Best AI tools for< Multivariate Time Series Classification >
2 - AI tool Sites
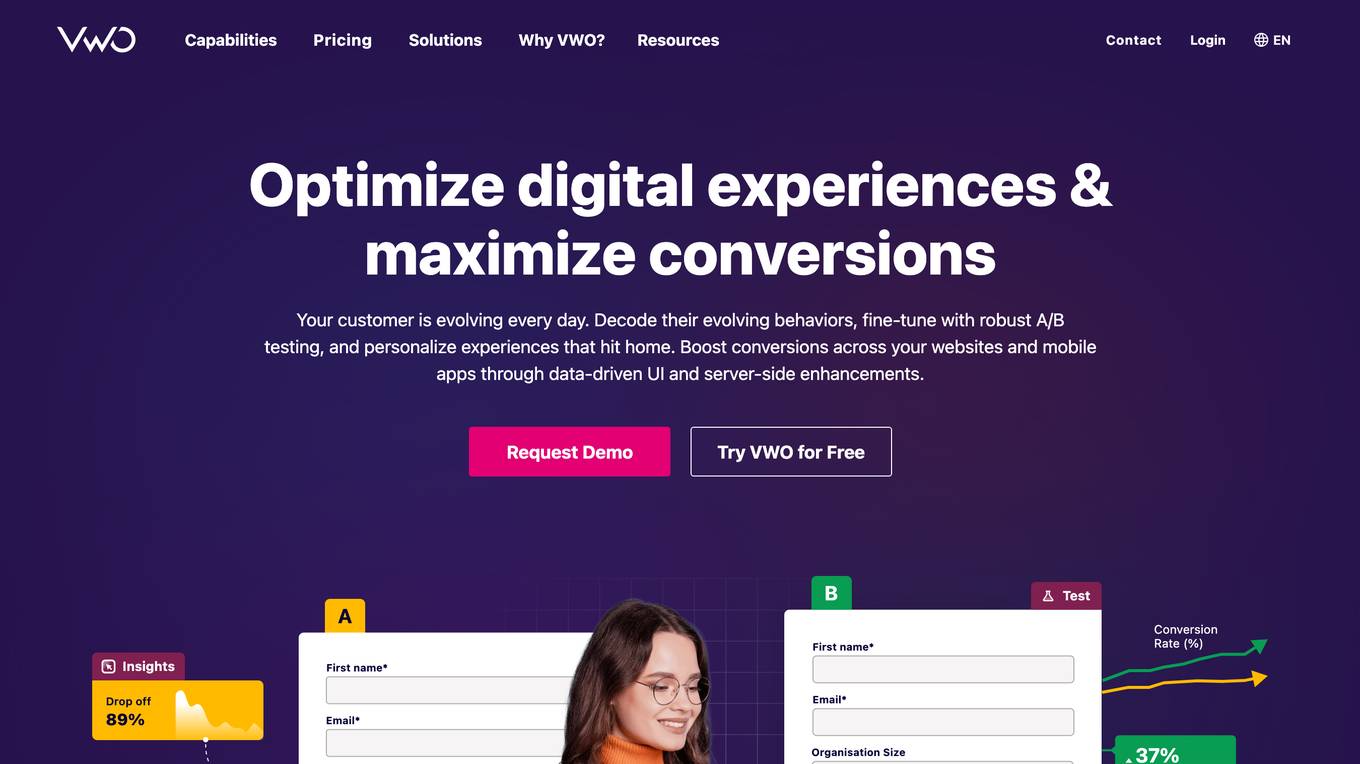
VWO
VWO is a comprehensive experimentation platform that enables businesses to optimize their digital experiences and maximize conversions. With a suite of products designed for the entire optimization program, VWO empowers users to understand user behavior, validate optimization hypotheses, personalize experiences, and deliver tailored content and experiences to specific audience segments. VWO's platform is designed to be enterprise-ready and scalable, with top-notch features, strong security, easy accessibility, and excellent performance. Trusted by thousands of leading brands, VWO has helped businesses achieve impressive growth through experimentation loops that shape customer experience in a positive direction.

Breadcrumbs
Breadcrumbs is a revenue acceleration platform that helps businesses optimize their entire sales and marketing funnel. It provides enterprise-grade lead scoring, allowing businesses to identify and prioritize their most promising leads. Breadcrumbs also offers a range of other features, such as data-driven model creation, unlimited workspaces and models, multi-variate testing, and integrations with a variety of marketing and sales tools. With Breadcrumbs, businesses can improve their lead quality, increase conversion rates, and accelerate revenue growth.
1 - Open Source AI Tools
LLMs4TS
LLMs4TS is a repository focused on the application of cutting-edge AI technologies for time-series analysis. It covers advanced topics such as self-supervised learning, Graph Neural Networks for Time Series, Large Language Models for Time Series, Diffusion models, Mixture-of-Experts architectures, and Mamba models. The resources in this repository span various domains like healthcare, finance, and traffic, offering tutorials, courses, and workshops from prestigious conferences. Whether you're a professional, data scientist, or researcher, the tools and techniques in this repository can enhance your time-series data analysis capabilities.