Best AI tools for< Optimize Software Deployment >
20 - AI tool Sites
GitLab
GitLab is a comprehensive AI-powered DevSecOps platform that balances speed and security in a single platform. It automates software delivery, boosts productivity, and secures the end-to-end software supply chain. GitLab simplifies the toolchain by providing all essential DevSecOps tools in one place, accelerates software delivery with automation and AI-powered workflows, and integrates security seamlessly. It allows users to deploy anywhere without cloud vendor lock-in, offering value stream management, analytics, and insights to accelerate coding and optimize processes.
Modular
Modular is a fast, scalable Gen AI inference platform that offers a comprehensive suite of tools and resources for AI development and deployment. It provides solutions for AI model development, deployment options, AI inference, research, and resources like documentation, models, tutorials, and step-by-step guides. Modular supports GPU and CPU performance, intelligent scaling to any cluster, and offers deployment options for various editions. The platform enables users to build agent workflows, utilize AI retrieval and controlled generation, develop chatbots, engage in code generation, and improve resource utilization through batch processing.
Render
Render is a platform that simplifies the deployment and scaling of web applications and services. It provides a seamless experience for developers to launch their applications quickly and efficiently. With Render, users can easily manage their infrastructure, monitor performance, and ensure high availability of their applications. The platform offers a range of features to streamline the deployment process and optimize the performance of web applications.
Harness
Harness is an AI-driven software delivery platform that empowers software engineering teams with AI-infused technology for seamless software delivery. It offers a single platform for all software delivery needs, including DevOps modernization, continuous delivery, GitOps, feature flags, infrastructure as code management, chaos engineering, service reliability management, secure software delivery, cloud cost optimization, and more. Harness aims to simplify the developer experience by providing actionable insights on SDLC, secure software supply chain assurance, and AI development assistance throughout the software delivery lifecycle.
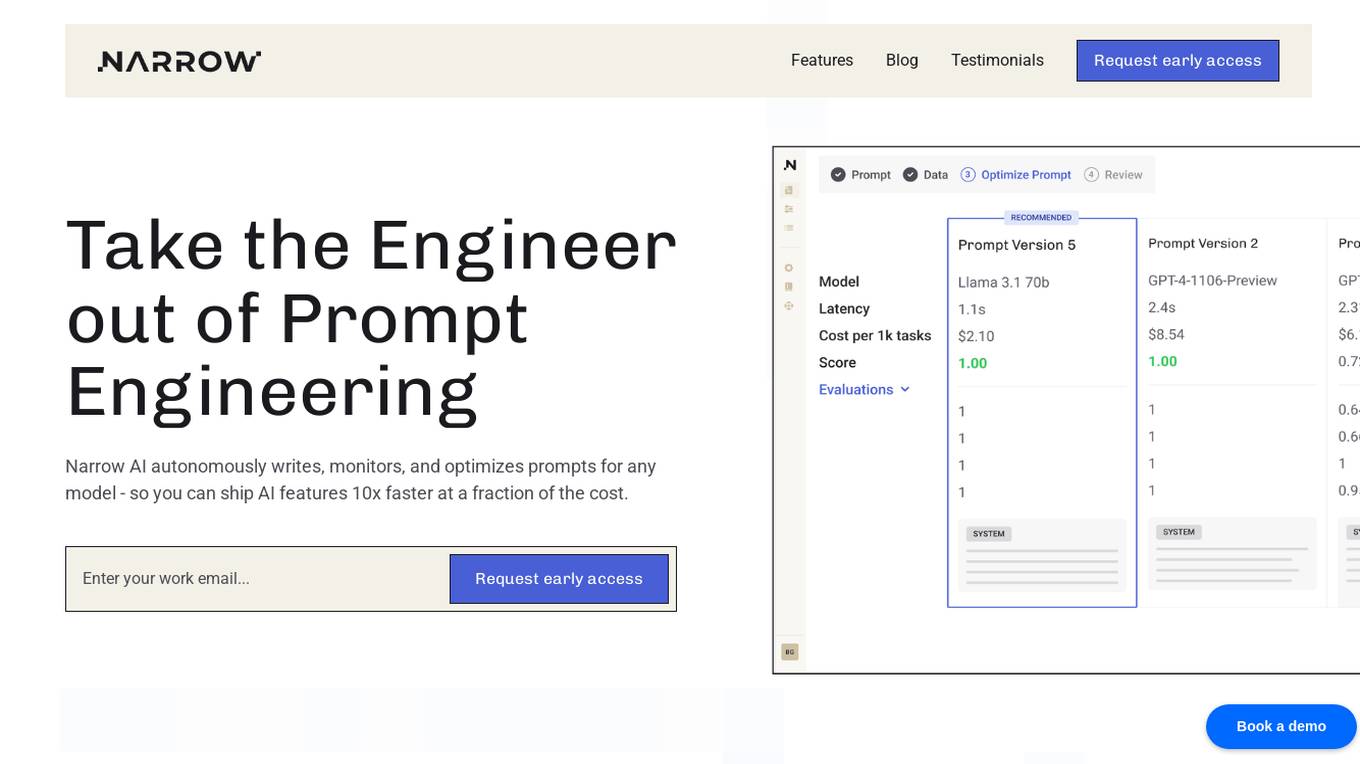
Narrow AI
Narrow AI is an AI application that autonomously writes, monitors, and optimizes prompts for any model, enabling users to ship AI features 10x faster at a fraction of the cost. It streamlines the workflow by allowing users to test new models in minutes, compare prompt performance, and deploy on the optimal model for their use case. Narrow AI helps users maximize efficiency by generating expert-level prompts, adapting prompts to new models, and optimizing prompts for quality, cost, and speed.

Alli AI
Alli AI is an SEO automation and real-time deployment tool that helps agencies and SEO teams scale and automate their campaigns while saving time and money. With Alli AI, you can optimize your site, do keyword research, track your rankings, audit your site, and build backlinks all under one roof.
FuriosaAI
FuriosaAI is an AI application that offers Hardware RNGD for LLM and Multimodality, as well as WARBOY for Computer Vision. It provides a comprehensive developer experience through the Furiosa SDK, Model Zoo, and Dev Support. The application focuses on efficient AI inference, high-performance LLM and multimodal deployment capabilities, and sustainable mass adoption of AI. FuriosaAI features the Tensor Contraction Processor architecture, software for streamlined LLM deployment, and a robust ecosystem support. It aims to deliver powerful and efficient deep learning acceleration while ensuring future-proof programmability and efficiency.
Microtica
Microtica is an AI-powered cloud delivery platform that offers a comprehensive suite of DevOps tools to help users build, deploy, and optimize their infrastructure efficiently. With features like AI Incident Investigator, AI Infrastructure Builder, Kubernetes deployment simplification, alert monitoring, pipeline automation, and cloud monitoring, Microtica aims to streamline the development and management processes for DevOps teams. The platform provides real-time insights, cost optimization suggestions, and guided deployments, making it a valuable tool for businesses looking to enhance their cloud infrastructure operations.
Integrail
Integrail is an AI tool that simplifies the process of building AI applications by allowing users to design and deploy multi-agent applications without the need for coding skills. It offers a range of features such as integrating external apps, optimizing cost and accuracy, and deploying applications securely in the cloud or on-premises. Integrail Studio provides access to popular AI models and enables users to transform business workflows efficiently.

Helix AI
Helix AI is a private GenAI platform that enables users to build AI applications using open source models. The platform offers tools for RAG (Retrieval-Augmented Generation) and fine-tuning, allowing deployment on-premises or in a Virtual Private Cloud (VPC). Users can access curated models, utilize Helix API tools to connect internal and external APIs, embed Helix Assistants into websites/apps for chatbot functionality, write AI application logic in natural language, and benefit from the innovative RAG system for Q&A generation. Additionally, users can fine-tune models for domain-specific needs and deploy securely on Kubernetes or Docker in any cloud environment. Helix Cloud offers free and premium tiers with GPU priority, catering to individuals, students, educators, and companies of varying sizes.
Kleene.ai
Kleene.ai is an AI application that offers easy data management solutions to transform businesses. It provides Decision Intelligence and Data Management Platform with various AI Applications and Data Consulting services. Kleene.ai helps organizations organize and analyze their data to drive real commercial impact in weeks with the help of AI. The platform offers features like Data Integrations, ELT, Data Ops Management, and Data Visualisation, and is suitable for various departments including Finance, Marketing, and Supply Chain. Kleene.ai is known for its fast deployment, full support along the data journey, unified data organization, and focus on delivering business value through advanced analytics.
Serenity Star
Serenity Star is a Generative AI deployment service that offers Models As A Service to help businesses increase productivity and design tailored solutions. The platform provides access to over 100 LLMs, an ecosystem with agents, co-pilots, and plugins, and features low code and no code solutions for quick market release. Serenity Star aims to simplify the implementation of Generative AI in enterprises by offering tools, support, and resources for process optimization, innovation, revenue maximization, and informed decision-making.
Embedl
Embedl is an AI tool that specializes in developing advanced solutions for efficient AI deployment in embedded systems. With a focus on deep learning optimization, Embedl offers a cost-effective solution that reduces energy consumption and accelerates product development cycles. The platform caters to industries such as automotive, aerospace, and IoT, providing cutting-edge AI products that drive innovation and competitive advantage.
Anycores
Anycores is an AI tool designed to optimize the performance of deep neural networks and reduce the cost of running AI models in the cloud. It offers a platform that provides automated solutions for tuning and inference consultation, optimized networks zoo, and platform for reducing AI model cost. Anycores focuses on faster execution, reducing inference time over 10x times, and footprint reduction during model deployment. It is device agnostic, supporting Nvidia, AMD GPUs, Intel, ARM, AMD CPUs, servers, and edge devices. The tool aims to provide highly optimized, low footprint networks tailored to specific deployment scenarios.
Qualcomm AI Hub
Qualcomm AI Hub is a platform that allows users to run AI models on Snapdragon® 8 Elite devices. It provides a collaborative ecosystem for model makers, cloud providers, runtime, and SDK partners to deploy on-device AI solutions quickly and efficiently. Users can bring their own models, optimize for deployment, and access a variety of AI services and resources. The platform caters to various industries such as mobile, automotive, and IoT, offering a range of models and services for edge computing.

PoplarML
PoplarML is a platform that enables the deployment of production-ready, scalable ML systems with minimal engineering effort. It offers one-click deploys, real-time inference, and framework agnostic support. With PoplarML, users can seamlessly deploy ML models using a CLI tool to a fleet of GPUs and invoke their models through a REST API endpoint. The platform supports Tensorflow, Pytorch, and JAX models.
Backend.AI
Backend.AI is an enterprise-scale cluster backend for AI frameworks that offers scalability, GPU virtualization, HPC optimization, and DGX-Ready software products. It provides a fast and efficient way to build, train, and serve AI models of any type and size, with flexible infrastructure options. Backend.AI aims to optimize backend resources, reduce costs, and simplify deployment for AI developers and researchers. The platform integrates seamlessly with existing tools and offers fractional GPU usage and pay-as-you-play model to maximize resource utilization.
Dynamiq
Dynamiq is an operating platform for GenAI applications that enables users to build compliant GenAI applications in their own infrastructure. It offers a comprehensive suite of features including rapid prototyping, testing, deployment, observability, and model fine-tuning. The platform helps streamline the development cycle of AI applications and provides tools for workflow automations, knowledge base management, and collaboration. Dynamiq is designed to optimize productivity, reduce AI adoption costs, and empower organizations to establish AI ahead of schedule.
CHAI AI
CHAI AI is a leading conversational AI platform that focuses on building AI solutions for quant traders. The platform has secured significant funding rounds to enhance both its computational capabilities and talent acquisition. CHAI AI offers a range of features and advantages, including model upgrades, deployment of various AI models, and efficient inference techniques. The platform aims to provide users with the ability to create their own ChatAIs and offers a unique approach to model blending for improved user retention. With a strong team of AI researchers and engineers, CHAI AI continues to innovate in the field of AI technology.
AMD AI Solutions
AMD AI Solutions is a leading AI innovation platform with a broad portfolio, open ecosystem, and cutting-edge technology for data centers, edge computing, and clients. The platform offers end-to-end solutions powered by CPUs, GPUs, accelerators, networking, and open software, delivering unmatched flexibility and performance. AMD enables accelerated AI outcomes, sustained AI success, and is recognized as a trusted AI partner. With a commitment to minimizing costs, prioritizing security, and staying flexible, AMD empowers businesses and consumers to scale AI deployments effectively and efficiently.
0 - Open Source AI Tools
20 - OpenAI Gpts



Software Delivery Management Advisor
Streamlines software delivery processes to optimize operational efficiency.

Software Kanban Management Advisor
Guides software development processes through Kanban methodologies.

Algorithm Expert
I develop and optimize algorithms with a technical and analytical approach.
Software Architect
Expert in software architecture, ensuring integrity and scalability through best practices.
Software expert
Server admin expert in cPanel, Softaculous, WHM, WordPress, and Elementor Pro.
Brilliantly Lazy - Project Optimizer
Mastering efficient laziness in your projects, big or small. Ask this GPT for a follow-up matrix to optimize next steps.
Performance Testing Advisor
Ensures software performance meets organizational standards and expectations.
Strategy
Strategically aligns financial, logistical, and operational approaches, weaving innovative solutions into complex software development landscapes.
SQL Support Wizard
Expert in SQL accounting software, prioritizing the user manual and SQL Wiki.

OptiCode
OptiCode is designed to streamline and enhance your experience with ChatGPT software, tools, and extensions, ensuring efficient problem resolution and optimization of ChatGPT-related workflows.
Code Buddy
Your own personal senior software engineer mentor critiquing and optimizing your code helping your improve.


OSL Coder
I'm a software engineer specializing in OSL for Octane, here to help with your coding needs.