
bionic-gpt
Bionic is an on-premise replacement for ChatGPT, offering the advantages of Generative AI while maintaining strict data confidentiality
Stars: 2259
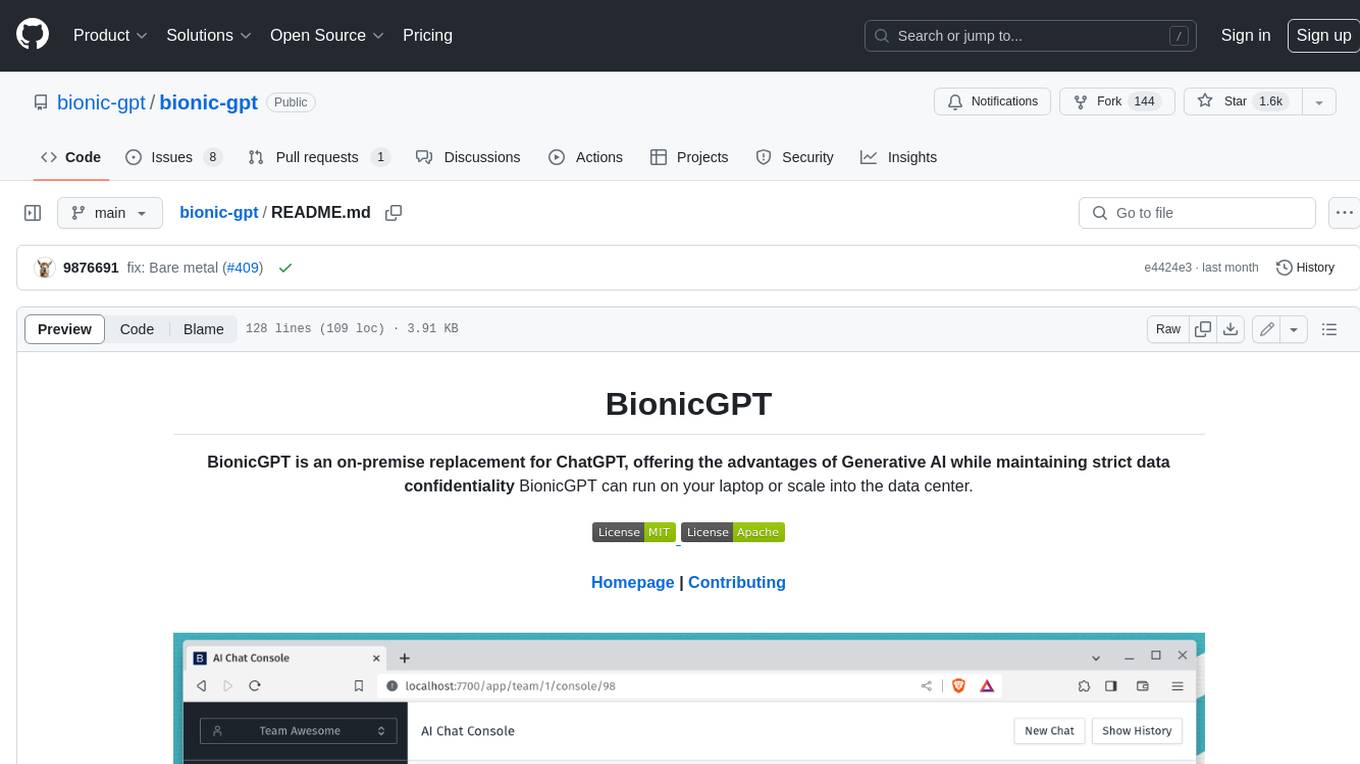
BionicGPT is an on-premise replacement for ChatGPT, offering the advantages of Generative AI while maintaining strict data confidentiality. BionicGPT can run on your laptop or scale into the data center.
README:

Try our Docker Compose installation. Ideal for running AI locally and for small pilots.
- 🖥️ Intuitive Interface: Our chat interface is inspired by ChatGPT to ensure a user-friendly experience.
- 🌈 Theme Customization: The theme for Bionic is completely customizable allowing you to brand Bionic as you like.
- ⚡ Ultra Fast UI: Enjoy fast and responsive performance from our Rust based UI.
- 📜 Chat History: Effortlessly access and manage your conversation history.
- 🤖 AI Assistants: Users can create assistants that work with their own data to enhance the AI.
- 🗨️ Share Assistants with Team Members: Generate and share assistants seamlessly between users, enhancing collaboration and communication.
- 📋 RAG Pipelines: Assistants are full scale enterprise ready RAG pipelines that can be launched in minutes.
- 📑 Any Documents: 80% of enterprise data exists in difficult-to-use formats like HTML, PDF, CSV, PNG, PPTX, and more. We support all of them.
- 💾 No Code: Configure embeddings engine and chunking algorithms all through our UI.
- 🗨️ System Prompts: Configure system prompts to get the LLM to reply in the way you want.
- 👫 Teams: Your company is made up of Teams of people and Bionic utilises this setup for maximum effect.
- 👫 Invite Team Members: Teams can self-manage in a controlled environment.
- 🙋 Manage Teams: Manage who has access to Bionic with your SSO system.
- 👬 Virtual Teams: Create teams within teams to
- 🚠 Switch Teams: Switch between teams whilst still keeping data isolated.
- 🚓 RBAC: Use your SSO system to configure which features users have access to.
- 👮 SAST: Static Application Security Testing - Our CI/CD pipeline runs SAST so we can identify risks before the code is built.
- 📢 Authorization RLS - We use Row Level Security in Postgres as another check to ensure data is not leaked between unauthorized users.
- 🚔 CSP: Our Content Security Policy is at the highest level and stops all manner of security threats.
- 🐳 Minimal containers: We build containers from Scratch whenever possible to limit supply chain attacks.
- ⏳ Non root containers: We run containers as non root to limit horizontal movement during an attack.
- 👮 Audit Trail: See who did what and when.
- ⏰ Postgres Roles: We run the minimum level of permissions for our postgres connections.
- 📣 SIEM integration: Integrate with your SIEM system for threat detection and investigation.
- ⌛ Resistant to timing attacks (api keys): Coming soon.
- 📭 SSO: We didn't build our own authentication but use industry leading and secure open source IAM systems.
- 👮 Secrets Management: Our Kubernetes operator creates secrets using secure algorithms at deployment time.
- 📈 Observability API: Compatible with Prometheus for measuring load and usage.
- 🤖 Dashboards: Create dashboards with Grafana for an overview of your whole system.
- 📚 Monitor Chats: All questions and responses are recording and available in the Postgres database.
- 📈 Fairly share resources: Without token limits it's easy for your models to become overloaded.
- 🔒 Reverse Proxy: All models are protected with our reverse proxy that allows you to set limits and ensure fair usage across your users.
- 👮 Role Based: Apply token usage limits based on a users role from your IAM system.
- 🔐 Assistants API: Any assistant you create can easily be turned into an Open AI compatible API.
- 🔑 Key Management: Users can create API keys for assistants they have access to.
- 🔏 Throttling limits: All API keys follow the users throttling limits ensuring fair access to the models.
- 📁 Batch Guardrails: Apply rules to documents uploaded by our batch data pipeline.
- 🏅 Streaming Guardrails: LLMs deliver results in streams, we can apply rules in realtime as the stream flies by.
- 👾 Prompt injection: We can guard against prompt injections attacks as well as many more.
- 🤖 Full support for open source models running locally or in your data center.
- 🌟 Multiple Model Support: Install and manage as many models as you want.
- 👾 Easy Switch: Seamlessly switch between different chat models for diverse interactions.
- ⚙️ Many Models Conversations: Effortlessly engage with various models simultaneously, harnessing their unique strengths for optimal responses. Enhance your experience by leveraging a diverse set of models in parallel.
⚠️ Configurable UI: Give users access or not to certain features based on roles you give them in your IAM system.- 🚦 With limits: Apply token usage limits based on a users role.
- 🎫 Fully secured: Rules are applied in our server and defence in depth secured one more time with Postgres RLS.
- 📤 100s of Sources: With our Airbyte integration you can batch upload data from sources such as Sharepoint, NFS, FTP, Kafka and more.
- 📥 Batching: Run upload once a day or every hour. Set the way you want.
- 📈 Real time: Capture data in real time to ensure your models are always using the latest data.
- 🚆 Manual Upload: Users have the ability to manually upload data so RAG pipelines can be setup in minutes.
- 🍟 Datasets: Data is stored in datasets and our security ensures data can't leak between users or teams.
- 📚 OCR: We can process documents using OCR to unlock even more data.
- 🚀 Effortless Setup: Install seamlessly using Kubernetes (k3s, Docker Desktop or the cloud) for a hassle-free experience.
- 🌟 Continuous Updates: We are committed to improving Bionic with regular updates and new features.
follow our guide to running Bionic-GPT in production.
Set the APP_BASE_URL environment variable to the public URL of your Bionic server. This value is used when constructing OAuth2 callback URLs.
flowchart TD
subgraph Users
Web[Web Users]
Devs[Developers]
Ops[Operations]
end
subgraph "Kubernetes Cluster"
subgraph "Namespace: bionic-gpt"
Nginx[Nginx]
OAuth[oauth2-proxy]
Server["Bionic Server<br><hr>• Limits Management<br>• Model Management<br>• MCP Server Management"]
Chunking[Chunking Engine]
ObjectStore[Object Storage]
DB[(PostgreSQL with Column Encryption and Vector DB)]
Grafana[Grafana]
end
subgraph "Namespace: model-garden"
MG["
• LLaMA 3
• Embeddings Model
• External Model API
"]
end
subgraph "Namespace: mcp-servers"
MCP["
• RAG Engine
• Time Service
"]
end
end
Web --> Nginx
Devs --> Nginx
Ops --> Grafana
Nginx --> OAuth
OAuth --> IdP[External Identity Provider]
OAuth --> Server
Server --> DB
Grafana --> DB
Server --> MG
Server --> MCP
Server --> Chunking
Server --> ObjectStore
Server --> Secrets[HSM via K8s Secrets]
%% Notes
Note1[/"MinIO or S3-compatible storage"/]
Note2[/"Chunking engine handles document preprocessing"/]
Note3[/"Vibe Coding"/]
ObjectStore -.-> Note1
Chunking -.-> Note2
Devs -.-> Note3For companies that need better security, user management and professional support
This covers:
- ✅ Help with integrations
- ✅ Feature Prioritization
- ✅ Custom Integrations
- ✅ LTS (Long Term Support) Versions
- ✅ Professional Support
- ✅ Custom SLAs
- ✅ Secure access with Single Sign-On
- ✅ Continuous Batching
- ✅ Data Pipelines
BionicGPT is optimized to run on Kubernetes and provide Generative AI services for potentially 1000's of users.

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for bionic-gpt
Similar Open Source Tools
bionic-gpt
BionicGPT is an on-premise replacement for ChatGPT, offering the advantages of Generative AI while maintaining strict data confidentiality. BionicGPT can run on your laptop or scale into the data center.

Instrukt
Instrukt is a terminal-based AI integrated environment that allows users to create and instruct modular AI agents, generate document indexes for question-answering, and attach tools to any agent. It provides a platform for users to interact with AI agents in natural language and run them inside secure containers for performing tasks. The tool supports custom AI agents, chat with code and documents, tools customization, prompt console for quick interaction, LangChain ecosystem integration, secure containers for agent execution, and developer console for debugging and introspection. Instrukt aims to make AI accessible to everyone by providing tools that empower users without relying on external APIs and services.

rhesis
Rhesis is a comprehensive test management platform designed for Gen AI teams, offering tools to create, manage, and execute test cases for generative AI applications. It ensures the robustness, reliability, and compliance of AI systems through features like test set management, automated test generation, edge case discovery, compliance validation, integration capabilities, and performance tracking. The platform is open source, emphasizing community-driven development, transparency, extensible architecture, and democratizing AI safety. It includes components such as backend services, frontend applications, SDK for developers, worker services, chatbot applications, and Polyphemus for uncensored LLM service. Rhesis enables users to address challenges unique to testing generative AI applications, such as non-deterministic outputs, hallucinations, edge cases, ethical concerns, and compliance requirements.
Conversation-Knowledge-Mining-Solution-Accelerator
The Conversation Knowledge Mining Solution Accelerator enables customers to leverage intelligence to uncover insights, relationships, and patterns from conversational data. It empowers users to gain valuable knowledge and drive targeted business impact by utilizing Azure AI Foundry, Azure OpenAI, Microsoft Fabric, and Azure Search for topic modeling, key phrase extraction, speech-to-text transcription, and interactive chat experiences.
extensionOS
Extension | OS is an open-source browser extension that brings AI directly to users' web browsers, allowing them to access powerful models like LLMs seamlessly. Users can create prompts, fix grammar, and access intelligent assistance without switching tabs. The extension aims to revolutionize online information interaction by integrating AI into everyday browsing experiences. It offers features like Prompt Factory for tailored prompts, seamless LLM model access, secure API key storage, and a Mixture of Agents feature. The extension was developed to empower users to unleash their creativity with custom prompts and enhance their browsing experience with intelligent assistance.
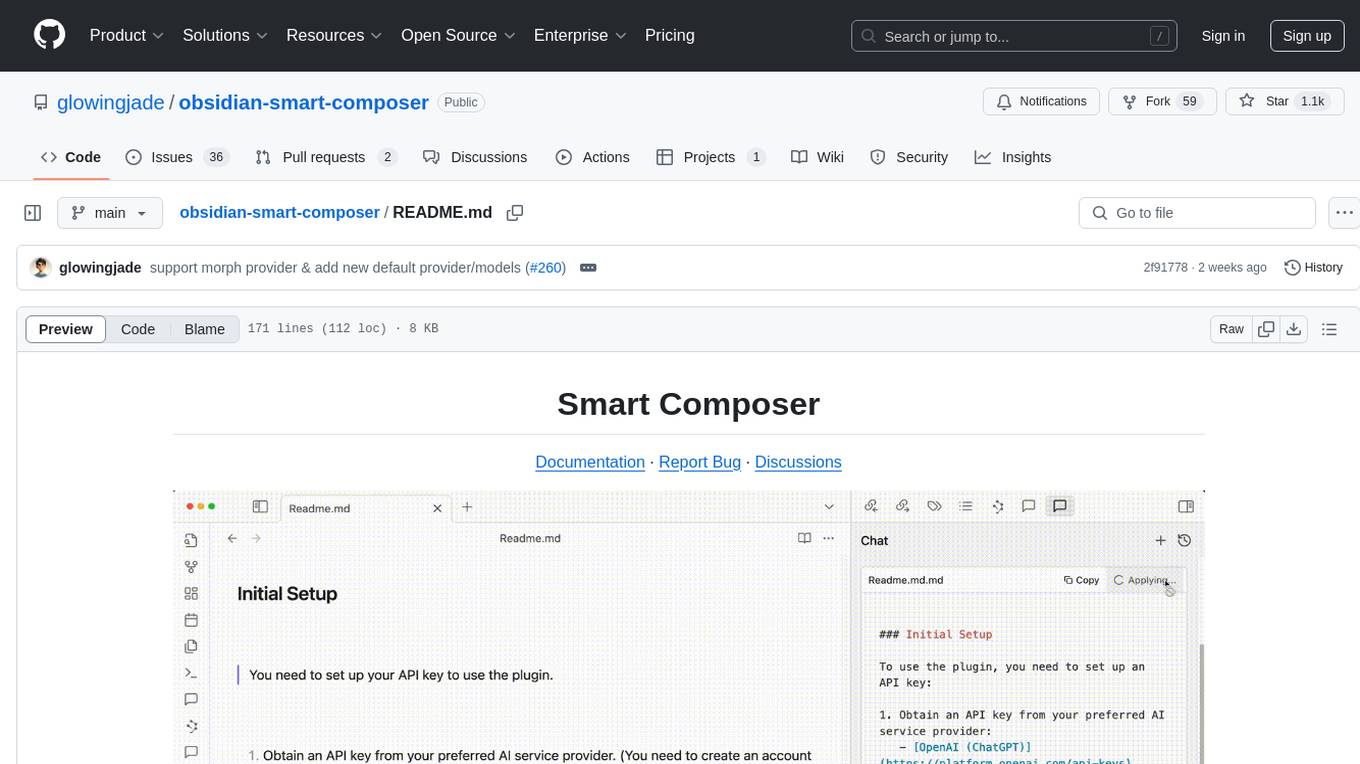
obsidian-smart-composer
Smart Composer is an Obsidian plugin that enhances note-taking and content creation by integrating AI capabilities. It allows users to efficiently write by referencing their vault content, providing contextual chat with precise context selection, multimedia context support for website links and images, document edit suggestions, and vault search for relevant notes. The plugin also offers features like custom model selection, local model support, custom system prompts, and prompt templates. Users can set up the plugin by installing it through the Obsidian community plugins, enabling it, and configuring API keys for supported providers like OpenAI, Anthropic, and Gemini. Smart Composer aims to streamline the writing process by leveraging AI technology within the Obsidian platform.
seatunnel
SeaTunnel is a high-performance, distributed data integration tool trusted by numerous companies for synchronizing vast amounts of data daily. It addresses common data integration challenges by seamlessly integrating with diverse data sources, supporting multimodal data integration, complex synchronization scenarios, resource efficiency, and quality monitoring. With over 100 connectors, SeaTunnel offers batch-stream integration, distributed snapshot algorithm, multi-engine support, JDBC multiplexing, and log parsing. It provides high throughput, low latency, real-time monitoring, and supports two job development methods. Users can configure jobs, select execution engines, and parallelize data using source connectors. SeaTunnel also supports multimodal data integration, Apache SeaTunnel tools, real-world use cases, and visual management of jobs through the SeaTunnel Web Project.
ai-chat-android
AI Chat Android demonstrates Google's Generative AI on Android with Firebase Realtime Database. It showcases Gemini API integration, Jetpack Compose UI elements, Android architecture components with Hilt, Kotlin Coroutines for background tasks, and Firebase Realtime Database integration for real-time events. The project follows Google's official architecture guidance with a modularized structure for reusability, parallel building, and decentralized focusing.
AI-Gateway
The AI-Gateway repository explores the AI Gateway pattern through a series of experimental labs, focusing on Azure API Management for handling AI services APIs. The labs provide step-by-step instructions using Jupyter notebooks with Python scripts, Bicep files, and APIM policies. The goal is to accelerate experimentation of advanced use cases and pave the way for further innovation in the rapidly evolving field of AI. The repository also includes a Mock Server to mimic the behavior of the OpenAI API for testing and development purposes.
Second-Me
Second Me is an open-source prototype that allows users to craft their own AI self, preserving their identity, context, and interests. It is locally trained and hosted, yet globally connected, scaling intelligence across an AI network. It serves as an AI identity interface, fostering collaboration among AI selves and enabling the development of native AI apps. The tool prioritizes individuality and privacy, ensuring that user information and intelligence remain local and completely private.
CursorLens
Cursor Lens is an open-source tool that acts as a proxy between Cursor and various AI providers, logging interactions and providing detailed analytics to help developers optimize their use of AI in their coding workflow. It supports multiple AI providers, captures and logs all requests, provides visual analytics on AI usage, allows users to set up and switch between different AI configurations, offers real-time monitoring of AI interactions, tracks token usage, estimates costs based on token usage and model pricing. Built with Next.js, React, PostgreSQL, Prisma ORM, Vercel AI SDK, Tailwind CSS, and shadcn/ui components.

llm-answer-engine
This repository contains the code and instructions needed to build a sophisticated answer engine that leverages the capabilities of Groq, Mistral AI's Mixtral, Langchain.JS, Brave Search, Serper API, and OpenAI. Designed to efficiently return sources, answers, images, videos, and follow-up questions based on user queries, this project is an ideal starting point for developers interested in natural language processing and search technologies.

mattermost-plugin-agents
The Mattermost Agents Plugin integrates AI capabilities directly into your Mattermost workspace, allowing users to run local LLMs on their infrastructure or connect to cloud providers. It offers multiple AI assistants with specialized personalities, thread and channel summarization, action item extraction, meeting transcription, semantic search, smart reactions, direct conversations with AI assistants, and flexible LLM support. The plugin comes with comprehensive documentation, installation instructions, system requirements, and development guidelines for users to interact with AI features and configure LLM providers.

cline-based-code-generator
HAI Code Generator is a cutting-edge tool designed to simplify and automate task execution while enhancing code generation workflows. Leveraging Specif AI, it streamlines processes like task execution, file identification, and code documentation through intelligent automation and AI-driven capabilities. Built on Cline's powerful foundation for AI-assisted development, HAI Code Generator boosts productivity and precision by automating task execution and integrating file management capabilities. It combines intelligent file indexing, context generation, and LLM-driven automation to minimize manual effort and ensure task accuracy. Perfect for developers and teams aiming to enhance their workflows.

cosdata
Cosdata is a cutting-edge AI data platform designed to power the next generation search pipelines. It features immutability, version control, and excels in semantic search, structured knowledge graphs, hybrid search capabilities, real-time search at scale, and ML pipeline integration. The platform is customizable, scalable, efficient, enterprise-grade, easy to use, and can manage multi-modal data. It offers high performance, indexing, low latency, and high requests per second. Cosdata is designed to meet the demands of modern search applications, empowering businesses to harness the full potential of their data.
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.
For similar tasks

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

ai-guide
This guide is dedicated to Large Language Models (LLMs) that you can run on your home computer. It assumes your PC is a lower-end, non-gaming setup.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.

jupyter-ai
Jupyter AI connects generative AI with Jupyter notebooks. It provides a user-friendly and powerful way to explore generative AI models in notebooks and improve your productivity in JupyterLab and the Jupyter Notebook. Specifically, Jupyter AI offers: * An `%%ai` magic that turns the Jupyter notebook into a reproducible generative AI playground. This works anywhere the IPython kernel runs (JupyterLab, Jupyter Notebook, Google Colab, Kaggle, VSCode, etc.). * A native chat UI in JupyterLab that enables you to work with generative AI as a conversational assistant. * Support for a wide range of generative model providers, including AI21, Anthropic, AWS, Cohere, Gemini, Hugging Face, NVIDIA, and OpenAI. * Local model support through GPT4All, enabling use of generative AI models on consumer grade machines with ease and privacy.

khoj
Khoj is an open-source, personal AI assistant that extends your capabilities by creating always-available AI agents. You can share your notes and documents to extend your digital brain, and your AI agents have access to the internet, allowing you to incorporate real-time information. Khoj is accessible on Desktop, Emacs, Obsidian, Web, and Whatsapp, and you can share PDF, markdown, org-mode, notion files, and GitHub repositories. You'll get fast, accurate semantic search on top of your docs, and your agents can create deeply personal images and understand your speech. Khoj is self-hostable and always will be.

langchain_dart
LangChain.dart is a Dart port of the popular LangChain Python framework created by Harrison Chase. LangChain provides a set of ready-to-use components for working with language models and a standard interface for chaining them together to formulate more advanced use cases (e.g. chatbots, Q&A with RAG, agents, summarization, extraction, etc.). The components can be grouped into a few core modules: * **Model I/O:** LangChain offers a unified API for interacting with various LLM providers (e.g. OpenAI, Google, Mistral, Ollama, etc.), allowing developers to switch between them with ease. Additionally, it provides tools for managing model inputs (prompt templates and example selectors) and parsing the resulting model outputs (output parsers). * **Retrieval:** assists in loading user data (via document loaders), transforming it (with text splitters), extracting its meaning (using embedding models), storing (in vector stores) and retrieving it (through retrievers) so that it can be used to ground the model's responses (i.e. Retrieval-Augmented Generation or RAG). * **Agents:** "bots" that leverage LLMs to make informed decisions about which available tools (such as web search, calculators, database lookup, etc.) to use to accomplish the designated task. The different components can be composed together using the LangChain Expression Language (LCEL).

danswer
Danswer is an open-source Gen-AI Chat and Unified Search tool that connects to your company's docs, apps, and people. It provides a Chat interface and plugs into any LLM of your choice. Danswer can be deployed anywhere and for any scale - on a laptop, on-premise, or to cloud. Since you own the deployment, your user data and chats are fully in your own control. Danswer is MIT licensed and designed to be modular and easily extensible. The system also comes fully ready for production usage with user authentication, role management (admin/basic users), chat persistence, and a UI for configuring Personas (AI Assistants) and their Prompts. Danswer also serves as a Unified Search across all common workplace tools such as Slack, Google Drive, Confluence, etc. By combining LLMs and team specific knowledge, Danswer becomes a subject matter expert for the team. Imagine ChatGPT if it had access to your team's unique knowledge! It enables questions such as "A customer wants feature X, is this already supported?" or "Where's the pull request for feature Y?"

infinity
Infinity is an AI-native database designed for LLM applications, providing incredibly fast full-text and vector search capabilities. It supports a wide range of data types, including vectors, full-text, and structured data, and offers a fused search feature that combines multiple embeddings and full text. Infinity is easy to use, with an intuitive Python API and a single-binary architecture that simplifies deployment. It achieves high performance, with 0.1 milliseconds query latency on million-scale vector datasets and up to 15K QPS.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.
LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.