Best AI tools for< Evaluate Valuations >
20 - AI tool Sites
Eilla
Eilla is an AI platform designed to streamline the workflow for Venture Capital (VC), Private Equity (PE), and Mergers & Acquisitions (M&A) professionals. It offers AI Analysts that support human experts in various tasks such as company research, valuation, market research, and scouting. Eilla's AI Analysts provide in-depth insights, identify competitors, valuation drivers, potential buyers, and more, helping users make informed decisions throughout the deal process. The platform is tailored for VC, PE, and M&A professionals, integrating seamlessly into their workflow to enhance productivity and efficiency.

Appraiser.AI
Appraiser.AI is an AI-powered appraisal tool designed to help users accurately assess the value of a wide range of collectibles and antiques. By leveraging advanced algorithms and data analysis, the tool provides users with instant appraisals for items such as vintage coins, jewelry, artwork, vinyl records, trading cards, and more. With a user-friendly interface, Appraiser.AI offers a convenient and reliable solution for individuals looking to determine the worth of their possessions quickly and efficiently.
AnalyStock.ai
AnalyStock.ai is a financial application leveraging AI to provide users with a next-generation investment toolbox. It helps users better understand businesses, risks, and make informed investment decisions. The platform offers direct access to the stock market, powerful data-driven tools to build top-ranking portfolios, and insights into company valuations and growth prospects. AnalyStock.ai aims to optimize the investment process, offering a reliable strategy with factors like A-Score, factor investing scores for value, growth, quality, volatility, momentum, and yield. Users can discover hidden gems, fine-tune filters, access company scorecards, perform activity analysis, understand industry dynamics, evaluate capital structure, profitability, and peers' valuation. The application also provides adjustable DCF valuation, portfolio management tools, net asset value computation, monthly commentary, and an AI assistant for personalized insights and assistance.
ZestyAI
ZestyAI is an artificial intelligence tool that helps users make brilliant climate and property risk decisions. The tool uses AI to provide insights on property values and risk exposure to natural disasters. It offers products such as Property Insights, Digital Roof, Roof Age, Location Insights, and Climate Risk Models to evaluate and understand property risks. ZestyAI is trusted by top insurers in North America and aims to bring a ten times return on investment to its customers.
Inspect
Inspect is an open-source framework for large language model evaluations created by the UK AI Safety Institute. It provides built-in components for prompt engineering, tool usage, multi-turn dialog, and model graded evaluations. Users can explore various solvers, tools, scorers, datasets, and models to create advanced evaluations. Inspect supports extensions for new elicitation and scoring techniques through Python packages.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.
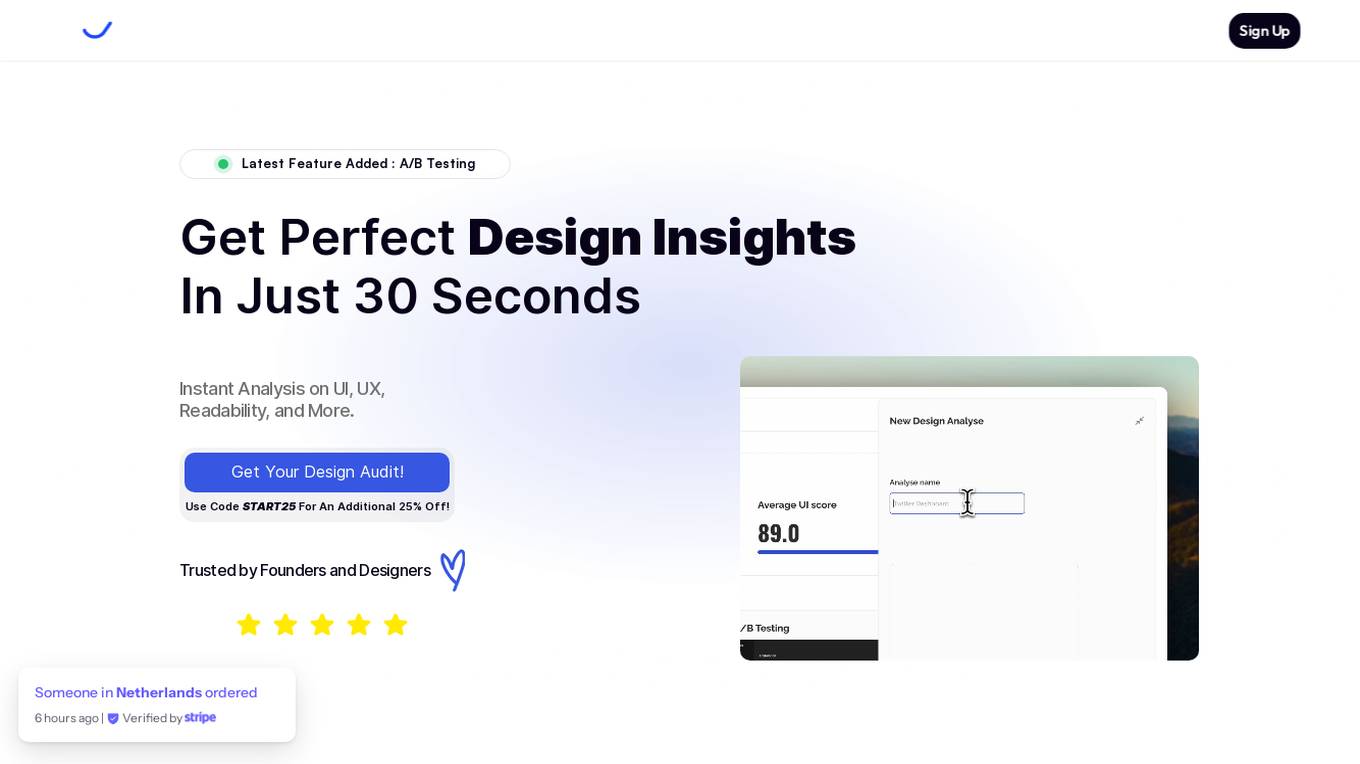
VisualHUB
VisualHUB is an AI-powered design analysis tool that provides instant insights on UI, UX, readability, and more. It offers features like A/B Testing, UI Analysis, UX Analysis, Readability Analysis, Margin and Hierarchy Analysis, and Competition Analysis. Users can upload product images to receive detailed reports with actionable insights and scores. Trusted by founders and designers, VisualHUB helps optimize design variations and identify areas for improvement in products.
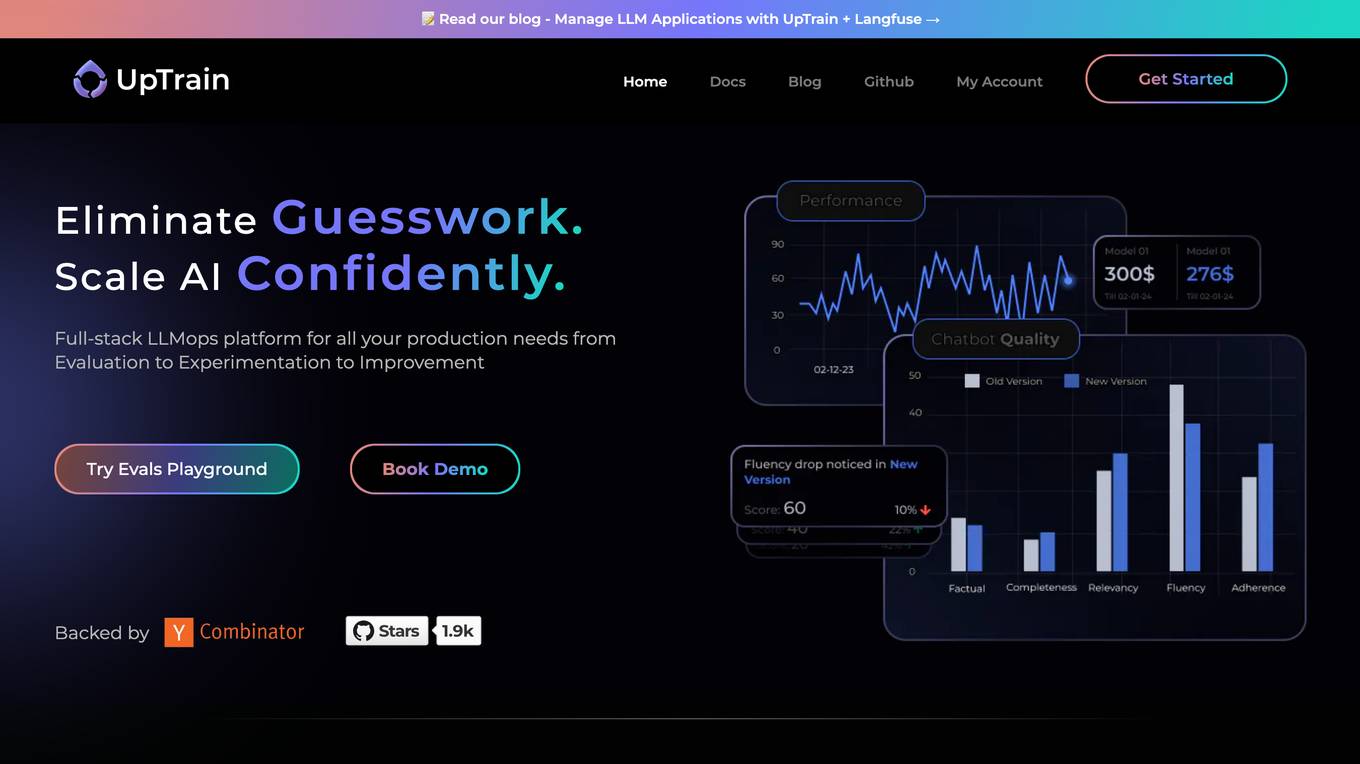
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users confidently scale AI by providing a comprehensive solution for all production needs, from evaluation to experimentation to improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and innovative techniques to generate high-quality scores. UpTrain is built for developers, compliant to data governance needs, cost-efficient, remarkably reliable, and open-source. It provides precision metrics, task understanding, safeguard systems, and covers a wide range of language features and quality aspects. The platform is suitable for developers, product managers, and business leaders looking to enhance their LLM applications.

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.
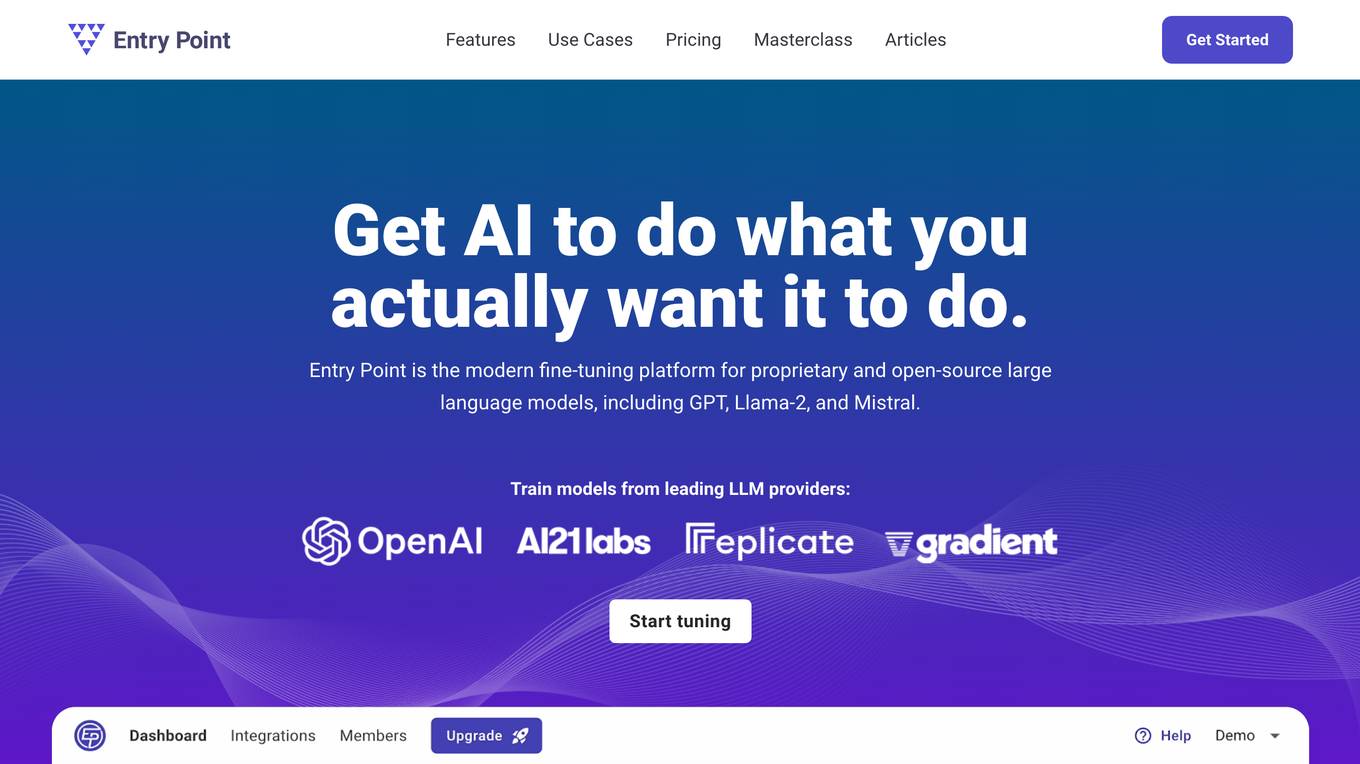
Entry Point AI
Entry Point AI is a modern AI optimization platform for fine-tuning proprietary and open-source language models. It provides a user-friendly interface to manage prompts, fine-tunes, and evaluations in one place. The platform enables users to optimize models from leading providers, train across providers, work collaboratively, write templates, import/export data, share models, and avoid common pitfalls associated with fine-tuning. Entry Point AI simplifies the fine-tuning process, making it accessible to users without the need for extensive data, infrastructure, or insider knowledge.

Flow AI
Flow AI is an advanced AI tool designed for evaluating and improving Large Language Model (LLM) applications. It offers a unique system for creating custom evaluators, deploying them with an API, and developing specialized LMs tailored to specific use cases. The tool aims to revolutionize AI evaluation and model development by providing transparent, cost-effective, and controllable solutions for AI teams across various domains.
RoundOneAI
RoundOneAI is an AI-driven platform revolutionizing tech recruitment by offering unbiased and efficient candidate assessments, ensuring skill-based evaluations free from demographic biases. The platform streamlines the hiring process with tailored job descriptions, AI-powered interviews, and insightful analytics. RoundOneAI helps companies evaluate candidates simultaneously, make informed hiring decisions, and identify top talent efficiently.
Scale AI
Scale AI is an AI tool that accelerates the development of AI applications for various sectors including enterprise, government, and automotive industries. It offers solutions for training models, fine-tuning, generative AI, and model evaluations. Scale Data Engine and GenAI Platform enable users to leverage enterprise data effectively. The platform collaborates with leading AI models and provides high-quality data for public and private sector applications.
Coval
Coval is an AI tool designed to help users ship reliable AI agents faster by providing simulation and evaluations for voice and chat agents. It allows users to simulate thousands of scenarios from a few test cases, create prompts for testing, and evaluate agent interactions comprehensively. Coval offers AI-powered simulations, voice AI compatibility, performance tracking, workflow metrics, and customizable evaluation metrics to optimize AI agents efficiently.
Weavel
Weavel is an AI tool designed to revolutionize prompt engineering for large language models (LLMs). It offers features such as tracing, dataset curation, batch testing, and evaluations to enhance the performance of LLM applications. Weavel enables users to continuously optimize prompts using real-world data, prevent performance regression with CI/CD integration, and engage in human-in-the-loop interactions for scoring and feedback. Ape, the AI prompt engineer, outperforms competitors on benchmark tests and ensures seamless integration and continuous improvement specific to each user's use case. With Weavel, users can effortlessly evaluate LLM applications without the need for pre-existing datasets, streamlining the assessment process and enhancing overall performance.
Athina AI
Athina AI is a comprehensive platform designed to monitor, debug, analyze, and improve the performance of Large Language Models (LLMs) in production environments. It provides a suite of tools and features that enable users to detect and fix hallucinations, evaluate output quality, analyze usage patterns, and optimize prompt management. Athina AI supports integration with various LLMs and offers a range of evaluation metrics, including context relevancy, harmfulness, summarization accuracy, and custom evaluations. It also provides a self-hosted solution for complete privacy and control, a GraphQL API for programmatic access to logs and evaluations, and support for multiple users and teams. Athina AI's mission is to empower organizations to harness the full potential of LLMs by ensuring their reliability, accuracy, and alignment with business objectives.
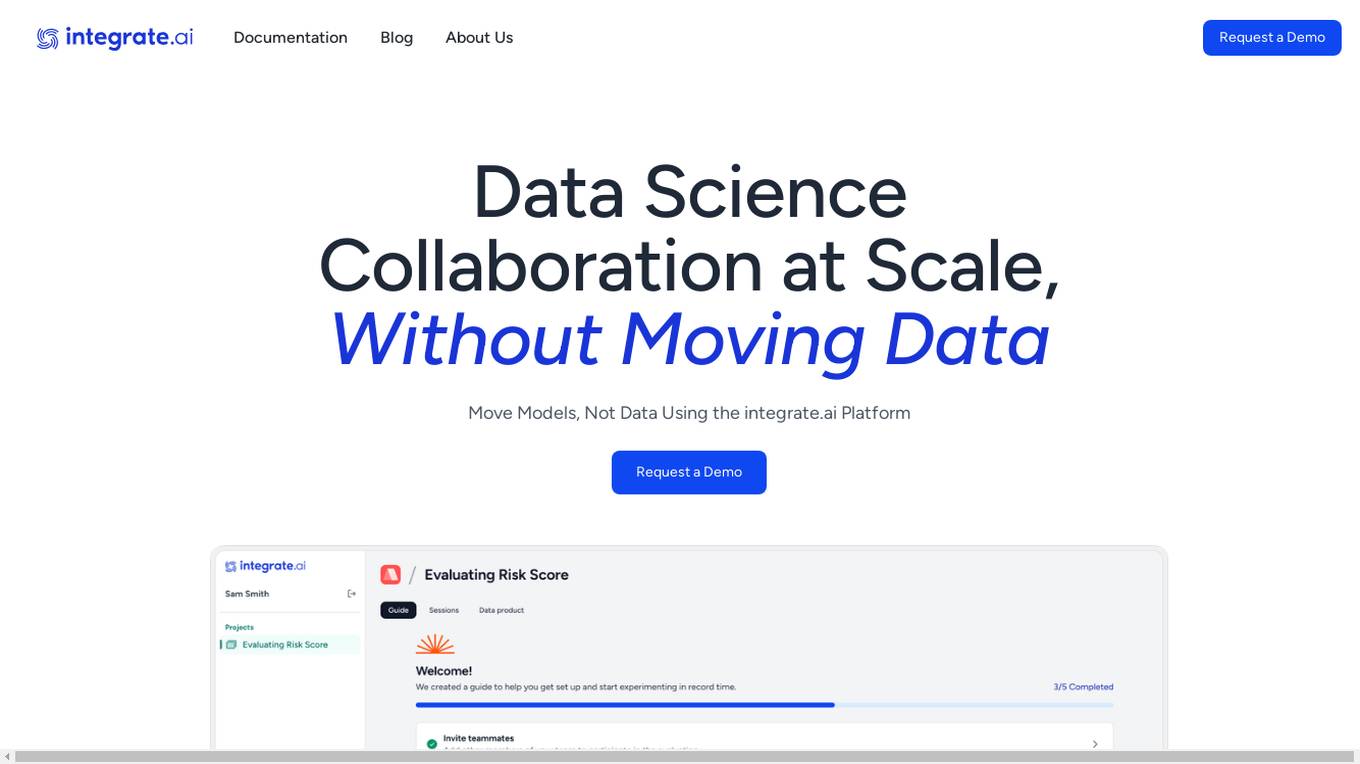
integrate.ai
integrate.ai is a platform that enables data and analytics providers to collaborate easily with enterprise data science teams without moving data. Powered by federated learning technology, the platform allows for efficient proof of concepts, data experimentation, infrastructure agnostic evaluations, collaborative data evaluations, and data governance controls. It supports various data science jobs such as match rate analysis, exploratory data analysis, correlation analysis, model performance analysis, feature importance & data influence, and model validation. The platform integrates with popular data science tools like Azure, Jupyter, Databricks, AWS, GCP, Snowflake, Pandas, PyTorch, MLflow, and scikit-learn.
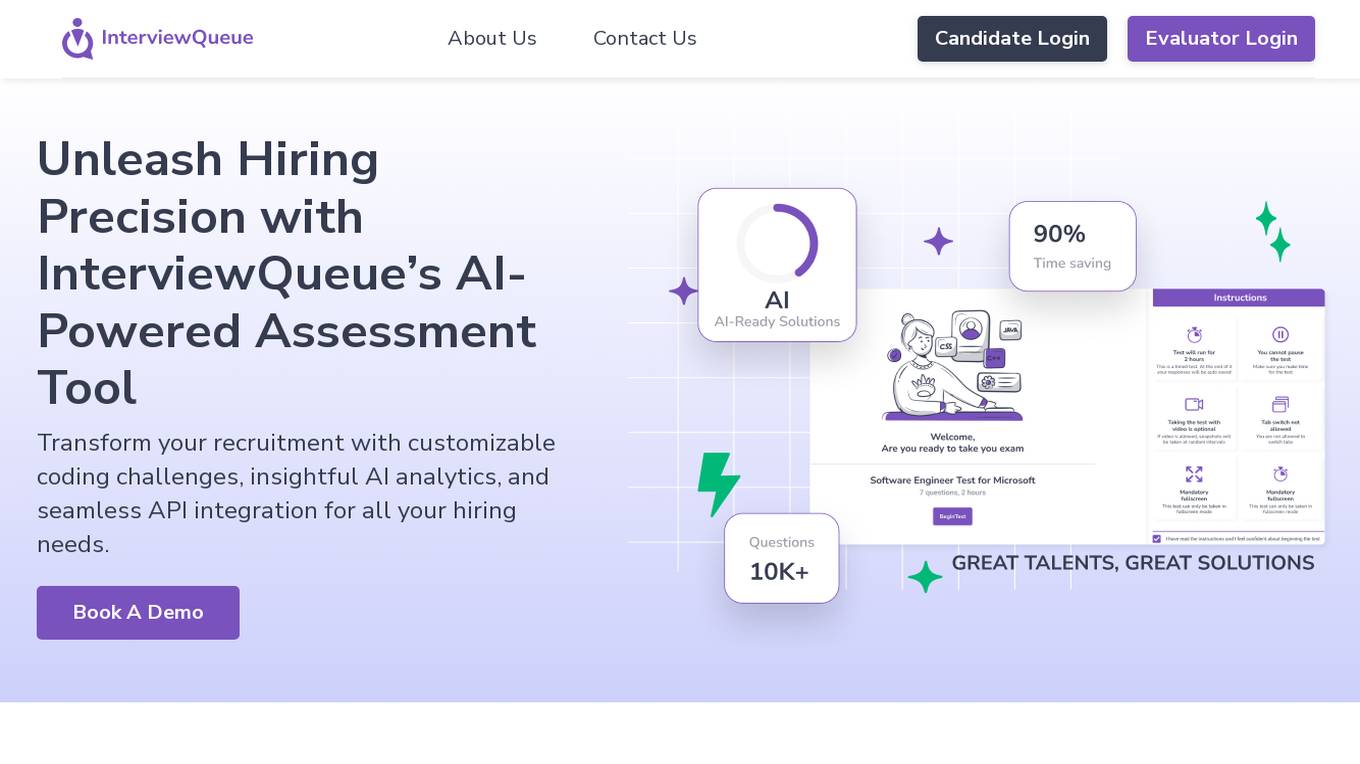
InterviewQueue
InterviewQueue is an AI-powered online assessment software platform that revolutionizes the recruitment process. It offers customizable coding challenges, insightful AI analytics, and seamless API integration for efficient hiring. With features like custom assessments, AI evaluation, and API integration, InterviewQueue aims to streamline the recruitment process and provide objective evaluations. The platform helps in making data-driven hiring decisions, optimizing the interview process, and enhancing the candidate experience. InterviewQueue focuses on efficiency, customization, objective evaluation, data-driven decisions, and candidate-centric assessments.
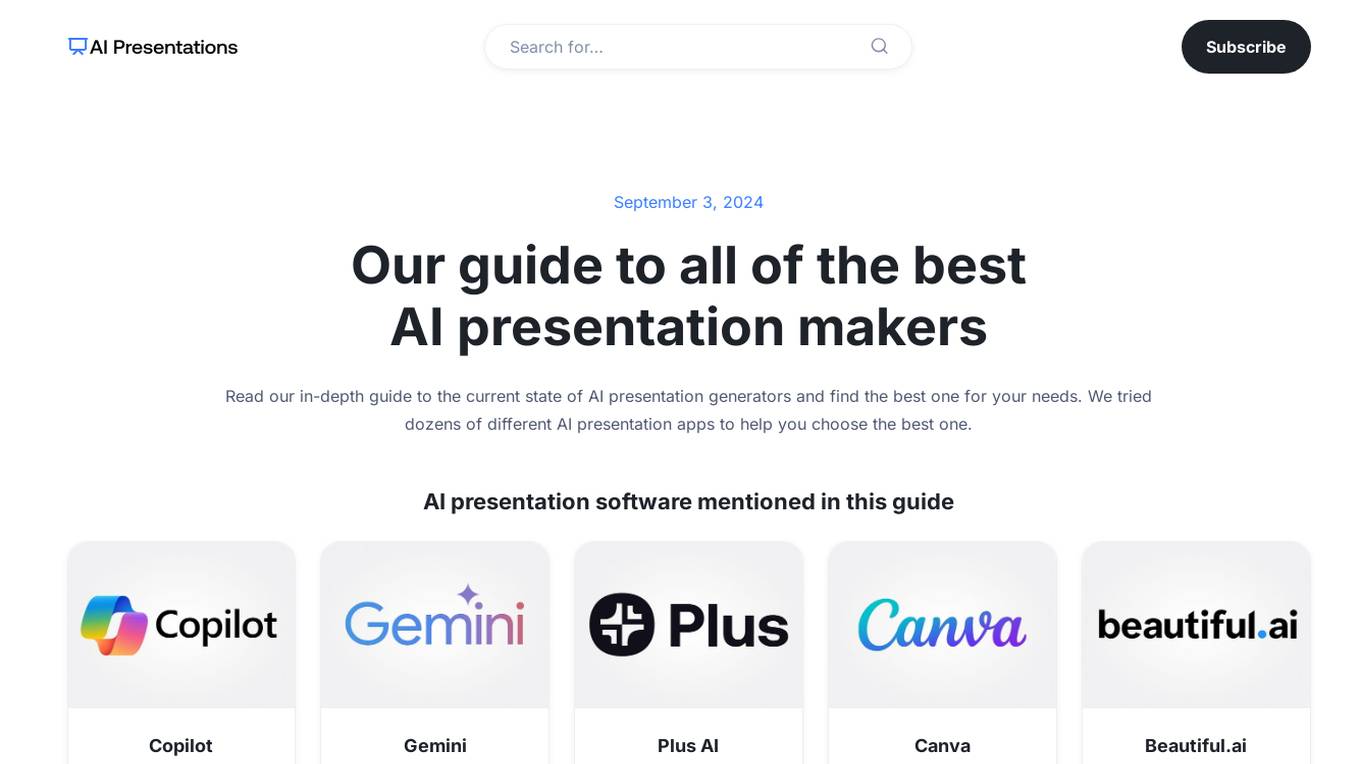
AIPresentationMakers
The website is a platform that provides reviews and recommendations for AI presentation makers. It offers in-depth guides on various AI presentation generators and helps users choose the best one for their needs. The site features detailed reviews of different AI presentation software, including their features, pros, and cons. Users can find information on popular AI tools like Plus AI, Canva, Beautiful.ai, and more. The platform also includes comparisons between different AI tools, pricing details, and evaluations of AI outputs and design components.
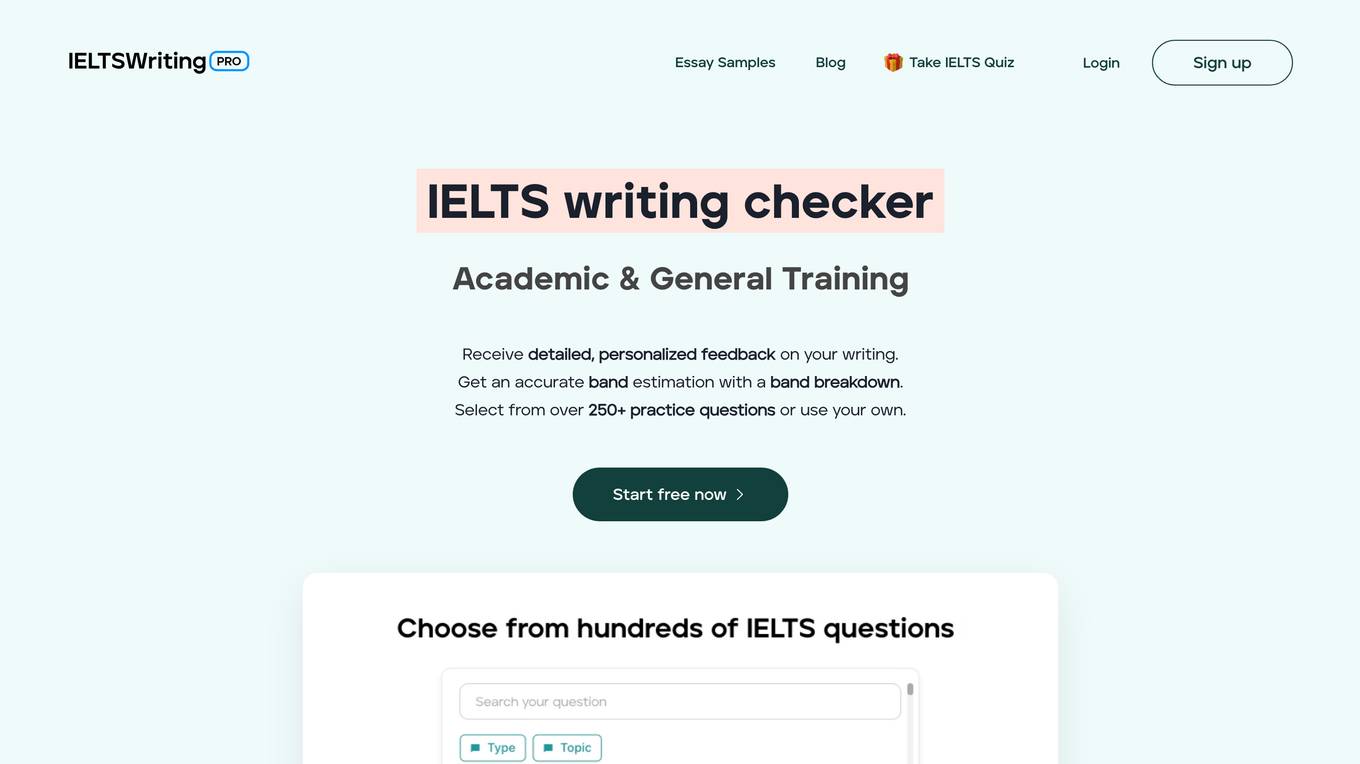
IELTSWritingPro
IELTSWritingPro is an AI-powered platform designed to help users improve their IELTS writing skills. It offers detailed feedback, band estimation, and personalized improvement suggestions based on official grading criteria. Users can practice with over 250+ questions, receive comprehensive correction reports, and benefit from advanced AI technology to enhance their writing abilities. The platform supports various IELTS tasks for both Academic and General Training modules, providing in-depth evaluations and insights to help users prepare effectively for the exam.
20 - Open Source AI Tools

swarms
Swarms provides simple, reliable, and agile tools to create your own Swarm tailored to your specific needs. Currently, Swarms is being used in production by RBC, John Deere, and many AI startups.
PromptChains
ChatGPT Queue Prompts is a collection of prompt chains designed to enhance interactions with large language models like ChatGPT. These prompt chains help build context for the AI before performing specific tasks, improving performance. Users can copy and paste prompt chains into the ChatGPT Queue extension to process prompts in sequence. The repository includes example prompt chains for tasks like conducting AI company research, building SEO optimized blog posts, creating courses, revising resumes, enriching leads for CRM, personal finance document creation, workout and nutrition plans, marketing plans, and more.
functionary
Functionary is a language model that interprets and executes functions/plugins. It determines when to execute functions, whether in parallel or serially, and understands their outputs. Function definitions are given as JSON Schema Objects, similar to OpenAI GPT function calls. It offers documentation and examples on functionary.meetkai.com. The newest model, meetkai/functionary-medium-v3.1, is ranked 2nd in the Berkeley Function-Calling Leaderboard. Functionary supports models with different context lengths and capabilities for function calling and code interpretation. It also provides grammar sampling for accurate function and parameter names. Users can deploy Functionary models serverlessly using Modal.com.
LLM-RGB
LLM-RGB is a repository containing a collection of detailed test cases designed to evaluate the reasoning and generation capabilities of Language Learning Models (LLMs) in complex scenarios. The benchmark assesses LLMs' performance in understanding context, complying with instructions, and handling challenges like long context lengths, multi-step reasoning, and specific response formats. Each test case evaluates an LLM's output based on context length difficulty, reasoning depth difficulty, and instruction compliance difficulty, with a final score calculated for each test case. The repository provides a score table, evaluation details, and quick start guide for running evaluations using promptfoo testing tools.
uptrain
UpTrain is an open-source unified platform to evaluate and improve Generative AI applications. We provide grades for 20+ preconfigured evaluations (covering language, code, embedding use cases), perform root cause analysis on failure cases and give insights on how to resolve them.

llm-jp-eval
LLM-jp-eval is a tool designed to automatically evaluate Japanese large language models across multiple datasets. It provides functionalities such as converting existing Japanese evaluation data to text generation task evaluation datasets, executing evaluations of large language models across multiple datasets, and generating instruction data (jaster) in the format of evaluation data prompts. Users can manage the evaluation settings through a config file and use Hydra to load them. The tool supports saving evaluation results and logs using wandb. Users can add new evaluation datasets by following specific steps and guidelines provided in the tool's documentation. It is important to note that using jaster for instruction tuning can lead to artificially high evaluation scores, so caution is advised when interpreting the results.

can-ai-code
Can AI Code is a self-evaluating interview tool for AI coding models. It includes interview questions written by humans and tests taken by AI, inference scripts for common API providers and CUDA-enabled quantization runtimes, a Docker-based sandbox environment for validating untrusted Python and NodeJS code, and the ability to evaluate the impact of prompting techniques and sampling parameters on large language model (LLM) coding performance. Users can also assess LLM coding performance degradation due to quantization. The tool provides test suites for evaluating LLM coding performance, a webapp for exploring results, and comparison scripts for evaluations. It supports multiple interviewers for API and CUDA runtimes, with detailed instructions on running the tool in different environments. The repository structure includes folders for interviews, prompts, parameters, evaluation scripts, comparison scripts, and more.

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.
do-not-answer
Do-Not-Answer is an open-source dataset curated to evaluate Large Language Models' safety mechanisms at a low cost. It consists of prompts to which responsible language models do not answer. The dataset includes human annotations and model-based evaluation using a fine-tuned BERT-like evaluator. The dataset covers 61 specific harms and collects 939 instructions across five risk areas and 12 harm types. Response assessment is done for six models, categorizing responses into harmfulness and action categories. Both human and automatic evaluations show the safety of models across different risk areas. The dataset also includes a Chinese version with 1,014 questions for evaluating Chinese LLMs' risk perception and sensitivity to specific words and phrases.
chembench
ChemBench is a project aimed at expanding chemistry benchmark tasks in a BIG-bench compatible way, providing a pipeline to benchmark frontier and open models. It enables benchmarking across a wide range of API-based models and employs an LLM-based extractor as a fallback mechanism. Users can evaluate models on specific chemistry topics and run comprehensive evaluations across all topics in the benchmark suite. The tool facilitates seamless benchmarking for any model supported by LiteLLM and allows running non-API hosted models.

pytest-evals
pytest-evals is a minimalistic pytest plugin designed to help evaluate the performance of Language Model (LLM) outputs against test cases. It allows users to test and evaluate LLM prompts against multiple cases, track metrics, and integrate easily with pytest, Jupyter notebooks, and CI/CD pipelines. Users can scale up by running tests in parallel with pytest-xdist and asynchronously with pytest-asyncio. The tool focuses on simplifying evaluation processes without the need for complex frameworks, keeping tests and evaluations together, and emphasizing logic over infrastructure.

ChainForge
ChainForge is a visual programming environment for battle-testing prompts to LLMs. It is geared towards early-stage, quick-and-dirty exploration of prompts, chat responses, and response quality that goes beyond ad-hoc chatting with individual LLMs. With ChainForge, you can: * Query multiple LLMs at once to test prompt ideas and variations quickly and effectively. * Compare response quality across prompt permutations, across models, and across model settings to choose the best prompt and model for your use case. * Setup evaluation metrics (scoring function) and immediately visualize results across prompts, prompt parameters, models, and model settings. * Hold multiple conversations at once across template parameters and chat models. Template not just prompts, but follow-up chat messages, and inspect and evaluate outputs at each turn of a chat conversation. ChainForge comes with a number of example evaluation flows to give you a sense of what's possible, including 188 example flows generated from benchmarks in OpenAI evals. This is an open beta of Chainforge. We support model providers OpenAI, HuggingFace, Anthropic, Google PaLM2, Azure OpenAI endpoints, and Dalai-hosted models Alpaca and Llama. You can change the exact model and individual model settings. Visualization nodes support numeric and boolean evaluation metrics. ChainForge is built on ReactFlow and Flask.

lmnr
Laminar is an all-in-one open-source platform designed for engineering AI products. It allows users to trace, evaluate, label, and analyze LLM data efficiently. The platform offers features such as automatic tracing of common AI frameworks and SDKs, local and online evaluations, simple UI for data labeling, dataset management, and scalability with gRPC communication. Laminar is built with a modern open-source stack including RabbitMQ, Postgres, Clickhouse, and Qdrant for semantic similarity search. It provides fast and beautiful dashboards for traces, evaluations, and labels, making it a comprehensive tool for AI product development.
PurpleLlama
Purple Llama is an umbrella project that aims to provide tools and evaluations to support responsible development and usage of generative AI models. It encompasses components for cybersecurity and input/output safeguards, with plans to expand in the future. The project emphasizes a collaborative approach, borrowing the concept of purple teaming from cybersecurity, to address potential risks and challenges posed by generative AI. Components within Purple Llama are licensed permissively to foster community collaboration and standardize the development of trust and safety tools for generative AI.
evaluation-guidebook
The LLM Evaluation guidebook provides comprehensive guidance on evaluating language model performance, including different evaluation methods, designing evaluations, and practical tips. It caters to both beginners and advanced users, offering insights on model inference, tokenization, and troubleshooting. The guide covers automatic benchmarks, human evaluation, LLM-as-a-judge scenarios, troubleshooting practicalities, and general knowledge on LLM basics. It also includes planned articles on automated benchmarks, evaluation importance, task-building considerations, and model comparison challenges. The resource is enriched with recommended links and acknowledgments to contributors and inspirations.

ai-rag-chat-evaluator
This repository contains scripts and tools for evaluating a chat app that uses the RAG architecture. It provides parameters to assess the quality and style of answers generated by the chat app, including system prompt, search parameters, and GPT model parameters. The tools facilitate running evaluations, with examples of evaluations on a sample chat app. The repo also offers guidance on cost estimation, setting up the project, deploying a GPT-4 model, generating ground truth data, running evaluations, and measuring the app's ability to say 'I don't know'. Users can customize evaluations, view results, and compare runs using provided tools.
ragas
Ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. RAG denotes a class of LLM applications that use external data to augment the LLM’s context. There are existing tools and frameworks that help you build these pipelines but evaluating it and quantifying your pipeline performance can be hard. This is where Ragas (RAG Assessment) comes in. Ragas provides you with the tools based on the latest research for evaluating LLM-generated text to give you insights about your RAG pipeline. Ragas can be integrated with your CI/CD to provide continuous checks to ensure performance.

RAGElo
RAGElo is a streamlined toolkit for evaluating Retrieval Augmented Generation (RAG)-powered Large Language Models (LLMs) question answering agents using the Elo rating system. It simplifies the process of comparing different outputs from multiple prompt and pipeline variations to a 'gold standard' by allowing a powerful LLM to judge between pairs of answers and questions. RAGElo conducts tournament-style Elo ranking of LLM outputs, providing insights into the effectiveness of different settings.

opencompass
OpenCompass is a one-stop platform for large model evaluation, aiming to provide a fair, open, and reproducible benchmark for large model evaluation. Its main features include: * Comprehensive support for models and datasets: Pre-support for 20+ HuggingFace and API models, a model evaluation scheme of 70+ datasets with about 400,000 questions, comprehensively evaluating the capabilities of the models in five dimensions. * Efficient distributed evaluation: One line command to implement task division and distributed evaluation, completing the full evaluation of billion-scale models in just a few hours. * Diversified evaluation paradigms: Support for zero-shot, few-shot, and chain-of-thought evaluations, combined with standard or dialogue-type prompt templates, to easily stimulate the maximum performance of various models. * Modular design with high extensibility: Want to add new models or datasets, customize an advanced task division strategy, or even support a new cluster management system? Everything about OpenCompass can be easily expanded! * Experiment management and reporting mechanism: Use config files to fully record each experiment, and support real-time reporting of results.
20 - OpenAI Gpts
Startup Critic
Apply gold-standard startup valuation and assessment methods to identify risks and gaps in your business model and product ideas.

Project Post-Project Evaluation Advisor
Optimizes project outcomes through comprehensive post-project evaluations.
Leica Guru
A Photography Expert specializing in personalized Leica gear advice and evaluations.
Luxury Authenticator
Expert in authenticating luxury items, providing detailed evaluations and ratings.

CIM Analyst
In-depth CIM analysis with a structured rating scale, offering detailed business evaluations.

HAI Assist
Formally evaluates clinical cases against CDC/NHSN HAI surveillance definition criteria

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model


WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms
