
chatgpt-adapter
集成了openai-api、coze、deepseek、cursor、windsurf、qodo、blackbox、you、grok、bing 绘画 多款AI的聊天逆向接口适配到 OpenAI API 标准接口服务端。
Stars: 807
ChatGPT-Adapter is an interface service that integrates various free services together. It provides a unified interface specification and integrates services like Bing, Claude-2, Gemini. Users can start the service by running the linux-server script and set proxies if needed. The tool offers model lists for different adapters, completion dialogues, authorization methods for different services like Claude, Bing, Gemini, Coze, and Lmsys. Additionally, it provides a free drawing interface with options like coze.dall-e-3, sd.dall-e-3, xl.dall-e-3, pg.dall-e-3 based on user-provided Authorization keys. The tool also supports special flags for enhanced functionality.
README:
具体配置请 » 查阅文档 »
支持高速流式输出、支持多轮对话,与ChatGPT接口完全兼容。
使用本项目,可享用以下内容转v1接口:
- 字节coze国际版
- new bing copilot
- cursor editor
- windsurf editor
- qodo
- deepseek
- Chatbot Arena LMSYS
- you
- grok
- huggingface 绘图
安装中间编译工具
go install ./cmd/iocgo
# or
make install正常指令附加
# ----- go build ------ #
# 原指令 #
go build ./main.go
# 附加指令 #
go build -toolexec iocgo ./main.go
# ----- go run ------ #
# 原指令 #
go run ./main.go
# 附加指令 #
go run -toolexec iocgo ./main.go其它go指令同理
make install
make build
./bin/[os]/server[.exe] -h- docker 命令:
docker run -p 8080:8080 -v ./config.yaml:/app/config.yaml ghcr.io/bincooo/chatgpt-adapter:latest- huggingface: Duplicate this Space
[Unit]
Description=ChatGPT adapter
After=network.target
[Service]
Type=simple
WorkingDirectory=/your_work_dir
ExecStart=/your_app --port 7860
Restart=on-failure
[Install]
WantedBy=multi-user.target看到有不少朋友似乎对逆向爬虫十分感兴趣,那我这里就浅谈一下个人的一点小经验吧
- 爬虫逆向之 ja3 指纹篇
- 爬虫逆向之 new bing copilot篇
- 爬虫逆向之 cursor & windsurf (protobuf+gzip)篇
本仓库发布的程序代码及其中涉及的任何解锁和解密分析脚本,仅用于测试和学习研究,禁止用于商业用途,不能保证其合法性,准确性,完整性和有效性,请根据情况自行判断。
本项目内所有资源文件,禁止任何公众号、自媒体进行任何形式的转载、发布。
本人对任何脚本/代码/访问资源问题概不负责,包括但不限于由任何脚本错误导致的任何损失或损害。
间接使用脚本/代码/访问资源的任何用户,包括但不限于建立VPS或在某些行为违反国家/地区法律或相关法规的情况下进行传播, 本人对于由此引起的任何隐私泄漏或其他后果概不负责。
请勿将本仓库的任何内容用于商业或非法目的,否则后果自负。
如果任何单位或个人认为该项目的脚本/代码/访问资源可能涉嫌侵犯其权利,则应及时通知并提供身份证明,所有权证明,我们将在收到认证文件后删除相关脚本。
任何以任何方式查看此项目的人或直接或间接使用该项目的任何脚本的使用者都应仔细阅读此声明。本人保留随时更改或补充此免责声明的权利。一旦使用并复制了任何相关脚本或Script项目的规则,则视为您已接受此免责声明。
您必须在下载后的24小时内从计算机或手机中完全删除以上内容.
您使用或者复制了本仓库且本人制作的任何脚本/代码,则视为 已接受 此声明,请仔细阅读!
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for chatgpt-adapter
Similar Open Source Tools
chatgpt-adapter
ChatGPT-Adapter is an interface service that integrates various free services together. It provides a unified interface specification and integrates services like Bing, Claude-2, Gemini. Users can start the service by running the linux-server script and set proxies if needed. The tool offers model lists for different adapters, completion dialogues, authorization methods for different services like Claude, Bing, Gemini, Coze, and Lmsys. Additionally, it provides a free drawing interface with options like coze.dall-e-3, sd.dall-e-3, xl.dall-e-3, pg.dall-e-3 based on user-provided Authorization keys. The tool also supports special flags for enhanced functionality.
ChatGPT-Next-Web
ChatGPT Next Web is a well-designed cross-platform ChatGPT web UI tool that supports Claude, GPT4, and Gemini Pro models. It allows users to deploy their private ChatGPT applications with ease. The tool offers features like one-click deployment, compact client for Linux/Windows/MacOS, compatibility with self-deployed LLMs, privacy-first approach with local data storage, markdown support, responsive design, fast loading speed, prompt templates, awesome prompts, chat history compression, multilingual support, and more.
HyperChat
HyperChat is an open Chat client that utilizes various LLM APIs to enhance the Chat experience and offer productivity tools through the MCP protocol. It supports multiple LLMs like OpenAI, Claude, Qwen, Deepseek, GLM, Ollama. The platform includes a built-in MCP plugin market for easy installation and also allows manual installation of third-party MCPs. Features include Windows and MacOS support, resource support, tools support, English and Chinese language support, built-in MCP client 'hypertools', 'fetch' + 'search', Bot support, Artifacts rendering, KaTeX for mathematical formulas, WebDAV synchronization, and a MCP plugin market. Future plans include permission pop-up, scheduled tasks support, Projects + RAG support, tools implementation by LLM, and a local shell + nodejs + js on web runtime environment.
rag-chatbot
rag-chatbot is a tool that allows users to chat with multiple PDFs using Ollama and LlamaIndex. It provides an easy setup for running on local machines or Kaggle notebooks. Users can leverage models from Huggingface and Ollama, process multiple PDF inputs, and chat in multiple languages. The tool offers a simple UI with Gradio, supporting chat with history and QA modes. Setup instructions are provided for both Kaggle and local environments, including installation steps for Docker, Ollama, Ngrok, and the rag_chatbot package. Users can run the tool locally and access it via a web interface. Future enhancements include adding evaluation, better embedding models, knowledge graph support, improved document processing, MLX model integration, and Corrective RAG.
auto-engineer
Auto Engineer is a tool designed to automate the Software Development Life Cycle (SDLC) by building production-grade applications with a combination of human and AI agents. It offers a plugin-based architecture that allows users to install only the necessary functionality for their projects. The tool guides users through key stages including Flow Modeling, IA Generation, Deterministic Scaffolding, AI Coding & Testing Loop, and Comprehensive Quality Checks. Auto Engineer follows a command/event-driven architecture and provides a modular plugin system for specific functionalities. It supports TypeScript with strict typing throughout and includes a built-in message bus server with a web dashboard for monitoring commands and events.
ai-real-estate-assistant
AI Real Estate Assistant is a modern platform that uses AI to assist real estate agencies in helping buyers and renters find their ideal properties. It features multiple AI model providers, intelligent query processing, advanced search and retrieval capabilities, and enhanced user experience. The tool is built with a FastAPI backend and Next.js frontend, offering semantic search, hybrid agent routing, and real-time analytics.
ChatGPT-API-Faucet
ChatGPT API Faucet is a frontend project for the public platform ChatGPT API Faucet, inspired by the crypto project MultiFaucet. It allows developers in the AI ecosystem to claim $1.00 for free every 24 hours. The program is developed using the Next.js framework and React library, with key components like _app.tsx for initializing pages, index.tsx for main modifications, and Layout.tsx for defining layout components. Users can deploy the project by installing dependencies, building the project, starting the project, configuring reverse proxies or using port:IP access, and running a development server. The tool also supports token balance queries and is related to projects like one-api, ChatGPT-Cost-Calculator, and Poe.Monster. It is licensed under the MIT license.
packages
This repository is a monorepo for NPM packages published under the `@elevenlabs` scope. It contains multiple packages in the `packages` folder. The setup allows for easy development, linking packages, creating new packages, and publishing them with GitHub actions.

dexto
Dexto is a lightweight runtime for creating and running AI agents that turn natural language into real-world actions. It serves as the missing intelligence layer for building AI applications, standalone chatbots, or as the reasoning engine inside larger products. Dexto features a powerful CLI and Web UI for running AI agents, supports multiple interfaces, allows hot-swapping of LLMs from various providers, connects to remote tool servers via the Model Context Protocol, is config-driven with version-controlled YAML, offers production-ready core features, extensibility for custom services, and enables multi-agent collaboration via MCP and A2A.
ai-gradio
ai-gradio is a Python package that simplifies the creation of machine learning apps using various models like OpenAI, Google's Gemini, Anthropic's Claude, LumaAI, CrewAI, XAI's Grok, and Hyperbolic. It provides easy installation with support for different providers and offers features like text chat, voice chat, video chat, code generation interfaces, and AI agent teams. Users can set API keys for different providers and customize interfaces for specific tasks.
inspector
A developer tool for testing and debugging Model Context Protocol (MCP) servers. It allows users to test the compliance of their MCP servers with the latest MCP specs, supports various transports like STDIO, SSE, and Streamable HTTP, features an LLM Playground for testing server behavior against different models, provides comprehensive logging and error reporting for MCP server development, and offers a modern developer experience with multiple server connections and saved configurations. The tool is built using Next.js and integrates MCP capabilities, AI SDKs from OpenAI, Anthropic, and Ollama, and various technologies like Node.js, TypeScript, and Next.js.

wzry_ai
This is an open-source project for playing the game King of Glory with an artificial intelligence model. The first phase of the project has been completed, and future upgrades will be built upon this foundation. The second phase of the project has started, and progress is expected to proceed according to plan. For any questions, feel free to join the QQ exchange group: 687853827. The project aims to learn artificial intelligence and strictly prohibits cheating. Detailed installation instructions are available in the doc/README.md file. Environment installation video: (bilibili) Welcome to follow, like, tip, comment, and provide your suggestions.
mcp-context-forge
MCP Context Forge is a powerful tool for generating context-aware data for machine learning models. It provides functionalities to create diverse datasets with contextual information, enhancing the performance of AI algorithms. The tool supports various data formats and allows users to customize the context generation process easily. With MCP Context Forge, users can efficiently prepare training data for tasks requiring contextual understanding, such as sentiment analysis, recommendation systems, and natural language processing.
mcp-devtools
MCP DevTools is a high-performance server written in Go that replaces multiple Node.js and Python-based servers. It provides access to essential developer tools through a unified, modular interface. The server is efficient, with minimal memory footprint and fast response times. It offers a comprehensive tool suite for agentic coding, including 20+ essential developer agent tools. The tool registry allows for easy addition of new tools. The server supports multiple transport modes, including STDIO, HTTP, and SSE. It includes a security framework for multi-layered protection and a plugin system for adding new tools.
readme-ai
README-AI is a developer tool that auto-generates README.md files using a combination of data extraction and generative AI. It streamlines documentation creation and maintenance, enhancing developer productivity. This project aims to enable all skill levels, across all domains, to better understand, use, and contribute to open-source software. It offers flexible README generation, supports multiple large language models (LLMs), provides customizable output options, works with various programming languages and project types, and includes an offline mode for generating boilerplate README files without external API calls.
llama-api-server
This project aims to create a RESTful API server compatible with the OpenAI API using open-source backends like llama/llama2. With this project, various GPT tools/frameworks can be compatible with your own model. Key features include: - **Compatibility with OpenAI API**: The API server follows the OpenAI API structure, allowing seamless integration with existing tools and frameworks. - **Support for Multiple Backends**: The server supports both llama.cpp and pyllama backends, providing flexibility in model selection. - **Customization Options**: Users can configure model parameters such as temperature, top_p, and top_k to fine-tune the model's behavior. - **Batch Processing**: The API supports batch processing for embeddings, enabling efficient handling of multiple inputs. - **Token Authentication**: The server utilizes token authentication to secure access to the API. This tool is particularly useful for developers and researchers who want to integrate large language models into their applications or explore custom models without relying on proprietary APIs.
For similar tasks
chatgpt-adapter
ChatGPT-Adapter is an interface service that integrates various free services together. It provides a unified interface specification and integrates services like Bing, Claude-2, Gemini. Users can start the service by running the linux-server script and set proxies if needed. The tool offers model lists for different adapters, completion dialogues, authorization methods for different services like Claude, Bing, Gemini, Coze, and Lmsys. Additionally, it provides a free drawing interface with options like coze.dall-e-3, sd.dall-e-3, xl.dall-e-3, pg.dall-e-3 based on user-provided Authorization keys. The tool also supports special flags for enhanced functionality.
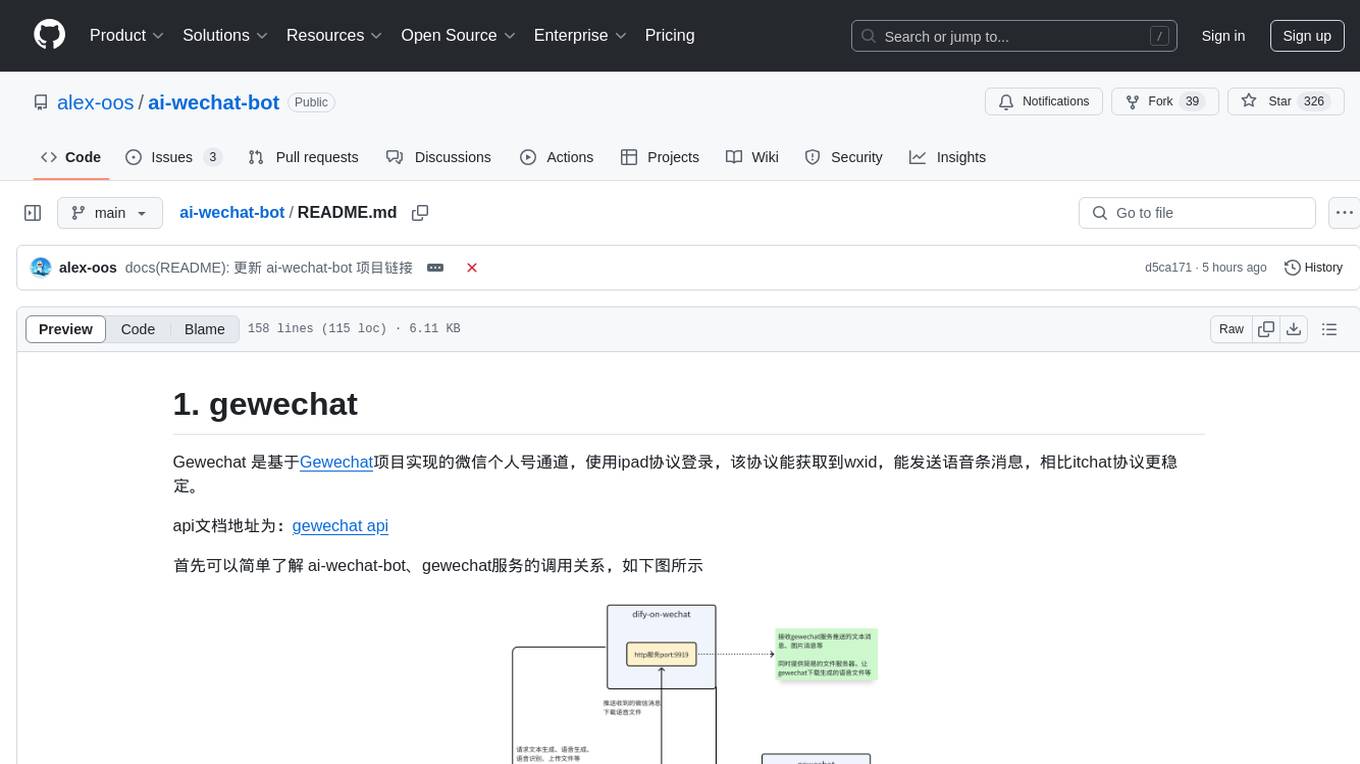
ai-wechat-bot
Gewechat is a project based on the Gewechat project to implement a personal WeChat channel, using the iPad protocol for login. It can obtain wxid and send voice messages, which is more stable than the itchat protocol. The project provides documentation for the API. Users can deploy the Gewechat service and use the ai-wechat-bot project to interface with it. Configuration parameters for Gewechat and ai-wechat-bot need to be set in the config.json file. Gewechat supports sending voice messages, with limitations on the duration of received voice messages. The project has restrictions such as requiring the server to be in the same province as the device logging into WeChat, limited file download support, and support only for text and image messages.
nosia
Nosia is a platform that allows users to run an AI model on their own data. It is designed to be easy to install and use. Users can follow the provided guides for quickstart, API usage, upgrading, starting, stopping, and troubleshooting. The platform supports custom installations with options for remote Ollama instances, custom completion models, and custom embeddings models. Advanced installation instructions are also available for macOS with a Debian or Ubuntu VM setup. Users can access the platform at 'https://nosia.localhost' and troubleshoot any issues by checking logs and job statuses.
xiaozhi-client
Xiaozhi Client is a tool that supports integration with Xiaozhi official servers, acts as a regular MCP Server integrated into various clients, allows configuration of multiple Xiaozhi access points for shared MCP configuration, aggregates multiple MCP Servers in a standard way, dynamically controls MCP Server tool visibility, supports local deployment of open-source server integration, provides web-based visual configuration allowing customization of IP and port, integrates ModelScope remote MCP services, creates Xiaozhi Client projects through templates, and supports running in the background.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.