Best AI tools for< Serve Llm >
20 - AI tool Sites
Empower
Empower is a serverless fine-tuned LLM hosting platform that offers a developer platform for fine-tuned LLMs, providing GPT4 level response quality at a fraction of the cost. It offers prebuilt task-specific base models, cost-effective serving with no compromise on performance, and flexible deployment options. Empower allows users to own their models, ensures no cold start, and charges on a per-token basis. The platform is designed to empower users to deploy and serve their fine-tuned LLMs effortlessly.
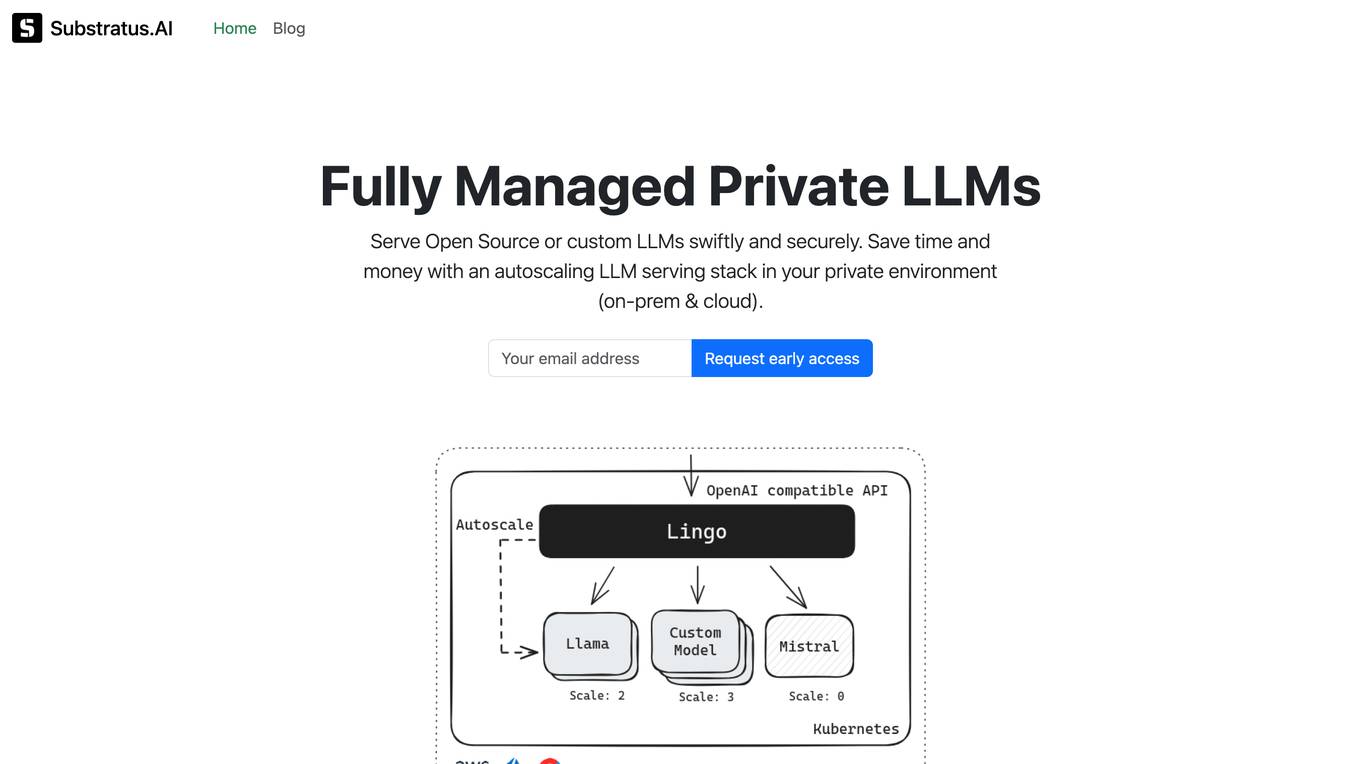
Substratus.AI
Substratus.AI is a fully managed private LLMs platform that allows users to serve LLMs (Llama and Mistral) in their own cloud account. It enables users to keep control of their data while reducing OpenAI costs by up to 10x. With Substratus.AI, users can utilize LLMs in production in hours instead of weeks, making it a convenient and efficient solution for AI model deployment.
Predibase
Predibase is a platform for fine-tuning and serving Large Language Models (LLMs). It provides a cost-effective and efficient way to train and deploy LLMs for a variety of tasks, including classification, information extraction, customer sentiment analysis, customer support, code generation, and named entity recognition. Predibase is built on proven open-source technology, including LoRAX, Ludwig, and Horovod.

vLLM
vLLM is a fast and easy-to-use library for LLM inference and serving. It offers state-of-the-art serving throughput, efficient management of attention key and value memory, continuous batching of incoming requests, fast model execution with CUDA/HIP graph, and various decoding algorithms. The tool is flexible with seamless integration with popular HuggingFace models, high-throughput serving, tensor parallelism support, and streaming outputs. It supports NVIDIA GPUs and AMD GPUs, Prefix caching, and Multi-lora. vLLM is designed to provide fast and efficient LLM serving for everyone.
LanguageGUI
LanguageGUI is an open-source design system and UI Kit for giving LLMs the flexibility of formatting text outputs into richer graphical user interfaces. It includes dozens of unique UI elements that serve different use cases for rich conversational user interfaces, such as 100+ UI components & customizable screens, 10+ conversational UI widgets, 20+ chat bubbles, 30+ pre-built screens to kickoff your design, 5+ chat sidebars with customizable settings, multi-prompt workflow screen designs, 8+ prompt boxes, and dark mode. LanguageGUI is designed with variables and styles, designed with Figma Auto Layout, and is free to use for both personal and commercial projects without required attribution.
LangChain
LangChain is an AI tool that offers a suite of products supporting developers in the LLM application lifecycle. It provides a framework to construct LLM-powered apps easily, visibility into app performance, and a turnkey solution for serving APIs. LangChain enables developers to build context-aware, reasoning applications and future-proof their applications by incorporating vendor optionality. LangSmith, a part of LangChain, helps teams improve accuracy and performance, iterate faster, and ship new AI features efficiently. The tool is designed to drive operational efficiency, increase discovery & personalization, and deliver premium products that generate revenue.
Anyscale
Anyscale is a company that provides a scalable compute platform for AI and Python applications. Their platform includes a serverless API for serving and fine-tuning open LLMs, a private cloud solution for data privacy and governance, and an open source framework for training, batch, and real-time workloads. Anyscale's platform is used by companies such as OpenAI, Uber, and Spotify to power their AI workloads.
WooKeys AI
WooKeys AI is an all-in-one platform for generating AI content. It offers a wide range of features, including text, image, code, video, audio, and music generation. WooKeys AI also provides an advanced dashboard for LLM observability, user management, credits monitoring, and tracing. Additionally, it offers project management capabilities, including project creation, team collaboration, and Kanban tracking. WooKeys AI supports multiple languages and allows users to create custom prompt templates. It also enables easy sharing of generated content in various formats and on different channels. WooKeys AI is designed to serve a wide range of users, including businesses, marketers, writers, and developers.
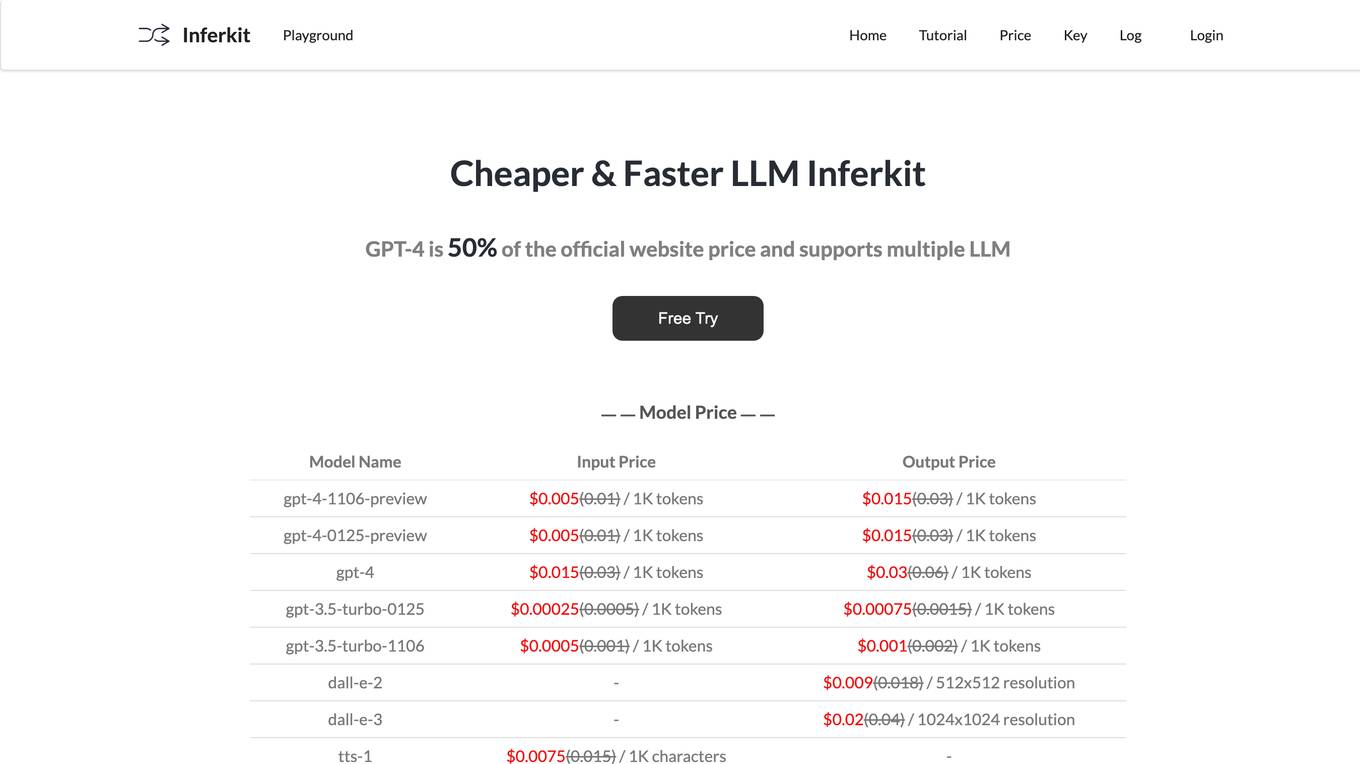
Inferkit AI
Inferkit AI is an AI tool that offers a cheaper and faster LLM router. It provides users with the ability to generate text content efficiently and cost-effectively. The tool is designed to assist users in creating various types of written content, such as articles, stories, and more, by leveraging advanced language models. Inferkit AI aims to streamline the content creation process and enhance productivity for individuals and businesses alike.
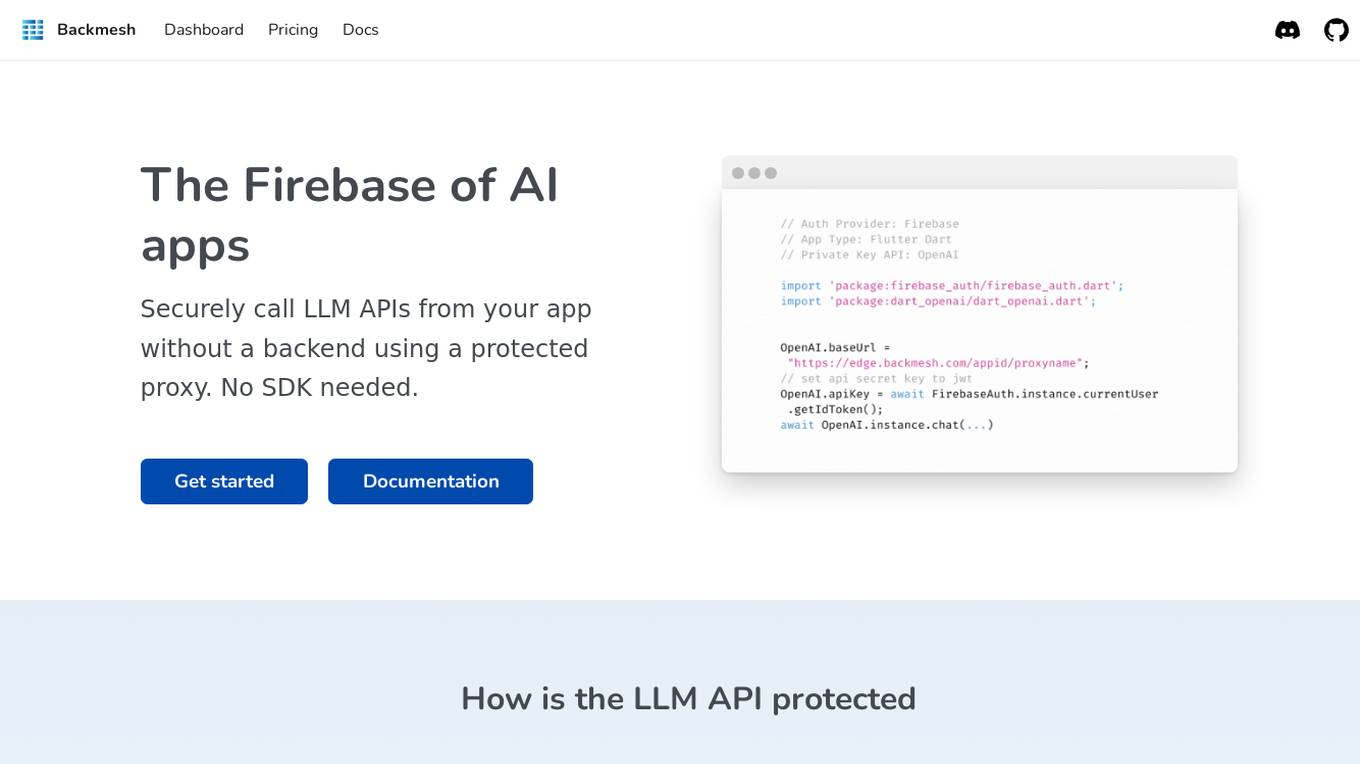
Backmesh
Backmesh is an AI tool that serves as a proxy on edge CDN servers, enabling secure and direct access to LLM APIs without the need for a backend or SDK. It allows users to call LLM APIs from their apps, ensuring protection through JWT verification and rate limits. Backmesh also offers user analytics for LLM API calls, helping identify usage patterns and enhance user satisfaction within AI applications.
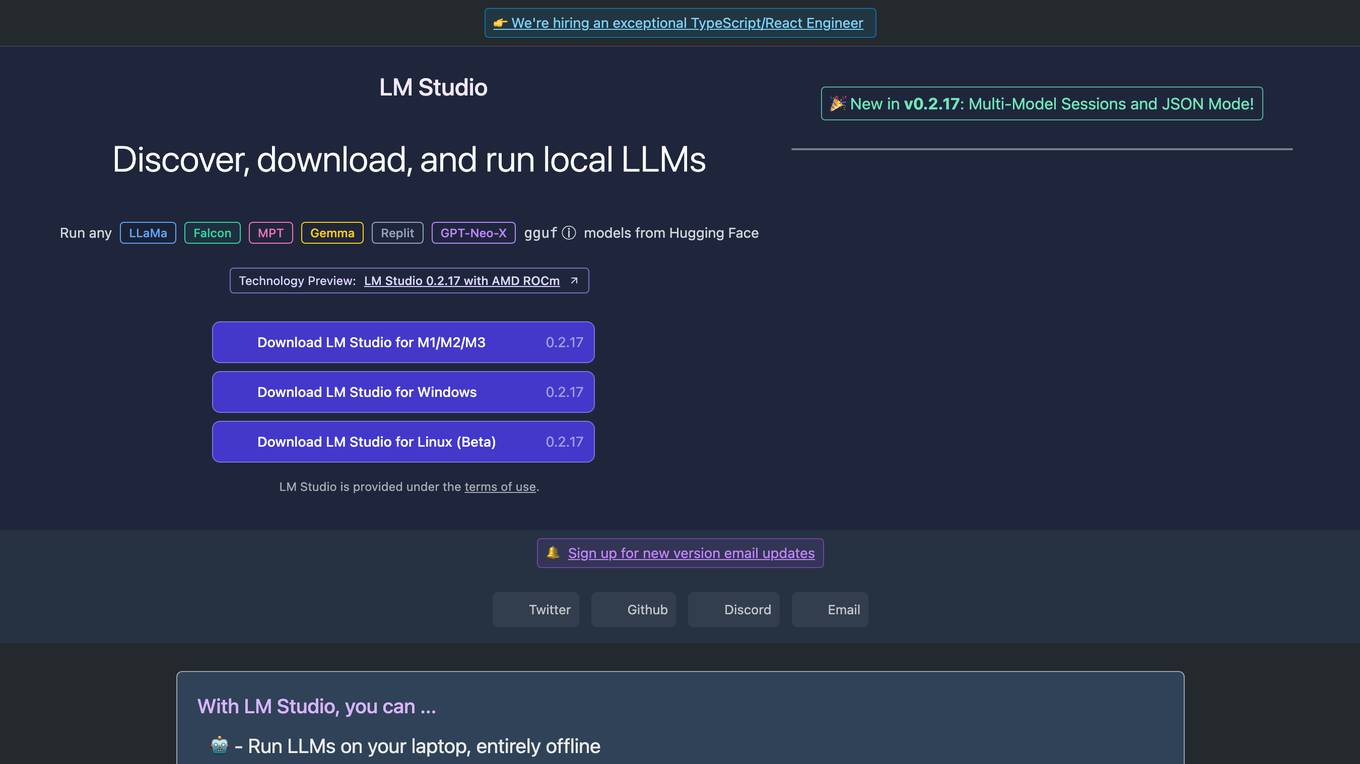
LM Studio
LM Studio is an AI tool designed for discovering, downloading, and running local LLMs (Large Language Models). Users can run LLMs on their laptops offline, use models through an in-app Chat UI or a local server, download compatible model files from HuggingFace repositories, and discover new LLMs. The tool ensures privacy by not collecting data or monitoring user actions, making it suitable for personal and business use. LM Studio supports various models like ggml Llama, MPT, and StarCoder on Hugging Face, with minimum hardware/software requirements specified for different platforms.
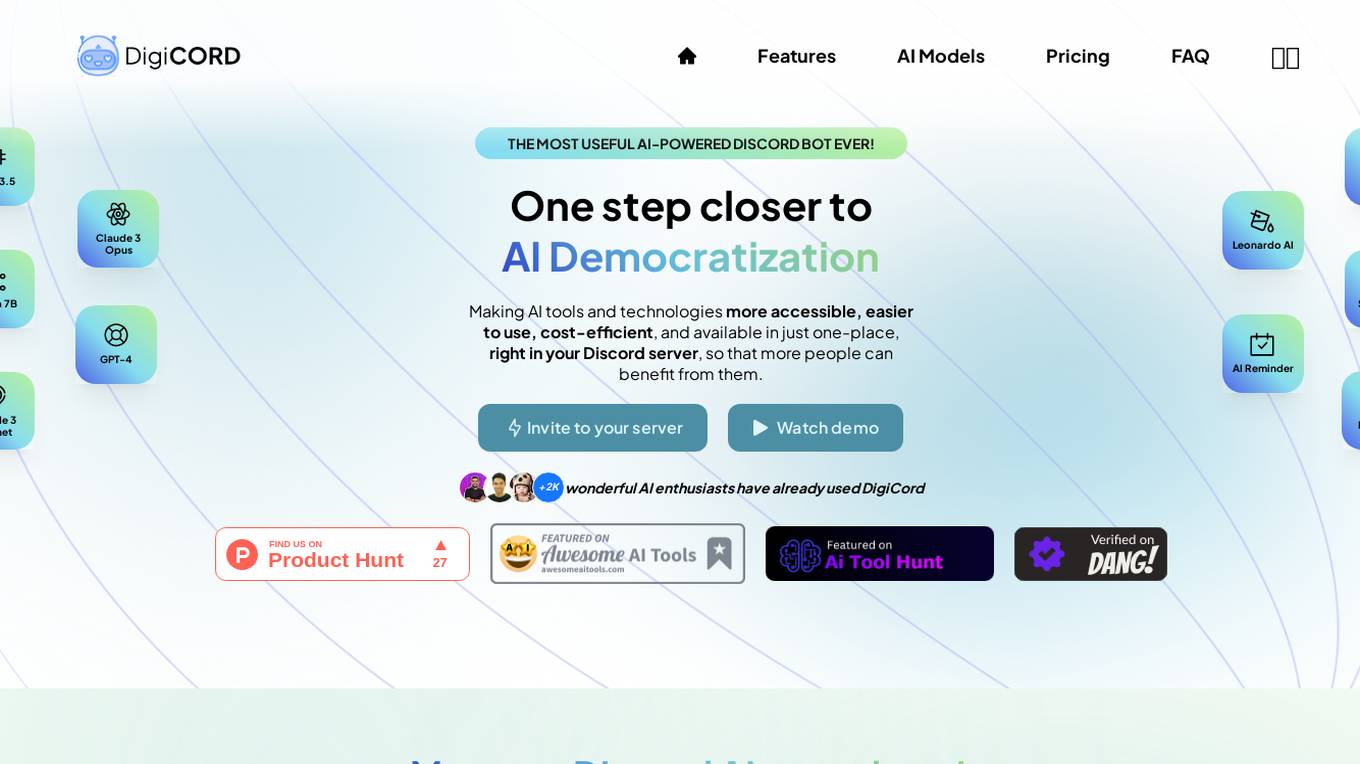
DigiCord
DigiCord is an AI-powered Discord bot that provides access to a wide range of large language models (LLMs) such as GPT-3.5, GPT-4, Claude, and more. It allows users to converse with AI, generate content, analyze images and data, and perform various tasks, all within the Discord server environment. DigiCord aims to democratize AI tools and technologies, making them more accessible, cost-efficient, and user-friendly for a diverse range of users, from students and digital artists to software engineers and entrepreneurs.
prompter.engineer
prompter.engineer is a domain that is currently parked for free, courtesy of GoDaddy.com. The website does not provide any specific content or services at the moment, as it is not associated with any particular company, product, or service. It primarily serves as a placeholder domain registered with GoDaddy, LLC, and does not imply any endorsement or association with third-party advertisers.

N/A
The website seems to be experiencing technical difficulties as indicated by the error message '502 Bad Gateway'. This error typically occurs when a server acting as a gateway or proxy receives an invalid response from an upstream server. The message 'openresty' suggests that the server may be using the OpenResty web platform. Users encountering a 502 Bad Gateway error may need to wait for the issue to be resolved by the website's administrators or try accessing the site at a later time.

Allganize Japan Blog
Allganize Japan Blog is an AI tool that provides information and updates about Allganize, a company offering AI solutions for enterprises. The blog covers topics such as AI applications, events, partnerships, and technical explanations related to AI technologies like LLM (Large Language Model). It serves as a platform to showcase the company's products, services, and industry insights.

chatQR.ai
chatQR.ai is an AI-powered ordering application that serves as a complete Point Of Sale/Kiosk replacement. It utilizes voice recognition technology combined with the latest Large Language Model (LLM) AI to create a seamless QR code ordering experience for customers. The system is designed to be AI-first, offering mature point of sale features and the ability to integrate the ChatQR Voice Assistant into existing systems. With support for multiple currencies and payment providers like Stripe and Square, chatQR.ai aims to revolutionize the way businesses manage orders and payments.

LiteLLM
LiteLLM is an AI tool that offers a Unified API for Azure OpenAI Vertex AI Bedrock. It provides a proxy server to manage authentication, load balancing, and spend tracking across various LLMs. LiteLLM supports integration with over 100 LLM providers and offers features such as virtual keys, budgets, teams, load balancing, RPM/TPM limits, Prometheus metrics, JWT authentication, single sign-on (SSO), and audit logs. The tool is available for both cloud deployment and self-hosted solutions, with different pricing tiers to cater to various enterprise needs. LiteLLM aims to simplify the process of working with AI technologies and streamline the management of AI resources.
ad:personam
ad:personam is an AI-powered Self Serve DSP platform for programmatic advertising, designed to empower businesses of any size to thrive in the programmatic advertising space. It offers a comprehensive suite of programmatic advertising solutions, cutting-edge AI-driven insights and planning tools, and transparent pricing. With features like multi-format ad uploads, cookieless targeting, and in-depth reporting, ad:personam aims to simplify programmatic advertising with AI efficiency and effectiveness.
BoldDesk
BoldDesk by Syncfusion is a comprehensive customer service software designed to effortlessly resolve 70% of customer inquiries through its all-in-one platform. It offers features such as ticketing system, live chat support, omnichannel inbox, knowledge base, task management, and AI Copilot for reducing support volume and increasing efficiency with Generative AI and automations. The software also provides workflow automation, contact management, customization options, reports & analytics, mobile app support, customer portal, apps & integrations, and satisfaction survey (CSAT). BoldDesk caters to startups, small businesses, and enterprises, offering solutions for email ticketing, shared inbox software, multi-brand help desk, internal help desk software, trouble ticketing software, and embedded help widgets.
Seldon
Seldon is an MLOps platform that helps enterprises deploy, monitor, and manage machine learning models at scale. It provides a range of features to help organizations accelerate model deployment, optimize infrastructure resource allocation, and manage models and risk. Seldon is trusted by the world's leading MLOps teams and has been used to install and manage over 10 million ML models. With Seldon, organizations can reduce deployment time from months to minutes, increase efficiency, and reduce infrastructure and cloud costs.
20 - Open Source AI Tools
llm-engine
Scale's LLM Engine is an open-source Python library, CLI, and Helm chart that provides everything you need to serve and fine-tune foundation models, whether you use Scale's hosted infrastructure or do it in your own cloud infrastructure using Kubernetes.

ray-llm
RayLLM (formerly known as Aviary) is an LLM serving solution that makes it easy to deploy and manage a variety of open source LLMs, built on Ray Serve. It provides an extensive suite of pre-configured open source LLMs, with defaults that work out of the box. RayLLM supports Transformer models hosted on Hugging Face Hub or present on local disk. It simplifies the deployment of multiple LLMs, the addition of new LLMs, and offers unique autoscaling support, including scale-to-zero. RayLLM fully supports multi-GPU & multi-node model deployments and offers high performance features like continuous batching, quantization and streaming. It provides a REST API that is similar to OpenAI's to make it easy to migrate and cross test them. RayLLM supports multiple LLM backends out of the box, including vLLM and TensorRT-LLM.
TensorRT-LLM
TensorRT-LLM is an easy-to-use Python API to define Large Language Models (LLMs) and build TensorRT engines that contain state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorRT-LLM contains components to create Python and C++ runtimes that execute those TensorRT engines. It also includes a backend for integration with the NVIDIA Triton Inference Server; a production-quality system to serve LLMs. Models built with TensorRT-LLM can be executed on a wide range of configurations going from a single GPU to multiple nodes with multiple GPUs (using Tensor Parallelism and/or Pipeline Parallelism).
ParrotServe
Parrot is a distributed serving system for LLM-based Applications, designed to efficiently serve LLM-based applications by adding Semantic Variable in the OpenAI-style API. It allows for horizontal scalability with multiple Engine instances running LLM models communicating with ServeCore. The system enables AI agents to interact with LLMs via natural language prompts for collaborative tasks.

OpenLLM
OpenLLM is a platform that helps developers run any open-source Large Language Models (LLMs) as OpenAI-compatible API endpoints, locally and in the cloud. It supports a wide range of LLMs, provides state-of-the-art serving and inference performance, and simplifies cloud deployment via BentoML. Users can fine-tune, serve, deploy, and monitor any LLMs with ease using OpenLLM. The platform also supports various quantization techniques, serving fine-tuning layers, and multiple runtime implementations. OpenLLM seamlessly integrates with other tools like OpenAI Compatible Endpoints, LlamaIndex, LangChain, and Transformers Agents. It offers deployment options through Docker containers, BentoCloud, and provides a community for collaboration and contributions.
llm-applications
A comprehensive guide to building Retrieval Augmented Generation (RAG)-based LLM applications for production. This guide covers developing a RAG-based LLM application from scratch, scaling the major components, evaluating different configurations, implementing LLM hybrid routing, serving the application in a highly scalable and available manner, and sharing the impacts LLM applications have had on products.

llm-on-ray
LLM-on-Ray is a comprehensive solution for building, customizing, and deploying Large Language Models (LLMs). It simplifies complex processes into manageable steps by leveraging the power of Ray for distributed computing. The tool supports pretraining, finetuning, and serving LLMs across various hardware setups, incorporating industry and Intel optimizations for performance. It offers modular workflows with intuitive configurations, robust fault tolerance, and scalability. Additionally, it provides an Interactive Web UI for enhanced usability, including a chatbot application for testing and refining models.

jina
Jina is a tool that allows users to build multimodal AI services and pipelines using cloud-native technologies. It provides a Pythonic experience for serving ML models and transitioning from local deployment to advanced orchestration frameworks like Docker-Compose, Kubernetes, or Jina AI Cloud. Users can build and serve models for any data type and deep learning framework, design high-performance services with easy scaling, serve LLM models while streaming their output, integrate with Docker containers via Executor Hub, and host on CPU/GPU using Jina AI Cloud. Jina also offers advanced orchestration and scaling capabilities, a smooth transition to the cloud, and easy scalability and concurrency features for applications. Users can deploy to their own cloud or system with Kubernetes and Docker Compose integration, and even deploy to JCloud for autoscaling and monitoring.

skypilot
SkyPilot is a framework for running LLMs, AI, and batch jobs on any cloud, offering maximum cost savings, highest GPU availability, and managed execution. SkyPilot abstracts away cloud infra burdens: - Launch jobs & clusters on any cloud - Easy scale-out: queue and run many jobs, automatically managed - Easy access to object stores (S3, GCS, R2) SkyPilot maximizes GPU availability for your jobs: * Provision in all zones/regions/clouds you have access to (the _Sky_), with automatic failover SkyPilot cuts your cloud costs: * Managed Spot: 3-6x cost savings using spot VMs, with auto-recovery from preemptions * Optimizer: 2x cost savings by auto-picking the cheapest VM/zone/region/cloud * Autostop: hands-free cleanup of idle clusters SkyPilot supports your existing GPU, TPU, and CPU workloads, with no code changes.

LitServe
LitServe is a high-throughput serving engine designed for deploying AI models at scale. It generates an API endpoint for models, handles batching, streaming, and autoscaling across CPU/GPUs. LitServe is built for enterprise scale with a focus on minimal, hackable code-base without bloat. It supports various model types like LLMs, vision, time-series, and works with frameworks like PyTorch, JAX, Tensorflow, and more. The tool allows users to focus on model performance rather than serving boilerplate, providing full control and flexibility.
resonance
Resonance is a framework designed to facilitate interoperability and messaging between services in your infrastructure and beyond. It provides AI capabilities and takes full advantage of asynchronous PHP, built on top of Swoole. With Resonance, you can: * Chat with Open-Source LLMs: Create prompt controllers to directly answer user's prompts. LLM takes care of determining user's intention, so you can focus on taking appropriate action. * Asynchronous Where it Matters: Respond asynchronously to incoming RPC or WebSocket messages (or both combined) with little overhead. You can set up all the asynchronous features using attributes. No elaborate configuration is needed. * Simple Things Remain Simple: Writing HTTP controllers is similar to how it's done in the synchronous code. Controllers have new exciting features that take advantage of the asynchronous environment. * Consistency is Key: You can keep the same approach to writing software no matter the size of your project. There are no growing central configuration files or service dependencies registries. Every relation between code modules is local to those modules. * Promises in PHP: Resonance provides a partial implementation of Promise/A+ spec to handle various asynchronous tasks. * GraphQL Out of the Box: You can build elaborate GraphQL schemas by using just the PHP attributes. Resonance takes care of reusing SQL queries and optimizing the resources' usage. All fields can be resolved asynchronously.
LLMSys-PaperList
This repository provides a comprehensive list of academic papers, articles, tutorials, slides, and projects related to Large Language Model (LLM) systems. It covers various aspects of LLM research, including pre-training, serving, system efficiency optimization, multi-model systems, image generation systems, LLM applications in systems, ML systems, survey papers, LLM benchmarks and leaderboards, and other relevant resources. The repository is regularly updated to include the latest developments in this rapidly evolving field, making it a valuable resource for researchers, practitioners, and anyone interested in staying abreast of the advancements in LLM technology.

llm-on-openshift
This repository provides resources, demos, and recipes for working with Large Language Models (LLMs) on OpenShift using OpenShift AI or Open Data Hub. It includes instructions for deploying inference servers for LLMs, such as vLLM, Hugging Face TGI, Caikit-TGIS-Serving, and Ollama. Additionally, it offers guidance on deploying serving runtimes, such as vLLM Serving Runtime and Hugging Face Text Generation Inference, in the Single-Model Serving stack of Open Data Hub or OpenShift AI. The repository also covers vector databases that can be used as a Vector Store for Retrieval Augmented Generation (RAG) applications, including Milvus, PostgreSQL+pgvector, and Redis. Furthermore, it provides examples of inference and application usage, such as Caikit, Langchain, Langflow, and UI examples.

candle-vllm
Candle-vllm is an efficient and easy-to-use platform designed for inference and serving local LLMs, featuring an OpenAI compatible API server. It offers a highly extensible trait-based system for rapid implementation of new module pipelines, streaming support in generation, efficient management of key-value cache with PagedAttention, and continuous batching. The tool supports chat serving for various models and provides a seamless experience for users to interact with LLMs through different interfaces.
tensorrtllm_backend
The TensorRT-LLM Backend is a Triton backend designed to serve TensorRT-LLM models with Triton Inference Server. It supports features like inflight batching, paged attention, and more. Users can access the backend through pre-built Docker containers or build it using scripts provided in the repository. The backend can be used to create models for tasks like tokenizing, inferencing, de-tokenizing, ensemble modeling, and more. Users can interact with the backend using provided client scripts and query the server for metrics related to request handling, memory usage, KV cache blocks, and more. Testing for the backend can be done following the instructions in the 'ci/README.md' file.
llm-twin-course
The LLM Twin Course is a free, end-to-end framework for building production-ready LLM systems. It teaches you how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices. The course is split into 11 hands-on written lessons and the open-source code you can access on GitHub. You can read everything and try out the code at your own pace.
20 - OpenAI Gpts
Create A Business Model Canvas For Your Business
Let's get started by telling me about your business: What do you offer? Who do you serve? ------------------------------------------------------- Need help Prompt Engineering? Reach out on LinkedIn: StephenHnilica
Il King del Fantacalcio - Esperto di Serie A
Analisi dettagliate e statistiche per il fantacalcio. Strategie, formazioni vincenti, e suggerimenti di mercato per la Serie A. Perfetto per chi cerca il podio nel proprio campionato. Aggiornamenti continui sui giocatori, performance e infortuni. Tutto quello che serve per la tua squadra ideale


Buildwell AI - UK Construction Regs Assistant
Provides Construction Support relating to Planning Permission, Building Regulations, Party Wall Act and Fire Safety in the UK. Obtain instant Guidance for your Construction Project.
World Animals Flight Attendant Uniform
Enjoy the world of anthropomorphic animals and enjoy a banquet in flight attendant uniforms
SQL Server assistant
Expert in SQL Server for database management, optimization, and troubleshooting.
Baci's AI Server
An AI waiter for Baci Bistro & Bar, knowledgeable about the menu and ready to assist.
Software expert
Server admin expert in cPanel, Softaculous, WHM, WordPress, and Elementor Pro.
アダチさん13号(SQLServer篇)
安達孝一さんがSE時代に蓄積してきた、SQL Serverのナレッジやノウハウ等 (SQL Server 2000/2005/2008/2012) について、ご質問頂けます。また、対話内容を基に、ChatGPT(GPT-4)向けの、汎用的な質問文例も作成できます。





CraftGPT
Your expert Minecraft server Java plugin assistant. Whether you're learning the ropes or are an experienced developer, I'm here to help you with Java concepts, coding examples, and any queries you have about Minecraft plugin development.
Gourmet GPT
As a high-class server, I describe dishes with luxury and elegance. Just upload your picture!

Bun Nook Kit App Builder
Expert in BNK server setup, typesafe routes, htmlody, and creating SQLite schemas with BNK.