
simply
Minimal and scalable research codebase in JAX, designed for rapid iteration on frontier research in LLM and other autoregressive models.
Stars: 65
Simply is a minimal and scalable research codebase in JAX, designed for rapid iteration on frontier research in LLM and other autoregressive models. It is quick to fork and hack for fast iteration, with minimal abstractions and dependencies for a simple and self-contained codebase. Users can easily implement new architectures, optimizers, training losses, etc., in a few hours. Simply allows users to get started with hacking quickly, providing example commands for local testing and running on Google Cloud TPUs. The main dependencies include Jax for model and training, Orbax for checkpoint management, and Grain for data pipeline. Users can install dependencies, set up model checkpoints and datasets, and cite the tool if found helpful.
README:
Simply is a minimal and scalable research codebase in JAX, designed for rapid iteration on frontier research in LLM and other autoregressive models.
- Quick to fork and hack for fast iteration. You should be able to implement your research ideas (e.g., new architecture, optimizer, training loss, etc) in a few hours.
- Minimal abstractions and dependencies for a simple and self-contained codebase. Learn Jax (if you haven't), and you are ready to read and hack the code.
- That's it, simply get started with hacking now :)
EXP=simply_local_test_1; rm -rf /tmp/${EXP}; python -m simply.main --experiment_config lm_test --experiment_dir /tmp/${EXP} --alsologtostderrOr if you want to debug by printing arrays like normal python code, you can disable jit and use_scan using the command below.
export JAX_DISABLE_JIT=True; EXP=simply_local_test_1; rm -rf /tmp/${EXP}; python -m simply.main --experiment_config lm_no_scan_test --experiment_dir /tmp/${EXP} --alsologtostderrSee the GCloud Quickstart to run your first experiment on a Cloud TPU, or the full GCloud guide for multi-host training, preemption handling, and monitoring.
The main dependencies are: Jax for model and training. Orbax for checkpoint management. Grain for data pipeline.
Install dependencies:
# JAX installation is environment-specific. See https://docs.jax.dev/en/latest/installation.html
# CPU:
pip install -U jax
# GPU:
pip install -U "jax[cuda13]"
# TPU:
pip install -U "jax[tpu]"
# Other dependencies:
pip install -r requirements.txtDownload datasets and model checkpoints in format supported by Simply from HuggingFace:
# Install huggingface_hub
pip install huggingface_hub
# Download both models and datasets
python setup/setup_assets.py
# Or download only models/datasets
python setup/setup_assets.py --models-only
python setup/setup_assets.py --datasets-onlyThis will download models to ~/.cache/simply/models/ and datasets to ~/.cache/simply/datasets/. You can customize locations with --models-dir and --datasets-dir flags, or set environment variables SIMPLY_MODELS and SIMPLY_DATASETS. (Currently we only included a few datasets and models for testing, and will add more soon.)
If you find Simply helpful, please cite the following BibTeX:
@misc{Liang2025Simply,
author = {Chen Liang and Da Huang and Chengrun Yang and Xiaomeng Yang and Andrew Li and Xinchen Yan and {Simply Contributors}},
title = {{Simply: an experiment to accelerate and automate AI research}},
year = {2025},
howpublished = {GitHub repository},
url = {https://github.com/google-deepmind/simply}
}
Contributors list: Alex Zhai, Xingjian Zhang, Jiaxi Tang, Lizhang Chen, Ran Tian
Copyright 2025 Google LLC
All software is licensed under the Apache License, Version 2.0 (Apache 2.0); you may not use this file except in compliance with the Apache 2.0 license. You may obtain a copy of the Apache 2.0 license at: https://www.apache.org/licenses/LICENSE-2.0
All other materials are licensed under the Creative Commons Attribution 4.0 International License (CC-BY). You may obtain a copy of the CC-BY license at: https://creativecommons.org/licenses/by/4.0/legalcode
Unless required by applicable law or agreed to in writing, all software and materials distributed here under the Apache 2.0 or CC-BY licenses are distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the licenses for the specific language governing permissions and limitations under those licenses.
This is not an official Google product.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for simply
Similar Open Source Tools
simply
Simply is a minimal and scalable research codebase in JAX, designed for rapid iteration on frontier research in LLM and other autoregressive models. It is quick to fork and hack for fast iteration, with minimal abstractions and dependencies for a simple and self-contained codebase. Users can easily implement new architectures, optimizers, training losses, etc., in a few hours. Simply allows users to get started with hacking quickly, providing example commands for local testing and running on Google Cloud TPUs. The main dependencies include Jax for model and training, Orbax for checkpoint management, and Grain for data pipeline. Users can install dependencies, set up model checkpoints and datasets, and cite the tool if found helpful.
llm-random
This repository contains code for research conducted by the LLM-Random research group at IDEAS NCBR in Warsaw, Poland. The group focuses on developing and using this repository to conduct research. For more information about the group and its research, refer to their blog, llm-random.github.io.

dlio_benchmark
DLIO is an I/O benchmark tool designed for Deep Learning applications. It emulates modern deep learning applications using Benchmark Runner, Data Generator, Format Handler, and I/O Profiler modules. Users can configure various I/O patterns, data loaders, data formats, datasets, and parameters. The tool is aimed at emulating the I/O behavior of deep learning applications and provides a modular design for flexibility and customization.

BALROG
BALROG is a benchmark tool designed to evaluate agentic Long-Longitudinal Memory (LLM) and Vision-Language Memory (VLM) capabilities using reinforcement learning environments. It provides a comprehensive assessment of agentic abilities, supports both language and vision-language models, integrates with popular AI APIs, and allows for easy integration of custom agents, new environments, and models.

verifAI
VerifAI is a document-based question-answering system that addresses hallucinations in generative large language models and search engines. It retrieves relevant documents, generates answers with references, and verifies answers for accuracy. The engine uses generative search technology and a verification model to ensure no misinformation. VerifAI supports various document formats and offers user registration with a React.js interface. It is open-source and designed to be user-friendly, making it accessible for anyone to use.

vespa
Vespa is a platform that performs operations such as selecting a subset of data in a large corpus, evaluating machine-learned models over the selected data, organizing and aggregating it, and returning it, typically in less than 100 milliseconds, all while the data corpus is continuously changing. It has been in development for many years and is used on a number of large internet services and apps which serve hundreds of thousands of queries from Vespa per second.

OSWorld
OSWorld is a benchmarking tool designed to evaluate multimodal agents for open-ended tasks in real computer environments. It provides a platform for running experiments, setting up virtual machines, and interacting with the environment using Python scripts. Users can install the tool on their desktop or server, manage dependencies with Conda, and run benchmark tasks. The tool supports actions like executing commands, checking for specific results, and evaluating agent performance. OSWorld aims to facilitate research in AI by providing a standardized environment for testing and comparing different agent baselines.
uTensor
uTensor is an extremely light-weight machine learning inference framework built on Tensorflow and optimized for Arm targets. It consists of a runtime library and an offline tool that handles most of the model translation work. The core runtime is only ~2KB. The workflow involves constructing and training a model in Tensorflow, then using uTensor to produce C++ code for inferencing. The runtime ensures system safety, guarantees RAM usage, and focuses on clear, concise, and debuggable code. The high-level API simplifies tensor handling and operator execution for embedded systems.

ontogpt
OntoGPT is a Python package for extracting structured information from text using large language models, instruction prompts, and ontology-based grounding. It provides a command line interface and a minimal web app for easy usage. The tool has been evaluated on test data and is used in related projects like TALISMAN for gene set analysis. OntoGPT enables users to extract information from text by specifying relevant terms and provides the extracted objects as output.
CoML
CoML (formerly MLCopilot) is an interactive coding assistant for data scientists and machine learning developers, empowered on large language models. It offers an out-of-the-box interactive natural language programming interface for data mining and machine learning tasks, integration with Jupyter lab and Jupyter notebook, and a built-in large knowledge base of machine learning to enhance the ability to solve complex tasks. The tool is designed to assist users in coding tasks related to data analysis and machine learning using natural language commands within Jupyter environments.
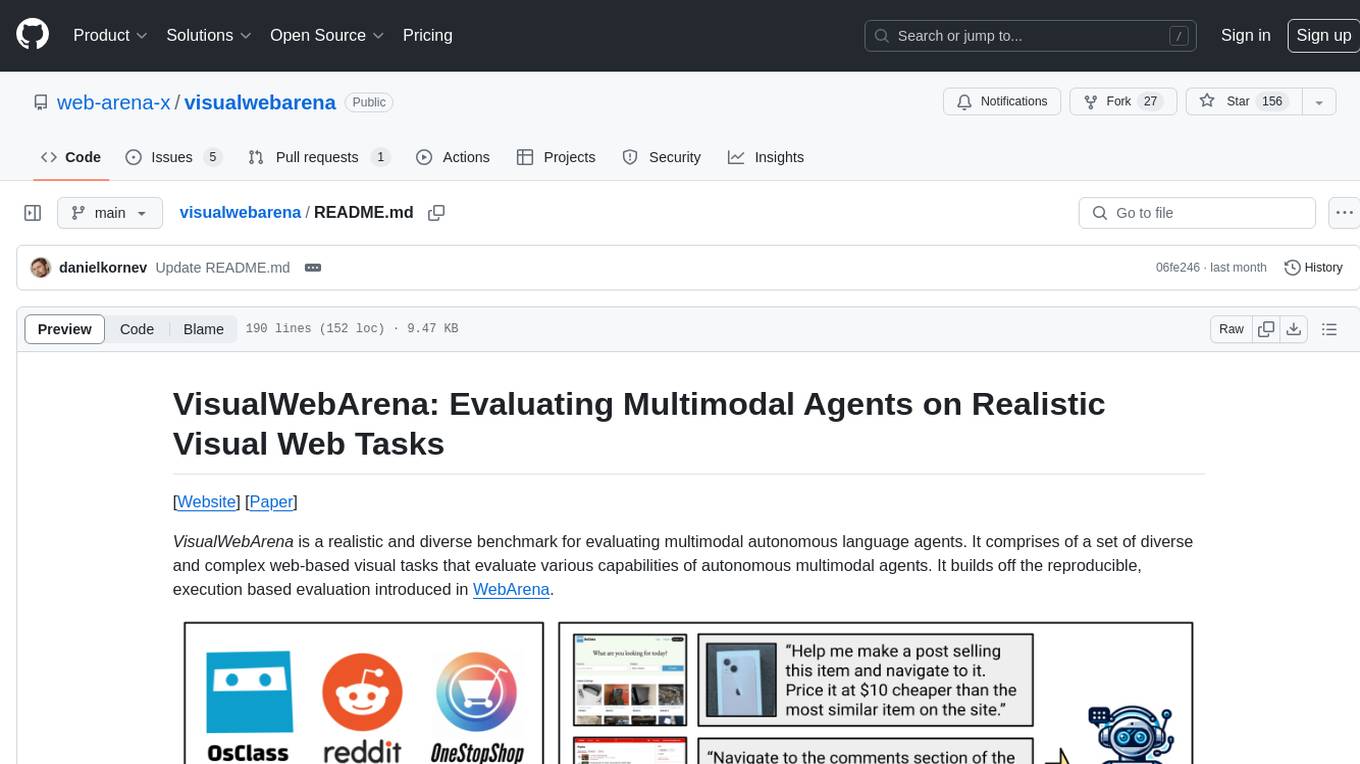
visualwebarena
VisualWebArena is a benchmark for evaluating multimodal autonomous language agents through diverse and complex web-based visual tasks. It builds on the reproducible evaluation introduced in WebArena. The repository provides scripts for end-to-end training, demos to run multimodal agents on webpages, and tools for setting up environments for evaluation. It includes trajectories of the GPT-4V + SoM agent on VWA tasks, along with human evaluations on 233 tasks. The environment supports OpenAI models and Gemini models for evaluation.

langchain
LangChain is a framework for developing Elixir applications powered by language models. It enables applications to connect language models to other data sources and interact with the environment. The library provides components for working with language models and off-the-shelf chains for specific tasks. It aims to assist in building applications that combine large language models with other sources of computation or knowledge. LangChain is written in Elixir and is not aimed for parity with the JavaScript and Python versions due to differences in programming paradigms and design choices. The library is designed to make it easy to integrate language models into applications and expose features, data, and functionality to the models.

fasttrackml
FastTrackML is an experiment tracking server focused on speed and scalability, fully compatible with MLFlow. It provides a user-friendly interface to track and visualize your machine learning experiments, making it easy to compare different models and identify the best performing ones. FastTrackML is open source and can be easily installed and run with pip or Docker. It is also compatible with the MLFlow Python package, making it easy to integrate with your existing MLFlow workflows.
cassio
cassIO is a framework-agnostic Python library that seamlessly integrates Apache Cassandra with ML/LLM/genAI workloads. It provides an easy-to-use interface for developers to connect their Cassandra databases to machine learning models, allowing them to perform complex data analysis and AI-powered tasks directly on their Cassandra data. cassIO is designed to be flexible and extensible, making it suitable for a wide range of use cases, from data exploration and visualization to predictive modeling and natural language processing.

knowledge-graph-of-thoughts
Knowledge Graph of Thoughts (KGoT) is an innovative AI assistant architecture that integrates LLM reasoning with dynamically constructed knowledge graphs (KGs). KGoT extracts and structures task-relevant knowledge into a dynamic KG representation, iteratively enhanced through external tools such as math solvers, web crawlers, and Python scripts. Such structured representation of task-relevant knowledge enables low-cost models to solve complex tasks effectively. The KGoT system consists of three main components: the Controller, the Graph Store, and the Integrated Tools, each playing a critical role in the task-solving process.

open-deep-research
Open Deep Research is an open-source project that serves as a clone of Open AI's Deep Research experiment. It utilizes Firecrawl's extract and search method along with a reasoning model to conduct in-depth research on the web. The project features Firecrawl Search + Extract, real-time data feeding to AI via search, structured data extraction from multiple websites, Next.js App Router for advanced routing, React Server Components and Server Actions for server-side rendering, AI SDK for generating text and structured objects, support for various model providers, styling with Tailwind CSS, data persistence with Vercel Postgres and Blob, and simple and secure authentication with NextAuth.js.
For similar tasks
simply
Simply is a minimal and scalable research codebase in JAX, designed for rapid iteration on frontier research in LLM and other autoregressive models. It is quick to fork and hack for fast iteration, with minimal abstractions and dependencies for a simple and self-contained codebase. Users can easily implement new architectures, optimizers, training losses, etc., in a few hours. Simply allows users to get started with hacking quickly, providing example commands for local testing and running on Google Cloud TPUs. The main dependencies include Jax for model and training, Orbax for checkpoint management, and Grain for data pipeline. Users can install dependencies, set up model checkpoints and datasets, and cite the tool if found helpful.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.