-v] [-d DATA_DIR] [-u OLLAMA_URL] [-t THEME_NAME] [-m {dark,light}]
[-s {local,site,chat,prompts,tools,create,options,logs}] [--use-last-tab-on-startup {0,1}] [-p PS_POLL] [-a {0,1}]
[--restore-defaults] [--purge-cache] [--purge-chats] [--purge-prompts] [--no-save] [--no-chat-save]
PAR LLAMA -- Ollama TUI.
options:
-h, --help show this help message and exit
-v, --version Show version information.
-d DATA_DIR, --data-dir DATA_DIR
Data Directory. Defaults to ~/.parllama
-u OLLAMA_URL, --ollama-url OLLAMA_URL
URL of your Ollama instance. Defaults to http://localhost:11434
-t THEME_NAME, --theme-name THEME_NAME
Theme name. Defaults to par
-m {dark,light}, --theme-mode {dark,light}
Dark / Light mode. Defaults to dark
-s {local,site,chat,prompts,tools,create,options,logs}, --starting-tab {local,site,chat,prompts,tools,create,options,logs}
Starting tab. Defaults to local
--use-last-tab-on-startup {0,1}
Use last tab on startup. Defaults to 1
-p PS_POLL, --ps-poll PS_POLL
Interval in seconds to poll ollama ps command. 0 = disable. Defaults to 3
-a {0,1}, --auto-name-session {0,1}
Auto name session using LLM. Defaults to 0
--restore-defaults Restore default settings and theme
--purge-cache Purge cached data
--purge-chats Purge all chat history
--purge-prompts Purge all custom prompts
--no-save Prevent saving settings for this session
--no-chat-save Prevent saving chats for this session
Unless you specify "--no-save" most flags such as -u, -t, -m, -s are sticky and will be used next time you start PAR_LLAMA.
- HOST Environment
- PARLLAMA_DATA_DIR/.env
- ParLlama Options Screen
- PARLLAMA_DATA_DIR - Used to set --data-dir
- PARLLAMA_THEME_NAME - Used to set --theme-name
- PARLLAMA_THEME_MODE - Used to set --theme-mode
- OLLAMA_URL - Used to set --ollama-url
- PARLLAMA_AUTO_NAME_SESSION - Set to 0 or 1 to disable / enable session auto naming using LLM
From anywhere:
parllamaFrom parent folder of venv
source venv/Scripts/activate
parllamaparllama -u "http://REMOTE_HOST:11434"Ollama by default only listens to localhost for connections, so you must set the environment variable OLLAMA_HOST=0.0.0.0:11434
to make it listen on all interfaces.
Note: this will allow connections to your Ollama server from other devices on any network you are connected to.
If you have Ollama installed via the native Windows installer you must set OLLAMA_HOST=0.0.0.0:11434 in the "System Variable" section
of the "Environment Variables" control panel.
If you installed Ollama under WSL, setting the var with export OLLAMA_HOST=0.0.0.0:11434 before starting the Ollama server will have it listen on all interfaces.
If your Ollama server is already running, stop and start it to ensure it picks up the new environment variable.
You can validate what interfaces the Ollama server is listening on by looking at the server.log file in the Ollama config folder.
You should see as one of the first few lines "OLLAMA_HOST:http://0.0.0.0:11434"
Now that the server is listening on all interfaces you must instruct PAR_LLAMA to use a custom Ollama connection url with the "-u" flag.
The command will look something like this:
parllama -u "http://$(hostname).local:11434"Depending on your DNS setup if the above does not work, try this:
parllama -u "http://$(grep -m 1 nameserver /etc/resolv.conf | awk '{print $2}'):11434"PAR_LLAMA will remember the -u flag so subsequent runs will not require that you specify it.
From repo root:
make dev- Start parllama.
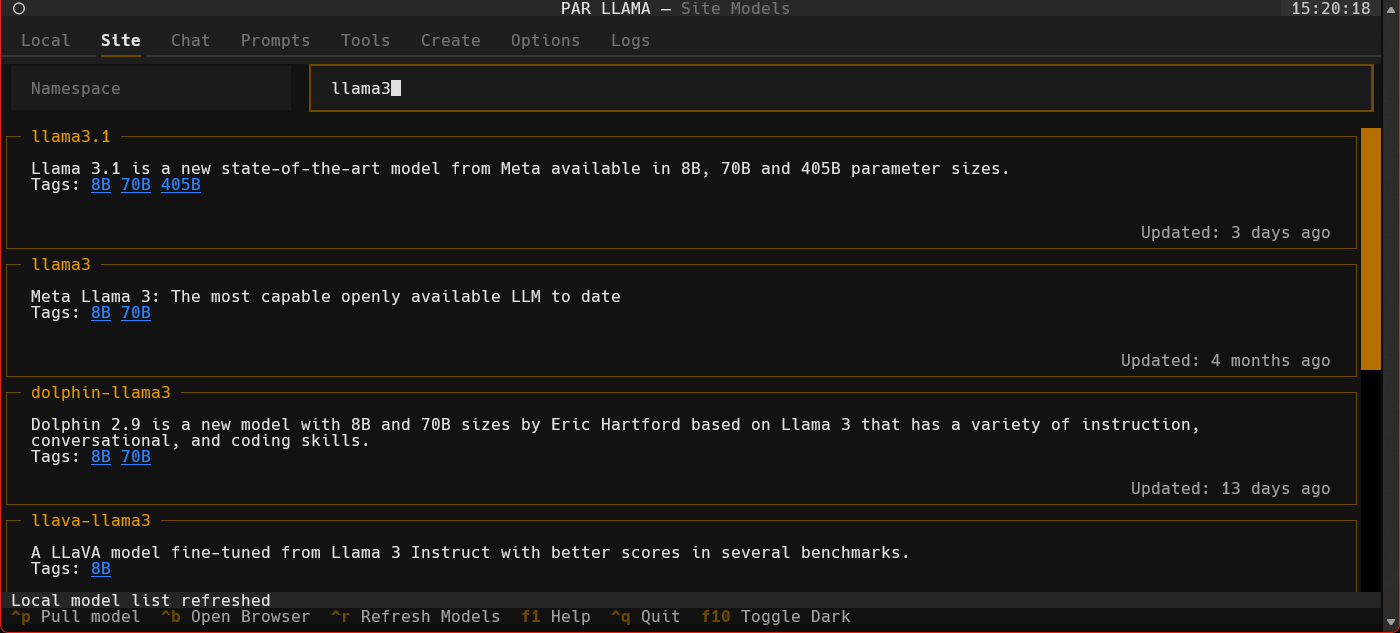
- Click the "Site" tab.
- Use ^R to fetch the latest models from Ollama.com.
- Use the "Filter Site models" text box and type "llama3".
- Find the entry with title of "llama3".
- Click the blue tag "8B" to update the search box to read "llama3:8b".
- Press ^P to pull the model from Ollama to your local machine. Depending on the size of the model and your internet connection this can take a few min.
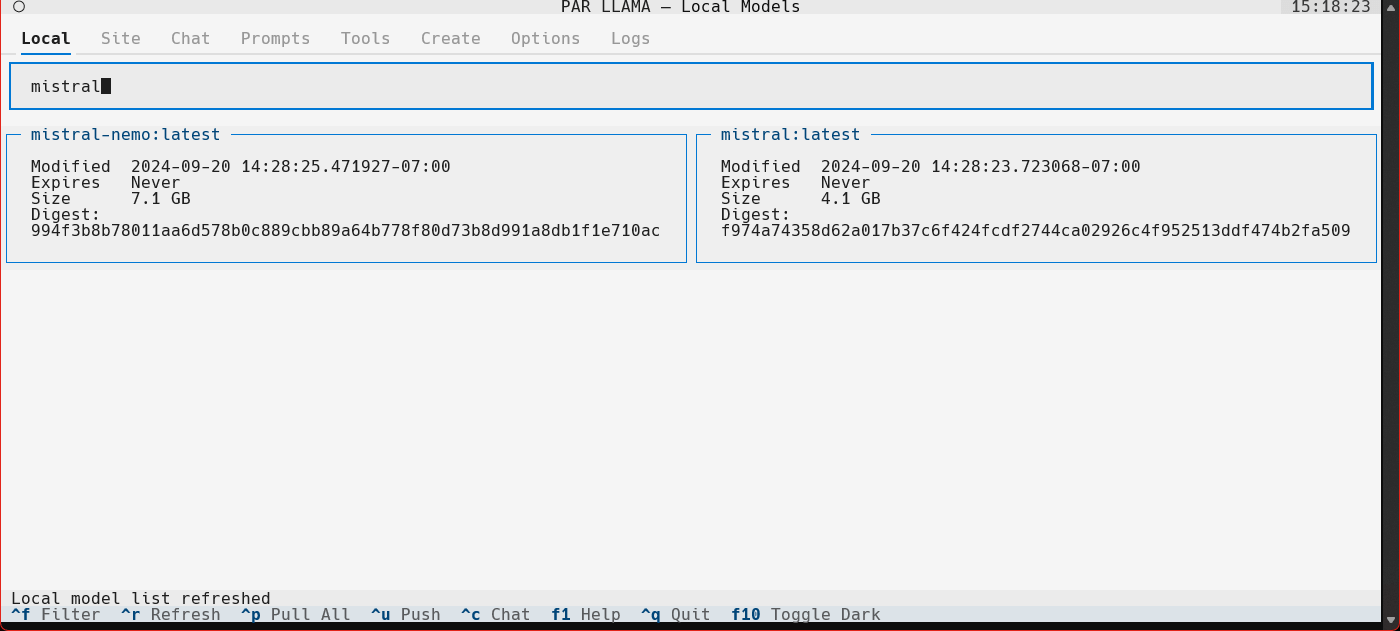
- Click the "Local" tab to see models that have been locally downloaded.
- Select the "llama3:8b" entry and press ^C to jump to the "Chat" tab and auto select the model.
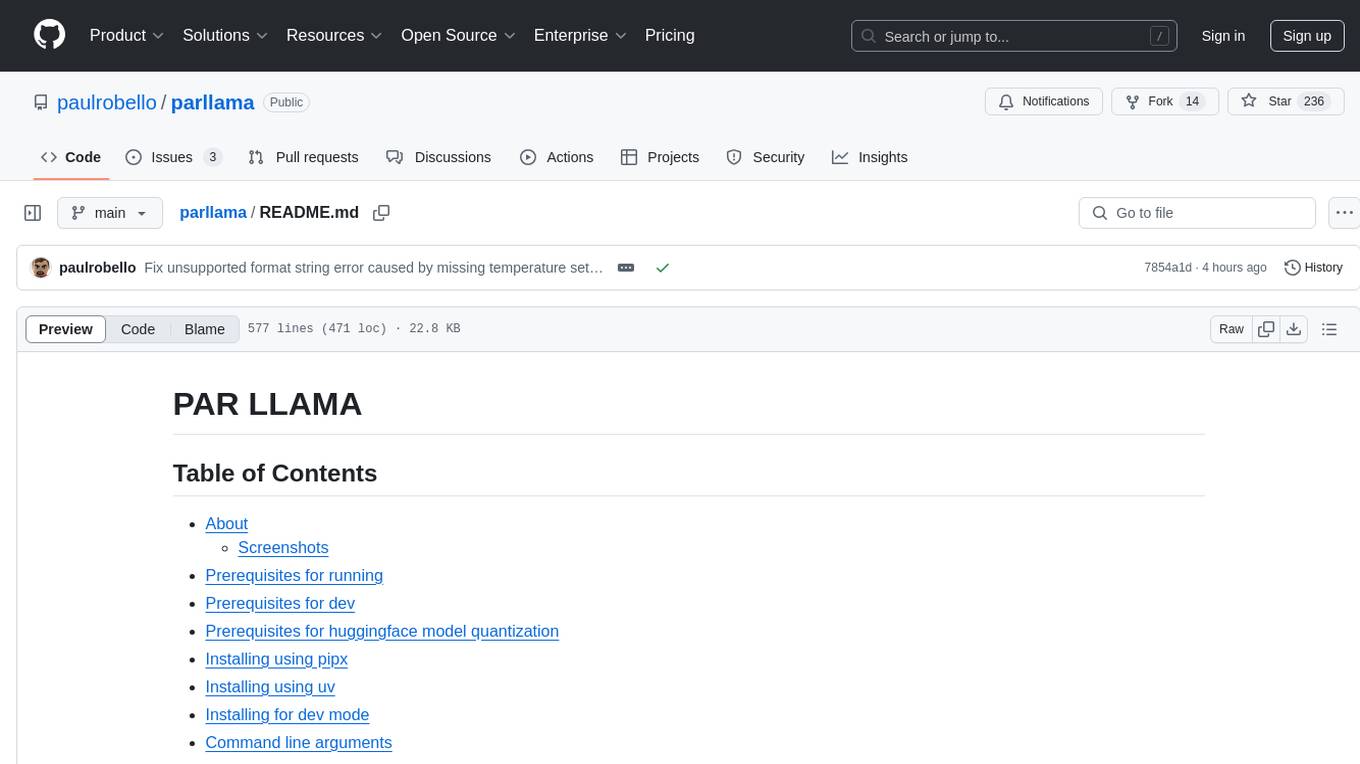
- Type a message to the model such as "Why is the sky blue?". It will take a few seconds for Ollama to load the model. After which the LLMs answer will stream in.
- Towards the very top of the app you will see what model is loaded and what percent of it is loaded into the GPU / CPU. If a model cant be loaded 100% on the GPU it will run slower.
- To export your conversation as a Markdown file type "/session.export" in the message input box. This will open a export dialog.
- Press ^N to add a new chat tab.
- Select a different model or change the temperature and ask the same questions.
- Jump between the tabs to compare responses by click the tabs or using slash commands
/tab.1and/tab.2 - Press ^S to see all your past and current sessions. You can recall any past session by selecting it and pressing Enter or ^N if you want to load it into a new tab.
- Press ^P to see / change your sessions config options such as provider, model, temperature, etc.
- Type "/help" or "/?" to see what other slash commands are available.
- Start parllama.
- Click the "Site" tab.
- Use ^R to fetch the latest models from Ollama.com.
- Use the "Filter Site models" text box and type "llava-llama3".
- Find the entry with title of "llava-llama3".
- Click the blue tag "8B" to update the search box to read "llava-llama3:8b".
- Press ^P to pull the model from Ollama to your local machine. Depending on the size of the model and your internet connection this can take a few min.
- Click the "Local" tab to see models that have been locally downloaded. If the download is complete and it isn't showing up here you may need to refresh the list with ^R.
- Select the "llava-llama3" entry and press ^C to jump to the "Chat" tab and auto select the model.
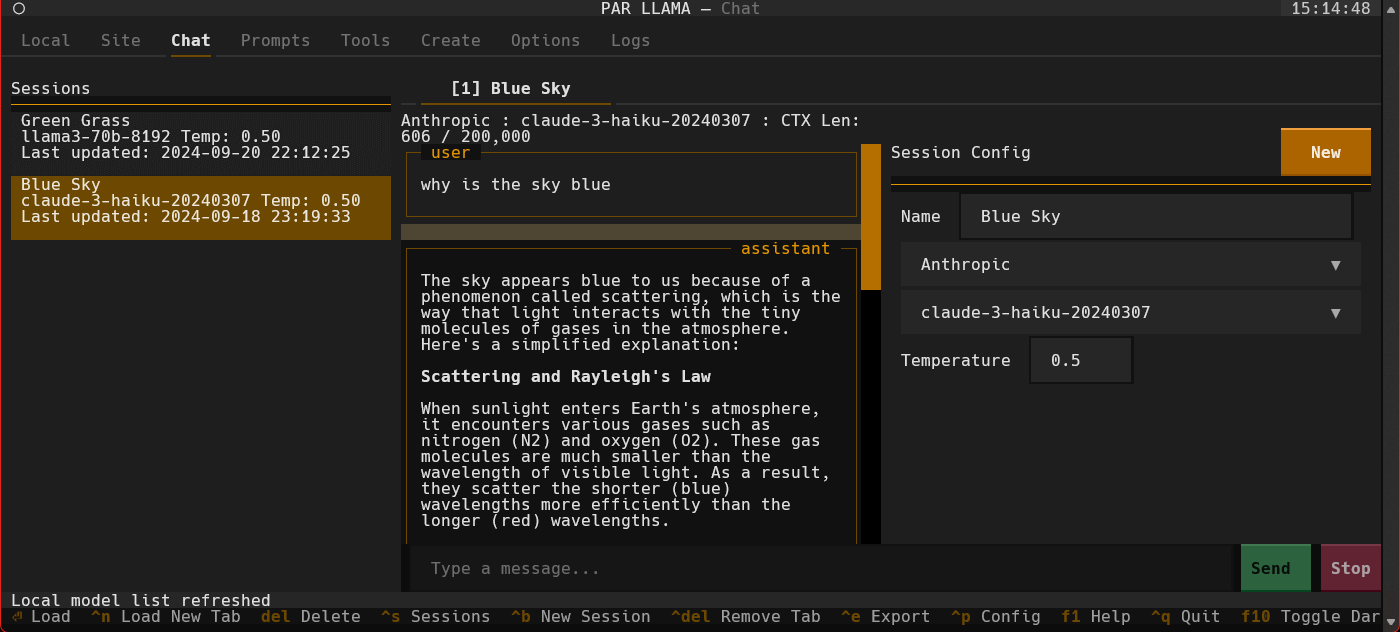
- Use a slash command to add an image and a prompt "/add.image PATH_TO_IMAGE describe whats happening in this image". It will take a few seconds for Ollama to load the model. After which the LLMs answer will stream in.
- Towards the very top of the app you will see what model is loaded and what percent of it is loaded into the GPU / CPU. If a model cant be loaded 100% on the GPU it will run slower.
- Type "/help" or "/?" to see what other slash commands are available.
- Start parllama.
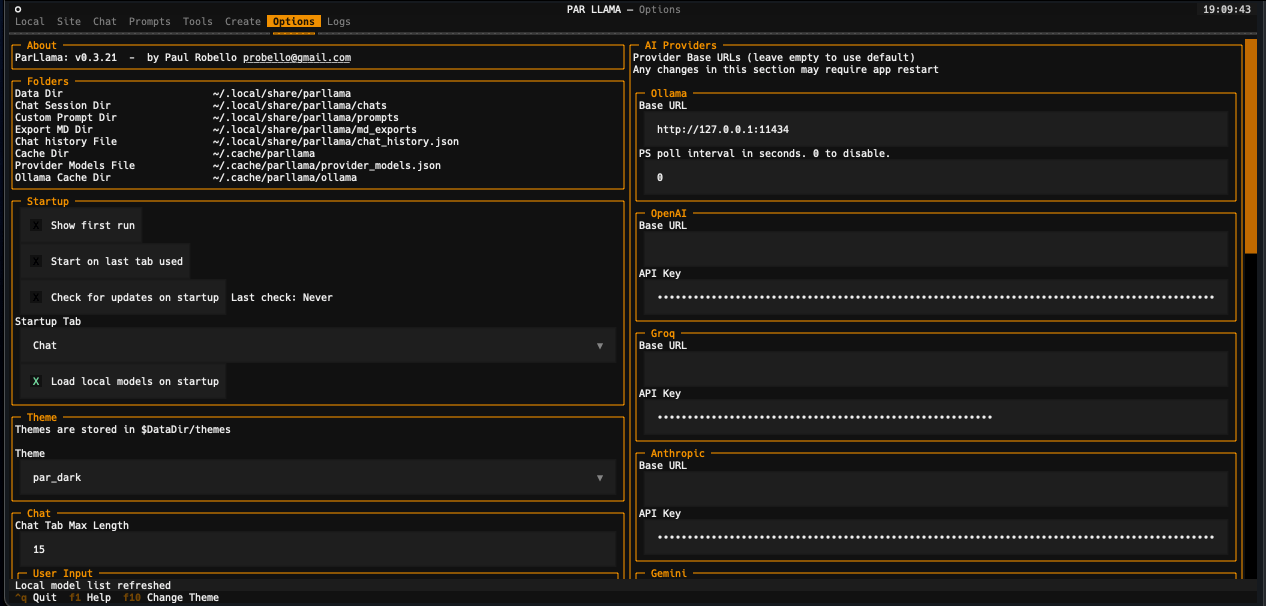
- Select the "Options" tab.
- Locate the AI provider you want to use the "Providers" section and enter your API key and base url if needed.
- You may need to restart parllama for some providers to fully take effect.
- Select the "Chat" tab
- If the "Session Config" panel on the right is not visible press
^p - Any providers that have don't need an API key or that do have an API key set should be selectable.
- Once a provider is selected available models should be loaded and selectable.
- Adjust any other session settings like Temperature.
- Click the message entry text box and converse with the LLM.
- Type "/help" or "/?" to see what slash commands are available.
Parllama supports LlamaCPP running OpenAI server mode. Parllama will use the default base_url of http://127.0.0.1:8080. This can be configured on the Options tab.
To start a LlamaCPP server run the following command in separate terminal:
llama-server -m PATH_TO_MODELor
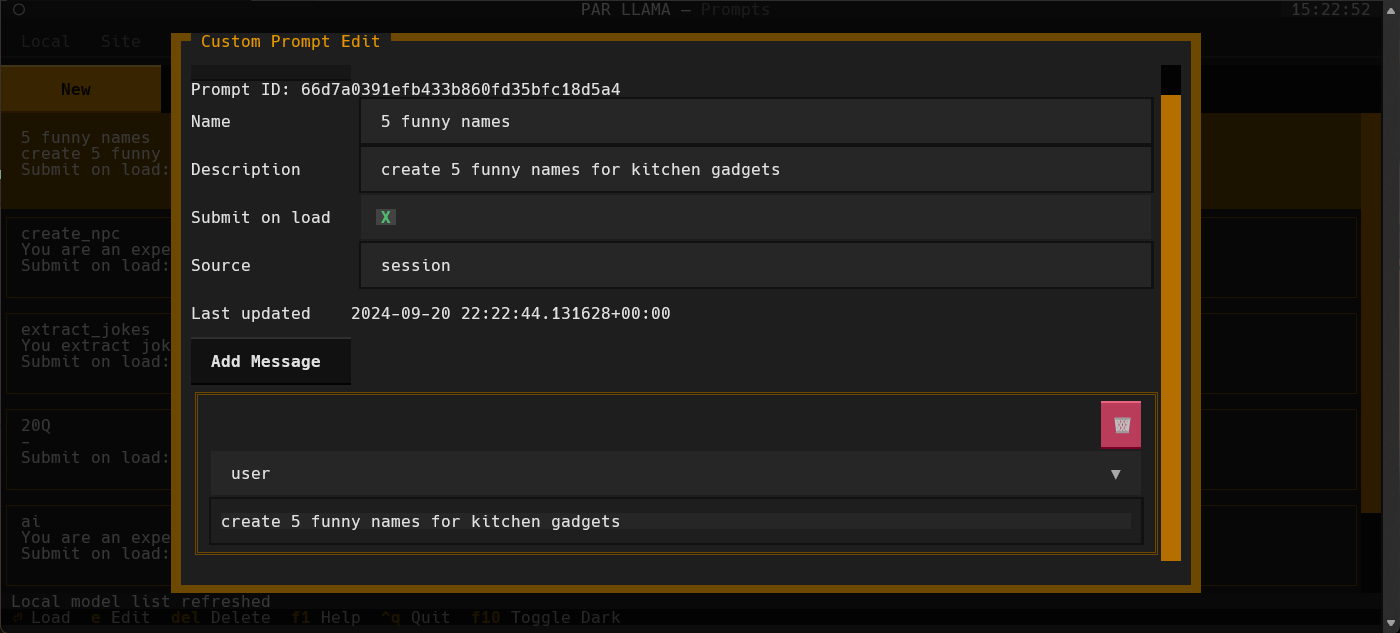
llama-server -mu URL_TO_MODELYou can create a library of custom prompts for easy starting of new chats.
You can set up system prompts and user messages to prime conversations with the option of sending immediately to the LLM upon loading of the prompt.
Currently, importing prompts from the popular Fabric project is supported with more on the way.
Themes are json files stored in the themes folder in the data directory which defaults to ~/.parllama/themes
The default theme is "par" so can be located in ~/.parllama/themes/par.json
Themes have a dark and light mode are in the following format:
{
"dark": {
"primary": "#e49500",
"secondary": "#6e4800",
"warning": "#ffa62b",
"error": "#ba3c5b",
"success": "#4EBF71",
"accent": "#6e4800",
"panel": "#111",
"surface":"#1e1e1e",
"background":"#121212",
"dark": true
},
"light": {
"primary": "#004578",
"secondary": "#ffa62b",
"warning": "#ffa62b",
"error": "#ba3c5b",
"success": "#4EBF71",
"accent": "#0178D4",
"background":"#efefef",
"surface":"#f5f5f5",
"dark": false
}
}You must specify at least one of light or dark for the theme to be usable.
Theme can be changed via command line with the --theme-name option.
Start by following the instructions in the section Installing for dev mode.
Please ensure that all pull requests are formatted with ruff, pass ruff lint and pyright.
You can run the make target pre-commit to ensure the pipeline will pass with your changes.
There is also a pre-commit config to that will assist with formatting and checks.
The easiest way to setup your environment to ensure smooth pull requests is:
With uv installed:
uv tool install pre-commitWith pipx installed:
pipx install pre-commitFrom repo root run the following:
pre-commit install
pre-commit run --all-filesAfter running the above all future commits will auto run pre-commit. pre-commit will fix what it can and show what if anything remains to be fixed before the commit is allowed.
- Q: Do I need Docker?
- A: Docker is only required if you want to Quantize models downloaded from Huggingface or similar llm repositories.
- Q: Does ParLlama require internet access?
- A: ParLlama by default does not require any network / internet access unless you enable checking for updates or want to import / use data from an online source.
- Q: Does ParLlama run on ARM?
- A: Short answer is yes. ParLlama should run any place python does. It has been tested on Windows 11 x64, Windows WSL x64, Mac OSX intel and silicon
- Q: Does ParLlama require Ollama be installed locally?
- A: No. ParLlama has options to connect to remote Ollama instances
- Q: Does ParLlama require Ollama?
- A: No. ParLlama can be used with most online AI providers
- Q: Does ParLlama support vision LLMs?
- A: Yes. If the selected provider / model supports vision you can add images to the chat via /slash commands
- Initial release - Find, maintain and create new models
- Theme support
- Connect to remote Ollama instances
- Chat with history / conversation management
- Chat tabs allow chat with multiple models at same time
- Custom prompt library with import from Fabric
- Auto complete of slash commands, input history, multi line edit
- Ability to use cloud AI providers like OpenAI, Anthropic, Groq, Google, xAI, OpenRouter, LiteLLM
- Use images with vision capable LLMs
- Ability to copy code and other sub sections from chat
- Better image support via file pickers
- Better support for reasoning / thinking models
- RAG for local documents and web pages
- Expand ability to import custom prompts of other tools
- LLM tool use
- Fix unsupported format string error caused by missing temperature setting
- Fix missing package error caused by previous update
- Updated dependencies for some major performance improvements
- Fixed crash on startup if Ollama is not available
- Fixed markdown display issues around fences
- Added "thinking" fence for deepseek thought output
- Much better support for displaying max input context size
- Added providers xAI, OpenRouter, Deepseek and LiteLLM
- Added copy button to the fence blocks in chat markdown for easy code copy
- Fix crash caused some models having some missing fields in model file
- Handle clipboard errors
- Fixed bug where changing providers that have custom urls would break other providers
- Fixed bug where changing Ollama base url would cause connection timed out
- Added ability to set max context size for Ollama and other providers that support it
- Limited support for LLamaCpp running in OpenAI Mode.
- Added ability to cycle through fences in selected chat message and copy to clipboard with
ctrl+shift+c - Added theme selector
- Varius bug fixes and performance improvements
- Updated core AI library and dependencies
- Fixed crash due to upstream library update
- Fixed crash issues on fresh installs
- Images are now stored in chat session json files
- Added API key checks for online providers
- Image support for models that support them using /add.image slash command. See the Quick start image chat workflow
- Add history support for both single and multi line input modes
- Fixed crash on models that dont have a license
- Fixed last model used not get used with new sessions
- Major rework of core to support providers other than Ollama
- Added support for the following online providers: OpenAI, Anthropic, Groq, Google
- New session config panel docked to right side of chat tab (more settings coming soon)
- Better counting of tokens (still not always 100% accurate)
- Fix for possible crash when there is more than one model loaded into ollama
- Added option to save chat input history and set its length
- Fixed tab switch issue on startup
- Added cache for Fabric import to speed up subsequent imports
- Added first time launch welcome
- Added Options tab which exposes more options than are available via command line switches
- Added option to auto check for new versions
- Added ability to import custom prompts from fabric
- Added toggle between single and multi line input (Note auto complete and command history features not available in multi line edit mode)
- Added custom prompt library support (Work in progress)
- Added cli option and environment var to enable auto naming of sessions using LLM (Work in progress)
- Added tokens per second stats to session info line on chat tab
- Fixed app crash when it cant contact ollama server for PS info
- Fixed slow startup when you have a lot of models available locally
- Fixed slow startup and reduced memory utilization when you have many / large chats
- Fixed session unique naming bug where it would always add a "1" to the session name
- Fixed app sometimes slowing down during LLM generation
- Major rework of internal message handling
- Issue where some footer items are not clickable has been resolved by a library PARLLAMA depends on
- Added ability to edit existing messages. select message in chat list and press "e" to edit, then "escape" to exit edit mode
- Add chat input history access via up / down arrow while chat message input has focus
- Added /session.system_prompt command to set system prompt in current chat tab
- Ollama ps stats bar now works with remote connections except for CPU / GPU %'s which ollama's api does not provide
- Chat tabs now have a session info bar with info like current / max context length
- Added conversation stop button to abort llm response
- Added ability to delete messages from session
- More model details displayed on model detail screen
- Better performance when changing session params on chat tab
- Add chat tabs to support multiple sessions
- Added cli option to prevent saving chat history to disk
- Renamed / namespaced chat slash commands for better consistency and grouping
- Fixed application crash when ollama binary not found
- Added chat history panel and management to chat page
- Fix missing dependency in package
- Added slash commands to chat input
- Added ability to export chat to markdown file
- ctrl+c on local model list will jump to chat tab and select currently selected local model
- ctrl+c on chat tab will copy selected chat message
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for parllama
Similar Open Source Tools
parllama
PAR LLAMA is a Text UI application for managing and using LLMs, designed with Textual and Rich and PAR AI Core. It runs on major OS's including Windows, Windows WSL, Mac, and Linux. Supports Dark and Light mode, custom themes, and various workflows like Ollama chat, image chat, and OpenAI provider chat. Offers features like custom prompts, themes, environment variables configuration, and remote instance connection. Suitable for managing and using LLMs efficiently.

lexido
Lexido is an innovative assistant for the Linux command line, designed to boost your productivity and efficiency. Powered by Gemini Pro 1.0 and utilizing the free API, Lexido offers smart suggestions for commands based on your prompts and importantly your current environment. Whether you're installing software, managing files, or configuring system settings, Lexido streamlines the process, making it faster and more intuitive.
OpenAI-sublime-text
The OpenAI Completion plugin for Sublime Text provides first-class code assistant support within the editor. It utilizes LLM models to manipulate code, engage in chat mode, and perform various tasks. The plugin supports OpenAI, llama.cpp, and ollama models, allowing users to customize their AI assistant experience. It offers separated chat histories and assistant settings for different projects, enabling context-specific interactions. Additionally, the plugin supports Markdown syntax with code language syntax highlighting, server-side streaming for faster response times, and proxy support for secure connections. Users can configure the plugin's settings to set their OpenAI API key, adjust assistant modes, and manage chat history. Overall, the OpenAI Completion plugin enhances the Sublime Text editor with powerful AI capabilities, streamlining coding workflows and fostering collaboration with AI assistants.
TerminalGPT
TerminalGPT is a terminal-based ChatGPT personal assistant app that allows users to interact with OpenAI GPT-3.5 and GPT-4 language models. It offers advantages over browser-based apps, such as continuous availability, faster replies, and tailored answers. Users can use TerminalGPT in their IDE terminal, ensuring seamless integration with their workflow. The tool prioritizes user privacy by not using conversation data for model training and storing conversations locally on the user's machine.
wcgw
wcgw is a shell and coding agent designed for Claude and Chatgpt. It provides full shell access with no restrictions, desktop control on Claude for screen capture and control, interactive command handling, large file editing, and REPL support. Users can use wcgw to create, execute, and iterate on tasks, such as solving problems with Python, finding code instances, setting up projects, creating web apps, editing large files, and running server commands. Additionally, wcgw supports computer use on Docker containers for desktop control. The tool can be extended with a VS Code extension for pasting context on Claude app and integrates with Chatgpt for custom GPT interactions.

Fabric
Fabric is an open-source framework designed to augment humans using AI by organizing prompts by real-world tasks. It addresses the integration problem of AI by creating and organizing prompts for various tasks. Users can create, collect, and organize AI solutions in a single place for use in their favorite tools. Fabric also serves as a command-line interface for those focused on the terminal. It offers a wide range of features and capabilities, including support for multiple AI providers, internationalization, speech-to-text, AI reasoning, model management, web search, text-to-speech, desktop notifications, and more. The project aims to help humans flourish by leveraging AI technology to solve human problems and enhance creativity.

torchchat
torchchat is a codebase showcasing the ability to run large language models (LLMs) seamlessly. It allows running LLMs using Python in various environments such as desktop, server, iOS, and Android. The tool supports running models via PyTorch, chatting, generating text, running chat in the browser, and running models on desktop/server without Python. It also provides features like AOT Inductor for faster execution, running in C++ using the runner, and deploying and running on iOS and Android. The tool supports popular hardware and OS including Linux, Mac OS, Android, and iOS, with various data types and execution modes available.
CLI
Bito CLI provides a command line interface to the Bito AI chat functionality, allowing users to interact with the AI through commands. It supports complex automation and workflows, with features like long prompts and slash commands. Users can install Bito CLI on Mac, Linux, and Windows systems using various methods. The tool also offers configuration options for AI model type, access key management, and output language customization. Bito CLI is designed to enhance user experience in querying AI models and automating tasks through the command line interface.
chatgpt-vscode
ChatGPT-VSCode is a Visual Studio Code integration that allows users to prompt OpenAI's GPT-4, GPT-3.5, GPT-3, and Codex models within the editor. It offers features like using improved models via OpenAI API Key, Azure OpenAI Service deployments, generating commit messages, storing conversation history, explaining and suggesting fixes for compile-time errors, viewing code differences, and more. Users can customize prompts, quick fix problems, save conversations, and export conversation history. The extension is designed to enhance developer experience by providing AI-powered assistance directly within VS Code.
claude-debugs-for-you
Claude Debugs For You is an MCP Server and VS Code extension that enables interactive debugging and evaluation of expressions with Claude or other LLM models. It is language-agnostic, requiring debugger console support and a valid launch.json for debugging in VSCode. Users can download the extension from releases or VS Code Marketplace, install it, and access commands through the status menu item 'Claude Debugs For You'. The tool supports debugging setups using stdio or /sse, and users can follow specific setup instructions depending on their configuration. Once set up, users can debug their code by interacting with the tool, which provides suggestions and fixes for identified issues.
testzeus-hercules
Hercules is the world’s first open-source testing agent designed to handle the toughest testing tasks for modern web applications. It turns simple Gherkin steps into fully automated end-to-end tests, making testing simple, reliable, and efficient. Hercules adapts to various platforms like Salesforce and is suitable for CI/CD pipelines. It aims to democratize and disrupt test automation, making top-tier testing accessible to everyone. The tool is transparent, reliable, and community-driven, empowering teams to deliver better software. Hercules offers multiple ways to get started, including using PyPI package, Docker, or building and running from source code. It supports various AI models, provides detailed installation and usage instructions, and integrates with Nuclei for security testing and WCAG for accessibility testing. The tool is production-ready, open core, and open source, with plans for enhanced LLM support, advanced tooling, improved DOM distillation, community contributions, extensive documentation, and a bounty program.
aimeos-typo3
Aimeos is a professional, full-featured, and high-performance e-commerce extension for TYPO3. It can be installed in an existing TYPO3 website within 5 minutes and can be adapted, extended, overwritten, and customized to meet specific needs.
robocorp
Robocorp is a platform that allows users to create, deploy, and operate Python automations and AI actions. It provides an easy way to extend the capabilities of AI agents, assistants, and copilots with custom actions written in Python. Users can create and deploy tools, skills, loaders, and plugins that securely connect any AI Assistant platform to their data and applications. The Robocorp Action Server makes Python scripts compatible with ChatGPT and LangChain by automatically creating and exposing an API based on function declaration, type hints, and docstrings. It simplifies the process of developing and deploying AI actions, enabling users to interact with AI frameworks effortlessly.
actions
Sema4.ai Action Server is a tool that allows users to build semantic actions in Python to connect AI agents with real-world applications. It enables users to create custom actions, skills, loaders, and plugins that securely connect any AI Assistant platform to data and applications. The tool automatically creates and exposes an API based on function declaration, type hints, and docstrings by adding '@action' to Python scripts. It provides an end-to-end stack supporting various connections between AI and user's apps and data, offering ease of use, security, and scalability.

dataline
DataLine is an AI-driven data analysis and visualization tool designed for technical and non-technical users to explore data quickly. It offers privacy-focused data storage on the user's device, supports various data sources, generates charts, executes queries, and facilitates report building. The tool aims to speed up data analysis tasks for businesses and individuals by providing a user-friendly interface and natural language querying capabilities.

kwaak
Kwaak is a tool that allows users to run a team of autonomous AI agents locally from their own machine. It enables users to write code, improve test coverage, update documentation, and enhance code quality while focusing on building innovative projects. Kwaak is designed to run multiple agents in parallel, interact with codebases, answer questions about code, find examples, write and execute code, create pull requests, and more. It is free and open-source, allowing users to bring their own API keys or models via Ollama. Kwaak is part of the bosun.ai project, aiming to be a platform for autonomous code improvement.
For similar tasks

XLearning
XLearning is a scheduling platform for big data and artificial intelligence, supporting various machine learning and deep learning frameworks. It runs on Hadoop Yarn and integrates frameworks like TensorFlow, MXNet, Caffe, Theano, PyTorch, Keras, XGBoost. XLearning offers scalability, compatibility, multiple deep learning framework support, unified data management based on HDFS, visualization display, and compatibility with code at native frameworks. It provides functions for data input/output strategies, container management, TensorBoard service, and resource usage metrics display. XLearning requires JDK >= 1.7 and Maven >= 3.3 for compilation, and deployment on CentOS 7.2 with Java >= 1.7 and Hadoop 2.6, 2.7, 2.8.
parllama
PAR LLAMA is a Text UI application for managing and using LLMs, designed with Textual and Rich and PAR AI Core. It runs on major OS's including Windows, Windows WSL, Mac, and Linux. Supports Dark and Light mode, custom themes, and various workflows like Ollama chat, image chat, and OpenAI provider chat. Offers features like custom prompts, themes, environment variables configuration, and remote instance connection. Suitable for managing and using LLMs efficiently.
mcp-ts-template
The MCP TypeScript Server Template is a production-grade framework for building powerful and scalable Model Context Protocol servers with TypeScript. It features built-in observability, declarative tooling, robust error handling, and a modular, DI-driven architecture. The template is designed to be AI-agent-friendly, providing detailed rules and guidance for developers to adhere to best practices. It enforces architectural principles like 'Logic Throws, Handler Catches' pattern, full-stack observability, declarative components, and dependency injection for decoupling. The project structure includes directories for configuration, container setup, server resources, services, storage, utilities, tests, and more. Configuration is done via environment variables, and key scripts are available for development, testing, and publishing to the MCP Registry.
receipt-ocr
An efficient OCR engine for receipt image processing, providing a comprehensive solution for Optical Character Recognition (OCR) on receipt images. The repository includes a dedicated Tesseract OCR module and a general receipt processing package using LLMs. Users can extract structured data from receipts, configure environment variables for multiple LLM providers, process receipts using CLI or programmatically in Python, and run the OCR engine as a Docker web service. The project also offers direct OCR capabilities using Tesseract and provides troubleshooting tips, contribution guidelines, and license information under the MIT license.
AGiXT
AGiXT is a dynamic Artificial Intelligence Automation Platform engineered to orchestrate efficient AI instruction management and task execution across a multitude of providers. Our solution infuses adaptive memory handling with a broad spectrum of commands to enhance AI's understanding and responsiveness, leading to improved task completion. The platform's smart features, like Smart Instruct and Smart Chat, seamlessly integrate web search, planning strategies, and conversation continuity, transforming the interaction between users and AI. By leveraging a powerful plugin system that includes web browsing and command execution, AGiXT stands as a versatile bridge between AI models and users. With an expanding roster of AI providers, code evaluation capabilities, comprehensive chain management, and platform interoperability, AGiXT is consistently evolving to drive a multitude of applications, affirming its place at the forefront of AI technology.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.