Best AI tools for< Python Data Scientist >
Infographic
20 - AI tool Sites
Mito
Mito is a low-code data app infrastructure that allows users to edit spreadsheets and automatically generate Python code. It is designed to help analysts automate their repetitive Excel work and take automation into their own hands. Mito is a Jupyter extension and Streamlit component, so users don't need to set up any new infrastructure. It is easy to get started with Mito, simply install it using pip and start using it in Jupyter or Streamlit.
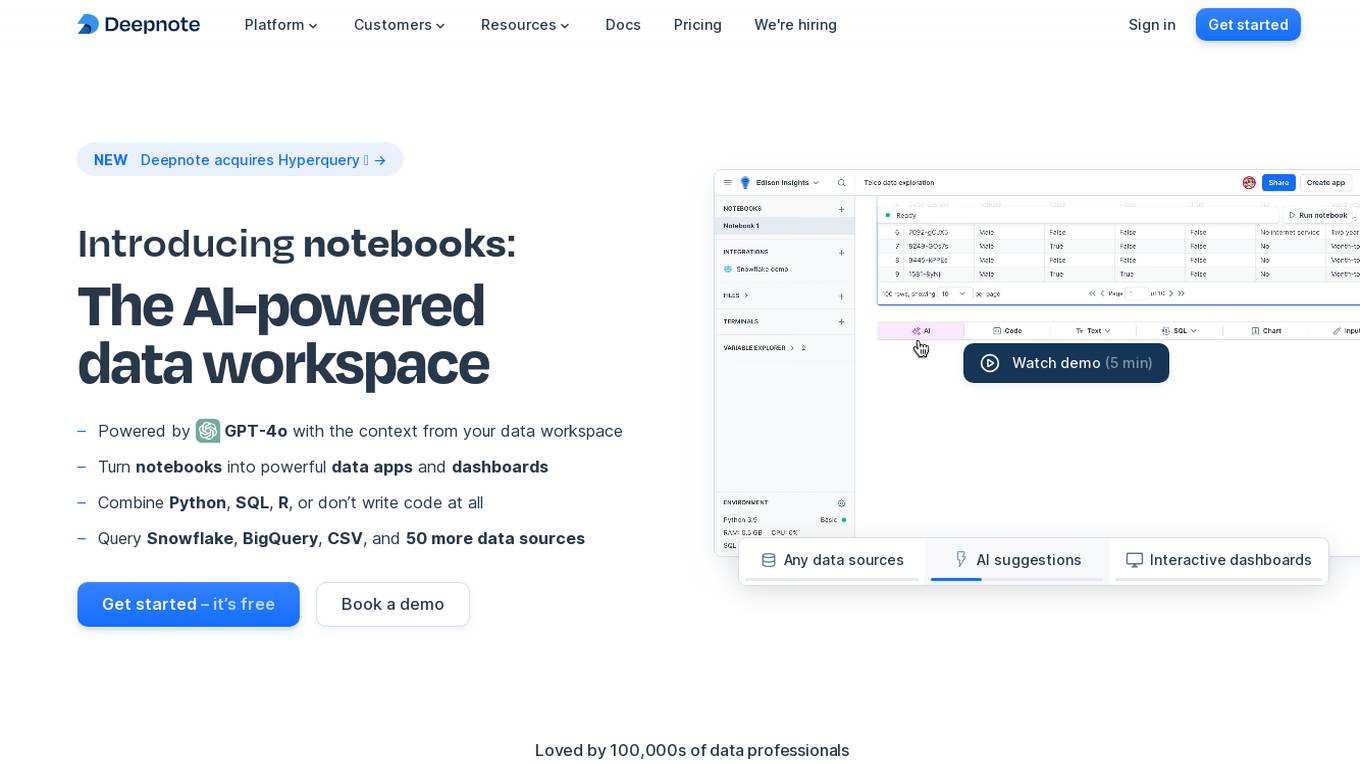
Deepnote
Deepnote is an AI-powered analytics and data science notebook platform designed for teams. It allows users to turn notebooks into powerful data apps and dashboards, combining Python, SQL, R, or even working without writing code at all. With Deepnote, users can query various data sources, generate code, explain code, and create interactive visualizations effortlessly. The platform offers features like collaborative workspaces, scheduling notebooks, deploying APIs, and integrating with popular data warehouses and databases. Deepnote prioritizes security and compliance, providing users with control over data access and encryption. It is loved by a community of data professionals and widely used in universities and by data analysts and scientists.
MOSTLY AI Platform
The website offers a Synthetic Data Generation platform with the highest accuracy for free. It provides detailed information on synthetic data, data anonymization, and features a Python Client for data generation. The platform ensures privacy and security, allowing users to create fully anonymous synthetic data from original data. It supports various AI/ML use cases, self-service analytics, testing & QA, and data sharing. The platform is designed for Enterprise organizations, offering scalability, privacy by design, and the world's most accurate synthetic data.
RTutor
RTutor is an AI tool that utilizes OpenAI's large language models to translate natural language into R or Python code for data analysis. Users can upload data in various formats, ask questions, and receive results in plain English. The tool allows for exploring data, generating basic plots, and gradually adding complexity to the analysis. RTutor can only analyze traditional statistics data where rows are observations and columns are variables. It offers a comprehensive EDA (Exploratory Data Analysis) report and provides code chunks for analysis.
Data Science Dojo
Data Science Dojo is a globally recognized e-learning platform that offers programs in data science, data analytics, machine learning, and more. They provide comprehensive and hands-on training in various formats such as in-person, virtual instructor-led, and self-paced training. The focus is on helping students develop a think-business-first mindset to apply their data science skills effectively in real-world scenarios. With over 2500 enterprises trained, Data Science Dojo aims to make data science accessible to everyone.
Amazon SageMaker Python SDK
Amazon SageMaker Python SDK is an open source library for training and deploying machine-learned models on Amazon SageMaker. With the SDK, you can train and deploy models using popular deep learning frameworks, algorithms provided by Amazon, or your own algorithms built into SageMaker-compatible Docker images.
Hex
Hex is a collaborative data workspace that provides a variety of tools for working with data, including queries, notebooks, reports, data apps, and AI. It is designed to be easy to use for people of all technical skill levels, and it integrates with a variety of other tools and services. Hex is a powerful tool for data exploration, analysis, and visualization.
LangChain
LangChain is a framework for developing applications powered by large language models (LLMs). It simplifies every stage of the LLM application lifecycle, including development, productionization, and deployment. LangChain consists of open-source libraries such as langchain-core, langchain-community, and partner packages. It also includes LangGraph for building stateful agents and LangSmith for debugging and monitoring LLM applications.
Quadratic
Quadratic is an infinite spreadsheet with Python, SQL, and AI. It combines the familiarity of a spreadsheet with the power of code, allowing users to analyze data, write code, and create visualizations in a single environment. With built-in Python library support, users can bring open source tools directly to their spreadsheets. Quadratic also features real-time collaboration, allowing multiple users to work on the same spreadsheet simultaneously. Additionally, Quadratic is built for speed and performance, utilizing Web Assembly and WebGL to deliver a smooth and responsive experience.

Hal9
Hal9 is an AI coworker creation platform that allows organizations, data teams, and developers to effortlessly build custom AI coworkers with any level of complexity. It provides a secure and customizable model-agnostic AI coworker solution that accelerates the development of AI applications by saving significant engineering time. Hal9 enables users to leverage the best generative AI models, connect their data securely, and start building enterprise-ready AI applications with the necessary engineering components. The platform aims to empower users to leverage AI technology effectively and efficiently in their projects.
DataCamp
DataCamp is an online learning platform that offers courses in data science, AI, and machine learning. The platform provides interactive exercises, short videos, and hands-on projects to help learners develop the skills they need to succeed in the field. DataCamp also offers a variety of resources for businesses, including team training, custom content development, and data science consulting.
PandasAI
PandasAI is an open-source AI tool designed for conversational data analysis. It allows users to ask questions in natural language to their enterprise data and receive real-time data insights. The tool is integrated with various data sources and offers enhanced analytics, actionable insights, detailed reports, and visual data representation. PandasAI aims to democratize data analysis for better decision-making, offering enterprise solutions for stable and scalable internal data analysis. Users can also fine-tune models, ingest universal data, structure data automatically, augment datasets, extract data from websites, and forecast trends using AI.
scikit-learn
Scikit-learn is a free software machine learning library for the Python programming language. It features various classification, regression and clustering algorithms including support vector machines, random forests, gradient boosting, k-means and DBSCAN, and is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy.
Google Colab
Google Colab is a free Jupyter notebook environment that runs in the cloud. It allows you to write and execute Python code without having to install any software or set up a local environment. Colab notebooks are shareable, so you can easily collaborate with others on projects.

NumPy
NumPy is a library for the Python programming language, adding support for large, multi-dimensional arrays and high-level mathematical functions to perform operations on these arrays. It is the fundamental package for scientific computing with Python and is used in a wide range of applications, including data science, machine learning, and image processing. NumPy is open source and distributed under a liberal BSD license, and is developed and maintained publicly on GitHub by a vibrant, responsive, and diverse community.
Walter Shields Data Academy
Walter Shields Data Academy is an AI-powered platform offering premium training in SQL, Python, and Excel. With over 200,000 learners, it provides curated courses from bestselling books and LinkedIn Learning. The academy aims to revolutionize data expertise and empower individuals to excel in data analysis and AI technologies.

NLTK
NLTK (Natural Language Toolkit) is a leading platform for building Python programs to work with human language data. It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries, and an active discussion forum. Thanks to a hands-on guide introducing programming fundamentals alongside topics in computational linguistics, plus comprehensive API documentation, NLTK is suitable for linguists, engineers, students, educators, researchers, and industry users alike.
Pickl.AI
Pickl.AI is a platform offering professional certification courses in Data Science, empowering individuals to enhance their career prospects. The platform provides a range of courses tailored for beginners, students, and professionals, covering topics such as Machine Learning, Python programming, and Data Analytics. Pickl.AI aims to equip learners with industry-relevant skills and expertise through expert-led lectures, real projects, and doubt-clearing sessions. The platform also offers job guarantee programs and short-term courses to cater to diverse learning needs.
AICorr.com
AICorr.com is a website offering free coding tutorials with a focus on artificial intelligence, data science, machine learning, and statistics. Users can learn and practice coding in Python and SQL, explore projects with real data, and access a wealth of information in an easy-to-understand format. The website aims to provide up-to-date and relevant information to a global audience, ensuring a seamless learning experience for all.

Supersimple
Supersimple is an AI-native data analytics platform that combines a semantic data modeling layer with the ability to answer ad hoc questions, giving users reliable, consistent data to power their day-to-day work.
0 - Open Source Tools
20 - OpenAI Gpts

Python Mentor
AI guide for Python certification PCEP and PCAP with project-based, exam-focused learning.

Therocial Scientist
I am a digital scientist skilled in Python, here to assist with scientific and data analysis tasks.
PyRefactor
Refactor python code. Python expert with proficiency in data science, machine learning (including LLM apps), and both OOP and functional programming.
Metaphor API Guide - Python SDK
Teaches you how to use the Metaphor Search API using our Python SDK
Python数据分析最强辅助
我是一个温和的老师,以最温和的语气解答我学生的一切问题,聪明的你提问吧,加微信simons2035获取python\numpy\pandas\matplotlib全套思维导图吧!
Python | A comprehensive course for everyone
Beginner-friendly Python guide including practical projects
! KAI - L'ultime assistant Python
KAI, votre assistant ultime dédié à tous l'univers Python dans son ensemble, sympathique et serviable. ALL LANGUAGES.
Python Mentor
Asistente y maestro experto en Python, enfocado en la enseñanza y apoyo en proyectos de programación.

Python Coach
I will start by asking you for your level of experience, then help you learn to program in Python. This Mini GPT is based on an Expert Guidance Prompt created in under 3 minutes with StructuredPrompt.com using AI-Assist.


Python Seniorify
Wise Python tutor for intermediate coders, focusing on advanced coding principles.

Python Puzzle Master
I offer engaging Python puzzles, explain solutions and immediately present the next challenge.