AI tools for document
Related Jobs:
Related Tools:
Docai
Docai is an AI-powered documentation tool that allows users to easily create high-quality instructional videos and how-to articles. By recording your screen and camera with the help of the Docai Chrome Extension, you can quickly generate comprehensive documentation using AI technology. Docai offers features such as studio-quality video production, auto-transcription, video editing capabilities, AI voice narrator, document templates, and collaborative editing. With key integrations, browser extensions, and a robust API, Docai can be seamlessly integrated into various workflows to streamline the documentation process.
Document360
Document360 is an AI-powered knowledge base software that helps businesses create, manage, and share documentation. It offers a range of features to make documentation easier and more efficient, including a user-friendly interface, advanced search capabilities, rich analytics, and AI-powered suggestions. Document360 can be used by businesses of all sizes to improve their customer service, product documentation, and internal knowledge sharing.
O.Translator
The website is an AI-powered online document translator that offers professional-grade translations for various document formats such as PDF, Word, EPUB, audio files, and more. It uses AI technology to preserve layout and formatting, providing fast, accurate, and high-quality translations. Users can also benefit from features like intelligent translation quality, online editing, free preview, competitive pricing, privacy protection, and collaborative team translation. The platform supports over 80 languages and 30 file formats, making it a versatile tool for individuals and organizations seeking efficient document translation solutions.
Base64.ai
Base64.ai is an AI-powered document intelligence platform that offers a comprehensive solution for document processing and data extraction. It leverages advanced AI technology to automate business decisions, improve efficiency, accuracy, and digital transformation. Base64.ai provides features such as GenAI models, Semantic AI, Custom Model Builder, Question & Answer capabilities, and Large Action Models to streamline document processing. The platform supports over 50 file formats and offers integrations with scanners, RPA platforms, and third-party software.
Immplify
Immplify is the ultimate platform for immigrants, offering an advanced document management system, on-demand immigration-related services, and a vibrant verified immigrant community. The platform prioritizes security, employing 2-factor authentication, data redaction, AES 256-bit encryption, and tokenization to protect users' confidential information. Immplify simplifies the immigration process by providing features like document digitization, on-the-go scanning, advanced encryption, automatic document organization, travel time tracking, intelligent document tracking, key insights dashboard, instant access to immigration guidance, and secure document sharing. Trusted by immigrants for its efficiency and reliability, Immplify streamlines tasks such as managing travel history, organizing documents, filling out visa forms, and ensuring document security.
WhatLetter
WhatLetter is an AI document translation tool designed to help immigrant families and seniors navigate important paperwork without language barriers. Users can snap a photo of any document to get instant insights, chat with an AI chatbot in their preferred language, and translate various types of documents such as personal, business, technical, and more. The tool prioritizes user privacy by not saving images on servers and retaining chat history solely for user reference. WhatLetter aims to simplify document understanding and empower users with a global experience through AI technology.
DeepL Translate
DeepL is an AI-powered translation tool that offers accurate and efficient translation services across multiple languages. It provides various features such as document translation, AI-powered edits, real-time voice translation, and integration with essential productivity tools. DeepL is widely used for personal, professional, and enterprise translation needs due to its high translation quality and user-friendly interface.
Ocrolus
Ocrolus is an intelligent document automation software that leverages AI-driven document processing automation with Human-in-the-Loop. It offers capabilities such as classifying, capturing, detecting, and analyzing documents, with use cases in cash flow, income, address, employment, and identity verification. Ocrolus caters to various industries like small business lending, mortgage, consumer finance, and multifamily housing. The platform provides resources for developers, including guides on income verification, fraud detection, and business process automation. Users can explore the API to build innovative customer experiences and make faster and more accurate financial decisions.
AI Bank Statement Converter
The AI Bank Statement Converter is an industry-leading tool designed for accountants and bookkeepers to extract data from financial documents using artificial intelligence technology. It offers features such as automated data extraction, integration with accounting software, enhanced security, streamlined workflow, and multi-format conversion capabilities. The tool revolutionizes financial document processing by providing high-precision data extraction, tailored for accounting businesses, and ensuring data security through bank-level encryption. It also offers Intelligent Document Processing (IDP) using AI and machine learning techniques to process structured, semi-structured, and unstructured documents.
DocuHelp
DocuHelp is an AI-powered platform that enables businesses to effortlessly create professional-grade documents, reports, proposals, and sales pitches in a matter of minutes. It facilitates real-time collaboration among team members, eliminating the need for email chains and ensuring accuracy and efficiency. With industry-focused backend prompts, access to backend systems, and the ability to train models on company-specific data, DocuHelp offers a tailored solution for businesses seeking to enhance their document creation process.

Totoy
Totoy is a Document AI tool that redefines the way documents are processed. Its API allows users to explain, classify, and create knowledge bases from documents without the need for training. The tool supports 19 languages and works with plain text, images, and PDFs. Totoy is ideal for automating workflows, complying with accessibility laws, and creating custom AI assistants for employees or customers.

Remko.online
Remko.online is an AI-driven document drafting application that offers solutions for various tasks such as due diligence, ebook creation, info reports, legal questions, and more. It leverages AI technology to streamline document management, enhance legal writing, and revolutionize office operations. Users can easily draft documents by selecting the document type, adding a filename, choosing the language, and following a simple filling form. The application provides examples and warnings for best results and allows users to log in with their Gmail account to access the drafted documents. Additionally, Remko.online offers AI-driven language solutions and consultation services to help businesses stay competitive in the digital age.
Petal
Petal is a document analysis platform powered by generative AI technology. It allows users to chat with their documents, providing fully sourced and reliable answers by linking to their own knowledge bases. Users can train AI on their documents to support their work, ensuring centralized knowledge management and document synchronization. Petal offers features such as automatic metadata extraction, file deduplication, and collaboration tools to enhance productivity and streamline workflows for researchers, faculty, and industry experts.
Dataku.ai
Dataku.ai is an advanced data extraction and analysis tool powered by AI technology. It offers seamless extraction of valuable insights from documents and texts, transforming unstructured data into structured, actionable information. The tool provides tailored data extraction solutions for various needs, such as resume extraction for streamlined recruitment processes, review insights for decoding customer sentiments, and leveraging customer data to personalize experiences. With features like market trend analysis and financial document analysis, Dataku.ai empowers users to make strategic decisions based on accurate data. The tool ensures precision, efficiency, and scalability in data processing, offering different pricing plans to cater to different user needs.
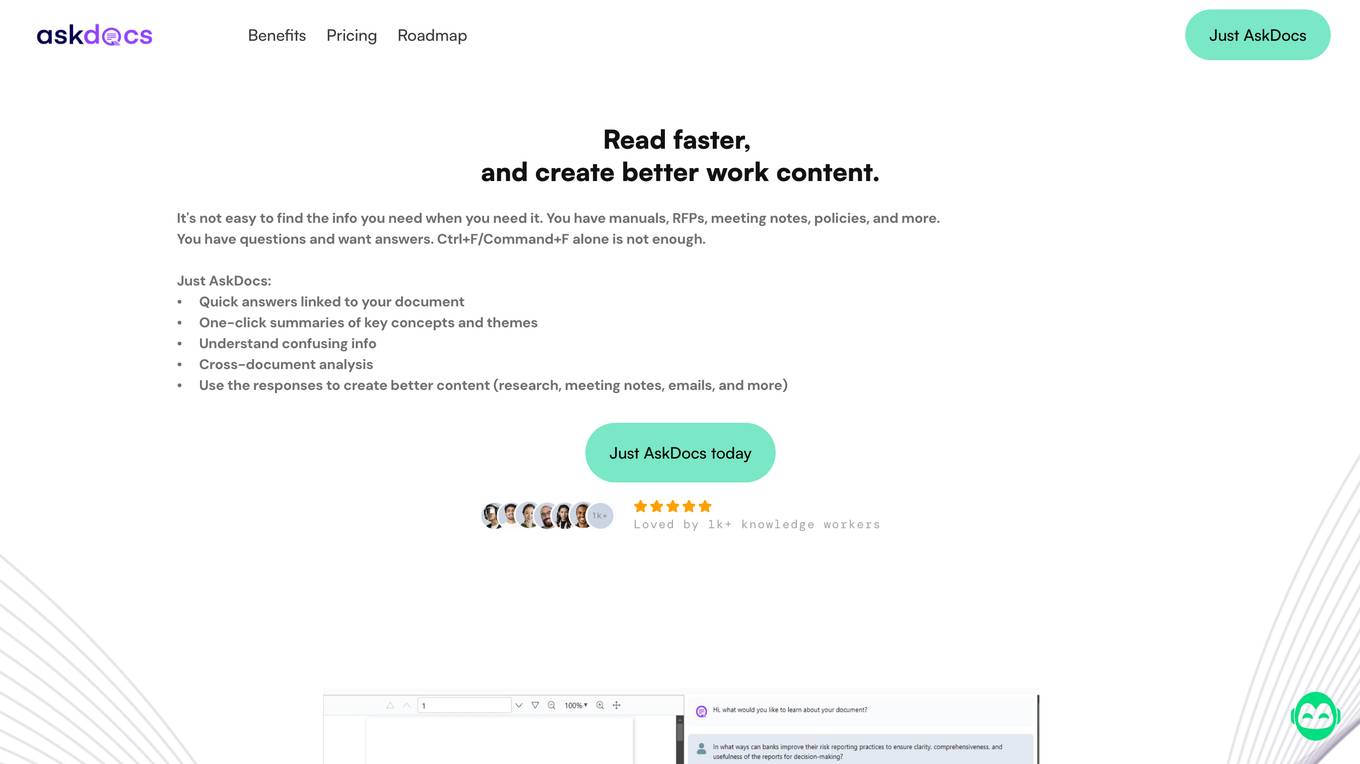
AskDocs
AskDocs is an AI-powered document assistant designed to help users read faster and create better work content. It offers cross-document analysis, quick answers linked to documents, one-click summaries of key concepts, and the ability to understand confusing information. With a focus on enhancing productivity, AskDocs is trusted by students, knowledge workers, and small businesses to streamline research, meeting notes, emails, and more. The tool supports various document types and provides instant answers directly linked to sources within the uploaded documents.
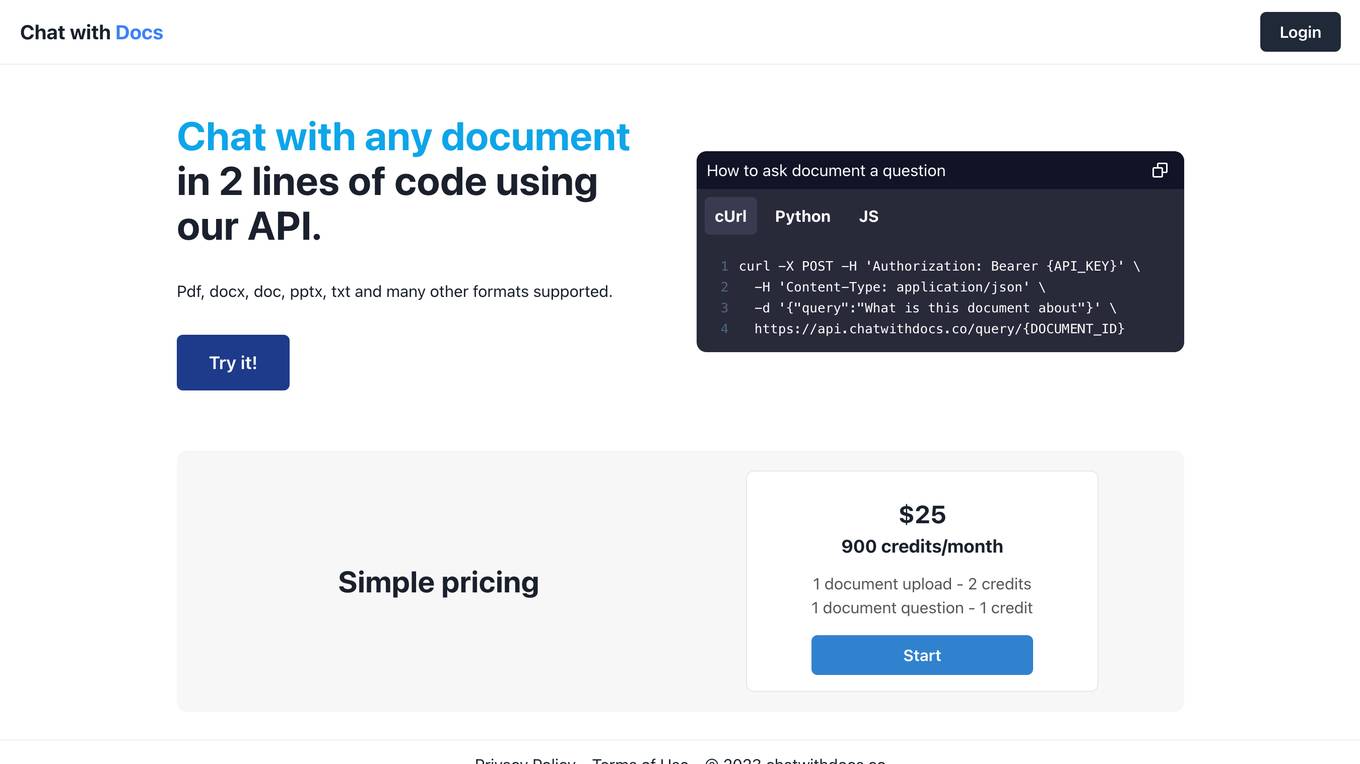
Chat with Docs
Chat with Docs is a platform that allows users to interact with documents using a simple API. Users can chat with any document by integrating just 2 lines of code. The platform supports various document formats such as Pdf, docx, doc, pptx, txt, and more. Users can ask questions about documents using cUrl, Python, or JavaScript. Chat with Docs offers a straightforward pricing model and emphasizes privacy and terms of use.
Docugami
Docugami is an AI-powered document engineering platform that enables business users to extract, analyze, and automate data from various types of documents. It empowers users with immediate impact without the need for extensive machine learning investments or IT development. Docugami's proprietary Business Document Foundation Model leverages Generative AI to transform unstructured text into structured information, allowing users to unlock insights and drive business processes efficiently.
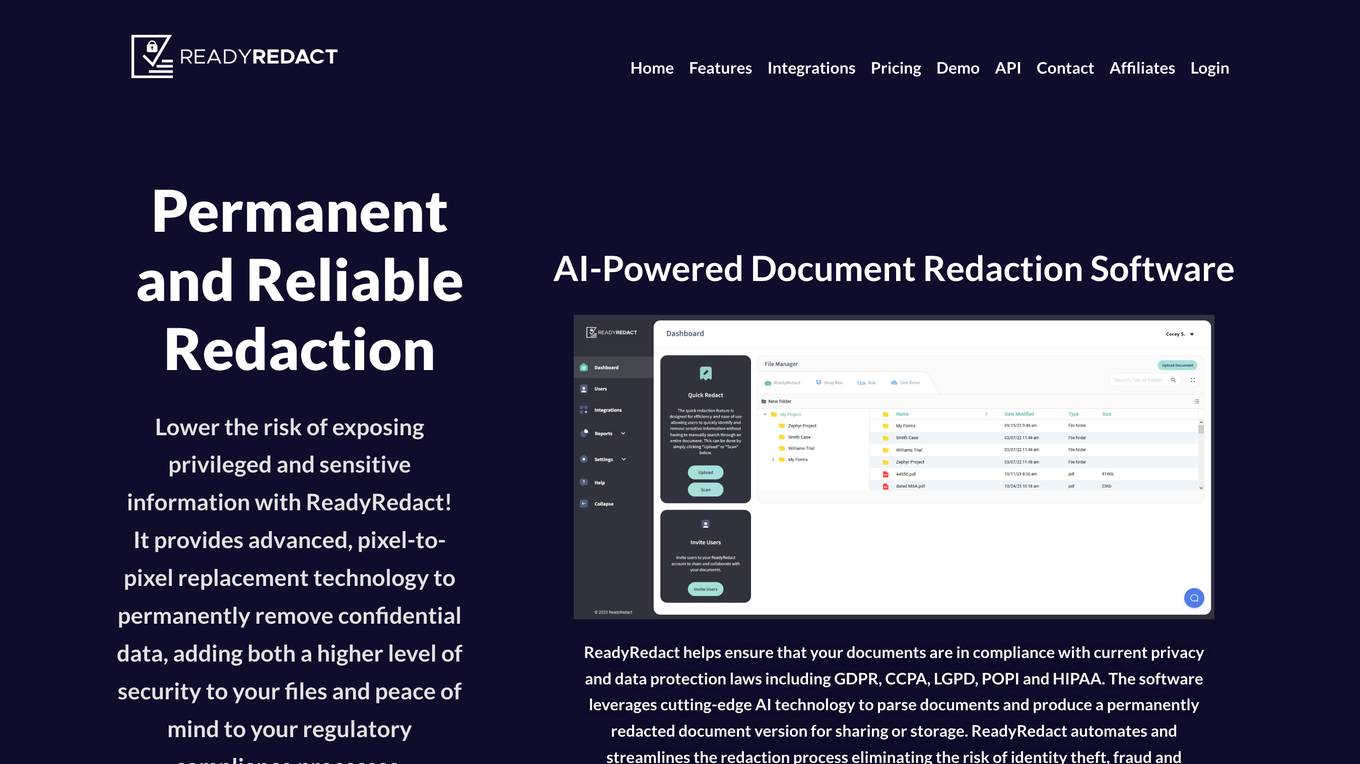
ReadyRedact
ReadyRedact is a cloud-based, AI-powered document redaction software that helps businesses and organizations permanently remove confidential data from documents. It uses advanced pixel-to-pixel replacement technology to ensure that sensitive information is completely removed, adding a higher level of security to files and peace of mind to regulatory compliance processes. ReadyRedact automates and streamlines the redaction process, eliminating the risk of identity theft, fraud, and litigation due to data leaks or outright theft.
super.AI
Super.AI provides Intelligent Document Processing (IDP) solutions powered by Large Language Models (LLMs) and human-in-the-loop (HITL) capabilities. It automates document processing tasks such as data extraction, classification, and redaction, enabling businesses to streamline their workflows and improve accuracy. Super.AI's platform leverages cutting-edge AI models from providers like Amazon, Google, and OpenAI to handle complex documents, ensuring high-quality outputs. With its focus on accuracy, flexibility, and scalability, Super.AI caters to various industries, including financial services, insurance, logistics, and healthcare.
PYQ
PYQ is an AI-powered platform that helps businesses automate document-related tasks, such as data extraction, form filling, and system integration. It uses natural language processing (NLP) and machine learning (ML) to understand the content of documents and perform tasks accordingly. PYQ's platform is designed to be easy to use, with pre-built automations for common use cases. It also offers custom automation development services for more complex needs.
Doc Maker
Prompt to create documents, such as design docs, reports, proposals, resumes, and more. Export to PDF, DOCX, PPTX, XLSX, CSV.

DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages

DocFlow
DocFlow is designed to assist in the creation and management of business-related documents. The assistant should leverage its knowledge base and language processing capabilities to provide detailed guidance, draft documents, and offer insights specific to business ventures.
Documentary Production Assistant
Expert in documentary film production, providing tailored creative and technical advice.
CineScriptAI
Write extended documentary scripts with free relevant video, music & thumbnail.
Florida Entrepreneur Startup Documents Package
Startup document generator for Florida entrepreneurs.
Chinese 智译
无需说明,自动在中文和其他语言间互译,支持翻译代码注释、文言文、文档文件以及图片。No need for explanations, automatically translate between Chinese and other languages, support translation of code comments, classical Chinese, document files, and images.

LexAid GPT
Meet LexAid GPT: Your AI-powered legal assistant. With advanced document analysis, secure handling, and expert legal knowledge, it streamlines case review and drafting, enhancing efficiency and accuracy in your legal practice
Automated Knowledge Distillation
For strategic knowledge distillation, upload the document you need to analyze and use !start. ENSURE the uploaded file shows DOCUMENT and NOT PDF. This workflow requires leveraging RAG to operate. Only a small amount of PDFs are supported, convert to txt or doc. For timeout, refresh & !continue
QuickSilver AI - Natural Language R.A.G DocuMaster
Easily format and optimize your documents, create NLRAG (Natural Language Retrieval Augmented Generation) indexes and more!

document-ai-samples
The Google Cloud Document AI Samples repository contains code samples and Community Samples demonstrating how to analyze, classify, and search documents using Google Cloud Document AI. It includes various projects showcasing different functionalities such as integrating with Google Drive, processing documents using Python, content moderation with Dialogflow CX, fraud detection, language extraction, paper summarization, tax processing pipeline, and more. The repository also provides access to test document files stored in a publicly-accessible Google Cloud Storage Bucket. Additionally, there are codelabs available for optical character recognition (OCR), form parsing, specialized processors, and managing Document AI processors. Community samples, like the PDF Annotator Sample, are also included. Contributions are welcome, and users can seek help or report issues through the repository's issues page. Please note that this repository is not an officially supported Google product and is intended for demonstrative purposes only.
accelerated-intelligent-document-processing-on-aws
Accelerated Intelligent Document Processing on AWS is a scalable, serverless solution for automated document processing and information extraction using AWS services. It combines OCR capabilities with generative AI to convert unstructured documents into structured data at scale. The solution features a serverless architecture built on AWS technologies, modular processing patterns, advanced classification support, few-shot example support, custom business logic integration, high throughput processing, built-in resilience, cost optimization, comprehensive monitoring, web user interface, human-in-the-loop integration, AI-powered evaluation, extraction confidence assessment, and document knowledge base query. The architecture uses nested CloudFormation stacks to support multiple document processing patterns while maintaining common infrastructure for queueing, tracking, and monitoring.
Document-Knowledge-Mining-Solution-Accelerator
The Document Knowledge Mining Solution Accelerator leverages Azure OpenAI and Azure AI Document Intelligence to ingest, extract, and classify content from various assets, enabling chat-based insight discovery, analysis, and prompt guidance. It uses OCR and multi-modal LLM to extract information from documents like text, handwritten text, charts, graphs, tables, and form fields. Users can customize the technical architecture and data processing workflow. Key features include ingesting and extracting real-world entities, chat-based insights discovery, text and document data analysis, prompt suggestion guidance, and multi-modal information processing.
documentation
Vespa documentation is served using GitHub Project pages with Jekyll. To edit documentation, check out and work off the master branch in this repository. Documentation is written in HTML or Markdown. Use a single Jekyll template _layouts/default.html to add header, footer and layout. Install bundler, then $ bundle install $ bundle exec jekyll serve --incremental --drafts --trace to set up a local server at localhost:4000 to see the pages as they will look when served. If you get strange errors on bundle install try $ export PATH=“/usr/local/opt/[email protected]/bin:$PATH” $ export LDFLAGS=“-L/usr/local/opt/[email protected]/lib” $ export CPPFLAGS=“-I/usr/local/opt/[email protected]/include” $ export PKG_CONFIG_PATH=“/usr/local/opt/[email protected]/lib/pkgconfig” The output will highlight rendering/other problems when starting serving. Alternatively, use the docker image `jekyll/jekyll` to run the local server on Mac $ docker run -ti --rm --name doc \ --publish 4000:4000 -e JEKYLL_UID=$UID -v $(pwd):/srv/jekyll \ jekyll/jekyll jekyll serve or RHEL 8 $ podman run -it --rm --name doc -p 4000:4000 -e JEKYLL_ROOTLESS=true \ -v "$PWD":/srv/jekyll:Z docker.io/jekyll/jekyll jekyll serve The layout is written in denali.design, see _layouts/default.html for usage. Please do not add custom style sheets, as it is harder to maintain.
mcp-documentation-server
The mcp-documentation-server is a lightweight server application designed to serve documentation files for projects. It provides a simple and efficient way to host and access project documentation, making it easy for team members and stakeholders to find and reference important information. The server supports various file formats, such as markdown and HTML, and allows for easy navigation through the documentation. With mcp-documentation-server, teams can streamline their documentation process and ensure that project information is easily accessible to all involved parties.
Documents-Parsing-Lab
A curated collection of Jupyter notebooks for experimenting with state-of-the-art OCR, document parsing, table extraction, and chart understanding techniques. This repository enables easy benchmarking and practical usage of the latest open-source and cloud-based solutions for document image processing.
llm-document-ocr
LLM Document OCR is a Node.js tool that utilizes GPT4 and Claude3 for OCR and data extraction. It converts PDFs into PNGs, crops white-space, cleans up JSON strings, and supports various image formats. Users can customize prompts for data extraction. The tool is sponsored by Mercoa, offering API for BillPay and Invoicing.
aws-ai-intelligent-document-processing
This repository is part of Intelligent Document Processing with AWS AI Services workshop. It aims to automate the extraction of information from complex content in various document formats such as insurance claims, mortgages, healthcare claims, contracts, and legal contracts using AWS Machine Learning services like Amazon Textract and Amazon Comprehend. The repository provides hands-on labs to familiarize users with these AI services and build solutions to automate business processes that rely on manual inputs and intervention across different file types and formats.
ryzen-ai-documentation
Ryzen AI Software is a tool developed by Advanced Micro Devices, Inc. for AI applications. It is licensed under the MIT License and provides information on technical inaccuracies, omissions, and typographical errors. The tool may be subject to changes due to product updates, component variations, software modifications, and security vulnerabilities. AMD disclaims any implied warranties and liabilities for inaccuracies or errors in the information provided. The tool is not warranted for use in safety-critical automotive applications without proper safety design and testing.
azure-ai-document-processing-samples
This repository contains a collection of code samples that demonstrate how to use various Azure AI capabilities to process documents. The samples help engineering teams establish techniques with Azure AI Foundry, Azure OpenAI, Azure AI Document Intelligence, and Azure AI Language services to build solutions for extracting structured data, classifying, and analyzing documents. The techniques simplify custom model training, improve reliability in document processing, and simplify document processing workflows by providing reusable code and patterns that can be easily modified and evaluated for most use cases.

h2ogpt
h2oGPT is an Apache V2 open-source project that allows users to query and summarize documents or chat with local private GPT LLMs. It features a private offline database of any documents (PDFs, Excel, Word, Images, Video Frames, Youtube, Audio, Code, Text, MarkDown, etc.), a persistent database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.), and efficient use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach). h2oGPT also offers parallel summarization and extraction, reaching an output of 80 tokens per second with the 13B LLaMa2 model, HYDE (Hypothetical Document Embeddings) for enhanced retrieval based upon LLM responses, a variety of models supported (LLaMa2, Mistral, Falcon, Vicuna, WizardLM. With AutoGPTQ, 4-bit/8-bit, LORA, etc.), GPU support from HF and LLaMa.cpp GGML models, and CPU support using HF, LLaMa.cpp, and GPT4ALL models. Additionally, h2oGPT provides Attention Sinks for arbitrarily long generation (LLaMa-2, Mistral, MPT, Pythia, Falcon, etc.), a UI or CLI with streaming of all models, the ability to upload and view documents through the UI (control multiple collaborative or personal collections), Vision Models LLaVa, Claude-3, Gemini-Pro-Vision, GPT-4-Vision, Image Generation Stable Diffusion (sdxl-turbo, sdxl) and PlaygroundAI (playv2), Voice STT using Whisper with streaming audio conversion, Voice TTS using MIT-Licensed Microsoft Speech T5 with multiple voices and Streaming audio conversion, Voice TTS using MPL2-Licensed TTS including Voice Cloning and Streaming audio conversion, AI Assistant Voice Control Mode for hands-free control of h2oGPT chat, Bake-off UI mode against many models at the same time, Easy Download of model artifacts and control over models like LLaMa.cpp through the UI, Authentication in the UI by user/password via Native or Google OAuth, State Preservation in the UI by user/password, Linux, Docker, macOS, and Windows support, Easy Windows Installer for Windows 10 64-bit (CPU/CUDA), Easy macOS Installer for macOS (CPU/M1/M2), Inference Servers support (oLLaMa, HF TGI server, vLLM, Gradio, ExLLaMa, Replicate, OpenAI, Azure OpenAI, Anthropic), OpenAI-compliant, Server Proxy API (h2oGPT acts as drop-in-replacement to OpenAI server), Python client API (to talk to Gradio server), JSON Mode with any model via code block extraction. Also supports MistralAI JSON mode, Claude-3 via function calling with strict Schema, OpenAI via JSON mode, and vLLM via guided_json with strict Schema, Web-Search integration with Chat and Document Q/A, Agents for Search, Document Q/A, Python Code, CSV frames (Experimental, best with OpenAI currently), Evaluate performance using reward models, and Quality maintained with over 1000 unit and integration tests taking over 4 GPU-hours.
haystack-core-integrations
This repository contains integrations to extend the capabilities of Haystack version 2.0 and onwards. The code in this repo is maintained by deepset, see each integration's `README` file for details around installation, usage and support.

deepdoctection
**deep** doctection is a Python library that orchestrates document extraction and document layout analysis tasks using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models. For more specific text processing tasks use one of the many other great NLP libraries. **deep** doctection focuses on applications and is made for those who want to solve real world problems related to document extraction from PDFs or scans in various image formats. **deep** doctection provides model wrappers of supported libraries for various tasks to be integrated into pipelines. Its core function does not depend on any specific deep learning library. Selected models for the following tasks are currently supported: * Document layout analysis including table recognition in Tensorflow with **Tensorpack**, or PyTorch with **Detectron2**, * OCR with support of **Tesseract**, **DocTr** (Tensorflow and PyTorch implementations available) and a wrapper to an API for a commercial solution, * Text mining for native PDFs with **pdfplumber**, * Language detection with **fastText**, * Deskewing and rotating images with **jdeskew**. * Document and token classification with all LayoutLM models provided by the **Transformer library**. (Yes, you can use any LayoutLM-model with any of the provided OCR-or pdfplumber tools straight away!). * Table detection and table structure recognition with **table-transformer**. * There is a small dataset for token classification available and a lot of new tutorials to show, how to train and evaluate this dataset using LayoutLMv1, LayoutLMv2, LayoutXLM and LayoutLMv3. * Comprehensive configuration of **analyzer** like choosing different models, output parsing, OCR selection. Check this notebook or the docs for more infos. * Document layout analysis and table recognition now runs with **Torchscript** (CPU) as well and **Detectron2** is not required anymore for basic inference. * [**new**] More angle predictors for determining the rotation of a document based on **Tesseract** and **DocTr** (not contained in the built-in Analyzer). * [**new**] Token classification with **LiLT** via **transformers**. We have added a model wrapper for token classification with LiLT and added a some LiLT models to the model catalog that seem to look promising, especially if you want to train a model on non-english data. The training script for LayoutLM can be used for LiLT as well and we will be providing a notebook on how to train a model on a custom dataset soon. **deep** doctection provides on top of that methods for pre-processing inputs to models like cropping or resizing and to post-process results, like validating duplicate outputs, relating words to detected layout segments or ordering words into contiguous text. You will get an output in JSON format that you can customize even further by yourself. Have a look at the **introduction notebook** in the notebook repo for an easy start. Check the **release notes** for recent updates. **deep** doctection or its support libraries provide pre-trained models that are in most of the cases available at the **Hugging Face Model Hub** or that will be automatically downloaded once requested. For instance, you can find pre-trained object detection models from the Tensorpack or Detectron2 framework for coarse layout analysis, table cell detection and table recognition. Training is a substantial part to get pipelines ready on some specific domain, let it be document layout analysis, document classification or NER. **deep** doctection provides training scripts for models that are based on trainers developed from the library that hosts the model code. Moreover, **deep** doctection hosts code to some well established datasets like **Publaynet** that makes it easy to experiment. It also contains mappings from widely used data formats like COCO and it has a dataset framework (akin to **datasets** so that setting up training on a custom dataset becomes very easy. **This notebook** shows you how to do this. **deep** doctection comes equipped with a framework that allows you to evaluate predictions of a single or multiple models in a pipeline against some ground truth. Check again **here** how it is done. Having set up a pipeline it takes you a few lines of code to instantiate the pipeline and after a for loop all pages will be processed through the pipeline.

open-parse
Open Parse is a Python library for visually discerning document layouts and chunking them effectively. It is designed to fill the gap in open-source libraries for handling complex documents. Unlike text splitting, which converts a file to raw text and slices it up, Open Parse visually analyzes documents for superior LLM input. It also supports basic markdown for parsing headings, bold, and italics, and has high-precision table support, extracting tables into clean Markdown formats with accuracy that surpasses traditional tools. Open Parse is extensible, allowing users to easily implement their own post-processing steps. It is also intuitive, with great editor support and completion everywhere, making it easy to use and learn.
terraform-genai-doc-summarization
This solution showcases how to summarize a large corpus of documents using Generative AI. It provides an end-to-end demonstration of document summarization going all the way from raw documents, detecting text in the documents and summarizing the documents on-demand using Vertex AI LLM APIs, Cloud Vision Optical Character Recognition (OCR) and BigQuery.
ExtractThinker
ExtractThinker is a library designed for extracting data from files and documents using Language Model Models (LLMs). It offers ORM-style interaction between files and LLMs, supporting multiple document loaders such as Tesseract OCR, Azure Form Recognizer, AWS TextExtract, and Google Document AI. Users can customize extraction using contract definitions, process documents asynchronously, handle various document formats efficiently, and split and process documents. The project is inspired by the LangChain ecosystem and focuses on Intelligent Document Processing (IDP) using LLMs to achieve high accuracy in document extraction tasks.

MegaParse
MegaParse is a powerful and versatile parser designed to handle various types of documents such as text, PDFs, Powerpoint presentations, and Word documents with no information loss. It is fast, efficient, and open source, supporting a wide range of file formats. MegaParse ensures compatibility with tables, table of contents, headers, footers, and images, making it a comprehensive solution for document parsing.

blinkid-android
The BlinkID Android SDK is a comprehensive solution for implementing secure document scanning and extraction. It offers powerful capabilities for extracting data from a wide range of identification documents. The SDK provides features for integrating document scanning into Android apps, including camera requirements, SDK resource pre-bundling, customizing the UX, changing default strings and localization, troubleshooting integration difficulties, and using the SDK through various methods. It also offers options for completely custom UX with low-level API integration. The SDK size is optimized for different processor architectures, and API documentation is available for reference. For any questions or support, users can contact the Microblink team at help.microblink.com.
project-lakechain
Project Lakechain is a cloud-native, AI-powered framework for building document processing pipelines on AWS. It provides a composable API with built-in middlewares for common tasks, scalable architecture, cost efficiency, GPU and CPU support, and the ability to create custom transform middlewares. With ready-made examples and emphasis on modularity, Lakechain simplifies the deployment of scalable document pipelines for tasks like metadata extraction, NLP analysis, text summarization, translations, audio transcriptions, computer vision, and more.
fittencode.nvim
Fitten Code AI Programming Assistant for Neovim provides fast completion using AI, asynchronous I/O, and support for various actions like document code, edit code, explain code, find bugs, generate unit test, implement features, optimize code, refactor code, start chat, and more. It offers features like accepting suggestions with Tab, accepting line with Ctrl + Down, accepting word with Ctrl + Right, undoing accepted text, automatic scrolling, and multiple HTTP/REST backends. It can run as a coc.nvim source or nvim-cmp source.