
facefusion
Industry leading face manipulation platform
Stars: 26820
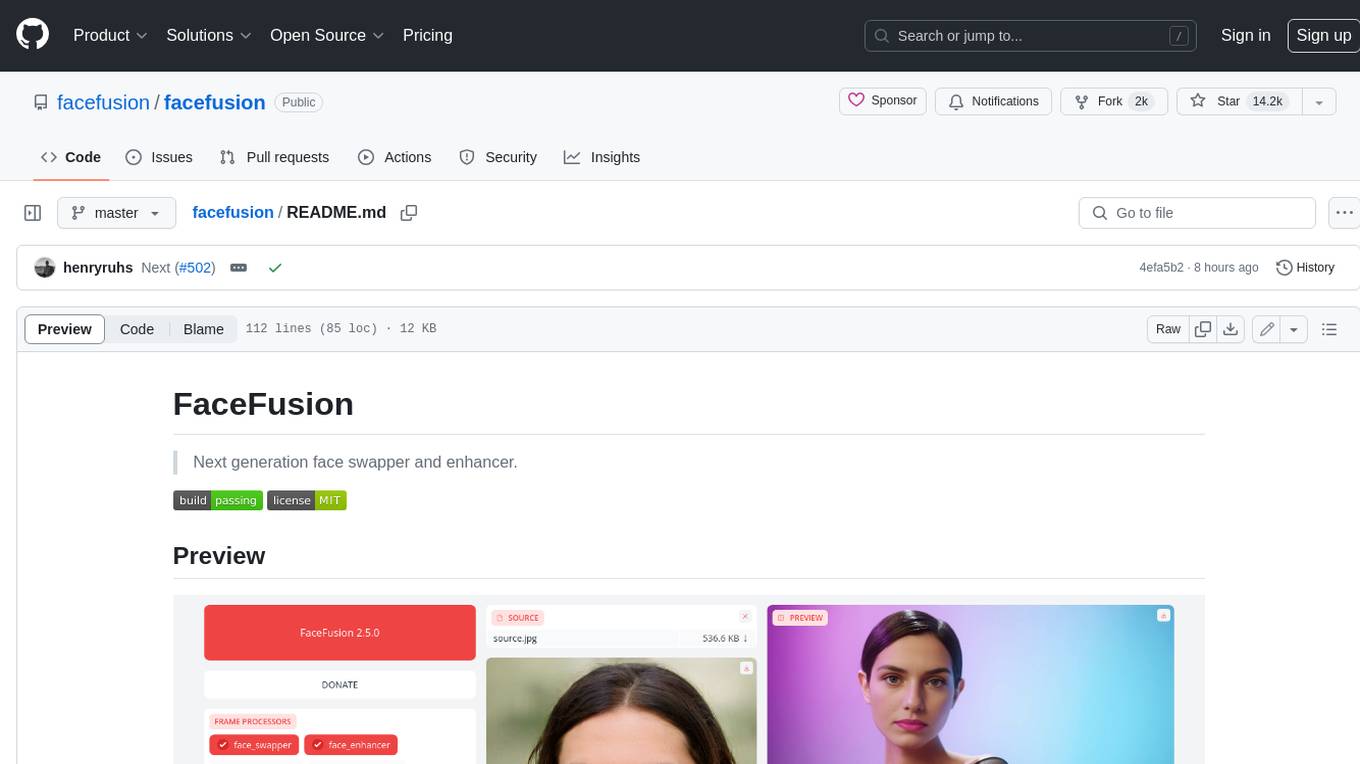
FaceFusion is a next-generation face swapper and enhancer that allows users to seamlessly swap faces in images and videos, as well as enhance facial features for a more polished and refined look. With its advanced deep learning models, FaceFusion provides users with a wide range of options for customizing their face swaps and enhancements, making it an ideal tool for content creators, artists, and anyone looking to explore their creativity with facial manipulation.
README:
Industry leading face manipulation platform.


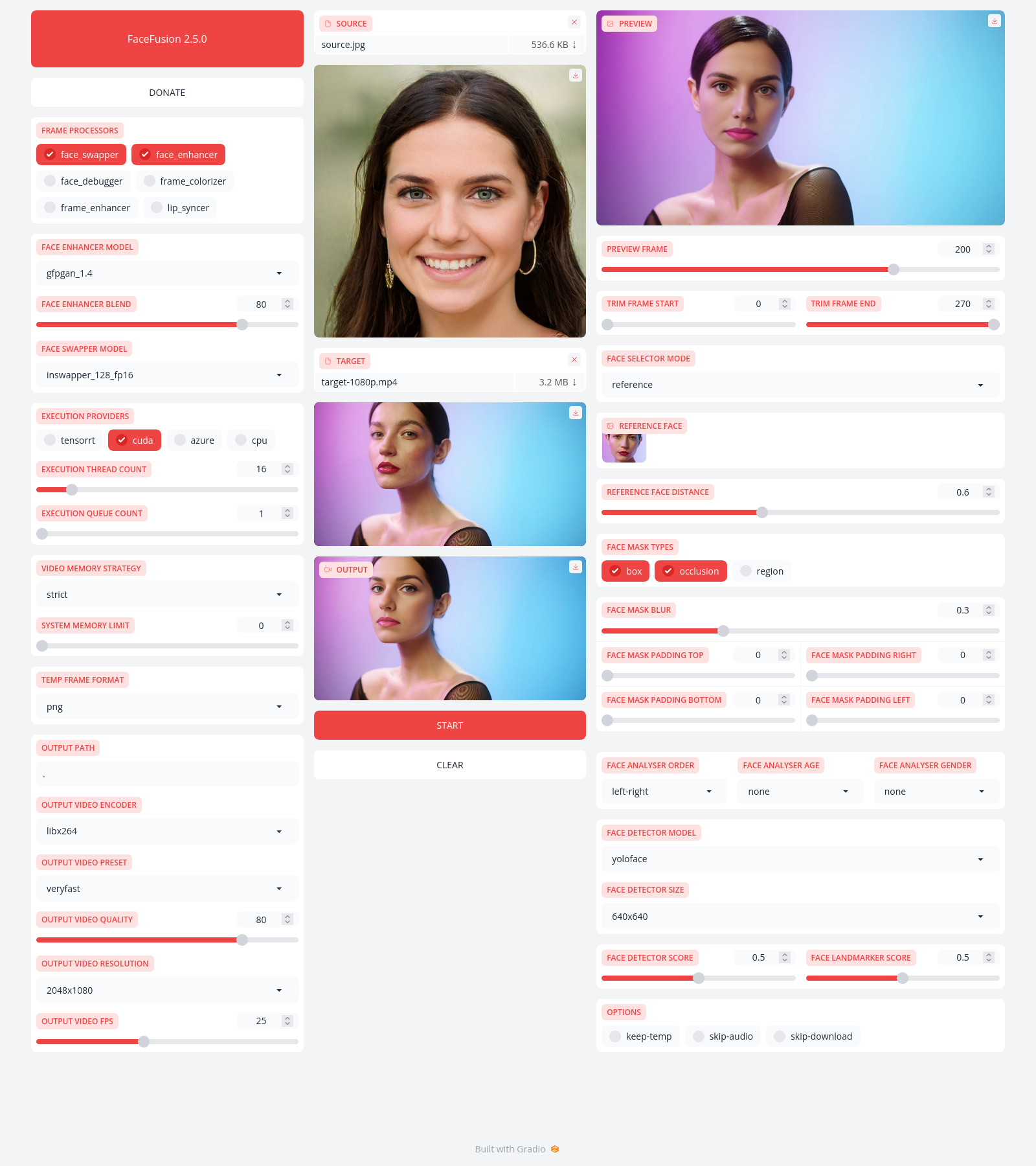
Be aware, the installation needs technical skills and is not recommended for beginners. In case you are not comfortable using a terminal, our Windows Installer and macOS Installer get you started.
Run the command:
python facefusion.py [commands] [options]
options:
-h, --help show this help message and exit
-v, --version show program's version number and exit
commands:
run run the program
headless-run run the program in headless mode
batch-run run the program in batch mode
force-download force automate downloads and exit
benchmark benchmark the program
job-list list jobs by status
job-create create a drafted job
job-submit submit a drafted job to become a queued job
job-submit-all submit all drafted jobs to become a queued jobs
job-delete delete a drafted, queued, failed or completed job
job-delete-all delete all drafted, queued, failed and completed jobs
job-add-step add a step to a drafted job
job-remix-step remix a previous step from a drafted job
job-insert-step insert a step to a drafted job
job-remove-step remove a step from a drafted job
job-run run a queued job
job-run-all run all queued jobs
job-retry retry a failed job
job-retry-all retry all failed jobs
Read the documentation for a deep dive.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for facefusion
Similar Open Source Tools
facefusion
FaceFusion is a next-generation face swapper and enhancer that allows users to seamlessly swap faces in images and videos, as well as enhance facial features for a more polished and refined look. With its advanced deep learning models, FaceFusion provides users with a wide range of options for customizing their face swaps and enhancements, making it an ideal tool for content creators, artists, and anyone looking to explore their creativity with facial manipulation.
ResuLLMe
ResuLLMe is a prototype tool that uses Large Language Models (LLMs) to enhance résumés by tailoring them to help candidates avoid common mistakes while applying for jobs. It acts as a smart career advisor to check and improve résumés. The tool supports both OpenAI and Gemini, providing users with smarter, more accurate career guidance. Users can upload their CV as a PDF or Word Document, and ResuLLMe uses LLMs to improve the résumé following published guidelines, convert it to a JSON Resume format, and render it using LaTeX to generate an enhanced PDF resume.
tegon
Tegon is an open-source AI-First issue tracking tool designed for engineering teams. It aims to simplify task management by leveraging AI and integrations to automate task creation, prioritize tasks, and enhance bug resolution. Tegon offers features like issues tracking, automatic title generation, AI-generated labels and assignees, custom views, and upcoming features like sprints and task prioritization. It integrates with GitHub, Slack, and Sentry to streamline issue tracking processes. Tegon also plans to introduce AI Agents like PR Agent and Bug Agent to enhance product management and bug resolution. Contributions are welcome, and the product is licensed under the MIT License.
pearai-app
PearAI is an AI-powered code editor designed to enhance development by reducing the amount of coding required. It is a fork of VSCode and the main functionality lies within the 'extension/pearai' submodule. Users can contribute to the project by fixing issues, submitting bugs and feature requests, reviewing source code changes, and improving documentation. The tool aims to streamline the coding process and provide an efficient environment for developers to work in.
dialog
Dialog is an API-focused tool designed to simplify the deployment of Large Language Models (LLMs) for programmers interested in AI. It allows users to deploy any LLM based on the structure provided by dialog-lib, enabling them to spend less time coding and more time training their models. The tool aims to humanize Retrieval-Augmented Generative Models (RAGs) and offers features for better RAG deployment and maintenance. Dialog requires a knowledge base in CSV format and a prompt configuration in TOML format to function effectively. It provides functionalities for loading data into the database, processing conversations, and connecting to the LLM, with options to customize prompts and parameters. The tool also requires specific environment variables for setup and configuration.

promptmage
PromptMage simplifies the process of creating and managing LLM workflows as a self-hosted solution. It offers an intuitive interface for prompt testing and comparison, incorporates version control features, and aims to improve productivity in both small teams and large enterprises. The tool bridges the gap in LLM workflow management, empowering developers, researchers, and organizations to make LLM technology more accessible and manageable for the next wave of AI innovations.
AppFlowy
AppFlowy.IO is an open-source alternative to Notion, providing users with control over their data and customizations. It aims to offer functionality, data security, and cross-platform native experience to individuals, as well as building blocks and collaboration infra services to enterprises and hackers. The tool is built with Flutter and Rust, supporting multiple platforms and emphasizing long-term maintainability. AppFlowy prioritizes data privacy, reliable native experience, and community-driven extensibility, aiming to democratize the creation of complex workplace management tools.
ainneve
Ainneve is an example game for Evennia, created by the Evennia community as a base for learning and building off of. It is currently in early development stages and undergoing major refactoring. The game provides a starting point for users to explore game systems and world settings, with extensive documentation available. Installation is straightforward, with pre-configured settings and clear instructions for setting up and starting the server. The project welcomes contributions and offers opportunities for users to get involved by checking open issues and joining the community Discord channel. Ainneve is licensed under the BSD license.
chatgpt-universe
ChatGPT is a large language model that can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in a conversational way. It is trained on a massive amount of text data, and it is able to understand and respond to a wide range of natural language prompts. Here are 5 jobs suitable for this tool, in lowercase letters: 1. content writer 2. chatbot assistant 3. language translator 4. creative writer 5. researcher

CodeProject.AI-Server
CodeProject.AI Server is a standalone, self-hosted, fast, free, and open-source Artificial Intelligence microserver designed for any platform and language. It can be installed locally without the need for off-device or out-of-network data transfer, providing an easy-to-use solution for developers interested in AI programming. The server includes a HTTP REST API server, backend analysis services, and the source code, enabling users to perform various AI tasks locally without relying on external services or cloud computing. Current capabilities include object detection, face detection, scene recognition, sentiment analysis, and more, with ongoing feature expansions planned. The project aims to promote AI development, simplify AI implementation, focus on core use-cases, and leverage the expertise of the developer community.
OpenHands
OpenHands is a community focused on AI-driven development, offering a Software Agent SDK, CLI, Local GUI, Cloud deployment, and Enterprise solutions. The SDK is a Python library for defining and running agents, the CLI provides an easy way to start using OpenHands, the Local GUI allows running agents on a laptop with REST API, the Cloud deployment offers hosted infrastructure with integrations, and the Enterprise solution enables self-hosting via Kubernetes with extended support and access to the research team. OpenHands is available under the MIT license.

agent-lightning
Agent Lightning is a lightweight and efficient tool for automating repetitive tasks in the field of data analysis and machine learning. It provides a user-friendly interface to create and manage automated workflows, allowing users to easily schedule and execute data processing, model training, and evaluation tasks. With its intuitive design and powerful features, Agent Lightning streamlines the process of building and deploying machine learning models, making it ideal for data scientists, machine learning engineers, and AI enthusiasts looking to boost their productivity and efficiency in their projects.
AgentStack
AgentStack is a command-line tool that helps users create AI agent projects quickly and efficiently. It offers CLI utilities for code generation and simplifies the process of building agents and tasks. The tool is designed to work on macOS, Windows, and Linux, providing a seamless experience for developers. AgentStack aims to streamline the development process by offering pre-built templates, easy access to tools, and a curated experience on top of popular agent frameworks and LLM providers. It is not a low-code solution but rather a head-start for starting agent projects from scratch.

morphik-core
Morphik is an AI-native toolset designed to help developers integrate context into their AI applications by providing tools to store, represent, and search unstructured data. It offers features such as multimodal search, fast metadata extraction, and integrations with existing tools. Morphik aims to address the challenges of traditional AI approaches that struggle with visually rich documents and provide a more comprehensive solution for understanding and processing complex data.

lollms-webui
LoLLMs WebUI (Lord of Large Language Multimodal Systems: One tool to rule them all) is a user-friendly interface to access and utilize various LLM (Large Language Models) and other AI models for a wide range of tasks. With over 500 AI expert conditionings across diverse domains and more than 2500 fine tuned models over multiple domains, LoLLMs WebUI provides an immediate resource for any problem, from car repair to coding assistance, legal matters, medical diagnosis, entertainment, and more. The easy-to-use UI with light and dark mode options, integration with GitHub repository, support for different personalities, and features like thumb up/down rating, copy, edit, and remove messages, local database storage, search, export, and delete multiple discussions, make LoLLMs WebUI a powerful and versatile tool.
agents-js
LiveKit Agents for Node.js is a framework designed for building realtime, programmable voice agents that can see, hear, and understand. It includes support for OpenAI Realtime API, allowing for ultra-low latency WebRTC transport between GPT-4o and users' devices. The framework provides concepts like Agents, Workers, and Plugins to create complex tasks. It offers a CLI interface for running agents and a versatile web frontend called 'playground' for building and testing agents. The framework is suitable for developers looking to create conversational voice agents with advanced capabilities.
For similar tasks
manga-image-translator
Translate texts in manga/images. Some manga/images will never be translated, therefore this project is born. * Image/Manga Translator * Samples * Online Demo * Disclaimer * Installation * Pip/venv * Poetry * Additional instructions for **Windows** * Docker * Hosting the web server * Using as CLI * Setting Translation Secrets * Using with Nvidia GPU * Building locally * Usage * Batch mode (default) * Demo mode * Web Mode * Api Mode * Related Projects * Docs * Recommended Modules * Tips to improve translation quality * Options * Language Code Reference * Translators Reference * GPT Config Reference * Using Gimp for rendering * Api Documentation * Synchronous mode * Asynchronous mode * Manual translation * Next steps * Support Us * Thanks To All Our Contributors :
facefusion
FaceFusion is a next-generation face swapper and enhancer that allows users to seamlessly swap faces in images and videos, as well as enhance facial features for a more polished and refined look. With its advanced deep learning models, FaceFusion provides users with a wide range of options for customizing their face swaps and enhancements, making it an ideal tool for content creators, artists, and anyone looking to explore their creativity with facial manipulation.
aidea
AIdea is an app that integrates mainstream large language models and drawing models, developed using Flutter. The code is completely open-source and supports various functions such as GPT-3.5, GPT-4 from OpenAI, Claude instant, Claude 2.1 from Anthropic, Gemini Pro and visual language models from Google, as well as various Chinese and open-source models. It also supports features like text-to-image, super-resolution, coloring black and white images, artistic fonts, artistic QR codes, and more.
NeuroSandboxWebUI
A simple and convenient interface for using various neural network models. Users can interact with LLM using text, voice, and image input to generate images, videos, 3D objects, music, and audio. The tool supports a wide range of models for different tasks such as image generation, video generation, audio file separation, voice conversion, and more. Users can also view files from the outputs directory in a gallery, download models, change application settings, and check system sensors. The goal of the project is to create an easy-to-use application for utilizing neural network models.
SUPIR
SUPIR is an AI-based image processing and upscaling tool that leverages cutting-edge technology to enhance image quality and resolution. The tool provides users with the ability to upscale images with high generalization and quality, as well as specific settings for light degradation scenarios. It offers a range of models and checkpoints for different use cases, along with detailed instructions for installation and usage. SUPIR also includes features for color fixing, linear CFG adjustments, and various prompts for image enhancement. The tool is designed for non-commercial use only and comes with a contact email for inquiries and permission requests for commercial use.
midjourney-bot
Discord Midjourney Bot is an open-source bot designed for AI enthusiasts, providing various AI art functionalities without any paywalls. Users can enjoy features like text to image conversion, image transformation, logo generation, face swap, image upscaling, and more. The bot aims to offer advanced customizable image generation capabilities, including access to language models and canvas size customization. Additionally, the project is open to partnerships and investments, with opportunities for bloggers to review the product. The bot requires Node v18+ to run and integrates with Replicate API for certain functionalities.
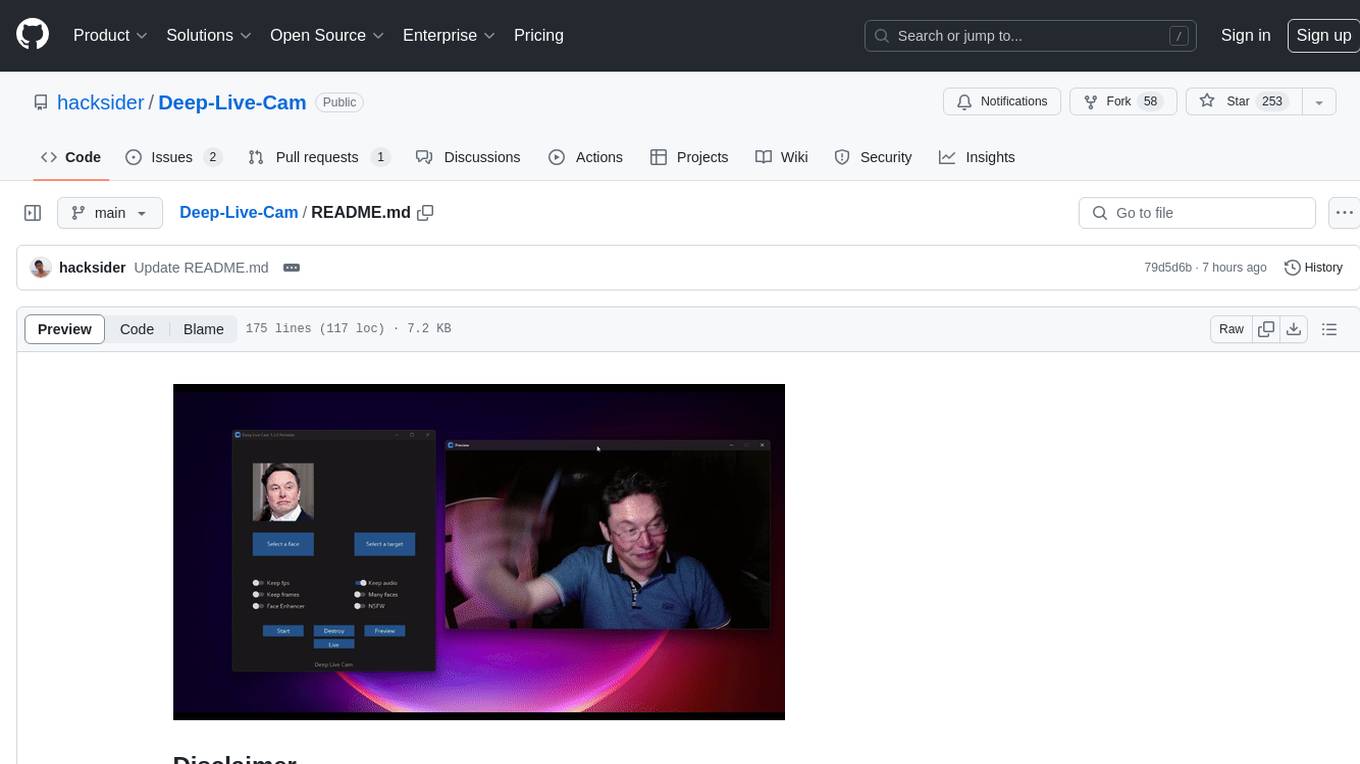
Deep-Live-Cam
Deep-Live-Cam is a software tool designed to assist artists in tasks such as animating custom characters or using characters as models for clothing. The tool includes built-in checks to prevent unethical applications, such as working on inappropriate media. Users are expected to use the tool responsibly and adhere to local laws, especially when using real faces for deepfake content. The tool supports both CPU and GPU acceleration for faster processing and provides a user-friendly GUI for swapping faces in images or videos.
For similar jobs
facefusion
FaceFusion is a next-generation face swapper and enhancer that allows users to seamlessly swap faces in images and videos, as well as enhance facial features for a more polished and refined look. With its advanced deep learning models, FaceFusion provides users with a wide range of options for customizing their face swaps and enhancements, making it an ideal tool for content creators, artists, and anyone looking to explore their creativity with facial manipulation.
forge
Forge is a free and open-source digital collectible card game (CCG) engine written in Java. It is designed to be easy to use and extend, and it comes with a variety of features that make it a great choice for developers who want to create their own CCGs. Forge is used by a number of popular CCGs, including Ascension, Dominion, and Thunderstone.
latentbox
Latent Box is a curated collection of resources for AI, creativity, and art. It aims to bridge the information gap with high-quality content, promote diversity and interdisciplinary collaboration, and maintain updates through community co-creation. The website features a wide range of resources, including articles, tutorials, tools, and datasets, covering various topics such as machine learning, computer vision, natural language processing, generative art, and creative coding.

fabric
Fabric is an open-source framework for augmenting humans using AI. It provides a structured approach to breaking down problems into individual components and applying AI to them one at a time. Fabric includes a collection of pre-defined Patterns (prompts) that can be used for a variety of tasks, such as extracting the most interesting parts of YouTube videos and podcasts, writing essays, summarizing academic papers, creating AI art prompts, and more. Users can also create their own custom Patterns. Fabric is designed to be easy to use, with a command-line interface and a variety of helper apps. It is also extensible, allowing users to integrate it with their own AI applications and infrastructure.
ColorPicker
ColorPicker Max is a powerful and intuitive color selection and manipulation tool that is designed to make working with color easier and more efficient than ever before. With its wide range of features and tools, ColorPicker Max offers an unprecedented level of control and customization over every aspect of color selection and manipulation.
ai-notes
Notes on AI state of the art, with a focus on generative and large language models. These are the "raw materials" for the https://lspace.swyx.io/ newsletter. This repo used to be called https://github.com/sw-yx/prompt-eng, but was renamed because Prompt Engineering is Overhyped. This is now an AI Engineering notes repo.
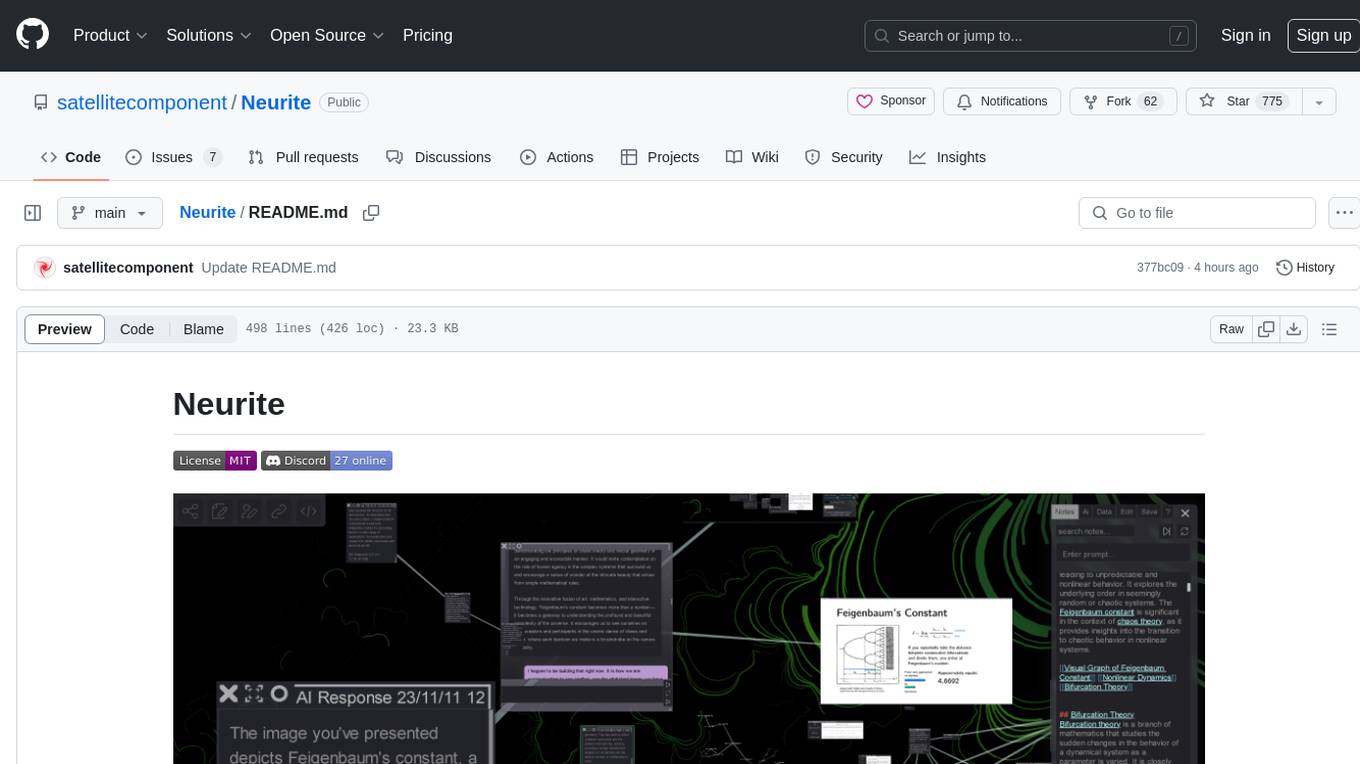
Neurite
Neurite is an innovative project that combines chaos theory and graph theory to create a digital interface that explores hidden patterns and connections for creative thinking. It offers a unique workspace blending fractals with mind mapping techniques, allowing users to navigate the Mandelbrot set in real-time. Nodes in Neurite represent various content types like text, images, videos, code, and AI agents, enabling users to create personalized microcosms of thoughts and inspirations. The tool supports synchronized knowledge management through bi-directional synchronization between mind-mapping and text-based hyperlinking. Neurite also features FractalGPT for modular conversation with AI, local AI capabilities for multi-agent chat networks, and a Neural API for executing code and sequencing animations. The project is actively developed with plans for deeper fractal zoom, advanced control over node placement, and experimental features.
ScribbleArchitect
ScribbleArchitect is a GUI tool designed for generating images from simple brush strokes or Bezier curves in real-time. It is primarily intended for use in architecture and sketching in the early stages of a project. The tool utilizes Stable Diffusion and ControlNet as AI backbone for the generative process, with IP Adapter support and a library of predefined styles. Users can transfer specific styles to their line work, upscale images for high resolution export, and utilize a ControlNet upscaler. The tool also features a screen capture function for working with external tools like Adobe Illustrator or Inkscape.