
Next-Generation-LLM-based-Recommender-Systems-Survey
The official GitHub page for the survey paper "Towards Next-Generation LLM-based Recommender Systems: A Survey and Beyond". And this paper is under review.
Stars: 84
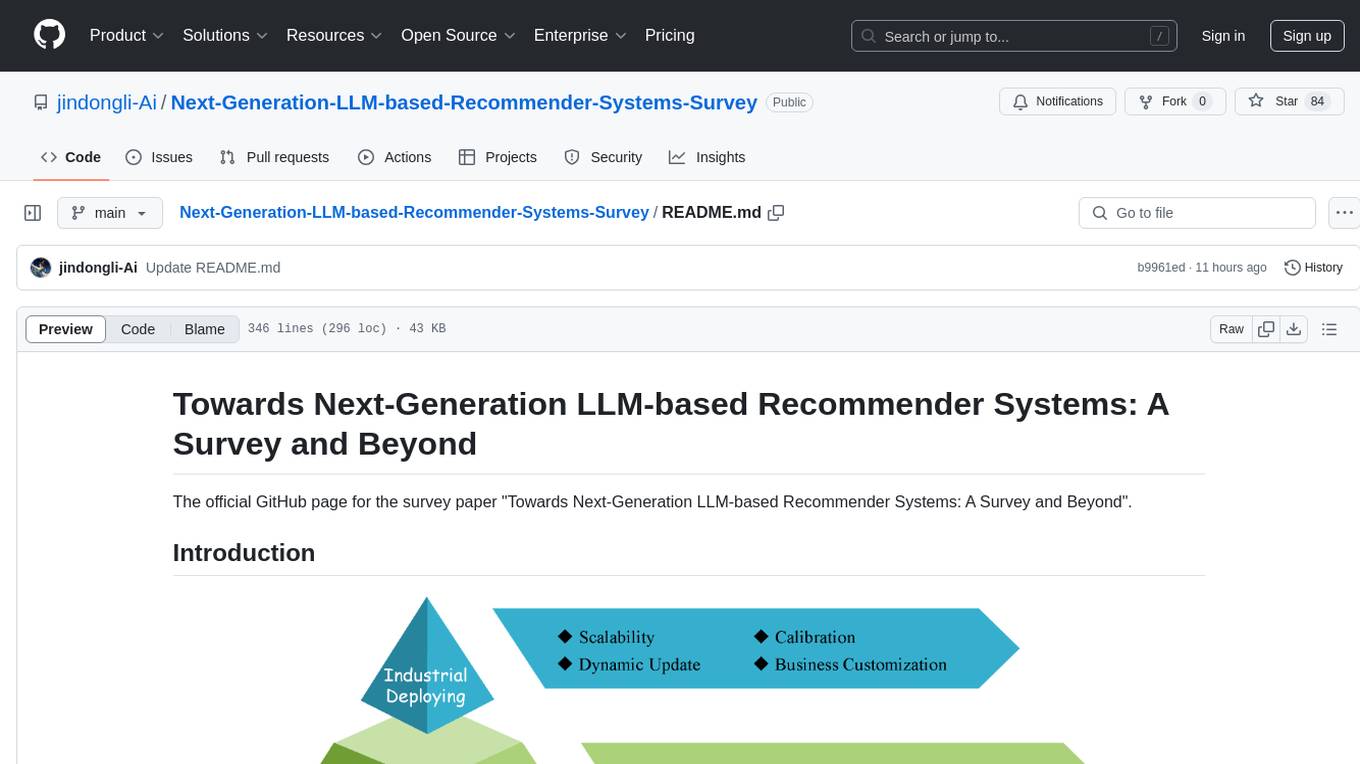
The Next-Generation LLM-based Recommender Systems Survey is a comprehensive overview of the latest advancements in recommender systems leveraging Large Language Models (LLMs). The survey covers various paradigms, approaches, and applications of LLMs in recommendation tasks, including generative and non-generative models, multimodal recommendations, personalized explanations, and industrial deployment. It discusses the comparison with existing surveys, different paradigms, and specific works in the field. The survey also addresses challenges and future directions in the domain of LLM-based recommender systems.
README:
The official GitHub page for the survey paper "Towards Next-Generation LLM-based Recommender Systems: A Survey and Beyond".

| Paper | Non-Gen. RS | Gen. RS | Scen. | Aca. | Ind. | Pipeline | Highlights |
|---|---|---|---|---|---|---|---|
| 'A survey on large language models for recommendation' | ✅ | ✅ | common (all kinds) | ✅ | (1) Discriminative LLM4REC (2) Generative LLM4REC Modeling Paradigms: (i) LLM Embeddings + RS (ii) LLM Tokens + RS (iii) LLM as RS | focuses on expanding the capacity of language models | |
| 'How Can Recommender Systems Benefit from Large Language Models: A Survey' | ✅ | common (all kinds) | ✅ | (1) Where to adapt to LLM (2) How to adapt to LLM | from the angle of the whole pipeline in industrial recommender systems | ||
| 'A Survey on Large Language Models for Personalized and Explainable Recommendations' | ✅ | personalized and explainable RecSys | ✅ | (1) Explanation Generating for Recommendation | focuses on utilizing LLMs for personalized explanation generating task | ||
| 'Recommender systems in the era of large language models (llms)' | ✅ | common (all kinds) | ✅ | (1) Pre-training (2) Fine-tuning (3) Prompting | comprehensively reviews such domain-specific techniques for adapting LLMs to recommendations | ||
| 'A Review of Modern Recommender Systems Using Generative Models (Gen-RecSys)' | ✅ | (1) interaction-driven (2) text-driven (3) multimodal | ✅ | (1) Generative Models for Interaction-Driven Recommendation (2) Large Language Models in Recommendation (3) Generative Multimodal Recommendation Systems | aims to connect the key advancements in RS using Generative Models (Gen-RecSys) | ||
| Multimodal Pretraining, Adaptation, and Generation for Recommendation: A Survey | ✅ | multimodal recommendation | ✅ | (1) Multimodal Pretraining for Recommendation (2) Multimodal Adaption for Recommendation (3) Multimodal Generation for Recommendation | seeks to provide a comprehensive exploration of the latest advancements and future trajectories in multimodal pretraining, adaptation, and generation techniques, as well as their applications to recommender systems | ||
| 'Large language models for generative recommendation: A survey and visionary discussions' | ✅ | common (all kinds) | ✅ | (1) ID Creation Methods (2) How to Do Generative Recommendation | reviews the recent progress of LLM-based generative recommendation and provides a general formulation for each generative recommendation task according to relevant research | ||
| Ours | ✅ | ✅ | common (all kinds) | ✅ | ✅ | (1) Representing and Understanding (2) Scheming and Utilizing (3) Industrial Deploying | (1) reviews existing works from the perspective of recommender system community (2) clearly discuss the gap from academic research to industrial application |
(Gen.: Generative, RS: Recommendation System, Scen.: Scenarios, Aca.: Academic, Ind.: Industrial)




- LLaRA: Large Language-Recommendation Assistant
- DRDT: Dynamic Reflection with Divergent Thinking for LLM-based Sequential Recommendation
- Modeling User Viewing Flow using Large Language Models for Article Recommendation
- Harnessing Large Language Models for Text-Rich Sequential Recommendation
- FineRec: Exploring Fine-grained Sequential Recommendation
- Enhancing Sequential Recommendation via LLM-based Semantic Embedding Learning
- A Multi-facet Paradigm to Bridge Large Language Model and Recommendation
- Understanding Before Recommendation: Semantic Aspect-Aware Review Exploitation via Large Language Models
- Representation Learning with Large Language Models for Recommendation
- LLM-Enhanced User-Item Interactions: Leveraging Edge Information for Optimized Recommendations
- GenRec: Large Language Model for Generative Recommendation
- IDGenRec: LLM-RecSys Alignment with Textual ID Learning
- Collaborative Large Language Model for Recommender Systems
- Multiple Key-value Strategy in Recommendation Systems Incorporating Large Language Model
- LLMRec: Large Language Models with Graph Augmentation for Recommendation
- InteraRec: Interactive Recommendations Using Multimodal Large Language Models
- Zero-Shot Recommendations with Pre-Trained Large Language Models for Multimodal Nudging
- Large Language Models for Next Point-of-Interest Recommendation
- Heterogeneous Knowledge Fusion: A Novel Approach for Personalized Recommendation via LLM
- MMREC: LLM Based Multi-Modal Recommender System
- Harnessing Multimodal Large Language Models for Multimodal Sequential Recommendation
- X-Reflect: Cross-Reflection Prompting for Multimodal Recommendation
- Understanding Before Recommendation: Semantic Aspect-Aware Review Exploitation via Large Language Models
- Learning Structure and Knowledge Aware Representation with Large Language Models for Concept Recommendation
- LLM-Guided Multi-View Hypergraph Learning for Human-Centric Explainable Recommendation
- RDRec: Rationale Distillation for LLM-based Recommendation
- User-Centric Conversational Recommendation: Adapting the Need of User with Large Language Models
- LLMRG: Improving Recommendations through Large Language Model Reasoning Graphs
- Unlocking the Potential of Large Language Models for Explainable Recommendations
- Fine-Tuning Large Language Model Based Explainable Recommendation with Explainable Quality Reward
- LLM4Vis: Explainable Visualization Recommendation using ChatGPT
- Navigating User Experience of ChatGPT-based Conversational Recommender Systems: The Effects of Prompt Guidance and Recommendation Domain
- DRE: Generating Recommendation Explanations by Aligning Large Language Models at Data-level
- Uncertainty-Aware Explainable Recommendation with Large Language Models
- Where to Move Next: Zero-shot Generalization of LLMs for Next POI Recommendation
- Leveraging ChatGPT for Automated Human-centered Explanations in Recommender Systems
- Logic-Scaffolding: Personalized Aspect-Instructed Recommendation Explanation Generation using LLMs
- Leveraging Large Language Models in Conversational Recommender Systems
- Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System
- Leveraging Large Language Models for Recommendation and Explanation
- GPT as a Baseline for Recommendation Explanation Texts
- Supporting Student Decisions on Learning Recommendations: An LLM-Based Chatbot with Knowledge Graph Contextualization for Conversational Explainability and Mentoring
- Knowledge Graphs as Context Sources for LLM-Based Explanations of Learning Recommendations
- BookGPT: A General Framework for Book Recommendation Empowered by Large Language Model
- LLMRec: Benchmarking Large Language Models on Recommendation Task
- PAP-REC: Personalized Automatic Prompt for Recommendation Language Model
- RecMind: Large Language Model Powered Agent For Recommendation
- Prompt Distillation for Efficient LLM-based Recommendation
- Rethinking Large Language Model Architectures for Sequential Recommendations
- LLMRec: Benchmarking Large Language Models on Recommendation Task
- Improving Sequential Recommendations with LLMs
- An Unified Search and Recommendation Foundation Model for Cold-Start Scenario
- Recommender AI Agent: Integrating Large Language Models for Interactive Recommendations
- Leveraging Large Language Models for Sequential Recommendation
- A Large Language Model Enhanced Conversational Recommender System
- Exploring Fine-tuning ChatGPT for News Recommendation
- Aligning Large Language Models with Recommendation Knowledge
- Conversational Recommender System and Large Language Model Are Made for Each Other in E-commerce Pre-sales Dialogue
- Data-Efficient Fine-Tuning for LLM-based Recommendation
- Large Language Model with Graph Convolution for Recommendation
- A Bi-Step Grounding Paradigm for Large Language Models in Recommendation Systems
- Learning Structure and Knowledge Aware Representation with Large Language Models for Concept Recommendation
- LoRec: Large Language Model for Robust Sequential Recommendation against Poisoning Attacks
- To Recommend or Not: Recommendability Identification in Conversations with Pre-trained Language Models
- Large Language Models for Next Point-of-Interest Recommendation
- Leveraging large language models in conversational recommender systems
- Fine-Tuning Large Language Model Based Explainable Recommendation with Explainable Quality Reward
- Enhancing Recommendation Diversity by Re-ranking with Large Language Models
- NoteLLM: A Retrievable Large Language Model for Note Recommendation
- Harnessing Large Language Models for Text-Rich Sequential Recommendation
- LLM4DSR: Leveraing Large Language Model for Denoising Sequential Recommendation
- Beyond Inter-Item Relations: Dynamic Adaptive Mixture-of-Experts for LLM-Based Sequential Recommendation
- Improving Sequential Recommendations with LLMs
- A Multi-facet Paradigm to Bridge Large Language Model and Recommendation
- Heterogeneous Knowledge Fusion: A Novel Approach for Personalized Recommendation via LLM
- Exploring Large Language Model for Graph Data Understanding in Online Job Recommendations
- Item-side Fairness of Large Language Model-based Recommendation System
- Integrating Large Language Models into Recommendation via Mutual Augmentation and Adaptive Aggregation
- RecRanker: Instruction Tuning Large Language Model as Ranker for Top-k Recommendation
- E4SRec: An Elegant Effective Efficient Extensible Solution of Large Language Models for Sequential Recommendation
- LLaRA: Large Language-Recommendation Assistant
- Unlocking the Potential of Large Language Models for Explainable Recommendations
- LlamaRec: Two-Stage Recommendation using Large Language Models for Ranking
- Review-driven Personalized Preference Reasoning with Large Language Models for Recommendation
- ONCE: Boosting Content-based Recommendation with Both Open- and Closed-source Large Language Models
- Breaking the Length Barrier: LLM-Enhanced CTR Prediction in Long Textual User Behaviors
- TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation
- Harnessing Large Language Models for Text-Rich Sequential Recommendation
- E4SRec: An Elegant Effective Efficient Extensible Solution of Large Language Models for Sequential Recommendation
- Enhancing Content-based Recommendation via Large Language Model
- Large Language Model Distilling Medication Recommendation Model
- LLaRA: Large Language-Recommendation Assistant
- Exact and Efficient Unlearning for Large Language Model-based Recommendation
- Towards Efficient and Effective Unlearning of Large Language Models for Recommendation
- LLM-based Federated Recommendation
- Aligning Large Language Models for Controllable Recommendations
- Lifelong Personalized Low-Rank Adaptation of Large Language Models for Recommendation
- Harnessing Multimodal Large Language Models for Multimodal Sequential Recommendation
- GANPrompt: Enhancing Robustness in LLM-Based Recommendations with GAN-Enhanced Diversity Prompts
- DELRec: Distilling Sequential Pattern to Enhance LLM-based Recommendation
- CoLLM: Integrating Collaborative Embeddings into Large Language Models for Recommendation
- Knowledge Plugins: Enhancing Large Language Models for Domain-Specific Recommendations
- DRDT: Dynamic Reflection with Divergent Thinking for LLM-based Sequential Recommendation
- Zero-Shot Next-Item Recommendation using Large Pretrained Language Models
- Zero-Shot Recommendations with Pre-Trained Large Language Models for Multimodal Nudging
- Large Language Models are Competitive Near Cold-start Recommenders for Language- and Item-based Preferences
- Large Language Model Augmented Narrative Driven Recommendations
- ChatGPT for Conversational Recommendation: Refining Recommendations by Reprompting with Feedback
- Federated Recommendation via Hybrid Retrieval Augmented Generation
- Re2LLM: Reflective Reinforcement Large Language Model for Session-based Recommendation
- RecMind: Large Language Model Powered Agent For Recommendation
- Reindex-Then-Adapt: Improving Large Language Models for Conversational Recommendation
- Improve Temporal Awareness of LLMs for Sequential Recommendation
- Tired of Plugins? Large Language Models Can Be End-To-End Recommenders
- Where to Move Next: Zero-shot Generalization of LLMs for Next POI Recommendation
- Large Language Models are Zero-Shot Rankers for Recommender Systems
- InteraRec: Interactive Recommendations Using Multimodal Large Language Models
- Large Language Models are Learnable Planners for Long-Term Recommendation
- Logic-Scaffolding: Personalized Aspect-Instructed Recommendation Explanation Generation using LLMs
- ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation
- RDRec: Rationale Distillation for LLM-based Recommendation
- LLM-Guided Multi-View Hypergraph Learning for Human-Centric Explainable Recommendation
- Large Language Model Interaction Simulator for Cold-Start Item Recommendation
- LLMRec: Large Language Models with Graph Augmentation for Recommendation
- LKPNR: LLM and KG for Personalized News Recommendation Framework
- LLM4Vis: Explainable Visualization Recommendation using ChatGPT
- LLMRG: Improving Recommendations through Large Language Model Reasoning Graphs
- Large Language Models for Intent-Driven Session Recommendations
- Understanding Before Recommendation: Semantic Aspect-Aware Review Exploitation via Large Language Models
- Leveraging Large Language Models (LLMs) to Empower Training-Free Dataset Condensation for Content-Based Recommendation
- CoRAL: Collaborative Retrieval-Augmented Large Language Models Improve Long-tail Recommendation
- Common Sense Enhanced Knowledge-based Recommendation with Large Language Model
- DynLLM: When Large Language Models Meet Dynamic Graph Recommendation
- FineRec: Exploring Fine-grained Sequential Recommendation
- LLM4SBR: A Lightweight and Effective Framework for Integrating Large Language Models in Session-based Recommendation
- Breaking the Barrier: Utilizing Large Language Models for Industrial Recommendation Systems through an Inferential Knowledge Graph
- Sequential Recommendation with Latent Relations based on Large Language Model
- News Recommendation with Category Description by a Large Language Model
- PAP-REC: Personalized Automatic Prompt for Recommendation Language Model
- Large Language Models as Data Augmenters for Cold-Start Item Recommendation
- MMREC: LLM Based Multi-Modal Recommender System
- DaRec: A Disentangled Alignment Framework for Large Language Model and Recommender System
- X-Reflect: Cross-Reflection Prompting for Multimodal Recommendation
- LLM4MSR: An LLM-Enhanced Paradigm for Multi-Scenario Recommendation
- LLM-Based Aspect Augmentations for Recommendation Systems
- Towards Open-World Recommendation with Knowledge Augmentation from Large Language Models
- LLM-Rec: Personalized Recommendation via Prompting Large Language Models
- PMG: Personalized Multimodal Generation with Large Language Models
- Language-Based User Profiles for Recommendation
- Prompt Tuning Large Language Models on Personalized Aspect Extraction for Recommendations
- RecPrompt: A Prompt Tuning Framework for News Recommendation Using Large Language Models
- Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System
- DRE: Generating Recommendation Explanations by Aligning Large Language Models at Data-level
- Efficient and Responsible Adaptation of Large Language Models for Robust Top-k Recommendations
- Uncovering ChatGPT’s Capabilities in Recommender Systems
- New Community Cold-Start Recommendation: A Novel Large Language Model-based Method
- LANE: Logic Alignment of Non-tuning Large Language Models and Online Recommendation Systems for Explainable Reason Generation
- GPT4Rec: A Generative Framework for Personalized Recommendation and User Interests Interpretation
- LLM-Enhanced User-Item Interactions: Leveraging Edge Information for Optimized Recommendations
- RecGPT: Generative Personalized Prompts for Sequential Recommendation via ChatGPT Training Paradigm
- RecGPT: Generative Pre-training for Text-based Recommendation
- IDGenRec: LLM-RecSys Alignment with Textual ID Learning
- Collaborative large language model for recommender systems
- CALRec: Contrastive Alignment of Generative LLMs For Sequential Recommendation
- How to Index Item IDs for Recommendation Foundation Models
- Supporting Student Decisions on Learning Recommendations: An LLM-based Chatbot with Knowledge Graph Contextualization for Conversational Explainability and Mentoring
- Large Language Models as Zero-Shot Conversational Recommenders
- Bookgpt: A General Framework for Book Recommendation Empowered by Large Language Model
- ONCE: Boosting Content-based Recommendation with Both Open- and Closed-source Large Language Models
| Model/Paper | Task/Domain | Data Modality | Main Techniques | Source Code |
|---|---|---|---|---|
| 'Multiple Key-value Strategy in Recommendation Systems Incorporating Large Language Model' | sequential recommendation | multiple key-value data | pre-train, instruction tuning | ~ |
| 'Large language models as zero-shot conversational recommenders' | zero-shot conversational recommendation | text (conversational recommendation dataset) | prompt | https://github.com/AaronHeee/LLMs-as-Zero-Shot-Conversational-RecSys |
| 'Bookgpt: A general framework for book recommendation empowered by large language model' | book recommendation | interaction, text | prompt | https://github.com/zhiyulee-RUC/bookgpt |
| 'How to index item ids for recommendation foundation models' | sequential recommendation | interaction, text | item ID indexing | https://github.com/Wenyueh/LLM-RecSys-ID |
| 'Supporting student decisions on learning recommendations: An llm-based chatbot with knowledge graph contextualization for conversational explainability and mentoring' | learning recommendation | graph data, text | ~ | ~ |
| 'GPT4Rec: A generative framework for personalized recommendation and user interests interpretation' | next-item prediction | interaction, item title | prompt, pre-train, fine-tune | ~ |
| 'LLM-Enhanced User-Item Interactions: Leveraging Edge Information for Optimized Recommendations' | item recommendation | interaction | prompt, pre-train, fine-tune | https://github.com/anord-wang/LLM4REC.git |
| 'RecGPT: Generative Personalized Prompts for Sequential Recommendation via ChatGPT Training Paradigm' | sequential recommendation | sequences of words | prompt, pre-train, fine-tune | ~ |
| 'RecGPT: Generative Pre-training for Text-based Recommendation' | rating prediction, sequential recommendation | text | pre-train, fine-tune | https://github.com/VinAIResearch/RecGPT |
| 'Genrec: Large language model for generative recommendation' | movie recommendation | interaction, textual-information | prompt, pre-train, fine-tune | https://github.com/rutgerswiselab/GenRec |
| 'IDGenRec: LLM-RecSys Alignment with Textual ID Learning' | sequential recommendation, zero-shot recommendation | interaction, text | natural language generation | https://github.com/agiresearch/IDGenRec |
| 'Collaborative large language model for recommender systems' | item recommendation | interaction, text | prompt, pre-train, fine-tune | https://github.com/yaochenzhu/llm4rec |
| 'PMG: Personalized Multimodal Generation with Large Language Models' | personalized multimodal generation | text, image, audio, etc | prompt, pre-train, Prompt Tuning (P-Tuning V2) | https://github.com/mindspore-lab/models/tree/master/research/huawei-noah/PMG |
| 'CALRec: Contrastive Alignment of Generative LLMs For Sequential Recommendation' | sequential recommendation | interaction, text | pre-train, fine-tune, contrastive learning | ~ |
| 'Once: Boosting content-based recommendation with both open-and closed-source large language models' | content-based recommendation (news recommendation, book recommendation) | interaction, text | prompt | https://github.com/Jyonn/ONCE |
- Breaking the Barrier: Utilizing Large Language Models for Industrial Recommendation Systems through an Inferential Knowledge Graph
- A Large Language Model Enhanced Sequential Recommender for Joint Video and Comment Recommendation
- RecGPT: Generative Personalized Prompts for Sequential Recommendation via ChatGPT Training Paradigm
- Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Application
- Enhancing Sequential Recommendation via LLM-based Semantic Embedding Learning
- Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations
- Breaking the length barrier: LLM-Enhanced CTR Prediction in Long Textual User Behaviors
- LLM4SBR: A Lightweight and Effective Framework for Integrating Large Language Models in Session-based Recommendation
- An Unified Search and Recommendation Foundation Model for Cold-Start Scenario
- Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Application
- Breaking the Barrier: Utilizing Large Language Models for Industrial Recommendation Systems through an Inferential Knowledge Graph
- DynLLM: When Large Language Models Meet Dynamic Graph Recommendation
- Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations
- COSMO: A large-scale e-commerce common sense knowledge generation and serving system at Amazon
- Modeling User Viewing Flow using Large Language Models for Article Recommendation
- Ad Recommendation in a Collapsed and Entangled World
- NoteLLM: A Retrievable Large Language Model for Note Recommendation
- Beyond Labels: Leveraging Deep Learning and LLMs for Content Metadata
- TRAWL: External Knowledge-Enhanced Recommendation with LLM Assistance
- Heterogeneous Knowledge Fusion: A Novel Approach for Personalized Recommendation via LLM
- COSMO: A large-scale e-commerce common sense knowledge generation and serving system at Amazon
| Model/Paper | Company | Task/Domain | Highlights |
|---|---|---|---|
| LLM-KERec, 'Breaking the Barrier: Utilizing Large Language Models for Industrial Recommendation Systems through an Inferential Knowledge Graph' | Ant Group | E-commerce Recommendation | Constructs a complementary knowledge graph by LLMs |
| LSVCR, 'A Large Language Model Enhanced Sequential Recommender for Joint Video and Comment Recommendation' | KuaiShou | Video Recommendation | Sequential recommendation model and supplemental LLM recommender |
| RecGPT, 'RecGPT: Generative Personalized Prompts for Sequential Recommendation via ChatGPT Training Paradigm' | KuaiShou | Sequential Recommendation | Models user behavior sequences using personalized prompts with ChatGPT. |
| SAID, 'Enhancing sequential recommendation via llm-based semantic embedding learning' | Ant Group | Sequential Recommendation | Explicitly learns Semantically Aligned item ID embeddings based on texts by utilizing LLMs. |
| BAHE, 'Breaking the length barrier: Llm-enhanced CTR prediction in long textual user behaviors' | Ant Group | CTR Prediction | Uses LLM's shallow layers for user behavior embeddings and deep layers for behavior interactions. |
| 'LLM4SBR: A Lightweight and Effective Framework for Integrating Large Language Models in Session-based Recommendation' | HuaWei | Session-based Recommendation | In short sequence data, LLM can infer preferences directly leveraging its language understanding capability without fine-tuning |
| DARE, 'A Decoding Acceleration Framework for Industrial Deployable LLM-based Recommender Systems' | HuaWei | CTR prediction | Identifies the issue of inference efficiency during deploying LLM-based recommendations and introduces speculative decoding to accelerate recommendation knowledge generation. |
| 'An Unified Search and Recommendation Foundation Model for Cold-Start Scenario' | Ant Group | Multi-domain Recommendation | LLM is applied to the S&R multi-domain foundation model to extract domain-invariant text features. |
| LEARN, 'Knowledge Adaptation from Large Language Model to Recommendation for Practical Industrial Application' | Kuaishou | Sequential Recommendation | Integrates the open-world knowledge encapsulated in LLMs into RS. |
| 'DynLLM: When Large Language Models Meet Dynamic Graph Recommendation' | Alibaba | E-commerce Recommendations | Generates user profiles based on textual historical purchase records and obtaining users' embeddings by LLM. |
| HSTU, 'Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations' | Meta | Generating user action sequence | Explores the scaling laws of RS; Optimising model architecture to accelerate inference. |
| COSMO, 'COSMO: A large-scale e-commerce common sense knowledge generation and serving system at Amazon' | Amazon | Semantic relevance and session-based recommendation | Is the first industry-scale knowledge system that adopts LLM to construct high-quality knowledge graphs and serve online applications |
| SINGLE, 'Modeling User Viewing Flow using Large Language Models for Article Recommendation' | Taobao, Alibaba | Article Recommendation | Summarises long articles and the user constant preference from view history by gpt-3.5-turbo or ChatGLM-6B. |
| 'Ad Recommendation in a Collapsed and Entangled World' | Tencent | Ad Recommendation | Obtains user or items embeddings by LLM. |
| NoteLLM, 'NoteLLM: A Retrievable Large Language Model for Note Recommendation' | xiaohongshu.com | Item-to-item Note Recommendation | Obtains article embeddings and generate hashtags/categories information by LLaMA-2. |
| Genre Spectrum, 'Beyond Labels: Leveraging Deep Learning and LLMs for Content Metadata' | tubi.tv | Movie & TV series Recommendation | Obtains content metadata embeddings by LLM. |
| TRAWL, 'TRAWL: External Knowledge-Enhanced Recommendation with LLM Assistance' | WeChat, Tencent | Article Recommendation | Uses Qwen1.5-7B extract knowledge from articles. |
| HKFR, 'Heterogeneous Knowledge Fusion: A Novel Approach for Personalized Recommendation via LLM' | Meituan | Catering Recommendation | Uses heterogeneous knowledge fusion for recommendations. |


For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for Next-Generation-LLM-based-Recommender-Systems-Survey
Similar Open Source Tools
Next-Generation-LLM-based-Recommender-Systems-Survey
The Next-Generation LLM-based Recommender Systems Survey is a comprehensive overview of the latest advancements in recommender systems leveraging Large Language Models (LLMs). The survey covers various paradigms, approaches, and applications of LLMs in recommendation tasks, including generative and non-generative models, multimodal recommendations, personalized explanations, and industrial deployment. It discusses the comparison with existing surveys, different paradigms, and specific works in the field. The survey also addresses challenges and future directions in the domain of LLM-based recommender systems.

awesome-generative-ai-guide
This repository serves as a comprehensive hub for updates on generative AI research, interview materials, notebooks, and more. It includes monthly best GenAI papers list, interview resources, free courses, and code repositories/notebooks for developing generative AI applications. The repository is regularly updated with the latest additions to keep users informed and engaged in the field of generative AI.
MMLU-Pro
MMLU-Pro is an enhanced benchmark designed to evaluate language understanding models across broader and more challenging tasks. It integrates more challenging, reasoning-focused questions and increases answer choices per question, significantly raising difficulty. The dataset comprises over 12,000 questions from academic exams and textbooks across 14 diverse domains. Experimental results show a significant drop in accuracy compared to the original MMLU, with greater stability under varying prompts. Models utilizing Chain of Thought reasoning achieved better performance on MMLU-Pro.
Academic_LLM_Sec_Papers
Academic_LLM_Sec_Papers is a curated collection of academic papers related to LLM Security Application. The repository includes papers sorted by conference name and published year, covering topics such as large language models for blockchain security, software engineering, machine learning, and more. Developers and researchers are welcome to contribute additional published papers to the list. The repository also provides information on listed conferences and journals related to security, networking, software engineering, and cryptography. The papers cover a wide range of topics including privacy risks, ethical concerns, vulnerabilities, threat modeling, code analysis, fuzzing, and more.
awesome-lifelong-llm-agent
This repository is a collection of papers and resources related to Lifelong Learning of Large Language Model (LLM) based Agents. It focuses on continual learning and incremental learning of LLM agents, identifying key modules such as Perception, Memory, and Action. The repository serves as a roadmap for understanding lifelong learning in LLM agents and provides a comprehensive overview of related research and surveys.

LMOps
LMOps is a research initiative focusing on fundamental research and technology for building AI products with foundation models, particularly enabling AI capabilities with Large Language Models (LLMs) and Generative AI models. The project explores various aspects such as prompt optimization, longer context handling, LLM alignment, acceleration of LLMs, LLM customization, and understanding in-context learning. It also includes tools like Promptist for automatic prompt optimization, Structured Prompting for efficient long-sequence prompts consumption, and X-Prompt for extensible prompts beyond natural language. Additionally, LLMA accelerators are developed to speed up LLM inference by referencing and copying text spans from documents. The project aims to advance technologies that facilitate prompting language models and enhance the performance of LLMs in various scenarios.
Prompt_Engineering
Prompt Engineering Techniques is a comprehensive repository for learning, building, and sharing prompt engineering techniques, from basic concepts to advanced strategies for leveraging large language models. It provides step-by-step tutorials, practical implementations, and a platform for showcasing innovative prompt engineering techniques. The repository covers fundamental concepts, core techniques, advanced strategies, optimization and refinement, specialized applications, and advanced applications in prompt engineering.
awesome-MLSecOps
Awesome MLSecOps is a curated list of open-source tools, resources, and tutorials for MLSecOps (Machine Learning Security Operations). It includes a wide range of security tools and libraries for protecting machine learning models against adversarial attacks, as well as resources for AI security, data anonymization, model security, and more. The repository aims to provide a comprehensive collection of tools and information to help users secure their machine learning systems and infrastructure.
rlhf_thinking_model
This repository is a collection of research notes and resources focusing on training large language models (LLMs) and Reinforcement Learning from Human Feedback (RLHF). It includes methodologies, techniques, and state-of-the-art approaches for optimizing preferences and model alignment in LLM training. The purpose is to serve as a reference for researchers and engineers interested in reinforcement learning, large language models, model alignment, and alternative RL-based methods.
langkit
LangKit is an open-source text metrics toolkit for monitoring language models. It offers methods for extracting signals from input/output text, compatible with whylogs. Features include text quality, relevance, security, sentiment, toxicity analysis. Installation via PyPI. Modules contain UDFs for whylogs. Benchmarks show throughput on AWS instances. FAQs available.

aimet
AIMET is a library that provides advanced model quantization and compression techniques for trained neural network models. It provides features that have been proven to improve run-time performance of deep learning neural network models with lower compute and memory requirements and minimal impact to task accuracy. AIMET is designed to work with PyTorch, TensorFlow and ONNX models. We also host the AIMET Model Zoo - a collection of popular neural network models optimized for 8-bit inference. We also provide recipes for users to quantize floating point models using AIMET.
DecryptPrompt
This repository does not provide a tool, but rather a collection of resources and strategies for academics in the field of artificial intelligence who are feeling depressed or overwhelmed by the rapid advancements in the field. The resources include articles, blog posts, and other materials that offer advice on how to cope with the challenges of working in a fast-paced and competitive environment.
LLMSys-PaperList
This repository provides a comprehensive list of academic papers, articles, tutorials, slides, and projects related to Large Language Model (LLM) systems. It covers various aspects of LLM research, including pre-training, serving, system efficiency optimization, multi-model systems, image generation systems, LLM applications in systems, ML systems, survey papers, LLM benchmarks and leaderboards, and other relevant resources. The repository is regularly updated to include the latest developments in this rapidly evolving field, making it a valuable resource for researchers, practitioners, and anyone interested in staying abreast of the advancements in LLM technology.
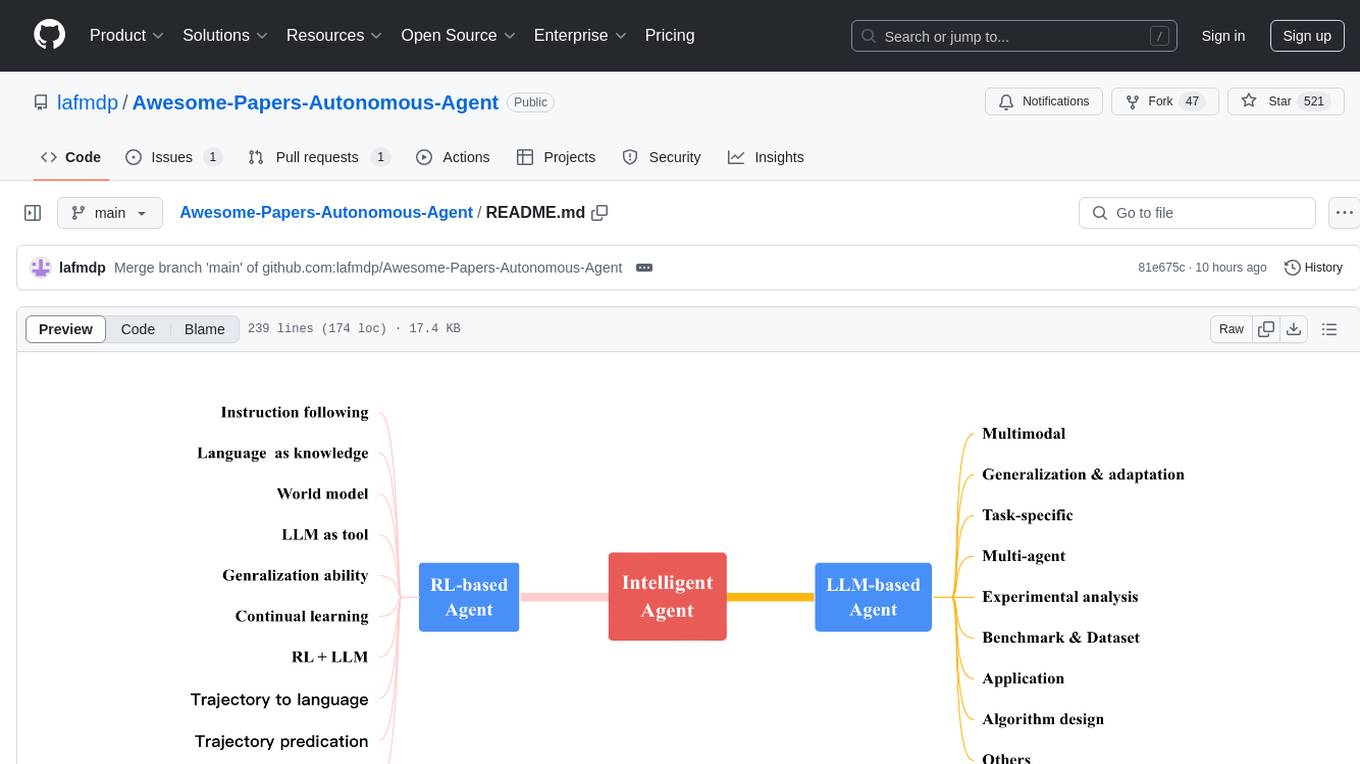
Awesome-Papers-Autonomous-Agent
Awesome-Papers-Autonomous-Agent is a curated collection of recent papers focusing on autonomous agents, specifically interested in RL-based agents and LLM-based agents. The repository aims to provide a comprehensive resource for researchers and practitioners interested in intelligent agents that can achieve goals, acquire knowledge, and continually improve. The collection includes papers on various topics such as instruction following, building agents based on world models, using language as knowledge, leveraging LLMs as a tool, generalization across tasks, continual learning, combining RL and LLM, transformer-based policies, trajectory to language, trajectory prediction, multimodal agents, training LLMs for generalization and adaptation, task-specific designing, multi-agent systems, experimental analysis, benchmarking, applications, algorithm design, and combining with RL.

awesome-LLM-resourses
A comprehensive repository of resources for Chinese large language models (LLMs), including data processing tools, fine-tuning frameworks, inference libraries, evaluation platforms, RAG engines, agent frameworks, books, courses, tutorials, and tips. The repository covers a wide range of tools and resources for working with LLMs, from data labeling and processing to model fine-tuning, inference, evaluation, and application development. It also includes resources for learning about LLMs through books, courses, and tutorials, as well as insights and strategies from building with LLMs.
For similar tasks
Next-Generation-LLM-based-Recommender-Systems-Survey
The Next-Generation LLM-based Recommender Systems Survey is a comprehensive overview of the latest advancements in recommender systems leveraging Large Language Models (LLMs). The survey covers various paradigms, approaches, and applications of LLMs in recommendation tasks, including generative and non-generative models, multimodal recommendations, personalized explanations, and industrial deployment. It discusses the comparison with existing surveys, different paradigms, and specific works in the field. The survey also addresses challenges and future directions in the domain of LLM-based recommender systems.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.