
GDPO
Official implementation of GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
Stars: 390
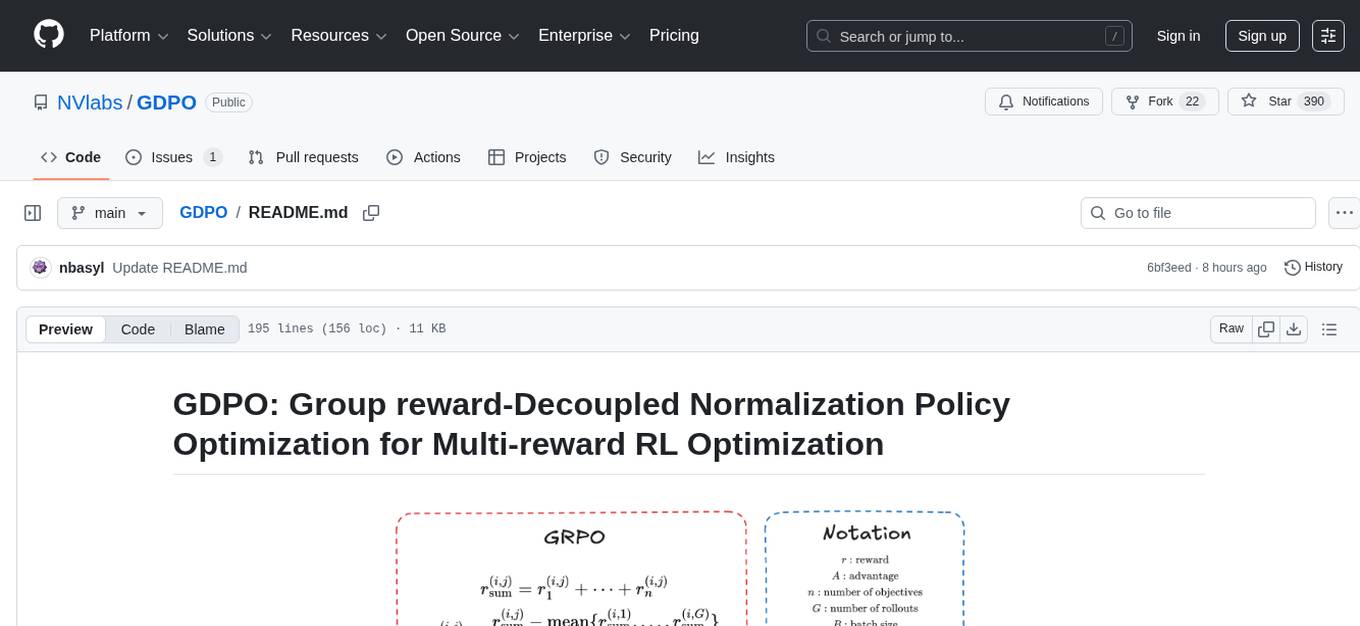
GDPO is a reinforcement learning optimization method designed for multi-reward training. It resolves reward advantages collapse by decoupling reward normalization across individual rewards, enabling more faithful preference optimization. The implementation includes easy-to-use training scripts for tool calling and math reasoning tasks. GDPO consistently outperforms existing approaches in training convergence and downstream evaluation performance.
README:

🤗 Hugging Face Page   |    📄 Paper |    📜 Page  
GDPO is a reinforcement learning optimization method designed for multi-reward training. While existing approaches commonly apply Group Relative Policy Optimization (GRPO) in multi-reward settings, we show that this leads to reward advantages collapse, reducing training signal resolution and causing unstable or failed convergence.
GDPO resolves this issue by decoupling reward normalization across individual rewards, preserving their relative differences and enabling more faithful preference optimization. Across tool calling, math reasoning, and code generation tasks, GDPO consistently surpasses GRPO in both training convergence and downstream evaluation performance.
In this repo, we provide implementation of GDPO based on VERL at verl-GDPO, TRL at trl-GDPO, and Nemo-RL at nemo_rl-GDPO.
We also include easy-to-use, slurm-free training scripts that enable the community to quickly validate GDPO’s effectiveness over GRPO on tool calling and math reasoning tasks. Each run can be completed in approximately 1 hour on a single node with 8×A100 GPUs, or around 2.5 hours on a single A100 GPU.
GDPO is now supported in the following RL-training libraries:
- TRL 🔥🔥 Example here!!
- Ms-swift 🔥🔥 Example here!!
- Axolotl 🔥🔥 Example here!!
- NeMo RL 🔥🔥 Coming in v0.6!!

Here we compare GDPO with GRPO on the tool calling task, specifically, the model trained to learn how to incorporate external tools into the reasoning trajectory to solve a user task following the output format of
**Output Format**
<think> Your thoughts and reasoning </think>
<tool_call>
{json_string}
...
</tool_call>
<response> AI's final response </response>
The training set consists of 4k samples. Each training instance contains a question and its corresponding ground-truth tool calls. The training involves two rewards:
- Format Reward: A binary reward (0 or 1) checks whether the model output satisfies the required structure and contains all necessary fields in the correct order.
- Correctness Reward: The correctness reward ∈ [−3, 3] evaluates the model-generated tool calls against the ground-truth calls using three metrics: tool name matching, parameter name matching, and parameter content matching.
We train Qwen2.5-1.5B-Instruct with GDPO and GRPO using verl for 100 steps. Check verl-GDPO for detailed implementation of GDPO based on VERL and how to reprodcue the above result.

We compare GDPO and GRPO in their ability to incentivize the model’s reasoning capabilities (i.e., achieving the “aha” moment). Specifically, the model is trained to first produce detailed reasoning steps and then output the final answer in a prescribed format when solving user queries.
Output Format:
<think>Your thoughts and reasoning</think>
<answer>Final answer in integer format</answer>
Training is conducted on the GSM8K dataset, where each example consists of a math problem paired with its ground-truth answer. The RL training incorporates three reward signals:
-
Format Reward: A binary reward (0 or 1) indicating whether the model output follows the required structure and includes all necessary tags in the correct order.
-
Correctness Reward: A binary reward (0 or 1) that verifies whether the final answer enclosed within
<answer></answer>matches the ground-truth solution. -
Integer Reward: A binary reward (0 or 1) that checks whether the final answer inside
<answer></answer>is an integer, encouraging integer-only outputs.
We train Qwen2.5-1.5B-Instruct with GDPO and GRPO using trl for 1 epoch. Check trl-GDPO for detailed implementation of GDPO based on TRL and how to reprodcue the above result.
# line 1254 in trl-GDPO/trl-0.18.0-gdpo/trl/trainer/grpo_trainer.py
# Gather the reward per function: this part is crucial, because the rewards are normalized per group and the
# completions may be distributed across processes
rewards_per_func = gather(rewards_per_func)
rewards = (rewards_per_func * self.reward_weights.to(device).unsqueeze(0)).nansum(dim=1)
# Compute grouped-wise rewards
mean_grouped_rewards = rewards.view(-1, self.num_generations).mean(dim=1)
std_grouped_rewards = rewards.view(-1, self.num_generations).std(dim=1)
is_std_zero = torch.isclose(std_grouped_rewards, torch.zeros_like(std_grouped_rewards))
# Normalize the rewards to compute the advantages
mean_grouped_rewards = mean_grouped_rewards.repeat_interleave(self.num_generations, dim=0)
std_grouped_rewards = std_grouped_rewards.repeat_interleave(self.num_generations, dim=0)
advantages = rewards - mean_grouped_rewards
if self.scale_rewards:
advantages = advantages / (std_grouped_rewards + 1e-4) # line 1222 in trl-GDPO/trl-0.18.0-gdpo/trl/trainer/grpo_trainer.py
# Gather the reward per function: this part is crucial, because the rewards are normalized per group and the
# completions may be distributed across processes
rewards_per_func = gather(rewards_per_func)
## Make sure every reward contain no nan value
rewards_per_func_filter = torch.nan_to_num(rewards_per_func)
all_reward_advantage = []
## Calculate the mean and std of each reward group-wise separately
for i in range(len(self.reward_weights)):
reward_i = rewards_per_func_filter[:,i]
each_reward_mean_grouped = reward_i.view(-1, self.num_generations).mean(dim=1)
each_reward_std_grouped = reward_i.view(-1, self.num_generations).std(dim=1)
each_reward_mean_grouped = each_reward_mean_grouped.repeat_interleave(self.num_generations, dim=0)
each_reward_std_grouped = each_reward_std_grouped.repeat_interleave(self.num_generations, dim=0)
each_reward_advantage = reward_i - each_reward_mean_grouped
each_reward_advantage = each_reward_advantage / (each_reward_std_grouped + 1e-4)
all_reward_advantage.append(each_reward_advantage)
combined_reward_advantage = torch.stack(all_reward_advantage, dim=1)
pre_bn_advantages = (combined_reward_advantage * self.reward_weights.to(device).unsqueeze(0)).nansum(dim=1)
## compute batch-wise mean and std
bn_advantages_mean = pre_bn_advantages.mean()
bn_advantages_std = pre_bn_advantages.std()
advantages = (pre_bn_advantages - bn_advantages_mean) / (bn_advantages_std + 1e-4) ## line 148 in verl-GDPO/verl/trainer/ppo/ray_trainer.py
elif adv_estimator == 'grpo':
token_level_rewards = data.batch['token_level_rewards']
index = data.non_tensor_batch['uid']
responses = data.batch['responses']
response_length = responses.size(-1)
attention_mask = data.batch['attention_mask']
response_mask = attention_mask[:, -response_length:]
advantages, returns = core_algos.compute_grpo_outcome_advantage(token_level_rewards=token_level_rewards,
eos_mask=response_mask,
index=index)
data.batch['advantages'] = advantages
data.batch['returns'] = returns ## line 175 in verl-GDPO/verl/trainer/ppo/ray_trainer.py
token_level_scores_correctness = data.batch['token_level_scores_correctness']
token_level_scores_format = data.batch['token_level_scores_format']
# shared variables
index = data.non_tensor_batch['uid']
responses = data.batch['responses']
response_length = responses.size(-1)
attention_mask = data.batch['attention_mask']
response_mask = attention_mask[:, -response_length:]
## handle correctness first
correctness_normalized_score, _ = core_algos.compute_grpo_outcome_advantage(token_level_rewards=token_level_scores_correctness,
eos_mask=response_mask,
index=index)
## handle format now
format_normalized_score, _ = core_algos.compute_grpo_outcome_advantage(token_level_rewards=token_level_scores_format,
eos_mask=response_mask,
index=index)
new_advantage = correctness_normalized_score + format_normalized_score
advantages = masked_whiten(new_advantage, response_mask) * response_mask
data.batch['advantages'] = advantages
data.batch['returns'] = advantagesIf you find GDPO useful, please star and cite it:
@misc{liu2026gdpogrouprewarddecouplednormalization,
title={GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization},
author={Shih-Yang Liu and Xin Dong and Ximing Lu and Shizhe Diao and Peter Belcak and Mingjie Liu and Min-Hung Chen and Hongxu Yin and Yu-Chiang Frank Wang and Kwang-Ting Cheng and Yejin Choi and Jan Kautz and Pavlo Molchanov},
year={2026},
eprint={2601.05242},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2601.05242},
}Copyright © 2026, NVIDIA Corporation. All rights reserved.
This work is made available under the NVIDIA Source Code License-NC. Click here to view a copy of this license.
For Tasks:
Click tags to check more tools for each tasksFor Jobs:
Alternative AI tools for GDPO
Similar Open Source Tools
GDPO
GDPO is a reinforcement learning optimization method designed for multi-reward training. It resolves reward advantages collapse by decoupling reward normalization across individual rewards, enabling more faithful preference optimization. The implementation includes easy-to-use training scripts for tool calling and math reasoning tasks. GDPO consistently outperforms existing approaches in training convergence and downstream evaluation performance.

create-million-parameter-llm-from-scratch
The 'create-million-parameter-llm-from-scratch' repository provides a detailed guide on creating a Large Language Model (LLM) with 2.3 million parameters from scratch. The blog replicates the LLaMA approach, incorporating concepts like RMSNorm for pre-normalization, SwiGLU activation function, and Rotary Embeddings. The model is trained on a basic dataset to demonstrate the ease of creating a million-parameter LLM without the need for a high-end GPU.

AgentFly
AgentFly is an extensible framework for building LLM agents with reinforcement learning. It supports multi-turn training by adapting traditional RL methods with token-level masking. It features a decorator-based interface for defining tools and reward functions, enabling seamless extension and ease of use. To support high-throughput training, it implemented asynchronous execution of tool calls and reward computations, and designed a centralized resource management system for scalable environment coordination. A suite of prebuilt tools and environments are provided.

MotionLLM
MotionLLM is a framework for human behavior understanding that leverages Large Language Models (LLMs) to jointly model videos and motion sequences. It provides a unified training strategy, dataset MoVid, and MoVid-Bench for evaluating human behavior comprehension. The framework excels in captioning, spatial-temporal comprehension, and reasoning abilities.

EasySteer
EasySteer is a unified framework built on vLLM for high-performance LLM steering. It offers fast, flexible, and easy-to-use steering capabilities with features like high performance, modular design, fine-grained control, pre-computed steering vectors, and an interactive demo. Users can interactively configure models, adjust steering parameters, and test interventions without writing code. The tool supports OpenAI-compatible APIs and provides modules for hidden states extraction, analysis-based steering, learning-based steering, and a frontend web interface for interactive steering and ReFT interventions.

OpenMusic
OpenMusic is a repository providing an implementation of QA-MDT, a Quality-Aware Masked Diffusion Transformer for music generation. The code integrates state-of-the-art models and offers training strategies for music generation. The repository includes implementations of AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. Users can train or fine-tune the model using different strategies and datasets. The model is well-pretrained and can be used for music generation tasks. The repository also includes instructions for preparing datasets, training the model, and performing inference. Contact information is provided for any questions or suggestions regarding the project.

qa-mdt
This repository provides an implementation of QA-MDT, integrating state-of-the-art models for music generation. It offers a Quality-Aware Masked Diffusion Transformer for enhanced music generation. The code is based on various repositories like AudioLDM, PixArt-alpha, MDT, AudioMAE, and Open-Sora. The implementation allows for training and fine-tuning the model with different strategies and datasets. The repository also includes instructions for preparing datasets in LMDB format and provides a script for creating a toy LMDB dataset. The model can be used for music generation tasks, with a focus on quality injection to enhance the musicality of generated music.
Endia
Endia is a dynamic Array library for Scientific Computing, offering automatic differentiation of arbitrary order, complex number support, dual API with PyTorch-like imperative or JAX-like functional interface, and JIT Compilation for speeding up training and inference. It can handle complex valued functions, perform both forward and reverse-mode automatic differentiation, and has a builtin JIT compiler. Endia aims to advance AI & Scientific Computing by pushing boundaries with clear algorithms, providing high-performance open-source code that remains readable and pythonic, and prioritizing clarity and educational value over exhaustive features.

continuous-eval
Open-Source Evaluation for LLM Applications. `continuous-eval` is an open-source package created for granular and holistic evaluation of GenAI application pipelines. It offers modularized evaluation, a comprehensive metric library covering various LLM use cases, the ability to leverage user feedback in evaluation, and synthetic dataset generation for testing pipelines. Users can define their own metrics by extending the Metric class. The tool allows running evaluation on a pipeline defined with modules and corresponding metrics. Additionally, it provides synthetic data generation capabilities to create user interaction data for evaluation or training purposes.

RTL-Coder
RTL-Coder is a tool designed to outperform GPT-3.5 in RTL code generation by providing a fully open-source dataset and a lightweight solution. It targets Verilog code generation and offers an automated flow to generate a large labeled dataset with over 27,000 diverse Verilog design problems and answers. The tool addresses the data availability challenge in IC design-related tasks and can be used for various applications beyond LLMs. The tool includes four RTL code generation models available on the HuggingFace platform, each with specific features and performance characteristics. Additionally, RTL-Coder introduces a new LLM training scheme based on code quality feedback to further enhance model performance and reduce GPU memory consumption.

rl
TorchRL is an open-source Reinforcement Learning (RL) library for PyTorch. It provides pytorch and **python-first** , low and high level abstractions for RL that are intended to be **efficient** , **modular** , **documented** and properly **tested**. The code is aimed at supporting research in RL. Most of it is written in python in a highly modular way, such that researchers can easily swap components, transform them or write new ones with little effort.

GraphRAG-SDK
Build fast and accurate GenAI applications with GraphRAG SDK, a specialized toolkit for building Graph Retrieval-Augmented Generation (GraphRAG) systems. It integrates knowledge graphs, ontology management, and state-of-the-art LLMs to deliver accurate, efficient, and customizable RAG workflows. The SDK simplifies the development process by automating ontology creation, knowledge graph agent creation, and query handling, enabling users to interact and query their knowledge graphs effectively. It supports multi-agent systems and orchestrates agents specialized in different domains. The SDK is optimized for FalkorDB, ensuring high performance and scalability for large-scale applications. By leveraging knowledge graphs, it enables semantic relationships and ontology-driven queries that go beyond standard vector similarity, enhancing retrieval-augmented generation capabilities.
inspectus
Inspectus is a versatile visualization tool for large language models. It provides multiple views, including Attention Matrix, Query Token Heatmap, Key Token Heatmap, and Dimension Heatmap, to offer insights into language model behaviors. Users can interact with the tool in Jupyter notebooks through an easy-to-use Python API. Inspectus allows users to visualize attention scores between tokens, analyze how tokens focus on each other during processing, and explore the relationships between query and key tokens. The tool supports the visualization of attention maps from Huggingface transformers and custom attention maps, making it a valuable resource for researchers and developers working with language models.

CodeTF
CodeTF is a Python transformer-based library for code large language models (Code LLMs) and code intelligence. It provides an interface for training and inferencing on tasks like code summarization, translation, and generation. The library offers utilities for code manipulation across various languages, including easy extraction of code attributes. Using tree-sitter as its core AST parser, CodeTF enables parsing of function names, comments, and variable names. It supports fast model serving, fine-tuning of LLMs, various code intelligence tasks, preprocessed datasets, model evaluation, pretrained and fine-tuned models, and utilities to manipulate source code. CodeTF aims to facilitate the integration of state-of-the-art Code LLMs into real-world applications, ensuring a user-friendly environment for code intelligence tasks.

MemoryLLM
MemoryLLM is a large language model designed for self-updating capabilities. It offers pretrained models with different memory capacities and features, such as chat models. The repository provides training code, evaluation scripts, and datasets for custom experiments. MemoryLLM aims to enhance knowledge retention and performance on various natural language processing tasks.

dLLM-RL
dLLM-RL is a revolutionary reinforcement learning framework designed for Diffusion Large Language Models. It supports various models with diverse structures, offers inference acceleration, RL training capabilities, and SFT functionalities. The tool introduces TraceRL for trajectory-aware RL and diffusion-based value models for optimization stability. Users can download and try models like TraDo-4B-Instruct and TraDo-8B-Instruct. The tool also provides support for multi-node setups and easy building of reinforcement learning methods. Additionally, it offers supervised fine-tuning strategies for different models and tasks.
For similar tasks
GDPO
GDPO is a reinforcement learning optimization method designed for multi-reward training. It resolves reward advantages collapse by decoupling reward normalization across individual rewards, enabling more faithful preference optimization. The implementation includes easy-to-use training scripts for tool calling and math reasoning tasks. GDPO consistently outperforms existing approaches in training convergence and downstream evaluation performance.
For similar jobs
GDPO
GDPO is a reinforcement learning optimization method designed for multi-reward training. It resolves reward advantages collapse by decoupling reward normalization across individual rewards, enabling more faithful preference optimization. The implementation includes easy-to-use training scripts for tool calling and math reasoning tasks. GDPO consistently outperforms existing approaches in training convergence and downstream evaluation performance.

weave
Weave is a toolkit for developing Generative AI applications, built by Weights & Biases. With Weave, you can log and debug language model inputs, outputs, and traces; build rigorous, apples-to-apples evaluations for language model use cases; and organize all the information generated across the LLM workflow, from experimentation to evaluations to production. Weave aims to bring rigor, best-practices, and composability to the inherently experimental process of developing Generative AI software, without introducing cognitive overhead.

agentcloud
AgentCloud is an open-source platform that enables companies to build and deploy private LLM chat apps, empowering teams to securely interact with their data. It comprises three main components: Agent Backend, Webapp, and Vector Proxy. To run this project locally, clone the repository, install Docker, and start the services. The project is licensed under the GNU Affero General Public License, version 3 only. Contributions and feedback are welcome from the community.

oss-fuzz-gen
This framework generates fuzz targets for real-world `C`/`C++` projects with various Large Language Models (LLM) and benchmarks them via the `OSS-Fuzz` platform. It manages to successfully leverage LLMs to generate valid fuzz targets (which generate non-zero coverage increase) for 160 C/C++ projects. The maximum line coverage increase is 29% from the existing human-written targets.

LLMStack
LLMStack is a no-code platform for building generative AI agents, workflows, and chatbots. It allows users to connect their own data, internal tools, and GPT-powered models without any coding experience. LLMStack can be deployed to the cloud or on-premise and can be accessed via HTTP API or triggered from Slack or Discord.

VisionCraft
The VisionCraft API is a free API for using over 100 different AI models. From images to sound.

kaito
Kaito is an operator that automates the AI/ML inference model deployment in a Kubernetes cluster. It manages large model files using container images, avoids tuning deployment parameters to fit GPU hardware by providing preset configurations, auto-provisions GPU nodes based on model requirements, and hosts large model images in the public Microsoft Container Registry (MCR) if the license allows. Using Kaito, the workflow of onboarding large AI inference models in Kubernetes is largely simplified.

PyRIT
PyRIT is an open access automation framework designed to empower security professionals and ML engineers to red team foundation models and their applications. It automates AI Red Teaming tasks to allow operators to focus on more complicated and time-consuming tasks and can also identify security harms such as misuse (e.g., malware generation, jailbreaking), and privacy harms (e.g., identity theft). The goal is to allow researchers to have a baseline of how well their model and entire inference pipeline is doing against different harm categories and to be able to compare that baseline to future iterations of their model. This allows them to have empirical data on how well their model is doing today, and detect any degradation of performance based on future improvements.