Best AI tools for< Quantize Llms >
0 - AI tool Sites
3 - Open Source AI Tools

litgpt
LitGPT is a command-line tool designed to easily finetune, pretrain, evaluate, and deploy 20+ LLMs **on your own data**. It features highly-optimized training recipes for the world's most powerful open-source large-language-models (LLMs).
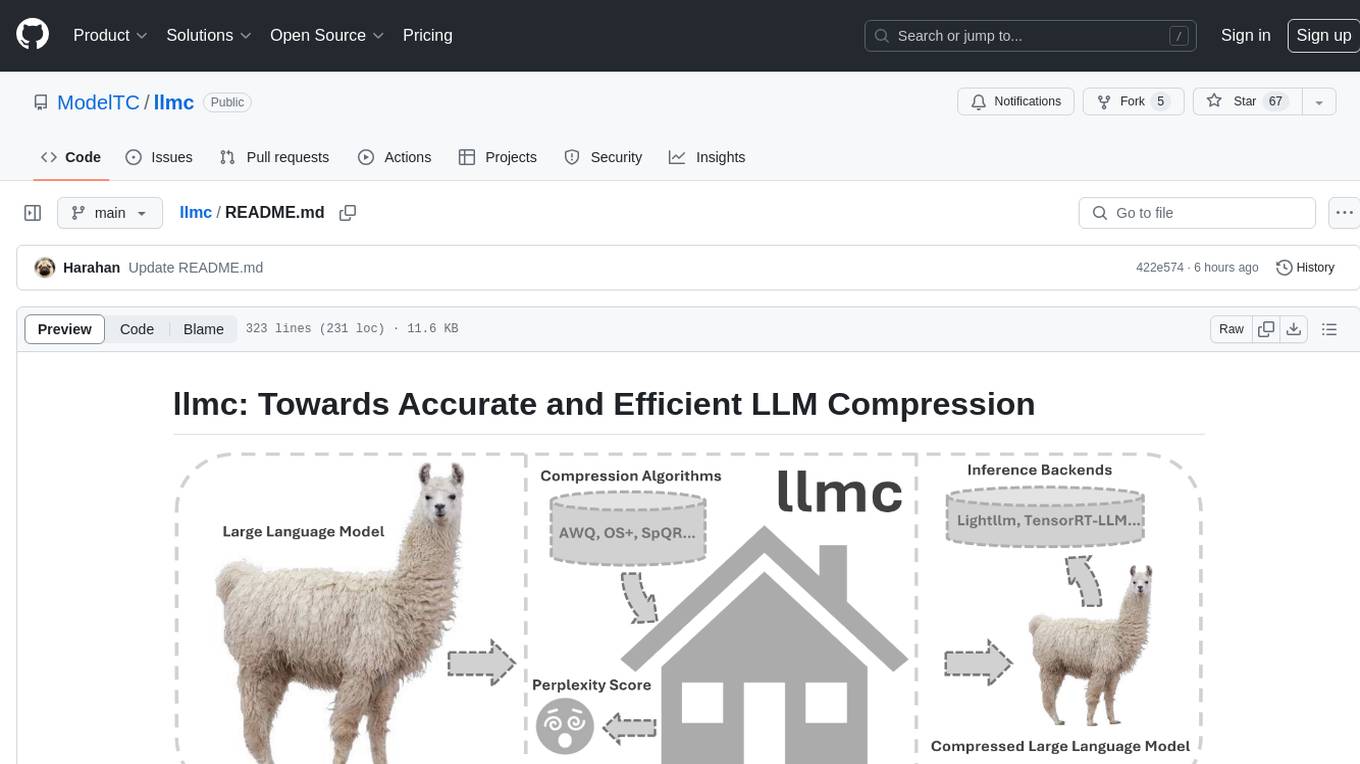
llmc
llmc is an off-the-shell tool designed for compressing LLM, leveraging state-of-the-art compression algorithms to enhance efficiency and reduce model size without compromising performance. It provides users with the ability to quantize LLMs, choose from various compression algorithms, export transformed models for further optimization, and directly infer compressed models with a shallow memory footprint. The tool supports a range of model types and quantization algorithms, with ongoing development to include pruning techniques. Users can design their configurations for quantization and evaluation, with documentation and examples planned for future updates. llmc is a valuable resource for researchers working on post-training quantization of large language models.
PrefixQuant
PrefixQuant is an official PyTorch implementation for static quantization that outperforms dynamic quantization in Large Language Models (LLMs) by utilizing prefixed outliers. The tool provides functionalities for quantization, inference, and visualization of activation distributions. Users can fine-tune quantization settings and evaluate pre-quantized models for tasks like PIQA, ARC, Hellaswag, and Winogrande. The approach aims to improve performance and efficiency in LLMs through innovative quantization techniques.