AI tools for letter
Related Jobs:
Related Tools:
Letter AI
Letter AI is a revenue acceleration platform powered by Generative AI, designed to empower sales teams to find information faster and support revenue growth. The platform offers AI-powered training and coaching, content creation and management, real-time assistance from an AI co-pilot, and tools for deal pursuit automation. Letter AI combines generative AI technology with company-specific data to deliver a unified revenue enablement platform, enhancing user experience and driving cost savings. The platform ensures security and privacy by adhering to industry-leading standards and responsible data practices.
Lettergram
Lettergram is a platform that allows users to send and receive engaging personalized letters to their physical address. Users can have a pen pal experience by receiving a letter and sending a written response in the return envelope. The platform aims to bring back the charm of traditional letter writing in a modern and convenient way.
Letterfy
Letterfy is an AI-powered cover letter generator that helps job seekers create high-quality cover letters quickly and easily. With Letterfy, you can generate a professional cover letter in minutes, tailored to the specific job you're applying for. Letterfy's AI technology analyzes your resume and LinkedIn profile to identify your skills and experience, and then generates a cover letter that highlights your most relevant qualifications. You can also customize your cover letter with your own personal touch, and download it in PDF format.
Letterdrop
Letterdrop is an AI-powered application designed to help businesses attract warm leads and increase their pipeline. It offers features such as uncovering contact-level leads, creating thought leadership content, and nurturing leads with turn-key content. Letterdrop aims to help users book more meetings, close deals faster, and improve their outbound messaging strategies. The application leverages AI to filter out irrelevant leads, identify warm leads, and provide context on why they were surfaced. With a focus on personalized outreach and nurturing, Letterdrop helps users engage with hot leads effectively.
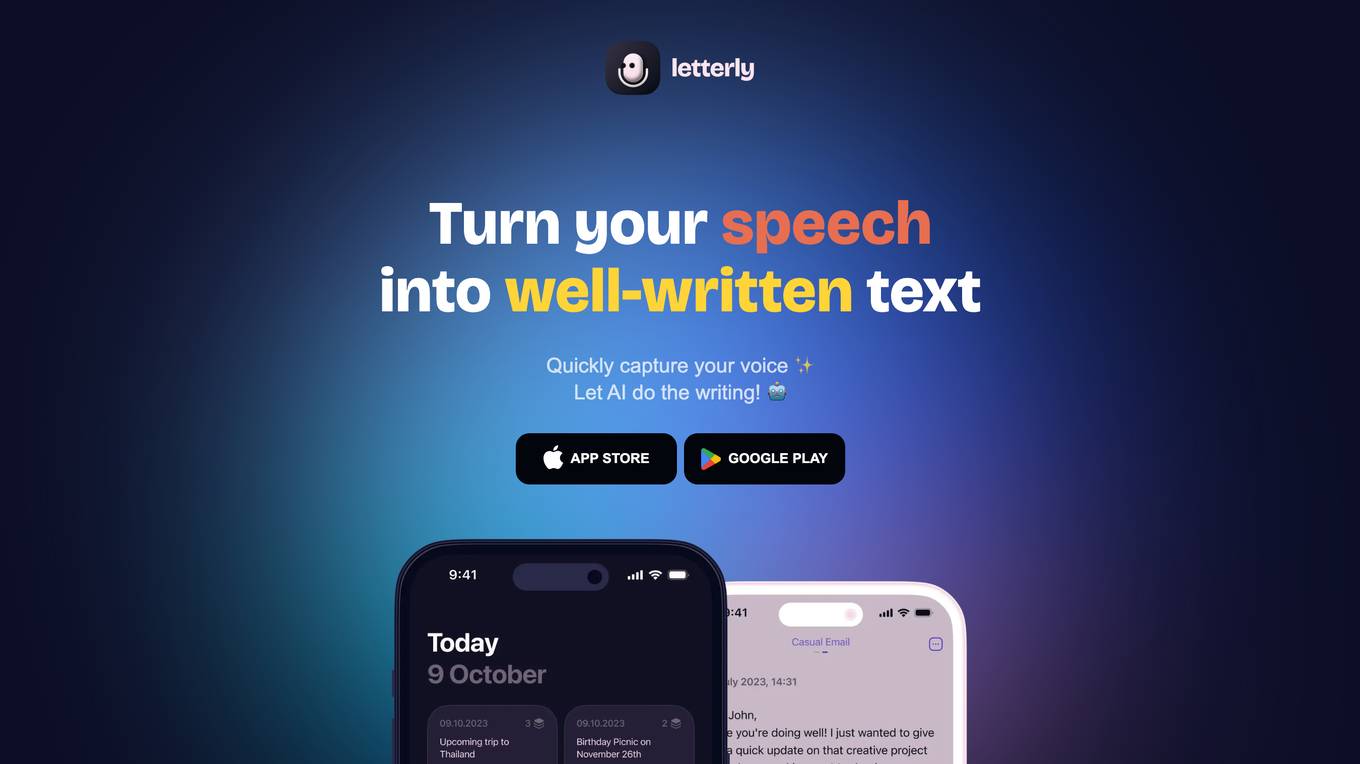
Letterly App
Letterly is an AI speech-to-text mobile app that allows users to quickly capture their voice and have AI convert it into well-crafted text. It offers features such as rewriting options, screen-off recording, multi-language support, and structured text inputs. Users can use Letterly for various tasks like sending clear emails by voice, generating social media posts, and creating to-do lists. The app has received positive reviews for its convenience and accuracy in transcribing voice messages.
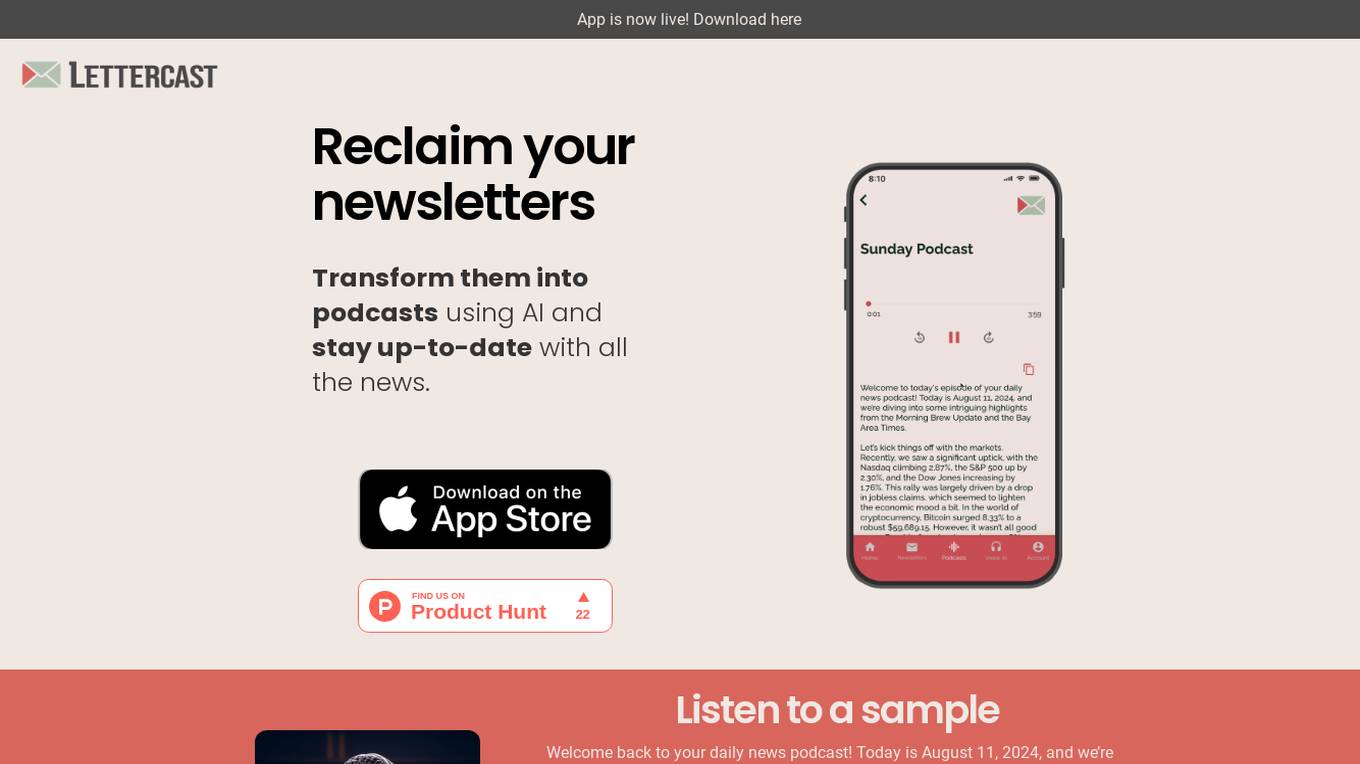
Lettercast
Lettercast is an AI-powered application that transforms your newsletters into personalized audio and text summaries, allowing you to stay up-to-date with all the news on the go. It converts your newsletters into bite-sized podcasts using the latest AI technology, providing a convenient way to consume information while commuting, working out, or cooking. With no limit on the number of newsletters you can convert, Lettercast ensures that you can listen to your daily podcasts at your convenience, all while prioritizing data security and user privacy.
AI Letter Generator
AI Letter Generator is a free online tool that helps users create professional letters easily with the assistance of artificial intelligence. The tool supports multiple letter types such as business letters, cover letters, personal letters, and thank you letters. It ensures privacy and data security, offers multi-language support, professional formatting options, and saves time by automating the letter creation process. Users can enjoy the core features of the AI Letter Generator for free, making it a convenient and efficient solution for letter writing needs.
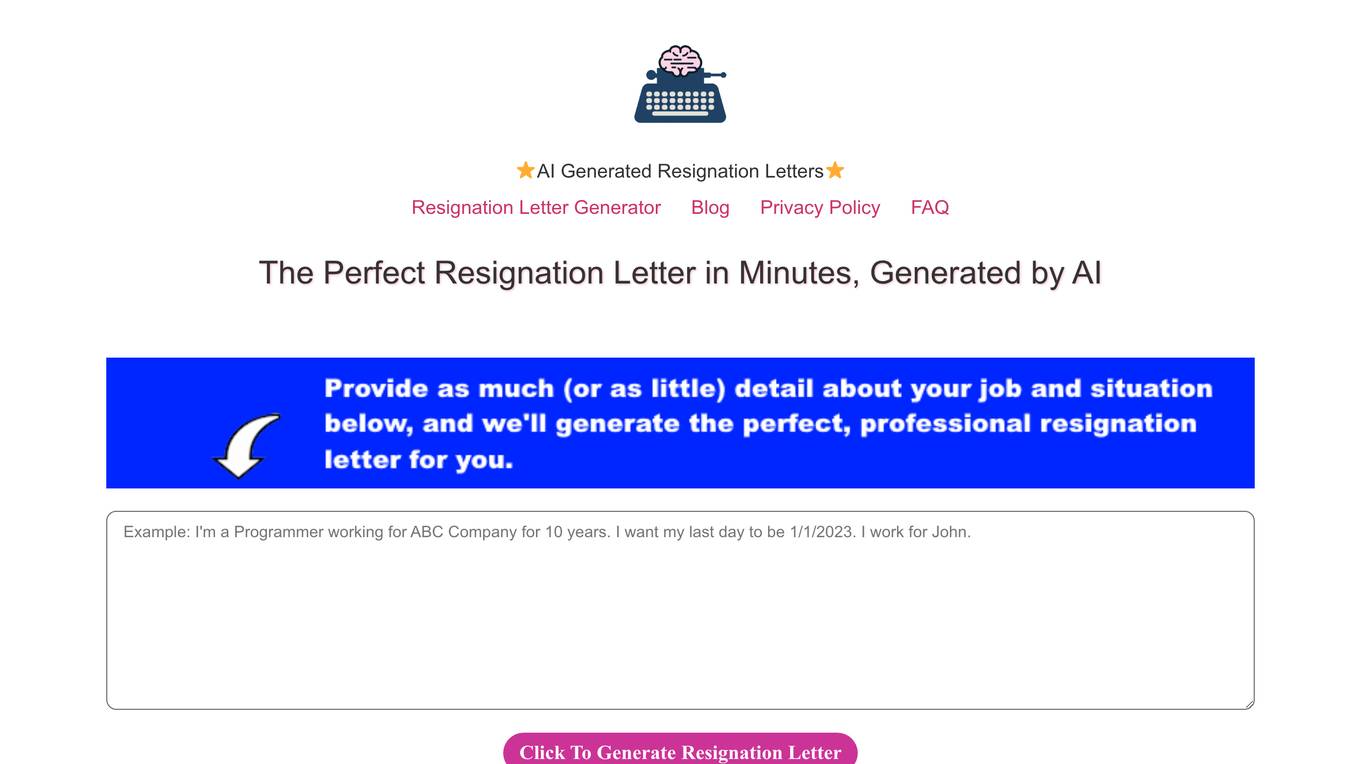
AI Resignation Letter Generator
The website offers an AI-powered Resignation Letter Generator that helps users create professional resignation letters in minutes. Users can input details about their job and circumstances, and the AI tool generates a tailored resignation letter. The platform emphasizes the importance of a well-written resignation letter in maintaining professional relationships, providing clarity, securing positive references, and aiding in a smooth transition. It aims to simplify the process of crafting a resignation letter and save users time and effort.
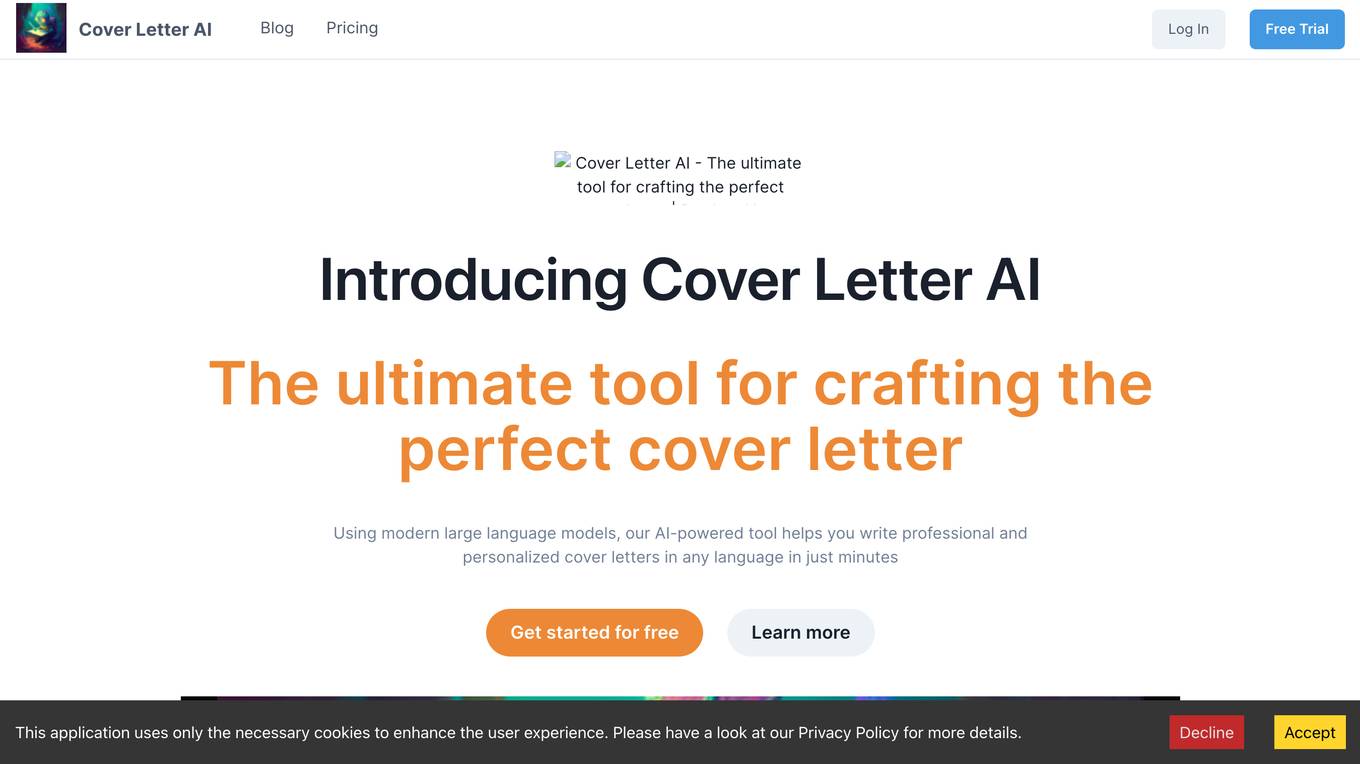
Cover Letter AI
Cover Letter AI is an AI-powered tool that helps job seekers write professional and personalized cover letters in any language in just minutes. The tool uses modern large language models to generate cover letters that are tailored to the specific job and company that the user is applying to. Cover Letter AI is easy to use and requires no prior writing experience. Users simply need to upload their CV and fill out a few basic details about the job they are applying for. Cover Letter AI will then generate multiple versions of the cover letter, which the user can then edit and refine until they are satisfied with the final result.
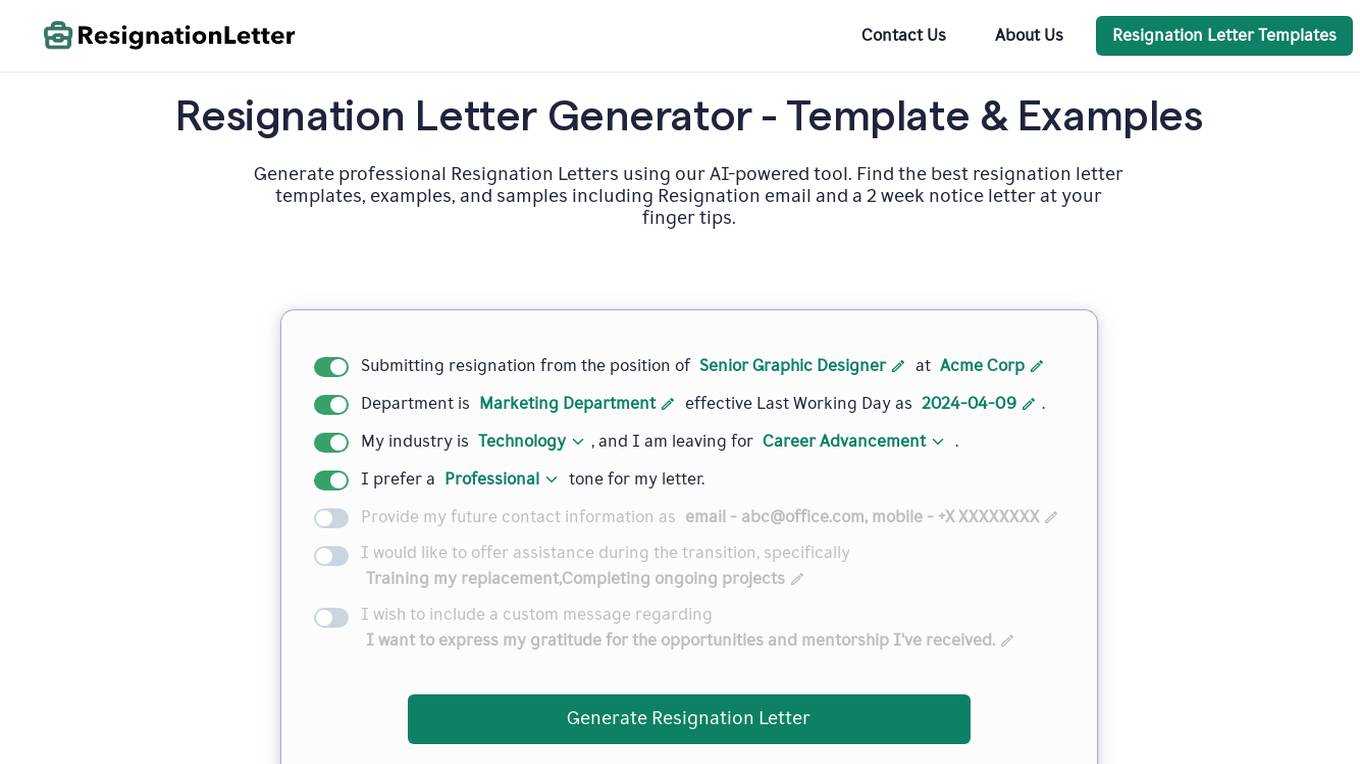
Resignation Letter Generator
This website provides a tool to generate professional resignation letters, including templates, examples, and samples. It also offers guidance on writing a formal and respectable letter of resignation with clear notice, expressing gratitude, offering support for the transition, and closing formally. Additionally, it provides tips on what to include and what not to include in a resignation letter, as well as a collection of resignation letter templates for various scenarios. The website also includes a section on frequently asked questions about resignation letters, covering topics such as whether a reason for resignation is compulsory, whether a resignation letter needs to be signed, who to send it to, whether it's acceptable to resign by email, the best day to resign, the appropriate notice period, and valid reasons for immediate resignation.
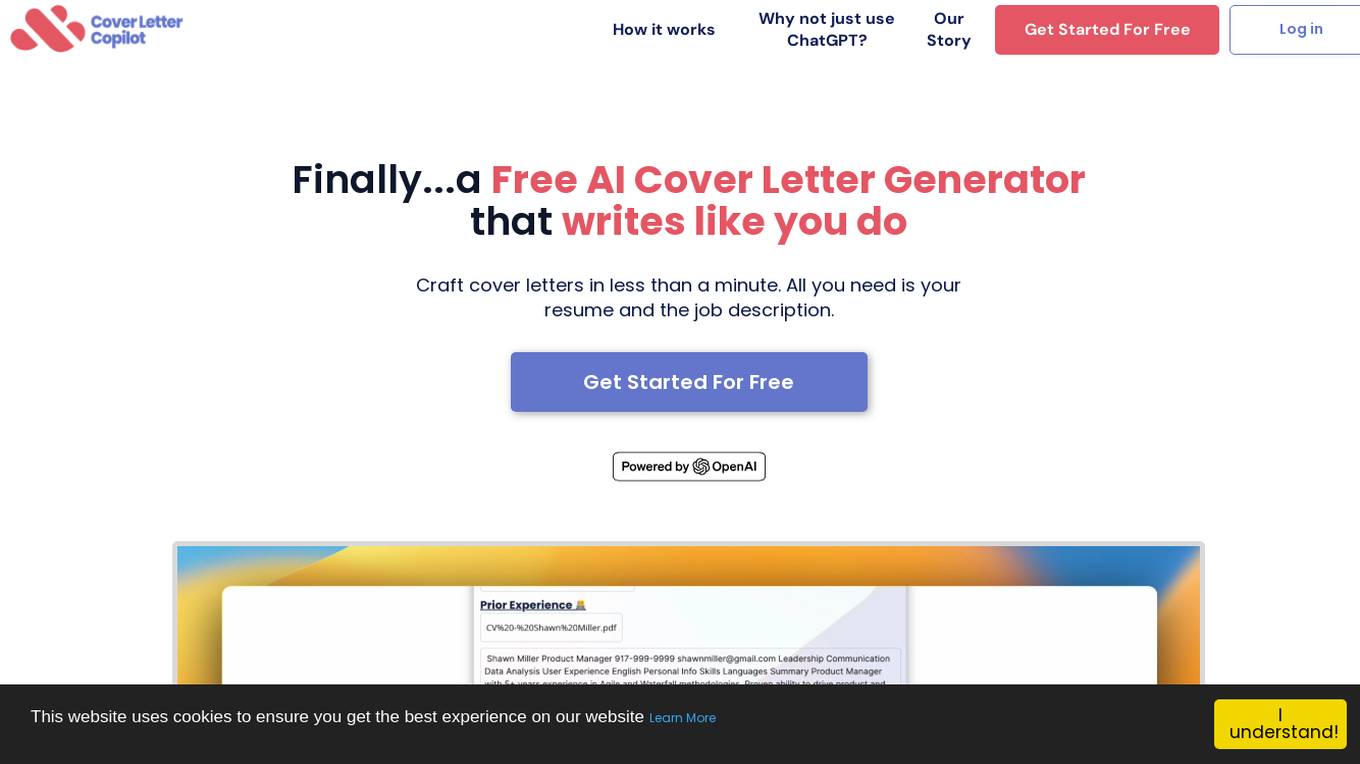
Cover Letter Copilot
Cover Letter Copilot is a free AI tool designed to help users generate professional cover letters effortlessly. The application uses artificial intelligence to analyze user input and create customized cover letters tailored to specific job positions. With a user-friendly interface, Cover Letter Copilot streamlines the process of crafting cover letters, saving users time and effort. Whether you are a job seeker looking to stand out in the application process or a professional seeking to enhance your cover letter writing skills, Cover Letter Copilot provides a convenient solution for creating impactful cover letters.
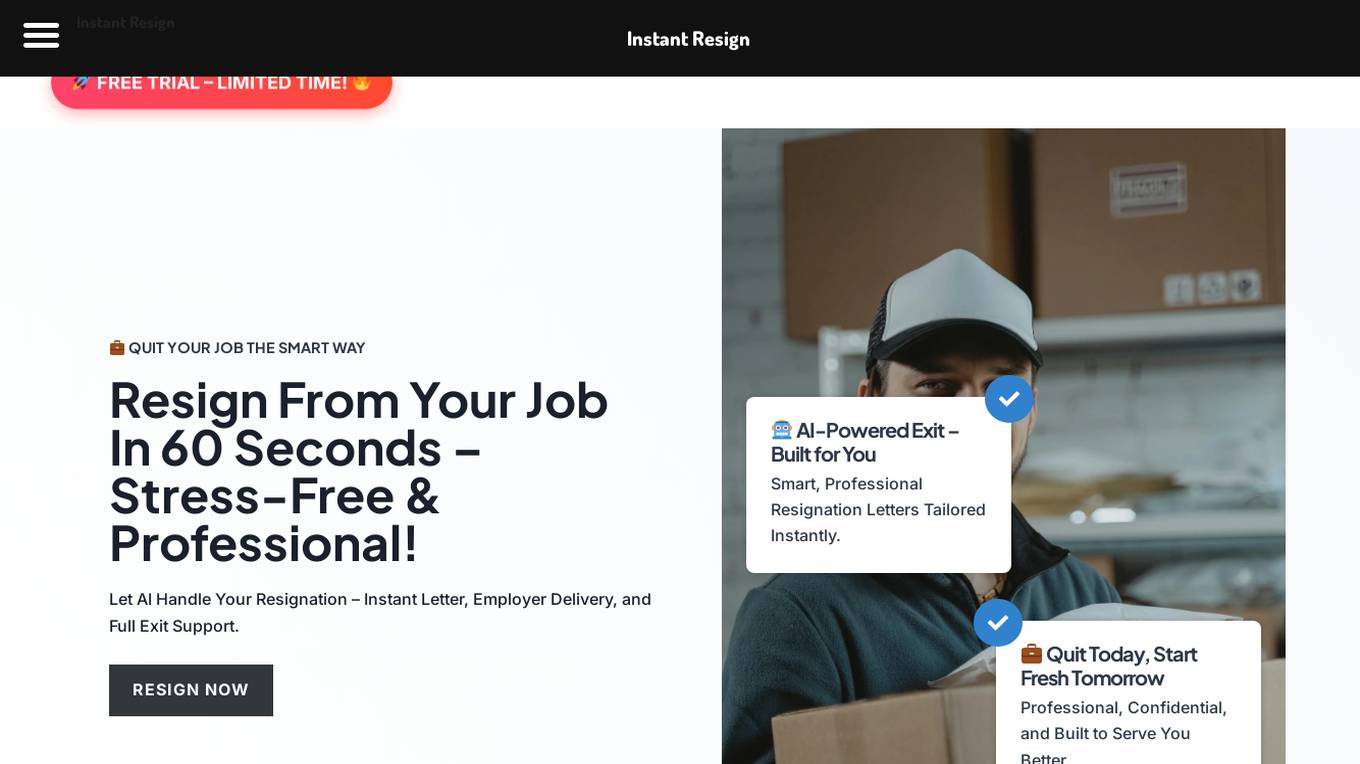
Instant Resign
Instant Resign is an AI-powered application designed to assist individuals in resigning from their jobs quickly and professionally. The platform offers a stress-free process by generating tailored resignation letters instantly and handling the delivery to the employer. With a user-friendly interface, Instant Resign aims to streamline the job resignation process and provide full exit support to users worldwide.

ProPlaintiff.ai
ProPlaintiff.ai is an AI-powered platform designed to assist personal injury law firms in creating demand letters, medical chronologies, summaries, and document reviews efficiently. The platform offers features such as batch analysis of PDFs, video & audio transcription, media analysis, and organizing documents by case. ProPlaintiff.ai aims to save time and enhance productivity for legal professionals by providing accurate and secure AI tools for case preparation and management.
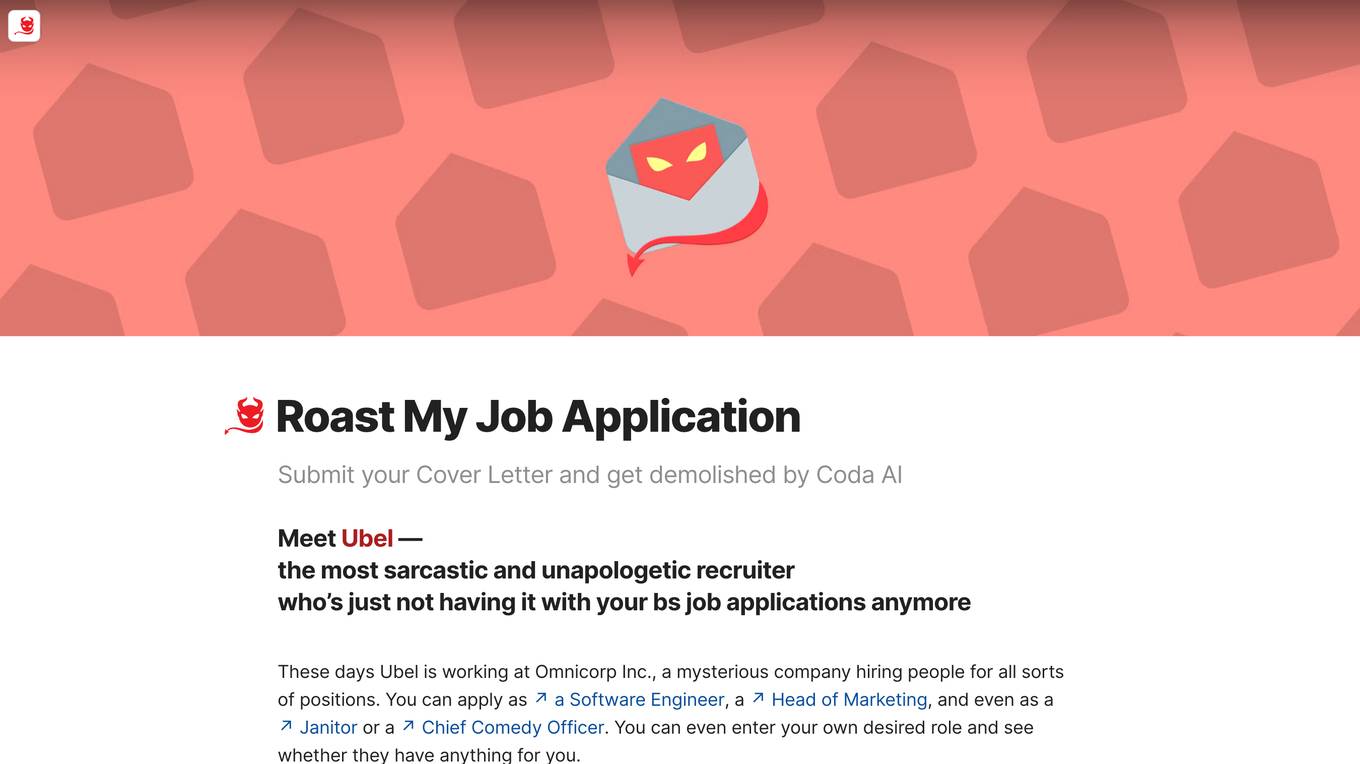
Roast My Job Application
Roast My Job Application is an AI-powered tool designed to provide brutally honest feedback on job applications. Users can submit their cover letters to be reviewed by Coda AI, specifically by Ubel, a sarcastic and unapologetic recruiter. The tool simulates a recruitment process at Omnicorp Inc., a fictional company, offering various positions for applicants to apply. The application is AI-generated and securely stores user data for composing rejection letters.
CovrLtr
CovrLtr is an AI-powered tool designed to help users create tailored cover letters and interview questions and answers for job applications. The platform utilizes the latest AI models to save users time and enhance their job application process. With a focus on customer satisfaction, CovrLtr offers expertise in various areas such as web design, digital marketing, e-commerce, and branding services.
Career Heero
Career Heero is an AI-powered platform designed to boost users' career prospects by offering a range of tools such as AI resume builder, resume summary generator, resume bullet point generator, AI cover letter generator, and AI resume scanner. The platform aims to help users tailor their job applications to stand out among other candidates by providing intelligent suggestions and templates for creating professional resumes and cover letters. Career Heero utilizes modern AI technologies like GPT from OpenAI to assist users in creating tailored resumes and cover letters efficiently.
CoverBot
CoverBot is a web application that utilizes AI technology to generate personalized covering letters for job applications. By extracting relevant information from the user's CV and job description, CoverBot creates unique and compelling cover letters in a matter of seconds. The platform aims to streamline the process of writing cover letters, saving users time and effort while highlighting their skills and experience effectively.
Behired
Behired is an AI-powered job application tool designed to help job seekers create compelling cover letters, tailored resumes, and prepare for interviews. By analyzing job offers and resumes, it generates personalized content and provides job match analysis. The tool aims to save time, increase job search effectiveness, and help users stand out in a competitive job market.
Instawrite
Instawrite is an AI-powered tool that helps job seekers create professional cover letters and resumes in minutes. With Instawrite, you can easily generate tailored cover letters and resumes that highlight your skills and experience, and increase your chances of getting noticed by potential employers.
Santa's Mailroom
I'm Santa and Mrs. Claus, answering kids' Christmas letters with joy and care.
Letter of Recommendation Expert
A counselor aiding in writing recommendation letters for PhD applications, with a formal and informative tone.
Letter Master
Letter Master can assist you in completing a well-written and accurate letter. The default is any language to English. If you need another language, just mark your target language at the end of the letter.

Personalized Cover Letter for Postdocs (Academia)
Writes Personalized Cover Letters for Advertised Positions; For Speculative Inquiries Writes Personalized Letters of Interest
The Scarlet Letter By Nathaniel Hawthorne
The Scarlet Letter: Unveiling Sin and Redemption in Puritan Massachusetts
Million Dollar Sales Letter
Million Dollar Sales Letter is designed to assist users in crafting high-conversion sales letters, offering options to analyze and learn from the 15 examples in Robert Collier's book using modern psychological theories.
Complaint Assistant
Creates conversational, effective complaint letters, offers document formatting.
promptbook
Promptbook is a library designed to build responsible, controlled, and transparent applications on top of large language models (LLMs). It helps users overcome limitations of LLMs like hallucinations, off-topic responses, and poor quality output by offering features such as fine-tuning models, prompt-engineering, and orchestrating multiple prompts in a pipeline. The library separates concerns, establishes a common format for prompt business logic, and handles low-level details like model selection and context size. It also provides tools for pipeline execution, caching, fine-tuning, anomaly detection, and versioning. Promptbook supports advanced techniques like Retrieval-Augmented Generation (RAG) and knowledge utilization to enhance output quality.
airport-codes
A website that tries to make sense of those three-letter airport codes. It provides detailed information about each airport, including its name, location, and a description. The site also includes a search function that allows users to find airports by name, city, or country. Airport content can be found in `/data` in individual files. Use the three-letter airport code as the filename (e.g. `phx.json`). Content in each `json` file: `id` = three-letter code (e.g. phx), `name` = airport name (Sky Harbor International Airport), `city` = primary city name (Phoenix), `state` = state name, if applicable (Arizona), `stateShort` = state abbreviation, if applicable (AZ), `country` = country name (USA), `description` = description, accepts markdown, use * for emphasis on letters, `imageCredit` = name of photographer, `imageCreditLink` = URL of photographer's Flickr page. You can also optionally add for aid in searching: `city2` = another city or country the airport may be known for. Adding a `json` file to `/data` will automatically render it. You do not need to manually add the path anywhere.
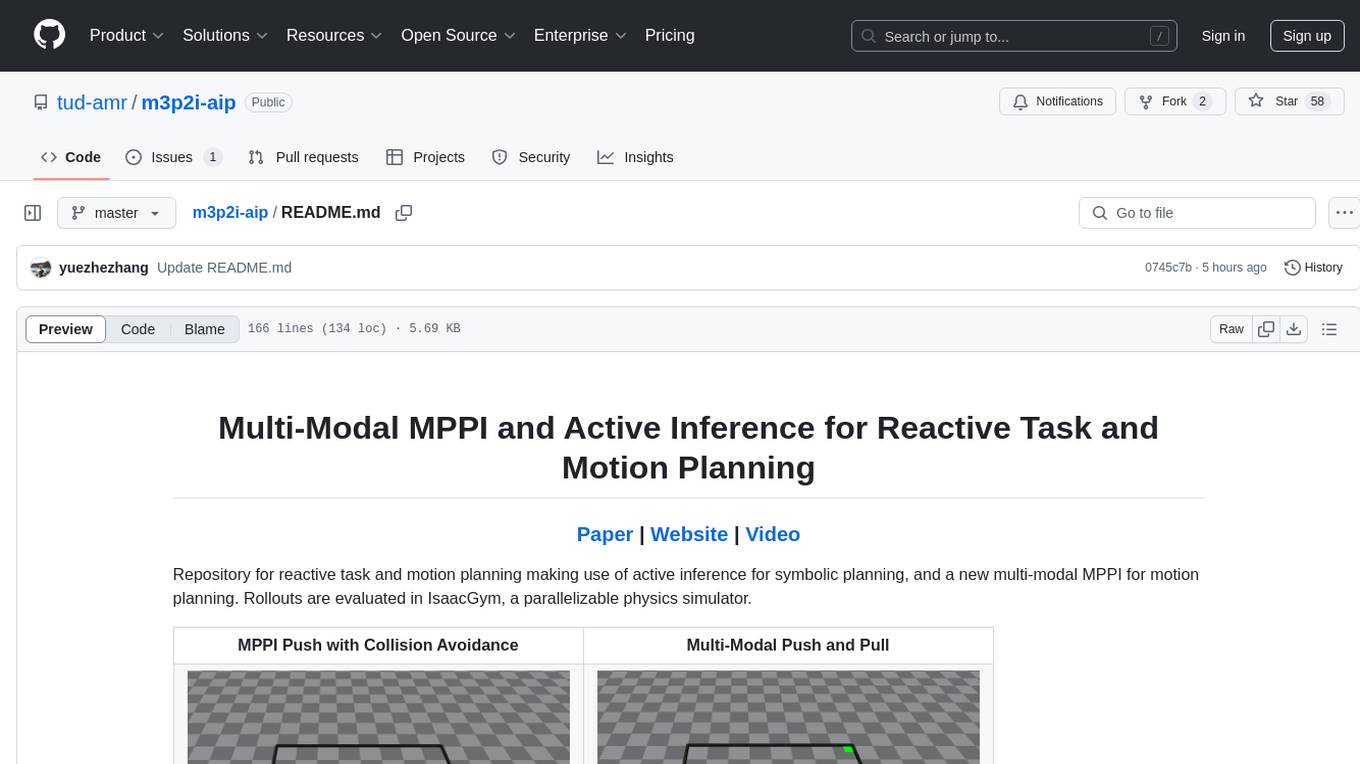
m3p2i-aip
Repository for reactive task and motion planning using active inference for symbolic planning and multi-modal MPPI for motion planning. Rollouts are evaluated in IsaacGym, a parallelizable physics simulator. The tool provides functionalities for push, pull, pick, and multi-modal push-pull tasks with collision avoidance.
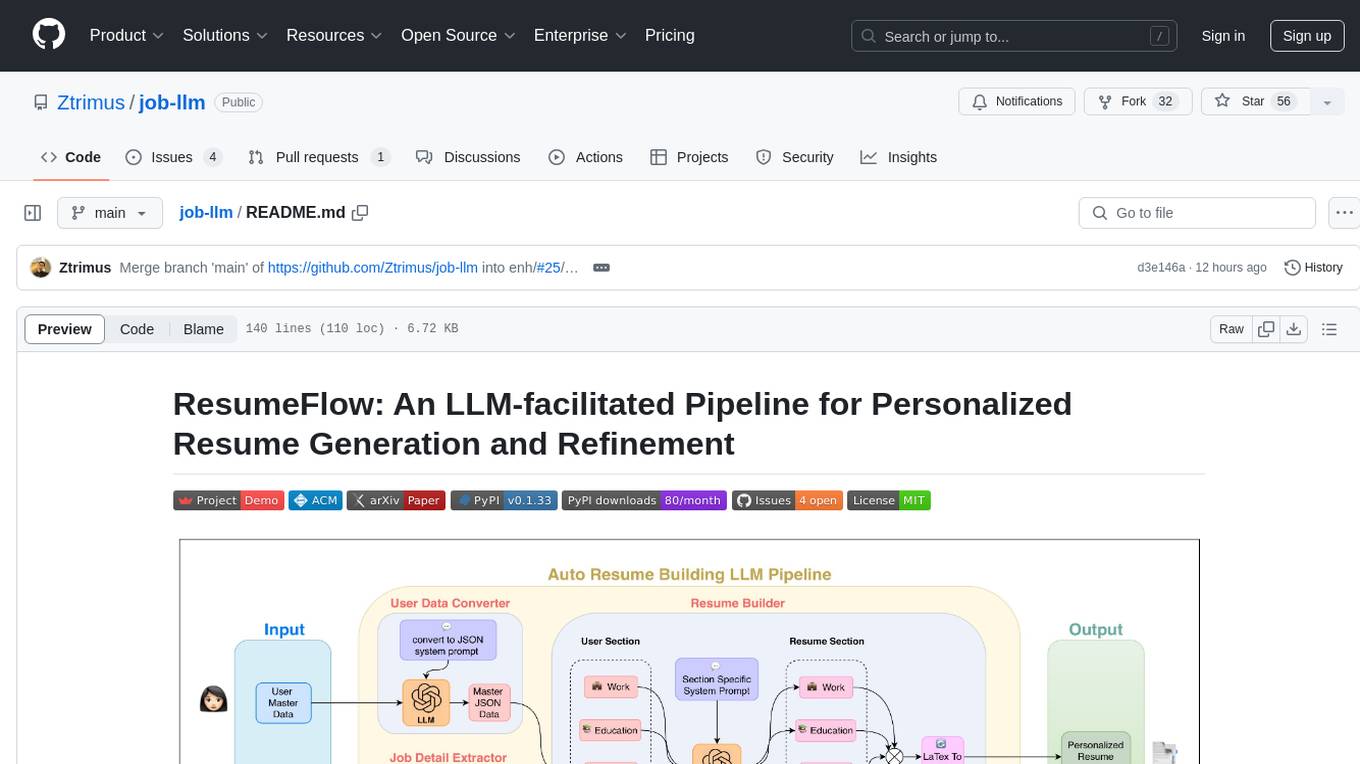
job-llm
ResumeFlow is an automated system utilizing Large Language Models (LLMs) to streamline the job application process. It aims to reduce human effort in various steps of job hunting by integrating LLM technology. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code. The project focuses on leveraging LLMs to automate tasks such as resume generation and refinement, making job applications smoother and more efficient.
geezap
Geezap-Job Aggregator is a Laravel-based application that simplifies the job search process by aggregating job listings from various platforms including LinkedIn, Upwork, Indeed, ZipRecruiter, and more. It not only consolidates job listings but also provides tools for application management, cover letter generation, and email communications. The platform offers features like unified search, real-time job updates, application tracking, customizable cover letter templates, personalized job recommendations, and social media sharing. Users can also receive weekly job digests, push notifications, and email alerts for saved jobs. The application utilizes technologies like Laravel, OpenAI API, MySQL, Livewire, and TailwindCSS.
genaiscript
GenAIScript is a scripting environment designed to facilitate file ingestion, prompt development, and structured data extraction. Users can define metadata and model configurations, specify data sources, and define tasks to extract specific information. The tool provides a convenient way to analyze files and extract desired content in a structured format. It offers a user-friendly interface for working with data and automating data extraction processes, making it suitable for various data processing tasks.
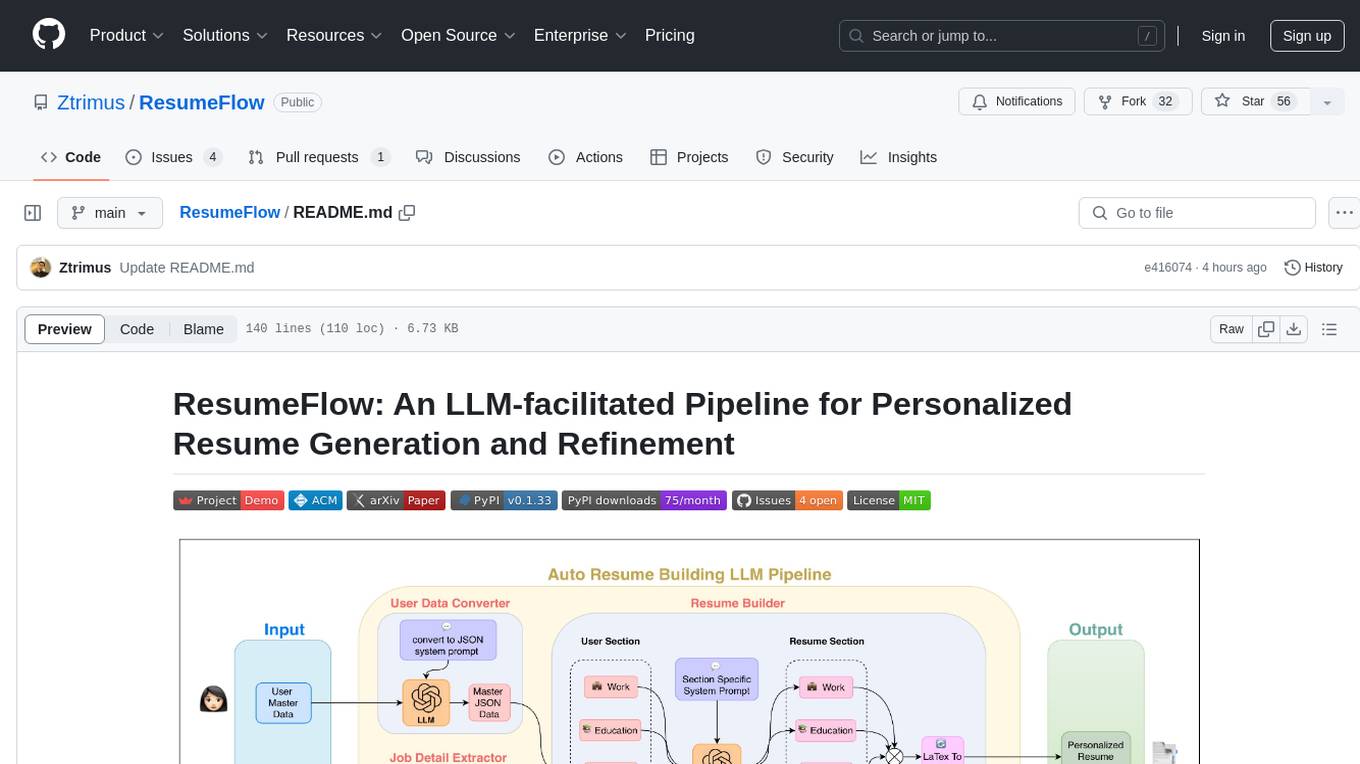
ResumeFlow
ResumeFlow is an automated system that leverages Large Language Models (LLMs) to streamline the job application process. By integrating LLM technology, the tool aims to automate various stages of job hunting, making it easier for users to apply for jobs. Users can access ResumeFlow as a web tool, install it as a Python package, or download the source code from GitHub. The tool requires Python 3.11.6 or above and an LLM API key from OpenAI or Gemini Pro for usage. ResumeFlow offers functionalities such as generating curated resumes and cover letters based on job URLs and user's master resume data.
Airports
Airports is a repository containing an up-to-date CSV dump of the Travelhackingtool.com airport database. It provides basic information about every IATA airport and city code worldwide, including IATA code, ICAO code, timezone, name, city code, country code, URL, elevation, coordinates, and geo-encoded city, county, and state.
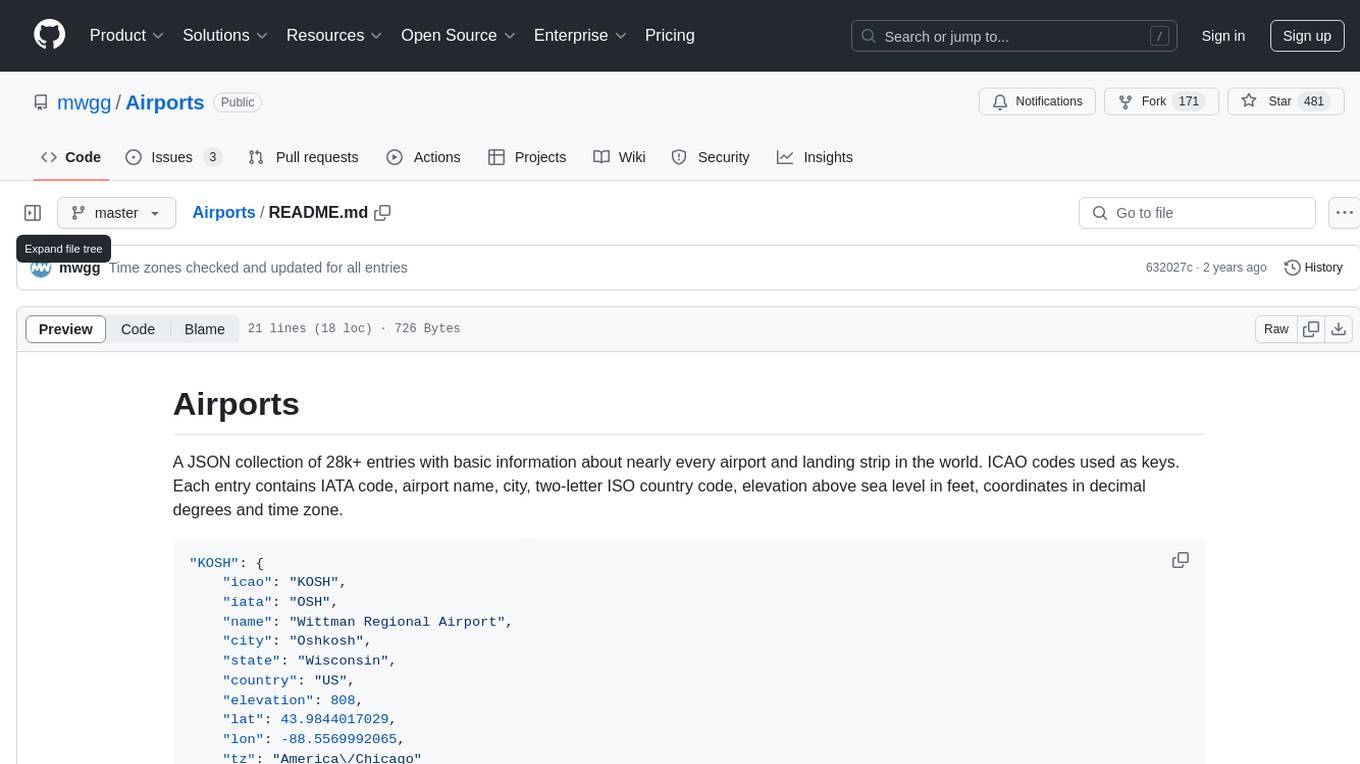
Airports
Airports is a JSON collection with detailed information about over 28,000 airports and landing strips worldwide. Each entry includes IATA code, airport name, city, country code, elevation, coordinates, and time zone.
airport-codes
The airport-codes repository contains a list of airport codes from around the world, including IATA and ICAO codes. The data is sourced from multiple different sources and is updated nightly. The repository provides a script to process the data and merge location coordinates. The data can be used for various purposes such as passenger reservation, ticketing, and ATC systems.

jiwu-mall-chat-tauri
Jiwu Chat Tauri APP is a desktop chat application based on Nuxt3 + Tauri + Element Plus framework. It provides a beautiful user interface with integrated chat and social functions. It also supports AI shopping chat and global dark mode. Users can engage in real-time chat, share updates, and interact with AI customer service through this application.

JiwuChat
JiwuChat is a lightweight multi-platform chat application built on Tauri2 and Nuxt3, with various real-time messaging features, AI group chat bots (such as 'iFlytek Spark', 'KimiAI' etc.), WebRTC audio-video calling, screen sharing, and AI shopping functions. It supports seamless cross-device communication, covering text, images, files, and voice messages, also supporting group chats and customizable settings. It provides light/dark mode for efficient social networking.
samples
Strands Agents Samples is a repository showcasing easy-to-use examples for building AI agents using a model-driven approach. The examples provided are for demonstration and educational purposes only, not intended for direct production use. Users can explore various samples to understand concepts and techniques, ensuring proper security and testing procedures before implementation.

dolma
Dolma is a dataset and toolkit for curating large datasets for (pre)-training ML models. The dataset consists of 3 trillion tokens from a diverse mix of web content, academic publications, code, books, and encyclopedic materials. The toolkit provides high-performance, portable, and extensible tools for processing, tagging, and deduplicating documents. Key features of the toolkit include built-in taggers, fast deduplication, and cloud support.

airweave
Airweave is an open-core tool that simplifies the process of making data searchable by unifying apps, APIs, and databases into a vector database with minimal configuration. It offers over 120 integrations, simplicity in syncing data from diverse sources, extensibility through 'sources', 'destinations', and 'embedders', and an async-first approach for large-scale data synchronization. With features like no-code setup, white-labeled multi-tenant support, chunk generators, automated sync, versioning & hashing, multi-source support, and scalability, Airweave provides a comprehensive solution for building applications that require semantic search.
vision-llms-are-blind
This repository contains the code and data for the paper 'Vision Language Models Are Blind'. It explores the limitations of large language models with vision capabilities (VLMs) in performing basic visual tasks that are easy for humans. The repository presents benchmark results showcasing the poor performance of state-of-the-art VLMs on tasks like counting line intersections, identifying circles, letters, and shapes, and following color-coded paths. The research highlights the challenges faced by VLMs in understanding visual information accurately, drawing parallels to myopia and blindness in human vision.
ai-directories
Welcome to 'Top AI Directories', a curated compilation of AI tool directories designed to simplify the process of discovering and submitting AI products. Whether you're an AI developer or a product team, this resource is your one-stop destination to explore a variety of directories that can help boost the visibility of your AI innovations. Join us in fostering collaboration and recognition within the AI community by leveraging this comprehensive list.
llm_aided_ocr
The LLM-Aided OCR Project is an advanced system that enhances Optical Character Recognition (OCR) output by leveraging natural language processing techniques and large language models. It offers features like PDF to image conversion, OCR using Tesseract, error correction using LLMs, smart text chunking, markdown formatting, duplicate content removal, quality assessment, support for local and cloud-based LLMs, asynchronous processing, detailed logging, and GPU acceleration. The project provides detailed technical overview, text processing pipeline, LLM integration, token management, quality assessment, logging, configuration, and customization. It requires Python 3.12+, Tesseract OCR engine, PDF2Image library, PyTesseract, and optional OpenAI or Anthropic API support for cloud-based LLMs. The installation process involves setting up the project, installing dependencies, and configuring environment variables. Users can place a PDF file in the project directory, update input file path, and run the script to generate post-processed text. The project optimizes processing with concurrent processing, context preservation, and adaptive token management. Configuration settings include choosing between local or API-based LLMs, selecting API provider, specifying models, and setting context size for local LLMs. Output files include raw OCR output and LLM-corrected text. Limitations include performance dependency on LLM quality and time-consuming processing for large documents.
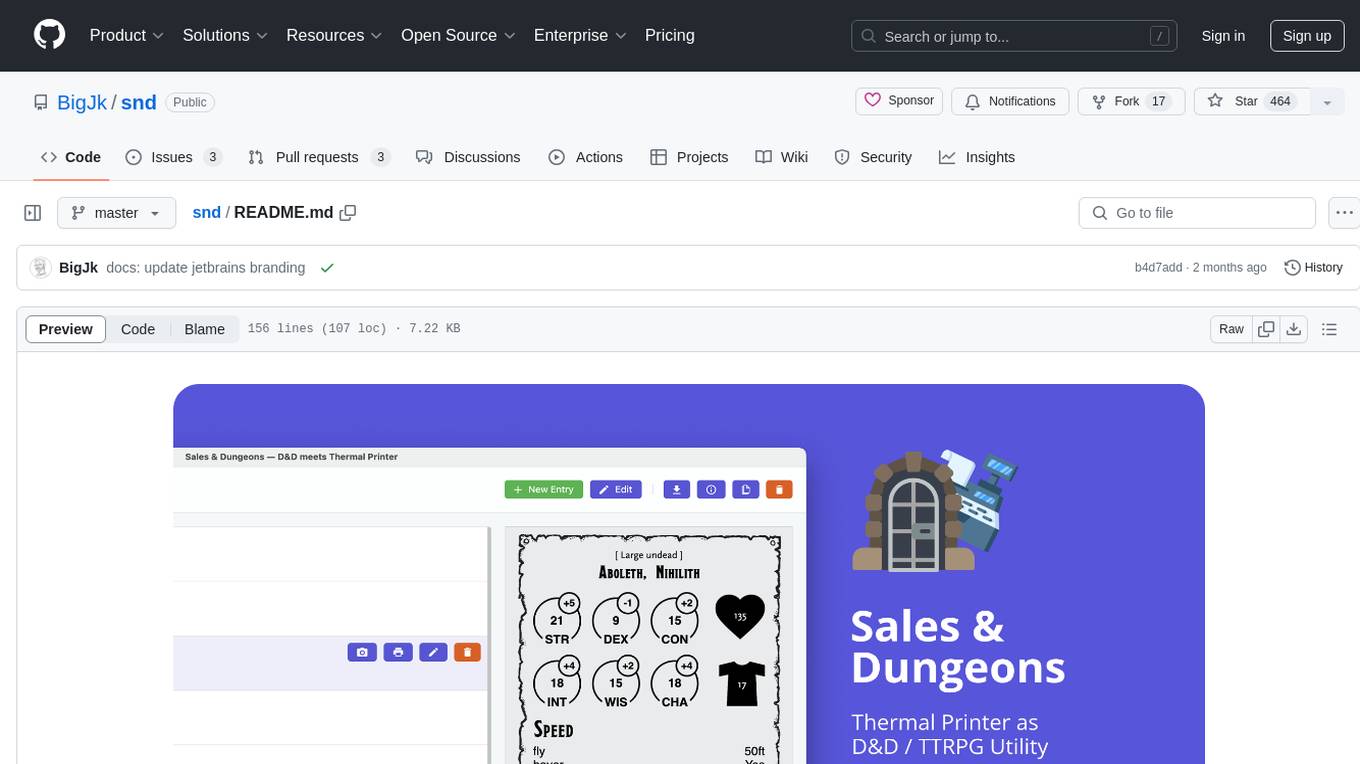
snd
Sales & Dungeons is a tool that utilizes thermal printers for creating customizable handouts, quick references, and more for Dungeons and Dragons sessions. It offers extensive templating and random generation systems, supports various connection methods, and allows importing/exporting templates and data sources. Users can access external data sources like Open5e, import data from CSV and other formats, and utilize AI prompt generation and translation. The tool supports cloud sync and is compatible with multiple operating systems and devices.
MLE-agent
MLE-Agent is an intelligent companion designed for machine learning engineers and researchers. It features autonomous baseline creation, integration with Arxiv and Papers with Code, smart debugging, file system organization, comprehensive tools integration, and an interactive CLI chat interface for seamless AI engineering and research workflows.