Best AI tools for< duplicate social media content >
14 - AI tool Sites
Duplikate
Duplikate is an AI-powered community management tool that helps businesses save time and effort by automating the process of finding, categorizing, and duplicating social media posts. With Duplikate, businesses can easily find relevant content to share on social media, and then customize it to match their brand and audience. Duplikate also provides analytics to help businesses understand which types of posts are most effective, and can even generate images to accompany posts.
Snapy
Snapy is an AI-powered video editing and generation tool that helps content creators create short videos, edit podcasts, and remove silent parts from videos. It offers a range of features such as turning text prompts into short videos, condensing long videos into engaging short clips, automatically removing silent parts from audio files, and auto-trimming, removing duplicate sentences and filler words, and adding subtitles to short videos. Snapy is designed to save time and effort for content creators, allowing them to publish more content, create more engaging videos, and improve the quality of their audio and video content.
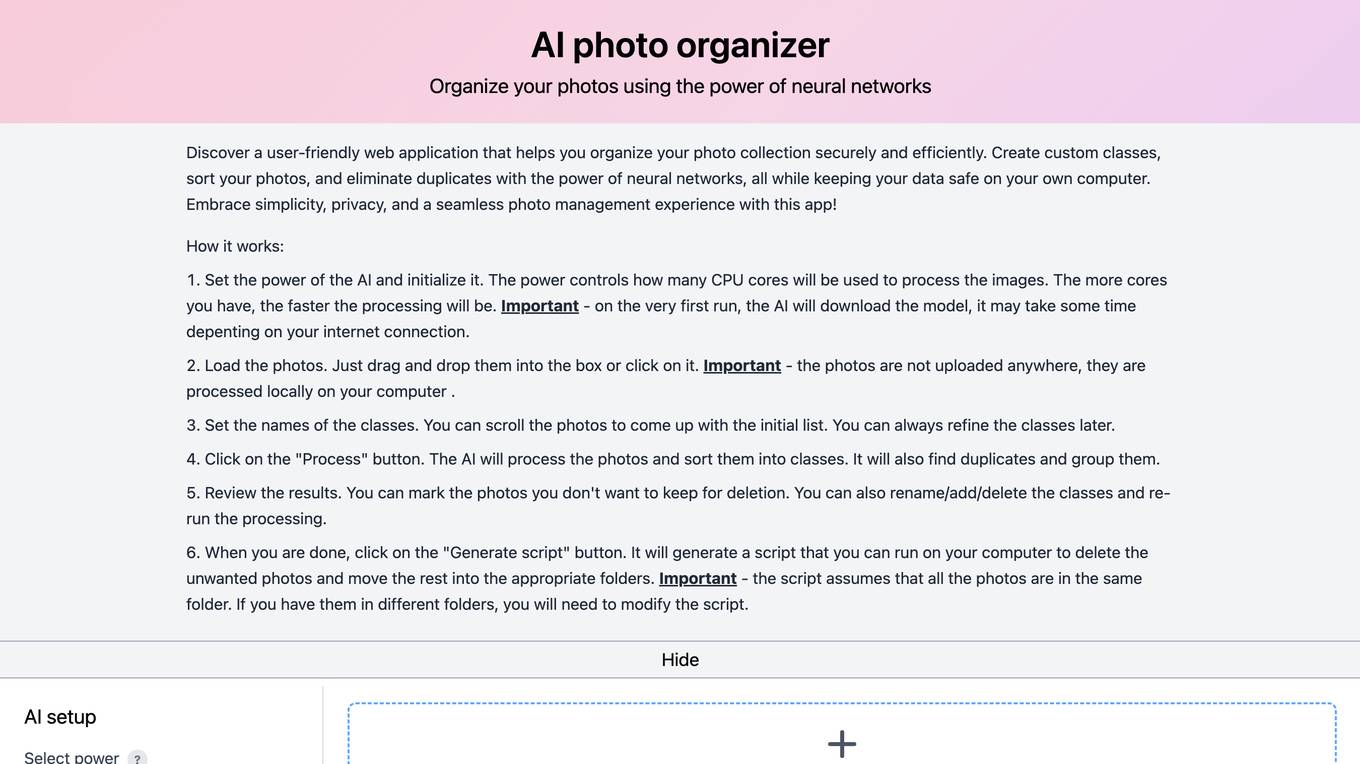
AI Photo Organizer
The AI photo organizer is a user-friendly web application that utilizes neural networks to help users securely and efficiently organize their photo collections. Users can create custom classes, sort photos, eliminate duplicates, and manage their data locally on their own computer. The application offers simplicity, privacy, and a seamless photo management experience.
Lenso.ai
Lenso.ai is an AI-powered reverse image search tool that allows users to explore billions of images from the web with advanced AI technology. It offers a more accurate and efficient process of reverse image search compared to traditional methods. Users can search for places, people, duplicates, and related images effortlessly. The tool is designed to cater to diverse needs, from professional photographers to marketers and enthusiasts, providing a faster, easier, and more accurate image search experience.
Quetext
Quetext is a plagiarism checker and AI content detector that helps students, teachers, and professionals identify potential plagiarism and AI in their work. With its deep search technology, contextual analysis, and smart algorithms, Quetext makes checking writing easier and more accurate. Quetext also offers a variety of features such as bulk uploads, source exclusion, enhanced citation generator, grammar & spell check, and Deep Search. With its rich and intuitive feedback, Quetext helps users find plagiarism and AI with less stress.
Nero Platinum Suite
Nero Platinum Suite is a comprehensive software collection for Windows PCs that provides a wide range of multimedia capabilities, including burning, managing, optimizing, and editing photos, videos, and music files. It includes various AI-powered features such as the Nero AI Image Upscaler, Nero AI Video Upscaler, and Nero AI Photo Tagger, which enhance and simplify multimedia tasks.
Goodlookup
Goodlookup is a smart function for spreadsheet users that gets very close to semantic understanding. It’s a pre-trained model that has the intuition of GPT-3 and the join capabilities of fuzzy matching. Use it like vlookup or index match to speed up your topic clustering work in google sheets!
Keploy
Keploy is an open-source platform that serves as a Stubs and API Test Generator for developers. It helps in converting API calls to test cases with data mocks, enabling streamlined testing, capturing network interactions, and generating automated tests. Keploy simplifies testing processes, accelerates development, and integrates seamlessly with various unit testing libraries for combined test coverage in CI/CD pipelines.
Roundtable
Roundtable is an AI-assisted data cleaning tool that helps users clean survey data efficiently. It offers an easy-to-integrate API for cleaning open-ended survey responses, saving up to 70% of time. The tool is trusted by leaders and innovators in various industries for improving data quality efforts and providing reliable human-generated insights.
Trieve
Trieve is an AI search infrastructure that offers an all-in-one solution for building search, recommendations, and RAG (Retrieve and Generate) capabilities into applications. It combines language models with tools for fine-tuning ranking and relevance, providing production-ready infrastructure to enhance search experiences. Trieve supports features such as semantic vector search, hybrid search, merchandising relevance tuning, date recency biasing, and sub-sentence highlighting. With Trieve, users can easily integrate AI-powered search functionalities into their products, focusing on building unique features while leveraging state-of-the-art retrieval models.

DVC
DVC is an open-source platform for managing machine learning data and experiments. It provides a unified interface for working with data from various sources, including local files, cloud storage, and databases. DVC also includes tools for versioning data and experiments, tracking metrics, and automating compute resources. DVC is designed to make it easy for data scientists and machine learning engineers to collaborate on projects and share their work with others.
Imagetwin
Imagetwin is an AI-based software designed to detect integrity issues in figures of scientific articles, specifically focusing on life science manuscripts. The application offers efficient and accurate detection of inappropriate manipulation, duplication, and plagiarism within various types of figures, such as western blots, microscopy images, and light photography. Imagetwin is a powerful tool that aids in the peer-review process by automatically identifying integrity issues, providing quick verification for reviewers, and ensuring data privacy and security by not storing uploaded content.
Hints
Hints is a sales AI assistant that helps sales reps to get more hours in a day while keeping CRM data accurate automatically. It works with Salesforce, Hubspot, and Pipedrive. With Hints, sales reps can log and retrieve CRM data on any device with chat and voice, get guidance on their next steps, and reminders of what's missing. Hints can also help sales reps to create complex CRM updates in seconds, find duplicates, suggest actions, automatically create associations, and look up sales data through chat and voice commands. Hints can assist sales reps in building the perfect sales process for their team and provides fast onboarding for new sales reps.
Sightengine
The website offers content moderation and image analysis products using powerful APIs to automatically assess, filter, and moderate images, videos, and text. It provides features such as image moderation, video moderation, text moderation, AI image detection, and video anonymization. The application helps in detecting unwanted content, AI-generated images, and personal information in videos. It also offers tools to identify near-duplicates, spam, and abusive links, and prevent phishing and circumvention attempts. The platform is fast, scalable, accurate, easy to integrate, and privacy compliant, making it suitable for various industries like marketplaces, dating apps, and news platforms.
20 - Open Source AI Tools



upgini
Upgini is an intelligent data search engine with a Python library that helps users find and add relevant features to their ML pipeline from various public, community, and premium external data sources. It automates the optimization of connected data sources by generating an optimal set of machine learning features using large language models, GraphNNs, and recurrent neural networks. The tool aims to simplify feature search and enrichment for external data to make it a standard approach in machine learning pipelines. It democratizes access to data sources for the data science community.
photoprism
PhotoPrism is an AI-powered photos app for the decentralized web. It uses the latest technologies to tag and find pictures automatically without getting in your way. You can run it at home, on a private server, or in the cloud.
MathPile
MathPile is a generative AI tool designed for math, offering a diverse and high-quality math-centric corpus comprising about 9.5 billion tokens. It draws from various sources such as textbooks, arXiv, Wikipedia, ProofWiki, StackExchange, and web pages, catering to different educational levels and math competitions. The corpus is meticulously processed to ensure data quality, with extensive documentation and data contamination detection. MathPile aims to enhance mathematical reasoning abilities of language models.

trieve
Trieve is an advanced relevance API for hybrid search, recommendations, and RAG. It offers a range of features including self-hosting, semantic dense vector search, typo tolerant full-text/neural search, sub-sentence highlighting, recommendations, convenient RAG API routes, the ability to bring your own models, hybrid search with cross-encoder re-ranking, recency biasing, tunable popularity-based ranking, filtering, duplicate detection, and grouping. Trieve is designed to be flexible and customizable, allowing users to tailor it to their specific needs. It is also easy to use, with a simple API and well-documented features.

deepdoctection
**deep** doctection is a Python library that orchestrates document extraction and document layout analysis tasks using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models. For more specific text processing tasks use one of the many other great NLP libraries. **deep** doctection focuses on applications and is made for those who want to solve real world problems related to document extraction from PDFs or scans in various image formats. **deep** doctection provides model wrappers of supported libraries for various tasks to be integrated into pipelines. Its core function does not depend on any specific deep learning library. Selected models for the following tasks are currently supported: * Document layout analysis including table recognition in Tensorflow with **Tensorpack**, or PyTorch with **Detectron2**, * OCR with support of **Tesseract**, **DocTr** (Tensorflow and PyTorch implementations available) and a wrapper to an API for a commercial solution, * Text mining for native PDFs with **pdfplumber**, * Language detection with **fastText**, * Deskewing and rotating images with **jdeskew**. * Document and token classification with all LayoutLM models provided by the **Transformer library**. (Yes, you can use any LayoutLM-model with any of the provided OCR-or pdfplumber tools straight away!). * Table detection and table structure recognition with **table-transformer**. * There is a small dataset for token classification available and a lot of new tutorials to show, how to train and evaluate this dataset using LayoutLMv1, LayoutLMv2, LayoutXLM and LayoutLMv3. * Comprehensive configuration of **analyzer** like choosing different models, output parsing, OCR selection. Check this notebook or the docs for more infos. * Document layout analysis and table recognition now runs with **Torchscript** (CPU) as well and **Detectron2** is not required anymore for basic inference. * [**new**] More angle predictors for determining the rotation of a document based on **Tesseract** and **DocTr** (not contained in the built-in Analyzer). * [**new**] Token classification with **LiLT** via **transformers**. We have added a model wrapper for token classification with LiLT and added a some LiLT models to the model catalog that seem to look promising, especially if you want to train a model on non-english data. The training script for LayoutLM can be used for LiLT as well and we will be providing a notebook on how to train a model on a custom dataset soon. **deep** doctection provides on top of that methods for pre-processing inputs to models like cropping or resizing and to post-process results, like validating duplicate outputs, relating words to detected layout segments or ordering words into contiguous text. You will get an output in JSON format that you can customize even further by yourself. Have a look at the **introduction notebook** in the notebook repo for an easy start. Check the **release notes** for recent updates. **deep** doctection or its support libraries provide pre-trained models that are in most of the cases available at the **Hugging Face Model Hub** or that will be automatically downloaded once requested. For instance, you can find pre-trained object detection models from the Tensorpack or Detectron2 framework for coarse layout analysis, table cell detection and table recognition. Training is a substantial part to get pipelines ready on some specific domain, let it be document layout analysis, document classification or NER. **deep** doctection provides training scripts for models that are based on trainers developed from the library that hosts the model code. Moreover, **deep** doctection hosts code to some well established datasets like **Publaynet** that makes it easy to experiment. It also contains mappings from widely used data formats like COCO and it has a dataset framework (akin to **datasets** so that setting up training on a custom dataset becomes very easy. **This notebook** shows you how to do this. **deep** doctection comes equipped with a framework that allows you to evaluate predictions of a single or multiple models in a pipeline against some ground truth. Check again **here** how it is done. Having set up a pipeline it takes you a few lines of code to instantiate the pipeline and after a for loop all pages will be processed through the pipeline.

swirl-search
Swirl is an open-source software that allows users to simultaneously search multiple content sources and receive AI-ranked results. It connects to various data sources, including databases, public data services, and enterprise sources, and utilizes AI and LLMs to generate insights and answers based on the user's data. Swirl is easy to use, requiring only the download of a YML file, starting in Docker, and searching with Swirl. Users can add credentials to preloaded SearchProviders to access more sources. Swirl also offers integration with ChatGPT as a configured AI model. It adapts and distributes user queries to anything with a search API, re-ranking the unified results using Large Language Models without extracting or indexing anything. Swirl includes five Google Programmable Search Engines (PSEs) to get users up and running quickly. Key features of Swirl include Microsoft 365 integration, SearchProvider configurations, query adaptation, synchronous or asynchronous search federation, optional subscribe feature, pipelining of Processor stages, results stored in SQLite3 or PostgreSQL, built-in Query Transformation support, matching on word stems and handling of stopwords, duplicate detection, re-ranking of unified results using Cosine Vector Similarity, result mixers, page through all results requested, sample data sets, optional spell correction, optional search/result expiration service, easily extensible Connector and Mixer objects, and a welcoming community for collaboration and support.
ai-comic-factory
The AI Comic Factory is a tool that allows you to create your own AI comics with a single prompt. It uses a large language model (LLM) to generate the story and dialogue, and a rendering API to generate the panel images. The AI Comic Factory is open-source and can be run on your own website or computer. It is a great tool for anyone who wants to create their own comics, or for anyone who is interested in the potential of AI for storytelling.

AIL-framework
AIL framework is a modular framework to analyze potential information leaks from unstructured data sources like pastes from Pastebin or similar services or unstructured data streams. AIL framework is flexible and can be extended to support other functionalities to mine or process sensitive information (e.g. data leak prevention).

gpt4all
GPT4All is an ecosystem to run powerful and customized large language models that work locally on consumer grade CPUs and any GPU. Note that your CPU needs to support AVX or AVX2 instructions. Learn more in the documentation. A GPT4All model is a 3GB - 8GB file that you can download and plug into the GPT4All open-source ecosystem software. Nomic AI supports and maintains this software ecosystem to enforce quality and security alongside spearheading the effort to allow any person or enterprise to easily train and deploy their own on-edge large language models.

superduperdb
SuperDuperDB is a Python framework for integrating AI models, APIs, and vector search engines directly with your existing databases, including hosting of your own models, streaming inference and scalable model training/fine-tuning. Build, deploy and manage any AI application without the need for complex pipelines, infrastructure as well as specialized vector databases, and moving our data there, by integrating AI at your data's source: - Generative AI, LLMs, RAG, vector search - Standard machine learning use-cases (classification, segmentation, regression, forecasting recommendation etc.) - Custom AI use-cases involving specialized models - Even the most complex applications/workflows in which different models work together SuperDuperDB is **not** a database. Think `db = superduper(db)`: SuperDuperDB transforms your databases into an intelligent platform that allows you to leverage the full AI and Python ecosystem. A single development and deployment environment for all your AI applications in one place, fully scalable and easy to manage.

WrenAI
WrenAI is a data assistant tool that helps users get results and insights faster by asking questions in natural language, without writing SQL. It leverages Large Language Models (LLM) with Retrieval-Augmented Generation (RAG) technology to enhance comprehension of internal data. Key benefits include fast onboarding, secure design, and open-source availability. WrenAI consists of three core services: Wren UI (intuitive user interface), Wren AI Service (processes queries using a vector database), and Wren Engine (platform backbone). It is currently in alpha version, with new releases planned biweekly.
x-crawl
x-crawl is a flexible Node.js AI-assisted crawler library that offers powerful AI assistance functions to make crawler work more efficient, intelligent, and convenient. It consists of a crawler API and various functions that can work normally even without relying on AI. The AI component is currently based on a large AI model provided by OpenAI, simplifying many tedious operations. The library supports crawling dynamic pages, static pages, interface data, and file data, with features like control page operations, device fingerprinting, asynchronous sync, interval crawling, failed retry handling, rotation proxy, priority queue, crawl information control, and TypeScript support.

ail-framework
AIL framework is a modular framework to analyze potential information leaks from unstructured data sources like pastes from Pastebin or similar services or unstructured data streams. AIL framework is flexible and can be extended to support other functionalities to mine or process sensitive information (e.g. data leak prevention).
optscale
OptScale is an open-source FinOps and MLOps platform that provides cloud cost optimization for all types of organizations and MLOps capabilities like experiment tracking, model versioning, ML leaderboards.
tegon
Tegon is an open-source AI-First issue tracking tool designed for engineering teams. It aims to simplify task management by leveraging AI and integrations to automate task creation, prioritize tasks, and enhance bug resolution. Tegon offers features like issues tracking, automatic title generation, AI-generated labels and assignees, custom views, and upcoming features like sprints and task prioritization. It integrates with GitHub, Slack, and Sentry to streamline issue tracking processes. Tegon also plans to introduce AI Agents like PR Agent and Bug Agent to enhance product management and bug resolution. Contributions are welcome, and the product is licensed under the MIT License.
feedgen
FeedGen is an open-source tool that uses Google Cloud's state-of-the-art Large Language Models (LLMs) to improve product titles, generate more comprehensive descriptions, and fill missing attributes in product feeds. It helps merchants and advertisers surface and fix quality issues in their feeds using Generative AI in a simple and configurable way. The tool relies on GCP's Vertex AI API to provide both zero-shot and few-shot inference capabilities on GCP's foundational LLMs. With few-shot prompting, users can customize the model's responses towards their own data, achieving higher quality and more consistent output. FeedGen is an Apps Script based application that runs as an HTML sidebar in Google Sheets, allowing users to optimize their feeds with ease.

Chinese-Tiny-LLM
Chinese-Tiny-LLM is a repository containing procedures for cleaning Chinese web corpora and pre-training code. It introduces CT-LLM, a 2B parameter language model focused on the Chinese language. The model primarily uses Chinese data from a 1,200 billion token corpus, showing excellent performance in Chinese language tasks. The repository includes tools for filtering, deduplication, and pre-training, aiming to encourage further research and innovation in language model development.
11 - OpenAI Gpts
Image Theme Clone
Type “Start” and Get Exact Details on Image Generation and/or Duplication
Data-Driven Messaging Campaign Generator
Create, analyze & duplicate customized automated message campaigns to boost retention & drive revenue for your website or app
Plagiarism Checker
Maintain the originality of your work with our Plagiarism Checker. This plagiarism checker identifies duplicate content, ensuring your work's uniqueness and integrity.