Best AI tools for< document classification >
20 - AI tool Sites
Ocrolus
Ocrolus is an AI-driven document processing automation software that helps lenders manage risk and avoid fraud. It uses machine learning, computer vision, and human validation to classify, capture, detect, and analyze financial documents. Ocrolus can be used to evaluate cash flow, calculate income, extract address information, retrieve employment data, and establish identity. It is a powerful tool that can help lenders make faster and more accurate financial decisions.
Kensho Solutions
Kensho Solutions is an AI tool that illuminates insights in the world's data by providing AI solutions for audio transcription, entity identification, document classification, data extraction, and company data mapping. Their AI solutions unlock insights, enabling users to make data-driven decisions with conviction. In partnership with S&P Global, Kensho Solutions has access to vast amounts of data, which they use to train and develop machine learning algorithms to address the business world's most pressing challenges.
Lexalytics
Lexalytics is a leading provider of text analytics and natural language processing (NLP) solutions. Our platform and services help businesses transform complex text data into valuable insights and actionable intelligence. With Lexalytics, you can: * **Analyze customer feedback** to understand what your customers are saying about your products, services, and brand. * **Identify trends and patterns** in text data to make better decisions about your business. * **Automate tasks** such as document classification, entity extraction, and sentiment analysis. * **Develop custom NLP applications** to meet your specific needs.
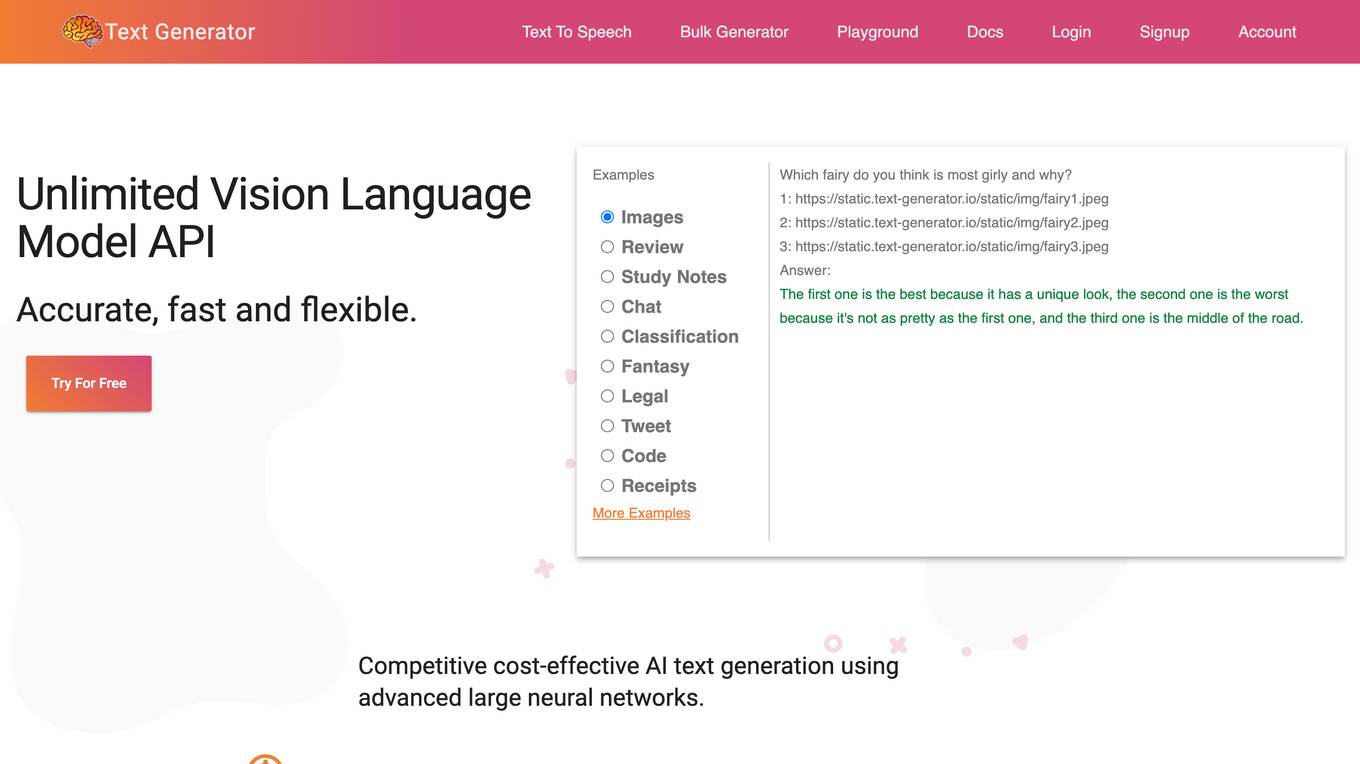
Text Generator
Text Generator is an AI-powered text generation tool that provides users with accurate, fast, and flexible text generation capabilities. With its advanced large neural networks, Text Generator offers a cost-effective solution for various text-related tasks. The tool's intuitive 'prompt engineering' feature allows users to guide text creation by providing keywords and natural questions, making it adaptable for tasks such as classification and sentiment analysis. Text Generator ensures industry-leading security by never storing personal information on its servers. The tool's continuous training ensures that its AI remains up-to-date with the latest events. Additionally, Text Generator offers a range of features including speech-to-text API, text-to-speech API, and code generation, supporting multiple spoken languages and programming languages. With its one-line migration from OpenAI's text generation hub and a shared embedding for multiple spoken languages, images, and code, Text Generator empowers users with powerful search, fingerprinting, tracking, and classification capabilities.
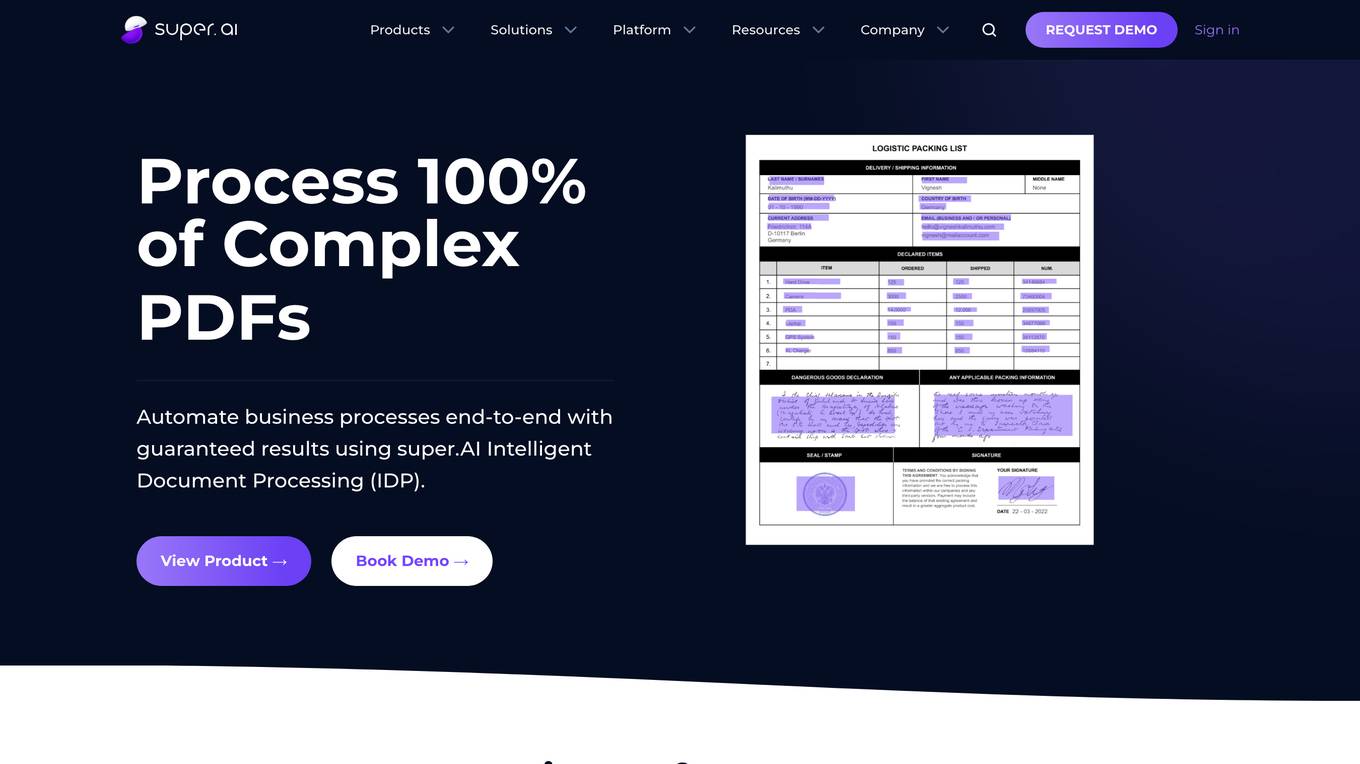
super.AI
Super.AI provides Intelligent Document Processing (IDP) solutions powered by Large Language Models (LLMs) and human-in-the-loop (HITL) capabilities. It automates document processing tasks such as data extraction, classification, and redaction, enabling businesses to streamline their workflows and improve accuracy. Super.AI's platform leverages cutting-edge AI models from providers like Amazon, Google, and OpenAI to handle complex documents, ensuring high-quality outputs. With its focus on accuracy, flexibility, and scalability, Super.AI caters to various industries, including financial services, insurance, logistics, and healthcare.
Convr
Convr is an AI-driven underwriting analysis platform that helps commercial P&C insurance organizations transform their underwriting operations. It provides a modularized AI underwriting and intelligent document automation workbench that enriches and expedites the commercial insurance new business and renewal submission flow with underwriting insights, business classification, and risk scoring. Convr's mission is to solve the last big problem of commercial insurance while improving profitability and increasing efficiency.
Convr
Convr is a modularized AI underwriting and intelligent document automation workbench that enriches and expedites the commercial insurance new business and renewal submission flow with underwriting insights, business classification and risk scoring. As a trusted technology partner and advisor with deep industry expertise, we help insurance organizations transform their underwriting operations through our AI-driven digital underwriting analysis platform.
Vellum AI
Vellum AI is an AI platform that supports using Microsoft Azure hosted OpenAI models. It offers tools for prompt engineering, semantic search, prompt chaining, evaluations, and monitoring. Vellum enables users to build AI systems with features like workflow automation, document analysis, fine-tuning, Q&A over documents, intent classification, summarization, vector search, chatbots, blog generation, sentiment analysis, and more. The platform is backed by top VCs and founders of well-known companies, providing a complete solution for building LLM-powered applications.
CategorAIze.io
CategorAIze.io is an AI-powered tool that helps users categorize data effortlessly using the latest AI technologies. Users can define custom categories, upload data items, and let the cutting-edge LLM AI automatically assign entries based on their content without the need for pretraining. The tool supports multi-level hierarchies, text and image-based categorization, and offers pay-as-you-go pricing options. Additionally, users can access the tool via browser, API, and plugins for a seamless experience.

Roe AI
Roe AI is an unstructured data warehouse that uses AI to process and analyze data from various sources, including documents, images, videos, and audio files. It provides a range of features to help businesses extract insights from their unstructured data, including data standardization, classification and inferencing, similarity search, and natural language processing. Roe AI is designed to be easy to use, even for teams with minimal ML background.
Lettria
Lettria is a no-code AI platform for text that helps users turn unstructured text data into structured knowledge. It combines the best of Large Language Models (LLMs) and symbolic AI to overcome current limitations in knowledge extraction. Lettria offers a suite of APIs for text cleaning, text mining, text classification, and prompt engineering. It also provides a Knowledge Studio for building knowledge graphs and private GPT models. Lettria is trusted by large organizations such as AP-HP and Leroy Merlin to improve their data analysis and decision-making processes.
Airstrip AI
Airstrip AI is a legal document creation tool that uses artificial intelligence (AI) to generate accurate and personalized legal documents for businesses and individuals. It is designed to make the process of creating legal documents easier and more accessible, even for those without legal knowledge. Airstrip AI's AI-powered features include: - Personalized questions to gather necessary information - AI-generated suggestions for potential answers - AI guidance throughout the process to ensure legal compliance - Seamless document skimming and automated revisions - AI-driven Q&A for document clarification - Lawyer-level document revisions Airstrip AI is trusted by hundreds of startups and businesses to create high-quality legal documents at an affordable price. It is compliant with various regulations, including HIPAA, GDPR, and CCPA, and uses AES-256 end-to-end encryption to protect user data.
Hana
Hana is an AI-powered Google Chat Assistant designed to enhance management efficiency by seamlessly integrating into Google Chat. It simplifies day-to-day tasks, boosts team productivity, and expands management capabilities. Hana acts as an intelligent teammate, offering step-by-step guidance, clear explanations, and actionable steps in group chat environments. It assists in tasks like code generation, concept clarification, QnA over web content, memory recall, document analysis, reminders, image intelligence, and more. Hana is a productivity machine that transforms workflows and ensures informed discussions and decisions.
AI Document Creator
AI Document Creator is an innovative tool that leverages artificial intelligence to assist users in generating various types of documents efficiently. The application utilizes advanced algorithms to analyze input data and create well-structured documents tailored to the user's needs. With AI Document Creator, users can save time and effort in document creation, ensuring accuracy and consistency in their outputs. The tool is user-friendly and accessible, making it suitable for individuals and businesses seeking to streamline their document creation process.
Coral AI
Coral AI is an AI-powered platform that helps users search, summarize, translate, and get citations from documents in over 90 languages. Trusted by researchers and professionals, it simplifies tasks such as summarizing documents, asking questions, translating content, and generating study guides. Users can upload documents, ask questions, and receive answers with page citations, making it a valuable tool for various use cases like books, legal documents, research papers, and more. With features like search without keywords, generating study guides, and simplifying document summaries, Coral AI enhances productivity and saves users time.
Affinda
Affinda is a document AI platform that can read, understand, and extract data from any document type. It combines 10+ years of IP in document reconstruction with the latest advancements in computer vision, natural language processing, and deep learning. Affinda's platform can be used to automate a variety of document processing workflows, including invoice processing, receipt processing, credit note processing, purchase order processing, account statement processing, resume parsing, job description parsing, resume redaction, passport processing, birth certificate processing, and driver's license processing. Affinda's platform is used by some of the world's leading organizations, including Google, Microsoft, Amazon, and IBM.
Docugami
Docugami is a document engineering platform that uses artificial intelligence to extract, analyze, and automate data from business documents. It is designed to empower business users with immediate impact, without the need for massive investment in machine learning, staff training, or IT development. Docugami's proprietary Business Document Foundation Model is an LLM for Generative AI that can be applied to any type of business document.
Procys
Procys is an AI-powered document processing tool that offers efficient and automated extraction of data from various types of documents, including invoices, receipts, ID cards, and passports. With a self-learning engine and seamless integration with over 260 apps, Procys simplifies data extraction and organization. The tool prioritizes data security, ensuring a secure environment for all information needs. Users can upload documents in PDF, image, or scanned format, process them using advanced OCR technology, and export the processed information in their preferred format. Procys is trusted by many users for its efficiency and accuracy in document processing.
Honeybear.ai
Honeybear.ai is an AI tool designed to simplify document reading tasks. It utilizes advanced algorithms to extract and analyze text from various documents, making it easier for users to access and comprehend information. With Honeybear.ai, users can streamline their document processing workflows and enhance productivity.
Cradl AI
Cradl AI is an AI-powered tool designed to automate document workflows with no-code AI. It enables users to extract data from any document automatically, integrate with no-code tools, and build custom AI models through an easy-to-use interface. The tool empowers automation teams across industries by extracting data from complex document layouts, regardless of language or structure. Cradl AI offers features such as line item extraction, fine-tuning AI models, human-in-the-loop validation, and seamless integration with automation tools. It is trusted by organizations for business-critical document automation, providing enterprise-level features like encrypted transmission, GDPR compliance, secure data handling, and auto-scaling.
20 - Open Source AI Tools

deepdoctection
**deep** doctection is a Python library that orchestrates document extraction and document layout analysis tasks using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models. For more specific text processing tasks use one of the many other great NLP libraries. **deep** doctection focuses on applications and is made for those who want to solve real world problems related to document extraction from PDFs or scans in various image formats. **deep** doctection provides model wrappers of supported libraries for various tasks to be integrated into pipelines. Its core function does not depend on any specific deep learning library. Selected models for the following tasks are currently supported: * Document layout analysis including table recognition in Tensorflow with **Tensorpack**, or PyTorch with **Detectron2**, * OCR with support of **Tesseract**, **DocTr** (Tensorflow and PyTorch implementations available) and a wrapper to an API for a commercial solution, * Text mining for native PDFs with **pdfplumber**, * Language detection with **fastText**, * Deskewing and rotating images with **jdeskew**. * Document and token classification with all LayoutLM models provided by the **Transformer library**. (Yes, you can use any LayoutLM-model with any of the provided OCR-or pdfplumber tools straight away!). * Table detection and table structure recognition with **table-transformer**. * There is a small dataset for token classification available and a lot of new tutorials to show, how to train and evaluate this dataset using LayoutLMv1, LayoutLMv2, LayoutXLM and LayoutLMv3. * Comprehensive configuration of **analyzer** like choosing different models, output parsing, OCR selection. Check this notebook or the docs for more infos. * Document layout analysis and table recognition now runs with **Torchscript** (CPU) as well and **Detectron2** is not required anymore for basic inference. * [**new**] More angle predictors for determining the rotation of a document based on **Tesseract** and **DocTr** (not contained in the built-in Analyzer). * [**new**] Token classification with **LiLT** via **transformers**. We have added a model wrapper for token classification with LiLT and added a some LiLT models to the model catalog that seem to look promising, especially if you want to train a model on non-english data. The training script for LayoutLM can be used for LiLT as well and we will be providing a notebook on how to train a model on a custom dataset soon. **deep** doctection provides on top of that methods for pre-processing inputs to models like cropping or resizing and to post-process results, like validating duplicate outputs, relating words to detected layout segments or ordering words into contiguous text. You will get an output in JSON format that you can customize even further by yourself. Have a look at the **introduction notebook** in the notebook repo for an easy start. Check the **release notes** for recent updates. **deep** doctection or its support libraries provide pre-trained models that are in most of the cases available at the **Hugging Face Model Hub** or that will be automatically downloaded once requested. For instance, you can find pre-trained object detection models from the Tensorpack or Detectron2 framework for coarse layout analysis, table cell detection and table recognition. Training is a substantial part to get pipelines ready on some specific domain, let it be document layout analysis, document classification or NER. **deep** doctection provides training scripts for models that are based on trainers developed from the library that hosts the model code. Moreover, **deep** doctection hosts code to some well established datasets like **Publaynet** that makes it easy to experiment. It also contains mappings from widely used data formats like COCO and it has a dataset framework (akin to **datasets** so that setting up training on a custom dataset becomes very easy. **This notebook** shows you how to do this. **deep** doctection comes equipped with a framework that allows you to evaluate predictions of a single or multiple models in a pipeline against some ground truth. Check again **here** how it is done. Having set up a pipeline it takes you a few lines of code to instantiate the pipeline and after a for loop all pages will be processed through the pipeline.

awesome-transformer-nlp
This repository contains a hand-curated list of great machine (deep) learning resources for Natural Language Processing (NLP) with a focus on Generative Pre-trained Transformer (GPT), Bidirectional Encoder Representations from Transformers (BERT), attention mechanism, Transformer architectures/networks, Chatbot, and transfer learning in NLP.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.
python-tutorial-notebooks
This repository contains Jupyter-based tutorials for NLP, ML, AI in Python for classes in Computational Linguistics, Natural Language Processing (NLP), Machine Learning (ML), and Artificial Intelligence (AI) at Indiana University.
yn
Yank Note is a highly extensible Markdown editor designed for productivity. It offers features like easy-to-use interface, powerful support for version control and various embedded content, high compatibility with local Markdown files, plug-in extension support, and encryption for saving private files. Users can write their own plug-ins to expand the editor's functionality. However, for more extendability, security protection is sacrificed. The tool supports sync scrolling, outline navigation, version control, encryption, auto-save, editing assistance, image pasting, attachment embedding, code running, to-do list management, quick file opening, integrated terminal, Katex expression, GitHub-style Markdown, multiple data locations, external link conversion, HTML resolving, multiple formats export, TOC generation, table cell editing, title link copying, embedded applets, various graphics embedding, mind map display, custom container support, macro replacement, image hosting service, OpenAI auto completion, and custom plug-ins development.
Awesome-LLM-Long-Context-Modeling
This repository includes papers and blogs about Efficient Transformers, Length Extrapolation, Long Term Memory, Retrieval Augmented Generation(RAG), and Evaluation for Long Context Modeling.

unilm
The 'unilm' repository is a collection of tools, models, and architectures for Foundation Models and General AI, focusing on tasks such as NLP, MT, Speech, Document AI, and Multimodal AI. It includes various pre-trained models, such as UniLM, InfoXLM, DeltaLM, MiniLM, AdaLM, BEiT, LayoutLM, WavLM, VALL-E, and more, designed for tasks like language understanding, generation, translation, vision, speech, and multimodal processing. The repository also features toolkits like s2s-ft for sequence-to-sequence fine-tuning and Aggressive Decoding for efficient sequence-to-sequence decoding. Additionally, it offers applications like TrOCR for OCR, LayoutReader for reading order detection, and XLM-T for multilingual NMT.

unstructured
The `unstructured` library provides open-source components for ingesting and pre-processing images and text documents, such as PDFs, HTML, Word docs, and many more. The use cases of `unstructured` revolve around streamlining and optimizing the data processing workflow for LLMs. `unstructured` modular functions and connectors form a cohesive system that simplifies data ingestion and pre-processing, making it adaptable to different platforms and efficient in transforming unstructured data into structured outputs.

intel-extension-for-transformers
Intel® Extension for Transformers is an innovative toolkit designed to accelerate GenAI/LLM everywhere with the optimal performance of Transformer-based models on various Intel platforms, including Intel Gaudi2, Intel CPU, and Intel GPU. The toolkit provides the below key features and examples: * Seamless user experience of model compressions on Transformer-based models by extending [Hugging Face transformers](https://github.com/huggingface/transformers) APIs and leveraging [Intel® Neural Compressor](https://github.com/intel/neural-compressor) * Advanced software optimizations and unique compression-aware runtime (released with NeurIPS 2022's paper [Fast Distilbert on CPUs](https://arxiv.org/abs/2211.07715) and [QuaLA-MiniLM: a Quantized Length Adaptive MiniLM](https://arxiv.org/abs/2210.17114), and NeurIPS 2021's paper [Prune Once for All: Sparse Pre-Trained Language Models](https://arxiv.org/abs/2111.05754)) * Optimized Transformer-based model packages such as [Stable Diffusion](examples/huggingface/pytorch/text-to-image/deployment/stable_diffusion), [GPT-J-6B](examples/huggingface/pytorch/text-generation/deployment), [GPT-NEOX](examples/huggingface/pytorch/language-modeling/quantization#2-validated-model-list), [BLOOM-176B](examples/huggingface/pytorch/language-modeling/inference#BLOOM-176B), [T5](examples/huggingface/pytorch/summarization/quantization#2-validated-model-list), [Flan-T5](examples/huggingface/pytorch/summarization/quantization#2-validated-model-list), and end-to-end workflows such as [SetFit-based text classification](docs/tutorials/pytorch/text-classification/SetFit_model_compression_AGNews.ipynb) and [document level sentiment analysis (DLSA)](workflows/dlsa) * [NeuralChat](intel_extension_for_transformers/neural_chat), a customizable chatbot framework to create your own chatbot within minutes by leveraging a rich set of [plugins](https://github.com/intel/intel-extension-for-transformers/blob/main/intel_extension_for_transformers/neural_chat/docs/advanced_features.md) such as [Knowledge Retrieval](./intel_extension_for_transformers/neural_chat/pipeline/plugins/retrieval/README.md), [Speech Interaction](./intel_extension_for_transformers/neural_chat/pipeline/plugins/audio/README.md), [Query Caching](./intel_extension_for_transformers/neural_chat/pipeline/plugins/caching/README.md), and [Security Guardrail](./intel_extension_for_transformers/neural_chat/pipeline/plugins/security/README.md). This framework supports Intel Gaudi2/CPU/GPU. * [Inference](https://github.com/intel/neural-speed/tree/main) of Large Language Model (LLM) in pure C/C++ with weight-only quantization kernels for Intel CPU and Intel GPU (TBD), supporting [GPT-NEOX](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptneox), [LLAMA](https://github.com/intel/neural-speed/tree/main/neural_speed/models/llama), [MPT](https://github.com/intel/neural-speed/tree/main/neural_speed/models/mpt), [FALCON](https://github.com/intel/neural-speed/tree/main/neural_speed/models/falcon), [BLOOM-7B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/bloom), [OPT](https://github.com/intel/neural-speed/tree/main/neural_speed/models/opt), [ChatGLM2-6B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/chatglm), [GPT-J-6B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptj), and [Dolly-v2-3B](https://github.com/intel/neural-speed/tree/main/neural_speed/models/gptneox). Support AMX, VNNI, AVX512F and AVX2 instruction set. We've boosted the performance of Intel CPUs, with a particular focus on the 4th generation Intel Xeon Scalable processor, codenamed [Sapphire Rapids](https://www.intel.com/content/www/us/en/products/docs/processors/xeon-accelerated/4th-gen-xeon-scalable-processors.html).
ExtractThinker
ExtractThinker is a library designed for extracting data from files and documents using Language Model Models (LLMs). It offers ORM-style interaction between files and LLMs, supporting multiple document loaders such as Tesseract OCR, Azure Form Recognizer, AWS TextExtract, and Google Document AI. Users can customize extraction using contract definitions, process documents asynchronously, handle various document formats efficiently, and split and process documents. The project is inspired by the LangChain ecosystem and focuses on Intelligent Document Processing (IDP) using LLMs to achieve high accuracy in document extraction tasks.

infinity
Infinity is a high-throughput, low-latency REST API for serving vector embeddings, supporting all sentence-transformer models and frameworks. It is developed under the MIT License and powers inference behind Gradient.ai. The API allows users to deploy models from SentenceTransformers, offers fast inference backends utilizing various accelerators, dynamic batching for efficient processing, correct and tested implementation, and easy-to-use API built on FastAPI with Swagger documentation. Users can embed text, rerank documents, and perform text classification tasks using the tool. Infinity supports various models from Huggingface and provides flexibility in deployment via CLI, Docker, Python API, and cloud services like dstack. The tool is suitable for tasks like embedding, reranking, and text classification.
zep
Zep is a long-term memory service for AI Assistant apps. With Zep, you can provide AI assistants with the ability to recall past conversations, no matter how distant, while also reducing hallucinations, latency, and cost. Zep persists and recalls chat histories, and automatically generates summaries and other artifacts from these chat histories. It also embeds messages and summaries, enabling you to search Zep for relevant context from past conversations. Zep does all of this asyncronously, ensuring these operations don't impact your user's chat experience. Data is persisted to database, allowing you to scale out when growth demands. Zep also provides a simple, easy to use abstraction for document vector search called Document Collections. This is designed to complement Zep's core memory features, but is not designed to be a general purpose vector database. Zep allows you to be more intentional about constructing your prompt: 1. automatically adding a few recent messages, with the number customized for your app; 2. a summary of recent conversations prior to the messages above; 3. and/or contextually relevant summaries or messages surfaced from the entire chat session. 4. and/or relevant Business data from Zep Document Collections.
llm-apps-java-spring-ai
The 'LLM Applications with Java and Spring AI' repository provides samples demonstrating how to build Java applications powered by Generative AI and Large Language Models (LLMs) using Spring AI. It includes projects for question answering, chat completion models, prompts, templates, multimodality, output converters, embedding models, document ETL pipeline, function calling, image models, and audio models. The repository also lists prerequisites such as Java 21, Docker/Podman, Mistral AI API Key, OpenAI API Key, and Ollama. Users can explore various use cases and projects to leverage LLMs for text generation, vector transformation, document processing, and more.
simpletransformers
Simple Transformers is a library based on the Transformers library by HuggingFace, allowing users to quickly train and evaluate Transformer models with only 3 lines of code. It supports various tasks such as Information Retrieval, Language Models, Encoder Model Training, Sequence Classification, Token Classification, Question Answering, Language Generation, T5 Model, Seq2Seq Tasks, Multi-Modal Classification, and Conversational AI.

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.
aiverify
AI Verify is an AI governance testing framework and software toolkit that validates the performance of AI systems against a set of internationally recognised principles through standardised tests. AI Verify is consistent with international AI governance frameworks such as those from European Union, OECD and Singapore. It is a single integrated toolkit that operates within an enterprise environment. It can perform technical tests on common supervised learning classification and regression models for most tabular and image datasets. It however does not define AI ethical standards and does not guarantee that any AI system tested will be free from risks or biases or is completely safe.

spark-nlp
Spark NLP is a state-of-the-art Natural Language Processing library built on top of Apache Spark. It provides simple, performant, and accurate NLP annotations for machine learning pipelines that scale easily in a distributed environment. Spark NLP comes with 36000+ pretrained pipelines and models in more than 200+ languages. It offers tasks such as Tokenization, Word Segmentation, Part-of-Speech Tagging, Named Entity Recognition, Dependency Parsing, Spell Checking, Text Classification, Sentiment Analysis, Token Classification, Machine Translation, Summarization, Question Answering, Table Question Answering, Text Generation, Image Classification, Image to Text (captioning), Automatic Speech Recognition, Zero-Shot Learning, and many more NLP tasks. Spark NLP is the only open-source NLP library in production that offers state-of-the-art transformers such as BERT, CamemBERT, ALBERT, ELECTRA, XLNet, DistilBERT, RoBERTa, DeBERTa, XLM-RoBERTa, Longformer, ELMO, Universal Sentence Encoder, Llama-2, M2M100, BART, Instructor, E5, Google T5, MarianMT, OpenAI GPT2, Vision Transformers (ViT), OpenAI Whisper, and many more not only to Python and R, but also to JVM ecosystem (Java, Scala, and Kotlin) at scale by extending Apache Spark natively.
Advanced-GPTs
Nerority's Advanced GPT Suite is a collection of 33 GPTs that can be controlled with natural language prompts. The suite includes tools for various tasks such as strategic consulting, business analysis, career profile building, content creation, educational purposes, image-based tasks, knowledge engineering, marketing, persona creation, programming, prompt engineering, role-playing, simulations, and task management. Users can access links, usage instructions, and guides for each GPT on their respective pages. The suite is designed for public demonstration and usage, offering features like meta-sequence optimization, AI priming, prompt classification, and optimization. It also provides tools for generating articles, analyzing contracts, visualizing data, distilling knowledge, creating educational content, exploring topics, generating marketing copy, simulating scenarios, managing tasks, and more.

Awesome-Colorful-LLM
Awesome-Colorful-LLM is a meticulously assembled anthology of vibrant multimodal research focusing on advancements propelled by large language models (LLMs) in domains such as Vision, Audio, Agent, Robotics, and Fundamental Sciences like Mathematics. The repository contains curated collections of works, datasets, benchmarks, projects, and tools related to LLMs and multimodal learning. It serves as a comprehensive resource for researchers and practitioners interested in exploring the intersection of language models and various modalities for tasks like image understanding, video pretraining, 3D modeling, document understanding, audio analysis, agent learning, robotic applications, and mathematical research.

AiTreasureBox
AiTreasureBox is a versatile AI tool that provides a collection of pre-trained models and algorithms for various machine learning tasks. It simplifies the process of implementing AI solutions by offering ready-to-use components that can be easily integrated into projects. With AiTreasureBox, users can quickly prototype and deploy AI applications without the need for extensive knowledge in machine learning or deep learning. The tool covers a wide range of tasks such as image classification, text generation, sentiment analysis, object detection, and more. It is designed to be user-friendly and accessible to both beginners and experienced developers, making AI development more efficient and accessible to a wider audience.
20 - OpenAI Gpts

TradeComply
Import Export Compliance | Tariff Classification | Shipping Queries | Logistics & Supply Chain Solutions



Refine Product Management Enhancement Document
I help refine product enhancements. Logic - Essential Details - Business Value
Property Manager Document Assistant
Provides analysis and data extraction of Property Management documents and contracts for managers
LaTeX Picture & Document Transcriber
Convert into usable LaTeX code any pictures of your handwritten notes, documents in any format. Start by uploading what you need to convert.

DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages
Florida Entrepreneur Startup Documents Package
Startup document generator for Florida entrepreneurs.
University Application Guider
Expert in tailored college application and document preparation.

EPB CoPilot
Guides USAF Airmen in EPB document creation, utilizing provided military resources.
Ghana - Law Guide
Conversational AI for Ghanaian legal advice and document prep. Ghana Law Guide can sometimes generate inaccurate information.