
ai-science-training-series
None
Stars: 192
This repository contains a student training series focusing on AI-driven science on supercomputers. It covers topics such as ALCF systems overview, AI on supercomputers, neural networks, LLMs, and parallel training techniques. The content is organized into subdirectories with prefixed indexes for easy navigation. The series aims to provide hands-on experience and knowledge in utilizing AI on supercomputers for scientific research.
README:
Public Page for Series Schedule
ALCF YouTube with recordings of sessions
Indico registration page (CLOSED)
This repository is organized into one subdirectory per topic. All content is prefixed by a two-digit index in the order of presentation in the tutorials.
Table of Contents
- Introduction to ALCF Systems
- ALCF Compute Systems Overview
- Shared Resources
- Introduction to Jupyter Notebooks
- How to Submit the Homeworks
- How to Login on the Command Line
- How to Setup a Shell Enviroment
- Submitting Jobs to a Queue
- Introduction to AI on Supercomputer
- Introduction to Neural Networks
- Advanced Topics in Neural Networks
- Introduction to LLMs
- LLMs -- Part II
- Parallel Training Techniques
- AI Testbeds
Note for contributors: please run git config --local include.path ../.gitconfig once
upon cloning the repository (from anywhere in the repo) to add the gitattribute
filter defintions to your local git
configuration options.1 Be sure that the jupyter command is in your $PATH,
otherwise the filter and git staging will fail.23
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ai-science-training-series
Similar Open Source Tools
ai-science-training-series
This repository contains a student training series focusing on AI-driven science on supercomputers. It covers topics such as ALCF systems overview, AI on supercomputers, neural networks, LLMs, and parallel training techniques. The content is organized into subdirectories with prefixed indexes for easy navigation. The series aims to provide hands-on experience and knowledge in utilizing AI on supercomputers for scientific research.

SuperKnowa
SuperKnowa is a fast framework to build Enterprise RAG (Retriever Augmented Generation) Pipelines at Scale, powered by watsonx. It accelerates Enterprise Generative AI applications to get prod-ready solutions quickly on private data. The framework provides pluggable components for tackling various Generative AI use cases using Large Language Models (LLMs), allowing users to assemble building blocks to address challenges in AI-driven text generation. SuperKnowa is battle-tested from 1M to 200M private knowledge base & scaled to billions of retriever tokens.
build-an-agentic-llm-assistant
This repository provides a hands-on workshop for developers and solution builders to build a real-life serverless LLM application using foundation models (FMs) through Amazon Bedrock and advanced design patterns such as Reason and Act (ReAct) Agent, text-to-SQL, and Retrieval Augmented Generation (RAG). It guides users through labs to explore common and advanced LLM application design patterns, helping them build a complex Agentic LLM assistant capable of answering retrieval and analytical questions on internal knowledge bases. The repository includes labs on IaC with AWS CDK, building serverless LLM assistants with AWS Lambda and Amazon Bedrock, refactoring LLM assistants into custom agents, extending agents with semantic retrieval, and querying SQL databases. Users need to set up AWS Cloud9, configure model access on Amazon Bedrock, and use Amazon SageMaker Studio environment to run data-pipelines notebooks.

Open-DocLLM
Open-DocLLM is an open-source project that addresses data extraction and processing challenges using OCR and LLM technologies. It consists of two main layers: OCR for reading document content and LLM for extracting specific content in a structured manner. The project offers a larger context window size compared to JP Morgan's DocLLM and integrates tools like Tesseract OCR and Mistral for efficient data analysis. Users can run the models on-premises using LLM studio or Ollama, and the project includes a FastAPI app for testing purposes.

Lecture_AI_in_Automotive_Technology
This Github repository contains practice session materials for the TUM course on Artificial Intelligence in Automotive Technology. It includes coding examples used in the lectures to teach the foundations of AI in automotive technology. The repository aims to provide hands-on experience and practical knowledge in applying AI concepts to the automotive industry.
End-to-End-LLM
The End-to-End LLM Bootcamp is a comprehensive training program that covers the entire process of developing and deploying large language models. Participants learn to preprocess datasets, train models, optimize performance using NVIDIA technologies, understand guardrail prompts, and deploy AI pipelines using Triton Inference Server. The bootcamp includes labs, challenges, and practical applications, with a total duration of approximately 7.5 hours. It is designed for individuals interested in working with advanced language models and AI technologies.
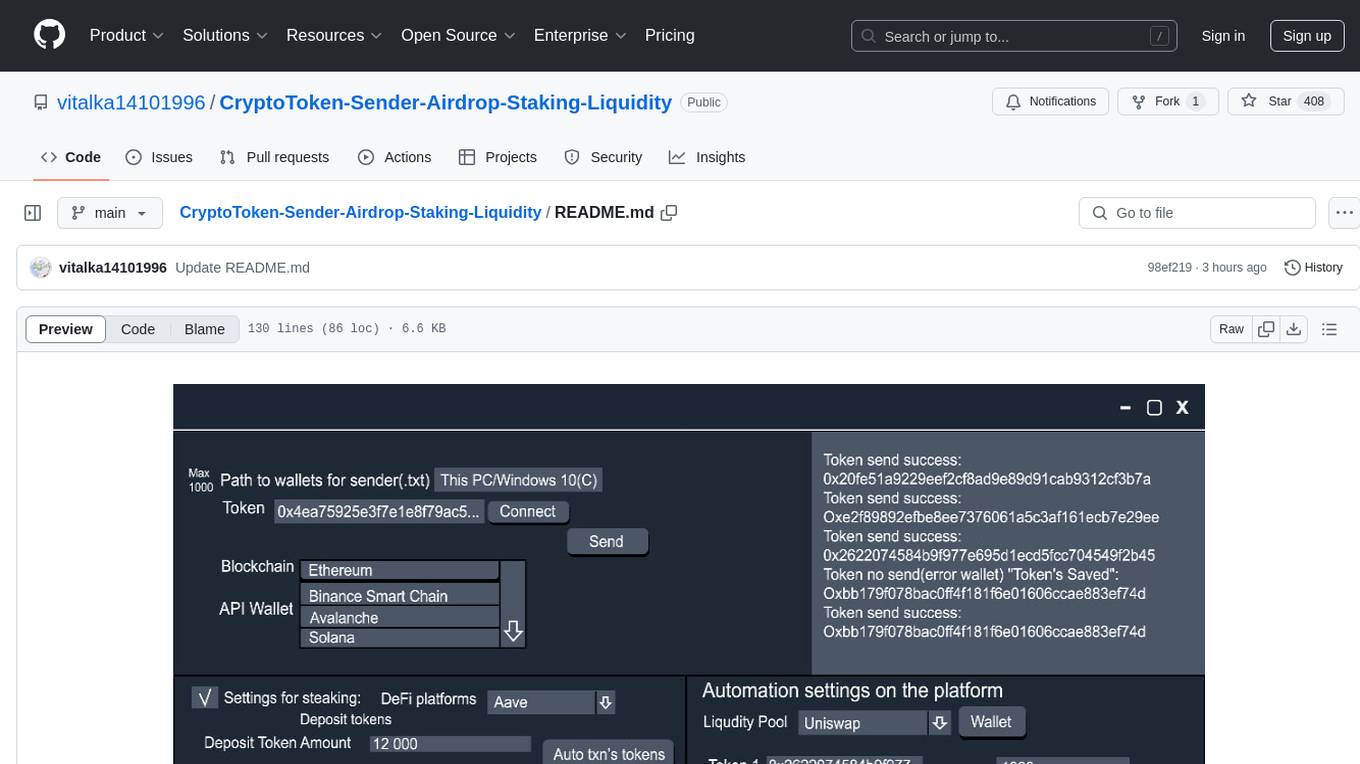
CryptoToken-Sender-Airdrop-Staking-Liquidity
The CryptoToken-Sender-Airdrop-Staking-Liquidity repository provides an ultimate tool for efficient and automated token distribution across blockchain wallets. It is designed for projects, DAOs, and blockchain-based organizations that need to distribute tokens to thousands of wallet addresses with ease. The platform offers advanced integrations with DeFi protocols for staking, liquidity farming, and automated payments. Users can send tokens in bulk, distribute tokens to multiple wallets instantly, optimize gas fees, integrate with DeFi protocols for liquidity provision and staking, set up recurring payments, automate liquidity farming strategies, support multi-chain operations, monitor transactions in real-time, and work with various token standards. The repository includes features for connecting to blockchains, importing and managing wallets, customizing mailing parameters, monitoring transaction status, logging transactions, and providing a user-friendly interface for configuration and operation.
OpenCat
OpenCat is an open-source Arduino and Raspberry Pi-based quadruped robotic pet framework developed by Petoi. It aims to foster collaboration in quadruped robotics research, education, and engineering development of agile and affordable quadruped robot pets. The project provides a base open source platform for creating programmable gaits, locomotion, and deployment of inverse kinematics quadruped robots, enabling simulations to the real world via block-based coding/C/C++/Python programming languages. Users have deployed various robotics/AI/IoT applications and the project has successfully crowdfunded mini robot kits, shipped worldwide, and established a production line for affordable robotic kits and accessories.
llvm-aie
This repository extends the LLVM framework to generate code for use with AMD/Xilinx AI Engine processors. AI Engine processors are in-order, exposed-pipeline VLIW processors focused on application acceleration for AI, Machine Learning, and DSP applications. The repository adds LLVM support for specific features like non-power of 2 pointers, operand latencies, resource conflicts, negative operand latencies, slot assignment, relocations, code alignment restrictions, and register allocation. It includes support for Clang, LLD, binutils, Compiler-RT, and LLVM-LIBC.
LLM-Geo
LLM-Geo is an AI-powered geographic information system (GIS) that leverages Large Language Models (LLMs) for automatic spatial data collection, analysis, and visualization. By adopting LLM as the reasoning core, it addresses spatial problems with self-generating, self-organizing, self-verifying, self-executing, and self-growing capabilities. The tool aims to make spatial analysis easier, faster, and more accessible by reducing manual operation time and delivering accurate results through case studies. It uses GPT-4 API in a Python environment and advocates for further research and development in autonomous GIS.

ianvs
Ianvs is a distributed synergy AI benchmarking project incubated in KubeEdge SIG AI. It aims to test the performance of distributed synergy AI solutions following recognized standards, providing end-to-end benchmark toolkits, test environment management tools, test case control tools, and benchmark presentation tools. It also collaborates with other organizations to establish comprehensive benchmarks and related applications. The architecture includes critical components like Test Environment Manager, Test Case Controller, Generation Assistant, Simulation Controller, and Story Manager. Ianvs documentation covers quick start, guides, dataset descriptions, algorithms, user interfaces, stories, and roadmap.
awesome-openvino
Awesome OpenVINO is a curated list of AI projects based on the OpenVINO toolkit, offering a rich assortment of projects, libraries, and tutorials covering various topics like model optimization, deployment, and real-world applications across industries. It serves as a valuable resource continuously updated to maximize the potential of OpenVINO in projects, featuring projects like Stable Diffusion web UI, Visioncom, FastSD CPU, OpenVINO AI Plugins for GIMP, and more.

long-context-attention
Long-Context-Attention (YunChang) is a unified sequence parallel approach that combines the strengths of DeepSpeed-Ulysses-Attention and Ring-Attention to provide a versatile and high-performance solution for long context LLM model training and inference. It addresses the limitations of both methods by offering no limitation on the number of heads, compatibility with advanced parallel strategies, and enhanced performance benchmarks. The tool is verified in Megatron-LM and offers best practices for 4D parallelism, making it suitable for various attention mechanisms and parallel computing advancements.
genai-factory
GenAI Factory is a collection of end-to-end blueprints to deploy generative AI infrastructures in Google Cloud Platform (GCP), following security best practices. It embraces Infrastructure as Code (IaC) best practices, implements infrastructure in Terraform, and follows the least-privilege principle. The tool is compatible with Cloud Foundation Fabric FAST project-factory and application templates, allowing users to deploy various AI applications and systems on GCP.
DevOpsGPT
DevOpsGPT is an AI-driven software development automation solution that combines Large Language Models (LLM) with DevOps tools to convert natural language requirements into working software. It improves development efficiency by eliminating the need for tedious requirement documentation, shortens development cycles, reduces communication costs, and ensures high-quality deliverables. The Enterprise Edition offers features like existing project analysis, professional model selection, and support for more DevOps platforms. The tool automates requirement development, generates interface documentation, provides pseudocode based on existing projects, facilitates code refinement, enables continuous integration, and supports software version release. Users can run DevOpsGPT with source code or Docker, and the tool comes with limitations in precise documentation generation and understanding existing project code. The product roadmap includes accurate requirement decomposition, rapid import of development requirements, and integration of more software engineering and professional tools for efficient software development tasks under AI planning and execution.
shipstation
ShipStation is an AI-based website and agents generation platform that optimizes landing page websites and generic connect-anything-to-anything services. It enables seamless communication between service providers and integration partners, offering features like user authentication, project management, code editing, payment integration, and real-time progress tracking. The project architecture includes server-side (Node.js) and client-side (React with Vite) components. Prerequisites include Node.js, npm or yarn, Anthropic API key, Supabase account, Tavily API key, and Razorpay account. Setup instructions involve cloning the repository, setting up Supabase, configuring environment variables, and starting the backend and frontend servers. Users can access the application through the browser, sign up or log in, create landing pages or portfolios, and get websites stored in an S3 bucket. Deployment to Heroku involves building the client project, committing changes, and pushing to the main branch. Contributions to the project are encouraged, and the license encourages doing good.
For similar tasks
ai-science-training-series
This repository contains a student training series focusing on AI-driven science on supercomputers. It covers topics such as ALCF systems overview, AI on supercomputers, neural networks, LLMs, and parallel training techniques. The content is organized into subdirectories with prefixed indexes for easy navigation. The series aims to provide hands-on experience and knowledge in utilizing AI on supercomputers for scientific research.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.