Best AI tools for< Parallel Training Techniques >
20 - AI tool Sites
VESSL AI
VESSL AI is a platform offering Liquid AI Infra & Persistent GPU Cloud services, allowing users to easily access and utilize GPUs for running AI workloads. It provides a seamless experience from zero to running AI workloads, catering to AI startups, enterprise AI teams, and research & academia. VESSL AI offers GPU products for every stage, with options like spot, on-demand, and reserved capacity, along with features like multi-cloud failover, pay-as-you-go pricing, and production-ready reliability. The platform is designed to help users scale their AI projects efficiently and effectively.
Nooks
Nooks is an AI-powered parallel dialer and virtual salesfloor platform designed to automate manual call tasks, boost volume, connect rates, and conversion rates. It offers features like call analytics, AI training, and Nooks Numbers to improve data coverage and quality. The platform enables users to coach and collaborate on live calls, transcribe and analyze calls, and work on talk tracks with tough personas using AI training. Nooks also provides resources like a blog, customer stories, and events to help users supercharge their sales pipeline.

Gorilla
Gorilla is an AI tool that integrates a large language model (LLM) with massive APIs to enable users to interact with a wide range of services. It offers features such as training the model to support parallel functions, benchmarking LLMs on function-calling capabilities, and providing a runtime for executing LLM-generated actions like code and API calls. Gorilla is open-source and focuses on enhancing interaction between apps and services with human-out-of-loop functionality.
xeditai
xeditai is an AI-powered studio that provides a comprehensive workspace for creating content using various AI models. It offers a range of features such as rich-text editing, cloud persistence, templates & tones, parallel mode, strategy mode, export & share functionalities, and seamless switching between AI models. xeditai is designed for individuals and teams who need to iterate on ideas, draft, compare, refine, and structure content until the thinking is clear. It aims to facilitate the creation of finished, structured output without relying on chat prompts, providing a platform for real creation and serious work.
Koncert
Koncert is an AI-powered sales dialer and remote salesfloor platform that helps businesses accelerate sales success. With its AI-enhanced dialing, automated local presence, and caller ID health heat map, Koncert helps sales teams connect with more prospects, have more conversations, and close more deals. Koncert also offers a range of other features, including a multi-channel sales sequencer, remote coaching, and conversation intelligence. With Koncert, sales teams can improve their productivity, increase their connect rates, and close more deals.
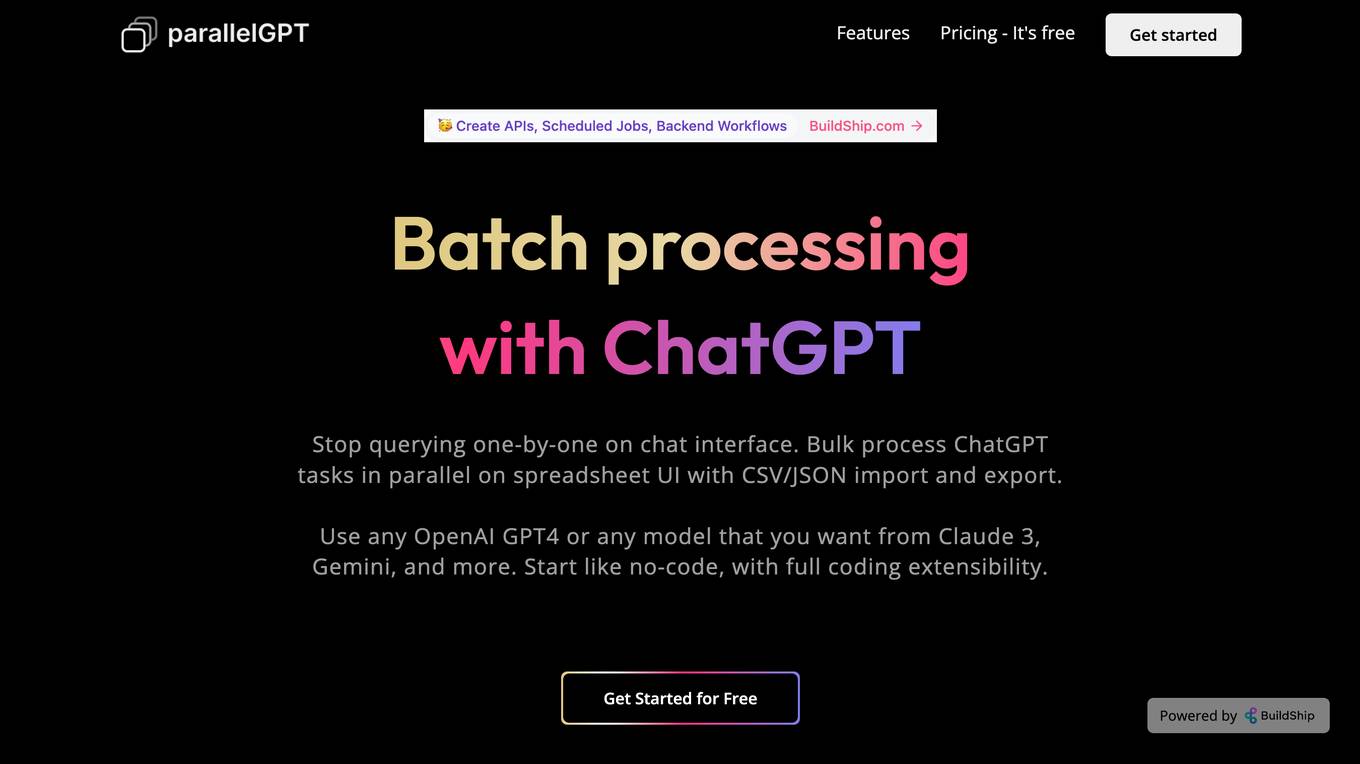
BuildShip
BuildShip is a batch processing tool for ChatGPT that allows users to process ChatGPT tasks in parallel on a spreadsheet UI with CSV/JSON import and export. It supports various OpenAI models, including GPT4, Claude 3, and Gemini. Users can start with readymade templates and customize them with their own logic and models. The data generated is stored securely on the user's own Google Cloud project, and team collaboration is supported with granular access control.
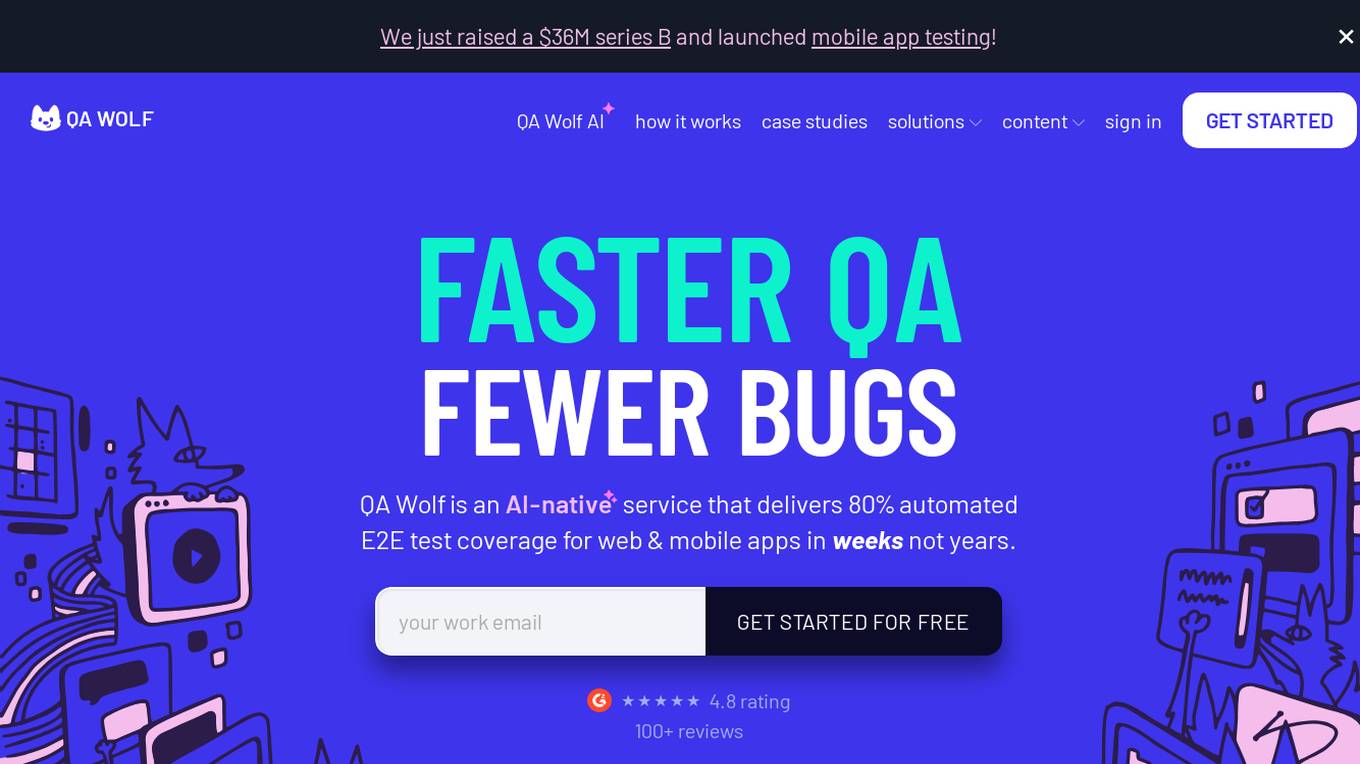
QA Wolf
QA Wolf is an AI-native service that delivers 80% automated end-to-end test coverage for web and mobile apps in weeks, not years. It automates hundreds of tests using Playwright code for web and Appium for mobile, providing reliable test results on every run. With features like 100% parallel run infrastructure, zero flake guarantee, and unlimited test runs, QA Wolf aims to help software teams ship better software faster by taking QA completely off their plate.
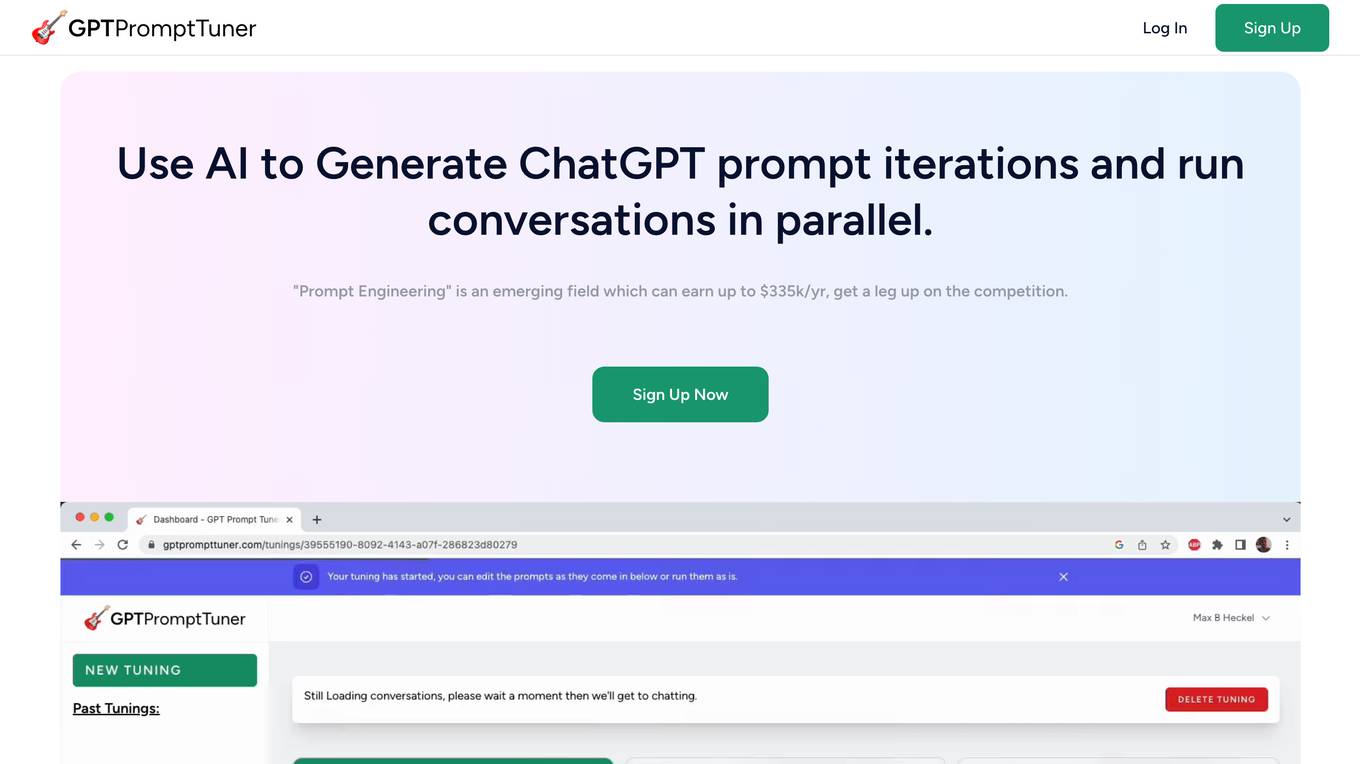
GPT Prompt Tuner
GPT Prompt Tuner is an AI tool that leverages AI to enhance ChatGPT prompts and facilitate parallel conversations. It enables users to generate prompt iterations, customize prompts, and run multiple conversations simultaneously. The tool is designed to streamline the process of prompt engineering, offering a flexible and efficient solution for users seeking to optimize their interactions with ChatGPT.
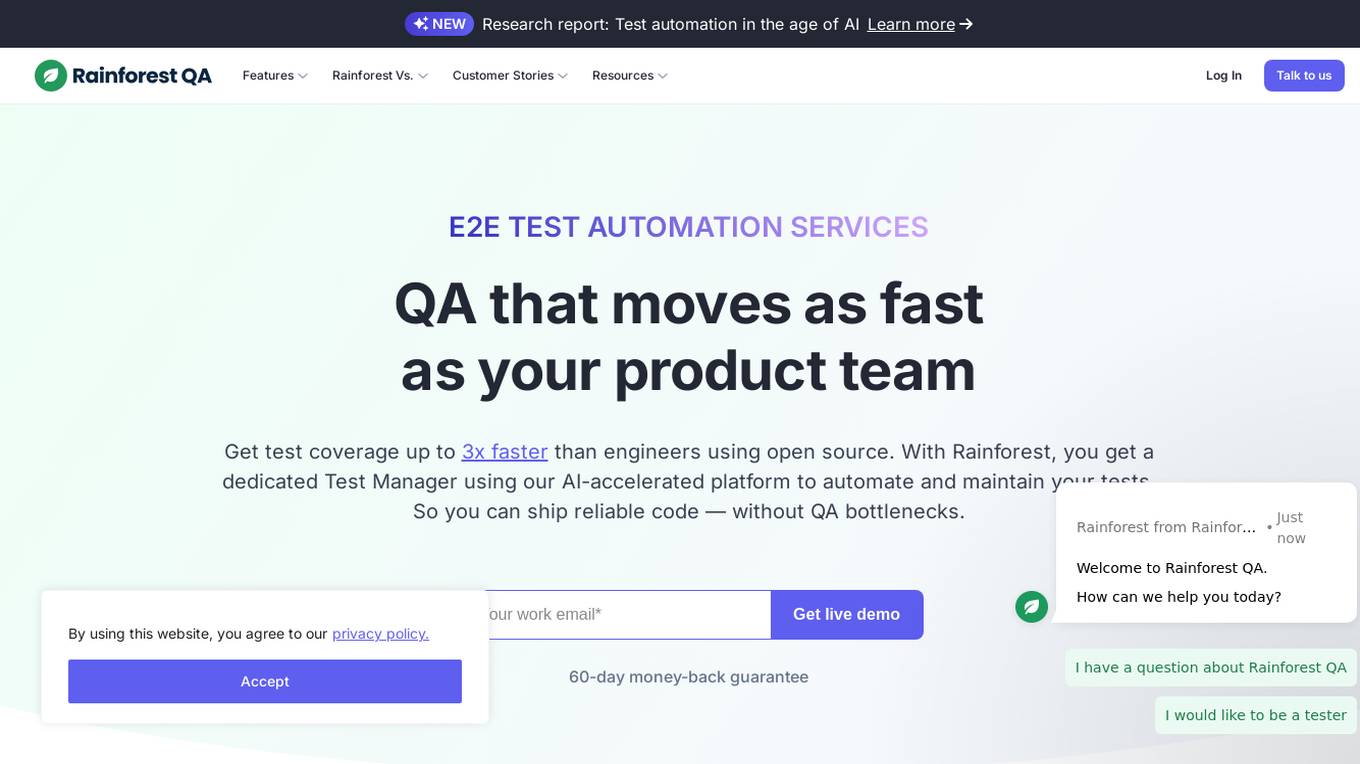
Rainforest QA
Rainforest QA is an AI-powered test automation platform designed for SaaS startups to streamline and accelerate their testing processes. It offers AI-accelerated testing, no-code test automation, and expert QA services to help teams achieve reliable test coverage and faster release cycles. Rainforest QA's platform integrates with popular tools, provides detailed insights for easy debugging, and ensures visual-first testing for a seamless user experience. With a focus on automating end-to-end tests, Rainforest QA aims to eliminate QA bottlenecks and help teams ship bug-free code with confidence.
Verdent
Verdent is an AI-native coding tool designed to assist developers in coding tasks by providing advanced agent support, parallel coding capabilities, and access to leading AI models. It streamlines the coding process, enhances collaboration, and helps users focus on creation by handling tasks like documentation, data analysis, and prototyping. Verdent is praised for its speed, efficiency, and ability to orchestrate parallel coding agents, making it a valuable tool for software development workflows.

Keymate.AI
Keymate.AI is an AI application that allows users to build GPTs with advanced search, browse, and long-term memory capabilities. It offers a personalized long-term memory on ChatGPT, parallel search functionality, and privacy features using Google API. Keymate.AI aims to elevate research, projects, and daily tasks by providing efficient AI memory management and real-time data retrieval from the web.
Zappx
Zappx is a powerful power dialer application designed for sales professionals to enhance their cold calling outreach. With Zappx, users can double their daily connection rate by implementing parallel calling, dial up to 5 prospects simultaneously, filter out wrong numbers, automate voice mails, and connect calls to live prospects. The application also offers AI-enhanced features such as automated call transcription, sentiment analysis, and real-time analytics for performance evaluation. Zappx is built by sales people for sales people, aiming to transform outbound sales approaches with lightning-fast dialing capabilities.
Otto
Otto is an AI-powered tool designed to streamline work processes by bringing reasoning to data. It allows users to define tables once and automate numerous tasks in minutes. With features like research capabilities, outbound message creation, and customizable columns, Otto enables users to work 10x faster by leveraging AI agents for parallel processing. The tool unlocks insights from various data sources, including websites, documents, and images, and offers an AI Assistant for contextual assistance. Otto aims to enhance productivity and efficiency by providing advanced data analysis and processing functionalities.
FlashIntel
FlashIntel is a revenue acceleration platform that offers a suite of tools and solutions to streamline sales and partnership processes. It provides features like real-time enrichment, personalized messaging, sequence and cadence, email deliverability, parallel dialing, account-based marketing, and more. The platform aims to help businesses uncover ideal prospects, target key insights, craft compelling outreach sequences, research companies and people's contacts in real-time, and execute omnichannel sequences with AI personalization.

Cykel AI
Cykel AI is an AI co-pilot designed to assist users in automating various digital tasks. It interacts with any website to complete complex tasks based on user instructions, allowing users to offload 50% of their to-do list to AI. From sending emails to updating spreadsheets, Cykel offers a seamless way to streamline digital workflows and boost productivity. With features like autonomous learning, scalable parallel tasking, and the ability to create and share shortcuts, Cykel aims to revolutionize task automation for individuals and teams across different industries.
Automata
Automata is a content repurposing tool that uses AI to help you turn your videos, blogs, and other content into a variety of other formats, such as social media posts, email newsletters, and more. It offers a variety of features to make content repurposing easy and efficient, including platform-specific writing styles, 15+ content output types, content repurposing templates, and parallel content creation. Automata also has an AI Chrome extension for LinkedIn that can help you repurpose your content directly from the platform.
Beam AI
Beam AI is the #1 end-to-end automated takeoff software designed for General Contractors, Subcontractors, and Suppliers in the construction industry. It leverages cutting-edge Artificial Intelligence technology to provide accurate and fast quantity takeoffs for various trades, saving up to 90% of the time typically spent on manual takeoffs. With Beam AI, users can streamline their bidding process, send out more estimates, and focus on value engineering to build competitive estimates. The software offers features such as cloud-based collaboration, 100% done-for-you quantity takeoffs, auto-detection of spec details, and the ability to process multiple takeoffs in parallel.
Pentest Copilot
Pentest Copilot by BugBase is an ultimate ethical hacking assistant that guides users through each step of the hacking journey, from analyzing web apps to root shells. It eliminates redundant research, automates payload and command generation, and provides intelligent contextual analysis to save time. The application excels at data extraction, privilege escalation, lateral movement, and leaving no trace behind. With features like secure VPN integration, total control over sessions, parallel command processing, and flexibility to choose between local or cloud execution, Pentest Copilot offers a seamless and efficient hacking experience without the need for Kali Linux installation.
Iambic Therapeutics
Iambic Therapeutics is a cutting-edge AI-driven drug discovery platform that tackles the most challenging design problems in drug discovery, addressing unmet patient need. Its physics-based AI algorithms drive a high-throughput experimental platform, converting new molecular designs to new biological insights each week. Iambic's platform optimizes target product profiles, exploring multiple profiles in parallel to ensure that molecules are designed to solve the right problems in disease biology. It also optimizes drug candidates, deeply exploring chemical space to reveal novel mechanisms of action and deliver diverse high-quality leads.
echowin
echowin is an AI Voice Agent Builder Platform that enables businesses to create AI agents for calls, chat, and Discord. It offers a comprehensive solution for automating customer support with features like Agentic AI logic and reasoning, support for over 30 languages, parallel call answering, and 24/7 availability. The platform allows users to build, train, test, and deploy AI agents quickly and efficiently, without compromising on capabilities or scalability. With a focus on simplicity and effectiveness, echowin empowers businesses to enhance customer interactions and streamline operations through cutting-edge AI technology.
1 - Open Source AI Tools
ai-science-training-series
This repository contains a student training series focusing on AI-driven science on supercomputers. It covers topics such as ALCF systems overview, AI on supercomputers, neural networks, LLMs, and parallel training techniques. The content is organized into subdirectories with prefixed indexes for easy navigation. The series aims to provide hands-on experience and knowledge in utilizing AI on supercomputers for scientific research.
4 - OpenAI Gpts
Data Herald -Historical Parallel-Identifier
Call me Data- I draw historical parallels to your queries // An education tool // "Nothing new under the sun"

MPM-AI
The Multiversal Prediction Matrix (MPM) leverages the speculative nature of multiverse theories to create a predictive framework. By simulating parallel universes with varied parameters, MPM explores a multitude of potential outcomes for different events and phenomena.

CUDA GPT
Expert in CUDA for configuration, installation, troubleshooting, and programming.