Best AI tools for< Extract Form Data >
20 - AI tool Sites
Peslac AI
Peslac AI is an intelligent document processing solution that leverages advanced AI technology to transform complex documents into structured data, streamline document-heavy workflows, and automate data extraction and form processing. It offers insights through document analysis, workflow automation, and tailored solutions for various industries such as insurance, finance, healthcare, legal, and more. Peslac aims to enhance operational efficiency, accuracy, and speed by automating document-heavy processes and providing seamless integration with existing systems.
DocuBridge
DocuBridge is a financial data automation software product designed to accelerate audit and financial tasks with its AI Excel Add-In, offering 10x faster data entry and structuring for maximum efficiency. It is built for finance and audit professionals to streamline Excel workflows and bridge documents for more efficient data workflows from entry to analysis. The platform also offers versatile integrations, data privacy, and SOC-2 compliance to ensure complete data protection.
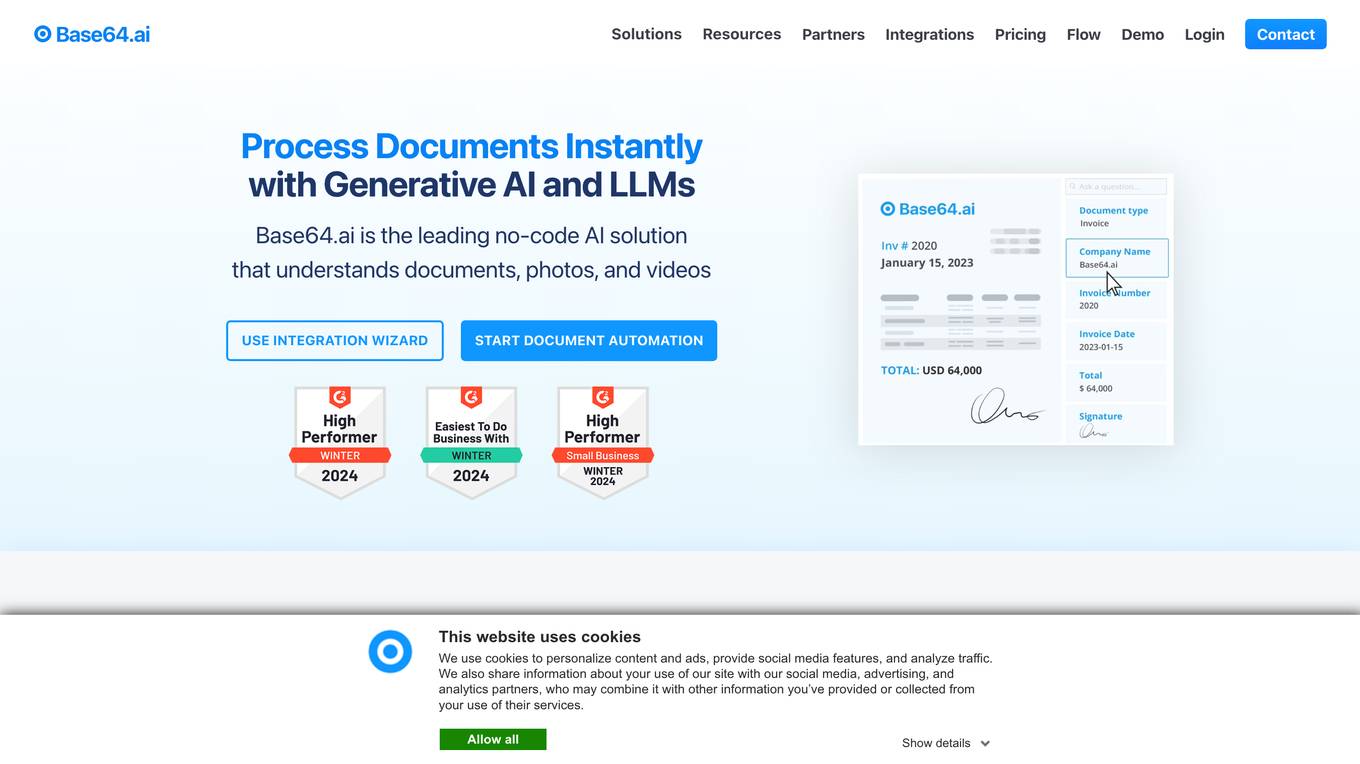
Base64.ai
Base64.ai is an AI-powered document intelligence company that offers a comprehensive solution to bring AI into document-based workflows. The platform enables users to power complex document processing, workflow automation, AI agents, and data intelligence. With features like multi-modal AI data ingestion, pre-trained deep learning models, AI agents for business decisions, and integrations with various systems, Base64.ai aims to enhance efficiency, accuracy, and digital transformation for organizations.
FillBot
FillBot is an AI-powered form filling and autofill extension designed to streamline workflows and save time by automating tedious data entry tasks. It enhances productivity, ensures data accuracy, and provides bank-level data security. FillBot simplifies tasks with advanced AI technology, smart data extraction, and seamless integration with Chrome. Trusted by professionals worldwide, FillBot is endorsed for its top-tier security, worldwide network support, award-winning innovation, and high customer satisfaction.
PYQ
PYQ is an AI-powered platform that helps businesses automate document-related tasks, such as data extraction, form filling, and system integration. It uses natural language processing (NLP) and machine learning (ML) to understand the content of documents and perform tasks accordingly. PYQ's platform is designed to be easy to use, with pre-built automations for common use cases. It also offers custom automation development services for more complex needs.
Bytebot
Bytebot is a web automation tool that uses AI to make it easy to create and manage web tasks. With Bytebot, you can create browser automations as intuitively as writing a simple prompt. Bytebot will take care of the code for you, so you can focus on the task at hand. Bytebot is perfect for a variety of tasks, including data extraction, form filling, and website monitoring.
Feathery
Feathery is an AI-powered platform that enables users to create powerful forms and workflows without the need for coding. It offers advanced features such as AI data extraction, document intelligence, signatures, and collaboration tools. Feathery caters to various industries like insurance, healthcare, financial services, software, and education, providing solutions to streamline processes and enhance user experiences. The platform is designed to automate form workflows, extract and fill documents, and connect with different systems, making it a versatile tool for data management and workflow optimization.
UpSum
UpSum is a text summarization tool that uses advanced AI technology to condense lengthy texts into concise summaries. It is designed to save users time and effort by extracting the key points and insights from documents, research papers, news articles, and other written content. UpSum's AI algorithm analyzes the text, identifies the most important sentences and phrases, and assembles them into a coherent summary that accurately represents the main ideas and key takeaways of the original text. The tool is easy to use, simply upload or paste your text, select the desired summary length, and click the summarize button. UpSum is available as a free web-based tool, as well as a premium subscription with additional features and capabilities.

Munch
Munch is an AI-powered video repurposing platform that helps businesses and individuals extract the most engaging and impactful clips from their long-form videos. With its advanced machine learning capabilities, Munch analyzes video content to identify key moments, generate captions, and create social media posts. It supports multiple languages and provides insights into marketing trends to help users optimize their content for different platforms.
Swiftask
Swiftask is an all-in-one AI Assistant designed to enhance individual and team productivity and creativity. It integrates a range of AI technologies, chatbots, and productivity tools into a cohesive chat interface. Swiftask offers features such as generating text, language translation, creative content writing, answering questions, extracting text from images and PDFs, table and form extraction, audio transcription, speech-to-text conversion, AI-based image generation, and project management capabilities. Users can benefit from Swiftask's comprehensive AI solutions to work smarter and achieve more.
Pictory
Pictory is an easy-to-use video creation platform that uses artificial intelligence (AI) to help you create engaging videos in minutes. With Pictory, you can create videos from scratch or transform existing content into videos, such as blog posts, scripts, and long-form videos. Pictory also offers a variety of features to help you customize your videos, such as AI-generated voiceovers, music, and captions. Whether you're a content marketer, business professional, or educator, Pictory can help you create videos that will engage your audience and help you achieve your goals.
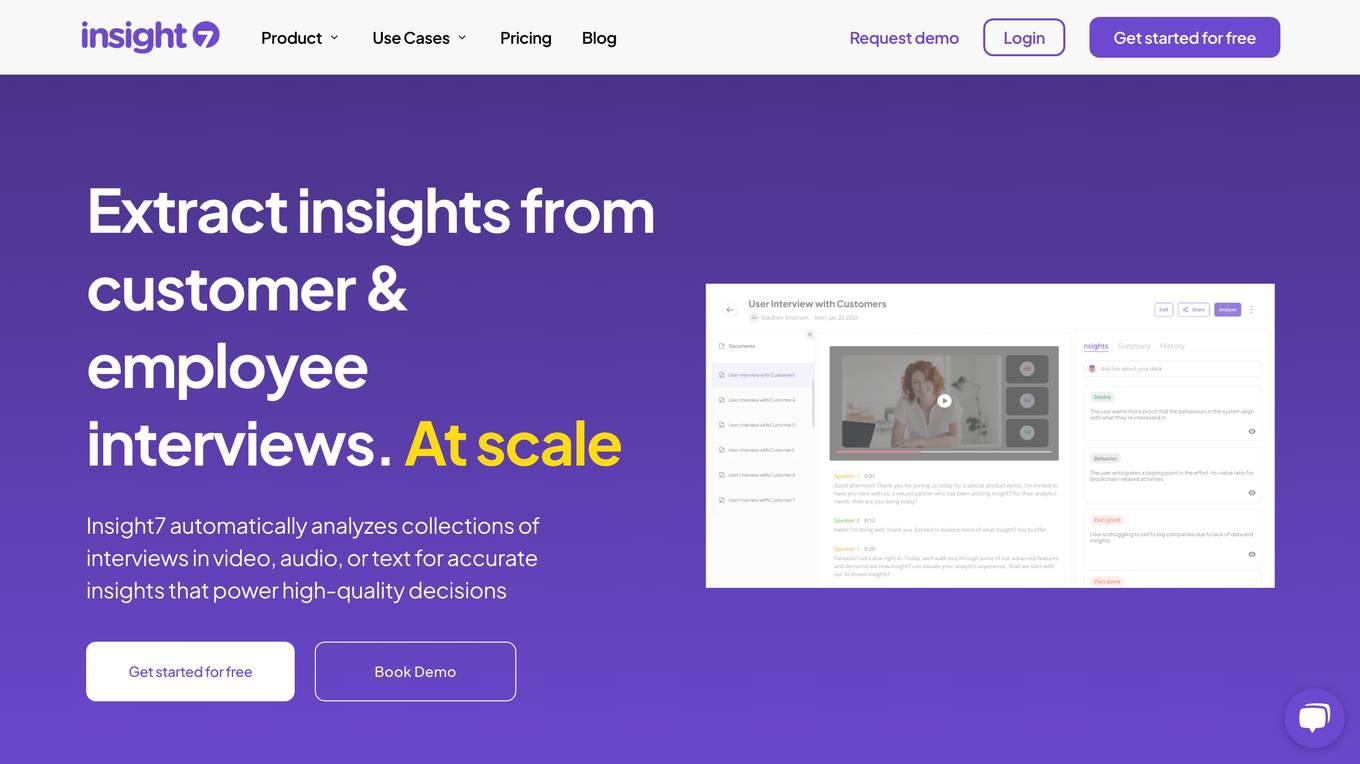
Insight7
Insight7 is a powerful AI-powered tool that helps businesses extract insights from customer and employee interviews. It uses natural language processing and machine learning to analyze large volumes of unstructured data, such as transcripts, audio recordings, and videos. Insight7 can identify key themes, trends, and sentiment, which can then be used to improve products, services, and customer experiences.
FormX.ai
FormX.ai is an AI-powered data extraction and conversion tool that automates the process of extracting data from physical documents and converting it into digital formats. It supports a wide range of document types, including invoices, receipts, purchase orders, bank statements, contracts, HR forms, shipping orders, loyalty member applications, annual reports, business certificates, personnel licenses, and more. FormX.ai's pre-configured data extraction models and effortless API integration make it easy for businesses to integrate data extraction into their existing systems and workflows. With FormX.ai, businesses can save time and money on manual data entry and improve the accuracy and efficiency of their data processing.
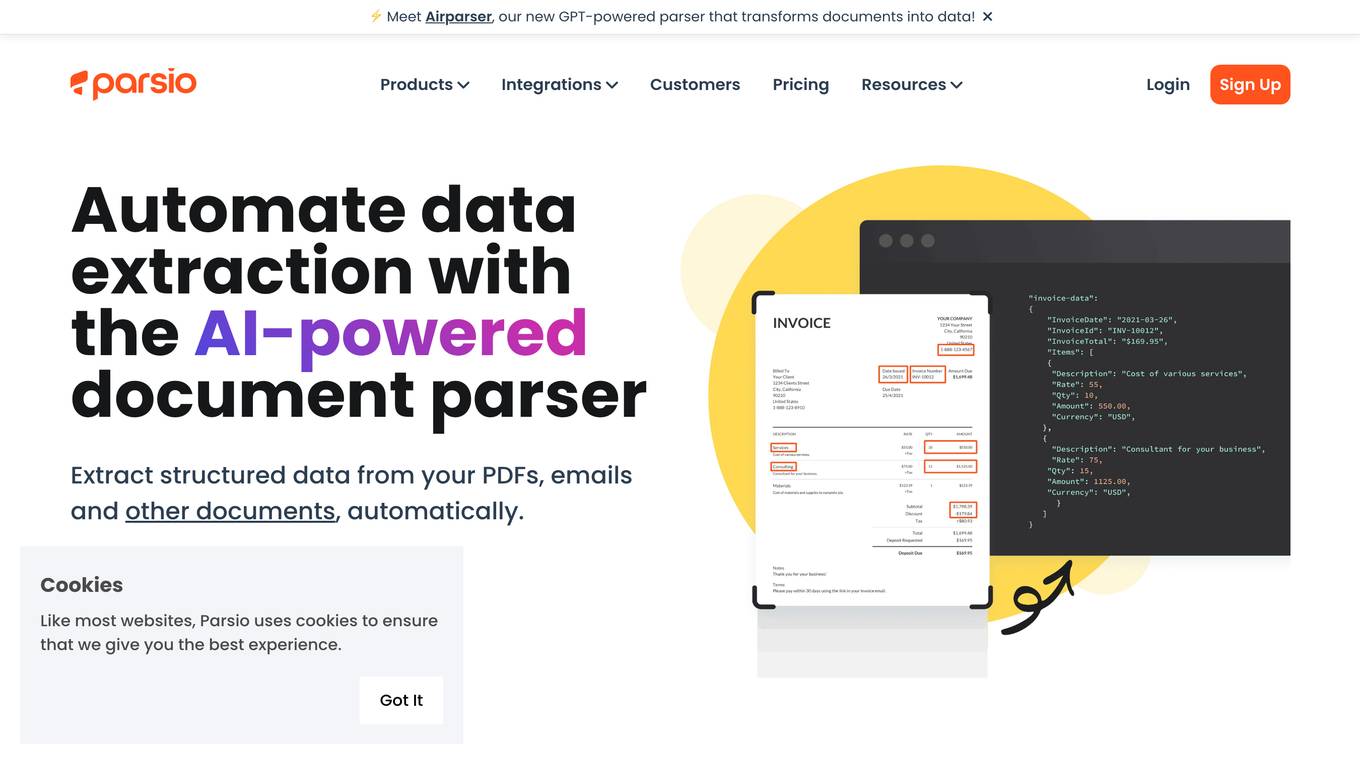
Parsio
Parsio is an AI-powered document parser that can extract structured data from PDFs, emails, and other documents. It uses natural language processing to understand the context of the document and identify the relevant data points. Parsio can be used to automate a variety of tasks, such as extracting data from invoices, receipts, and emails.
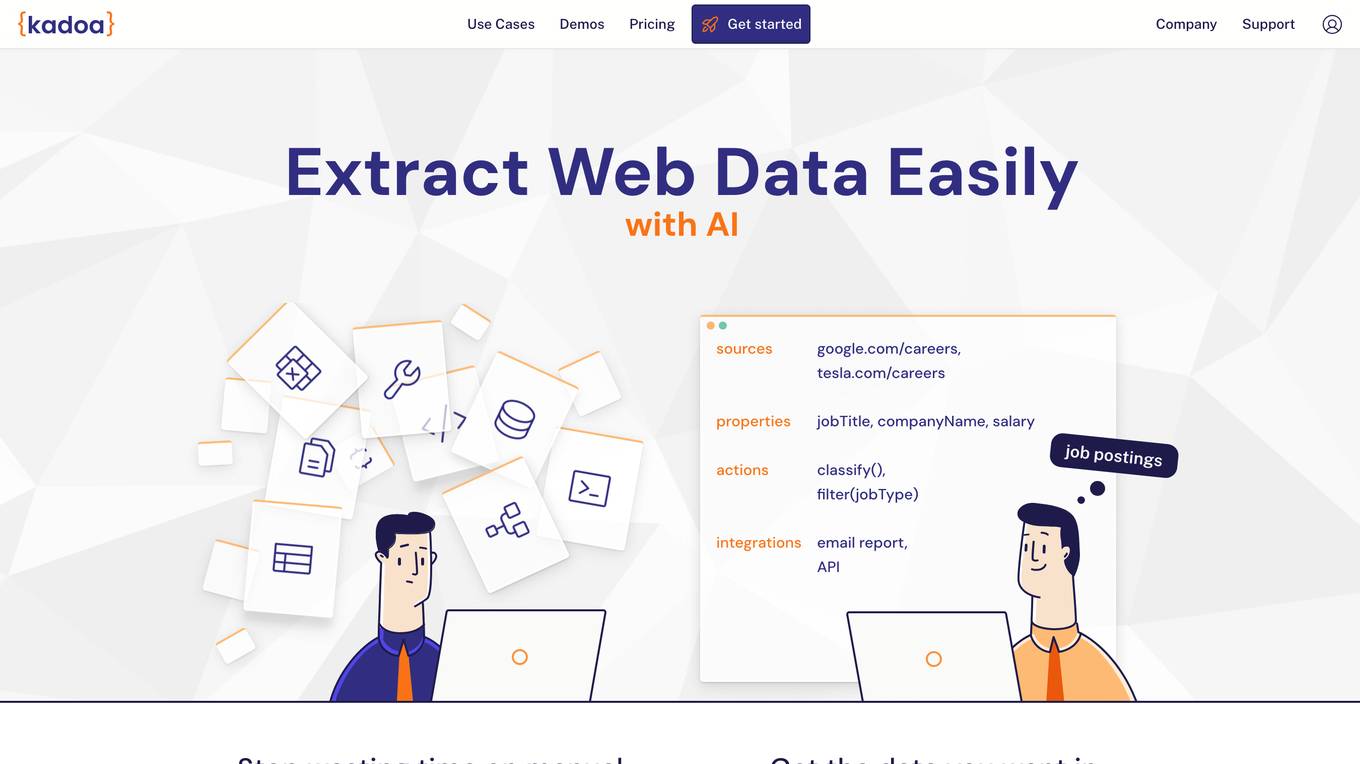
Kadoa
Kadoa is an AI web scraper tool that extracts unstructured web data at scale automatically, without the need for coding. It offers a fast and easy way to integrate web data into applications, providing high accuracy, scalability, and automation in data extraction and transformation. Kadoa is trusted by various industries for real-time monitoring, lead generation, media monitoring, and more, offering zero setup or maintenance effort and smart navigation capabilities.

RIDO Protocol
RIDO Protocol is a decentralized data protocol that allows users to extract value from their personal data in Web2 and Web3. It provides users with a variety of features, including programmable data generation, programmable access control, and cross-application data sharing. RIDO also has a data marketplace where users can list or offer their data information and ownership. Additionally, RIDO has a DataFi protocol which promotes the flowing of data information and value.
Tablize
Tablize is a powerful data extraction tool that helps you turn unstructured data into structured, tabular format. With Tablize, you can easily extract data from PDFs, images, and websites, and export it to Excel, CSV, or JSON. Tablize uses artificial intelligence to automate the data extraction process, making it fast and easy to get the data you need.
Podwise
Podwise is an AI-powered podcast tool designed for podcast lovers to extract structured knowledge from episodes at 10x speed. It offers features such as AI-powered summarization, mind mapping, content outlining, transcription, and seamless integration with knowledge management workflows. Users can subscribe to favorite content, get lightning-speed access to structured knowledge, and discover episodes of interest. Podwise aims to address the challenge of enjoying podcasts, recalling less, and forgetting quickly, by providing a meticulous, accurate, and impactful tool for efficient podcast referencing and note consolidation.
Nex
Nex is an AI Knowledge Copilot application designed to help users efficiently extract main points from long YouTube videos and articles. It offers features like summarizing content, providing quick takeaways, highlighting essential parts, and saving inspirations. With Nex, users can improve their information absorption and save time by focusing on the most relevant parts of the content.
Browse AI
Browse AI is an AI-powered data extraction platform that allows users to scrape and monitor data from any website without the need for coding. It offers managed services for stress-free data extraction, turning any website into an API within minutes. Users can monitor websites for changes and access a complete suite of features for data extraction. Browse AI caters to various industries such as E-Commerce, Real Estate, Recruitment, and Investors & VCs, providing valuable insights and data-driven decisions. The platform ensures best-in-class data reliability through automated site layout monitoring, human behavior emulation, and location-based data extraction.
20 - Open Source AI Tools
langchain-extract
LangChain Extract is a simple web server that allows you to extract information from text and files using LLMs. It is built using FastAPI, LangChain, and Postgresql. The backend closely follows the extraction use-case documentation and provides a reference implementation of an app that helps to do extraction over data using LLMs. This repository is meant to be a starting point for building your own extraction application which may have slightly different requirements or use cases.
text-extract-api
The text-extract-api is a powerful tool that allows users to convert images, PDFs, or Office documents to Markdown text or JSON structured documents with high accuracy. It is built using FastAPI and utilizes Celery for asynchronous task processing, with Redis for caching OCR results. The tool provides features such as PDF/Office to Markdown and JSON conversion, improving OCR results with LLama, removing Personally Identifiable Information from documents, distributed queue processing, caching using Redis, switchable storage strategies, and a CLI tool for task management. Users can run the tool locally or on cloud services, with support for GPU processing. The tool also offers an online demo for testing purposes.

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.
data-prep-kit
Data Prep Kit is a community project aimed at democratizing and speeding up unstructured data preparation for LLM app developers. It provides high-level APIs and modules for transforming data (code, language, speech, visual) to optimize LLM performance across different use cases. The toolkit supports Python, Ray, Spark, and Kubeflow Pipelines runtimes, offering scalability from laptop to datacenter-scale processing. Developers can contribute new custom modules and leverage the data processing library for building data pipelines. Automation features include workflow automation with Kubeflow Pipelines for transform execution.

sparrow
Sparrow is an innovative open-source solution for efficient data extraction and processing from various documents and images. It seamlessly handles forms, invoices, receipts, and other unstructured data sources. Sparrow stands out with its modular architecture, offering independent services and pipelines all optimized for robust performance. One of the critical functionalities of Sparrow - pluggable architecture. You can easily integrate and run data extraction pipelines using tools and frameworks like LlamaIndex, Haystack, or Unstructured. Sparrow enables local LLM data extraction pipelines through Ollama or Apple MLX. With Sparrow solution you get API, which helps to process and transform your data into structured output, ready to be integrated with custom workflows. Sparrow Agents - with Sparrow you can build independent LLM agents, and use API to invoke them from your system. **List of available agents:** * **llamaindex** - RAG pipeline with LlamaIndex for PDF processing * **vllamaindex** - RAG pipeline with LLamaIndex multimodal for image processing * **vprocessor** - RAG pipeline with OCR and LlamaIndex for image processing * **haystack** - RAG pipeline with Haystack for PDF processing * **fcall** - Function call pipeline * **unstructured-light** - RAG pipeline with Unstructured and LangChain, supports PDF and image processing * **unstructured** - RAG pipeline with Weaviate vector DB query, Unstructured and LangChain, supports PDF and image processing * **instructor** - RAG pipeline with Unstructured and Instructor libraries, supports PDF and image processing. Works great for JSON response generation

free-for-life
A massive list including a huge amount of products and services that are completely free! ⭐ Star on GitHub • 🤝 Contribute # Table of Contents * APIs, Data & ML * Artificial Intelligence * BaaS * Code Editors * Code Generation * DNS * Databases * Design & UI * Domains * Email * Font * For Students * Forms * Linux Distributions * Messaging & Streaming * PaaS * Payments & Billing * SSL

aiid
The Artificial Intelligence Incident Database (AIID) is a collection of incidents involving the development and use of artificial intelligence (AI). The database is designed to help researchers, policymakers, and the public understand the potential risks and benefits of AI, and to inform the development of policies and practices to mitigate the risks and promote the benefits of AI. The AIID is a collaborative project involving researchers from the University of California, Berkeley, the University of Washington, and the University of Toronto.

HuggingFists
HuggingFists is a low-code data flow tool that enables convenient use of LLM and HuggingFace models. It provides functionalities similar to Langchain, allowing users to design, debug, and manage data processing workflows, create and schedule workflow jobs, manage resources environment, and handle various data artifact resources. The tool also offers account management for users, allowing centralized management of data source accounts and API accounts. Users can access Hugging Face models through the Inference API or locally deployed models, as well as datasets on Hugging Face. HuggingFists supports breakpoint debugging, branch selection, function calls, workflow variables, and more to assist users in developing complex data processing workflows.

langserve
LangServe helps developers deploy `LangChain` runnables and chains as a REST API. This library is integrated with FastAPI and uses pydantic for data validation. In addition, it provides a client that can be used to call into runnables deployed on a server. A JavaScript client is available in LangChain.js.

clickolas-cage
Clickolas-cage is a Chrome extension designed to autonomously perform web browsing actions to achieve specific goals using LLM as a brain. Users can interact with the extension by setting goals, which triggers a series of actions including navigation, element extraction, and step generation. The extension is developed using Node.js and can be locally run for testing and development purposes before packing it for submission to the Chrome Web Store.

skyvern
Skyvern automates browser-based workflows using LLMs and computer vision. It provides a simple API endpoint to fully automate manual workflows, replacing brittle or unreliable automation solutions. Traditional approaches to browser automations required writing custom scripts for websites, often relying on DOM parsing and XPath-based interactions which would break whenever the website layouts changed. Instead of only relying on code-defined XPath interactions, Skyvern adds computer vision and LLMs to the mix to parse items in the viewport in real-time, create a plan for interaction and interact with them. This approach gives us a few advantages: 1. Skyvern can operate on websites it’s never seen before, as it’s able to map visual elements to actions necessary to complete a workflow, without any customized code 2. Skyvern is resistant to website layout changes, as there are no pre-determined XPaths or other selectors our system is looking for while trying to navigate 3. Skyvern leverages LLMs to reason through interactions to ensure we can cover complex situations. Examples include: 1. If you wanted to get an auto insurance quote from Geico, the answer to a common question “Were you eligible to drive at 18?” could be inferred from the driver receiving their license at age 16 2. If you were doing competitor analysis, it’s understanding that an Arnold Palmer 22 oz can at 7/11 is almost definitely the same product as a 23 oz can at Gopuff (even though the sizes are slightly different, which could be a rounding error!) Want to see examples of Skyvern in action? Jump to #real-world-examples-of- skyvern
ExtractThinker
ExtractThinker is a library designed for extracting data from files and documents using Language Model Models (LLMs). It offers ORM-style interaction between files and LLMs, supporting multiple document loaders such as Tesseract OCR, Azure Form Recognizer, AWS TextExtract, and Google Document AI. Users can customize extraction using contract definitions, process documents asynchronously, handle various document formats efficiently, and split and process documents. The project is inspired by the LangChain ecosystem and focuses on Intelligent Document Processing (IDP) using LLMs to achieve high accuracy in document extraction tasks.

towhee
Towhee is a cutting-edge framework designed to streamline the processing of unstructured data through the use of Large Language Model (LLM) based pipeline orchestration. It can extract insights from diverse data types like text, images, audio, and video files using generative AI and deep learning models. Towhee offers rich operators, prebuilt ETL pipelines, and a high-performance backend for efficient data processing. With a Pythonic API, users can build custom data processing pipelines easily. Towhee is suitable for tasks like sentence embedding, image embedding, video deduplication, question answering with documents, and cross-modal retrieval based on CLIP.

lector
Lector is a text analysis tool that helps users extract insights from unstructured text data. It provides functionalities such as sentiment analysis, keyword extraction, entity recognition, and text summarization. With Lector, users can easily analyze large volumes of text data to uncover patterns, trends, and valuable information. The tool is designed to be user-friendly and efficient, making it suitable for both beginners and experienced users in the field of natural language processing and text mining.

lotus
LOTUS (LLMs Over Tables of Unstructured and Structured Data) is a query engine that provides a declarative programming model and an optimized query engine for reasoning-based query pipelines over structured and unstructured data. It offers a simple and intuitive Pandas-like API with semantic operators for fast and easy LLM-powered data processing. The tool implements a semantic operator programming model, allowing users to write AI-based pipelines with high-level logic and leaving the rest of the work to the query engine. LOTUS supports various semantic operators like sem_map, sem_filter, sem_extract, sem_agg, sem_topk, sem_join, sem_sim_join, and sem_search, enabling users to perform tasks like mapping records, filtering data, aggregating records, and more. The tool also supports different model classes such as LM, RM, and Reranker for language modeling, retrieval, and reranking tasks respectively.

baml
BAML is a config file format for declaring LLM functions that you can then use in TypeScript or Python. With BAML you can Classify or Extract any structured data using Anthropic, OpenAI or local models (using Ollama) ## Resources  [Discord Community](https://discord.gg/boundaryml)  [Follow us on Twitter](https://twitter.com/boundaryml) * Discord Office Hours - Come ask us anything! We hold office hours most days (9am - 12pm PST). * Documentation - Learn BAML * Documentation - BAML Syntax Reference * Documentation - Prompt engineering tips * Boundary Studio - Observability and more #### Starter projects * BAML + NextJS 14 * BAML + FastAPI + Streaming ## Motivation Calling LLMs in your code is frustrating: * your code uses types everywhere: classes, enums, and arrays * but LLMs speak English, not types BAML makes calling LLMs easy by taking a type-first approach that lives fully in your codebase: 1. Define what your LLM output type is in a .baml file, with rich syntax to describe any field (even enum values) 2. Declare your prompt in the .baml config using those types 3. Add additional LLM config like retries or redundancy 4. Transpile the .baml files to a callable Python or TS function with a type-safe interface. (VSCode extension does this for you automatically). We were inspired by similar patterns for type safety: protobuf and OpenAPI for RPCs, Prisma and SQLAlchemy for databases. BAML guarantees type safety for LLMs and comes with tools to give you a great developer experience:  Jump to BAML code or how Flexible Parsing works without additional LLM calls. | BAML Tooling | Capabilities | | ----------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | | BAML Compiler install | Transpiles BAML code to a native Python / Typescript library (you only need it for development, never for releases) Works on Mac, Windows, Linux  | | VSCode Extension install | Syntax highlighting for BAML files Real-time prompt preview Testing UI | | Boundary Studio open (not open source) | Type-safe observability Labeling |

data-juicer
Data-Juicer is a one-stop data processing system to make data higher-quality, juicier, and more digestible for LLMs. It is a systematic & reusable library of 80+ core OPs, 20+ reusable config recipes, and 20+ feature-rich dedicated toolkits, designed to function independently of specific LLM datasets and processing pipelines. Data-Juicer allows detailed data analyses with an automated report generation feature for a deeper understanding of your dataset. Coupled with multi-dimension automatic evaluation capabilities, it supports a timely feedback loop at multiple stages in the LLM development process. Data-Juicer offers tens of pre-built data processing recipes for pre-training, fine-tuning, en, zh, and more scenarios. It provides a speedy data processing pipeline requiring less memory and CPU usage, optimized for maximum productivity. Data-Juicer is flexible & extensible, accommodating most types of data formats and allowing flexible combinations of OPs. It is designed for simplicity, with comprehensive documentation, easy start guides and demo configs, and intuitive configuration with simple adding/removing OPs from existing configs.
20 - OpenAI Gpts

Fill PDF Forms
Fill legal forms & complex PDF documents easily! Upload a file, provide data sources and I'll handle the rest.
PDF Ninja
I extract data and tables from PDFs to CSV, focusing on data privacy and precision.
Visual Storyteller
Extract the essence of the novel story according to the quantity requirements and generate corresponding images. The images can be used directly to create novel videos.小说推文图片自动批量生成,可自动生成风格一致性图片
Receipt CSV Formatter
Extract from receipts to CSV: Date of Purchase, Item Purchased, Quantity Purchased, Units
PDF AI
PDFChat : Analyse 1000's of PDF's in seconds, extract and chat with PDFs in any language.
Watch Identification, Pricing, Sales Research Tool
Analyze watch images, extract text, and craft sales descriptions. Add 1 or more images for a single watch to get started.
The Enigmancer
Put your prompt engineering skills to the ultimate test! Embark on a journey to outwit a mythical guardian of ancient secrets. Try to extract the secret passphrase hidden in the system prompt and enter it in chat when you think you have it and claim your glory. Good luck!

Dissertation & Thesis GPT
An Ivy Leage Scholar GPT equipped to understand your research needs, formulate comprehensive literature review strategies, and extract pertinent information from a plethora of academic databases and journals. I'll then compose a peer review-quality paper with citations.


ExtractWisdom
Takes in any text and extracts the wisdom from it like you spent 3 hours taking handwritten notes.

QCM
ce GPT va recevoir des images dans lesquelles il y a des questions QCM codingame ou Problem Solving sur les sujets : Java, Hibernate, Angular, Spring Boot, SQL. Il doit extraire le texte depuis l'image et répondre au question QCM le plus rapidement possible.
Ringkesan
Nyimpulkeun sareng nimba poin konci tina téks, artikel, video, dokumén sareng seueur deui