
free-llm-collect
搜集免费的LLM(大语言模型)API(GPT、Claude、BingCopilot、Llama、Gemini)
Stars: 132
This repository is a collection of free large language models (LLMs) that can be used for various natural language processing tasks. It includes information on different free LLM APIs and projects that can be deployed without cost. Users can find details on the performance, login requirements, function calling capabilities, and deployment environments of each listed LLM source.
README:
搜集免费的LLM(大语言模型)
之前一直用的公司的GPT API key做机器人,结果后来被收回了,又不想掏钱,只能上网寻觅下免费的LLM API,这里做个记录
注:这里记录的都是可以用来部署的项目或者官方API
- DeepSeek
-
OpenRouter提供的免费R1
- 使用体验:响应较快
- 是否需要登录或cookie:需要API key
- 是否能够函数调用:否
- 是否需要外网环境部署:未知
-
硅基流动提供的免费蒸馏R1
- 使用体验:响应很慢
- 是否需要登录或cookie:需要API key
- 是否能够函数调用:是
- 是否需要外网环境部署:否
-
无问芯穹提供的免费R1
- 使用体验:响应较快
- 是否需要登录或cookie:需要API key
- 是否能够函数调用:否
- 是否需要外网环境部署:否
-
OpenRouter提供的免费R1
- GPT
-
官网无需登录ChatGPT逆向
- 使用体验:响应慢,偶尔抽风,不稳定
- 是否需要登录或cookie:无需
- 是否能够函数调用:否
- 是否需要外网环境部署:是
-
字节Coze海外平台提供的免费GPT
- 使用体验:响应慢,有次数限制,十分稳定
- 是否需要登录或cookie:因为使用了discord,需要传discord的cookie,cookie生命周期很长
- 是否能够函数调用:否
- 是否需要外网环境部署:是
-
DuckDuckGo提供的免费GPT3.5
- 使用体验:响应较快,较稳定
- 是否需要登录或cookie:无需
- 是否能够函数调用:否
- 是否需要外网环境部署:是
-
ChandlerAi提供的免费GPT3.5
- 使用体验:响应较快,较稳定
- 是否需要登录或cookie:需要自己抓取token
- 是否能够函数调用:否
- 是否需要外网环境部署:否
-
官网无需登录ChatGPT逆向
- Claude
-
DuckDuckGo提供的免费Claude3Haiku
- 使用体验:响应较快,较稳定
- 是否需要登录或cookie:无需
- 其他:这个项目没有增加Claude模型,可以自行寻找其他项目,或者自己改
- 是否能够函数调用:否
- 是否需要外网环境部署:是
-
DuckDuckGo提供的免费Claude3Haiku
- Bing Copilot
-
BingAI逆向
- 使用体验:响应很慢,不稳定
- 是否需要登录或cookie:需要在UI界面中登录或填cookie
- 是否能够函数调用:否
- 是否需要外网环境部署:是
-
BingAI逆向
- Gemini
-
Gemini免费套餐
- 使用体验:响应很快,十分稳定,免费版有调用量限制,对于个人而言完全够用了
- 是否需要登录或cookie:需要API key
- 是否能够函数调用:是
- 是否需要外网环境访问:是
-
Gemini免费套餐
- LLama
-
nvidia免费套餐使用体验:响应很快,十分稳定,尚不清楚调用量上限是否需要登录或cookie:使用nvidia提供的API key是否需要外网环境访问:否- 有免费额度,用完即没
-
HuggingFace提供的免费Chat逆向
- 这里有个我自己写的,已有的一个python的项目我没调用成功
- 使用体验:响应较快,较稳定,尚不清楚调用量上限
- 是否需要登录或cookie:需要cookie
- 是否能够函数调用:否
- 是否需要外网环境部署:是
-
CloudFlare免费套餐
- 使用体验:响应很快,十分稳定,尚不清楚调用量上限
- 是否需要登录或cookie:需要API key
- 是否能够函数调用:否
- 是否需要外网环境访问:否
-
Groq免费套餐
- 使用体验:响应较快,不稳定,有封号风险,挂的日本的梯子也没聊啥就被封了
- 是否需要登录或cookie:需要API key
- 是否需要外网环境访问:是
-
ChandlerAi提供的免费LLama3
- 使用体验:响应较快,较稳定
- 是否需要登录或cookie:需要抓token
- 是否能够函数调用:否
- 是否需要外网环境部署:否
-
- 国产模型
-
智谱清言免费套餐
- 使用体验:响应较快,很稳定,仅限glm-4-flash免费
- 是否需要登录或cookie:需要API key
- 是否能够函数调用:是
- 是否需要外网环境部署:否
-
阿里 通义千问逆向
- 使用体验:响应较快,很稳定
- 是否需要登录或cookie:需要API key
- 是否能够函数调用:否
- 是否需要外网环境部署:否
-
月之暗面 Kimi逆向
- 使用体验:响应较快,很稳定,据说有封号风险
- 是否需要登录或cookie:需要API key
- 是否能够函数调用:否
- 是否需要外网环境部署:否
-
阶跃星辰 跃问逆向
- 使用体验:响应较快,很稳定
- 是否需要登录或cookie:需要API key
- 是否能够函数调用:否
- 是否需要外网环境部署:否
-
智谱清言 GLM逆向
- 使用体验:响应较快,很稳定
- 是否需要登录或cookie:需要API key
- 是否能够函数调用:否
- 是否需要外网环境部署:否
-
讯飞 星火逆向
- 使用体验:响应较快,很稳定
- 是否需要登录或cookie:需要API key
- 是否能够函数调用:否
- 是否需要外网环境部署:否
-
秘塔AI逆向
- 使用体验:未使用过
- 是否需要登录或cookie:需要API key
- 是否能够函数调用:否
- 是否需要外网环境部署:否
-
海螺AI逆向
- 使用体验:未使用过
- 是否需要登录或cookie:需要API key
- 是否能够函数调用:否
- 是否需要外网环境部署:否
-
聆心智能逆向
- 使用体验:未使用过
- 是否需要登录或cookie:需要API key
- 是否能够函数调用:否
- 是否需要外网环境部署:否
-
智谱清言免费套餐
- 其他模型
-
siliconflow
- 使用体验:响应较快,但免费的都是一些国内的非旗舰模型,另有FLUX.1、sd等文生图模型限时免费!
- 是否需要外网环境部署:否
-
mistral免费套餐
- 使用体验:响应较快,不太稳定
- 是否需要登录或cookie:需要API key
- 是否需要外网环境部署:否
- 是否能够函数调用:是
-
glhf免费API
- 使用体验:响应较慢。包含一些开源的旗舰模型,还可以自己部署模型
- 是否需要登录或cookie:需要API key
- 是否能够函数调用:否
- 是否需要外网环境部署:否
-
siliconflow
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for free-llm-collect
Similar Open Source Tools
free-llm-collect
This repository is a collection of free large language models (LLMs) that can be used for various natural language processing tasks. It includes information on different free LLM APIs and projects that can be deployed without cost. Users can find details on the performance, login requirements, function calling capabilities, and deployment environments of each listed LLM source.

terraform-provider-airbyte
Programatically control Airbyte Cloud through an API. Developers can create an API Key within the Developer Portal to make API requests. The provider allows for integration building by showing network request information and API usage details. It offers resources and data sources for various destinations and sources, enabling users to manage data flow between different services.
hongbomiao.com
hongbomiao.com is a personal research and development (R&D) lab that facilitates the sharing of knowledge. The repository covers a wide range of topics including web development, mobile development, desktop applications, API servers, cloud native technologies, data processing, machine learning, computer vision, embedded systems, simulation, database management, data cleaning, data orchestration, testing, ops, authentication, authorization, security, system tools, reverse engineering, Ethereum, hardware, network, guidelines, design, bots, and more. It provides detailed information on various tools, frameworks, libraries, and platforms used in these domains.
llm_interview_note
This repository provides a comprehensive overview of large language models (LLMs), covering various aspects such as their history, types, underlying architecture, training techniques, and applications. It includes detailed explanations of key concepts like Transformer models, distributed training, fine-tuning, and reinforcement learning. The repository also discusses the evaluation and limitations of LLMs, including the phenomenon of hallucinations. Additionally, it provides a list of related courses and references for further exploration.
LLM_book
LLM_book is a learning record and roadmap for programmers with a certain AI foundation to learn Large Language Models (LLM). It covers topics such as PyTorch basics, Transformer architecture, langchain basics, foundational concepts of large models, fine-tuning methods, RAG (Retrieval-Augmented Generation), and building intelligent agents using LLM. The repository provides learning materials, code implementations, and documentation to help users progress in understanding and implementing LLM technologies.
LLM-Navigation
LLM-Navigation is a repository dedicated to documenting learning records related to large models, including basic knowledge, prompt engineering, building effective agents, model expansion capabilities, security measures against prompt injection, and applications in various fields such as AI agent control, browser automation, financial analysis, 3D modeling, and tool navigation using MCP servers. The repository aims to organize and collect information for personal learning and self-improvement through AI exploration.
AcademicForge
Academic Forge is a collection of skills integrated for academic writing workflows. It provides a curated set of skills related to academic writing and research, allowing for precise skill calls, avoiding confusion between similar skills, maintaining focus on research workflows, and receiving timely updates from original authors. The forge integrates carefully selected skills covering various areas such as bioinformatics, clinical research, data analysis, scientific writing, laboratory automation, machine learning, databases, AI research, model architectures, fine-tuning, post-training, distributed training, optimization, inference, evaluation, agents, multimodal tasks, and machine learning paper writing. It is designed to streamline the academic writing and AI research processes by providing a cohesive and community-driven collection of skills.
DeepBattler
DeepBattler is a tool designed for Hearthstone Battlegrounds players, providing real-time strategic advice and insights to improve gameplay experience. It integrates with the Hearthstone Deck Tracker plugin and offers voice-assisted guidance. The tool is powered by a large language model (LLM) and can match the strength of top players on EU servers. Users can set up the tool by adding dependencies, configuring the plugin path, and launching the LLM agent. DeepBattler is licensed for personal, educational, and non-commercial use, with guidelines on non-commercial distribution and acknowledgment of external contributions.
chatwiki
ChatWiki is an open-source knowledge base AI question-answering system. It is built on large language models (LLM) and retrieval-augmented generation (RAG) technologies, providing out-of-the-box data processing, model invocation capabilities, and helping enterprises quickly build their own knowledge base AI question-answering systems. It offers exclusive AI question-answering system, easy integration of models, data preprocessing, simple user interface design, and adaptability to different business scenarios.
ai_wiki
This repository provides a comprehensive collection of resources, open-source tools, and knowledge related to quantitative analysis. It serves as a valuable knowledge base and navigation guide for individuals interested in various aspects of quantitative investing, including platforms, programming languages, mathematical foundations, machine learning, deep learning, and practical applications. The repository is well-structured and organized, with clear sections covering different topics. It includes resources on system platforms, programming codes, mathematical foundations, algorithm principles, machine learning, deep learning, reinforcement learning, graph networks, model deployment, and practical applications. Additionally, there are dedicated sections on quantitative trading and investment, as well as large models. The repository is actively maintained and updated, ensuring that users have access to the latest information and resources.
Daily-DeepLearning
Daily-DeepLearning is a repository that covers various computer science topics such as data structures, operating systems, computer networks, Python programming, data science packages like numpy, pandas, matplotlib, machine learning theories, deep learning theories, NLP concepts, machine learning practical applications, deep learning practical applications, and big data technologies like Hadoop and Hive. It also includes coding exercises related to '剑指offer'. The repository provides detailed explanations and examples for each topic, making it a comprehensive resource for learning and practicing different aspects of computer science and data-related fields.
AI-Catalog
AI-Catalog is a curated list of AI tools, platforms, and resources across various domains. It serves as a comprehensive repository for users to discover and explore a wide range of AI applications. The catalog includes tools for tasks such as text-to-image generation, summarization, prompt generation, writing assistance, code assistance, developer tools, low code/no code tools, audio editing, video generation, 3D modeling, search engines, chatbots, email assistants, fun tools, gaming, music generation, presentation tools, website builders, education assistants, autonomous AI agents, photo editing, AI extensions, deep face/deep fake detection, text-to-speech, startup tools, SQL-related AI tools, education tools, and text-to-video conversion.
CyberSentinel-AI
CyberSentinel AI is a powerful automated security monitoring and AI analysis system designed to help security researchers and enthusiasts track the latest security vulnerabilities (CVE) and security-related repositories on GitHub in real-time. It utilizes artificial intelligence technology for in-depth analysis and automatically publishes valuable security intelligence to a blogging platform. The system features multiple data sources monitoring, intelligent AI analysis using OpenAI and Gemini engines, fully automated workflow with 24/7 monitoring, daily briefings, and dynamic blacklists, flexible configuration and management with support for multiple tokens, configurable parameters, and detailed logging, and automatic blog publishing with integrated blogging platform and Markdown reports.
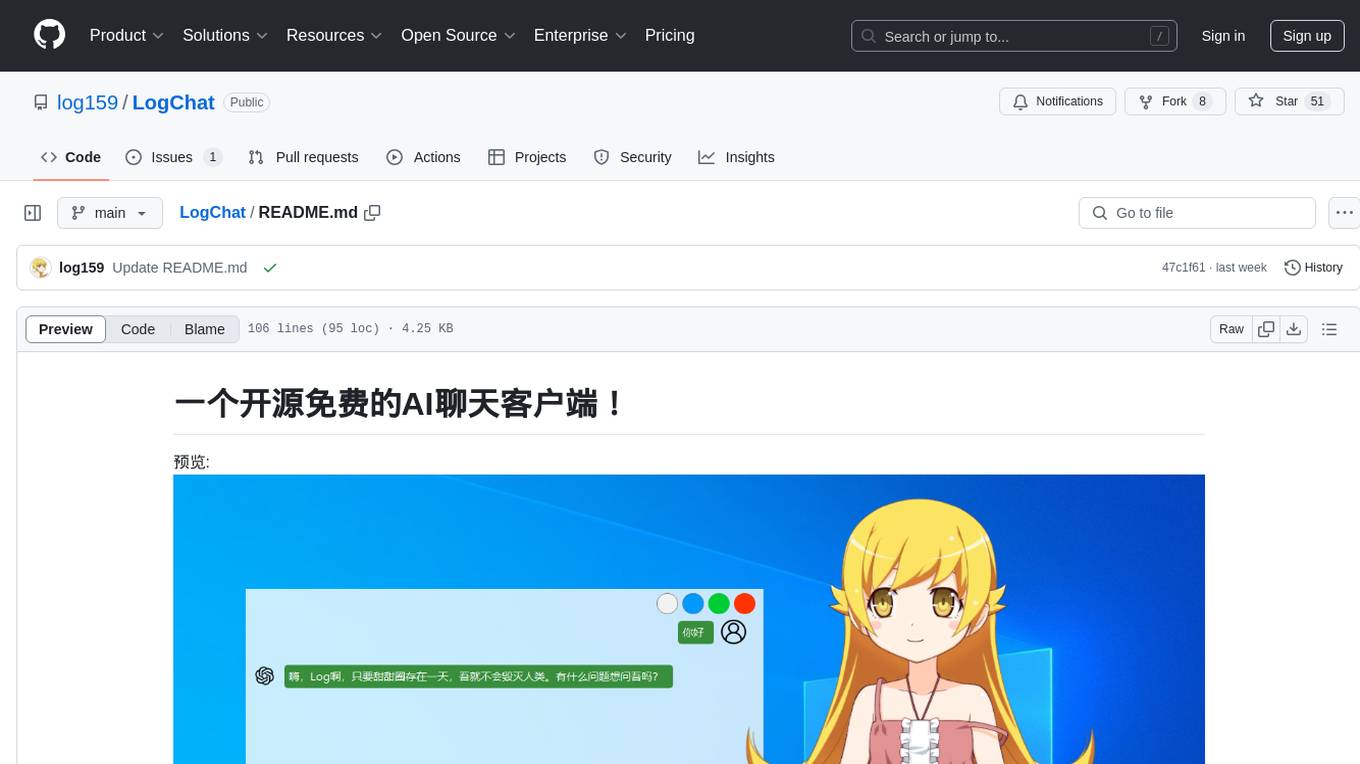
LogChat
LogChat is an open-source and free AI chat client that supports various chat models and technologies such as ChatGPT, 讯飞星火, DeepSeek, LLM, TTS, STT, and Live2D. The tool provides a user-friendly interface designed using Qt Creator and can be used on Windows systems without any additional environment requirements. Users can interact with different AI models, perform voice synthesis and recognition, and customize Live2D character models. LogChat also offers features like language translation, AI platform integration, and menu items like screenshot editing, clock, and application launcher.

nix-ai-tools
Exploring the integration between Nix and AI coding agents, this repository serves as a testbed for packaging, sandboxing, and enhancing AI-powered development tools within the Nix ecosystem. It provides a collection of AI tools with descriptions, versions, sources, licenses, homepages, and usage instructions. The repository also supports daily updates using GitHub Actions and offers a platform for experimental features like sandboxed execution, provider abstraction, and tool composition in Nix environments. Contributions are welcome, and the Nix packaging code in this repository is licensed under MIT.
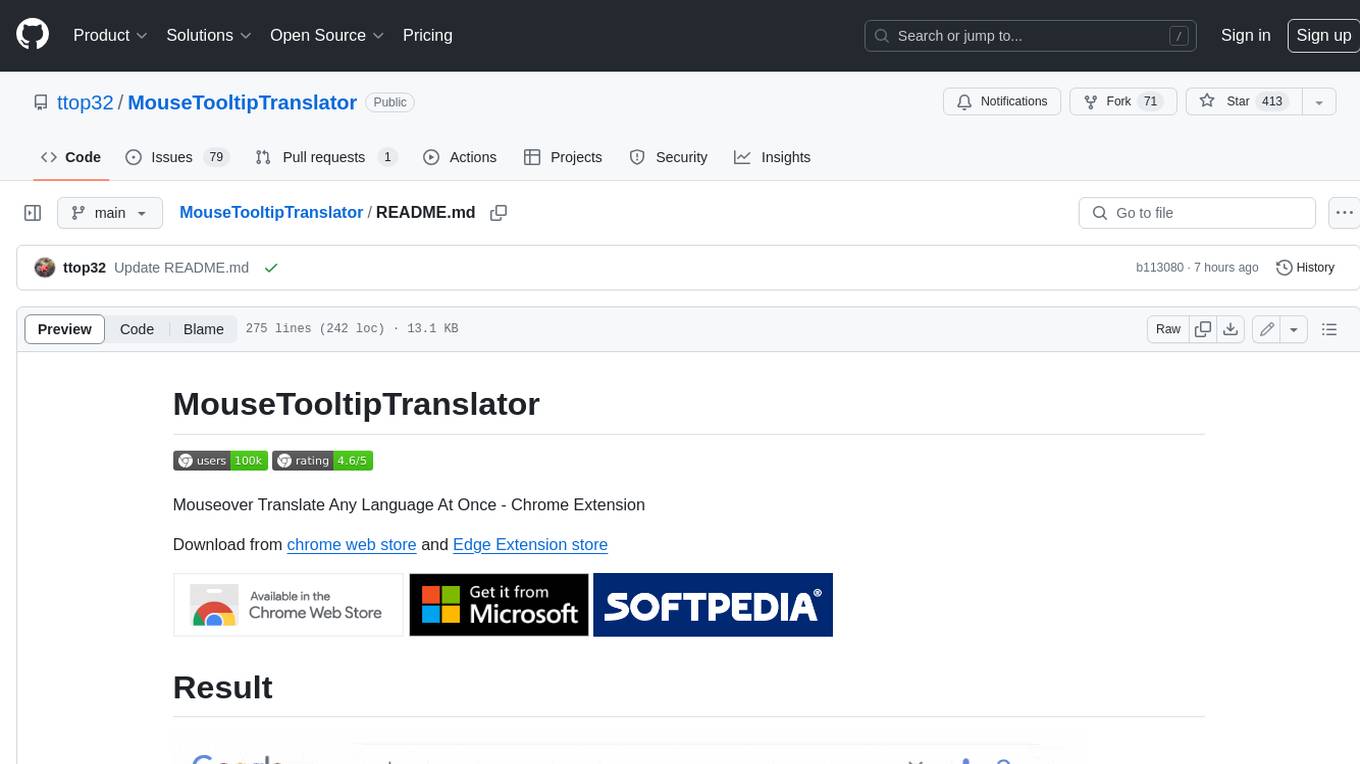
MouseTooltipTranslator
MouseTooltipTranslator is a Chrome extension that allows users to translate any text on a webpage by simply hovering over it. It supports both Google Translate and Bing Translate, and can also be used to listen to the pronunciation of words and phrases. Additionally, the extension can be used to translate text in input boxes and highlighted text, and to display translated tooltips for PDFs and YouTube videos. It also supports OCR, allowing users to translate text in images by holding down the left shift key and hovering over the image.
For similar tasks

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.

adata
AData is a free and open-source A-share database that focuses on transaction-related data. It provides comprehensive data on stocks, including basic information, market data, and sentiment analysis. AData is designed to be easy to use and integrate with other applications, making it a valuable tool for quantitative trading and AI training.

PIXIU
PIXIU is a project designed to support the development, fine-tuning, and evaluation of Large Language Models (LLMs) in the financial domain. It includes components like FinBen, a Financial Language Understanding and Prediction Evaluation Benchmark, FIT, a Financial Instruction Dataset, and FinMA, a Financial Large Language Model. The project provides open resources, multi-task and multi-modal financial data, and diverse financial tasks for training and evaluation. It aims to encourage open research and transparency in the financial NLP field.

hezar
Hezar is an all-in-one AI library designed specifically for the Persian community. It brings together various AI models and tools, making it easy to use AI with just a few lines of code. The library seamlessly integrates with Hugging Face Hub, offering a developer-friendly interface and task-based model interface. In addition to models, Hezar provides tools like word embeddings, tokenizers, feature extractors, and more. It also includes supplementary ML tools for deployment, benchmarking, and optimization.

text-embeddings-inference
Text Embeddings Inference (TEI) is a toolkit for deploying and serving open source text embeddings and sequence classification models. TEI enables high-performance extraction for popular models like FlagEmbedding, Ember, GTE, and E5. It implements features such as no model graph compilation step, Metal support for local execution on Macs, small docker images with fast boot times, token-based dynamic batching, optimized transformers code for inference using Flash Attention, Candle, and cuBLASLt, Safetensors weight loading, and production-ready features like distributed tracing with Open Telemetry and Prometheus metrics.

CodeProject.AI-Server
CodeProject.AI Server is a standalone, self-hosted, fast, free, and open-source Artificial Intelligence microserver designed for any platform and language. It can be installed locally without the need for off-device or out-of-network data transfer, providing an easy-to-use solution for developers interested in AI programming. The server includes a HTTP REST API server, backend analysis services, and the source code, enabling users to perform various AI tasks locally without relying on external services or cloud computing. Current capabilities include object detection, face detection, scene recognition, sentiment analysis, and more, with ongoing feature expansions planned. The project aims to promote AI development, simplify AI implementation, focus on core use-cases, and leverage the expertise of the developer community.

spark-nlp
Spark NLP is a state-of-the-art Natural Language Processing library built on top of Apache Spark. It provides simple, performant, and accurate NLP annotations for machine learning pipelines that scale easily in a distributed environment. Spark NLP comes with 36000+ pretrained pipelines and models in more than 200+ languages. It offers tasks such as Tokenization, Word Segmentation, Part-of-Speech Tagging, Named Entity Recognition, Dependency Parsing, Spell Checking, Text Classification, Sentiment Analysis, Token Classification, Machine Translation, Summarization, Question Answering, Table Question Answering, Text Generation, Image Classification, Image to Text (captioning), Automatic Speech Recognition, Zero-Shot Learning, and many more NLP tasks. Spark NLP is the only open-source NLP library in production that offers state-of-the-art transformers such as BERT, CamemBERT, ALBERT, ELECTRA, XLNet, DistilBERT, RoBERTa, DeBERTa, XLM-RoBERTa, Longformer, ELMO, Universal Sentence Encoder, Llama-2, M2M100, BART, Instructor, E5, Google T5, MarianMT, OpenAI GPT2, Vision Transformers (ViT), OpenAI Whisper, and many more not only to Python and R, but also to JVM ecosystem (Java, Scala, and Kotlin) at scale by extending Apache Spark natively.

scikit-llm
Scikit-LLM is a tool that seamlessly integrates powerful language models like ChatGPT into scikit-learn for enhanced text analysis tasks. It allows users to leverage large language models for various text analysis applications within the familiar scikit-learn framework. The tool simplifies the process of incorporating advanced language processing capabilities into machine learning pipelines, enabling users to benefit from the latest advancements in natural language processing.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.