Best AI tools for< Analyze Audio & Video >
20 - AI tool Sites
VideoInsights.ai
VideoInsights.ai is an AI-powered platform that serves as your AI assistant for media analysis. It allows users to analyze media content in real-time and gain valuable insights through lightning-fast, conversational analysis. The platform offers powerful features such as chat with videos, visual analysis, uploading and managing audio/video files, analyzing YouTube videos, and integrating analysis features via API. VideoInsights GPT provides a conversational interface to intuitively analyze audio and visual content, enhancing the overall media experience.
Sonix
Sonix is a powerful and easy-to-use online audio and video transcription service. It uses advanced artificial intelligence (AI) to convert speech to text quickly and accurately. Sonix supports over 38 languages and offers a variety of features, including automatic transcription, translation, subtitling, and summarization. It is a valuable tool for journalists, researchers, students, businesses, and anyone who needs to transcribe audio or video content.
GenIQ
GenIQ is an AI-powered application that allows users to interact with files through natural language. It generates concise summaries of lengthy documents using Generative AI technology. Users can work with various file types such as audio, video, PDF, and Word documents by asking questions in natural language and receiving real-time answers. GenIQ offers features like audio & video analysis, document processing, multilingual support, and handwritten document analysis.
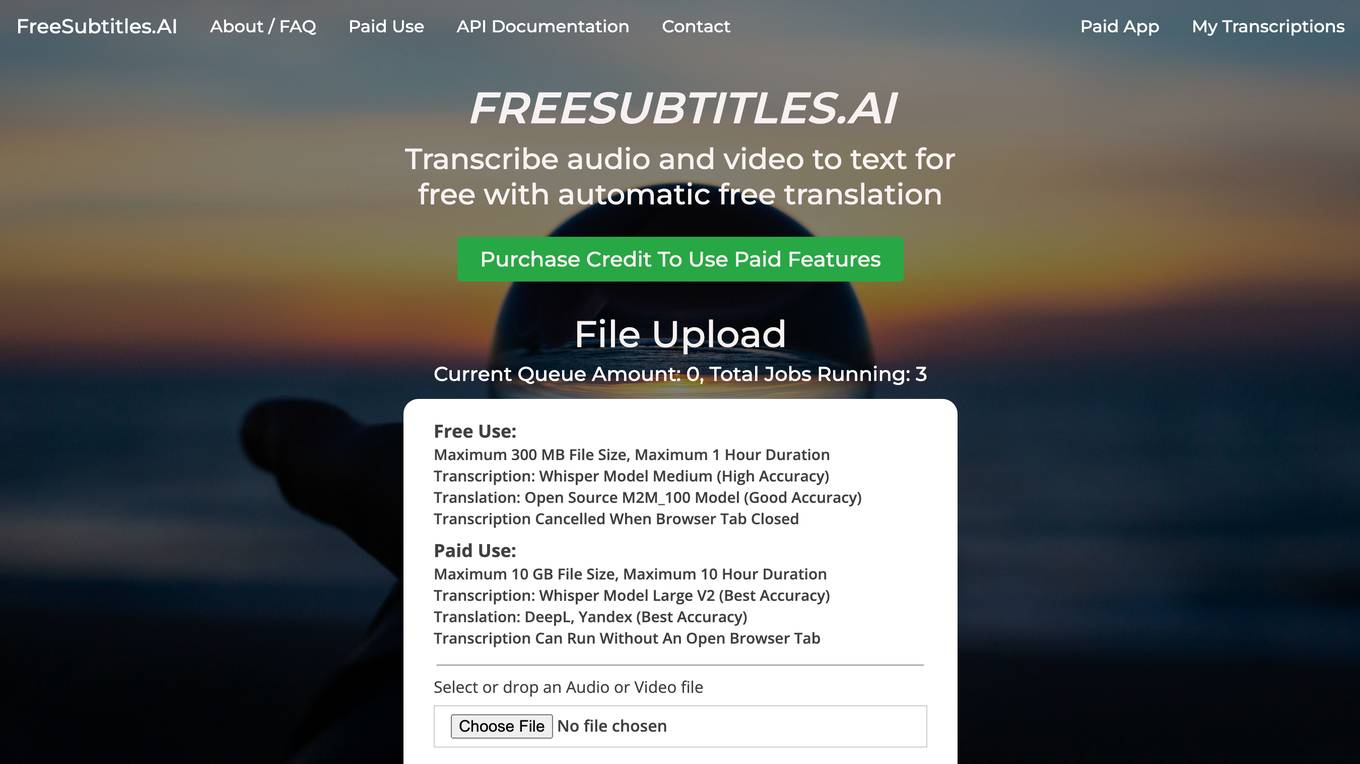
FreeSubtitles.AI
FreeSubtitles.AI is a free online tool that allows users to transcribe audio and video files to text. It supports a wide range of file formats and languages, and offers both free and paid transcription services. The free service allows users to transcribe files up to 300 MB in size and 1 hour in duration, while the paid service offers more advanced features such as larger file size limits, longer transcription durations, and higher accuracy models.
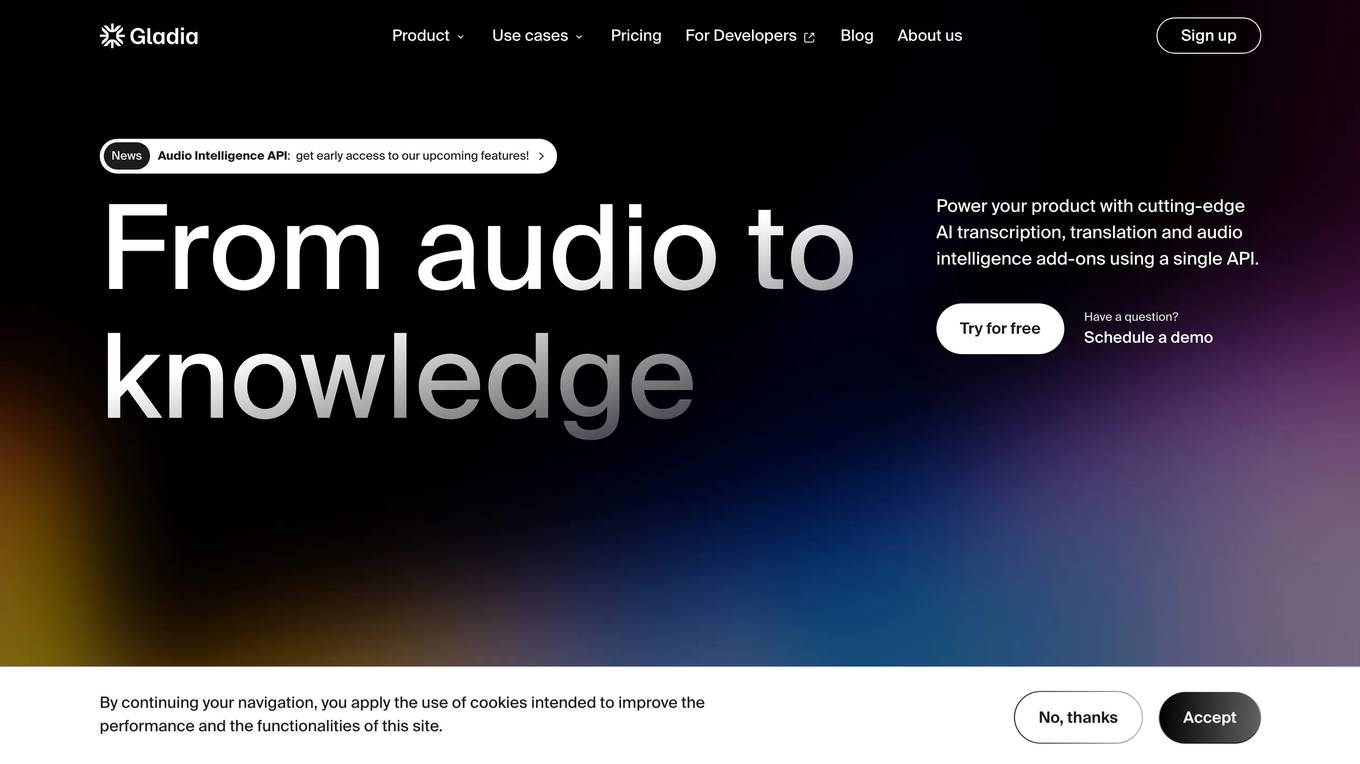
Gladia
Gladia provides a fast and accurate way to turn unstructured audio data into valuable business knowledge. Its Audio Intelligence API helps capture, enrich, and leverage hidden insights in audio data, powered by optimized Whisper ASR. Key features include highly accurate audio and video transcription, speech-to-text translation in 99 languages, in-depth insights with add-ons, and secure hosting options. Gladia's AI transcription and multilingual audio intelligence features enhance user experience and boost retention in various industries, including content and media, virtual meetings, workspace collaboration, and call centers. Developers can easily integrate cutting-edge AI into their products without AI expertise or setup costs.

Yescribe.ai
Yescribe.ai is an AI-powered transcription tool that converts audio and video files into text with fast, accurate, and affordable transcription services. It supports 98 languages, ensuring global coverage and accessibility. Users can easily upload files, transcribe them within minutes, and export/share the transcripts in multiple formats. The tool is ideal for professionals in various industries such as healthcare, legal, financial services, hospitality, technology, and real estate, offering unparalleled efficiency and accuracy in transcription. Yescribe.ai also provides insightful summaries, private and secure data handling, and extended support for up to 5-hour uploads.
Deepgram
Deepgram is a speech recognition and transcription service that uses artificial intelligence to convert audio into text. It is designed to be accurate, fast, and easy to use. Deepgram offers a variety of features, including: - Automatic speech recognition - Speaker diarization - Language identification - Custom acoustic models - Real-time transcription - Batch transcription - Webhooks - Integrations with popular platforms such as Zoom, Google Meet, and Microsoft Teams
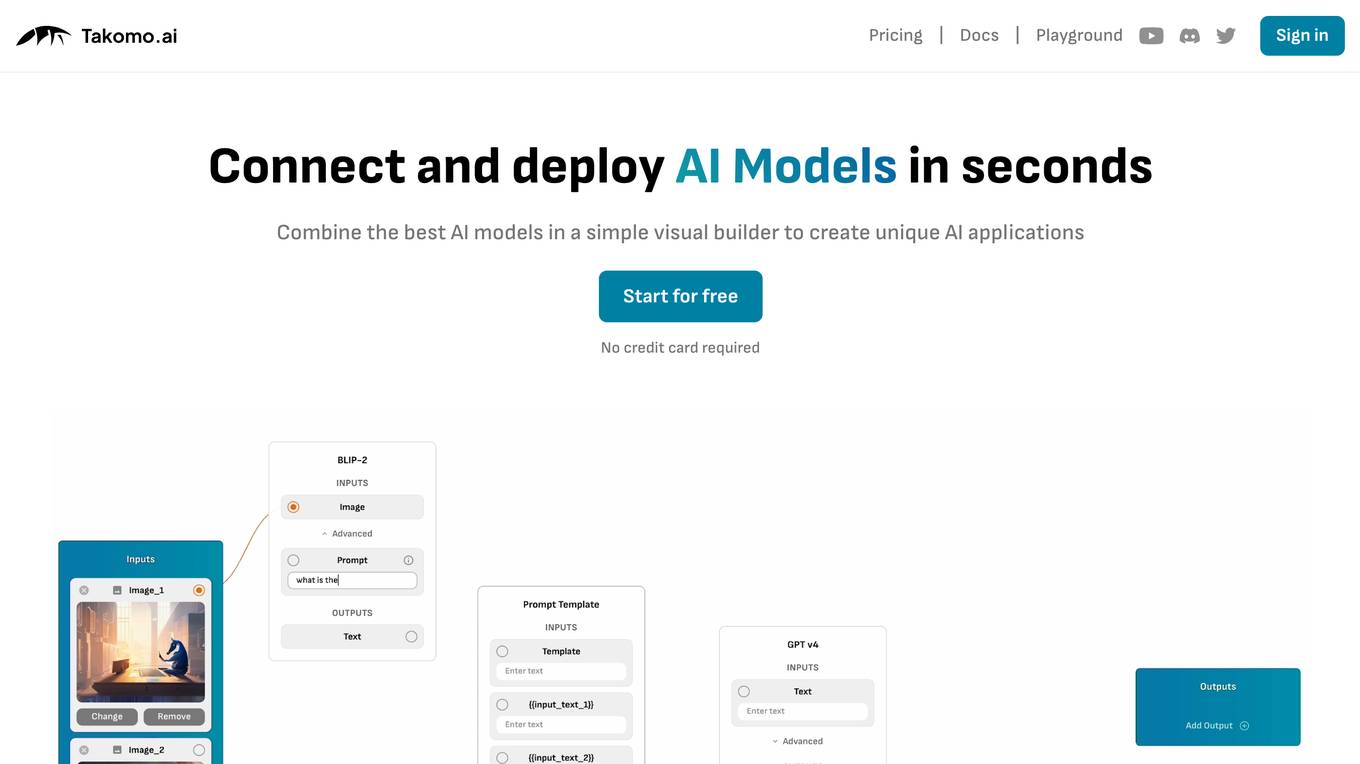
Takomo.ai
Takomo.ai is a no-code AI builder that allows users to connect and deploy AI models in seconds. With Takomo.ai, users can combine the best AI models in a simple visual builder to create unique AI applications. Takomo.ai offers a variety of features, including a drag-and-drop builder, pre-trained ML models, and a single API call for accessing multi-model pipelines.
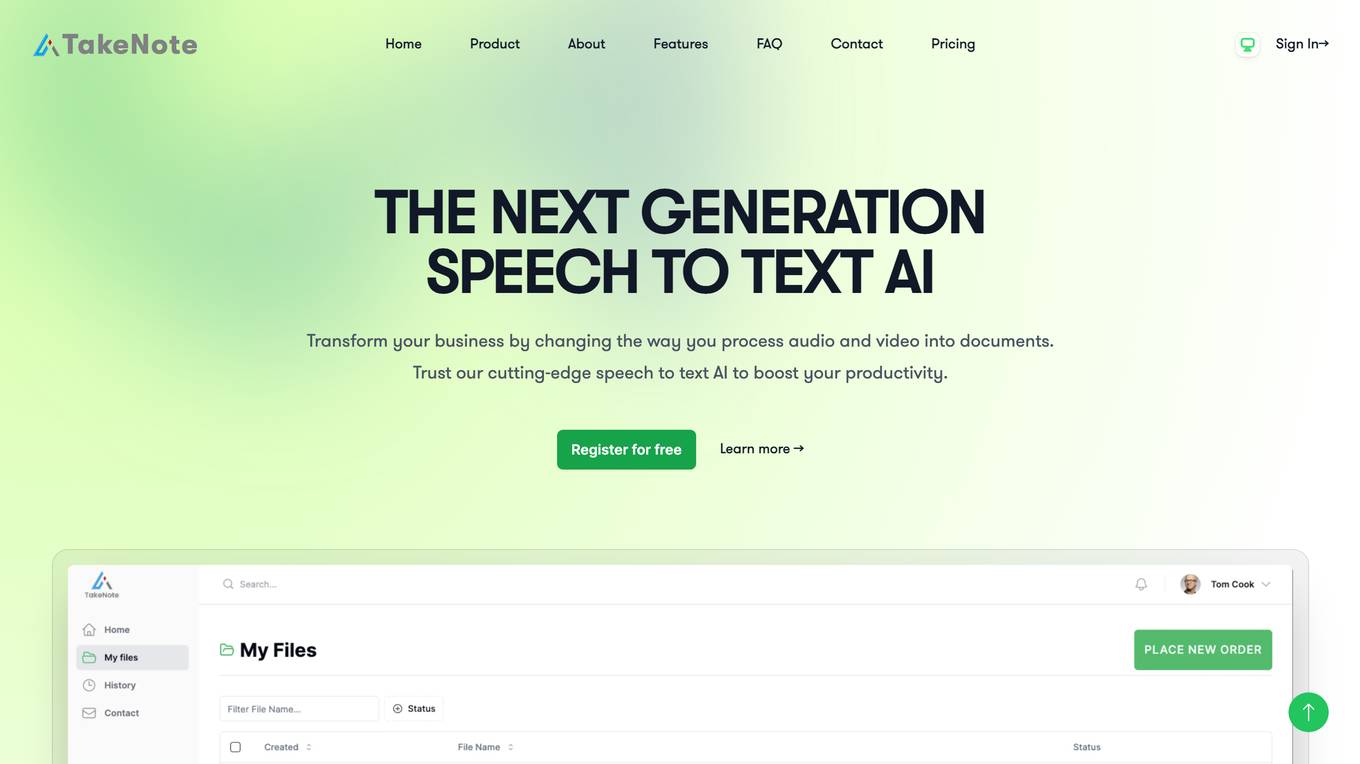
TakeNote
TakeNote is a cutting-edge speech-to-text AI that transforms audio and video into documents, boosting productivity and enhancing meeting experiences. Its advanced AI models provide exceptional accuracy, approaching human-level robustness and accuracy in English speech recognition. TakeNote AI empowers teams to transcribe meetings into accurate transcripts, generate precise summaries, analyze sentiment, and identify speakers, all while ensuring high levels of security and data protection.
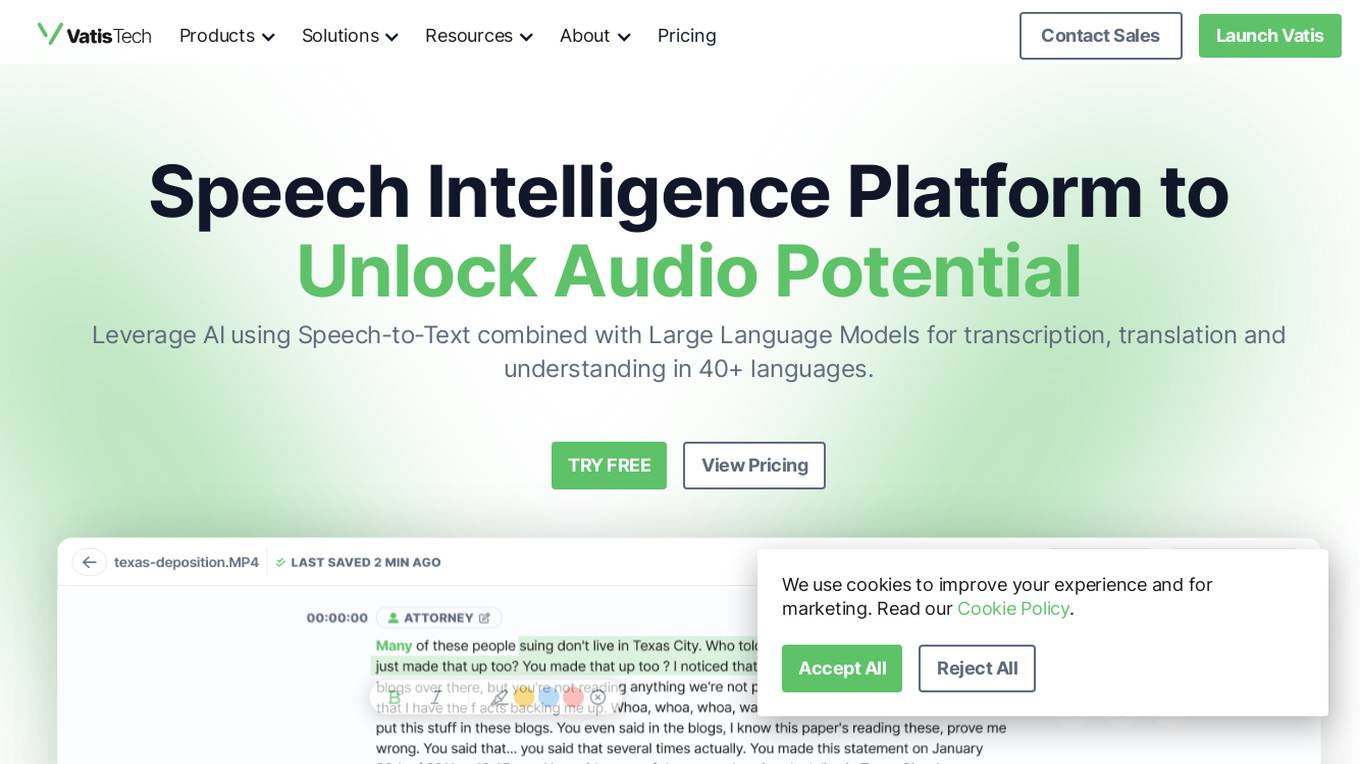
Vatis Tech
Vatis Tech is an AI-powered speech-to-text infrastructure that offers transcription software to help teams and individuals streamline their workflow. The platform provides accurate, accessible, and affordable speech-to-text API, caption generator, and audio intelligence solutions. It caters to various industries such as contact centers, broadcasting, medical, legal, media, newsrooms, and more. Vatis Tech's technology is powered by state-of-the-art AI, enabling near-human accuracy in transcribing speech with fast turnaround times. The platform also offers features like real-time transcription, custom AI models, and support for multiple languages.
Rythmex Converter
Rythmex Converter is an AI-powered audio-to-text converter tool that allows users to easily, quickly, and effectively transcribe audio files into text. With support for over 140 languages, Rythmex offers a seamless transcription experience for various industries such as business, education, journalism, law, and more. Users can upload their audio or video files, choose the language, and receive accurate transcriptions within minutes. The tool is designed to save time and effort by providing automated transcription services using machine learning technology.
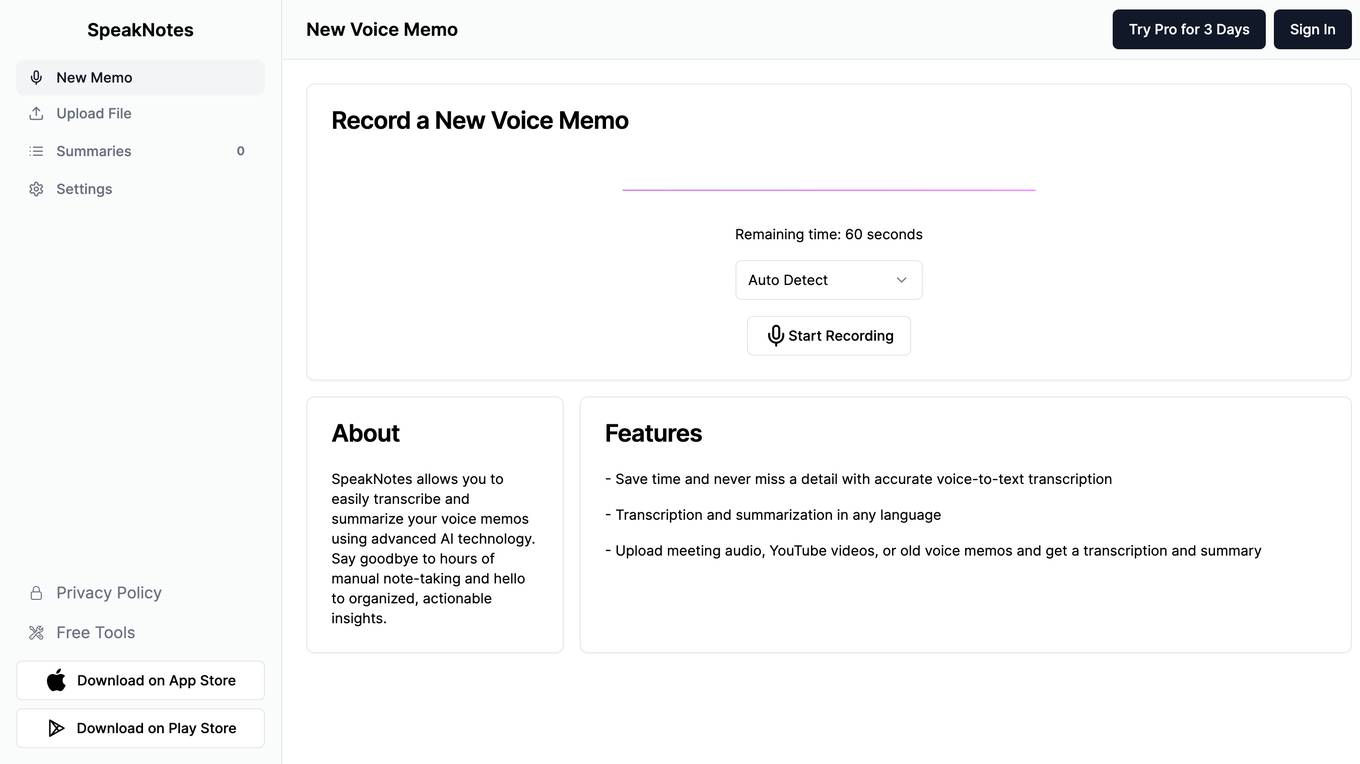
SpeakNotes
SpeakNotes is a revolutionary voice note summarizer that uses advanced AI technology to condense lengthy audio recordings into concise, easy-to-read summaries. With SpeakNotes, you can save time and effort by quickly capturing the key points of your voice notes, making it an invaluable tool for students, professionals, and anyone who relies on audio recordings for communication and information gathering.
Izwe.ai
Izwe.ai is a multi-lingual technology platform that transcribes speech to text in local languages. It is trusted by companies of all sizes, from startups to enterprises. Izwe.ai offers a range of solutions for businesses, including customer experience, developer automation, and personal transcription. The platform's features include automatic agent assessments, support from an internal knowledge base, and recommendations for actions and additional professional services.
SpeechFlow
SpeechFlow is a powerful speech-to-text API that transcribes audio and video files into text with high accuracy. It supports 14 languages and offers features such as punctuation, easy deployment, scalability, and fast processing. SpeechFlow is ideal for businesses and individuals who need accurate and timely transcription services.
Clips AI
Clips AI is an open-source Python library designed for developers to automatically convert longform videos into clips. It simplifies the process of segmenting videos and resizing their aspect ratio, making it ideal for audio-centric, narrative-based content like podcasts, interviews, speeches, and sermons. By analyzing video transcripts, Clips AI identifies key segments and dynamically reframes videos to focus on the current speaker. The tool streamlines the creation of engaging video content with minimal coding effort.
Deepfake Detector
Deepfake Detector is an AI tool designed to identify deepfake audio and video content with 92% model accuracy. It helps individuals and businesses protect themselves from deepfake scams by analyzing voice messages and calls for authenticity. The tool offers probabilities as a guide for further investigation, ensuring credibility in media reporting and legal proceedings. With features like AI Noise Remover and easy API integration, Deepfake Detector is a market leader in detecting deepfakes and preventing financial losses.
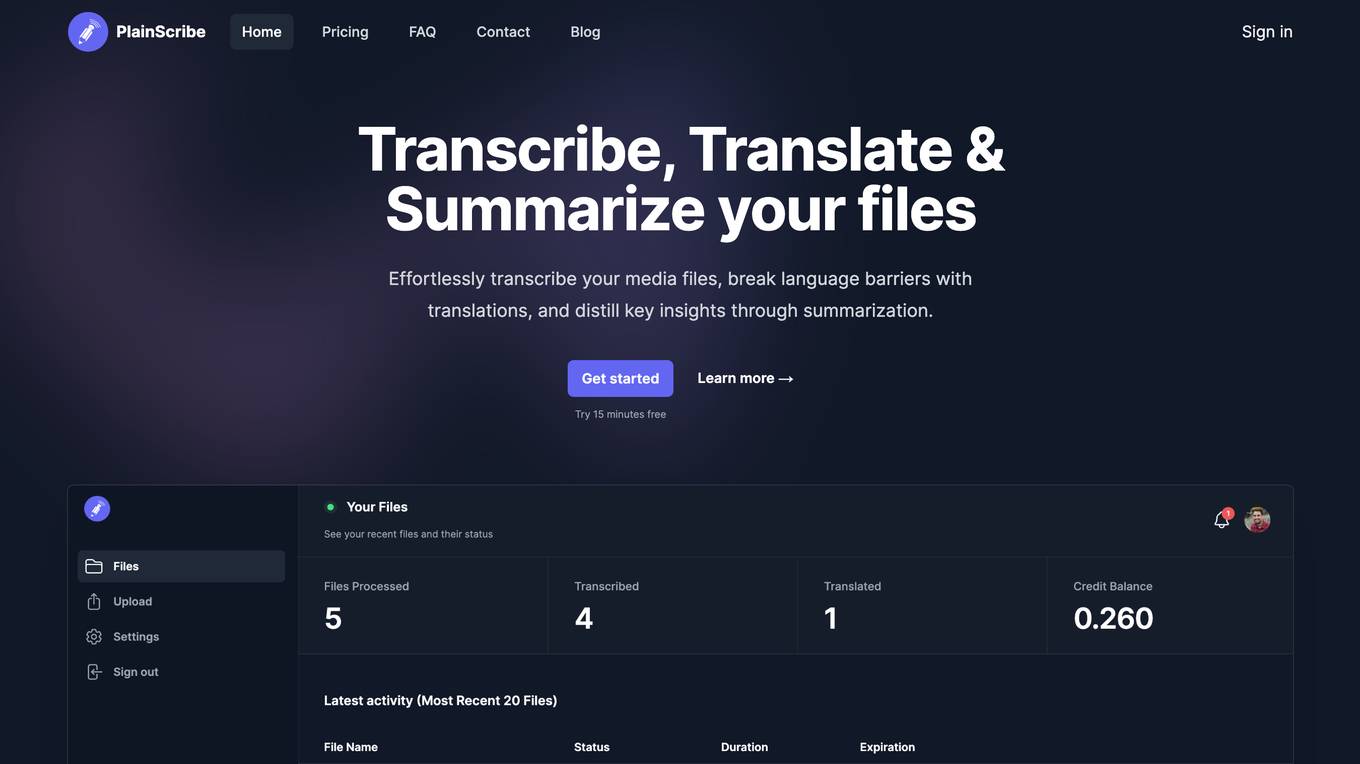
PlainScribe
PlainScribe is a versatile online tool that offers transcription, translation, and summarization services for various media files. Users can effortlessly transcribe their audio and video files, overcome language barriers with translations, and distill key insights through summarization. The platform supports a wide range of file sizes and provides a pay-as-you-go model for cost efficiency. With a focus on privacy and security, PlainScribe automatically deletes user data after 7 days. Additionally, users can benefit from multilingual support, summarized transcripts, and flexible export options like CSV and subtitle formats.
Easy Save AI
Easy Save AI is a comprehensive directory of Digital Marketing AI tools available online and curated by a digital marketing expert, Muritala Yusuf. Easy Save AI's primary objective is to ensure that AI is accessible to everyone. You can conveniently utilize our website to discover new AI tools and services or locate specific ones based on your requirements by Using our easy-to-use filter on the home page. AI technology is constantly progressing, and experts are continuously developing sophisticated models for various applications. Our directory includes an array of AI tools such as AI copywriters, text and image generators, AI transcription, SEO automation tools, and more. There is something suitable for every individual! Our website is committed to offering user-friendly AI tools and resources that can contribute to the success of you and your business in the digital era. We meticulously evaluate and curate each tool to ensure they possess valuable features and are accessible to both novices and experts. With the Easy Save AI platform, you can locate the AI tools you require and save valuable time and money. We sometimes have discounts on AI Tools and we always specify on the product page for you to use.
Speak Ai
Speak Ai is an AI-powered software that helps businesses and individuals transcribe, analyze, and visualize unstructured language data. With Speak Ai, users can automatically transcribe audio and video recordings, analyze text data, and generate insights from qualitative research. Speak Ai also offers a range of features to help users manage and share their data, including embeddable recorders, integrations with popular applications, and secure data storage.
Voicetapp
Voicetapp is a powerful cloud-based artificial intelligence software that helps you automatically convert audio to text with up to 100% accuracy. It supports over 170 languages and dialects, allowing you to quickly and accurately transcribe speech from audio and video files. Voicetapp also offers features such as speaker identification, live transcription, and multiple input formats, making it a versatile tool for various use cases.
20 - Open Source AI Tools

towhee
Towhee is a cutting-edge framework designed to streamline the processing of unstructured data through the use of Large Language Model (LLM) based pipeline orchestration. It can extract insights from diverse data types like text, images, audio, and video files using generative AI and deep learning models. Towhee offers rich operators, prebuilt ETL pipelines, and a high-performance backend for efficient data processing. With a Pythonic API, users can build custom data processing pipelines easily. Towhee is suitable for tasks like sentence embedding, image embedding, video deduplication, question answering with documents, and cross-modal retrieval based on CLIP.
freegenius
FreeGenius AI is an ambitious project offering a comprehensive suite of AI solutions that mirror the capabilities of LetMeDoIt AI. It is designed to engage in intuitive conversations, execute codes, provide up-to-date information, and perform various tasks. The tool is free, customizable, and provides access to real-time data and device information. It aims to support offline and online backends, open-source large language models, and optional API keys. Users can use FreeGenius AI for tasks like generating tweets, analyzing audio, searching financial data, checking weather, and creating maps.

amazon-transcribe-live-call-analytics
The Amazon Transcribe Live Call Analytics (LCA) with Agent Assist Sample Solution is designed to help contact centers assess and optimize caller experiences in real time. It leverages Amazon machine learning services like Amazon Transcribe, Amazon Comprehend, and Amazon SageMaker to transcribe and extract insights from contact center audio. The solution provides real-time supervisor and agent assist features, integrates with existing contact centers, and offers a scalable, cost-effective approach to improve customer interactions. The end-to-end architecture includes features like live call transcription, call summarization, AI-powered agent assistance, and real-time analytics. The solution is event-driven, ensuring low latency and seamless processing flow from ingested speech to live webpage updates.
toolmate
ToolMate AI is an advanced AI companion that integrates agents, tools, and plugins to excel in conversations, generative work, and task execution. It supports multi-step actions, allowing users to customize workflows for tackling complex projects with ease. The tool offers a wide range of AI backends and models, including Ollama, Llama.cpp, Groq Cloud API, OpenAI API, and Google Gemini via Vertex AI. Users can easily switch between backends and leverage AI models like wizardlm2 and mixtral. ToolMate AI stands out for its distinctive features such as tool calling for any LLMs, running multiple tools in one go, highly customizable plugins, and integration with popular AI tools. It also supports quick tool calling using '@' notation and enables the execution of computing tasks on demand. With features like multiple tools in one go, customizable plugins, system command and fabric integration, GPU offloading support, real-time data access, and device information retrieval, ToolMate AI offers a comprehensive solution for various tasks and content creation.
WeeaBlind
Weeablind is a program that uses modern AI speech synthesis, diarization, language identification, and voice cloning to dub multi-lingual media and anime. It aims to create a pleasant alternative for folks facing accessibility hurdles such as blindness, dyslexia, learning disabilities, or simply those that don't enjoy reading subtitles. The program relies on state-of-the-art technologies such as ffmpeg, pydub, Coqui TTS, speechbrain, and pyannote.audio to analyze and synthesize speech that stays in-line with the source video file. Users have the option of dubbing every subtitle in the video, setting the start and end times, dubbing only foreign-language content, or full-blown multi-speaker dubbing with speaking rate and volume matching.
ai-audio-startups
The 'ai-audio-startups' repository is a community list of startups working with AI for audio and music tech. It includes a comprehensive collection of tools and platforms that leverage artificial intelligence to enhance various aspects of music creation, production, source separation, analysis, recommendation, health & wellbeing, radio/podcast, hearing, sound detection, speech transcription, synthesis, enhancement, and manipulation. The repository serves as a valuable resource for individuals interested in exploring innovative AI applications in the audio and music industry.

awesome-ai-tools
Awesome AI Tools is a curated list of popular tools and resources for artificial intelligence enthusiasts. It includes a wide range of tools such as machine learning libraries, deep learning frameworks, data visualization tools, and natural language processing resources. Whether you are a beginner or an experienced AI practitioner, this repository aims to provide you with a comprehensive collection of tools to enhance your AI projects and research. Explore the list to discover new tools, stay updated with the latest advancements in AI technology, and find the right resources to support your AI endeavors.

awesome-large-audio-models
This repository is a curated list of awesome large AI models in audio signal processing, focusing on the application of large language models to audio tasks. It includes survey papers, popular large audio models, automatic speech recognition, neural speech synthesis, speech translation, other speech applications, large audio models in music, and audio datasets. The repository aims to provide a comprehensive overview of recent advancements and challenges in applying large language models to audio signal processing, showcasing the efficacy of transformer-based architectures in various audio tasks.

data-juicer
Data-Juicer is a one-stop data processing system to make data higher-quality, juicier, and more digestible for LLMs. It is a systematic & reusable library of 80+ core OPs, 20+ reusable config recipes, and 20+ feature-rich dedicated toolkits, designed to function independently of specific LLM datasets and processing pipelines. Data-Juicer allows detailed data analyses with an automated report generation feature for a deeper understanding of your dataset. Coupled with multi-dimension automatic evaluation capabilities, it supports a timely feedback loop at multiple stages in the LLM development process. Data-Juicer offers tens of pre-built data processing recipes for pre-training, fine-tuning, en, zh, and more scenarios. It provides a speedy data processing pipeline requiring less memory and CPU usage, optimized for maximum productivity. Data-Juicer is flexible & extensible, accommodating most types of data formats and allowing flexible combinations of OPs. It is designed for simplicity, with comprehensive documentation, easy start guides and demo configs, and intuitive configuration with simple adding/removing OPs from existing configs.
Top-AI-Tools
Top AI Tools is a comprehensive, community-curated directory that aims to catalog and showcase the most outstanding AI-powered products. This index is not exhaustive, but rather a compilation of our research and contributions from the community.
letmedoit
LetMeDoIt AI is a virtual assistant designed to revolutionize the way you work. It goes beyond being a mere chatbot by offering a unique and powerful capability - the ability to execute commands and perform computing tasks on your behalf. With LetMeDoIt AI, you can access OpenAI ChatGPT-4, Google Gemini Pro, and Microsoft AutoGen, local LLMs, all in one place, to enhance your productivity.



ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.

wdoc
wdoc is a powerful Retrieval-Augmented Generation (RAG) system designed to summarize, search, and query documents across various file types. It aims to handle large volumes of diverse document types, making it ideal for researchers, students, and professionals dealing with extensive information sources. wdoc uses LangChain to process and analyze documents, supporting tens of thousands of documents simultaneously. The system includes features like high recall and specificity, support for various Language Model Models (LLMs), advanced RAG capabilities, advanced document summaries, and support for multiple tasks. It offers markdown-formatted answers and summaries, customizable embeddings, extensive documentation, scriptability, and runtime type checking. wdoc is suitable for power users seeking document querying capabilities and AI-powered document summaries.

outspeed
Outspeed is a PyTorch-inspired SDK for building real-time AI applications on voice and video input. It offers low-latency processing of streaming audio and video, an intuitive API familiar to PyTorch users, flexible integration of custom AI models, and tools for data preprocessing and model deployment. Ideal for developing voice assistants, video analytics, and other real-time AI applications processing audio-visual data.

VITA
VITA is an open-source interactive omni multimodal Large Language Model (LLM) capable of processing video, image, text, and audio inputs simultaneously. It stands out with features like Omni Multimodal Understanding, Non-awakening Interaction, and Audio Interrupt Interaction. VITA can respond to user queries without a wake-up word, track and filter external queries in real-time, and handle various query inputs effectively. The model utilizes state tokens and a duplex scheme to enhance the multimodal interactive experience.
20 - OpenAI Gpts
ArtGPT
Doing art design and research, including fine arts, audio arts and video arts, designed by Prof. Dr. Fred Y. Ye (Ying Ye)
Video Insights: Summaries/Transcription/Vision
Chat with any video or audio. High-quality search, summarization, insights, multi-language transcriptions, and more. We currently support Youtube and files uploaded on our website.

Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.

Signal Processing Advisor
Provides expert guidance on signal processing in engineering projects.
Technical SEO Audit by MTS
I analyze websites and blog posts for technical SEO compliance and provide detailed reports.


Log Analyzer
I'm designed to help You analyze any logs like Linux system logs, Windows logs, any security logs, access logs, error logs, etc. Please do not share information that You would like to keep private. The author does not collect or process any personal data.

Is it a ranking factor?
Explore the 14,000 ranking factors, signals, and features revealed in the latest leaked Google Search docs. Updated May 2024.