Best AI tools for< Tiktoker >
Infographic
1 - AI tool Sites
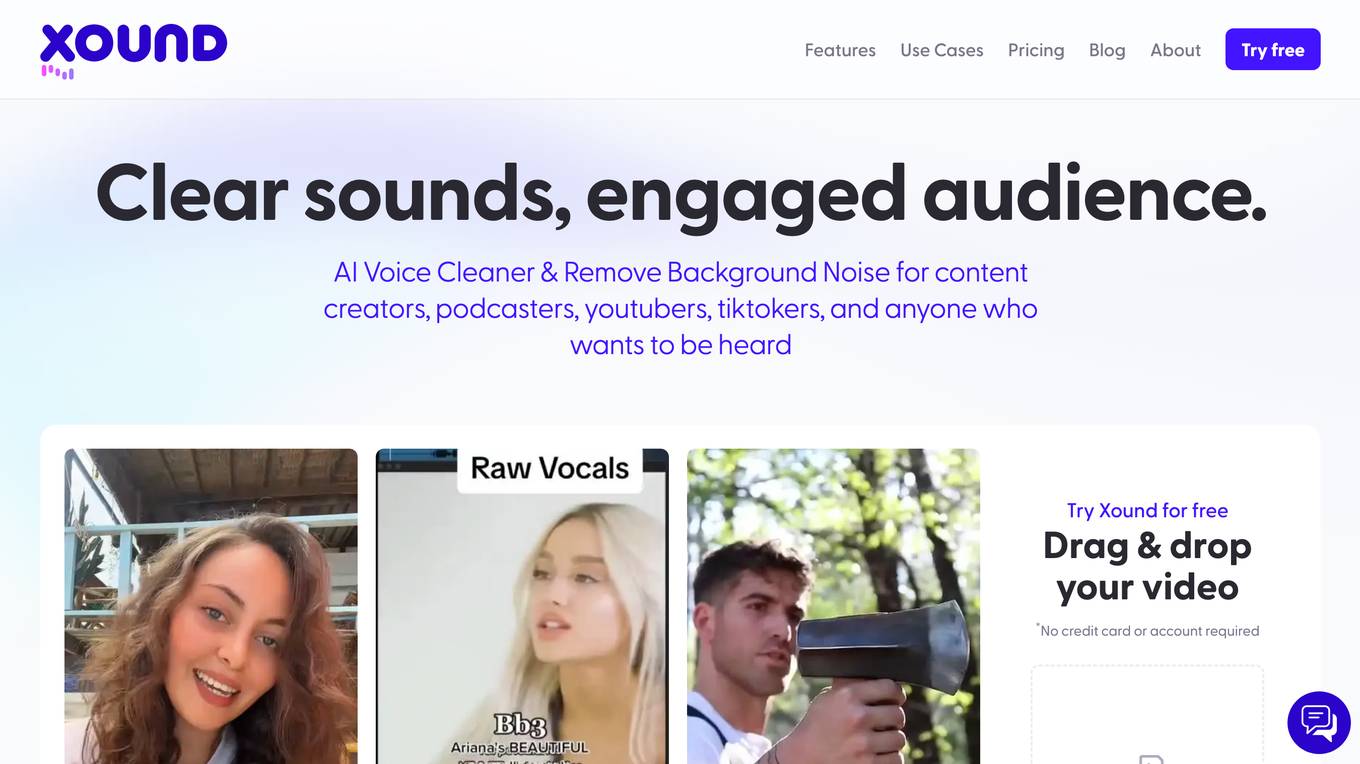
Xound.io
Xound.io is an AI-powered voice cleaner and background noise removal tool designed for content creators, podcasters, YouTubers, TikTokers, and anyone who wants to improve the audio quality of their content. It uses advanced algorithms to remove background noise, enhance vocals, and improve the overall listening experience. Xound.io is easy to use, with a simple drag-and-drop interface and no need for any technical expertise. It also offers a variety of features, including natural pitch correction, AI background noise removal, and high-frequency presence.
site
: 68.1k
0 - Open Source Tools
No tools available
2 - OpenAI Gpts

Tiktoers Creative Toolbox
Help tiktoers craft titles, short scripts, thumbnails, channel names, find niches, transfer formats. V20231118
gpt
: 400+