Best AI tools for< extracting information from pdfs >
20 - AI tool Sites

HelpMoji
HelpMoji is a next-generation search engine for online support. It provides instant solutions to technical queries related to websites, apps, and games. Unlike regular AI, HelpMoji utilizes Google and ChatGPT to deliver highly relevant and accurate answers. It is free to use, works on all devices with a browser and internet connection, and offers features such as App Assist, Gaming Aid, Screenshot2Solution, and PDF Assist.
FragDasPDF
**FragDasPDF** is an AI-powered tool that allows users to ask questions about PDF documents and receive answers in natural language. It supports a wide range of languages and can extract information from complex documents quickly and easily. With FragDasPDF, users can save time and effort by getting the information they need without having to read through long and dense documents.
Summarize This
Summarize This is an AI-powered tool that provides instant summaries for text, PDFs, websites, and YouTube videos. It utilizes advanced AI algorithms to extract the most important information from any content, making it easier and faster to gather insights. With Summarize This, you can quickly condense large amounts of text into concise summaries, saving you time and effort. The tool is particularly useful for students, researchers, professionals, and anyone who needs to process large amounts of information efficiently.
Kupiks
Kupiks is an automated email parsing tool designed to simplify data entry processes by extracting key information from emails such as customer inquiries, leads, invoices, and more. By automating the data entry process, Kupiks helps save valuable time and reduce errors. The tool is user-friendly and streamlines workflow by providing a seamless solution for customer support, order management, and expense management.
FormX.ai
FormX.ai is an AI-powered data extraction and conversion tool that automates the process of extracting data from physical documents and converting it into digital formats. It supports a wide range of document types, including invoices, receipts, purchase orders, bank statements, contracts, HR forms, shipping orders, loyalty member applications, annual reports, business certificates, personnel licenses, and more. FormX.ai's pre-configured data extraction models and effortless API integration make it easy for businesses to integrate data extraction into their existing systems and workflows. With FormX.ai, businesses can save time and money on manual data entry and improve the accuracy and efficiency of their data processing.
jamie
jamie is an AI-powered notetaking tool designed for meeting notes and automated action items. It offers automatic generation of meeting summaries, transcripts, and action items across various tools and languages. With a privacy-first approach, jamie helps users become master notetakers effortlessly by extracting tasks, detecting decisions, and providing detailed transcripts. It works seamlessly with popular meeting platforms and offers features like semantic search, custom note templates, and the ability to teach custom words for accurate summaries. Users can save time, improve productivity, and effortlessly retrieve information from meeting notes with jamie.
Notable AI
Notable AI is an AI tool designed to help users capture, share, and manage key takeaways from various sources efficiently. It leverages artificial intelligence to streamline the process of extracting and organizing important information, making it easier for users to access and utilize valuable insights. With Notable AI, users can enhance their productivity by quickly capturing essential points, sharing them with others, and effectively managing their key learnings.
TextMine
TextMine is an AI-powered knowledge base that helps businesses analyze, manage, and search thousands of documents. It uses AI to analyze unstructured textual data and document databases, automatically retrieving key terms to help users make informed decisions. TextMine's features include a document vault for storing and managing documents, a categorization system for organizing documents, and a data extraction tool for extracting insights from documents. TextMine can help businesses save time, money, and improve efficiency by automating manual data entry and information retrieval tasks.
BabblerAI
BabblerAI is an advanced artificial intelligence tool designed to assist businesses in analyzing and extracting valuable insights from large volumes of text data. The application utilizes natural language processing and machine learning algorithms to provide users with actionable intelligence and automate the process of information extraction. With BabblerAI, users can streamline their data analysis workflows, uncover trends and patterns, and make data-driven decisions with confidence. The tool is user-friendly and offers a range of features to enhance productivity and efficiency in data analysis tasks.
LeaseLens
LeaseLens is a free AI-based lease abstraction software that simplifies the process of extracting relevant data points from real estate or commercial lease documents. It uses machine learning technology to provide accurate lease abstracts in minutes, saving time and cost compared to manual abstraction services. Users can customize the information extracted and export results to Excel or Word for a small fee. The platform ensures data privacy by not sharing information with third parties and deleting leases after abstraction.
Summarize.ing
Summarize.ing is an AI-powered tool that provides instant summaries of YouTube videos. It helps users save time by extracting key insights, concepts, and highlights from videos, making it easier to understand and retain information. The tool is particularly useful for educational content, tutorials, and news videos.

ContextClue
ContextClue is an AI-powered text analysis tool that helps users quickly understand and extract information from large volumes of text. It can summarize content, simplify complex topics, and answer questions based on the provided text. ContextClue is designed to assist researchers, students, journalists, businesses, data analysts, and anyone who needs to efficiently process and comprehend textual information.
Recap
Recap is an open-source browser extension that allows users to easily summarize any portion of a webpage using ChatGPT. It provides a convenient way to extract key information from articles or websites. Users can simply select the text they want to summarize, and Recap will generate a concise summary using the power of ChatGPT. The extension is designed to enhance productivity and streamline information consumption for users who need quick insights or summaries while browsing the web.
ScreenApp
ScreenApp is an AI-powered tool that offers a range of features such as notetaking, transcription, summarization, and recording for both audio and video content. It provides users with the ability to easily transcribe, summarize, and generate notes from various types of recordings using advanced AI technology. ScreenApp aims to streamline content review processes, enhance productivity, and facilitate efficient information extraction from recorded meetings, lectures, webinars, and more. The tool prioritizes data security by undergoing regular security checks, offering secure data storage, data encryption, and optional local storage for added security.
PYQ
PYQ is an AI-powered platform that helps businesses automate document-related tasks, such as data extraction, form filling, and system integration. It uses natural language processing (NLP) and machine learning (ML) to understand the content of documents and perform tasks accordingly. PYQ's platform is designed to be easy to use, with pre-built automations for common use cases. It also offers custom automation development services for more complex needs.
Docugami
Docugami is a document engineering platform that uses artificial intelligence to extract, analyze, and automate data from business documents. It is designed to empower business users with immediate impact, without the need for massive investment in machine learning, staff training, or IT development. Docugami's proprietary Business Document Foundation Model is an LLM for Generative AI that can be applied to any type of business document.
Make your image 3D
This website provides a tool that allows users to convert 2D images into 3D images. The tool uses artificial intelligence to extract depth information from the image, which is then used to create a 3D model. The resulting 3D model can be embedded into a website or shared via a link.

Flash Insights
Flash Insights is a web extension that allows users to extract valuable insights from any webpage or video and integrate them with AI chatbots. It offers a range of features to help users learn more efficiently, including the ability to summarize podcasts, extract recipes from cooking videos, and get unbiased news analysis. Flash Insights is free to use and available for a variety of browsers, including Google Chrome, Microsoft Edge, and Mozilla Firefox.
Honeybear.ai
Honeybear.ai is an AI tool designed to simplify document reading tasks. It utilizes advanced algorithms to extract and analyze text from various documents, making it easier for users to access and comprehend information. With Honeybear.ai, users can streamline their document processing workflows and enhance productivity.
Extracta.ai
Extracta.ai is a cloud-based data extraction platform that uses artificial intelligence (AI) to automatically extract data from unstructured documents. It can be used to extract data from a variety of document types, including invoices, resumes, contracts, receipts, and custom documents. Extracta.ai is easy to use and requires no training. Simply define the fields that you want to extract from your documents, upload the documents, and Extracta.ai will do the rest. Extracta.ai is a powerful tool that can help you save time and money by automating your data extraction processes.
20 - Open Source AI Tools

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.
langroid
Langroid is a Python framework that makes it easy to build LLM-powered applications. It uses a multi-agent paradigm inspired by the Actor Framework, where you set up Agents, equip them with optional components (LLM, vector-store and tools/functions), assign them tasks, and have them collaboratively solve a problem by exchanging messages. Langroid is a fresh take on LLM app-development, where considerable thought has gone into simplifying the developer experience; it does not use Langchain.
vectordb-recipes
This repository contains examples, applications, starter code, & tutorials to help you kickstart your GenAI projects. * These are built using LanceDB, a free, open-source, serverless vectorDB that **requires no setup**. * It **integrates into python data ecosystem** so you can simply start using these in your existing data pipelines in pandas, arrow, pydantic etc. * LanceDB has **native Typescript SDK** using which you can **run vector search** in serverless functions! This repository is divided into 3 sections: - Examples - Get right into the code with minimal introduction, aimed at getting you from an idea to PoC within minutes! - Applications - Ready to use Python and web apps using applied LLMs, VectorDB and GenAI tools - Tutorials - A curated list of tutorials, blogs, Colabs and courses to get you started with GenAI in greater depth.

spring-ai
The Spring AI project provides a Spring-friendly API and abstractions for developing AI applications. It offers a portable client API for interacting with generative AI models, enabling developers to easily swap out implementations and access various models like OpenAI, Azure OpenAI, and HuggingFace. Spring AI also supports prompt engineering, providing classes and interfaces for creating and parsing prompts, as well as incorporating proprietary data into generative AI without retraining the model. This is achieved through Retrieval Augmented Generation (RAG), which involves extracting, transforming, and loading data into a vector database for use by AI models. Spring AI's VectorStore abstraction allows for seamless transitions between different vector database implementations.

zshot
Zshot is a highly customizable framework for performing Zero and Few shot named entity and relationships recognition. It can be used for mentions extraction, wikification, zero and few shot named entity recognition, zero and few shot named relationship recognition, and visualization of zero-shot NER and RE extraction. The framework consists of two main components: the mentions extractor and the linker. There are multiple mentions extractors and linkers available, each serving a specific purpose. Zshot also includes a relations extractor and a knowledge extractor for extracting relations among entities and performing entity classification. The tool requires Python 3.6+ and dependencies like spacy, torch, transformers, evaluate, and datasets for evaluation over datasets like OntoNotes. Optional dependencies include flair and blink for additional functionalities. Zshot provides examples, tutorials, and evaluation methods to assess the performance of the components.

serverless-pdf-chat
The serverless-pdf-chat repository contains a sample application that allows users to ask natural language questions of any PDF document they upload. It leverages serverless services like Amazon Bedrock, AWS Lambda, and Amazon DynamoDB to provide text generation and analysis capabilities. The application architecture involves uploading a PDF document to an S3 bucket, extracting metadata, converting text to vectors, and using a LangChain to search for information related to user prompts. The application is not intended for production use and serves as a demonstration and educational tool.
LLMAgentPapers
LLM Agents Papers is a repository containing must-read papers on Large Language Model Agents. It covers a wide range of topics related to language model agents, including interactive natural language processing, large language model-based autonomous agents, personality traits in large language models, memory enhancements, planning capabilities, tool use, multi-agent communication, and more. The repository also provides resources such as benchmarks, types of tools, and a tool list for building and evaluating language model agents. Contributors are encouraged to add important works to the repository.

open-parse
Open Parse is a Python library for visually discerning document layouts and chunking them effectively. It is designed to fill the gap in open-source libraries for handling complex documents. Unlike text splitting, which converts a file to raw text and slices it up, Open Parse visually analyzes documents for superior LLM input. It also supports basic markdown for parsing headings, bold, and italics, and has high-precision table support, extracting tables into clean Markdown formats with accuracy that surpasses traditional tools. Open Parse is extensible, allowing users to easily implement their own post-processing steps. It is also intuitive, with great editor support and completion everywhere, making it easy to use and learn.

thepipe
The Pipe is a multimodal-first tool for feeding files and web pages into vision-language models such as GPT-4V. It is best for LLM and RAG applications that require a deep understanding of tricky data sources. The Pipe is available as a hosted API at thepi.pe, or it can be set up locally.

HuggingFists
HuggingFists is a low-code data flow tool that enables convenient use of LLM and HuggingFace models. It provides functionalities similar to Langchain, allowing users to design, debug, and manage data processing workflows, create and schedule workflow jobs, manage resources environment, and handle various data artifact resources. The tool also offers account management for users, allowing centralized management of data source accounts and API accounts. Users can access Hugging Face models through the Inference API or locally deployed models, as well as datasets on Hugging Face. HuggingFists supports breakpoint debugging, branch selection, function calls, workflow variables, and more to assist users in developing complex data processing workflows.
llm-graph-builder
Knowledge Graph Builder App is a tool designed to convert PDF documents into a structured knowledge graph stored in Neo4j. It utilizes OpenAI's GPT/Diffbot LLM to extract nodes, relationships, and properties from PDF text content. Users can upload files from local machine or S3 bucket, choose LLM model, and create a knowledge graph. The app integrates with Neo4j for easy visualization and querying of extracted information.

deepdoctection
**deep** doctection is a Python library that orchestrates document extraction and document layout analysis tasks using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models. For more specific text processing tasks use one of the many other great NLP libraries. **deep** doctection focuses on applications and is made for those who want to solve real world problems related to document extraction from PDFs or scans in various image formats. **deep** doctection provides model wrappers of supported libraries for various tasks to be integrated into pipelines. Its core function does not depend on any specific deep learning library. Selected models for the following tasks are currently supported: * Document layout analysis including table recognition in Tensorflow with **Tensorpack**, or PyTorch with **Detectron2**, * OCR with support of **Tesseract**, **DocTr** (Tensorflow and PyTorch implementations available) and a wrapper to an API for a commercial solution, * Text mining for native PDFs with **pdfplumber**, * Language detection with **fastText**, * Deskewing and rotating images with **jdeskew**. * Document and token classification with all LayoutLM models provided by the **Transformer library**. (Yes, you can use any LayoutLM-model with any of the provided OCR-or pdfplumber tools straight away!). * Table detection and table structure recognition with **table-transformer**. * There is a small dataset for token classification available and a lot of new tutorials to show, how to train and evaluate this dataset using LayoutLMv1, LayoutLMv2, LayoutXLM and LayoutLMv3. * Comprehensive configuration of **analyzer** like choosing different models, output parsing, OCR selection. Check this notebook or the docs for more infos. * Document layout analysis and table recognition now runs with **Torchscript** (CPU) as well and **Detectron2** is not required anymore for basic inference. * [**new**] More angle predictors for determining the rotation of a document based on **Tesseract** and **DocTr** (not contained in the built-in Analyzer). * [**new**] Token classification with **LiLT** via **transformers**. We have added a model wrapper for token classification with LiLT and added a some LiLT models to the model catalog that seem to look promising, especially if you want to train a model on non-english data. The training script for LayoutLM can be used for LiLT as well and we will be providing a notebook on how to train a model on a custom dataset soon. **deep** doctection provides on top of that methods for pre-processing inputs to models like cropping or resizing and to post-process results, like validating duplicate outputs, relating words to detected layout segments or ordering words into contiguous text. You will get an output in JSON format that you can customize even further by yourself. Have a look at the **introduction notebook** in the notebook repo for an easy start. Check the **release notes** for recent updates. **deep** doctection or its support libraries provide pre-trained models that are in most of the cases available at the **Hugging Face Model Hub** or that will be automatically downloaded once requested. For instance, you can find pre-trained object detection models from the Tensorpack or Detectron2 framework for coarse layout analysis, table cell detection and table recognition. Training is a substantial part to get pipelines ready on some specific domain, let it be document layout analysis, document classification or NER. **deep** doctection provides training scripts for models that are based on trainers developed from the library that hosts the model code. Moreover, **deep** doctection hosts code to some well established datasets like **Publaynet** that makes it easy to experiment. It also contains mappings from widely used data formats like COCO and it has a dataset framework (akin to **datasets** so that setting up training on a custom dataset becomes very easy. **This notebook** shows you how to do this. **deep** doctection comes equipped with a framework that allows you to evaluate predictions of a single or multiple models in a pipeline against some ground truth. Check again **here** how it is done. Having set up a pipeline it takes you a few lines of code to instantiate the pipeline and after a for loop all pages will be processed through the pipeline.
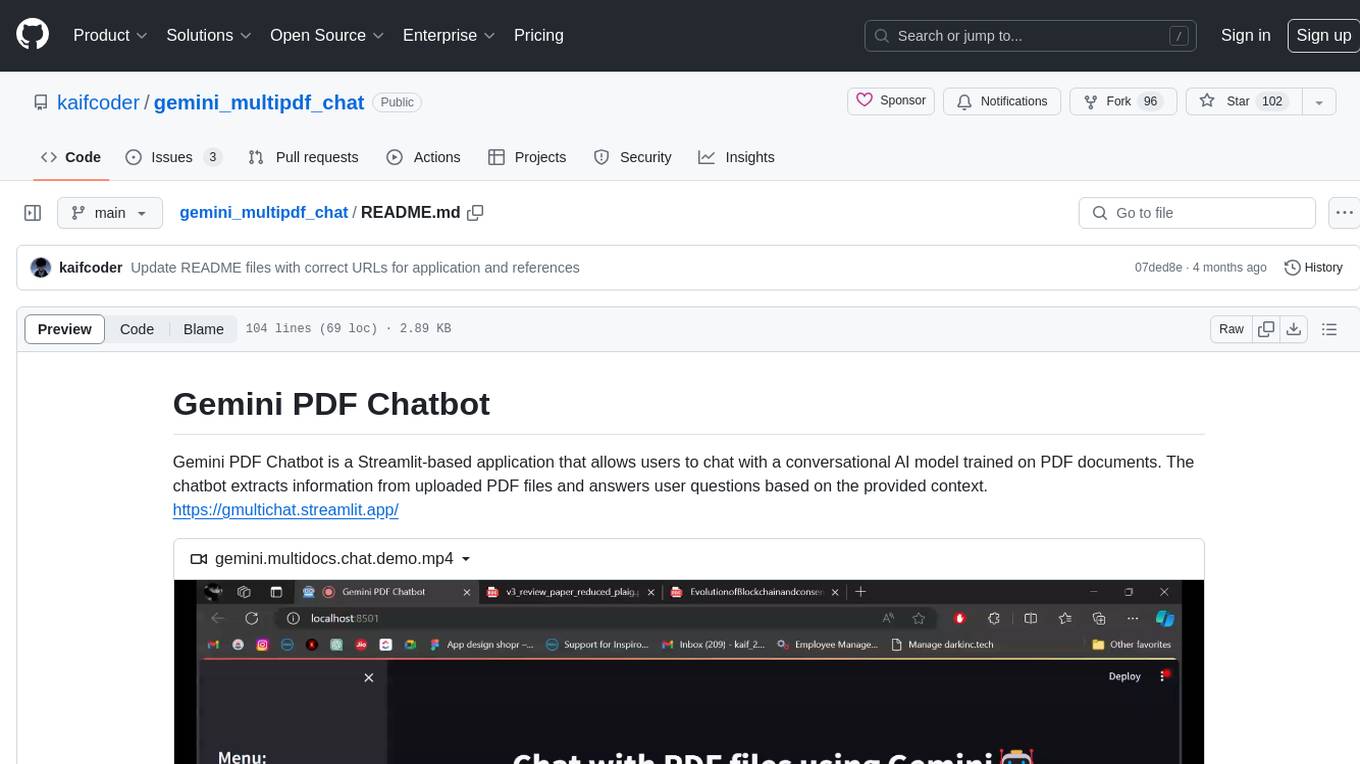
gemini_multipdf_chat
Gemini PDF Chatbot is a Streamlit-based application that allows users to chat with a conversational AI model trained on PDF documents. The chatbot extracts information from uploaded PDF files and answers user questions based on the provided context. It features PDF upload, text extraction, conversational AI using the Gemini model, and a chat interface. Users can deploy the application locally or to the cloud, and the project structure includes main application script, environment variable file, requirements, and documentation. Dependencies include PyPDF2, langchain, Streamlit, google.generativeai, and dotenv.

dify
Dify is an open-source LLM app development platform that combines AI workflow, RAG pipeline, agent capabilities, model management, observability features, and more. It allows users to quickly go from prototype to production. Key features include: 1. Workflow: Build and test powerful AI workflows on a visual canvas. 2. Comprehensive model support: Seamless integration with hundreds of proprietary / open-source LLMs from dozens of inference providers and self-hosted solutions. 3. Prompt IDE: Intuitive interface for crafting prompts, comparing model performance, and adding additional features. 4. RAG Pipeline: Extensive RAG capabilities that cover everything from document ingestion to retrieval. 5. Agent capabilities: Define agents based on LLM Function Calling or ReAct, and add pre-built or custom tools. 6. LLMOps: Monitor and analyze application logs and performance over time. 7. Backend-as-a-Service: All of Dify's offerings come with corresponding APIs for easy integration into your own business logic.
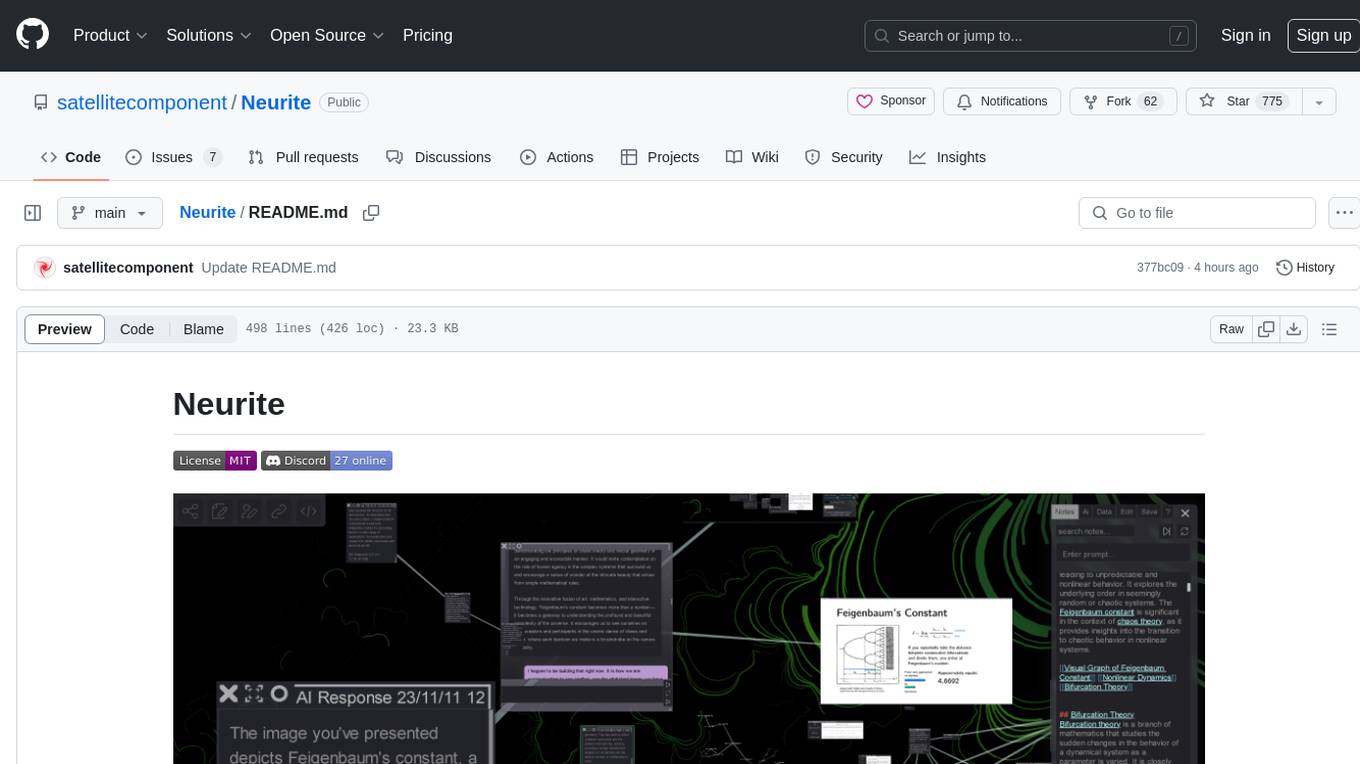
Neurite
Neurite is an innovative project that combines chaos theory and graph theory to create a digital interface that explores hidden patterns and connections for creative thinking. It offers a unique workspace blending fractals with mind mapping techniques, allowing users to navigate the Mandelbrot set in real-time. Nodes in Neurite represent various content types like text, images, videos, code, and AI agents, enabling users to create personalized microcosms of thoughts and inspirations. The tool supports synchronized knowledge management through bi-directional synchronization between mind-mapping and text-based hyperlinking. Neurite also features FractalGPT for modular conversation with AI, local AI capabilities for multi-agent chat networks, and a Neural API for executing code and sequencing animations. The project is actively developed with plans for deeper fractal zoom, advanced control over node placement, and experimental features.
20 - OpenAI Gpts

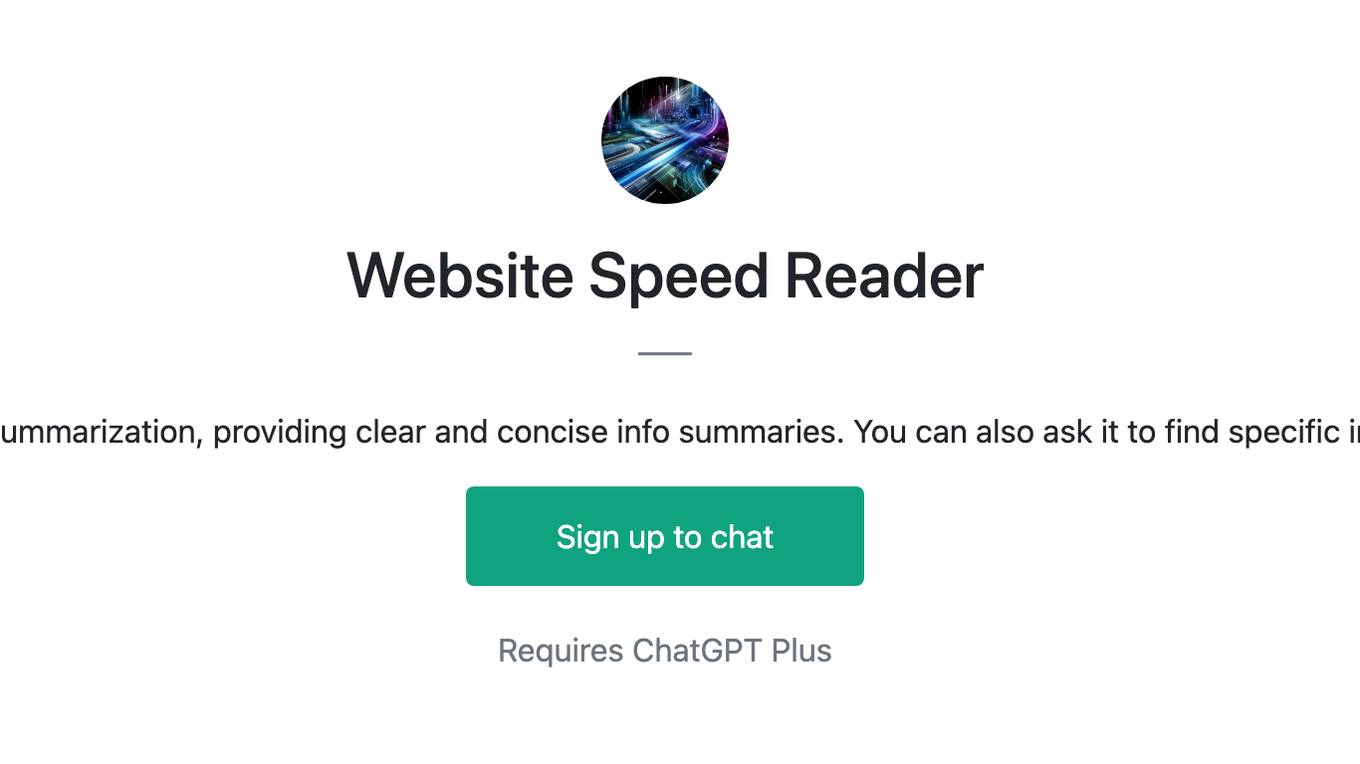
Website Speed Reader
Expert in website summarization, providing clear and concise info summaries. You can also ask it to find specific info from the site.

Procedure Extraction and Formatting
Extracts and formats procedures from manuals into templates
The Librarian
A digital librarian who identifies books from photos and provides detailed information.
Create a Business 1-Pager Snippet v2
1) Input a URL, attachment, or copy/paste a bunch of info about your biz. 2) I will return a summary of what's important. 3) Use what I give you for other prompts, e.g.: marketing strategy, content ideas, competitive analysis, etc
Data Extractor Pro
Expert in data extraction and context-driven analysis. Can read most filetypes including PDFS, XLSX, Word, TXT, CSV, EML, Etc.


WIN With Lex Fridman
Explore Lex Fridman's podcast universe with Lex Fridman GPT—extracting wisdom from deep conversations with brilliant minds on technology, humanity, and philosophy.
艺术盲盒-概念对撞机|Art Concept Collider
这只是一个哲学和思想概念的游戏性质的探索工具:将任意输入的词汇、概念或场景进行深度分析,从多个学术领域提炼与之相关的哲学术语。This is just a game like exploration tool for philosophical and intellectual concepts: conducting in-depth analysis of vocabulary, extracting philosophical terms related to it from multiple academic fields.联系vx:[email protected]
