Best AI tools for< Rename Files >
7 - AI tool Sites
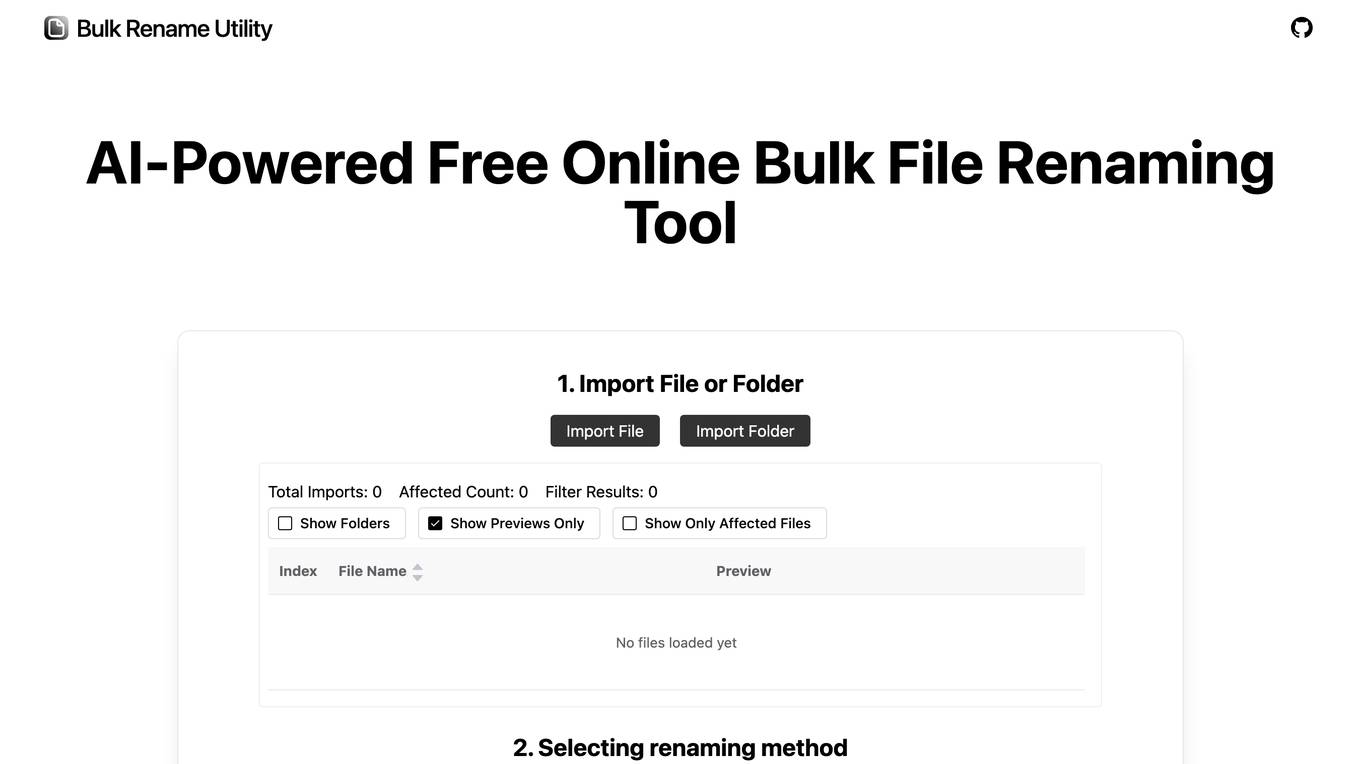
AI Bulk Rename Utility
AI Bulk Rename Utility is an innovative file renaming tool that leverages advanced artificial intelligence and rule-based operations to provide users with smart and efficient file management solutions. The application allows users to rename files and folders without the need to upload them online, ensuring privacy and security. With features like AI-powered intelligence, dual operation modes, diverse renaming rules, and support for various file operations, AI Bulk Rename Utility stands out as a user-friendly and versatile tool for both Windows and Mac users.

AI Renamer
AI Renamer is an application that utilizes artificial intelligence to automatically rename files based on their content. It offers powerful features such as smart recognition, batch processing, and support for various file types. Users can also integrate their own AI models for enhanced flexibility and privacy. The application provides credit-based pricing options and supports both Mac and Windows platforms.
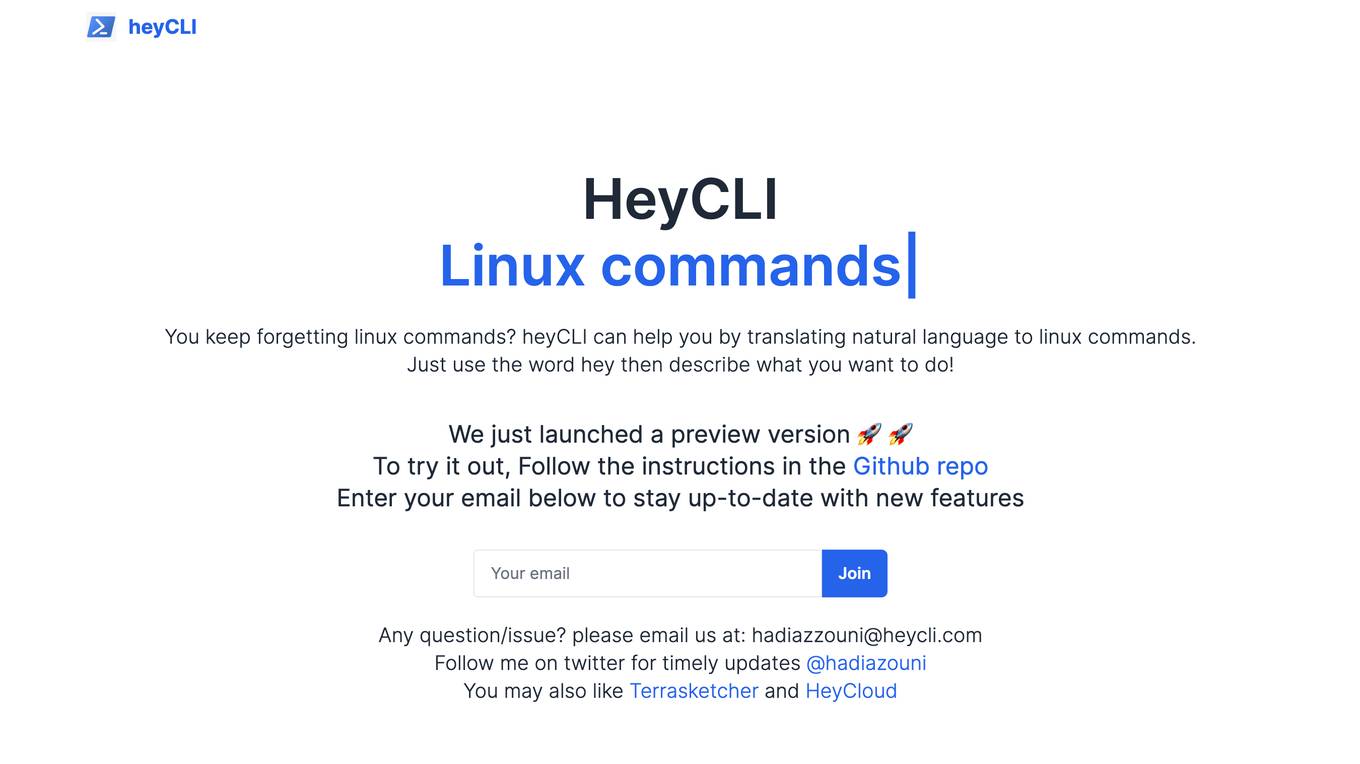
heyCLI
heyCLI is a command-line interface (CLI) tool that allows users to interact with their Linux systems using natural language. It is designed to make it easier for users to perform common tasks without having to memorize complex commands. heyCLI is still in its early stages of development, but it has the potential to be a valuable tool for both new and experienced Linux users.
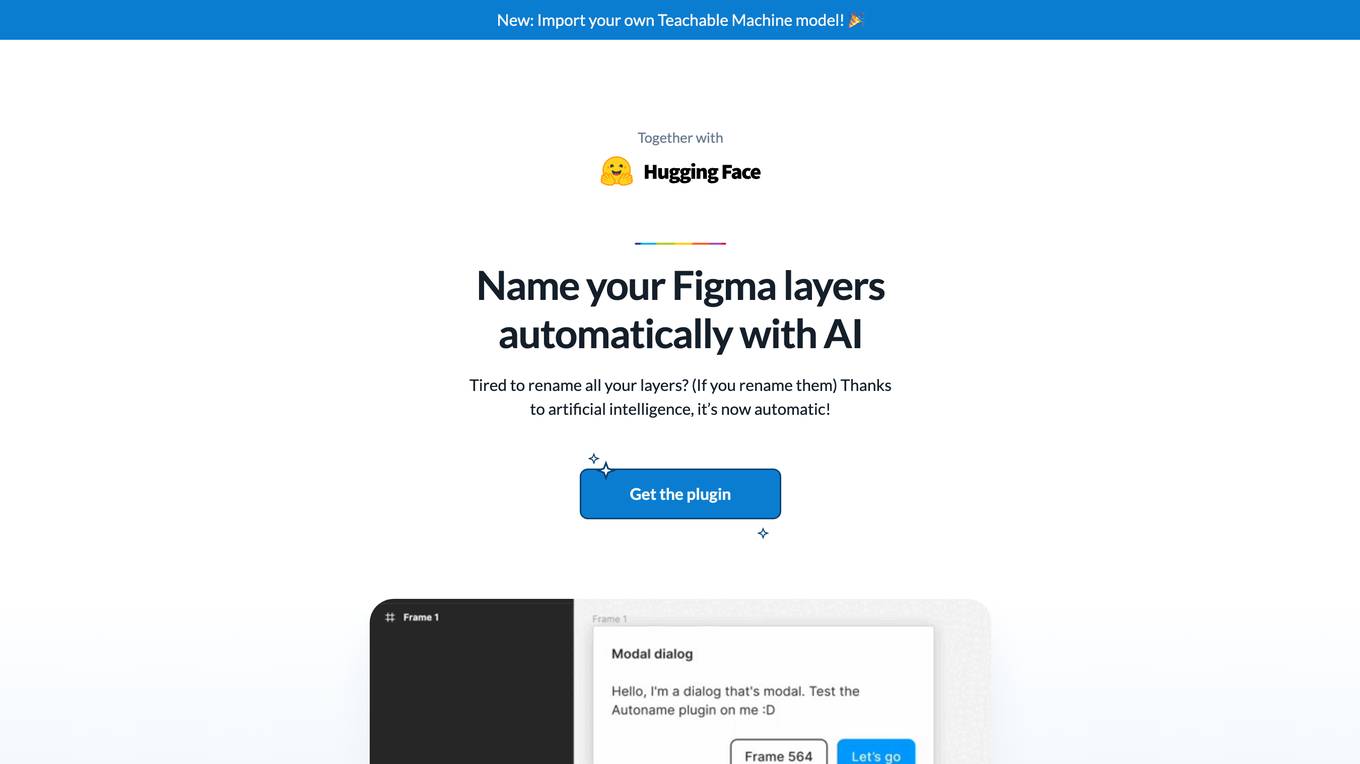
Figma Autoname
Figma Autoname is an AI-powered plugin designed to simplify the process of renaming layers in Figma designs. By leveraging artificial intelligence, the plugin automates the task of renaming layers, saving designers valuable time and effort. With features like blazing fast renaming, smart detection of components names, and community-driven development, Figma Autoname offers a seamless experience for designers looking to enhance their workflow. The plugin is free to use and open-source, allowing users to contribute to its development. Figma Autoname has garnered praise from the design community for its efficiency and user-friendly interface.
Diagram
Diagram is a suite of AI-powered design tools that help designers create beautiful and effective designs. With Diagram, you can generate SVG icons, create magical visuals, write and edit text, rename layers, and more. Diagram also offers a variety of features that make it easy to collaborate with other designers and share your work.

Redirector
The website is a simple redirecting tool that forwards users from one URL to another. It is a basic utility used to automatically send visitors to a different web address. This tool is commonly employed in scenarios where a webpage has been moved or renamed, ensuring a seamless user experience by automatically redirecting them to the new location.
N/A
The website appears to have encountered an error as the requested page could not be found. It seems like the user has landed on a 'Page not found' message. This message typically indicates that the URL the user tried to access does not exist or has been moved. It is a common occurrence on websites when users mistype URLs or when pages are removed or renamed. The 'Page not found' message is a standard way to inform users that the content they are looking for is unavailable.
1 - Open Source AI Tools
file-organizer-2000
AI File Organizer 2000 is an Obsidian Plugin that uses AI to transcribe audio, annotate images, and automatically organize files by moving them to the most likely folders. It supports text, audio, and images, with upcoming local-first LLM support. Users can simply place unorganized files into the 'Inbox' folder for automatic organization. The tool renames and moves files quickly, providing a seamless file organization experience. Self-hosting is also possible by running the server and enabling the 'Self-hosted' option in the plugin settings. Join the community Discord server for more information and use the provided iOS shortcut for easy access on mobile devices.
1 - OpenAI Gpts