
ai-gradio
A Python package that makes it easy for developers to create AI apps powered by various AI providers.
Stars: 1573
ai-gradio is a Python package that simplifies the creation of machine learning apps using various models like OpenAI, Google's Gemini, Anthropic's Claude, LumaAI, CrewAI, XAI's Grok, and Hyperbolic. It provides easy installation with support for different providers and offers features like text chat, voice chat, video chat, code generation interfaces, and AI agent teams. Users can set API keys for different providers and customize interfaces for specific tasks.
README:
A Python package that makes it easy for developers to create machine learning apps powered by various AI providers. Built on top of Gradio, it provides a unified interface for multiple AI models and services.
- Multi-Provider Support: Integrate with 15+ AI providers including OpenAI, Google Gemini, Anthropic, and more
- Text Chat: Interactive chat interfaces for all text models
- Voice Chat: Real-time voice interactions with OpenAI models
- Video Chat: Video processing capabilities with Gemini models
- Code Generation: Specialized interfaces for coding assistance
- Multi-Modal: Support for text, image, and video inputs
- Agent Teams: CrewAI integration for collaborative AI tasks
- Browser Automation: AI agents that can perform web-based tasks
- Computer-Use: AI agents that can control a virtual local macOS/Linux environment
| Provider | Models |
|---|---|
| OpenAI | gpt-4-turbo, gpt-4, gpt-3.5-turbo |
| Anthropic | claude-3-opus, claude-3-sonnet, claude-3-haiku |
| Gemini | gemini-pro, gemini-pro-vision, gemini-2.0-flash-exp |
| Groq | llama-3.2-70b-chat, mixtral-8x7b-chat |
| Provider | Type | Models |
|---|---|---|
| LumaAI | Generation | dream-machine, photon-1 |
| DeepSeek | Multi-purpose | deepseek-chat, deepseek-coder, deepseek-vision |
| CrewAI | Agent Teams | Support Team, Article Team |
| Qwen | Language | qwen-turbo, qwen-plus, qwen-max |
| Browser | Automation | browser-use-agent |
| Cua | Computer-Use | OpenAI Computer-Use Preview |
# Install core package
pip install ai-gradio
# Install with specific provider support
pip install 'ai-gradio[openai]' # OpenAI support
pip install 'ai-gradio[gemini]' # Google Gemini support
pip install 'ai-gradio[anthropic]' # Anthropic Claude support
pip install 'ai-gradio[groq]' # Groq support
# Install all providers
pip install 'ai-gradio[all]'pip install 'ai-gradio[crewai]' # CrewAI support
pip install 'ai-gradio[lumaai]' # LumaAI support
pip install 'ai-gradio[xai]' # XAI/Grok support
pip install 'ai-gradio[cohere]' # Cohere support
pip install 'ai-gradio[sambanova]' # SambaNova support
pip install 'ai-gradio[hyperbolic]' # Hyperbolic support
pip install 'ai-gradio[deepseek]' # DeepSeek support
pip install 'ai-gradio[smolagents]' # SmolagentsAI support
pip install 'ai-gradio[fireworks]' # Fireworks support
pip install 'ai-gradio[together]' # Together support
pip install 'ai-gradio[qwen]' # Qwen support
pip install 'ai-gradio[browser]' # Browser support
pip install 'ai-gradio[cua]' # Computer-Use support# Core Providers
export OPENAI_API_KEY=<your token>
export GEMINI_API_KEY=<your token>
export ANTHROPIC_API_KEY=<your token>
export GROQ_API_KEY=<your token>
export TAVILY_API_KEY=<your token> # Required for Langchain agents
# Additional Providers (as needed)
export LUMAAI_API_KEY=<your token>
export XAI_API_KEY=<your token>
export COHERE_API_KEY=<your token>
# ... (other provider keys)
# Twilio credentials (required for WebRTC voice chat)
export TWILIO_ACCOUNT_SID=<your Twilio account SID>
export TWILIO_AUTH_TOKEN=<your Twilio auth token>import gradio as gr
import ai_gradio
# Create a simple chat interface
gr.load(
name='openai:gpt-4-turbo', # or 'gemini:gemini-1.5-flash', 'groq:llama-3.2-70b-chat'
src=ai_gradio.registry,
title='AI Chat',
description='Chat with an AI model'
).launch()
# Create a chat interface with Transformers models
gr.load(
name='transformers:phi-4', # or 'transformers:tulu-3', 'transformers:olmo-2-13b'
src=ai_gradio.registry,
title='Local AI Chat',
description='Chat with locally running models'
).launch()
# Create a coding assistant with OpenAI
gr.load(
name='openai:gpt-4-turbo',
src=ai_gradio.registry,
coder=True,
title='OpenAI Code Assistant',
description='OpenAI Code Generator'
).launch()
# Create a coding assistant with Gemini
gr.load(
name='gemini:gemini-2.0-flash-thinking-exp-1219', # or 'openai:gpt-4-turbo', 'anthropic:claude-3-opus'
src=ai_gradio.registry,
coder=True,
title='Gemini Code Generator',
).launch()gr.load(
name='openai:gpt-4-turbo',
src=ai_gradio.registry,
enable_voice=True,
title='AI Voice Assistant'
).launch()# Create a vision-enabled interface with camera support
gr.load(
name='gemini:gemini-2.0-flash-exp',
src=ai_gradio.registry,
camera=True,
).launch()import gradio as gr
import ai_gradio
with gr.Blocks() as demo:
with gr.Tab("Text"):
gr.load('openai:gpt-4-turbo', src=ai_gradio.registry)
with gr.Tab("Vision"):
gr.load('gemini:gemini-pro-vision', src=ai_gradio.registry)
with gr.Tab("Code"):
gr.load('deepseek:deepseek-coder', src=ai_gradio.registry)
demo.launch()# Article Creation Team
gr.load(
name='crewai:gpt-4-turbo',
src=ai_gradio.registry,
crew_type='article',
title='AI Writing Team'
).launch()playwright installuse python 3.11+ for browser use
import gradio as gr
import ai_gradio
# Create a browser automation interface
gr.load(
name='browser:gpt-4-turbo',
src=ai_gradio.registry,
title='AI Browser Assistant',
description='Let AI help with web tasks'
).launch()Example tasks:
- Flight searches on Google Flights
- Weather lookups
- Product price comparisons
- News searches
# Install Computer-Use Agent support
pip install 'ai-gradio[cua]'
# Install Lume daemon (macOS only)
sudo /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/trycua/cua/main/libs/lume/scripts/install.sh)"
# Start the Lume daemon service (in a separate terminal)
lume serve
# Pull the pre-built macOS image
lume pull macos-sequoia-cua:latest --no-cacheRequires macOS with Apple Silicon (M1/M2/M3/M4) and macOS 14 (Sonoma) or newer.
import gradio as gr
import ai_gradio
from dotenv import load_dotenv
# Load API keys from .env file
load_dotenv()
# Create a computer-use automation interface with OpenAI
gr.load(
name='cua:gpt-4-turbo', # Format: 'cua:model_name'
src=ai_gradio.registry,
title='Computer-Use Agent',
description='AI that can control a virtual macOS environment'
).launch()Example tasks:
- Create Python virtual environments and run data analysis scripts
- Open PDFs in Preview, add annotations, and save compressed versions
- Browse Safari and manage bookmarks
- Clone and build GitHub repositories
- Configure SSH keys and remote connections
- Create automation scripts and schedule them with cron
import gradio as gr
import ai_gradio
# Create a chat interface with Swarms
gr.load(
name='swarms:gpt-4-turbo', # or other OpenAI models
src=ai_gradio.registry,
agent_name="Stock-Analysis-Agent", # customize agent name
title='Swarms Chat',
description='Chat with an AI agent powered by Swarms'
).launch()import gradio as gr
import ai_gradio
# Create a Langchain agent interface
gr.load(
name='langchain:gpt-4-turbo', # or other supported models
src=ai_gradio.registry,
title='Langchain Agent',
description='AI agent powered by Langchain'
).launch()- Python 3.10+
- gradio >= 5.9.1
- Voice Chat: gradio-webrtc, numba==0.60.0, pydub, librosa
- Video Chat: opencv-python, Pillow
- Agent Teams: crewai>=0.1.0, langchain>=0.1.0
If you encounter 401 errors, verify your API keys:
import os
# Set API keys manually if needed
os.environ["OPENAI_API_KEY"] = "your-api-key"
os.environ["GEMINI_API_KEY"] = "your-api-key"If you see "no providers installed" errors:
# Install specific provider
pip install 'ai-gradio[provider_name]'
# Or install all providers
pip install 'ai-gradio[all]'Contributions are welcome! Please feel free to submit a Pull Request.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for ai-gradio
Similar Open Source Tools
ai-gradio
ai-gradio is a Python package that simplifies the creation of machine learning apps using various models like OpenAI, Google's Gemini, Anthropic's Claude, LumaAI, CrewAI, XAI's Grok, and Hyperbolic. It provides easy installation with support for different providers and offers features like text chat, voice chat, video chat, code generation interfaces, and AI agent teams. Users can set API keys for different providers and customize interfaces for specific tasks.

dexto
Dexto is a lightweight runtime for creating and running AI agents that turn natural language into real-world actions. It serves as the missing intelligence layer for building AI applications, standalone chatbots, or as the reasoning engine inside larger products. Dexto features a powerful CLI and Web UI for running AI agents, supports multiple interfaces, allows hot-swapping of LLMs from various providers, connects to remote tool servers via the Model Context Protocol, is config-driven with version-controlled YAML, offers production-ready core features, extensibility for custom services, and enables multi-agent collaboration via MCP and A2A.
NextChat
NextChat is a well-designed cross-platform ChatGPT web UI tool that supports Claude, GPT4, and Gemini Pro. It offers a compact client for Linux, Windows, and MacOS, with features like self-deployed LLMs compatibility, privacy-first data storage, markdown support, responsive design, and fast loading speed. Users can create, share, and debug chat tools with prompt templates, access various prompts, compress chat history, and use multiple languages. The tool also supports enterprise-level privatization and customization deployment, with features like brand customization, resource integration, permission control, knowledge integration, security auditing, private deployment, and continuous updates.
ChatGPT-Next-Web
ChatGPT Next Web is a well-designed cross-platform ChatGPT web UI tool that supports Claude, GPT4, and Gemini Pro models. It allows users to deploy their private ChatGPT applications with ease. The tool offers features like one-click deployment, compact client for Linux/Windows/MacOS, compatibility with self-deployed LLMs, privacy-first approach with local data storage, markdown support, responsive design, fast loading speed, prompt templates, awesome prompts, chat history compression, multilingual support, and more.
adk-rust
ADK-Rust is a comprehensive and production-ready Rust framework for building AI agents. It features type-safe agent abstractions with async execution and event streaming, multiple agent types including LLM agents, workflow agents, and custom agents, realtime voice agents with bidirectional audio streaming, a tool ecosystem with function tools, Google Search, and MCP integration, production features like session management, artifact storage, memory systems, and REST/A2A APIs, and a developer-friendly experience with interactive CLI, working examples, and comprehensive documentation. The framework follows a clean layered architecture and is production-ready and actively maintained.
agentops
AgentOps is a toolkit for evaluating and developing robust and reliable AI agents. It provides benchmarks, observability, and replay analytics to help developers build better agents. AgentOps is open beta and can be signed up for here. Key features of AgentOps include: - Session replays in 3 lines of code: Initialize the AgentOps client and automatically get analytics on every LLM call. - Time travel debugging: (coming soon!) - Agent Arena: (coming soon!) - Callback handlers: AgentOps works seamlessly with applications built using Langchain and LlamaIndex.
BrowserAI
BrowserAI is a production-ready tool that allows users to run AI models directly in the browser, offering simplicity, speed, privacy, and open-source capabilities. It provides WebGPU acceleration for fast inference, zero server costs, offline capability, and developer-friendly features. Perfect for web developers, companies seeking privacy-conscious AI solutions, researchers experimenting with browser-based AI, and hobbyists exploring AI without infrastructure overhead. The tool supports various AI tasks like text generation, speech recognition, and text-to-speech, with pre-configured popular models ready to use. It offers a simple SDK with multiple engine support and seamless switching between MLC and Transformers engines.
browser-ai
Browser AI is a TypeScript library that provides access to in-browser AI model providers with seamless fallback to server-side models. It offers different packages for Chrome/Edge built-in browser AI models, open-source models via WebLLM, and 🤗 Transformers.js models. The library simplifies the process of integrating AI models into web applications by handling the complexities of custom hooks, UI components, state management, and compatibility with server-side models.
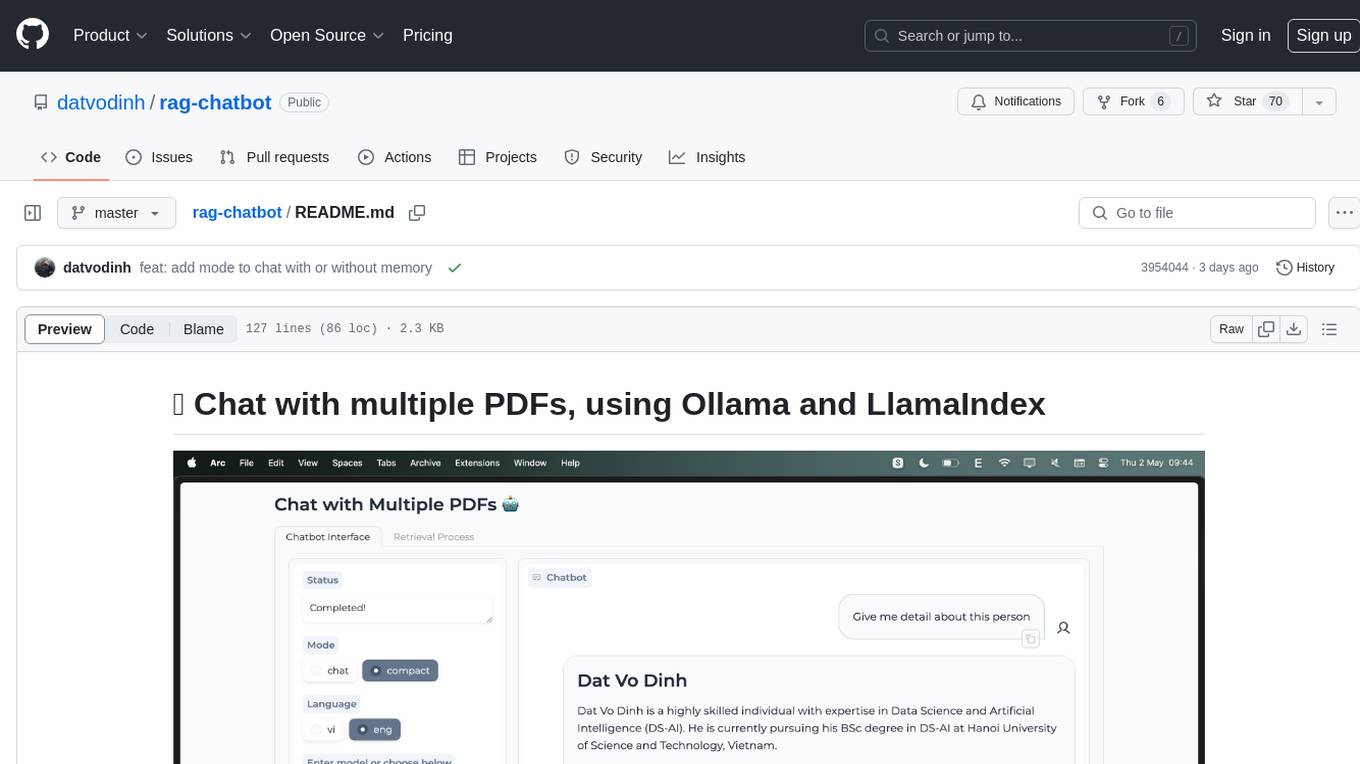
rag-chatbot
rag-chatbot is a tool that allows users to chat with multiple PDFs using Ollama and LlamaIndex. It provides an easy setup for running on local machines or Kaggle notebooks. Users can leverage models from Huggingface and Ollama, process multiple PDF inputs, and chat in multiple languages. The tool offers a simple UI with Gradio, supporting chat with history and QA modes. Setup instructions are provided for both Kaggle and local environments, including installation steps for Docker, Ollama, Ngrok, and the rag_chatbot package. Users can run the tool locally and access it via a web interface. Future enhancements include adding evaluation, better embedding models, knowledge graph support, improved document processing, MLX model integration, and Corrective RAG.
ai-coders-context
The @ai-coders/context repository provides the Ultimate MCP for AI Agent Orchestration, Context Engineering, and Spec-Driven Development. It simplifies context engineering for AI by offering a universal process called PREVC, which consists of Planning, Review, Execution, Validation, and Confirmation steps. The tool aims to address the problem of context fragmentation by introducing a single `.context/` directory that works universally across different tools. It enables users to create structured documentation, generate agent playbooks, manage workflows, provide on-demand expertise, and sync across various AI tools. The tool follows a structured, spec-driven development approach to improve AI output quality and ensure reproducible results across projects.
auto-engineer
Auto Engineer is a tool designed to automate the Software Development Life Cycle (SDLC) by building production-grade applications with a combination of human and AI agents. It offers a plugin-based architecture that allows users to install only the necessary functionality for their projects. The tool guides users through key stages including Flow Modeling, IA Generation, Deterministic Scaffolding, AI Coding & Testing Loop, and Comprehensive Quality Checks. Auto Engineer follows a command/event-driven architecture and provides a modular plugin system for specific functionalities. It supports TypeScript with strict typing throughout and includes a built-in message bus server with a web dashboard for monitoring commands and events.
UnrealGenAISupport
The Unreal Engine Generative AI Support Plugin is a tool designed to integrate various cutting-edge LLM/GenAI models into Unreal Engine for game development. It aims to simplify the process of using AI models for game development tasks, such as controlling scene objects, generating blueprints, running Python scripts, and more. The plugin currently supports models from organizations like OpenAI, Anthropic, XAI, Google Gemini, Meta AI, Deepseek, and Baidu. It provides features like API support, model control, generative AI capabilities, UI generation, project file management, and more. The plugin is still under development but offers a promising solution for integrating AI models into game development workflows.
dspy.rb
DSPy.rb is a Ruby framework for building reliable LLM applications using composable, type-safe modules. It enables developers to define typed signatures and compose them into pipelines, offering a more structured approach compared to traditional prompting. The framework embraces Ruby conventions and adds innovations like CodeAct agents and enhanced production instrumentation, resulting in scalable LLM applications that are robust and efficient. DSPy.rb is actively developed, with a focus on stability and real-world feedback through the 0.x series before reaching a stable v1.0 API.

tokscale
Tokscale is a high-performance CLI tool and visualization dashboard for tracking token usage and costs across multiple AI coding agents. It helps monitor and analyze token consumption from various AI coding tools, providing real-time pricing calculations using LiteLLM's pricing data. Inspired by the Kardashev scale, Tokscale measures token consumption as users scale the ranks of AI-augmented development. It offers interactive TUI mode, multi-platform support, real-time pricing, detailed breakdowns, web visualization, flexible filtering, and social platform features.
chatgpt-adapter
ChatGPT-Adapter is an interface service that integrates various free services together. It provides a unified interface specification and integrates services like Bing, Claude-2, Gemini. Users can start the service by running the linux-server script and set proxies if needed. The tool offers model lists for different adapters, completion dialogues, authorization methods for different services like Claude, Bing, Gemini, Coze, and Lmsys. Additionally, it provides a free drawing interface with options like coze.dall-e-3, sd.dall-e-3, xl.dall-e-3, pg.dall-e-3 based on user-provided Authorization keys. The tool also supports special flags for enhanced functionality.

Acontext
Acontext is a context data platform designed for production AI agents, offering unified storage, built-in context management, and observability features. It helps agents scale from local demos to production without the need to rebuild context infrastructure. The platform provides solutions for challenges like scattered context data, long-running agents requiring context management, and tracking states from multi-modal agents. Acontext offers core features such as context storage, session management, disk storage, agent skills management, and sandbox for code execution and analysis. Users can connect to Acontext, install SDKs, initialize clients, store and retrieve messages, perform context engineering, and utilize agent storage tools. The platform also supports building agents using end-to-end scripts in Python and Typescript, with various templates available. Acontext's architecture includes client layer, backend with API and core components, infrastructure with PostgreSQL, S3, Redis, and RabbitMQ, and a web dashboard. Join the Acontext community on Discord and follow updates on GitHub.
For similar tasks
ai-gradio
ai-gradio is a Python package that simplifies the creation of machine learning apps using various models like OpenAI, Google's Gemini, Anthropic's Claude, LumaAI, CrewAI, XAI's Grok, and Hyperbolic. It provides easy installation with support for different providers and offers features like text chat, voice chat, video chat, code generation interfaces, and AI agent teams. Users can set API keys for different providers and customize interfaces for specific tasks.

neo
Neo.mjs is a revolutionary Application Engine for the web that offers true multithreading and context engineering, enabling desktop-class UI performance and AI-driven runtime mutation. It is not a framework but a complete runtime and toolchain for enterprise applications, excelling in single page apps and browser-based multi-window applications. With a pioneering Off-Main-Thread architecture, Neo.mjs ensures butter-smooth UI performance by keeping the main thread free for flawless user interactions. The latest version, v11, introduces AI-native capabilities, allowing developers to work with AI agents as first-class partners in the development process. The platform offers a suite of dedicated Model Context Protocol servers that give agents the context they need to understand, build, and reason about the code, enabling a new level of human-AI collaboration.
aios-core
Synkra AIOS is a Framework for Universal AI Agents powered by AI. It is founded on Agent-Driven Agile Development, offering revolutionary capabilities for AI-driven development and more. Transform any domain with specialized AI expertise: software development, entertainment, creative writing, business strategy, personal well-being, and more. The framework follows a clear hierarchy of priorities: CLI First, Observability Second, UI Third. The CLI is where intelligence resides, all execution, decisions, and automation happen there. Observability is for observing and monitoring what happens in the CLI in real-time. The UI is for specific management and visualizations when necessary. The two key innovations of Synkra AIOS are Planejamento Agêntico and Desenvolvimento Contextualizado por Engenharia, which eliminate inconsistency in planning and loss of context in AI-assisted development.
qwery-core
Qwery is a platform for querying and visualizing data using natural language without technical knowledge. It seamlessly integrates with various datasources, generates optimized queries, and delivers outcomes like result sets, dashboards, and APIs. Features include natural language querying, multi-database support, AI-powered agents, visual data apps, desktop & cloud options, template library, and extensibility through plugins. The project is under active development and not yet suitable for production use.
For similar jobs

promptflow
**Prompt flow** is a suite of development tools designed to streamline the end-to-end development cycle of LLM-based AI applications, from ideation, prototyping, testing, evaluation to production deployment and monitoring. It makes prompt engineering much easier and enables you to build LLM apps with production quality.

deepeval
DeepEval is a simple-to-use, open-source LLM evaluation framework specialized for unit testing LLM outputs. It incorporates various metrics such as G-Eval, hallucination, answer relevancy, RAGAS, etc., and runs locally on your machine for evaluation. It provides a wide range of ready-to-use evaluation metrics, allows for creating custom metrics, integrates with any CI/CD environment, and enables benchmarking LLMs on popular benchmarks. DeepEval is designed for evaluating RAG and fine-tuning applications, helping users optimize hyperparameters, prevent prompt drifting, and transition from OpenAI to hosting their own Llama2 with confidence.

MegaDetector
MegaDetector is an AI model that identifies animals, people, and vehicles in camera trap images (which also makes it useful for eliminating blank images). This model is trained on several million images from a variety of ecosystems. MegaDetector is just one of many tools that aims to make conservation biologists more efficient with AI. If you want to learn about other ways to use AI to accelerate camera trap workflows, check out our of the field, affectionately titled "Everything I know about machine learning and camera traps".

leapfrogai
LeapfrogAI is a self-hosted AI platform designed to be deployed in air-gapped resource-constrained environments. It brings sophisticated AI solutions to these environments by hosting all the necessary components of an AI stack, including vector databases, model backends, API, and UI. LeapfrogAI's API closely matches that of OpenAI, allowing tools built for OpenAI/ChatGPT to function seamlessly with a LeapfrogAI backend. It provides several backends for various use cases, including llama-cpp-python, whisper, text-embeddings, and vllm. LeapfrogAI leverages Chainguard's apko to harden base python images, ensuring the latest supported Python versions are used by the other components of the stack. The LeapfrogAI SDK provides a standard set of protobuffs and python utilities for implementing backends and gRPC. LeapfrogAI offers UI options for common use-cases like chat, summarization, and transcription. It can be deployed and run locally via UDS and Kubernetes, built out using Zarf packages. LeapfrogAI is supported by a community of users and contributors, including Defense Unicorns, Beast Code, Chainguard, Exovera, Hypergiant, Pulze, SOSi, United States Navy, United States Air Force, and United States Space Force.

llava-docker
This Docker image for LLaVA (Large Language and Vision Assistant) provides a convenient way to run LLaVA locally or on RunPod. LLaVA is a powerful AI tool that combines natural language processing and computer vision capabilities. With this Docker image, you can easily access LLaVA's functionalities for various tasks, including image captioning, visual question answering, text summarization, and more. The image comes pre-installed with LLaVA v1.2.0, Torch 2.1.2, xformers 0.0.23.post1, and other necessary dependencies. You can customize the model used by setting the MODEL environment variable. The image also includes a Jupyter Lab environment for interactive development and exploration. Overall, this Docker image offers a comprehensive and user-friendly platform for leveraging LLaVA's capabilities.

carrot
The 'carrot' repository on GitHub provides a list of free and user-friendly ChatGPT mirror sites for easy access. The repository includes sponsored sites offering various GPT models and services. Users can find and share sites, report errors, and access stable and recommended sites for ChatGPT usage. The repository also includes a detailed list of ChatGPT sites, their features, and accessibility options, making it a valuable resource for ChatGPT users seeking free and unlimited GPT services.

TrustLLM
TrustLLM is a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. The document explains how to use the trustllm python package to help you assess the performance of your LLM in trustworthiness more quickly. For more details about TrustLLM, please refer to project website.

AI-YinMei
AI-YinMei is an AI virtual anchor Vtuber development tool (N card version). It supports fastgpt knowledge base chat dialogue, a complete set of solutions for LLM large language models: [fastgpt] + [one-api] + [Xinference], supports docking bilibili live broadcast barrage reply and entering live broadcast welcome speech, supports Microsoft edge-tts speech synthesis, supports Bert-VITS2 speech synthesis, supports GPT-SoVITS speech synthesis, supports expression control Vtuber Studio, supports painting stable-diffusion-webui output OBS live broadcast room, supports painting picture pornography public-NSFW-y-distinguish, supports search and image search service duckduckgo (requires magic Internet access), supports image search service Baidu image search (no magic Internet access), supports AI reply chat box [html plug-in], supports AI singing Auto-Convert-Music, supports playlist [html plug-in], supports dancing function, supports expression video playback, supports head touching action, supports gift smashing action, supports singing automatic start dancing function, chat and singing automatic cycle swing action, supports multi scene switching, background music switching, day and night automatic switching scene, supports open singing and painting, let AI automatically judge the content.