Best AI tools for< Train New Boo Ai >
20 - AI tool Sites
Peqaboo
Peqaboo is an AI-powered pet social app designed to help pet owners with various aspects of pet care. The app allows users to ask Boo AI questions about their pets, identify toxic plants or foods, and receive instant answers based on their pet's profile. Peqaboo also offers a feature to train a new Boo AI, enabling users to transform their knowledge into AI tools. The app aims to make pet life easier and more enjoyable by providing personalized pet care advice and fostering a global pet community.
DocAI
DocAI is an API-driven platform that enables you to implement contracts AI into your applications, without requiring development from the ground-up. Our AI identifies and extracts 1,300+ common legal clauses, provisions and data points from a variety of document types. Our AI is a low-code experience for all. Easily train new fields without the need for a data scientist. All you need is subject matter expertise. Flexible and scalable. Flexible deployment options in the Zuva hosted cloud or on prem, across multiple geographical regions. Reliable, expert-built AI our customers can trust. Over 1,300+ out of the box AI fields that are built and trained by experienced lawyers and subject matter experts. Fields identify and extract common legal clauses, provisions and data points from unstructured documents and contracts, including ones written in non-standard language.
LaunchPal
LaunchPal is an AI-powered marketing tool designed to streamline and enhance the marketing workflow for individuals, agencies, and enterprises. It enables users to train AI on new brands in minutes, deliver results quickly, manage clients efficiently, and improve content delivery over time. LaunchPal offers features such as effortless setup, content engine, client portal, pricing plans tailored for different user needs, and a user-friendly interface for a seamless experience.
Workout Tools
Workout Tools is an AI-powered personal trainer that helps you train smarter and reach your fitness goals faster. It takes into account different parameters, such as your physics, the type of workout you're interested in, your available equipment, and comes up with a suggested workout. Don't like the workout? Just generate another one. It's that simple.
CrazyHorseAI
CrazyHorseAI is an AI tool that offers an API for users to enhance and customize the appearance and personality traits of an AI girl through features like changing clothes, hair, body, pose, and background. The tool provides functionalities such as natural language processing, emotional intelligence, and adaptive learning capabilities to create immersive and engaging experiences.
Unsloth
Unsloth is an AI tool designed to make finetuning large language models like Llama-3, Mistral, Phi-3, and Gemma 2x faster, use 70% less memory, and with no degradation in accuracy. The tool provides documentation to help users navigate through training their custom models, covering essentials such as installing and updating Unsloth, creating datasets, running, and deploying models. Users can also integrate third-party tools and utilize platforms like Google Colab.
Surge AI
Surge AI is a data labeling platform that provides human-generated data for training and evaluating large language models (LLMs). It offers a global workforce of annotators who can label data in over 40 languages. Surge AI's platform is designed to be easy to use and integrates with popular machine learning tools and frameworks. The company's customers include leading AI companies, research labs, and startups.
Passarel
Passarel is an AI tool designed to simplify teammate onboarding by developing bespoke GPT-like models for employee interaction. It centralizes knowledge bases into a custom model, allowing new teammates to access information efficiently. Passarel leverages various integrations to tailor language models to team needs, handling contradictions and providing accurate information. The tool works by training models on chosen knowledge bases, learning from data and configurations provided, and deploying the model for team use.
ImagineMe
ImagineMe is a personal AI art generator that allows users to create stunning art of themselves from a simple text description. The application uses AI models to convert text into corresponding images, enabling users to visualize themselves in various scenarios. ImagineMe offers an easy, affordable, and magical way to create personalized art.
Cartesia Sonic Team Blog Research Playground
Cartesia Sonic Team Blog Research Playground is an AI application that offers real-time multimodal intelligence for every device. The application aims to build the next generation of AI by providing ubiquitous, interactive intelligence that can run on any device. It features the fastest, ultra-realistic generative voice API and is backed by research on simple linear attention language models and state-space models. The founding team, who met at the Stanford AI Lab, has invented State Space Models (SSMs) and scaled it up to achieve state-of-the-art results in various modalities such as text, audio, video, images, and time-series data.
Deep English
Deep English is an AI chatbot application designed to help users improve their English language skills through interactive lessons, practice conversations with AI assistance, and engaging storytelling. The platform offers free lessons, fast fluency formulas, and personalized vocabulary learning. Users can speak quickly, understand native speakers, and connect with a global community for 24/7 English practice. Deep English aims to boost users' confidence in speaking English fluently and understanding conversations effectively.
Unified DevOps platform to build AI applications
This is a unified DevOps platform to build AI applications. It provides a comprehensive set of tools and services to help developers build, deploy, and manage AI applications. The platform includes a variety of features such as a code editor, a debugger, a profiler, and a deployment manager. It also provides access to a variety of AI services, such as natural language processing, machine learning, and computer vision.
AGENT
AGENT is an AI chatbot powered by OpenAI and Anthropic, designed to handle customer inquiries, qualify leads, and enhance customer engagement. Developed by I Need Leads Ltd, AGENT combines advanced natural language processing, intelligent chatbots, and machine learning to empower businesses of all sizes in generating and managing leads efficiently. The platform adapts, learns, and grows with businesses, ensuring they stay ahead in the competitive digital landscape.
Bifrost AI
Bifrost AI is a data generation engine designed for AI and robotics applications. It enables users to train and validate AI models faster by generating physically accurate synthetic datasets in 3D simulations, eliminating the need for real-world data. The platform offers pixel-perfect labels, scenario metadata, and a simulated 3D world to enhance AI understanding. Bifrost AI empowers users to create new scenarios and datasets rapidly, stress test AI perception, and improve model performance. It is built for teams at every stage of AI development, offering features like automated labeling, class imbalance correction, and performance enhancement.
Audimee
Audimee is an AI-powered application that offers unlimited vocals and creative freedom to users. With Audimee, users can convert vocals using royalty-free voices, train their own voices, create copyright-free cover vocals, and more. The application utilizes a reworked RVC model and superior studio recordings to provide users with high-quality and dynamic human-like voices. Audimee is designed to handle a wider range of pitches and produce fewer detectable AI artifacts, setting a new standard in vocal conversion technology.
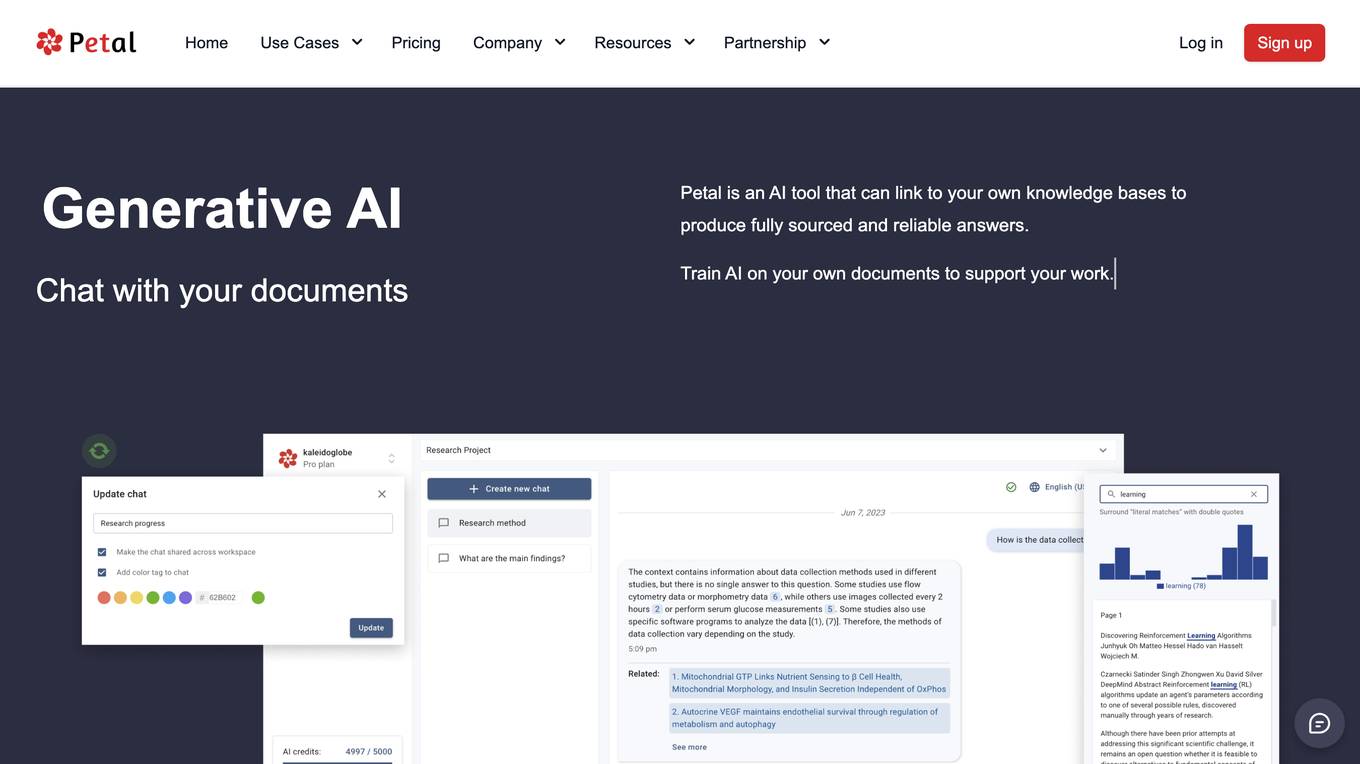
Petal
Petal is a document analysis platform powered by generative AI technology. It allows users to chat with their documents, providing fully sourced and reliable answers by linking to their own knowledge bases. Users can train AI on their documents to support their work, ensuring centralized knowledge management and document synchronization. Petal offers features such as automatic metadata extraction, file deduplication, and collaboration tools to enhance productivity and streamline workflows for researchers, faculty, and industry experts.

LAION
LAION is a non-profit organization that provides datasets, tools, and models to advance machine learning research. The organization's goal is to promote open public education and encourage the reuse of existing datasets and models to reduce the environmental impact of machine learning research.
PyTorch
PyTorch is an open-source machine learning library based on the Torch library. It is used for applications such as computer vision, natural language processing, and reinforcement learning. PyTorch is known for its flexibility and ease of use, making it a popular choice for researchers and developers in the field of artificial intelligence.
syntheticAIdata
syntheticAIdata is a platform that provides synthetic data for training vision AI models. Synthetic data is generated artificially, and it can be used to augment existing real-world datasets or to create new datasets from scratch. syntheticAIdata's platform is easy to use, and it can be integrated with leading cloud platforms. The company's mission is to make synthetic data accessible to everyone, and to help businesses overcome the challenges of acquiring high-quality data for training their vision AI models.

Incribo
Incribo is a company that provides synthetic data for training machine learning models. Synthetic data is artificially generated data that is designed to mimic real-world data. This data can be used to train machine learning models without the need for real-world data, which can be expensive and difficult to obtain. Incribo's synthetic data is high quality and affordable, making it a valuable resource for machine learning developers.
0 - Open Source AI Tools
20 - OpenAI Gpts

Sales Assistant GPT
I'm here to help sales people position value to customers! Tell me about your product and service, who are are selling to, and what we need to do!

ZhongKui (TradeMaster)
Advanced Real-Time Market Data Analysis AI Trader Incubator Professional Trading Trainer
Furry Love
Your AI-powered pet care assistant! Tailored for both new and seasoned pet owners, it offers customized advice on everything from choosing the right breed to detailed care plans. Understand your pet's behavior, get first aid tips, and enjoy a user-friendly experience in your preferred language.
RansomChatGPT
I'm a ransomware negotiation simulation and analysis bot trained with over 131 real-life negotiations. Type "start negotiation" to begin! New feature: Type "threat actor personality test"

Golden Retriever Training Assistant and Consultant
Golden Retriever training expert providing advice and tips
U-boat Command
Military submarine terminal simulator. Copyright (C) 2023, Sourceduty - All Rights Reserved.
Historical Strategist: The Rise of Julius Caesar
A Roman strategy game with many different facets, from war to espionage to building your empire, and every game unique
Training Manual Generator GPT
I create tailored training manuals for various jobs and industries.

末日幸存者:社会动态模拟 Doomsday Survivor
上帝视角观察、探索和影响一个末日丧尸灾难后的人类社会。Observe, explore and influence human society after the apocalyptic zombie disaster from a God's perspective. Sponsor:小红书“ ItsJoe就出行 ”


HR Automation GPT
Advises on automating HR processes with GPTs, focusing on practicality and industry trends.