
StarWhisper
StarWhisper:LLM for Astronomy
Stars: 280
StarWhisper is a multi-modal model repository developed under the support of the National Astronomical Observatory-Zhijiang Laboratory. It includes language models, temporal models, and multi-modal models ranging from 7B to 72B. The repository provides pre-trained models and technical reports for tasks such as pulsar identification, light curve classification, and telescope control. It aims to integrate astronomical knowledge using large models and explore the possibilities of solving specific astronomical problems through multi-modal approaches.
README:



在国家天文台-之江实验室的支持下,我们开发了StarWhisper4天文大模型系列,包括语言模型、时序模型、多模态模型(7B-72B)。
1.通过清洗订正科普、科研数据飞轮得到的数据,改进训练方法,进一步提升了模型的天文物理、代码与Agent能力,开源了星语3训练集于LLM_Data目录,开源了星语4多模态模型权重于魔搭平台。
2.发布了StarWhisper Pulsar的技术报告,一种SOTA的基于多模态大模型的脉冲星识别方法。
3.发布了StarWhisper LC的技术报告,基于迁移学习、大模型的光变曲线分类方法,上传了论文相关测试代码。

4.发布了StarWhisper Telescope的技术报告,一种基于大模型智能体的望远镜控制工作流,已应用于近邻星系巡天项目。


下面是一个使用StarWhisper4模型,进行多轮对话交互的样例:
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
from modelscope import snapshot_download
model_dir = snapshot_download("AstroYuYang/StarWhisper4")
# default: Load the model on the available device(s)
model = Qwen2VLForConditionalGeneration.from_pretrained(
model_dir, torch_dtype="auto", device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen2VLForConditionalGeneration.from_pretrained(
# model_dir,
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# default processer
processor = AutoProcessor.from_pretrained(model_dir)
# The default range for the number of visual tokens per image in the model is 4-16384. You can set min_pixels and max_pixels according to your needs, such as a token count range of 256-1280, to balance speed and memory usage.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained(model_dir, min_pixels=min_pixels, max_pixels=max_pixels)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)司天工程是我国天文学家面向时域天文学所提出的“十五五”天文重大基础设施,一期计划在国内多个优选观测台址布置54台(18组)口径1米级的大视场望远镜,组成多波段同时监测网络,每30分钟完成1万平方度天区的高精度三色“凝视”巡天。司天的采样频率比全球其它巡天项目高近两个量级,将突破目前探测时标的限制,在新的空域和时域下发现大批新天体、新现象,在宇宙极端高能爆发源、引力波电磁对应体、系外行星和太阳系天体等理论和观测研究中形成新的突破,在“两暗一黑三起源”等重大科学问题研究以及地球文明灾难预警等国家空间安全问题方面发挥重要作用。

其中司天"大脑"作为数据智能处理中枢,需要适配于天文的AI工具。StarWhisper作为其备选方案,在使用大模型整合天文知识的同时,探索多模态解决具体天文问题的可能性。
项目源码遵从Apache-2.0 license,Qwen1.5-14B Chat的模型权重使用需遵从相应许可。

- 调整监督微调中,通用数据和专业数据的比例,缓解灾难性遗忘问题。
- 通过人工反馈的强化学习,进一步提升模型性能。
- 通过特定数据集微调,提升模型总结能力,进一步适配知识库。
- 完成天文知识图谱,与模型链接,进一步降低天文领域的幻觉现象。
- 开源在多模态微调权重。
- 进一步探索多模态模型在天文图像生成与识别上应用的可能性。
- 提升模型在天文领域的编程能力。
- 在MiniSiTian/司天样机上,进行与天文环境交互的Agent探索工作。
- 考虑通过工具学习,链接天文专业工具。
- 尝试Agent相关工作,验证作为司天大脑备选方案的可行性。
如果这篇工作对你有帮助,请引用:
@misc{wang2024starwhispertelescopeagentbasedobservation,
title={StarWhisper Telescope: Agent-Based Observation Assistant System to Approach AI Astrophysicist},
author={Cunshi Wang and Xinjie Hu and Yu Zhang and Xunhao Chen and Pengliang Du and Yiming Mao and Rui Wang and Yuyang Li and Ying Wu and Hang Yang and Yansong Li and Beichuan Wang and Haiyang Mu and Zheng Wang and Jianfeng Tian and Liang Ge and Yongna Mao and Shengming Li and Xiaomeng Lu and Jinhang Zou and Yang Huang and Ningchen Sun and Jie Zheng and Min He and Yu Bai and Junjie Jin and Hong Wu and Chaohui Shang and Jifeng Liu},
year={2024},
eprint={2412.06412},
archivePrefix={arXiv},
primaryClass={astro-ph.IM},
url={https://arxiv.org/abs/2412.06412},
}For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for StarWhisper
Similar Open Source Tools
StarWhisper
StarWhisper is a multi-modal model repository developed under the support of the National Astronomical Observatory-Zhijiang Laboratory. It includes language models, temporal models, and multi-modal models ranging from 7B to 72B. The repository provides pre-trained models and technical reports for tasks such as pulsar identification, light curve classification, and telescope control. It aims to integrate astronomical knowledge using large models and explore the possibilities of solving specific astronomical problems through multi-modal approaches.

Janus
Janus is a series of unified multimodal understanding and generation models, including Janus-Pro, Janus, and JanusFlow. Janus-Pro is an advanced version that improves both multimodal understanding and visual generation significantly. Janus decouples visual encoding for unified multimodal understanding and generation, surpassing previous models. JanusFlow harmonizes autoregression and rectified flow for unified multimodal understanding and generation, achieving comparable or superior performance to specialized models. The models are available for download and usage, supporting a broad range of research in academic and commercial communities.

mLLMCelltype
mLLMCelltype is a multi-LLM consensus framework for automated cell type annotation in single-cell RNA sequencing (scRNA-seq) data. The tool integrates multiple large language models to improve annotation accuracy through consensus-based predictions. It offers advantages over single-model approaches by combining predictions from models like OpenAI GPT-5.2, Anthropic Claude-4.6/4.5, Google Gemini-3, and others. Researchers can incorporate mLLMCelltype into existing workflows without the need for reference datasets.

cellseg_models.pytorch
cellseg-models.pytorch is a Python library built upon PyTorch for 2D cell/nuclei instance segmentation models. It provides multi-task encoder-decoder architectures and post-processing methods for segmenting cell/nuclei instances. The library offers high-level API to define segmentation models, open-source datasets for training, flexibility to modify model components, sliding window inference, multi-GPU inference, benchmarking utilities, regularization techniques, and example notebooks for training and finetuning models with different backbones.
mlp-mixer-pytorch
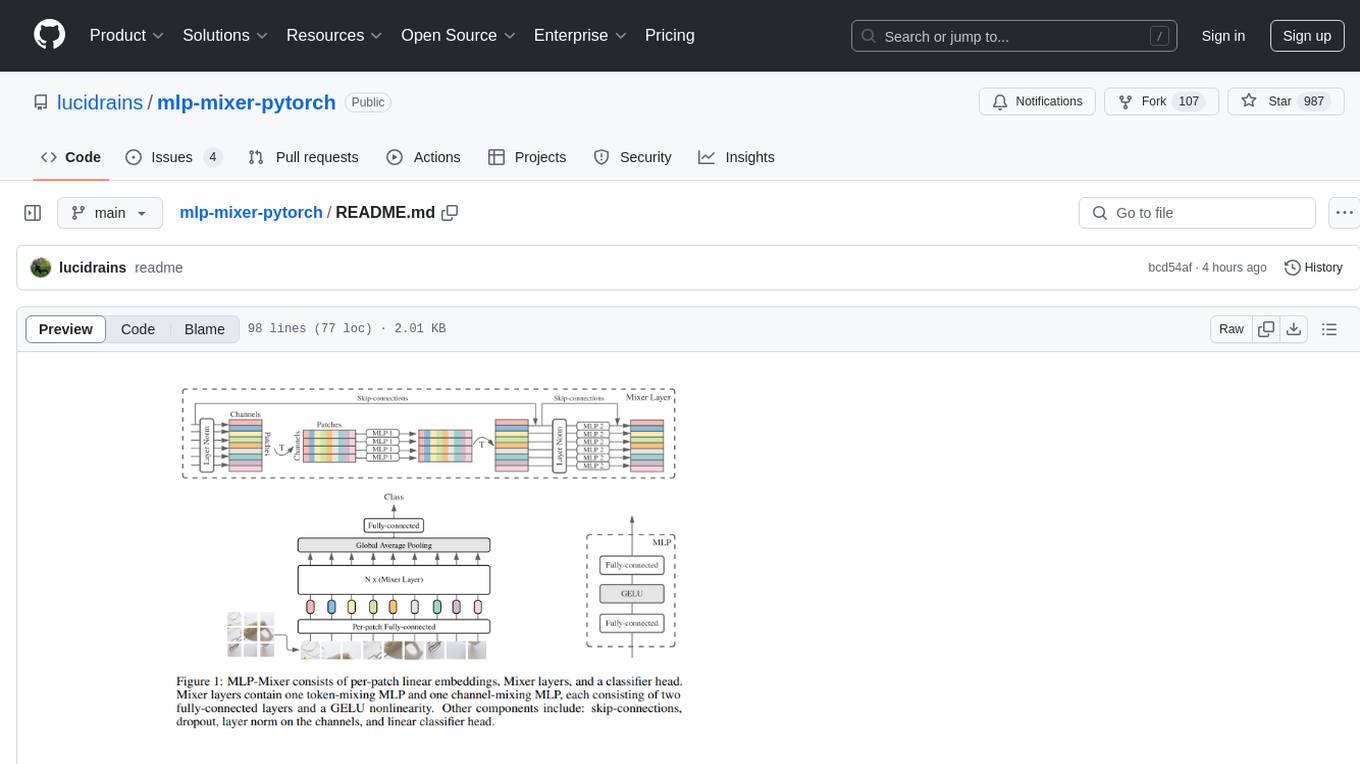
MLP Mixer - Pytorch is an all-MLP solution for vision tasks, developed by Google AI, implemented in Pytorch. It provides an architecture that does not require convolutions or attention mechanisms, offering an alternative approach for image and video processing. The tool is designed to handle tasks related to image classification and video recognition, utilizing multi-layer perceptrons (MLPs) for feature extraction and classification. Users can easily install the tool using pip and integrate it into their Pytorch projects to experiment with MLP-based vision models.
ChatPDF
ChatPDF is a knowledge question and answer retrieval tool based on local LLM. It supports various open-source LLM models like ChatGLM3-6b, Chinese-LLaMA-Alpaca-2, Baichuan, YI, and multiple file formats including PDF, docx, markdown, txt. The tool optimizes RAG accuracy, Chinese chunk segmentation, embedding using text2vec's sentence embedding, retrieval matching with rank_BM25, and introduces reranker module for reranking candidate sets. It also enhances candidate chunk extension context, supports custom RAG models, and provides a Gradio-based RAG conversation page for seamless dialogue.
Torch-Pruning
Torch-Pruning (TP) is a library for structural pruning that enables pruning for a wide range of deep neural networks. It uses an algorithm called DepGraph to physically remove parameters. The library supports pruning off-the-shelf models from various frameworks and provides benchmarks for reproducing results. It offers high-level pruners, dependency graph for automatic pruning, low-level pruning functions, and supports various importance criteria and modules. Torch-Pruning is compatible with both PyTorch 1.x and 2.x versions.
zenu
ZeNu is a high-performance deep learning framework implemented in pure Rust, featuring a pure Rust implementation for safety and performance, GPU performance comparable to PyTorch with CUDA support, a simple and intuitive API, and a modular design for easy extension. It supports various layers like Linear, Convolution 2D, LSTM, and optimizers such as SGD and Adam. ZeNu also provides device support for CPU and CUDA (NVIDIA GPU) with CUDA 12.3 and cuDNN 9. The project structure includes main library, automatic differentiation engine, neural network layers, matrix operations, optimization algorithms, CUDA implementation, and other support crates. Users can find detailed implementations like MNIST classification, CIFAR10 classification, and ResNet implementation in the examples directory. Contributions to ZeNu are welcome under the MIT License.
langchain-rust
LangChain Rust is a library for building applications with Large Language Models (LLMs) through composability. It provides a set of tools and components that can be used to create conversational agents, document loaders, and other applications that leverage LLMs. LangChain Rust supports a variety of LLMs, including OpenAI, Azure OpenAI, Ollama, and Anthropic Claude. It also supports a variety of embeddings, vector stores, and document loaders. LangChain Rust is designed to be easy to use and extensible, making it a great choice for developers who want to build applications with LLMs.

wenxin-starter
WenXin-Starter is a spring-boot-starter for Baidu's "Wenxin Qianfan WENXINWORKSHOP" large model, which can help you quickly access Baidu's AI capabilities. It fully integrates the official API documentation of Wenxin Qianfan. Supports text-to-image generation, built-in dialogue memory, and supports streaming return of dialogue. Supports QPS control of a single model and supports queuing mechanism. Plugins will be added soon.
freeGPT
freeGPT provides free access to text and image generation models. It supports various models, including gpt3, gpt4, alpaca_7b, falcon_40b, prodia, and pollinations. The tool offers both asynchronous and non-asynchronous interfaces for text completion and image generation. It also features an interactive Discord bot that provides access to all the models in the repository. The tool is easy to use and can be integrated into various applications.

evalplus
EvalPlus is a rigorous evaluation framework for LLM4Code, providing HumanEval+ and MBPP+ tests to evaluate large language models on code generation tasks. It offers precise evaluation and ranking, coding rigorousness analysis, and pre-generated code samples. Users can use EvalPlus to generate code solutions, post-process code, and evaluate code quality. The tool includes tools for code generation and test input generation using various backends.
pixeltable
Pixeltable is a Python library designed for ML Engineers and Data Scientists to focus on exploration, modeling, and app development without the need to handle data plumbing. It provides a declarative interface for working with text, images, embeddings, and video, enabling users to store, transform, index, and iterate on data within a single table interface. Pixeltable is persistent, acting as a database unlike in-memory Python libraries such as Pandas. It offers features like data storage and versioning, combined data and model lineage, indexing, orchestration of multimodal workloads, incremental updates, and automatic production-ready code generation. The tool emphasizes transparency, reproducibility, cost-saving through incremental data changes, and seamless integration with existing Python code and libraries.
x
Ant Design X is a tool for crafting AI-driven interfaces effortlessly. It is built on the best practices of enterprise-level AI products, offering flexible and diverse atomic components for various AI dialogue scenarios. The tool provides out-of-the-box model integration with inference services compatible with OpenAI standards. It also enables efficient management of conversation data flows, supports rich template options, complete TypeScript support, and advanced theme customization. Ant Design X is designed to enhance development efficiency and deliver exceptional AI interaction experiences.
libllm
libLLM is an open-source project designed for efficient inference of large language models (LLM) on personal computers and mobile devices. It is optimized to run smoothly on common devices, written in C++14 without external dependencies, and supports CUDA for accelerated inference. Users can build the tool for CPU only or with CUDA support, and run libLLM from the command line. Additionally, there are API examples available for Python and the tool can export Huggingface models.
netsaur
Netsaur is a powerful machine learning library for Deno, offering a lightweight and easy-to-use neural network solution. It is blazingly fast and efficient, providing a simple API for creating and training neural networks. Netsaur can run on both CPU and GPU, making it suitable for serverless environments. With Netsaur, users can quickly build and deploy machine learning models for various applications with minimal dependencies. This library is perfect for both beginners and experienced machine learning practitioners.
For similar tasks
StarWhisper
StarWhisper is a multi-modal model repository developed under the support of the National Astronomical Observatory-Zhijiang Laboratory. It includes language models, temporal models, and multi-modal models ranging from 7B to 72B. The repository provides pre-trained models and technical reports for tasks such as pulsar identification, light curve classification, and telescope control. It aims to integrate astronomical knowledge using large models and explore the possibilities of solving specific astronomical problems through multi-modal approaches.
For similar jobs
StarWhisper
StarWhisper is a multi-modal model repository developed under the support of the National Astronomical Observatory-Zhijiang Laboratory. It includes language models, temporal models, and multi-modal models ranging from 7B to 72B. The repository provides pre-trained models and technical reports for tasks such as pulsar identification, light curve classification, and telescope control. It aims to integrate astronomical knowledge using large models and explore the possibilities of solving specific astronomical problems through multi-modal approaches.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.