AI tools for Text to speech
Related Tools:
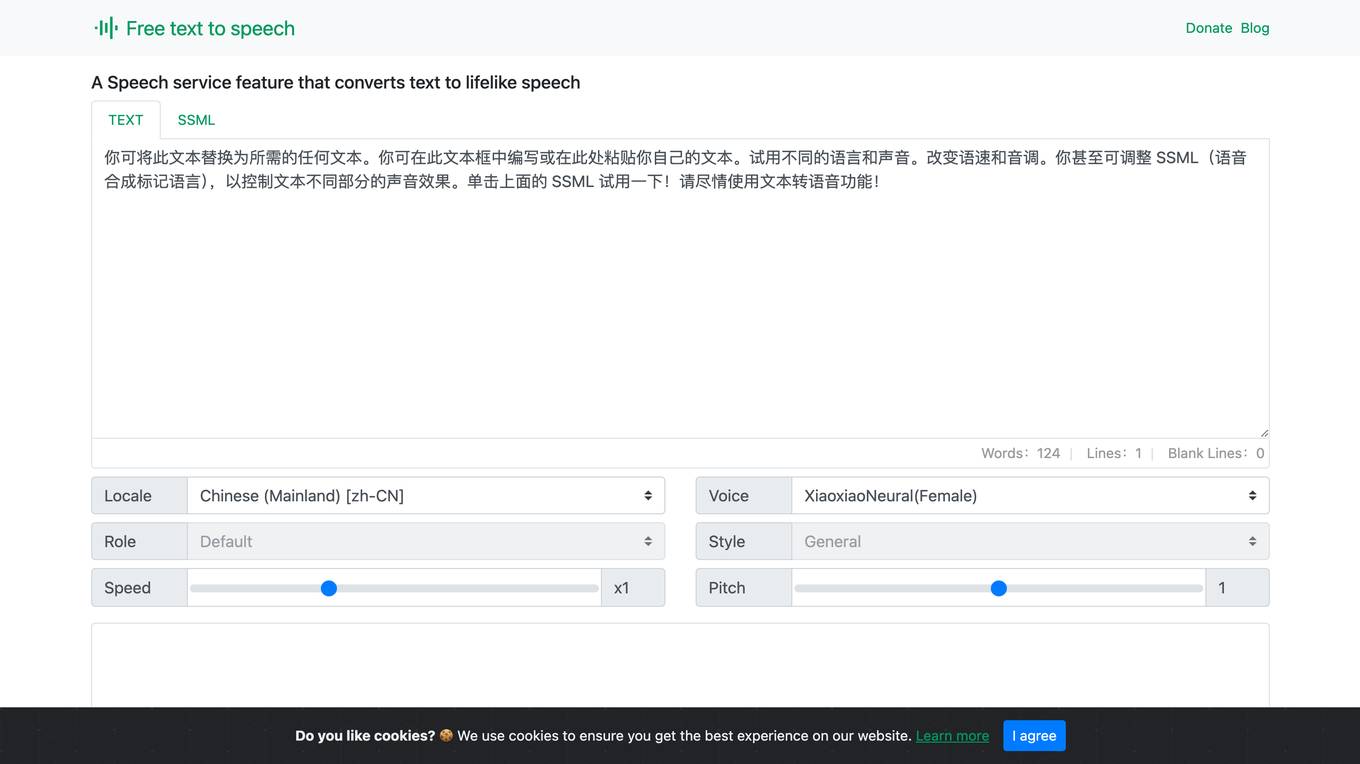
Free Text to Speech Online Converter Tools
This website provides a free text-to-speech converter tool that utilizes Microsoft's AI speech library to synthesize realistic-sounding speech from text. It offers customizable voice options, fine-tuned speech controls, and multilingual support with over 330 neural network voices across 129 languages. The tool is accessible on various browsers, including Chrome, Firefox, and Edge, and can be used for a range of applications, such as text readers and voice-enabled assistants.
Speech Intellect
Speech Intellect is an AI-powered speech-to-text and text-to-speech solution that provides real-time transcription and voice synthesis with emotional analysis. It utilizes a proprietary "Sense Theory" algorithm to capture the meaning and tone of speech, enabling businesses to automate tasks, improve customer interactions, and create personalized experiences.
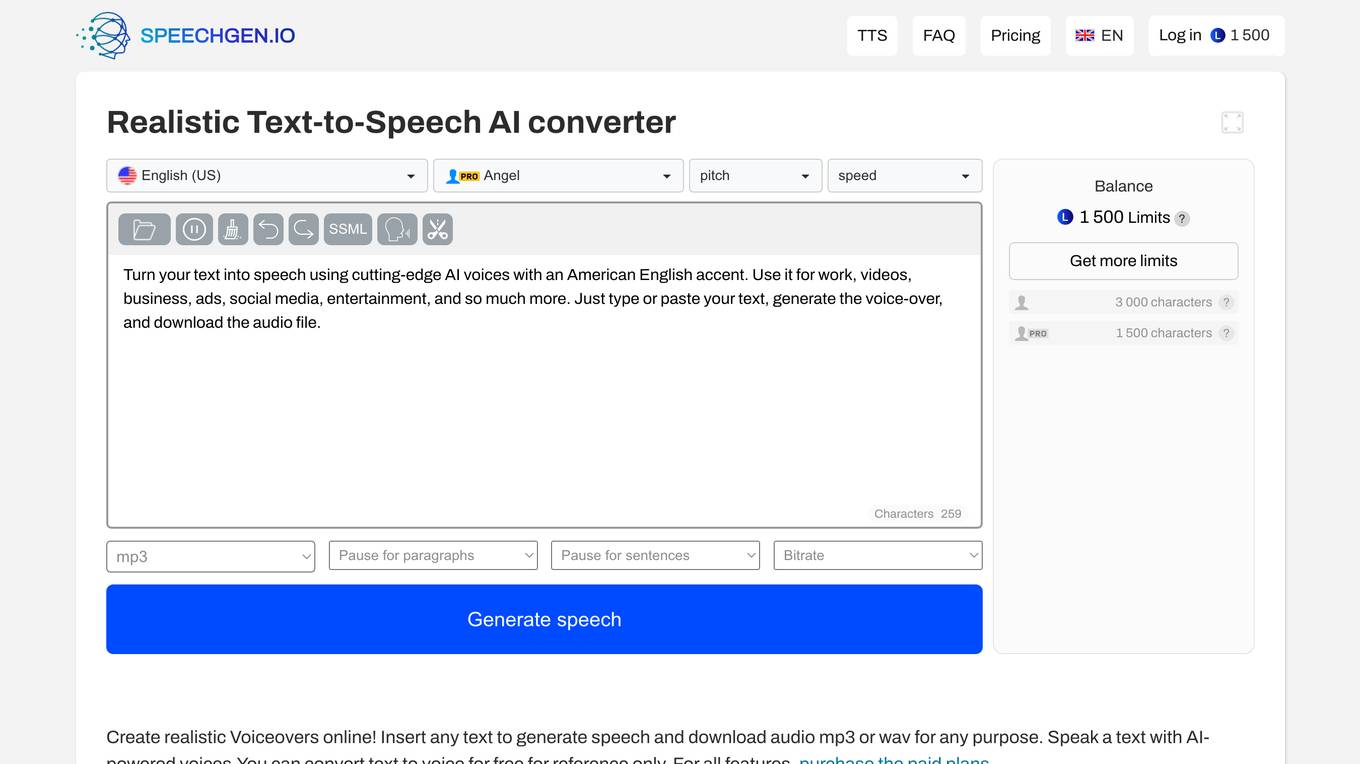
SpeechGen.io
SpeechGen.io is a realistic text-to-speech converter and AI voice generator that allows users to convert text into speech using cutting-edge AI voices with an American English accent. With SpeechGen.io, users can create realistic voiceovers for videos, e-learning materials, advertising, public announcements, podcasts, mobile apps, presentations, and more. The platform offers a wide range of features, including the ability to download converted audio files in MP3, WAV, and OGG formats, support for long texts, commercial use of generated audio, multi-voice editing, custom voice settings, SSML support, and more. SpeechGen.io is accessible in any browser and offers an intuitive interface suitable for beginners. The platform also provides powerful support and is compatible with various editing programs.
Speechify
Speechify is the #1 rated AI text to speech app in its category with over 250,000 5 star reviews. It is available as a Chrome extension, iOS app, Android app, Microsoft Edge Add-on, and web app. Speechify can convert any text into natural-sounding AI voice in over 50 languages and accents. It can also read aloud any PDF, doc, or web page. Speechify is used by students, professionals, readers, and those who struggle to read. It can help with reading comprehension, focus, and retention. Speechify is also a great tool for people with disabilities such as dyslexia, ADHD, and dry eyes.
SpeechEasy
SpeechEasy is a high-quality text-to-speech tool that harnesses the power of AI and machine learning to convert text into natural-sounding audio. With SpeechEasy, you can generate studio-grade synthetic voices that are easy to understand and consume, making it perfect for on-the-go listening, home or office use, and e-learning content.
Speechki
Speechki is an AI Realistic Voice Generator and Text-to-Speech Solution offering over 1,100 voices in 80+ languages. It provides a user-friendly platform for converting text into engaging audio with AI-powered voices. The application is designed to cater to various needs such as audiobook production, content creation, podcasting, and more. With features like real-time proof-listening, chapter-like formatting, streamlined role management, precision pause control, and nuanced speech control, Speechki aims to enhance the user experience and deliver lifelike audio output. The tool also offers global reach with multicast and multilanguage support, making it suitable for a diverse audience.
PlayAI
PlayAI is a powerful AI voice generator and text-to-speech platform that offers a wide range of features to create natural-sounding voiceovers in multiple languages. With over 206 AI voices, users can generate audio content for various purposes such as audiobooks, YouTube videos, documentaries, and more. The platform also provides customization options like speech styles, pronunciations, and voice inflections to enhance the quality of generated voices. PlayAI's API integration allows seamless incorporation into different platforms, making it suitable for a wide range of applications from e-learning to gaming.
Replica Studios
Replica Studios is an AI tool that provides cutting-edge text-to-speech and speech-to-speech solutions in multiple languages for creative professionals. It offers fully licensed AI models safe for commercial use, allowing users to customize voices for various creative and professional use cases, such as gaming, animation, film, audiobooks, e-learning, and social media. The tool enables users to generate voice overs and dialogue instantly, manage scripts, and create unique voices using Voice Lab. Replica Studios prioritizes ethical voice AI by collaborating with voice actors and ensuring commercial use compliance.
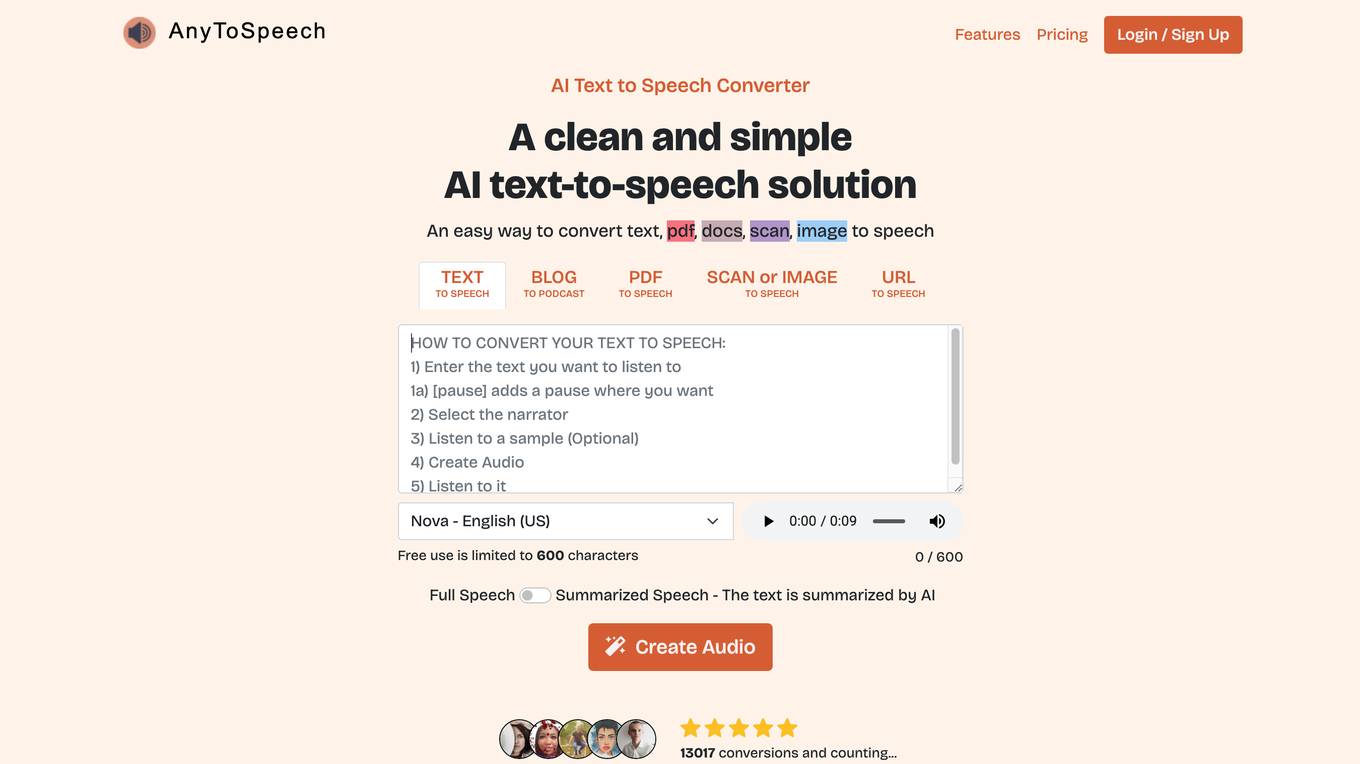
AnyToSpeech
AnyToSpeech is an AI text-to-speech and PDF to Audiobook solution that offers a clean and simple way to convert text, PDFs, documents, scans, and images to speech. It provides a variety of realistic voices in multiple languages for users to choose from. The platform also allows users to convert URLs to speech and offers a library to save and access their generated audio files at any time.
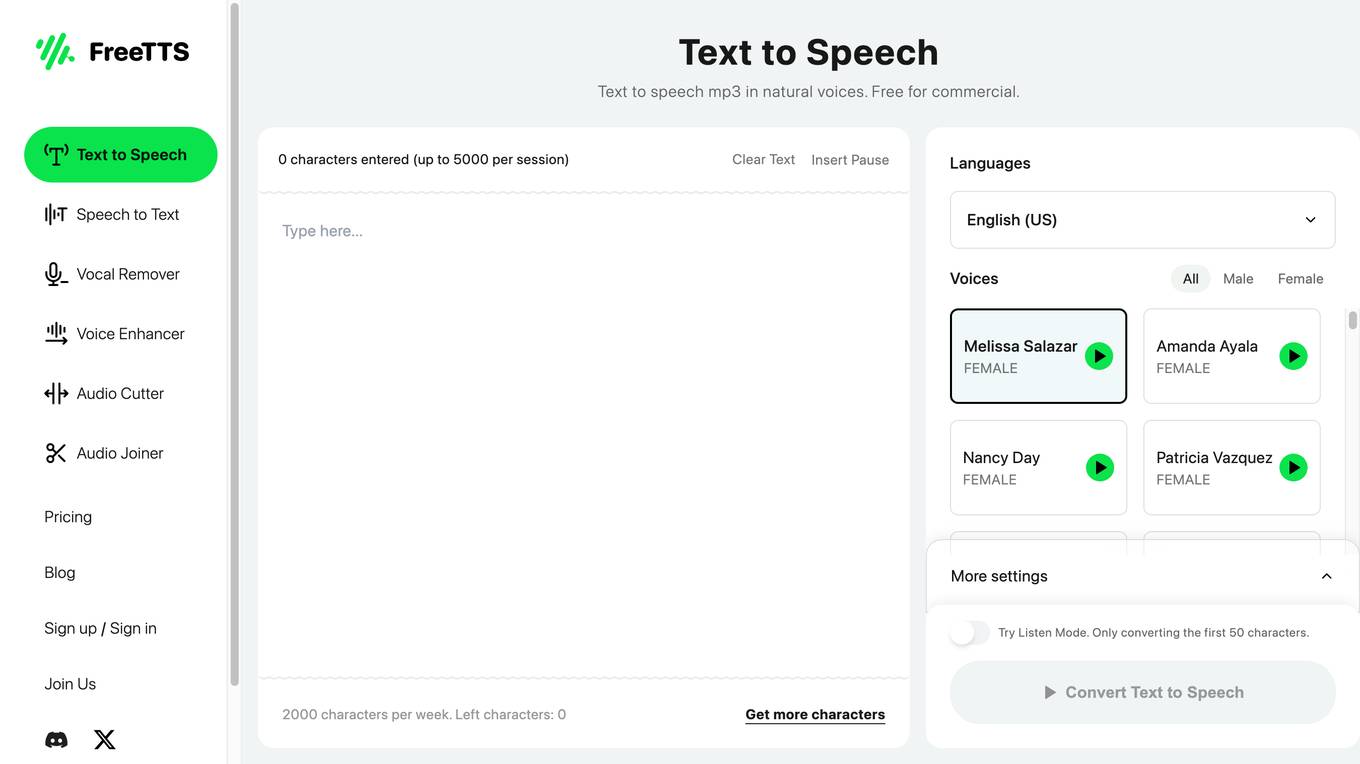
FreeTTS
FreeTTS is a free online text-to-speech tool that allows users to convert text into natural-sounding speech in various languages and voices. It supports a range of features such as text-to-speech conversion, speech-to-text conversion, vocal removal, voice enhancement, audio cutting, and audio joining. FreeTTS is suitable for various applications, including content creation, education, accessibility, and entertainment.
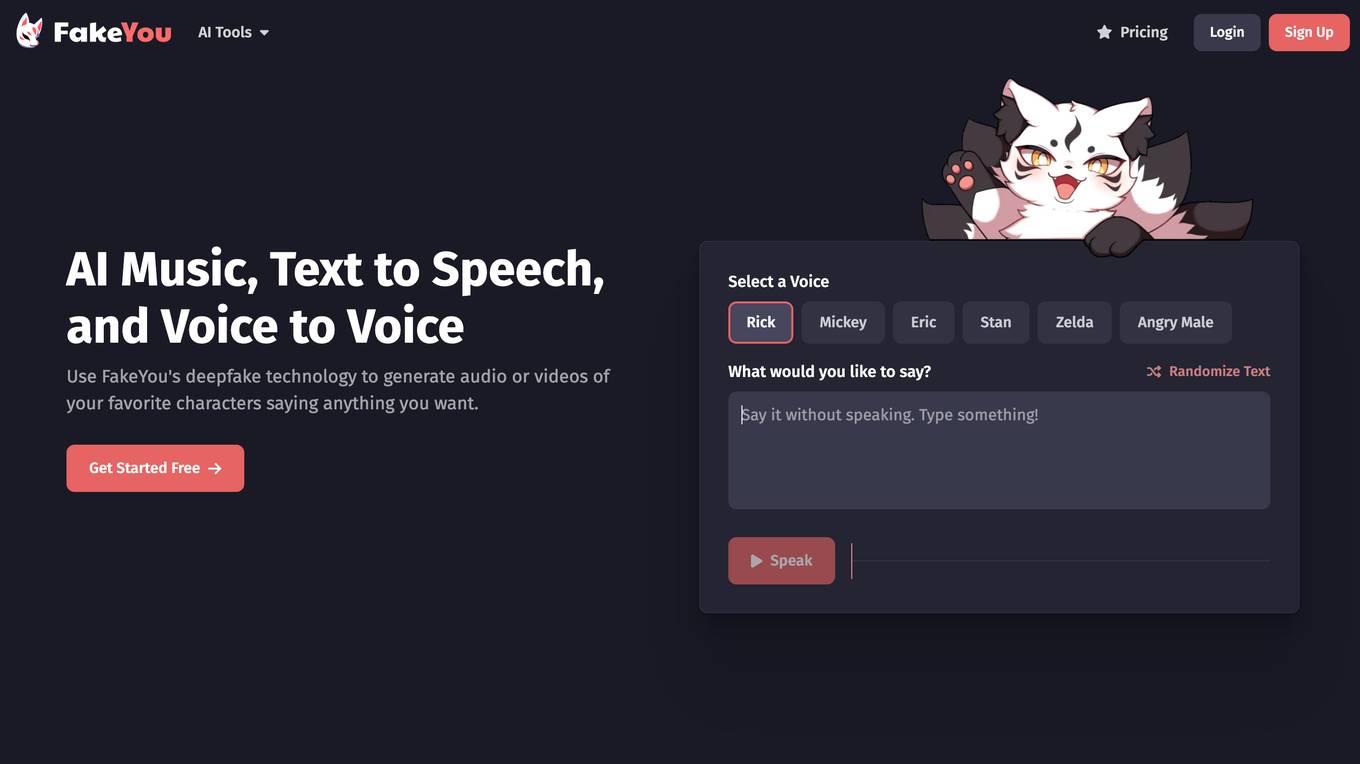
FakeYou
FakeYou is a free online tool that allows you to create realistic text-to-speech audio files. With FakeYou, you can choose from a variety of voices, languages, and accents to create custom audio files that sound like real people. FakeYou is perfect for creating voiceovers for videos, presentations, or other projects.
TTSMaker
TTSMaker is a free online text-to-speech tool that allows users to convert text into natural-sounding speech. It supports multiple languages and voices, and the resulting audio files can be downloaded for free and used for commercial purposes. TTSMaker is a valuable tool for creating audiobooks, dubbing videos, and other projects that require high-quality voiceovers.
Beepbooply
Beepbooply is a text-to-speech tool that uses artificial intelligence to generate realistic and natural-sounding speech. With over 900 voices to choose from, you can create audio content for any purpose, including videos, podcasts, and customer service. Beepbooply is easy to use and affordable, making it a great option for anyone who needs to create high-quality audio content.
Murf AI
Murf AI is a versatile text-to-speech software that simplifies business communication. It offers a range of solutions for various projects, including voiceovers, translations, and AI dubbing, ensuring clear, engaging, and far-reaching messages. With over 120 voices in 20+ languages, Murf AI empowers users to create realistic voiceovers that enhance content accessibility and engagement. Its voice cloning feature allows for the creation of near-perfect voice twins, ensuring intellectual property rights and delivering a realistic audio experience. Murf AI's AI dubbing service enables businesses to take their stories to a global audience with over 20 languages available, promoting universal understanding and cultural connectivity. Additionally, Murf AI's translation service simplifies the translation of business content into more than 20 languages, facilitating seamless international engagement. The Murf API allows developers to integrate high-quality voices into their digital platforms, ensuring a consistent brand voice across various applications. Murf Voices Installer adds favorite Murf voices to Windows systems, enabling users to enjoy them on any Microsoft SAPI-supported platform.
article2audio
Article2audio is a text-to-speech application that focuses on web content. It uses AI to understand and enhance English articles and blog posts before converting them to audio, making listening easier and more natural. Some of its key features include descriptive imagery, table summaries, complex text interpretation, and meaningful voice-overs.
LOVO
LOVO is an AI-powered voice generator that allows users to create realistic and high-quality voiceovers. It offers a wide range of features, including text-to-speech, voice cloning, and video editing. LOVO is perfect for businesses, content creators, educators, and anyone looking to create engaging content that stands out from the crowd.
NaturalReader
NaturalReader is a text-to-speech software that converts text, PDF, and other formats into spoken audio. It is designed for personal, commercial, and educational use. NaturalReader has a variety of features, including cross-platform compatibility, an AI voice generator, and support for students with dyslexia or other learning disabilities.
Woord
Woord is an online text-to-speech (TTS) tool that allows users to convert text into natural-sounding speech. It offers a wide range of voices in over 34 languages, including regional variations. Woord also provides advanced features such as SSML editing, OCR support, and API access. With its user-friendly interface and affordable pricing, Woord is a great choice for individuals and businesses looking to add speech capabilities to their applications.
TTS Generator AI
TTS Generator AI is a free online text-to-speech tool that leverages cutting-edge AI technology to convert written text into high-quality, natural-sounding audio. This tool is invaluable for a variety of users, including students who need auditory learning materials, researchers who want to listen to long documents, and professionals seeking to make their written content more accessible. One of the standout features of TTS Tool is its ability to support a range of text formats, from simple text files to complex PDFs, making it incredibly versatile.

AI Voice Generator
AI Voice Generator is a Telegram bot that converts text into audio using artificial intelligence. It offers a variety of neural voices, making it easy to create natural-sounding voiceovers. The bot is simple to use, and you can generate audio in seconds.
Speech Parody
Create speech transcript parodies. Copyright (C) 2023, Sourceduty - All Rights Reserved.

Video GPT
AI Video Maker. Generate videos for social media - YouTube, Instagram, TikTok and more! Free text to video & speech tool with AI Avatars, TTS, music, and stock footage.
Chat with GPT 4o ("Omni") Assistant
Try the new AI chat model: GPT 4o ("Omni") Assistant. It's faster and better than regular GPT. Plus it will incorporate speech-to-text, intelligence, and speech-to-text capabilities with extra low latency.

Business intelligence
We provide you with intelligent text generation capabilities to help you create high-quality text content in various applications.
Universal Bilingual Translator
The universal bilingual translation GPT is suitable for dialogue between different languages, simultaneous interpretation, and other speaking scenarios. Starts with a pair of language name, such as "Chinese English", "English French"
Rhetoric Analyzer
Expert in Rhetorical Analysis, providing detailed text analysis and insights.
AI Phonetics and Reading Coach with Speech
Phonetics and reading coach with interactive voice capabilities, tailored for adult beginners.

speech-to-speech
This repository implements a speech-to-speech cascaded pipeline with consecutive parts including Voice Activity Detection (VAD), Speech to Text (STT), Language Model (LM), and Text to Speech (TTS). It aims to provide a fully open and modular approach by leveraging models available on the Transformers library via the Hugging Face hub. The code is designed for easy modification, with each component implemented as a class. Users can run the pipeline either on a server/client approach or locally, with detailed setup and usage instructions provided in the readme.

openedai-speech
OpenedAI Speech is a free, private text-to-speech server compatible with the OpenAI audio/speech API. It offers custom voice cloning and supports various models like tts-1 and tts-1-hd. Users can map their own piper voices and create custom cloned voices. The server provides multilingual support with XTTS voices and allows fixing incorrect sounds with regex. Recent changes include bug fixes, improved error handling, and updates for multilingual support. Installation can be done via Docker or manual setup, with usage instructions provided. Custom voices can be created using Piper or Coqui XTTS v2, with guidelines for preparing audio files. The tool is suitable for tasks like generating speech from text, creating custom voices, and multilingual text-to-speech applications.
talk-to-chatgpt
Talk-To-ChatGPT is a Google Chrome and Microsoft Edge extension that enables users to interact with the ChatGPT AI using voice commands for speech recognition and text-to-speech responses. The tool enhances the conversational experience by allowing users to speak to the AI and receive spoken responses, making interactions more natural and engaging. It also supports ElevenLabs API integration for creating custom voices for text-to-speech. The extension provides settings for voice, language, and more, and can be installed from the Chrome and Edge web stores or manually. While the project has been discontinued due to upcoming desktop apps from OpenAI, it has been used to assist individuals with disabilities and the elderly in interacting with ChatGPT.
END-TO-END-GENERATIVE-AI-PROJECTS
The 'END TO END GENERATIVE AI PROJECTS' repository is a collection of awesome industry projects utilizing Large Language Models (LLM) for various tasks such as chat applications with PDFs, image to speech generation, video transcribing and summarizing, resume tracking, text to SQL conversion, invoice extraction, medical chatbot, financial stock analysis, and more. The projects showcase the deployment of LLM models like Google Gemini Pro, HuggingFace Models, OpenAI GPT, and technologies such as Langchain, Streamlit, LLaMA2, LLaMAindex, and more. The repository aims to provide end-to-end solutions for different AI applications.
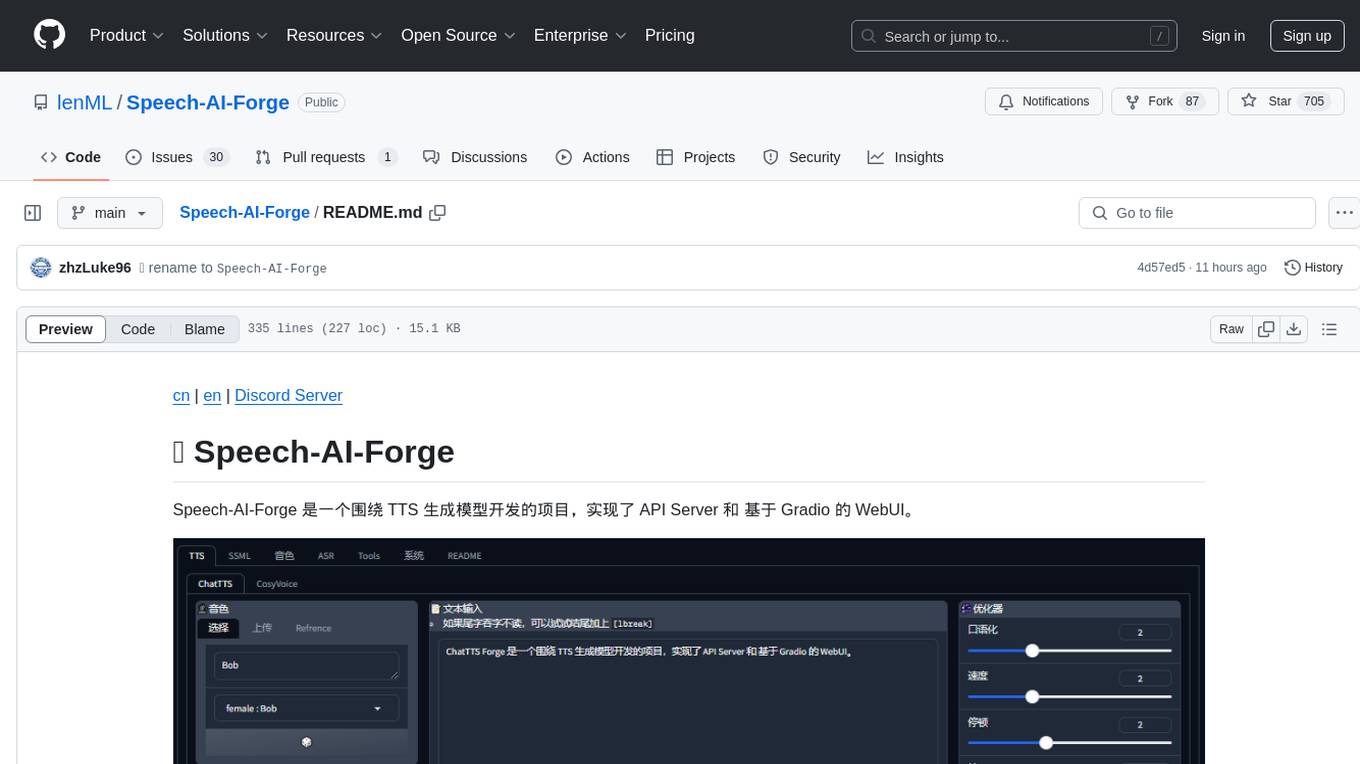
Speech-AI-Forge
Speech-AI-Forge is a project developed around TTS generation models, implementing an API Server and a WebUI based on Gradio. The project offers various ways to experience and deploy Speech-AI-Forge, including online experience on HuggingFace Spaces, one-click launch on Colab, container deployment with Docker, and local deployment. The WebUI features include TTS model functionality, speaker switch for changing voices, style control, long text support with automatic text segmentation, refiner for ChatTTS native text refinement, various tools for voice control and enhancement, support for multiple TTS models, SSML synthesis control, podcast creation tools, voice creation, voice testing, ASR tools, and post-processing tools. The API Server can be launched separately for higher API throughput. The project roadmap includes support for various TTS models, ASR models, voice clone models, and enhancer models. Model downloads can be manually initiated using provided scripts. The project aims to provide inference services and may include training-related functionalities in the future.
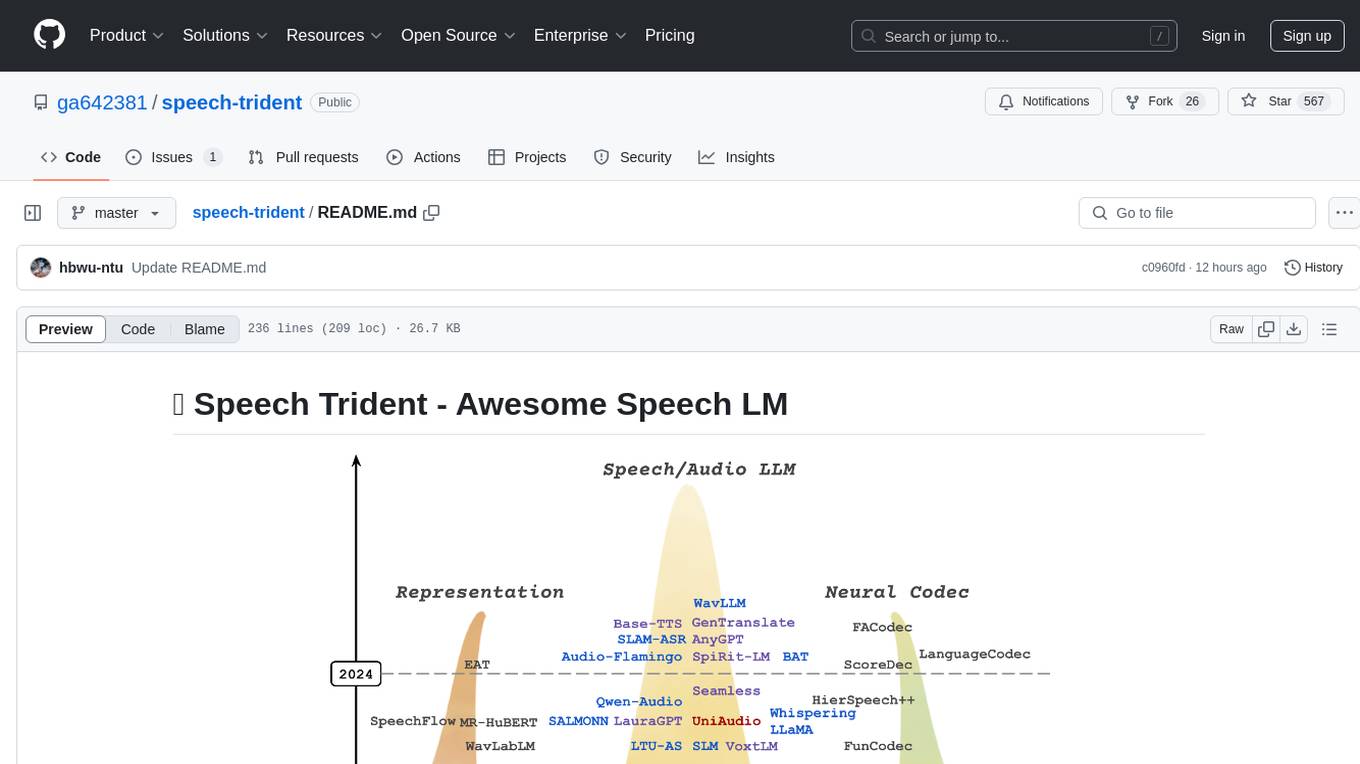
speech-trident
Speech Trident is a repository focusing on speech/audio large language models, covering representation learning, neural codec, and language models. It explores speech representation models, speech neural codec models, and speech large language models. The repository includes contributions from various researchers and provides a comprehensive list of speech/audio language models, representation models, and codec models.

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text

bark.cpp
Bark.cpp is a C/C++ implementation of the Bark model, a real-time, multilingual text-to-speech generation model. It supports AVX, AVX2, and AVX512 for x86 architectures, and is compatible with both CPU and GPU backends. Bark.cpp also supports mixed F16/F32 precision and 4-bit, 5-bit, and 8-bit integer quantization. It can be used to generate realistic-sounding audio from text prompts.

tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.
MeloTTS
MeloTTS is a high-quality multi-lingual text-to-speech library by MyShell.ai. It supports various languages including English (American, British, Indian, Australian), Spanish, French, Chinese, Japanese, and Korean. The Chinese speaker also supports mixed Chinese and English. The library is fast enough for CPU real-time inference and offers features like using without installation, local installation, and training on custom datasets. The Python API and model cards are available in the repository and on HuggingFace. The community can join the Discord channel for discussions and collaboration opportunities. Contributions are welcome, and the library is under the MIT License. MeloTTS is based on TTS, VITS, VITS2, and Bert-VITS2.
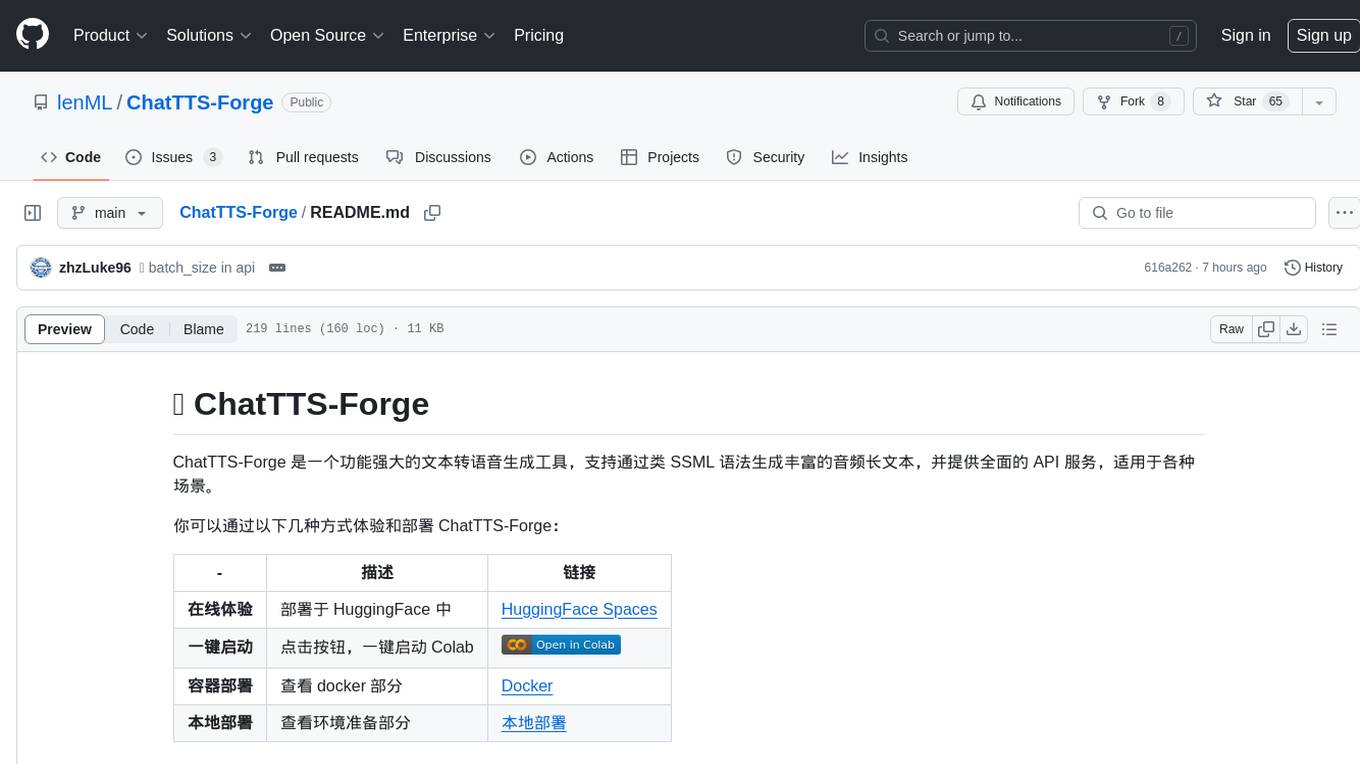
ChatTTS-Forge
ChatTTS-Forge is a powerful text-to-speech generation tool that supports generating rich audio long texts using a SSML-like syntax and provides comprehensive API services, suitable for various scenarios. It offers features such as batch generation, support for generating super long texts, style prompt injection, full API services, user-friendly debugging GUI, OpenAI-style API, Google-style API, support for SSML-like syntax, speaker management, style management, independent refine API, text normalization optimized for ChatTTS, and automatic detection and processing of markdown format text. The tool can be experienced and deployed online through HuggingFace Spaces, launched with one click on Colab, deployed using containers, or locally deployed after cloning the project, preparing models, and installing necessary dependencies.

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.
EmotiVoice
EmotiVoice is a powerful and modern open-source text-to-speech engine that supports emotional synthesis, enabling users to create speech with a wide range of emotions such as happy, excited, sad, and angry. It offers over 2000 different voices in both English and Chinese. Users can access EmotiVoice through an easy-to-use web interface or a scripting interface for batch generation of results. The tool is continuously evolving with new features and updates, prioritizing community input and user feedback.
pyht
pyht is a Python SDK for the PlayHT's AI Text-to-Speech API, allowing users to convert text into high-quality audio streams in humanlike voice. It supports real-time text-to-speech streaming, pre-built and custom voices, various audio formats, and different sample rates.
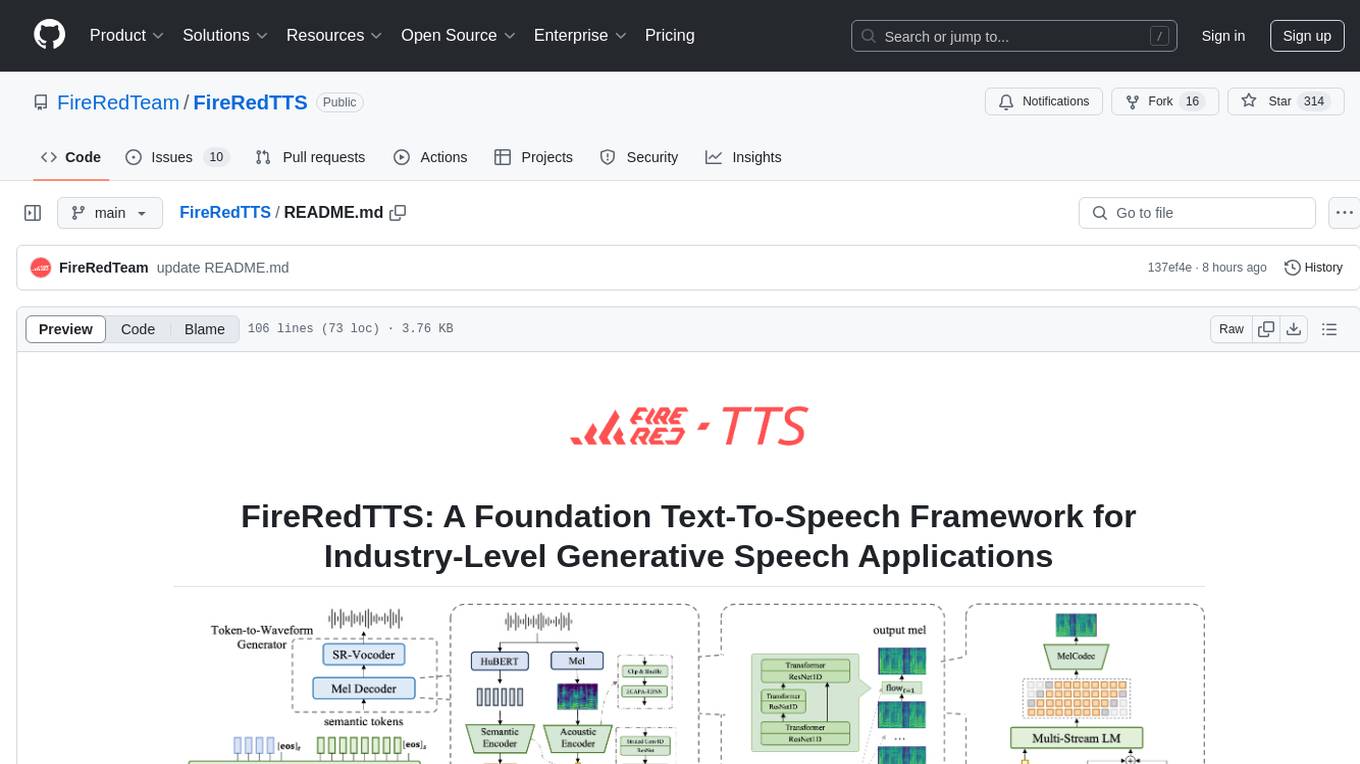
FireRedTTS
FireRedTTS is a foundation text-to-speech framework designed for industry-level generative speech applications. It offers a rich-punctuation model with expanded punctuation coverage and enhanced audio production consistency. The tool provides pre-trained checkpoints, inference code, and an interactive demo space. Users can clone the repository, create a conda environment, download required model files, and utilize the tool for synthesizing speech in various languages. FireRedTTS aims to enhance stability and provide controllable human-like speech generation capabilities.
openai-edge-tts
This project provides a local, OpenAI-compatible text-to-speech (TTS) API using `edge-tts`. It emulates the OpenAI TTS endpoint (`/v1/audio/speech`), enabling users to generate speech from text with various voice options and playback speeds, just like the OpenAI API. `edge-tts` uses Microsoft Edge's online text-to-speech service, making it completely free. The project supports multiple audio formats, adjustable playback speed, and voice selection options, providing a flexible and customizable TTS solution for users.
AivisSpeech
AivisSpeech is a Japanese text-to-speech software based on the VOICEVOX editor UI. It incorporates the AivisSpeech Engine for generating emotionally rich voices easily. It supports AIVMX format voice synthesis model files and specific model architectures like Style-Bert-VITS2. Users can download AivisSpeech and AivisSpeech Engine for Windows and macOS PCs, with minimum memory requirements specified. The development follows the latest version of VOICEVOX, focusing on minimal modifications, rebranding only where necessary, and avoiding refactoring. The project does not update documentation, maintain test code, or refactor unused features to prevent conflicts with VOICEVOX.

LLMVoX
LLMVoX is a lightweight 30M-parameter, LLM-agnostic, autoregressive streaming Text-to-Speech (TTS) system designed to convert text outputs from Large Language Models into high-fidelity streaming speech with low latency. It achieves significantly lower Word Error Rate compared to speech-enabled LLMs while operating at comparable latency and speech quality. Key features include being lightweight & fast with only 30M parameters, LLM-agnostic for easy integration with existing models, multi-queue streaming for continuous speech generation, and multilingual support for easy adaptation to new languages.
TTS-WebUI
TTS WebUI is a comprehensive tool for text-to-speech synthesis, audio/music generation, and audio conversion. It offers a user-friendly interface for various AI projects related to voice and audio processing. The tool provides a range of models and extensions for different tasks, along with integrations like Silly Tavern and OpenWebUI. With support for Docker setup and compatibility with Linux and Windows, TTS WebUI aims to facilitate creative and responsible use of AI technologies in a user-friendly manner.

wunjo.wladradchenko.ru
Wunjo AI is a comprehensive tool that empowers users to explore the realm of speech synthesis, deepfake animations, video-to-video transformations, and more. Its user-friendly interface and privacy-first approach make it accessible to both beginners and professionals alike. With Wunjo AI, you can effortlessly convert text into human-like speech, clone voices from audio files, create multi-dialogues with distinct voice profiles, and perform real-time speech recognition. Additionally, you can animate faces using just one photo combined with audio, swap faces in videos, GIFs, and photos, and even remove unwanted objects or enhance the quality of your deepfakes using the AI Retouch Tool. Wunjo AI is an all-in-one solution for your voice and visual AI needs, offering endless possibilities for creativity and expression.