Best AI tools for< ocr >
20 - AI tool Sites
Receipt OCR API
Receipt OCR API by ReceiptUp is an advanced tool for precise data extraction from receipt and invoice images. The API leverages OCR and AI technology to accurately extract total amounts, taxes, dates, and merchant information, streamlining financial operations. It supports over 50 languages, multiple image formats, and offers affordable pricing. Users can easily integrate the API into their software systems for efficient receipt management and enhanced business analytics.
Ocrolus
Ocrolus is an intelligent document automation software that utilizes AI-driven document processing automation with Human-in-the-Loop. It offers capabilities such as Classify, Capture, Detect, and Analyze to streamline document processing tasks. The application caters to various industries like small business lending, mortgage, consumer, and multifamily, providing solutions for income verification, fraud detection, cash flow analysis, and business process automation. Ocrolus helps users manage risk, avoid fraud, and make faster and more accurate financial decisions by automating document analysis.
GrabText
GrabText is an online OCR tool that allows users to convert handwritten or printed text from photos, graphics, or documents into editable text. It uses ChatGPT to automatically correct spelling, grammar, and other illegal writings. The tool also supports math equations and offers flexible output options such as txt, latex, doc, and pdf.
GetSearchablePDF
GetSearchablePDF is an online tool that allows users to convert scanned or image-based PDF documents into searchable PDFs. With its advanced OCR (Optical Character Recognition) technology, the tool accurately extracts text from images, making the resulting PDFs easy to search, edit, and share. The process is simple and straightforward: users simply connect their Dropbox or OneDrive account, drag and drop their PDF files into the designated folder, and the tool automatically converts them into searchable PDFs.
Booke AI
Booke AI is an AI-driven bookkeeping software that automates tasks, reduces errors, and improves communication. It uses AI to categorize transactions, extract data from invoices and receipts, and provide expert reconciliation assistance. Booke AI integrates with Xero, QuickBooks, and Zoho Books, and offers a user-friendly client portal for seamless collaboration. With Booke AI, businesses can save time, reduce stress, and improve the accuracy of their bookkeeping.
TextUnbox
TextUnbox is an AI-powered tool that allows users to extract text from images, generate images from text descriptions, translate text, remove image backgrounds, and more. It supports over 20 languages and can be used in the browser or integrated into custom solutions using its REST API.
LedgerBox
LedgerBox is an intelligent document processing tool that leverages artificial intelligence and machine learning to automate the extraction of valuable data from various documents such as bank statements, invoices, and receipts. It helps streamline tasks like data entry, financial auditing, expense management, tax preparation, and more, by efficiently processing structured, semi-structured, and unstructured documents. With LedgerBox, users can improve accuracy, reduce manual errors, and enhance operational efficiency in tasks related to financial management and compliance monitoring.
Shufti Pro
Shufti Pro is an award-winning global identity verification platform that provides businesses with a suite of tools to verify the identities of their customers. The platform uses artificial intelligence (AI) to automate the identity verification process, making it faster, more accurate, and more secure. Shufti Pro's solutions are used by businesses in a variety of industries, including banking, fintech, crypto, forex, gaming, insurance, education, healthcare, e-commerce, and travel.
Be My Eyes
Be My Eyes is an AI-powered visual assistance application that connects blind and low-vision users with volunteers and companies worldwide. Users can request live video support, receive assistance through artificial intelligence, and access professional support from partners. The app aims to improve accessibility for individuals with visual impairments by providing a platform for real-time assistance and support.
Be My Eyes
Be My Eyes is a free mobile app that connects blind and low-vision people with sighted volunteers and AI-powered assistance. With Be My Eyes, blind and low-vision people can access visual information, get help with everyday tasks, and connect with others in the community. Be My Eyes is available in over 180 languages and has over 6 million volunteers worldwide.
Picture to Text Converter
Picture to Text Converter is an online tool that uses Optical Character Recognition (OCR) technology to extract text from images. It can process various image formats like JPG, PNG, GIF, scanned documents (PDFs), and even photos taken with your phone's camera. The extracted text can be copied to the clipboard or downloaded as a TXT file. Picture to Text Converter is free to use and does not require any registration or installation. It is a convenient and efficient way to convert images into editable text.
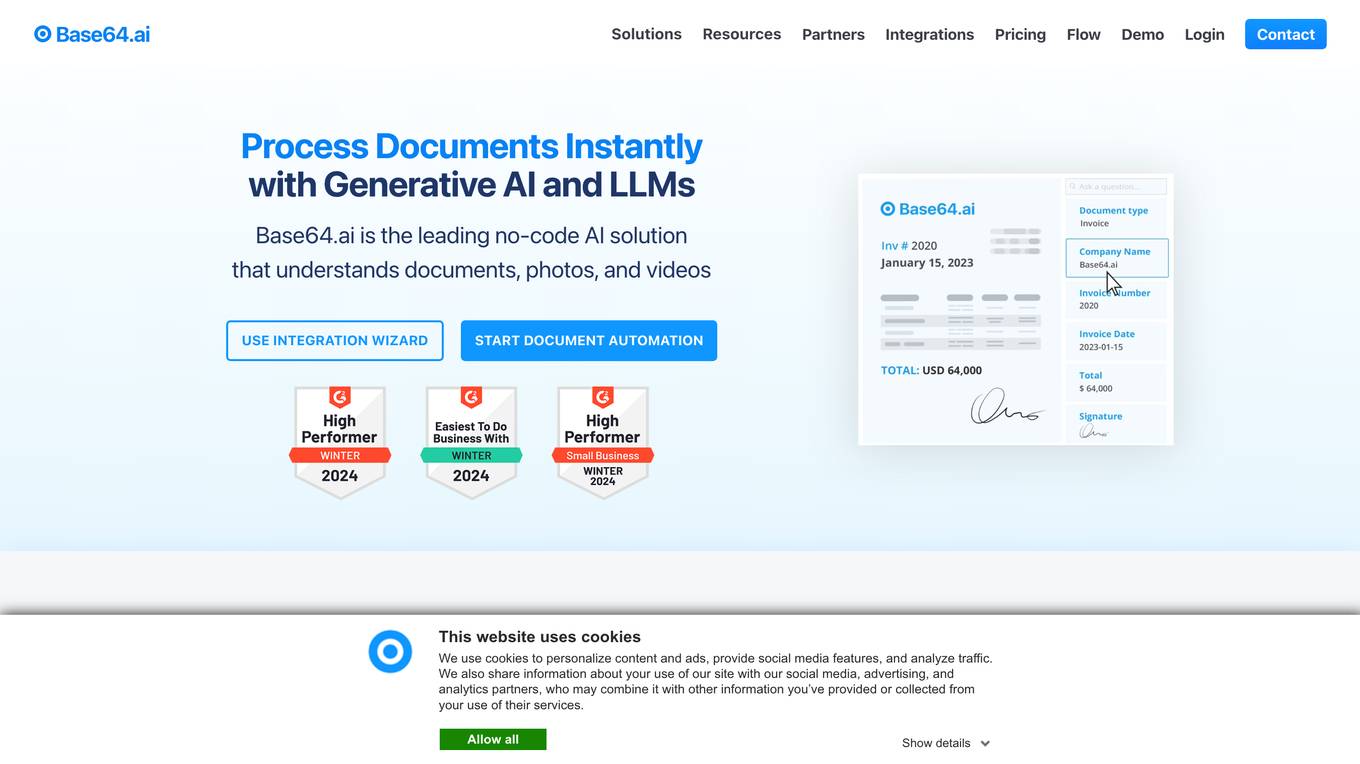
Base64.ai
Base64.ai is an automated document processing API that offers a leading no-code AI solution for understanding documents, photos, and videos. It provides a wide range of AI document processing features and solutions for various industries. With over 400+ integrations, Base64.ai ensures fast, secure, and accurate data extraction, certified for ISO, HIPAA, SOC 2 Type 1 & 2, and GDPR compliance. The platform allows users to add new document types, integrations, and business rules, commanding the AI to meet specific needs. Base64.ai also offers PII redaction, human-in-the-loop verification, and is accessible via API, RPA systems, scanners, web, and mobile apps.
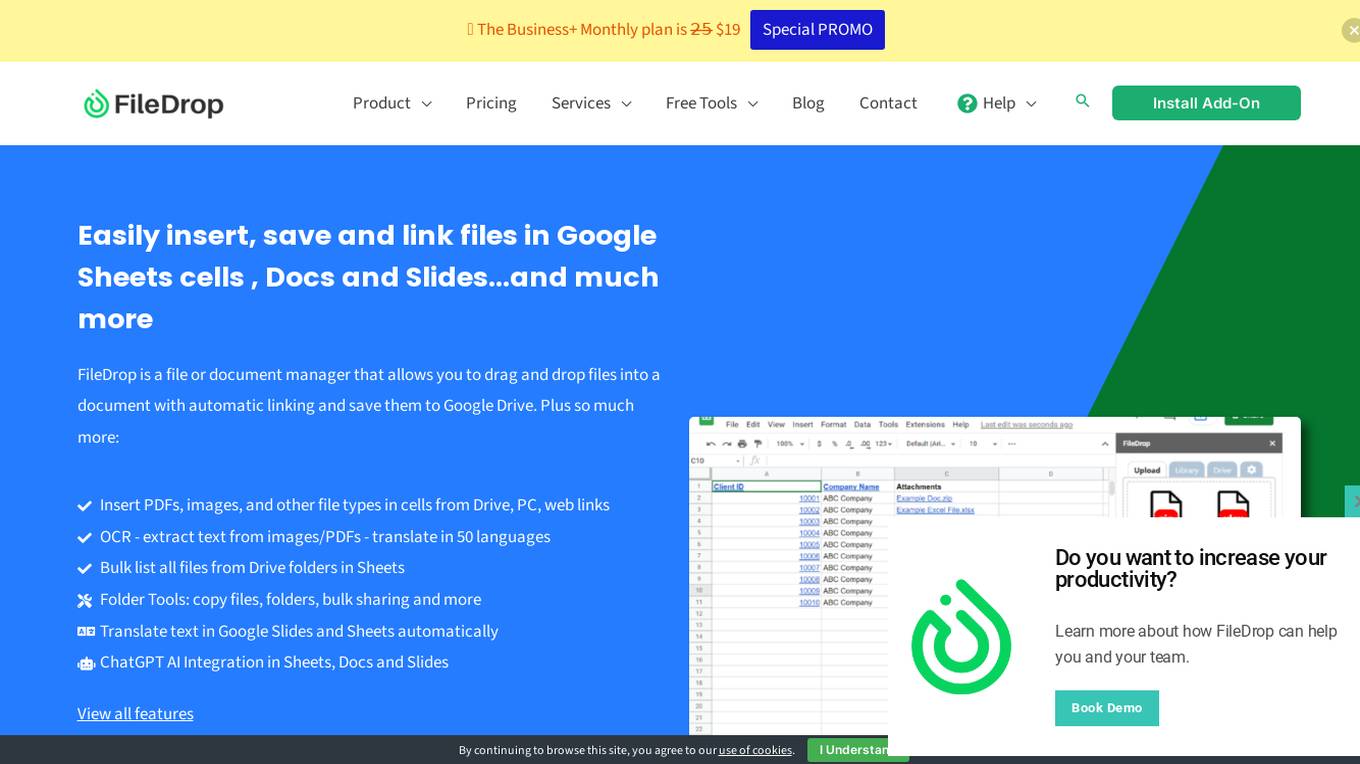
FileDrop
FileDrop is a file or document manager that allows you to drag and drop files into a document with automatic linking and save them to Google Drive. It also offers features like OCR, translation, and AI integration. With FileDrop, you can easily insert, save, and link files in Google Sheets cells, Docs, and Slides.
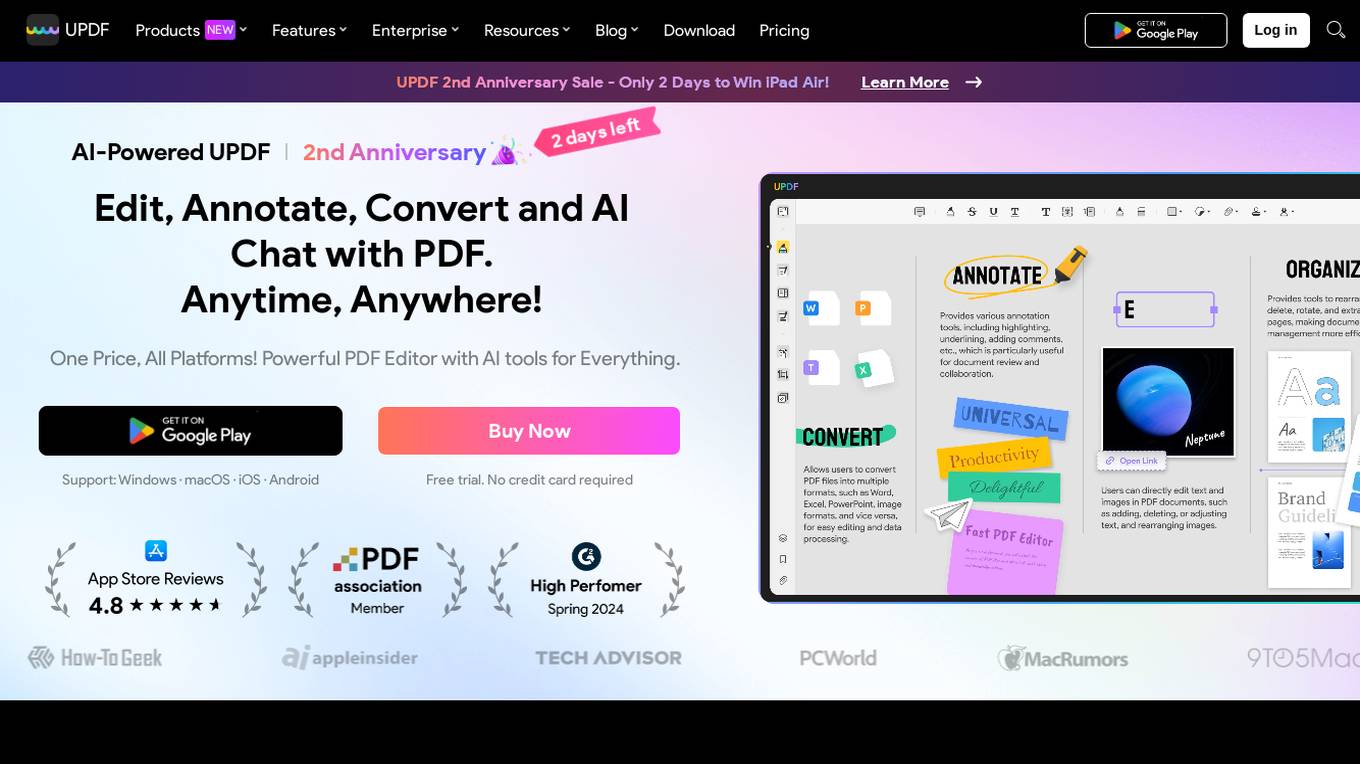
UPDF
UPDF is an AI-integrated PDF editor, converter, annotator, and reader that offers a comprehensive set of features for seamless PDF editing. It provides cross-platform support on Windows, Mac, iOS, and Android devices. With UPDF AI capabilities, users can summarize, translate, and chat with PDF, making it a versatile tool for various tasks. The application is user-friendly, well-priced, and reliable, catering to both individual and enterprise needs. UPDF also offers localized interface in 11 languages and responsive customer support.
VoiceGPT
VoiceGPT is an Android app that provides a voice-based interface to interact with AI language models like ChatGPT, Bing AI, and Bard. It offers features such as unlimited free messages, voice input and output in 67+ languages, a floating bubble for easy switching between apps, OCR text recognition, code execution, image generation with DALL-E 2, and support for ChatGPT Plus accounts. VoiceGPT is designed to be accessible for users with visual impairments, dyslexia, or other conditions, and it can be set as the default assistant to be activated hands-free with a custom hotword.
Pen2txt
Pen2txt is an AI-powered tool that converts handwritten notes and sketches into digital text and images. It uses advanced image recognition and natural language processing to accurately transcribe handwriting, making it easy to digitize and share your notes. Pen2txt is designed to be user-friendly and accessible, with a simple interface and a variety of features to help you get the most out of your notes.
LightPDF
LightPDF is an AI-powered, free online PDF editor, converter, and reader. It offers a wide range of PDF tools, including the ability to convert PDFs to and from other formats, edit PDFs, add watermarks, split and merge PDFs, rotate PDFs, annotate PDFs, optimize PDFs, compress PDFs, perform OCR on PDFs, and protect PDFs. LightPDF also offers a variety of AI-powered features, such as an AI chatbot that can answer questions about documents and an AI-powered OCR engine that can convert scanned PDFs and images to text.
GoPDF
GoPDF is a free online PDF editor and AI-powered PDF management tool that allows users to create, manage, convert, eSign, and edit PDF documents from anywhere in the world. It offers a wide range of features including PDF editing, PDF to JPG conversion, PDF to Word conversion, PDF compression, PDF merging, PDF protection, PDF filling and signing, PDF search and replace, PDF cropping, and OCR PDF. GoPDF is designed to simplify PDF management and make it easy for users to work with PDF documents.
Scanner Go
Scanner Go is a free PDF tool that offers easy-to-use scanning and conversion features. Users can quickly scan various types of documents, images, and books, and convert them to PDF format. The tool provides high-quality scans even in low light conditions and offers powerful OCR technology to extract text from PDFs and images. Additionally, users can save their documents to the cloud for easy access on any device. Scanner Go also includes tools for managing, editing, printing, and sharing documents, making it a versatile productivity tool for everyday use.
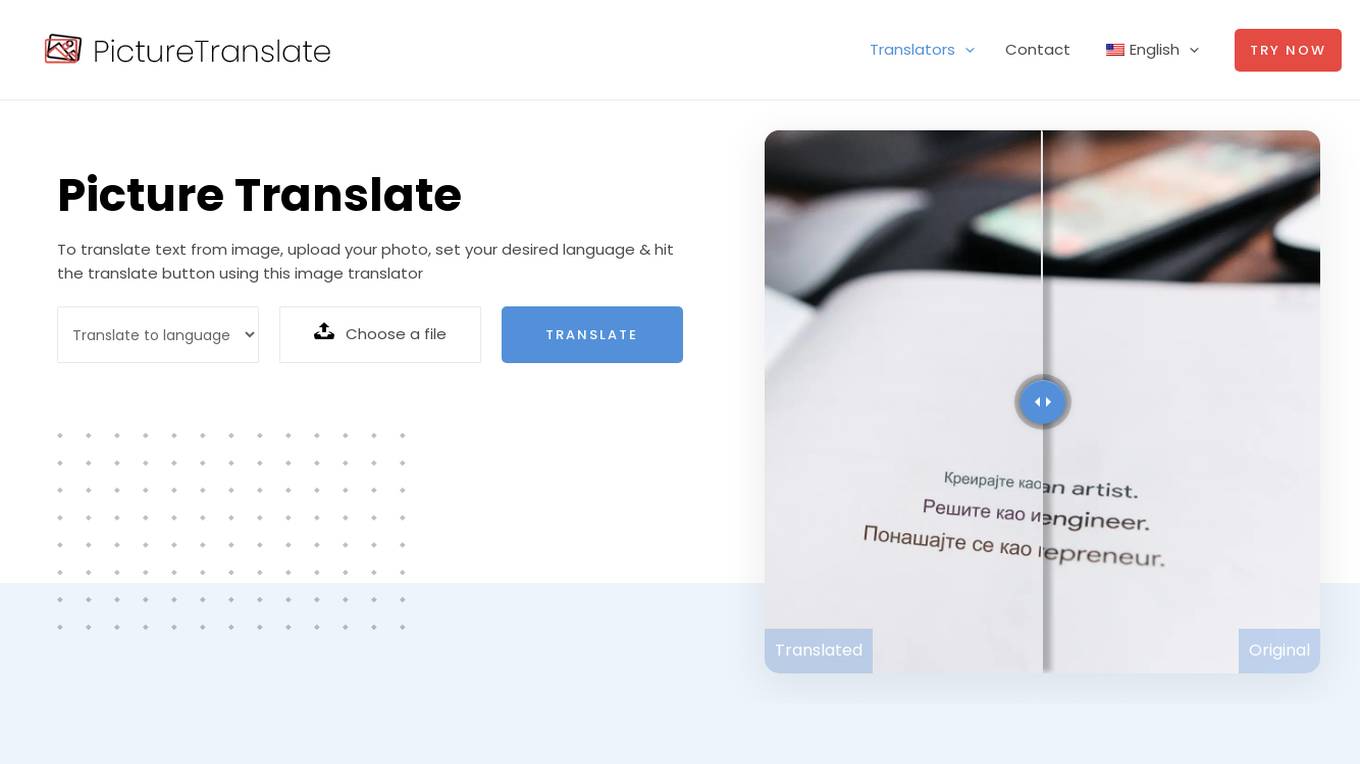
Picture Translate
Picture Translate is an online tool that allows users to translate text from images for free. It leverages advanced Optical Character Recognition (OCR) technology to accurately identify and translate text from images, including low-resolution images and handwritten notes. The tool supports multilingual translation, real-time results, and cross-platform compatibility, making it ideal for various applications such as travel, education, business, healthcare, and more. Picture Translate aims to break down language barriers and provide a user-friendly experience for seamless image translation.
20 - Open Source Tools
llm-document-ocr
LLM Document OCR is a Node.js tool that utilizes GPT4 and Claude3 for OCR and data extraction. It converts PDFs into PNGs, crops white-space, cleans up JSON strings, and supports various image formats. Users can customize prompts for data extraction. The tool is sponsored by Mercoa, offering API for BillPay and Invoicing.

Open-DocLLM
Open-DocLLM is an open-source project that addresses data extraction and processing challenges using OCR and LLM technologies. It consists of two main layers: OCR for reading document content and LLM for extracting specific content in a structured manner. The project offers a larger context window size compared to JP Morgan's DocLLM and integrates tools like Tesseract OCR and Mistral for efficient data analysis. Users can run the models on-premises using LLM studio or Ollama, and the project includes a FastAPI app for testing purposes.
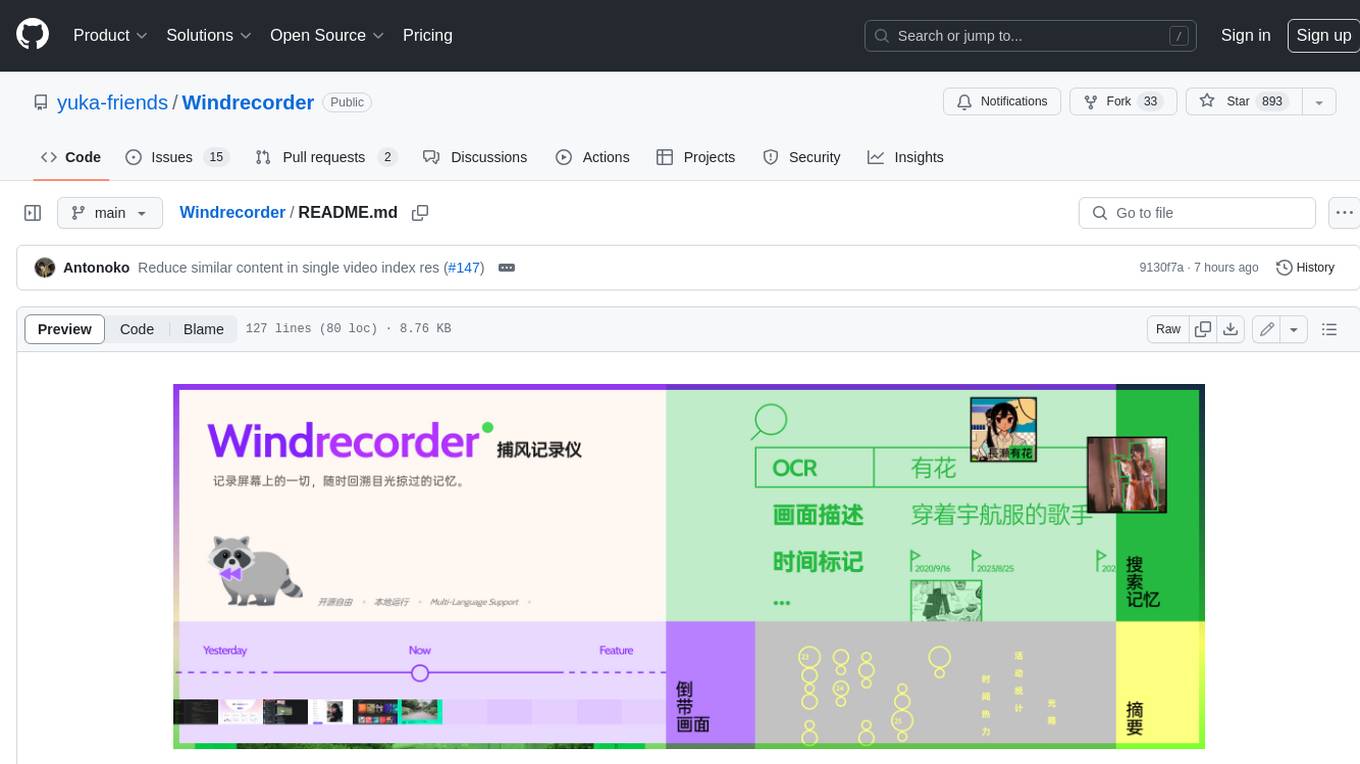
Windrecorder
Windrecorder is an open-source tool that helps you retrieve memory cues by recording everything on your screen. It can search based on OCR text or image descriptions and provides a summary of your activities. All of its capabilities run entirely locally, without the need for an internet connection or uploading any data, giving you complete ownership of your data.
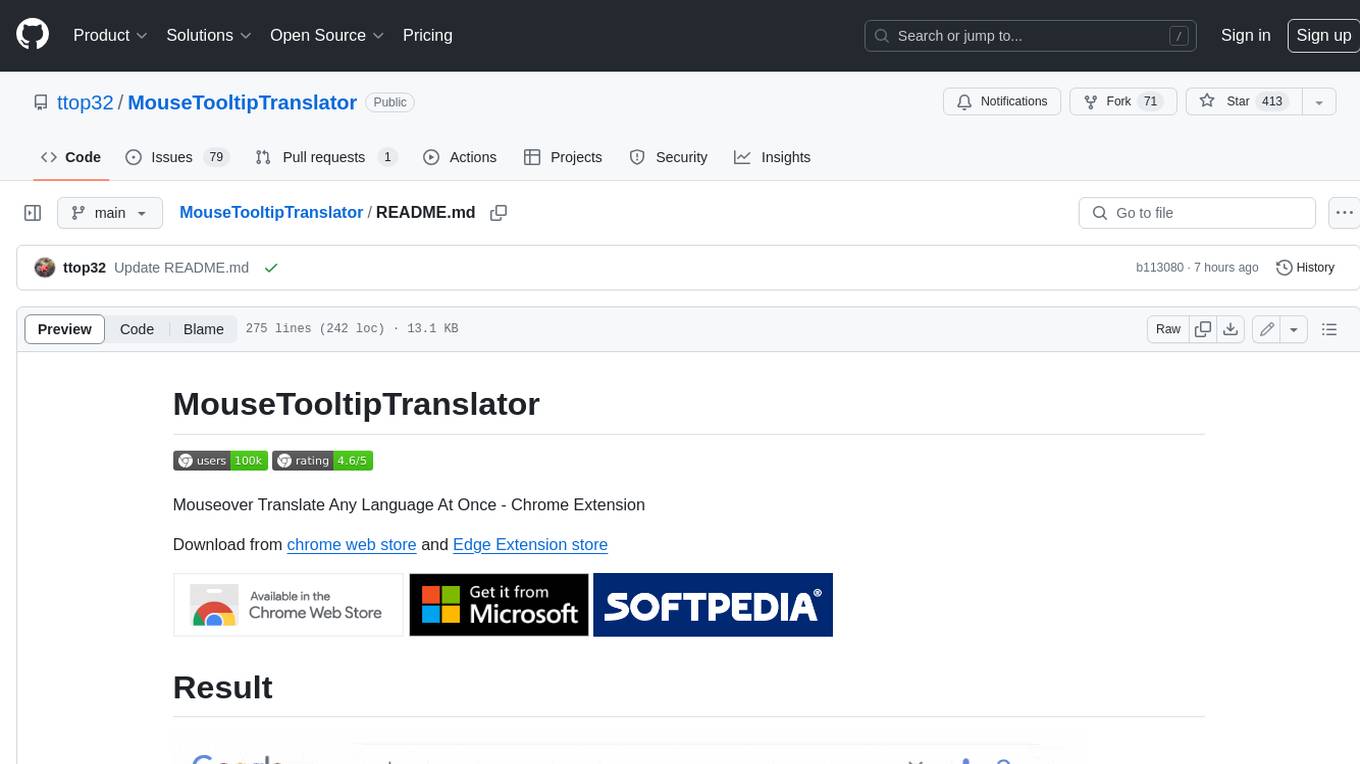
MouseTooltipTranslator
MouseTooltipTranslator is a Chrome extension that allows users to translate any text on a webpage by simply hovering over it. It supports both Google Translate and Bing Translate, and can also be used to listen to the pronunciation of words and phrases. Additionally, the extension can be used to translate text in input boxes and highlighted text, and to display translated tooltips for PDFs and YouTube videos. It also supports OCR, allowing users to translate text in images by holding down the left shift key and hovering over the image.
ddddocr
ddddocr is a Rust version of a simple OCR API server that provides easy deployment for captcha recognition without relying on the OpenCV library. It offers a user-friendly general-purpose captcha recognition Rust library. The tool supports recognizing various types of captchas, including single-line text, transparent black PNG images, target detection, and slider matching algorithms. Users can also import custom OCR training models and utilize the OCR API server for flexible OCR result control and range limitation. The tool is cross-platform and can be easily deployed.

PanelCleaner
Panel Cleaner is a tool that uses machine learning to find text in images and generate masks to cover it up with high accuracy. It is designed to clean text bubbles without leaving artifacts, avoiding painting over non-text parts, and inpainting bubbles that can't be masked out. The tool offers various customization options, detailed analytics on the cleaning process, supports batch processing, and can run OCR on pages. It supports CUDA acceleration, multiple themes, and can handle bubbles on any solid grayscale background color. Panel Cleaner is aimed at saving time for cleaners by automating monotonous work and providing precise cleaning of text bubbles.

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.

deepdoctection
**deep** doctection is a Python library that orchestrates document extraction and document layout analysis tasks using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models. For more specific text processing tasks use one of the many other great NLP libraries. **deep** doctection focuses on applications and is made for those who want to solve real world problems related to document extraction from PDFs or scans in various image formats. **deep** doctection provides model wrappers of supported libraries for various tasks to be integrated into pipelines. Its core function does not depend on any specific deep learning library. Selected models for the following tasks are currently supported: * Document layout analysis including table recognition in Tensorflow with **Tensorpack**, or PyTorch with **Detectron2**, * OCR with support of **Tesseract**, **DocTr** (Tensorflow and PyTorch implementations available) and a wrapper to an API for a commercial solution, * Text mining for native PDFs with **pdfplumber**, * Language detection with **fastText**, * Deskewing and rotating images with **jdeskew**. * Document and token classification with all LayoutLM models provided by the **Transformer library**. (Yes, you can use any LayoutLM-model with any of the provided OCR-or pdfplumber tools straight away!). * Table detection and table structure recognition with **table-transformer**. * There is a small dataset for token classification available and a lot of new tutorials to show, how to train and evaluate this dataset using LayoutLMv1, LayoutLMv2, LayoutXLM and LayoutLMv3. * Comprehensive configuration of **analyzer** like choosing different models, output parsing, OCR selection. Check this notebook or the docs for more infos. * Document layout analysis and table recognition now runs with **Torchscript** (CPU) as well and **Detectron2** is not required anymore for basic inference. * [**new**] More angle predictors for determining the rotation of a document based on **Tesseract** and **DocTr** (not contained in the built-in Analyzer). * [**new**] Token classification with **LiLT** via **transformers**. We have added a model wrapper for token classification with LiLT and added a some LiLT models to the model catalog that seem to look promising, especially if you want to train a model on non-english data. The training script for LayoutLM can be used for LiLT as well and we will be providing a notebook on how to train a model on a custom dataset soon. **deep** doctection provides on top of that methods for pre-processing inputs to models like cropping or resizing and to post-process results, like validating duplicate outputs, relating words to detected layout segments or ordering words into contiguous text. You will get an output in JSON format that you can customize even further by yourself. Have a look at the **introduction notebook** in the notebook repo for an easy start. Check the **release notes** for recent updates. **deep** doctection or its support libraries provide pre-trained models that are in most of the cases available at the **Hugging Face Model Hub** or that will be automatically downloaded once requested. For instance, you can find pre-trained object detection models from the Tensorpack or Detectron2 framework for coarse layout analysis, table cell detection and table recognition. Training is a substantial part to get pipelines ready on some specific domain, let it be document layout analysis, document classification or NER. **deep** doctection provides training scripts for models that are based on trainers developed from the library that hosts the model code. Moreover, **deep** doctection hosts code to some well established datasets like **Publaynet** that makes it easy to experiment. It also contains mappings from widely used data formats like COCO and it has a dataset framework (akin to **datasets** so that setting up training on a custom dataset becomes very easy. **This notebook** shows you how to do this. **deep** doctection comes equipped with a framework that allows you to evaluate predictions of a single or multiple models in a pipeline against some ground truth. Check again **here** how it is done. Having set up a pipeline it takes you a few lines of code to instantiate the pipeline and after a for loop all pages will be processed through the pipeline.

sparrow
Sparrow is an innovative open-source solution for efficient data extraction and processing from various documents and images. It seamlessly handles forms, invoices, receipts, and other unstructured data sources. Sparrow stands out with its modular architecture, offering independent services and pipelines all optimized for robust performance. One of the critical functionalities of Sparrow - pluggable architecture. You can easily integrate and run data extraction pipelines using tools and frameworks like LlamaIndex, Haystack, or Unstructured. Sparrow enables local LLM data extraction pipelines through Ollama or Apple MLX. With Sparrow solution you get API, which helps to process and transform your data into structured output, ready to be integrated with custom workflows. Sparrow Agents - with Sparrow you can build independent LLM agents, and use API to invoke them from your system. **List of available agents:** * **llamaindex** - RAG pipeline with LlamaIndex for PDF processing * **vllamaindex** - RAG pipeline with LLamaIndex multimodal for image processing * **vprocessor** - RAG pipeline with OCR and LlamaIndex for image processing * **haystack** - RAG pipeline with Haystack for PDF processing * **fcall** - Function call pipeline * **unstructured-light** - RAG pipeline with Unstructured and LangChain, supports PDF and image processing * **unstructured** - RAG pipeline with Weaviate vector DB query, Unstructured and LangChain, supports PDF and image processing * **instructor** - RAG pipeline with Unstructured and Instructor libraries, supports PDF and image processing. Works great for JSON response generation
lowcode-vscode
This repository is a low-code tool that supports ChatGPT and other LLM models. It provides functionalities such as OCR translation, generating specified format JSON, translating Chinese to camel case, translating current directory to English, and quickly creating code templates. Users can also generate CURD operations for managing backend list pages. The tool allows users to select templates, initialize query form configurations using OCR, initialize table configurations using OCR, translate Chinese fields using ChatGPT, and generate code without writing a single line. It aims to enhance productivity by simplifying code generation and development processes.
ExtractThinker
ExtractThinker is a library designed for extracting data from files and documents using Language Model Models (LLMs). It offers ORM-style interaction between files and LLMs, supporting multiple document loaders such as Tesseract OCR, Azure Form Recognizer, AWS TextExtract, and Google Document AI. Users can customize extraction using contract definitions, process documents asynchronously, handle various document formats efficiently, and split and process documents. The project is inspired by the LangChain ecosystem and focuses on Intelligent Document Processing (IDP) using LLMs to achieve high accuracy in document extraction tasks.

MiniCPM-V
MiniCPM-V is a series of end-side multimodal LLMs designed for vision-language understanding. The models take image and text inputs to provide high-quality text outputs. The series includes models like MiniCPM-Llama3-V 2.5 with 8B parameters surpassing proprietary models, and MiniCPM-V 2.0, a lighter model with 2B parameters. The models support over 30 languages, efficient deployment on end-side devices, and have strong OCR capabilities. They achieve state-of-the-art performance on various benchmarks and prevent hallucinations in text generation. The models can process high-resolution images efficiently and support multilingual capabilities.

CLIPPyX
CLIPPyX is a powerful system-wide image search and management tool that offers versatile search options to find images based on their content, text, and visual similarity. With advanced features, users can effortlessly locate desired images across their entire computer's disk(s), regardless of their location or file names. The tool utilizes OpenAI's CLIP for image embeddings and text-based search, along with OCR for extracting text from images. It also employs Voidtools Everything SDK to list paths of all images on the system. CLIPPyX server receives search queries and queries collections of image embeddings and text embeddings to return relevant images.
AutoNode
AutoNode is a self-operating computer system designed to automate web interactions and data extraction processes. It leverages advanced technologies like OCR (Optical Character Recognition), YOLO (You Only Look Once) models for object detection, and a custom site-graph to navigate and interact with web pages programmatically. Users can define objectives, create site-graphs, and utilize AutoNode via API to automate tasks on websites. The tool also supports training custom YOLO models for object detection and OCR for text recognition on web pages. AutoNode can be used for tasks such as extracting product details, automating web interactions, and more.
NekoImageGallery
NekoImageGallery is an online AI image search engine that utilizes the Clip model and Qdrant vector database. It supports keyword search and similar image search. The tool generates 768-dimensional vectors for each image using the Clip model, supports OCR text search using PaddleOCR, and efficiently searches vectors using the Qdrant vector database. Users can deploy the tool locally or via Docker, with options for metadata storage using Qdrant database or local file storage. The tool provides API documentation through FastAPI's built-in Swagger UI and can be used for tasks like image search, text extraction, and vector search.
Awesome-AITools
This repo collects AI-related utilities. ## All Categories * All Categories * ChatGPT and other closed-source LLMs * AI Search engine * Open Source LLMs * GPT/LLMs Applications * LLM training platform * Applications that integrate multiple LLMs * AI Agent * Writing * Programming Development * Translation * AI Conversation or AI Voice Conversation * Image Creation * Speech Recognition * Text To Speech * Voice Processing * AI generated music or sound effects * Speech translation * Video Creation * Video Content Summary * OCR(Optical Character Recognition)
terraform-genai-doc-summarization
This solution showcases how to summarize a large corpus of documents using Generative AI. It provides an end-to-end demonstration of document summarization going all the way from raw documents, detecting text in the documents and summarizing the documents on-demand using Vertex AI LLM APIs, Cloud Vision Optical Character Recognition (OCR) and BigQuery.

document-ai-samples
The Google Cloud Document AI Samples repository contains code samples and Community Samples demonstrating how to analyze, classify, and search documents using Google Cloud Document AI. It includes various projects showcasing different functionalities such as integrating with Google Drive, processing documents using Python, content moderation with Dialogflow CX, fraud detection, language extraction, paper summarization, tax processing pipeline, and more. The repository also provides access to test document files stored in a publicly-accessible Google Cloud Storage Bucket. Additionally, there are codelabs available for optical character recognition (OCR), form parsing, specialized processors, and managing Document AI processors. Community samples, like the PDF Annotator Sample, are also included. Contributions are welcome, and users can seek help or report issues through the repository's issues page. Please note that this repository is not an officially supported Google product and is intended for demonstrative purposes only.
AIBotPublic
AIBotPublic is an open-source version of AIBotPro, a comprehensive AI tool that provides various features such as knowledge base construction, AI drawing, API hosting, and more. It supports custom plugins and parallel processing of multiple files. The tool is built using bootstrap4 for the frontend, .NET6.0 for the backend, and utilizes technologies like SqlServer, Redis, and Milvus for database and vector database functionalities. It integrates third-party dependencies like Baidu AI OCR, Milvus C# SDK, Google Search, and more to enhance its capabilities.
SimpleAICV_pytorch_training_examples
SimpleAICV_pytorch_training_examples is a repository that provides simple training and testing examples for various computer vision tasks such as image classification, object detection, semantic segmentation, instance segmentation, knowledge distillation, contrastive learning, masked image modeling, OCR text detection, OCR text recognition, human matting, salient object detection, interactive segmentation, image inpainting, and diffusion model tasks. The repository includes support for multiple datasets and networks, along with instructions on how to prepare datasets, train and test models, and use gradio demos. It also offers pretrained models and experiment records for download from huggingface or Baidu-Netdisk. The repository requires specific environments and package installations to run effectively.
17 - OpenAI Gpts
Journal Recognizer OCR
Optimized OCR for Handwritten Notebooks, up to 10 image transcript copy w/1-click. No text prompt necessary. Reads journals, reports, notes. All handwriting transcribed verbatim, then text summarized, graphic image features described. Ask to change any behavior.

kz image 2 typescript 2 image
Generate a Structured description in typescript format from the image and generate an image from that description. and OCR

Photo of a business card 2 Contacts
Wizard to business card photos to CSV files for Google Contacts.
Lector de recetas médicas
Ayuda a descifrar la indescifrable caligrafía de las recetas de los médicos

DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages