
InferenceX
Open Source Continuous Inference Benchmarking Qwen3.5, DeepSeek, GPTOSS - GB200 NVL72 vs MI355X vs B200 vs GB300 NVL72 vs H100 & soon™ TPUv6e/v7/Trainium2/3
Stars: 508
InferenceX™ is an open-source benchmarking tool designed to track real-time performance improvements in popular open-source inference frameworks. It runs benchmarks nightly, capturing progress as software stacks evolve. The tool provides a live dashboard for monitoring inference performance. InferenceX™ addresses the challenge of benchmarking quickly evolving software ecosystems by offering continuous benchmarking updates, ensuring that performance metrics remain up-to-date and relevant.
README:
InferenceX™ (formerly InferenceMAX) runs our suite of benchmarks every night, continually re-benchmarking the world’s most popular open-source inference frameworks used by major token factories and models to track real performance in real time. As these software stacks improve, InferenceX™ captures that progress in near real-time, providing a live indicator of inference performance progress. A live dashboard is available for free publicly at https://inferencex.com/.
[!IMPORTANT] Only SemiAnalysisAI/InferenceX repo contains the Official InferenceX™ result, all other forks & repos are Unofficial. The benchmark setup & quality of machines/clouds in unofficial repos may be differ leading to subpar benchmarking. Unofficial must be explicitly labelled as Unofficial. Forks may not remove this disclaimer
Full Article Write Up for InferenceXv2 Full Article Write Up for InferenceXv1
InferenceX™, an open-source, under Apache2 license, automated benchmark designed to move at the same rapid speed as the software ecosystem itself, is built to address this challenge.
LLM Inference performance is driven by two pillars, hardware and software. While hardware innovation drives step jumps in performance every year through the release of new GPUs/XPUs and new systems, software evolves every single day, delivering continuous performance gains on top of these step jumps. Speed is the Moat 🚀
AI software like SGLang, vLLM, TensorRT-LLM, CUDA, ROCm and achieve this continuous improvement in performance through kernel-level optimizations, distributed inference strategies, and scheduling innovations that increase the pareto frontier of performance in incremental releases that can be just days apart.
This pace of software advancement creates a challenge: benchmarks conducted at a fixed point in time quickly go stale and do not represent the performance that can be achieved with the latest software packages.
Thank you to Lisa Su and Anush Elangovan for providing the MI355X and CDNA3 GPUs for this free and open-source project. We want to recognize the many AMD contributors for their responsiveness and for debugging, optimizing, and validating performance across AMD GPUs. We’re also grateful to Jensen Huang and Ian Buck for supporting this open source with access to a GB200 NVL72 rack (through OCI) and B200 GPUs. Thank you to the many NVIDIA contributors from the NVIDIA inference team, NVIDIA Dynamo team.
We also want to recognize the SGLang, vLLM, and TensorRT-LLM maintainers for building a world-class software stack and open sourcing it to the entire world. Finally, we’re grateful to Crusoe, CoreWeave, Nebius, TensorWave, Oracle and TogetherAI for supporting open-source innovation through compute resources, enabling this.
"As we build systems at unprecedented scale, it's critical for the ML community to have open, transparent benchmarks that reflect how inference really performs across hardware and software. InferenceX™'s head-to-head benchmarks cut through the noise and provide a living picture of token throughput, performance per dollar, and tokens per Megawatt. This kind of open source effort strengthens the entire ecosystem and helps everyone, from researchers to operators of frontier datacenters, make smarter decisions." - Peter Hoeschele, VP of Infrastructure and Industrial Compute, OpenAI Stargate
"The gap between theoretical peak and real-world inference throughput is often determined by systems software: inference engine, distributed strategies, and low-level kernels. InferenceX™ is valuable because it benchmarks the latest software showing how optimizations actually play out across various hardware. Open, reproducible results like these help the whole community move faster.” - Tri Dao, Chief Scientist of Together AI & Inventor of Flash Attention
“The industry needs many public, reproducible benchmarks of inference performance. We’re excited to collaborate with InferenceX™ from the vLLM team. More diverse workloads and scenarios that everyone can trust and reference will help the ecosystem move forward. Fair, transparent measurements drive progress across every layer of the stack, from model architectures to inference engines to hardware.” – Simon Mo, vLLM Project Co-Lead
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for InferenceX
Similar Open Source Tools
InferenceX
InferenceX™ is an open-source benchmarking tool designed to track real-time performance improvements in popular open-source inference frameworks. It runs benchmarks nightly, capturing progress as software stacks evolve. The tool provides a live dashboard for monitoring inference performance. InferenceX™ addresses the challenge of benchmarking quickly evolving software ecosystems by offering continuous benchmarking updates, ensuring that performance metrics remain up-to-date and relevant.
InferenceMAX
InferenceMAX™ is an open-source benchmarking tool designed to track real-time performance improvements in popular open-source inference frameworks and models. It runs a suite of benchmarks every night to capture progress in near real-time, providing a live indicator of inference performance. The tool addresses the challenge of rapidly evolving software ecosystems by benchmarking the latest software packages, ensuring that benchmarks do not go stale. InferenceMAX™ is supported by industry leaders and contributors, providing transparent and reproducible benchmarks that help the ML community make informed decisions about hardware and software performance.

metaflow
Metaflow is a user-friendly library designed to assist scientists and engineers in developing and managing real-world data science projects. Initially created at Netflix, Metaflow aimed to enhance the productivity of data scientists working on diverse projects ranging from traditional statistics to cutting-edge deep learning. For further information, refer to Metaflow's website and documentation.
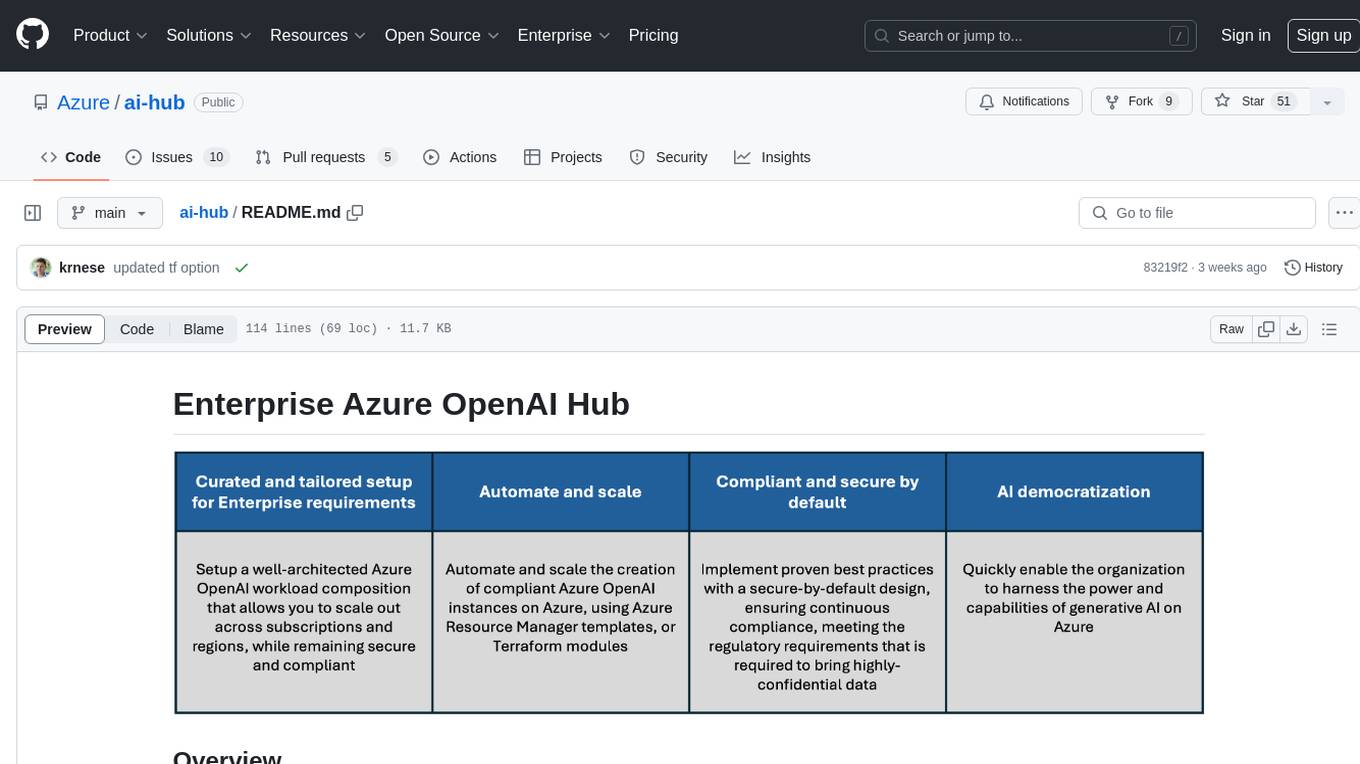
ai-hub
The Enterprise Azure OpenAI Hub is a comprehensive repository designed to guide users through the world of Generative AI on the Azure platform. It offers a structured learning experience to accelerate the transition from concept to production in an Enterprise context. The hub empowers users to explore various use cases with Azure services, ensuring security and compliance. It provides real-world examples and playbooks for practical insights into solving complex problems and developing cutting-edge AI solutions. The repository also serves as a library of proven patterns, aligning with industry standards and promoting best practices for secure and compliant AI development.
foundationallm
FoundationaLLM is a platform designed for deploying, scaling, securing, and governing generative AI in enterprises. It allows users to create AI agents grounded in enterprise data, integrate REST APIs, experiment with various large language models, centrally manage AI agents and their assets, deploy scalable vectorization data pipelines, enable non-developer users to create their own AI agents, control access with role-based access controls, and harness capabilities from Azure AI and Azure OpenAI. The platform simplifies integration with enterprise data sources, provides fine-grain security controls, scalability, extensibility, and addresses the challenges of delivering enterprise copilots or AI agents.
foundationallm
FoundationaLLM is a platform designed for deploying, scaling, securing, and governing generative AI in enterprises. It allows users to create AI agents grounded in enterprise data, integrate REST APIs, experiment with large language models, centrally manage AI agents and assets, deploy scalable vectorization data pipelines, enable non-developer users to create their own AI agents, control access with role-based access controls, and harness capabilities from Azure AI and Azure OpenAI. The platform simplifies integration with enterprise data sources, provides fine-grain security controls, load balances across multiple endpoints, and is extensible to new data sources and orchestrators. FoundationaLLM addresses the need for customized copilots or AI agents that are secure, licensed, flexible, and suitable for enterprise-scale production.
Build-Modern-AI-Apps
This repository serves as a hub for Microsoft Official Build & Modernize AI Applications reference solutions and content. It provides access to projects demonstrating how to build Generative AI applications using Azure services like Azure OpenAI, Azure Container Apps, Azure Kubernetes, and Azure Cosmos DB. The solutions include Vector Search & AI Assistant, Real-Time Payment and Transaction Processing, and Medical Claims Processing. Additionally, there are workshops like the Intelligent App Workshop for Microsoft Copilot Stack, focusing on infusing intelligence into traditional software systems using foundation models and design thinking.
farmvibes-ai
FarmVibes.AI is a repository focused on developing multi-modal geospatial machine learning models for agriculture and sustainability. It enables users to fuse various geospatial and spatiotemporal datasets, such as satellite imagery, drone imagery, and weather data, to generate robust insights for agriculture-related problems. The repository provides fusion workflows, data preparation tools, model training notebooks, and an inference engine to facilitate the creation of geospatial models tailored for agriculture and farming. Users can interact with the tools via a local cluster, REST API, or a Python client, and the repository includes documentation and notebook examples to guide users in utilizing FarmVibes.AI for tasks like harvest date detection, climate impact estimation, micro climate prediction, and crop identification.

learn-generative-ai
Learn Cloud Applied Generative AI Engineering (GenEng) is a course focusing on the application of generative AI technologies in various industries. The course covers topics such as the economic impact of generative AI, the role of developers in adopting and integrating generative AI technologies, and the future trends in generative AI. Students will learn about tools like OpenAI API, LangChain, and Pinecone, and how to build and deploy Large Language Models (LLMs) for different applications. The course also explores the convergence of generative AI with Web 3.0 and its potential implications for decentralized intelligence.
intelligent-app-workshop
Welcome to the envisioning workshop designed to help you build your own custom Copilot using Microsoft's Copilot stack. This workshop aims to rethink user experience, architecture, and app development by leveraging reasoning engines and semantic memory systems. You will utilize Azure AI Foundry, Prompt Flow, AI Search, and Semantic Kernel. Work with Miyagi codebase, explore advanced capabilities like AutoGen and GraphRag. This workshop guides you through the entire lifecycle of app development, including identifying user needs, developing a production-grade app, and deploying on Azure with advanced capabilities. By the end, you will have a deeper understanding of leveraging Microsoft's tools to create intelligent applications.
oci-data-science-ai-samples
The Oracle Cloud Infrastructure Data Science and AI services Examples repository provides demos, tutorials, and code examples showcasing various features of the OCI Data Science service and AI services. It offers tools for data scientists to develop and deploy machine learning models efficiently, with features like Accelerated Data Science SDK, distributed training, batch processing, and machine learning pipelines. Whether you're a beginner or an experienced practitioner, OCI Data Science Services provide the resources needed to build, train, and deploy models easily.
AI-CryptoTrader
AI-CryptoTrader is a state-of-the-art cryptocurrency trading bot that uses ensemble methods to combine the predictions of multiple algorithms. Written in Python, it connects to the Binance trading platform and integrates with Azure for efficiency and scalability. The bot uses technical indicators and machine learning algorithms to generate predictions for buy and sell orders, adjusting to market conditions. While robust, users should be cautious due to cryptocurrency market volatility.
FedML
FedML is a unified and scalable machine learning library for running training and deployment anywhere at any scale. It is highly integrated with FEDML Nexus AI, a next-gen cloud service for LLMs & Generative AI. FEDML Nexus AI provides holistic support of three interconnected AI infrastructure layers: user-friendly MLOps, a well-managed scheduler, and high-performance ML libraries for running any AI jobs across GPU Clouds.

kaapana
Kaapana is an open-source toolkit for state-of-the-art platform provisioning in the field of medical data analysis. The applications comprise AI-based workflows and federated learning scenarios with a focus on radiological and radiotherapeutic imaging. Obtaining large amounts of medical data necessary for developing and training modern machine learning methods is an extremely challenging effort that often fails in a multi-center setting, e.g. due to technical, organizational and legal hurdles. A federated approach where the data remains under the authority of the individual institutions and is only processed on-site is, in contrast, a promising approach ideally suited to overcome these difficulties. Following this federated concept, the goal of Kaapana is to provide a framework and a set of tools for sharing data processing algorithms, for standardized workflow design and execution as well as for performing distributed method development. This will facilitate data analysis in a compliant way enabling researchers and clinicians to perform large-scale multi-center studies. By adhering to established standards and by adopting widely used open technologies for private cloud development and containerized data processing, Kaapana integrates seamlessly with the existing clinical IT infrastructure, such as the Picture Archiving and Communication System (PACS), and ensures modularity and easy extensibility.
husky
Husky is a research-focused programming language designed for next-generation computing. It aims to provide a powerful and ergonomic development experience for various tasks, including system level programming, web/native frontend development, parser/compiler tasks, game development, formal verification, machine learning, and more. With a strong type system and support for human-in-the-loop programming, Husky enables users to tackle complex tasks such as explainable image classification, natural language processing, and reinforcement learning. The language prioritizes debugging, visualization, and human-computer interaction, offering agile compilation and evaluation, multiparadigm support, and a commitment to a good ecosystem.
For similar tasks
InferenceX
InferenceX™ is an open-source benchmarking tool designed to track real-time performance improvements in popular open-source inference frameworks. It runs benchmarks nightly, capturing progress as software stacks evolve. The tool provides a live dashboard for monitoring inference performance. InferenceX™ addresses the challenge of benchmarking quickly evolving software ecosystems by offering continuous benchmarking updates, ensuring that performance metrics remain up-to-date and relevant.

aiges
AIGES is a core component of the Athena Serving Framework, designed as a universal encapsulation tool for AI developers to deploy AI algorithm models and engines quickly. By integrating AIGES, you can deploy AI algorithm models and engines rapidly and host them on the Athena Serving Framework, utilizing supporting auxiliary systems for networking, distribution strategies, data processing, etc. The Athena Serving Framework aims to accelerate the cloud service of AI algorithm models and engines, providing multiple guarantees for cloud service stability through cloud-native architecture. You can efficiently and securely deploy, upgrade, scale, operate, and monitor models and engines without focusing on underlying infrastructure and service-related development, governance, and operations.
holoinsight
HoloInsight is a cloud-native observability platform that provides low-cost and high-performance monitoring services for cloud-native applications. It offers deep insights through real-time log analysis and AI integration. The platform is designed to help users gain a comprehensive understanding of their applications' performance and behavior in the cloud environment. HoloInsight is easy to deploy using Docker and Kubernetes, making it a versatile tool for monitoring and optimizing cloud-native applications. With a focus on scalability and efficiency, HoloInsight is suitable for organizations looking to enhance their observability and monitoring capabilities in the cloud.
awesome-AIOps
awesome-AIOps is a curated list of academic researches and industrial materials related to Artificial Intelligence for IT Operations (AIOps). It includes resources such as competitions, white papers, blogs, tutorials, benchmarks, tools, companies, academic materials, talks, workshops, papers, and courses covering various aspects of AIOps like anomaly detection, root cause analysis, incident management, microservices, dependency tracing, and more.

OpenLLM
OpenLLM is a platform that helps developers run any open-source Large Language Models (LLMs) as OpenAI-compatible API endpoints, locally and in the cloud. It supports a wide range of LLMs, provides state-of-the-art serving and inference performance, and simplifies cloud deployment via BentoML. Users can fine-tune, serve, deploy, and monitor any LLMs with ease using OpenLLM. The platform also supports various quantization techniques, serving fine-tuning layers, and multiple runtime implementations. OpenLLM seamlessly integrates with other tools like OpenAI Compatible Endpoints, LlamaIndex, LangChain, and Transformers Agents. It offers deployment options through Docker containers, BentoCloud, and provides a community for collaboration and contributions.
laravel-slower
Laravel Slower is a powerful package designed for Laravel developers to optimize the performance of their applications by identifying slow database queries and providing AI-driven suggestions for optimal indexing strategies and performance improvements. It offers actionable insights for debugging and monitoring database interactions, enhancing efficiency and scalability.

genkit
Firebase Genkit (beta) is a framework with powerful tooling to help app developers build, test, deploy, and monitor AI-powered features with confidence. Genkit is cloud optimized and code-centric, integrating with many services that have free tiers to get started. It provides unified API for generation, context-aware AI features, evaluation of AI workflow, extensibility with plugins, easy deployment to Firebase or Google Cloud, observability and monitoring with OpenTelemetry, and a developer UI for prototyping and testing AI features locally. Genkit works seamlessly with Firebase or Google Cloud projects through official plugins and templates.
llmops-workshop
LLMOps Workshop is a course designed to help users build, evaluate, monitor, and deploy Large Language Model solutions efficiently using Azure AI, Azure Machine Learning Prompt Flow, Content Safety, and Azure OpenAI. The workshop covers various aspects of LLMOps to help users master the process.
For similar jobs

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.

tabby
Tabby is a self-hosted AI coding assistant, offering an open-source and on-premises alternative to GitHub Copilot. It boasts several key features: * Self-contained, with no need for a DBMS or cloud service. * OpenAPI interface, easy to integrate with existing infrastructure (e.g Cloud IDE). * Supports consumer-grade GPUs.

spear
SPEAR (Simulator for Photorealistic Embodied AI Research) is a powerful tool for training embodied agents. It features 300 unique virtual indoor environments with 2,566 unique rooms and 17,234 unique objects that can be manipulated individually. Each environment is designed by a professional artist and features detailed geometry, photorealistic materials, and a unique floor plan and object layout. SPEAR is implemented as Unreal Engine assets and provides an OpenAI Gym interface for interacting with the environments via Python.

Magick
Magick is a groundbreaking visual AIDE (Artificial Intelligence Development Environment) for no-code data pipelines and multimodal agents. Magick can connect to other services and comes with nodes and templates well-suited for intelligent agents, chatbots, complex reasoning systems and realistic characters.