AI tools for 4k
Related Tools:
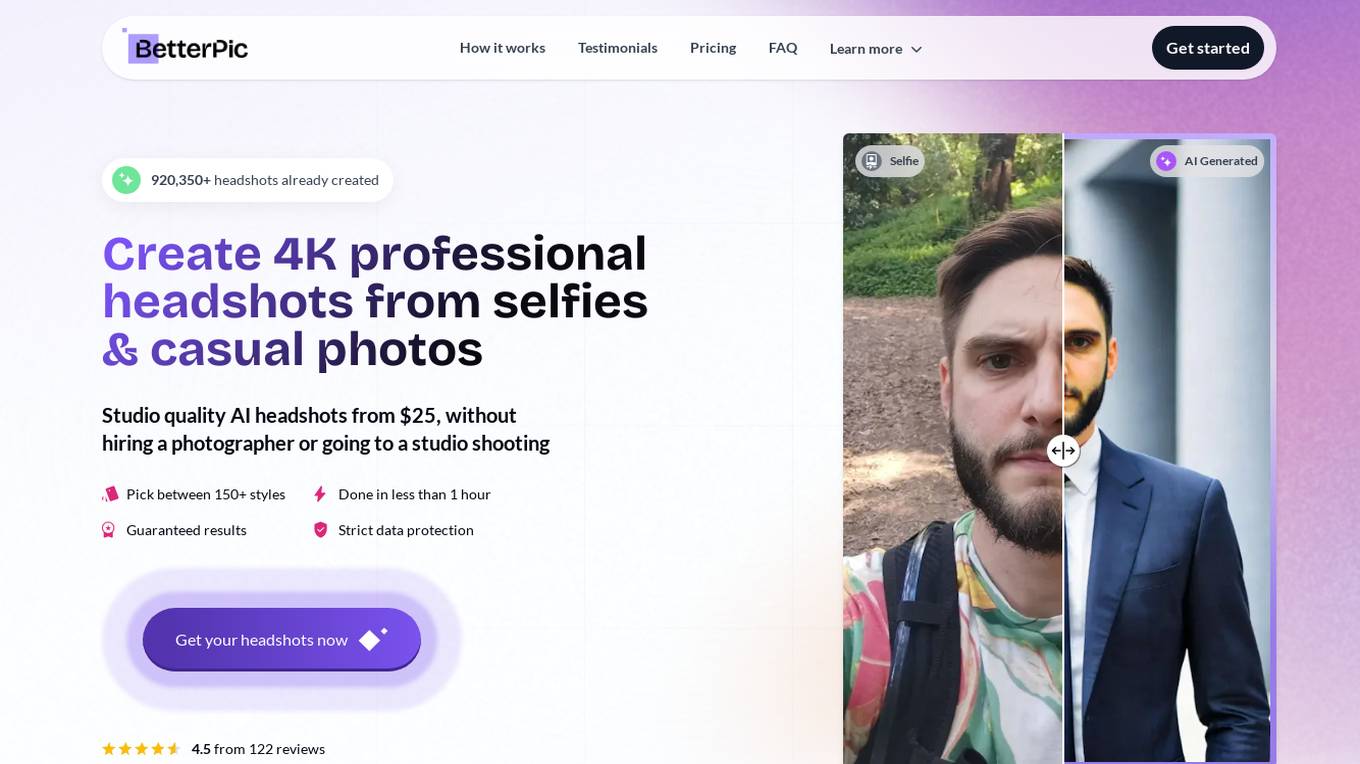
BetterPic
BetterPic is an AI-powered platform that allows users to create professional headshots from selfies and casual photos. With over 913,833 headshots already created, BetterPic is a popular choice for individuals and remote teams looking for high-quality, affordable headshots. The platform offers a variety of features, including 150+ styles and backgrounds, a quick turnaround time, and a satisfaction guarantee.
ImaginePro
ImaginePro is a professional AI image generator that transforms text and images into high-quality visuals using cutting-edge AI technology. It offers powerful features for limitless creativity, allowing users to create professional-quality images in seconds, fine-tune results with precise style references, and generate lifelike, high-resolution images perfect for various purposes. The tool is designed for professionals, designers, and creators seeking to bring their ideas to life with unmatched quality and realism.
DVDFab
DVDFab is the world's leading multimedia solution provider, offering a wide range of tools for DVD, Blu-ray, and UHD disc backup, conversion, and authoring. With over 20 years of industry experience, DVDFab provides users with comprehensive solutions for disc editing, disc-to-file conversion, and video enhancement. The application also includes features like DVD/Blu-ray/UHD copying, format conversion, video playback, streaming video downloading, and AI-powered video upscaling. Trusted by millions of users worldwide, DVDFab continues to innovate and expand its product line to meet the evolving needs of multimedia enthusiasts.

DVDFab
DVDFab is a comprehensive multimedia solution provider that offers a wide range of software for DVD, Blu-ray, and UHD backup, conversion, and authoring. With over 20 years of experience in the industry, DVDFab has become a trusted name among users for its reliable and high-quality products. The company's flagship product, DVDFab All-In-One, is a comprehensive suite that includes all of DVDFab's DVD, Blu-ray, and UHD tools. Other popular products from DVDFab include StreamFab, a streaming video downloader; UniFab, an AI-powered video enhancer; and PlayerFab, an Ultra HD player.
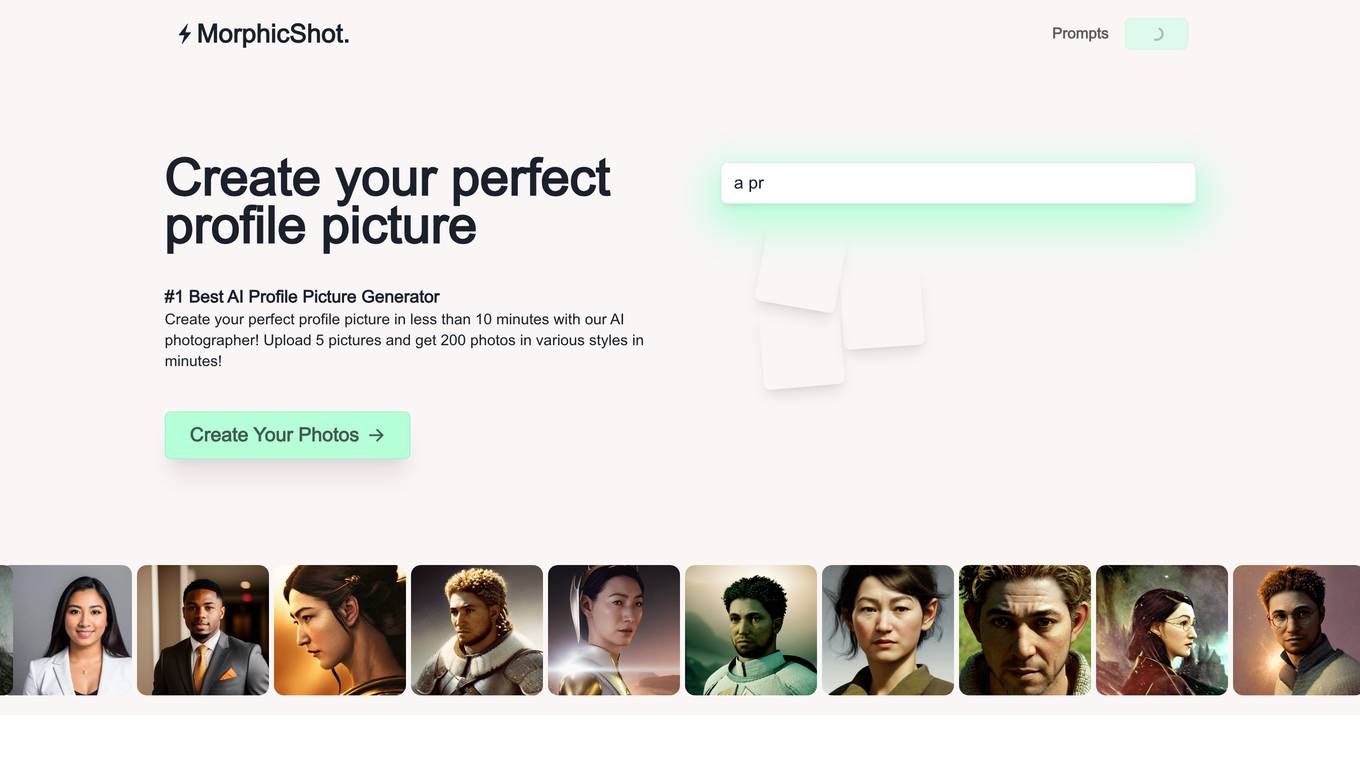
MorphicShot
MorphicShot is an AI-powered profile picture generator that allows users to create their perfect profile pictures in less than 10 minutes. Users can upload 5 pictures and receive 200 photos in various styles. The tool uses AI technology to build a studio based on the uploaded photos and provides prompt assistance to craft the perfect profile picture. With a one-time payment of $15, users can access a custom trained model and upscale their profile pictures to 4K resolution. MorphicShot aims to simplify the process of creating professional-looking profile pictures with the help of AI technology.
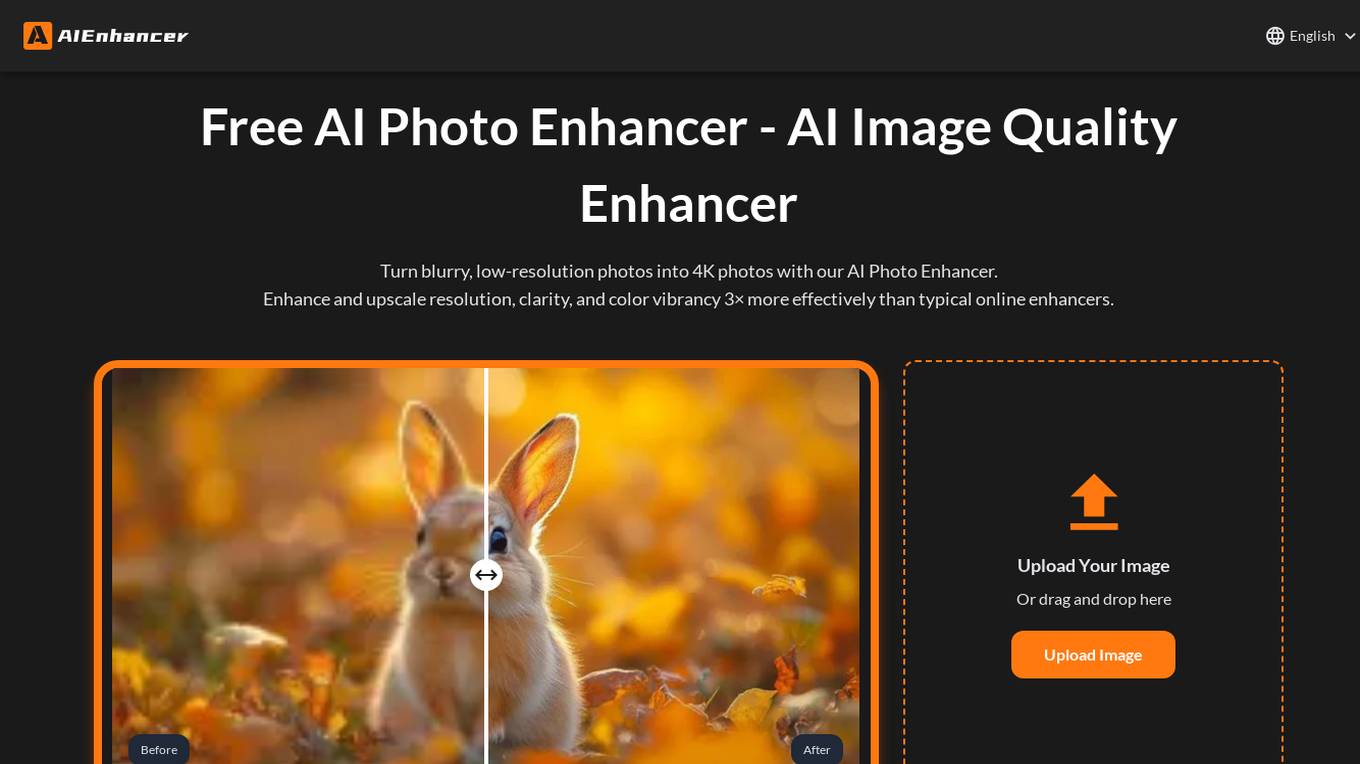
AI Photo Enhancer
The AI Photo Enhancer is an online tool that uses artificial intelligence to enhance and upscale the resolution, clarity, and color vibrancy of photos. It can transform blurry, low-resolution, or AI-generated images into stunning high-resolution photos with minimal effort. The tool is trusted by over 1 million users worldwide and offers various enhancement modes such as resolution upscaling, noise and blur removal, color correction, and AI-art repair.
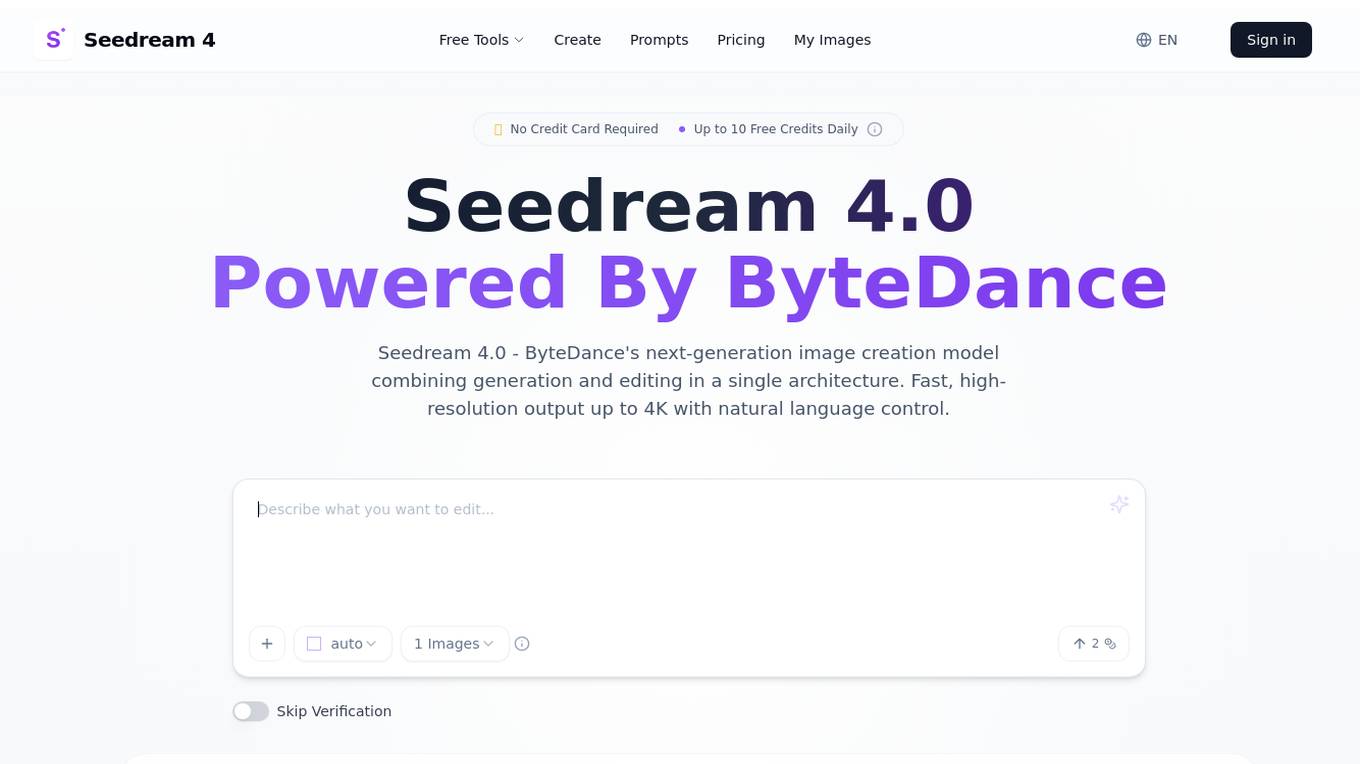
Seedream 4.0
Seedream 4.0 is a free advanced AI image editor powered by ByteDance, offering fast, high-resolution image creation with natural language control. It combines text-to-image generation and image editing in a single architecture, providing features like batch processing, versatile style transfer, and knowledge-driven generation. Users can upload images, describe prompts in natural language, and get instant results with professional quality outputs.
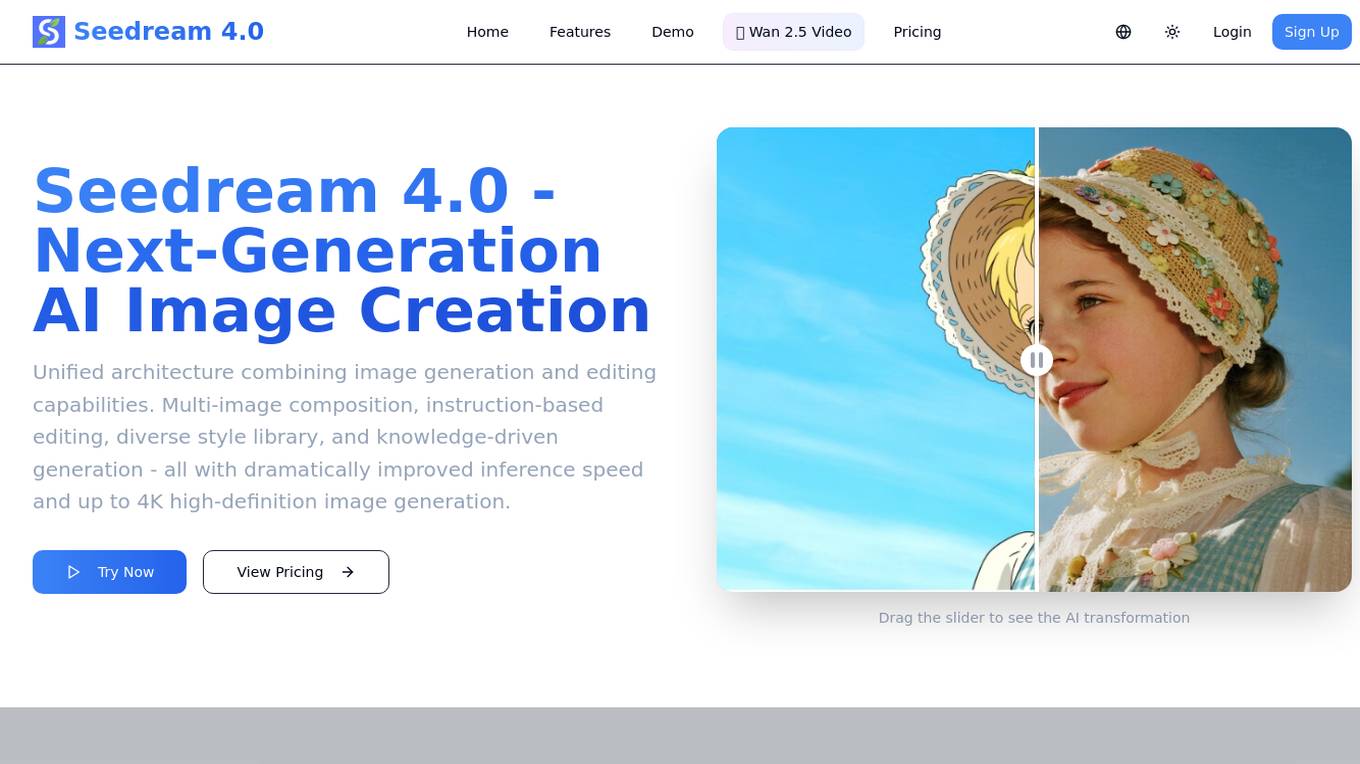
Seedream 4.0
Seedream 4.0 is an AI image generator and editor that offers a unified architecture combining image generation and editing capabilities. It provides features such as multi-image composition, instruction-based editing, diverse style library, and knowledge-driven generation. Users can experience the next generation of AI image creation with dramatically improved inference speed and up to 4K high-definition image generation.
Wondershare UniConverter
Wondershare UniConverter is a powerful and versatile video converter and compressor that supports over 1000 formats, including popular audio and video formats like MP4, MOV, MKV, WMV, MP3, and more. It also enables alpha channel video output in MP4 and WEBM formats. UniConverter is designed to process 4K/8K/HDR files with ease, and it offers a range of features to help you convert, compress, and edit your videos. These features include: * **High-speed conversion:** UniConverter is the fastest video converter on the market, with conversion speeds of up to 130X. This is thanks to its GPU-accelerated conversion engine, which takes advantage of the latest hardware to deliver lightning-fast performance. * **Lossless HD processing:** UniConverter preserves the quality of your videos during conversion, even when converting between different formats. This is thanks to its advanced video processing algorithms, which ensure that your videos look their best on any device. * **AI-powered enhancement:** UniConverter uses AI to enhance your videos, making them look and sound their best. This includes features like AI noise reduction, AI image enhancement, and AI scene detection. * **Extensive formats support:** UniConverter supports over 1000 audio and video formats, including MOV, AV1, MP4, etc., providing comprehensive coverage for all your file conversion needs.
ArtSpace.ai
ArtSpace.ai is an innovative AI tool that leverages artificial intelligence to revolutionize the art industry. It offers a platform where artists can showcase their work, connect with art enthusiasts, and gain exposure globally. The tool utilizes advanced algorithms to analyze art trends, provide personalized recommendations, and facilitate art sales. With ArtSpace.ai, artists can enhance their visibility, reach a wider audience, and boost their artistic careers.
Ray3 AI
Ray3 AI is an AI video generator tool that allows users to create high-quality videos effortlessly. With features like text-to-image conversion, image editing, and aspect ratio adjustment, Ray3 AI simplifies the video creation process. Users can generate videos in various formats, including 16:9 and 9:16, with auto credits costing 10 per creation. The tool is powered by Tencent Hunyuan LIVE 5.0 and offers a seamless user experience for both beginners and experienced video creators.
Clipchamp
Clipchamp is a free and easy-to-use video editor that allows users to create professional-quality videos without any prior experience. With a wide range of features and tools, Clipchamp makes it easy to create videos for any purpose, including YouTube, TikTok, Instagram, and Facebook. Clipchamp also offers a variety of templates and stock footage to help users get started quickly and easily.
VIVA.ai
VIVA is an AI-powered creative visual design platform that aims to bring every moment to life. It provides users with tools and features to create visually appealing designs effortlessly. With VIVA, users can unleash their creativity and design stunning visuals for various purposes such as social media posts, presentations, and marketing materials. The platform leverages artificial intelligence to streamline the design process and help users achieve professional-looking results without the need for advanced design skills.
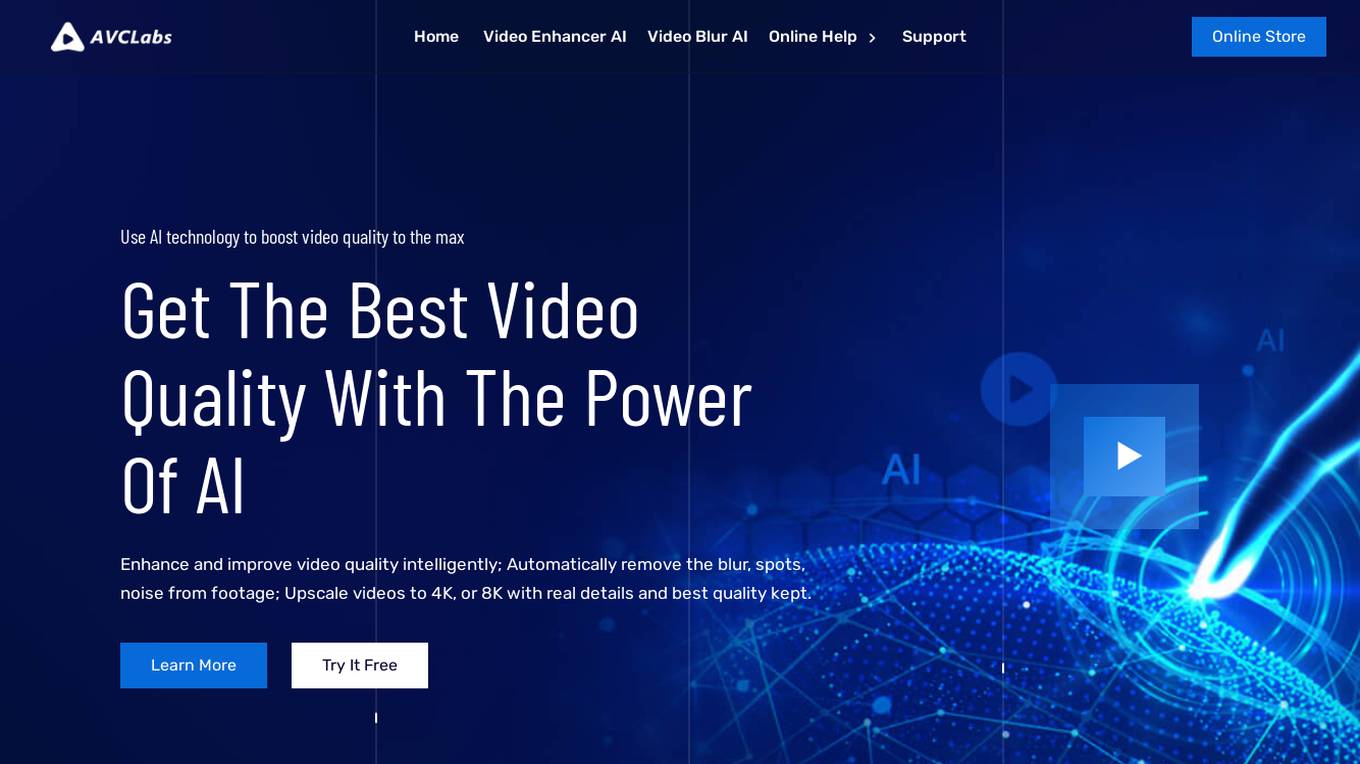
AVCLabs Video Enhancer AI
AVCLabs Video Enhancer AI is a powerful AI-powered video enhancement tool that can automatically improve the quality of your videos. With its advanced AI algorithms, it can remove blur, spots, noise, and other imperfections from your footage, and upscale it to 4K or even 8K resolution. It's easy to use, fully automatic, and can process videos of all types, including old home videos, films, recordings, animes, and cartoons.
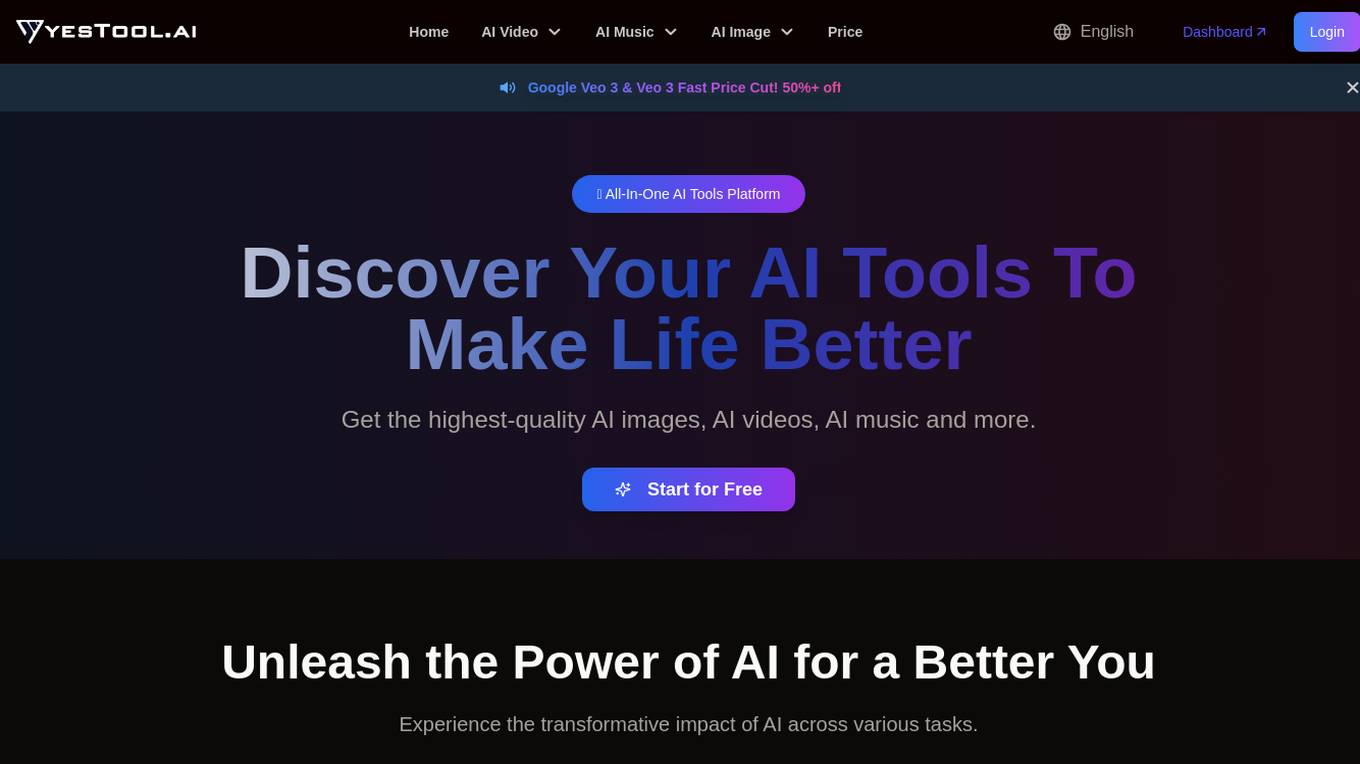
Yestool.ai
Yestool.ai is an all-in-one AI platform that offers a range of AI tools to create professional videos effortlessly. Users can input scripts, stories, or content descriptions into the AI-powered editor, which then processes the content to generate high-quality videos with visuals, voiceover, and music. The platform allows instant download and sharing of the created videos in HD quality, suitable for any platform. Yestool.ai also provides tools for upscaling videos, converting speech to video, generating music from text or lyrics, and creating images from text or existing images. With a focus on simplicity and efficiency, Yestool.ai aims to empower users to enhance their video creation process using advanced AI technology.
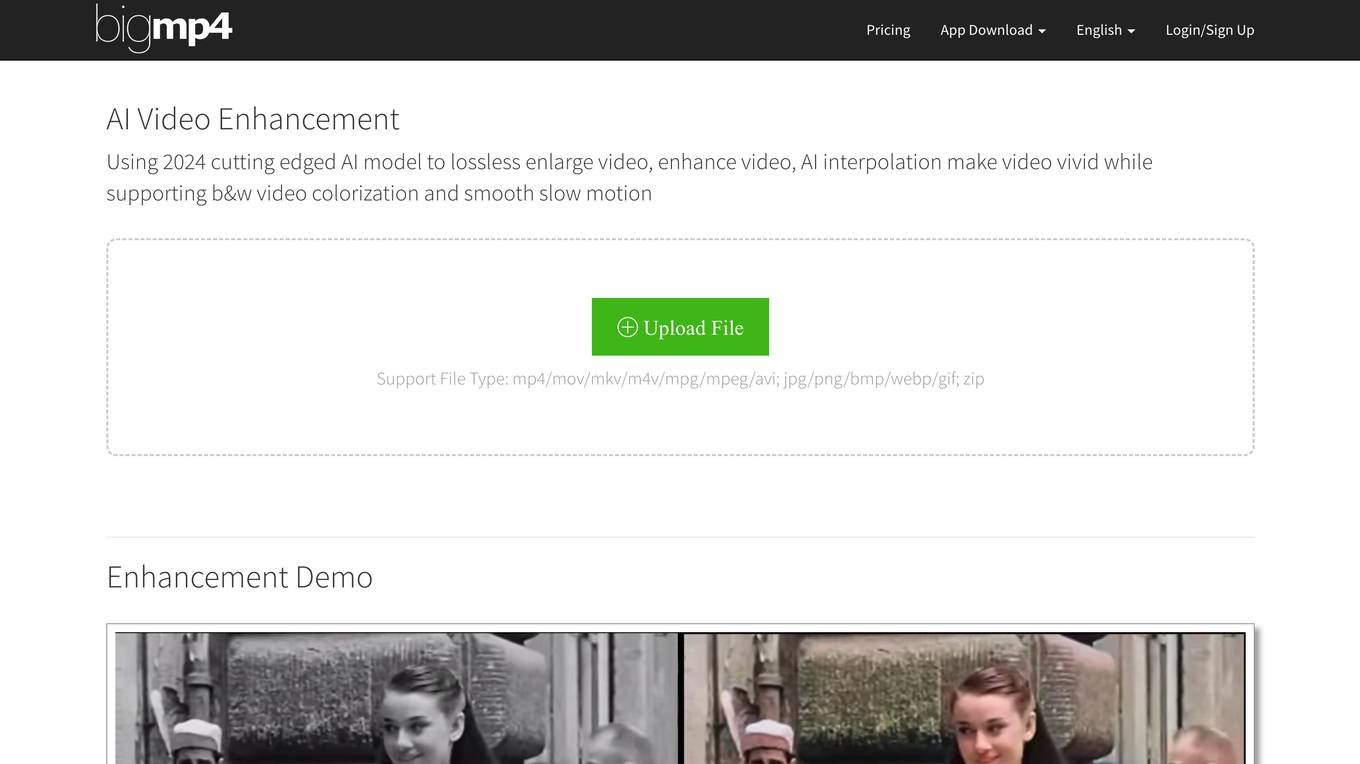
bigmp4
bigmp4 is an AI-powered video enhancement tool that uses cutting-edge AI models to enhance the quality of videos. It offers features such as lossless video enlargement, video enhancement, AI interpolation to make videos more vivid, black and white video colorization, and smooth slow motion. The tool supports various file formats, including mp4, mov, mkv, m4v, mpg, mpeg, avi, jpg, png, bmp, webp, and gif. It also supports batch mode processing, allowing users to upload multiple files for simultaneous processing.
Aimages
Aimages is an online AI video enhancer and upscaler that allows users to improve and upscale videos using AI technology directly from a web browser. The platform offers a simple and efficient way to enhance video quality in less than 3 minutes without the need for installation. Aimages is trusted by thousands of users and has been used to enhance thousands of videos and images daily, providing high-quality results with minimal artifacts.
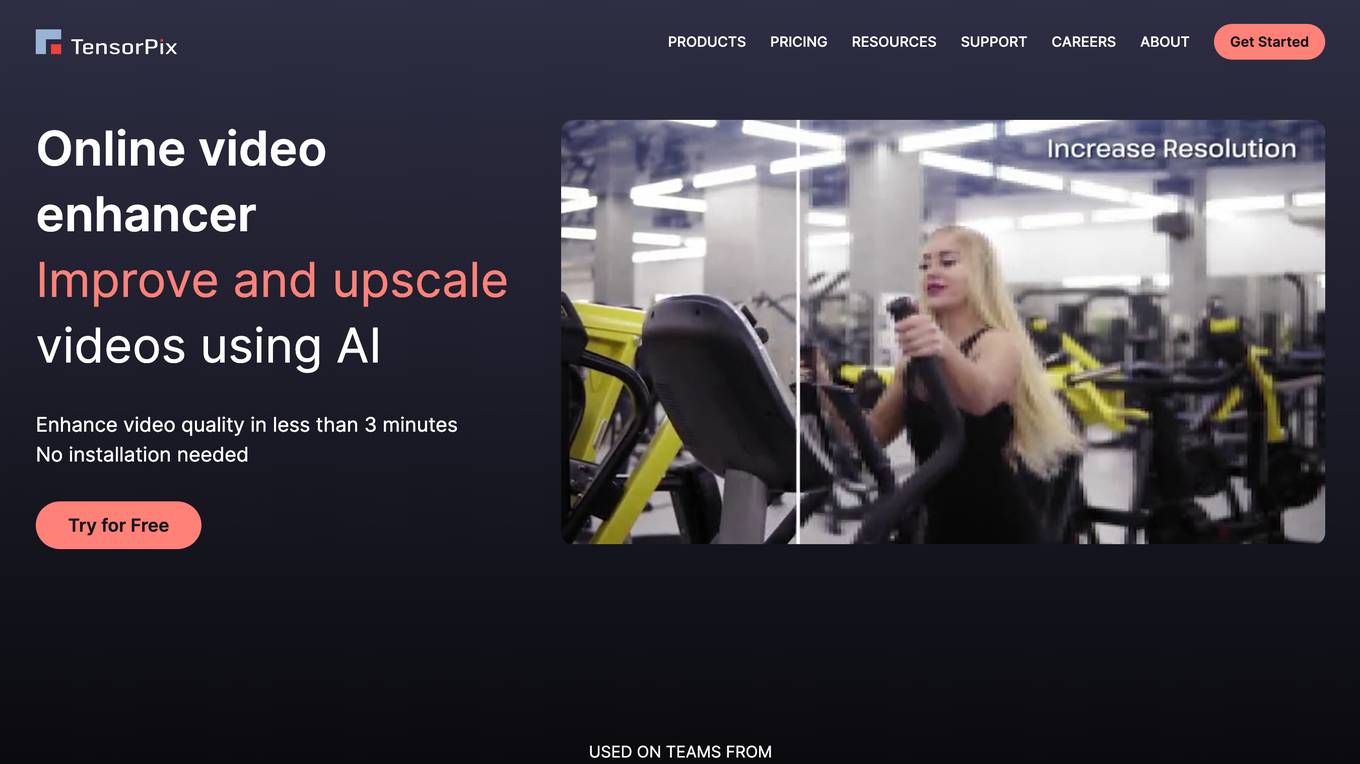
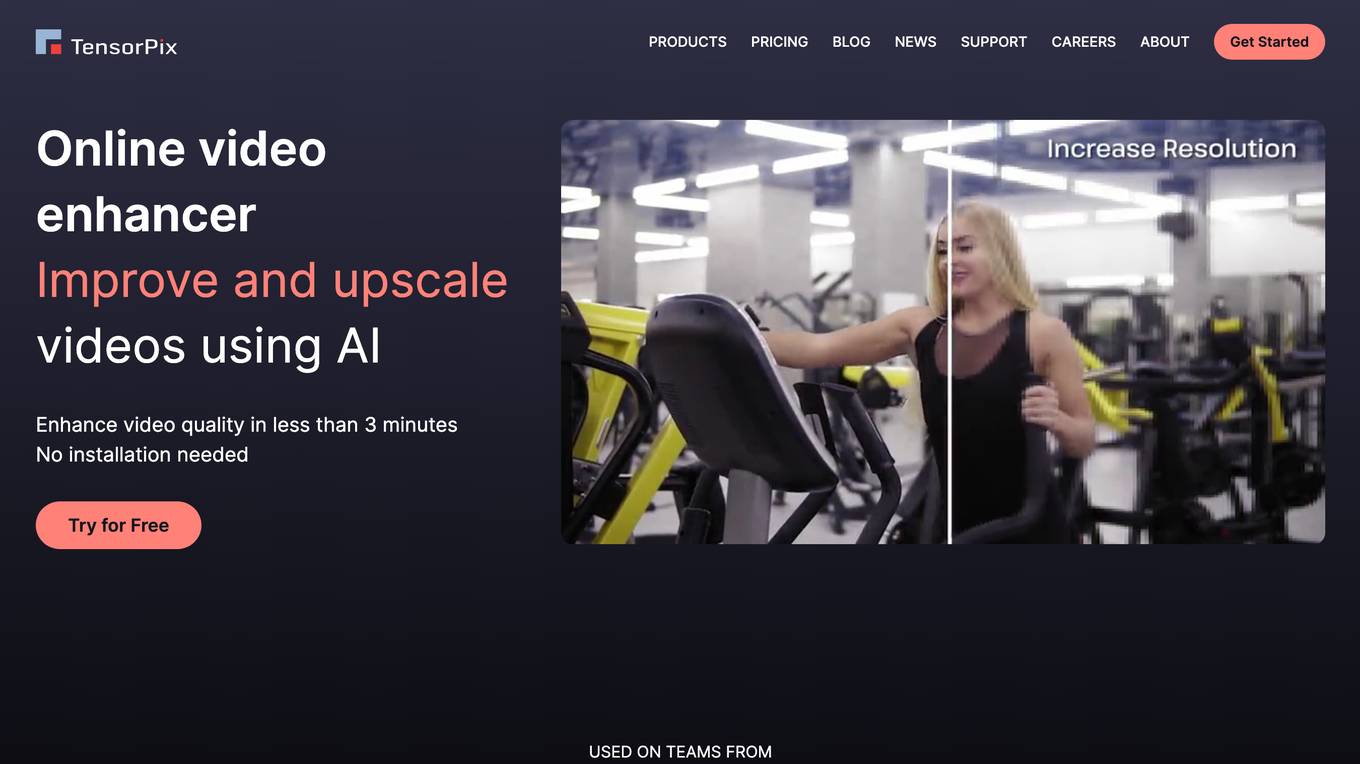
TensorPix
TensorPix is an online AI-powered video enhancer and upscaler that can improve and upscale videos in less than 3 minutes. It is a cloud-based service that can be used to enhance videos from any device, including smartphones and tablets. TensorPix uses AI to enhance video quality, including resolution, framerate, and color correction. It can also remove flickering, film dirt, and interlacing artifacts from old videos. TensorPix is used by thousands of users, including filmmakers, studios, and businesses. It is a powerful tool that can help you improve the quality of your videos and images.
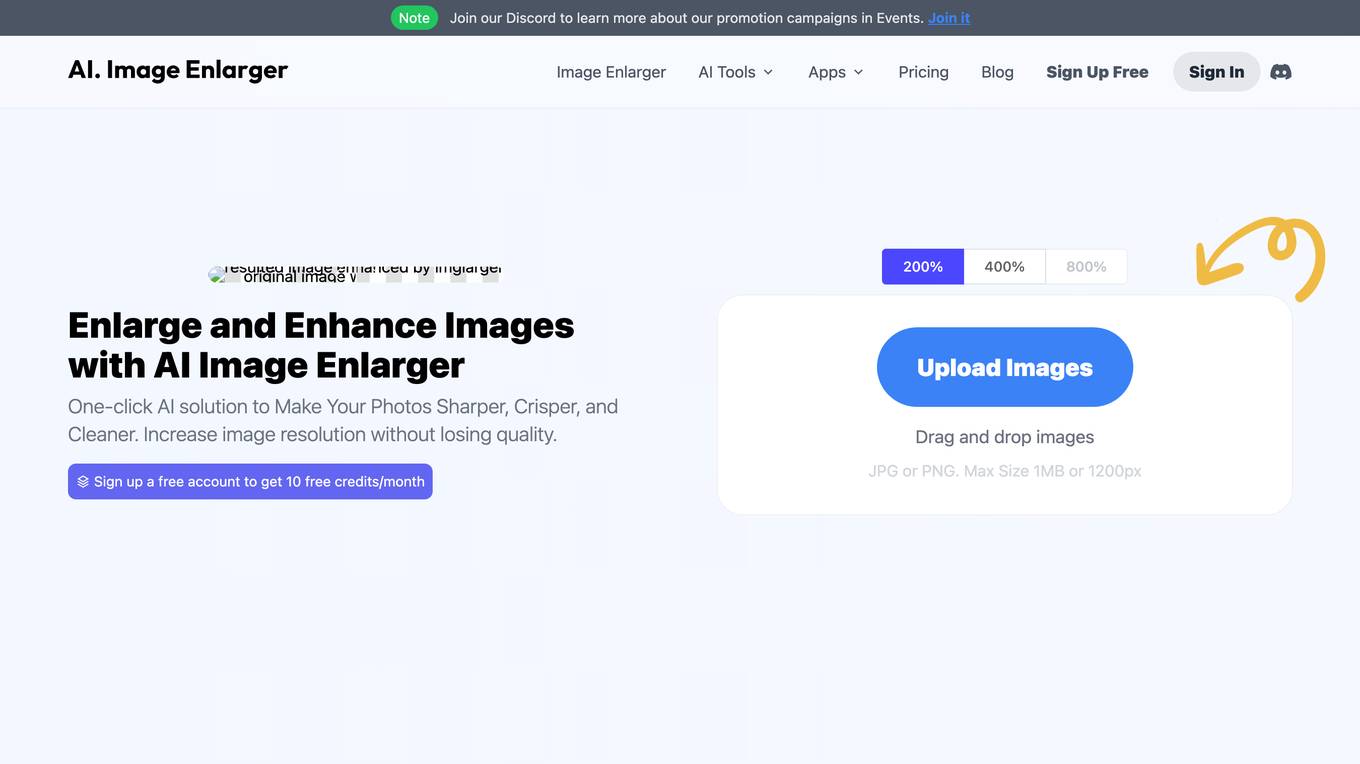
AI Image Enlarger
AI Image Enlarger is an online tool that allows users to enlarge images without losing quality. It uses artificial intelligence to upscale images, resulting in high-quality, detailed results. The tool is easy to use, simply drag and drop your image onto the website and select the desired enlargement factor. AI Image Enlarger is a great tool for photographers, graphic designers, and anyone who needs to enlarge images for any purpose.
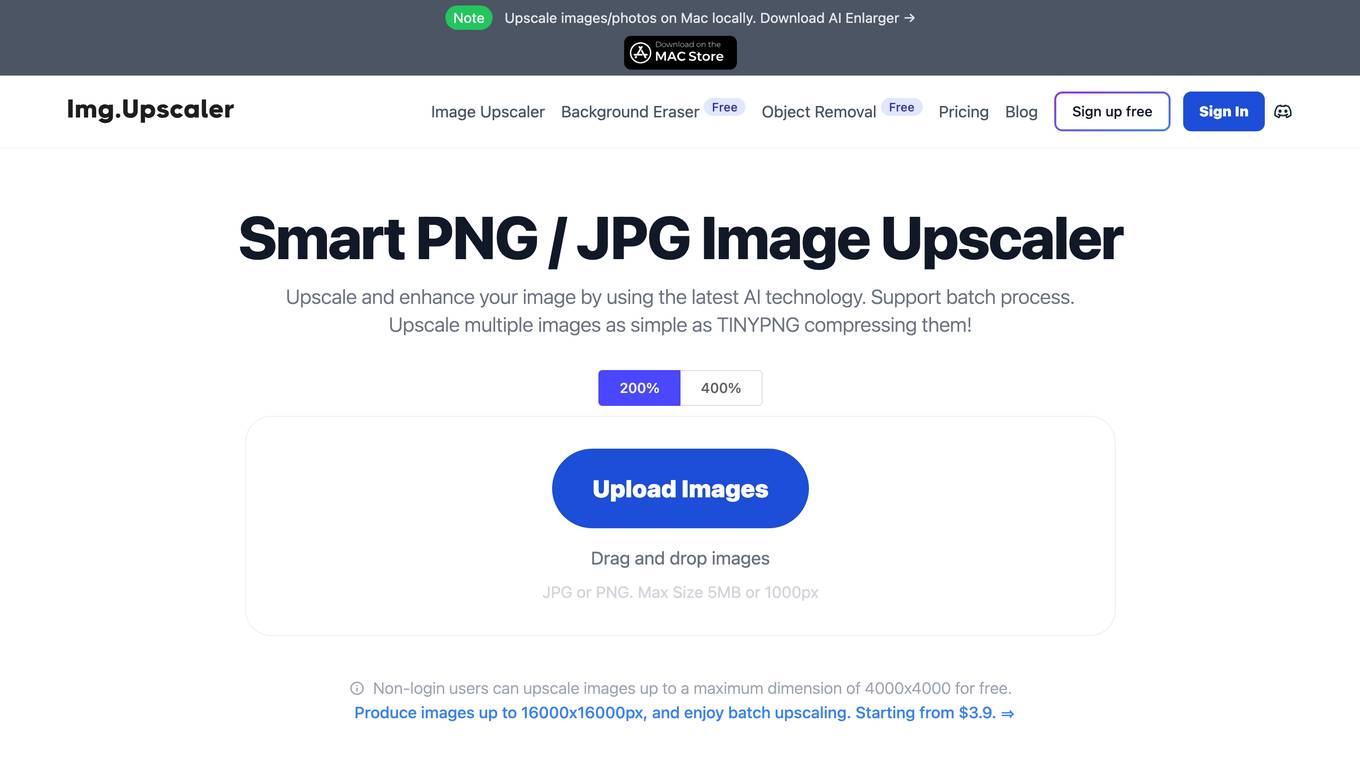
ImgUpscaler
ImgUpscaler is an AI-powered image upscaler that allows users to enhance and upscale images using deep learning and super-resolution technology. It supports batch processing, allowing users to upscale multiple images simultaneously. ImgUpscaler is particularly effective for upscaling anime and cartoon images, producing higher quality results compared to other tools like ImgLarger and Waifu2x. The tool is free to use for non-login users, with limitations on image size and batch processing. Paid plans starting from $3.9 are available for users who require higher resolution and batch processing capabilities.

Santa's Gift Helper GPT
I find the best-priced Christmas gifts locally or online. Upload or Paste your family and friends Christmas list and your zip code.
Correcteur d'orthographe et de grammaire
Je corrige les fautes d'orthographe et de grammaire en français et explique les erreurs.
LikeImFive GPT | Get Clear Answers Fast
"LikeImFive" is a specialized GPT designed to provide simplified explanations and clear answers to a wide range of everyday questions. It is tailored for those seeking to understand complex topics in simple, straightforward terms. No Fluff.
UpScaler
DALL-E user? Resize/de-noise images or uploads! Print & show-off your masterpiece or display in 4K! Supports 0.5x-4x to poster size. Abbreviations support. Enter your image prompt or, "m" for a menu to begin.
Asesor Laboral ES
Experto en asesoramiento jurídico laboral español basado en leyes vigentes 2024


OTP Prompt Generator
OTP Prompt Generator Helps Creates diverse, engaging prompts for fanfiction and role-play.

SA Speed Cameras
See if a mobile speed camera or roadwork is on a South Australian road today!
Singularity Academic Reviewer
Detailed academic reviewer focusing on integrity and accuracy, using verified sources. Start with customizations!

LongRAG
This repository contains the code for LongRAG, a framework that enhances retrieval-augmented generation with long-context LLMs. LongRAG introduces a 'long retriever' and a 'long reader' to improve performance by using a 4K-token retrieval unit, offering insights into combining RAG with long-context LLMs. The repo provides instructions for installation, quick start, corpus preparation, long retriever, and long reader.

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.
react-native-vision-camera
VisionCamera is a powerful, high-performance Camera library for React Native. It features Photo and Video capture, QR/Barcode scanner, Customizable devices and multi-cameras ("fish-eye" zoom), Customizable resolutions and aspect-ratios (4k/8k images), Customizable FPS (30..240 FPS), Frame Processors (JS worklets to run facial recognition, AI object detection, realtime video chats, ...), Smooth zooming (Reanimated), Fast pause and resume, HDR & Night modes, Custom C++/GPU accelerated video pipeline (OpenGL).

InternLM-XComposer
InternLM-XComposer2 is a groundbreaking vision-language large model (VLLM) based on InternLM2-7B excelling in free-form text-image composition and comprehension. It boasts several amazing capabilities and applications: * **Free-form Interleaved Text-Image Composition** : InternLM-XComposer2 can effortlessly generate coherent and contextual articles with interleaved images following diverse inputs like outlines, detailed text requirements and reference images, enabling highly customizable content creation. * **Accurate Vision-language Problem-solving** : InternLM-XComposer2 accurately handles diverse and challenging vision-language Q&A tasks based on free-form instructions, excelling in recognition, perception, detailed captioning, visual reasoning, and more. * **Awesome performance** : InternLM-XComposer2 based on InternLM2-7B not only significantly outperforms existing open-source multimodal models in 13 benchmarks but also **matches or even surpasses GPT-4V and Gemini Pro in 6 benchmarks** We release InternLM-XComposer2 series in three versions: * **InternLM-XComposer2-4KHD-7B** 🤗: The high-resolution multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _High-resolution understanding_ , _VL benchmarks_ and _AI assistant_. * **InternLM-XComposer2-VL-7B** 🤗 : The multi-task trained VLLM model with InternLM-7B as the initialization of the LLM for _VL benchmarks_ and _AI assistant_. **It ranks as the most powerful vision-language model based on 7B-parameter level LLMs, leading across 13 benchmarks.** * **InternLM-XComposer2-VL-1.8B** 🤗 : A lightweight version of InternLM-XComposer2-VL based on InternLM-1.8B. * **InternLM-XComposer2-7B** 🤗: The further instruction tuned VLLM for _Interleaved Text-Image Composition_ with free-form inputs. Please refer to Technical Report and 4KHD Technical Reportfor more details.
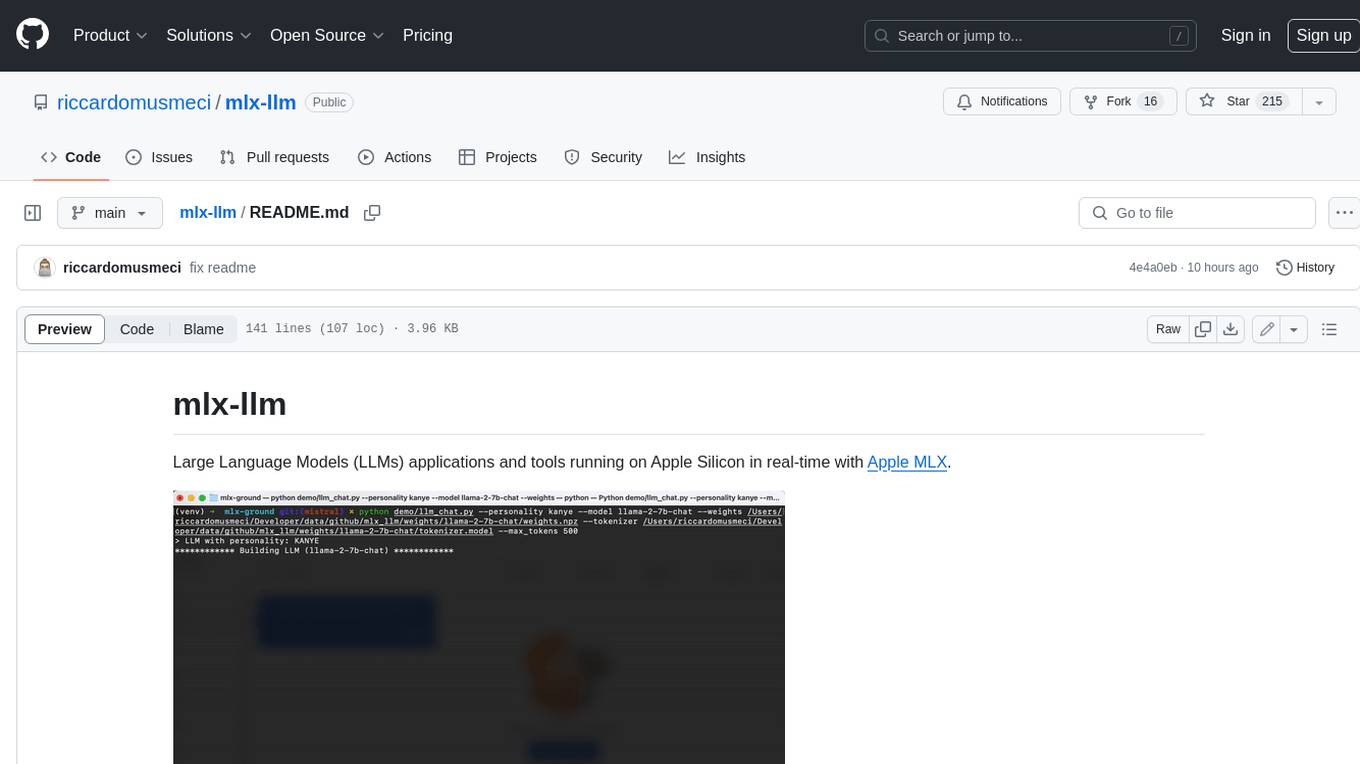
mlx-llm
mlx-llm is a library that allows you to run Large Language Models (LLMs) on Apple Silicon devices in real-time using Apple's MLX framework. It provides a simple and easy-to-use API for creating, loading, and using LLM models, as well as a variety of applications such as chatbots, fine-tuning, and retrieval-augmented generation.
ai-clone-whatsapp
This repository provides a tool to create an AI chatbot clone of yourself using your WhatsApp chats as training data. It utilizes the Torchtune library for finetuning and inference. The code includes preprocessing of WhatsApp chats, finetuning models, and chatting with the AI clone via a command-line interface. Supported models are Llama3-8B-Instruct and Mistral-7B-Instruct-v0.2. Hardware requirements include approximately 16 GB vRAM for QLoRa Llama3 finetuning with a 4k context length. The repository addresses common issues like adjusting parameters for training and preprocessing non-English chats.
BurstGPT
This repository provides a real-world trace dataset of LLM serving workloads for research and academic purposes. The dataset includes two files, BurstGPT.csv with trace data for 2 months including some failures, and BurstGPT_without_fails.csv without any failures. Users can scale the RPS in the trace, model patterns, and leverage the trace for various evaluations. Future plans include updating the time range of the trace, adding request end times, updating conversation logs, and open-sourcing a benchmark suite for LLM inference. The dataset covers 61 consecutive days, contains 1.4 million lines, and is approximately 50MB in size.

LLM-TPU
LLM-TPU project aims to deploy various open-source generative AI models on the BM1684X chip, with a focus on LLM. Models are converted to bmodel using TPU-MLIR compiler and deployed to PCIe or SoC environments using C++ code. The project has deployed various open-source models such as Baichuan2-7B, ChatGLM3-6B, CodeFuse-7B, DeepSeek-6.7B, Falcon-40B, Phi-3-mini-4k, Qwen-7B, Qwen-14B, Qwen-72B, Qwen1.5-0.5B, Qwen1.5-1.8B, Llama2-7B, Llama2-13B, LWM-Text-Chat, Mistral-7B-Instruct, Stable Diffusion, Stable Diffusion XL, WizardCoder-15B, Yi-6B-chat, Yi-34B-chat. Detailed model deployment information can be found in the 'models' subdirectory of the project. For demonstrations, users can follow the 'Quick Start' section. For inquiries about the chip, users can contact SOPHGO via the official website.
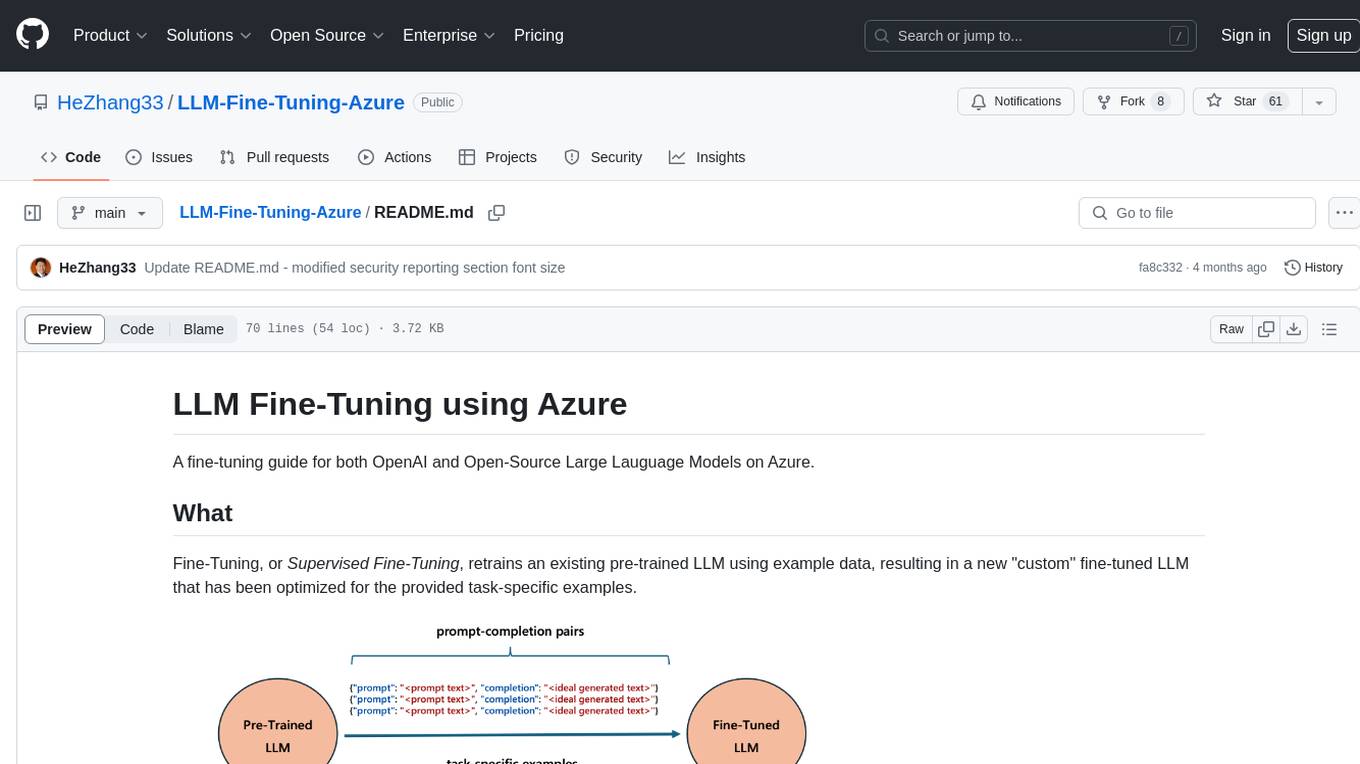
LLM-Fine-Tuning-Azure
A fine-tuning guide for both OpenAI and Open-Source Large Language Models on Azure. Fine-Tuning retrains an existing pre-trained LLM using example data, resulting in a new 'custom' fine-tuned LLM optimized for task-specific examples. Use cases include improving LLM performance on specific tasks and introducing information not well represented by the base LLM model. Suitable for cases where latency is critical, high accuracy is required, and clear evaluation metrics are available. Learning path includes labs for fine-tuning GPT and Llama2 models via Dashboards and Python SDK.

LongRoPE
LongRoPE is a method to extend the context window of large language models (LLMs) beyond 2 million tokens. It identifies and exploits non-uniformities in positional embeddings to enable 8x context extension without fine-tuning. The method utilizes a progressive extension strategy with 256k fine-tuning to reach a 2048k context. It adjusts embeddings for shorter contexts to maintain performance within the original window size. LongRoPE has been shown to be effective in maintaining performance across various tasks from 4k to 2048k context lengths.
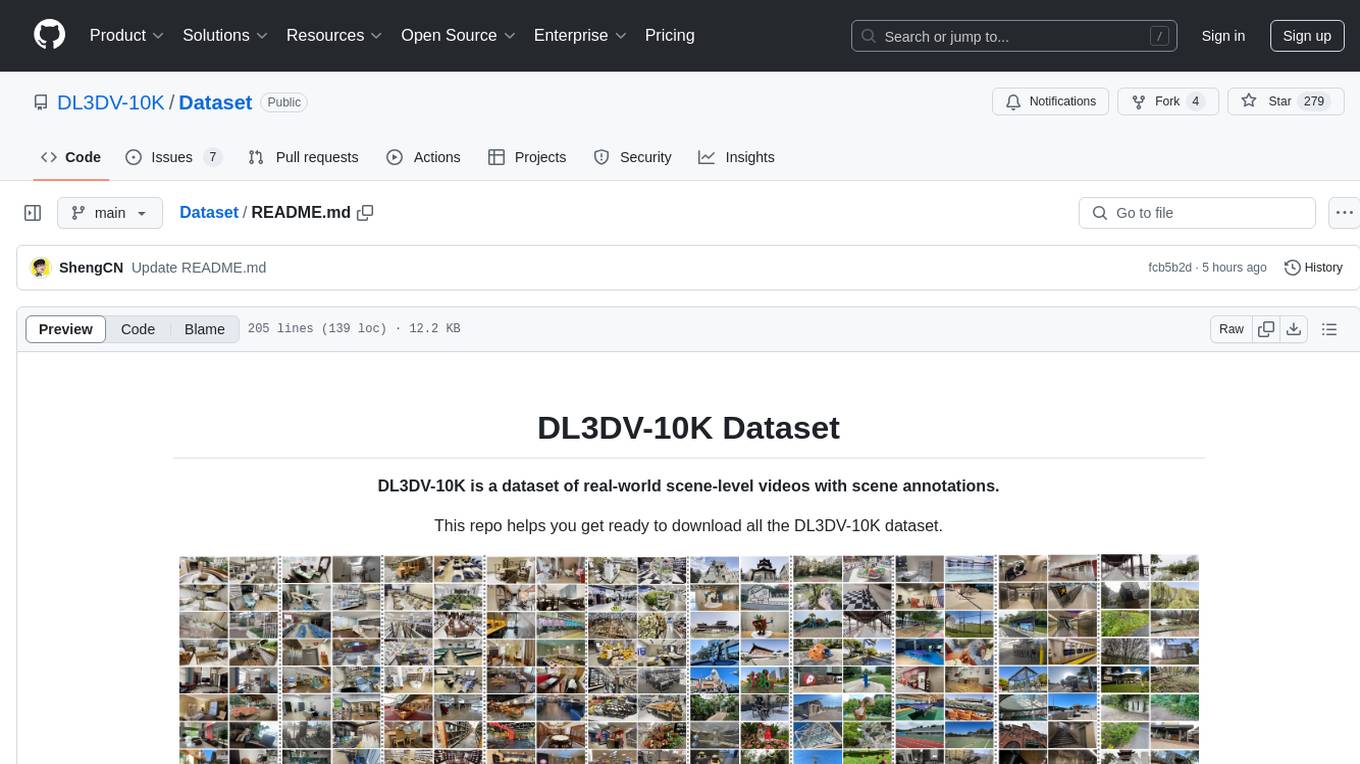
Dataset
DL3DV-10K is a large-scale dataset of real-world scene-level videos with annotations, covering diverse scenes with different levels of reflection, transparency, and lighting. It includes 10,510 multi-view scenes with 51.2 million frames at 4k resolution, and offers benchmark videos for novel view synthesis (NVS) methods. The dataset is designed to facilitate research in deep learning-based 3D vision and provides valuable insights for future research in NVS and 3D representation learning.
yalm
Yalm (Yet Another Language Model) is an LLM inference implementation in C++/CUDA, emphasizing performance engineering, documentation, scientific optimizations, and readability. It is not for production use and has been tested on Mistral-v0.2 and Llama-3.2. Requires C++20-compatible compiler, CUDA toolkit, and LLM safetensor weights in huggingface format converted to .yalm file.

onnxruntime-genai
ONNX Runtime Generative AI is a library that provides the generative AI loop for ONNX models, including inference with ONNX Runtime, logits processing, search and sampling, and KV cache management. Users can call a high level `generate()` method, or run each iteration of the model in a loop. It supports greedy/beam search and TopP, TopK sampling to generate token sequences, has built in logits processing like repetition penalties, and allows for easy custom scoring.
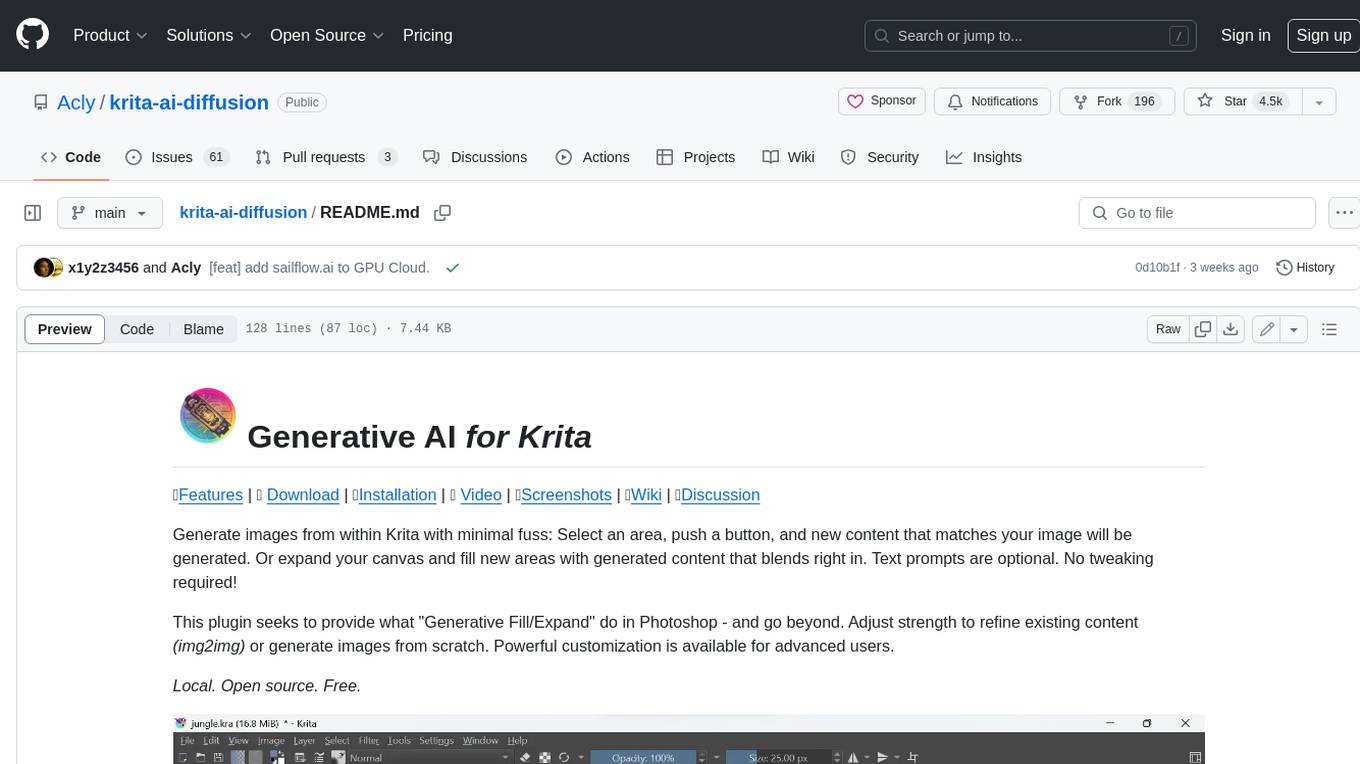
krita-ai-diffusion
Krita-AI-Diffusion is a plugin for Krita that allows users to generate images from within the program. It offers a variety of features, including inpainting, outpainting, generating images from scratch, refining existing content, live painting, and control over image creation. The plugin is designed to fit into an interactive workflow where AI generation is used as just another tool while painting. It is meant to synergize with traditional tools and the layer stack.
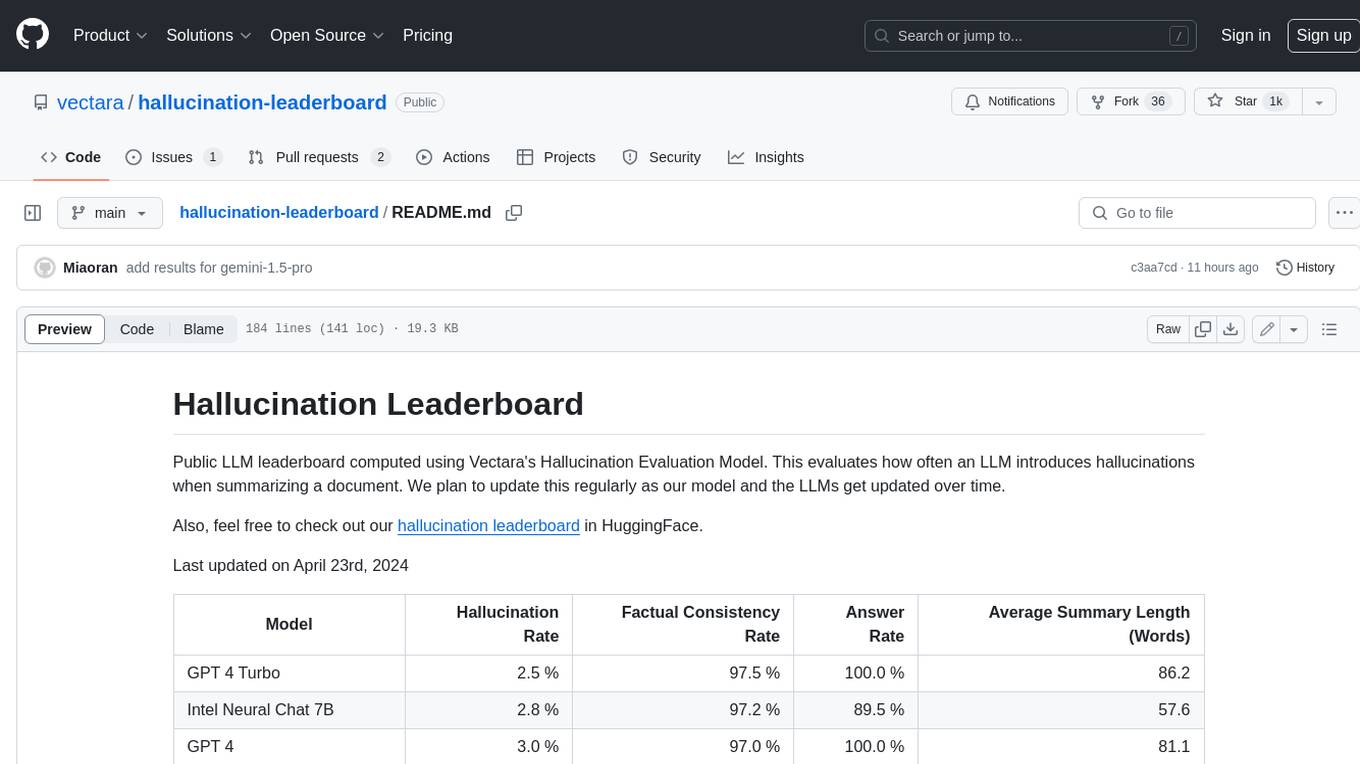
hallucination-leaderboard
This leaderboard evaluates the hallucination rate of various Large Language Models (LLMs) when summarizing documents. It uses a model trained by Vectara to detect hallucinations in LLM outputs. The leaderboard includes models from OpenAI, Anthropic, Google, Microsoft, Amazon, and others. The evaluation is based on 831 documents that were summarized by all the models. The leaderboard shows the hallucination rate, factual consistency rate, answer rate, and average summary length for each model.
Awesome-Chinese-LLM
Analyze the following text from a github repository (name and readme text at end) . Then, generate a JSON object with the following keys and provide the corresponding information for each key, ,'for_jobs' (List 5 jobs suitable for this tool,in lowercase letters), 'ai_keywords' (keywords of the tool,in lowercase letters), 'for_tasks' (list of 5 specific tasks user can use this tool to do,in less than 3 words,Verb + noun form,in daily spoken language,in lowercase letters).Answer in english languagesname:Awesome-Chinese-LLM readme:# Awesome Chinese LLM   An Awesome Collection for LLM in Chinese 收集和梳理中文LLM相关    自ChatGPT为代表的大语言模型(Large Language Model, LLM)出现以后,由于其惊人的类通用人工智能(AGI)的能力,掀起了新一轮自然语言处理领域的研究和应用的浪潮。尤其是以ChatGLM、LLaMA等平民玩家都能跑起来的较小规模的LLM开源之后,业界涌现了非常多基于LLM的二次微调或应用的案例。本项目旨在收集和梳理中文LLM相关的开源模型、应用、数据集及教程等资料,目前收录的资源已达100+个! 如果本项目能给您带来一点点帮助,麻烦点个⭐️吧~ 同时也欢迎大家贡献本项目未收录的开源模型、应用、数据集等。提供新的仓库信息请发起PR,并按照本项目的格式提供仓库链接、star数,简介等相关信息,感谢~

LLaVA-pp
This repository, LLaVA++, extends the visual capabilities of the LLaVA 1.5 model by incorporating the latest LLMs, Phi-3 Mini Instruct 3.8B, and LLaMA-3 Instruct 8B. It provides various models for instruction-following LMMS and academic-task-oriented datasets, along with training scripts for Phi-3-V and LLaMA-3-V. The repository also includes installation instructions and acknowledgments to related open-source contributions.

AgentBench
AgentBench is a benchmark designed to evaluate Large Language Models (LLMs) as autonomous agents in various environments. It includes 8 distinct environments such as Operating System, Database, Knowledge Graph, Digital Card Game, and Lateral Thinking Puzzles. The tool provides a comprehensive evaluation of LLMs' ability to operate as agents by offering Dev and Test sets for each environment. Users can quickly start using the tool by following the provided steps, configuring the agent, starting task servers, and assigning tasks. AgentBench aims to bridge the gap between LLMs' proficiency as agents and their practical usability.
fms-fsdp
The 'fms-fsdp' repository is a companion to the Foundation Model Stack, providing a (pre)training example to efficiently train FMS models, specifically Llama2, using native PyTorch features like FSDP for training and SDPA implementation of Flash attention v2. It focuses on leveraging FSDP for training efficiently, not as an end-to-end framework. The repo benchmarks training throughput on different GPUs, shares strategies, and provides installation and training instructions. It trained a model on IBM curated data achieving high efficiency and performance metrics.