
physics-sims
Interesting physics-sims generated via LLM prompting.
Stars: 182
Physics Simulations is a repository containing interesting physics simulations generated via LLM prompting. The repository includes HTML files showcasing simulations such as Earth's magnetic field, electromagnetic solenoid, general relativity, and planetary orbit with Hohmann Transfer Orbit. Users can clone the repository and run the HTML files using Live Server to interact with the simulations. In case of issues, users are advised to check Dev Tools for errors and seek help from ChatGPT, Gemini, or Grok for problem resolution.
README:
Interesting physics-sims generated via LLM prompting.
- Clone the repository and run any HTML file with Live Server to test it out.
- If you have issues check Dev Tools and look for errors. Use ChatGPT, Gemini, or Grok to help resolve the problem.
EARTHS_MAGNETIC_FIELD.HTML: Earth with a dipole field tilted at 11 degrees from the Earth's spin access.
EM_SOLENOID.HTML: Classic Electricitty and Magnetism demonstration, a charged solenoid creating a magnetic field.
GENERAL_RELATIVITY.HTML: Demonstrates Einstien's theory of General Relativity: curvature of space time.
PLANETARY_ORBIT.HTML: Planetary orbit plus the Hohmann Transfer Orbit - Launch Window.
If you get value from this repository follow me on X @renderfiction

For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for physics-sims
Similar Open Source Tools
physics-sims
Physics Simulations is a repository containing interesting physics simulations generated via LLM prompting. The repository includes HTML files showcasing simulations such as Earth's magnetic field, electromagnetic solenoid, general relativity, and planetary orbit with Hohmann Transfer Orbit. Users can clone the repository and run the HTML files using Live Server to interact with the simulations. In case of issues, users are advised to check Dev Tools for errors and seek help from ChatGPT, Gemini, or Grok for problem resolution.
AI4Animation
AI4Animation is a comprehensive framework for data-driven character animation, including data processing, neural network training, and runtime control, developed in Unity3D/PyTorch. It explores deep learning opportunities for character animation, covering biped and quadruped locomotion, character-scene interactions, sports and fighting games, and embodied avatar motions in AR/VR. The research focuses on generative frameworks, codebook matching, periodic autoencoders, animation layering, local motion phases, and neural state machines for character control and animation.
awesome-openvino
Awesome OpenVINO is a curated list of AI projects based on the OpenVINO toolkit, offering a rich assortment of projects, libraries, and tutorials covering various topics like model optimization, deployment, and real-world applications across industries. It serves as a valuable resource continuously updated to maximize the potential of OpenVINO in projects, featuring projects like Stable Diffusion web UI, Visioncom, FastSD CPU, OpenVINO AI Plugins for GIMP, and more.

xlstm-jax
The xLSTM-jax repository contains code for training and evaluating the xLSTM model on language modeling using JAX. xLSTM is a Recurrent Neural Network architecture that improves upon the original LSTM through Exponential Gating, normalization, stabilization techniques, and a Matrix Memory. It is optimized for large-scale distributed systems with performant triton kernels for faster training and inference.
Here-Comes-the-AI-Worm
Large Language Models (LLMs) are now embedded in everyday tools like email assistants, chat apps, and productivity software. This project introduces DonkeyRail, a lightweight guardrail that detects and blocks malicious self-replicating prompts known as RAGworm within GenAI-powered applications. The guardrail is fast, accurate, and practical for real-world GenAI systems, preventing activities like spam, phishing campaigns, and data leaks.

llms-tools
The 'llms-tools' repository is a comprehensive collection of AI tools, open-source projects, and research related to Large Language Models (LLMs) and Chatbots. It covers a wide range of topics such as AI in various domains, open-source models, chats & assistants, visual language models, evaluation tools, libraries, devices, income models, text-to-image, computer vision, audio & speech, code & math, games, robotics, typography, bio & med, military, climate, finance, and presentation. The repository provides valuable resources for researchers, developers, and enthusiasts interested in exploring the capabilities of LLMs and related technologies.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.

Raspberry
Raspberry is an open source project aimed at creating a toy dataset for finetuning Large Language Models (LLMs) with reasoning abilities. The project involves synthesizing complex user queries across various domains, generating CoT and Self-Critique data, cleaning and rectifying samples, finetuning an LLM with the dataset, and seeking funding for scalability. The ultimate goal is to develop a dataset that challenges models with tasks requiring math, coding, logic, reasoning, and planning skills, spanning different sectors like medicine, science, and software development.

aitlas
The AiTLAS toolbox (Artificial Intelligence Toolbox for Earth Observation) includes state-of-the-art machine learning methods for exploratory and predictive analysis of satellite imagery as well as a repository of AI-ready Earth Observation (EO) datasets. It can be easily applied for a variety of Earth Observation tasks, such as land use and cover classification, crop type prediction, localization of specific objects (semantic segmentation), etc. The main goal of AiTLAS is to facilitate better usability and adoption of novel AI methods (and models) by EO experts, while offering easy access and standardized format of EO datasets to AI experts which allows benchmarking of various existing and novel AI methods tailored for EO data.

LLM-Viewer
LLM-Viewer is a tool for visualizing Language and Learning Models (LLMs) and analyzing performance on different hardware platforms. It enables network-wise analysis, considering factors such as peak memory consumption and total inference time cost. With LLM-Viewer, users can gain valuable insights into LLM inference and performance optimization. The tool can be used in a web browser or as a command line interface (CLI) for easy configuration and visualization. The ongoing project aims to enhance features like showing tensor shapes, expanding hardware platform compatibility, and supporting more LLMs with manual model graph configuration.
matchem-llm
A public repository collecting links to state-of-the-art training sets, QA, benchmarks and other evaluations for various ML and LLM applications in materials science and chemistry. It includes datasets related to chemistry, materials, multimodal data, and knowledge graphs in the field. The repository aims to provide resources for training and evaluating machine learning models in the materials science and chemistry domains.
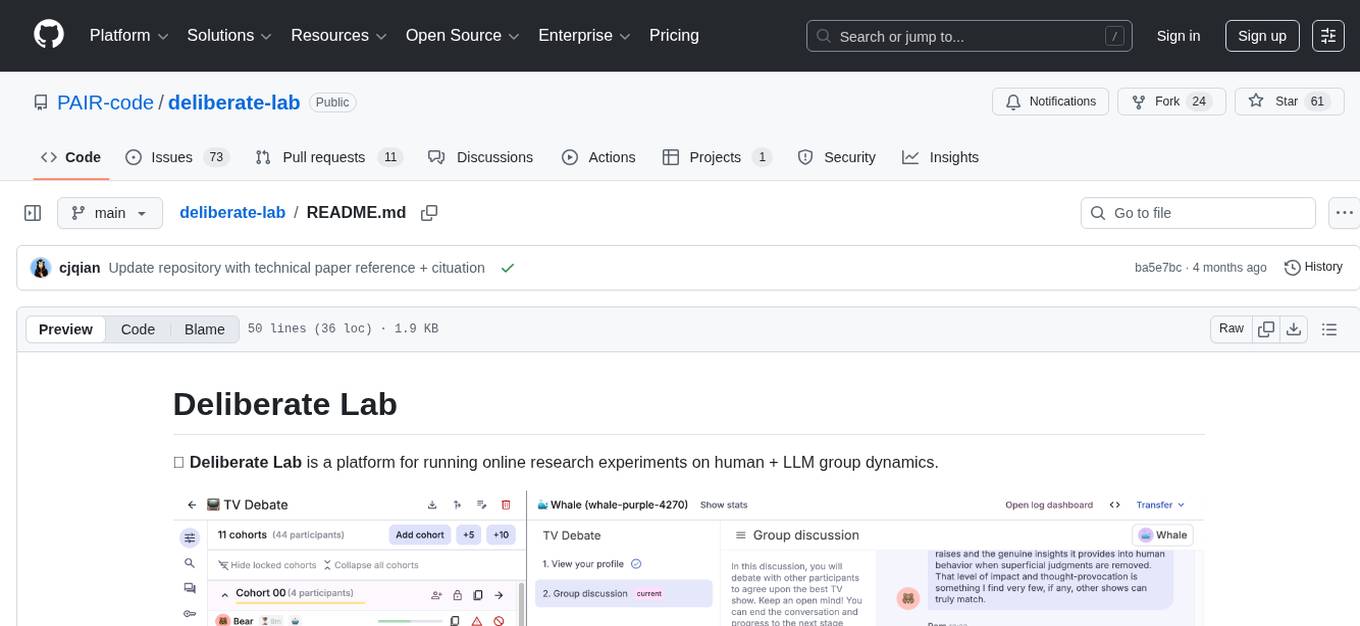
deliberate-lab
Deliberate Lab is a platform designed for conducting online research experiments focusing on human and LLM group dynamics. It provides documentation for researchers and developers, offers a quick start guide for developers, and includes a technical paper. The platform allows users to run real-time human-AI social experiments and provides tools for analyzing group interactions and dynamics.
miles-credit
CREDIT is an open software platform for training and deploying AI atmospheric prediction models. It offers fast models with flexible configuration options for input data and neural network architecture. The user-friendly interface enables quick setup and iteration. Developed by the MILES group and NSF National Center for Atmospheric Research, CREDIT combines advanced AI/ML with atmospheric science expertise. It provides a stable release with various models, training, and deployment options, with ongoing development. Detailed documentation is available for installation, training, deployment, config file interpretation, and API usage.

ManipVQA
ManipVQA is a framework that enhances Multimodal Large Language Models (MLLMs) with manipulation-centric knowledge through a Visual Question-Answering (VQA) format. It addresses the deficiency of conventional MLLMs in understanding affordances and physical concepts crucial for manipulation tasks. By infusing robotics-specific knowledge, including tool detection, affordance recognition, and physical concept comprehension, ManipVQA improves the performance of robots in manipulation tasks. The framework involves fine-tuning MLLMs with a curated dataset of interactive objects, enabling robots to understand and execute natural language instructions more effectively.

oreilly-hands-on-gpt-llm
This repository contains code for the O'Reilly Live Online Training for Deploying GPT & LLMs. Learn how to use GPT-4, ChatGPT, OpenAI embeddings, and other large language models to build applications for experimenting and production. Gain practical experience in building applications like text generation, summarization, question answering, and more. Explore alternative generative models such as Cohere and GPT-J. Understand prompt engineering, context stuffing, and few-shot learning to maximize the potential of GPT-like models. Focus on deploying models in production with best practices and debugging techniques. By the end of the training, you will have the skills to start building applications with GPT and other large language models.

Me-LLaMA
Me LLaMA introduces a suite of open-source medical Large Language Models (LLMs), including Me LLaMA 13B/70B and their chat-enhanced versions. Developed through innovative continual pre-training and instruction tuning, these models leverage a vast medical corpus comprising PubMed papers, medical guidelines, and general domain data. Me LLaMA sets new benchmarks on medical reasoning tasks, making it a significant asset for medical NLP applications and research. The models are intended for computational linguistics and medical research, not for clinical decision-making without validation and regulatory approval.
For similar tasks
physics-sims
Physics Simulations is a repository containing interesting physics simulations generated via LLM prompting. The repository includes HTML files showcasing simulations such as Earth's magnetic field, electromagnetic solenoid, general relativity, and planetary orbit with Hohmann Transfer Orbit. Users can clone the repository and run the HTML files using Live Server to interact with the simulations. In case of issues, users are advised to check Dev Tools for errors and seek help from ChatGPT, Gemini, or Grok for problem resolution.
For similar jobs

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.

Azure-Analytics-and-AI-Engagement
The Azure-Analytics-and-AI-Engagement repository provides packaged Industry Scenario DREAM Demos with ARM templates (Containing a demo web application, Power BI reports, Synapse resources, AML Notebooks etc.) that can be deployed in a customer’s subscription using the CAPE tool within a matter of few hours. Partners can also deploy DREAM Demos in their own subscriptions using DPoC.

minio
MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0. It is API compatible with Amazon S3 cloud storage service. Use MinIO to build high performance infrastructure for machine learning, analytics and application data workloads.

mage-ai
Mage is an open-source data pipeline tool for transforming and integrating data. It offers an easy developer experience, engineering best practices built-in, and data as a first-class citizen. Mage makes it easy to build, preview, and launch data pipelines, and provides observability and scaling capabilities. It supports data integrations, streaming pipelines, and dbt integration.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.

tidb
TiDB is an open-source distributed SQL database that supports Hybrid Transactional and Analytical Processing (HTAP) workloads. It is MySQL compatible and features horizontal scalability, strong consistency, and high availability.

airbyte
Airbyte is an open-source data integration platform that makes it easy to move data from any source to any destination. With Airbyte, you can build and manage data pipelines without writing any code. Airbyte provides a library of pre-built connectors that make it easy to connect to popular data sources and destinations. You can also create your own connectors using Airbyte's no-code Connector Builder or low-code CDK. Airbyte is used by data engineers and analysts at companies of all sizes to build and manage their data pipelines.

labelbox-python
Labelbox is a data-centric AI platform for enterprises to develop, optimize, and use AI to solve problems and power new products and services. Enterprises use Labelbox to curate data, generate high-quality human feedback data for computer vision and LLMs, evaluate model performance, and automate tasks by combining AI and human-centric workflows. The academic & research community uses Labelbox for cutting-edge AI research.