Best AI tools for< Reconstruct Landscapes >
4 - AI tool Sites
Historica
Historica is an AI-powered history map application that offers a unique and immersive experience by crafting historical maps of civilizations' timelines. The application utilizes cutting-edge AI technologies such as NLP, computer vision, and GIS to reconstruct landscapes from centuries past, providing users with a rich tapestry of historical knowledge. Historica aims to revive the past and make history more accessible through the fusion of technology and historical research.
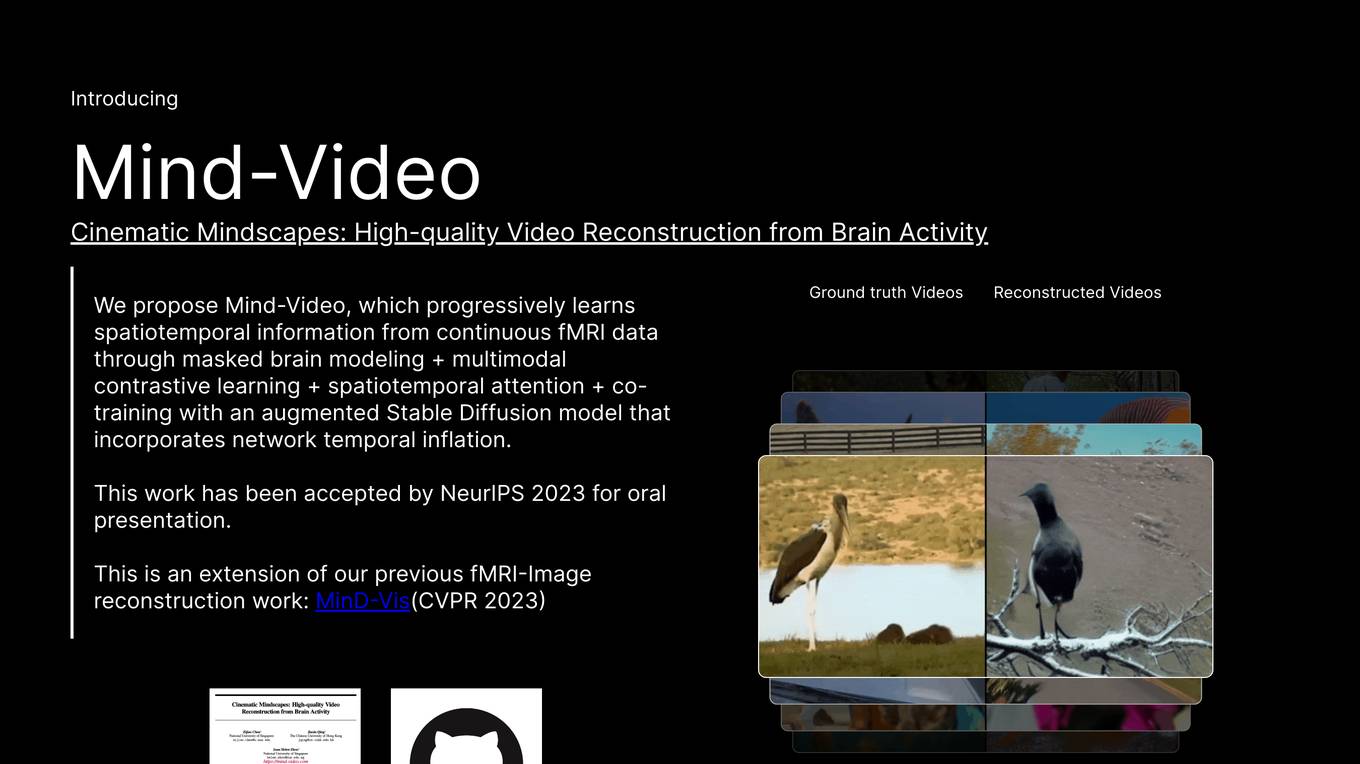
Mind-Video
Mind-Video is an AI tool that focuses on high-quality video reconstruction from brain activity data. It bridges the gap between image and video brain decoding by utilizing masked brain modeling, multimodal contrastive learning, spatiotemporal attention, and co-training with an augmented Stable Diffusion model. The tool aims to recover accurate semantic information from fMRI signals, enabling the generation of realistic videos based on brain activities.

Remover.app
Remover.app is a free online tool that allows you to remove unwanted objects, people, or defects from your photos. It uses artificial intelligence to reconstruct the background behind the object, so you can achieve professional results in just a few clicks. Remover.app is easy to use, simply upload your photo and brush over the object you want to remove. The AI will do the rest! Remover.app is perfect for removing unwanted objects from product photos, real estate photos, and even family photos. It's also great for removing blemishes, wrinkles, and other imperfections from your photos.
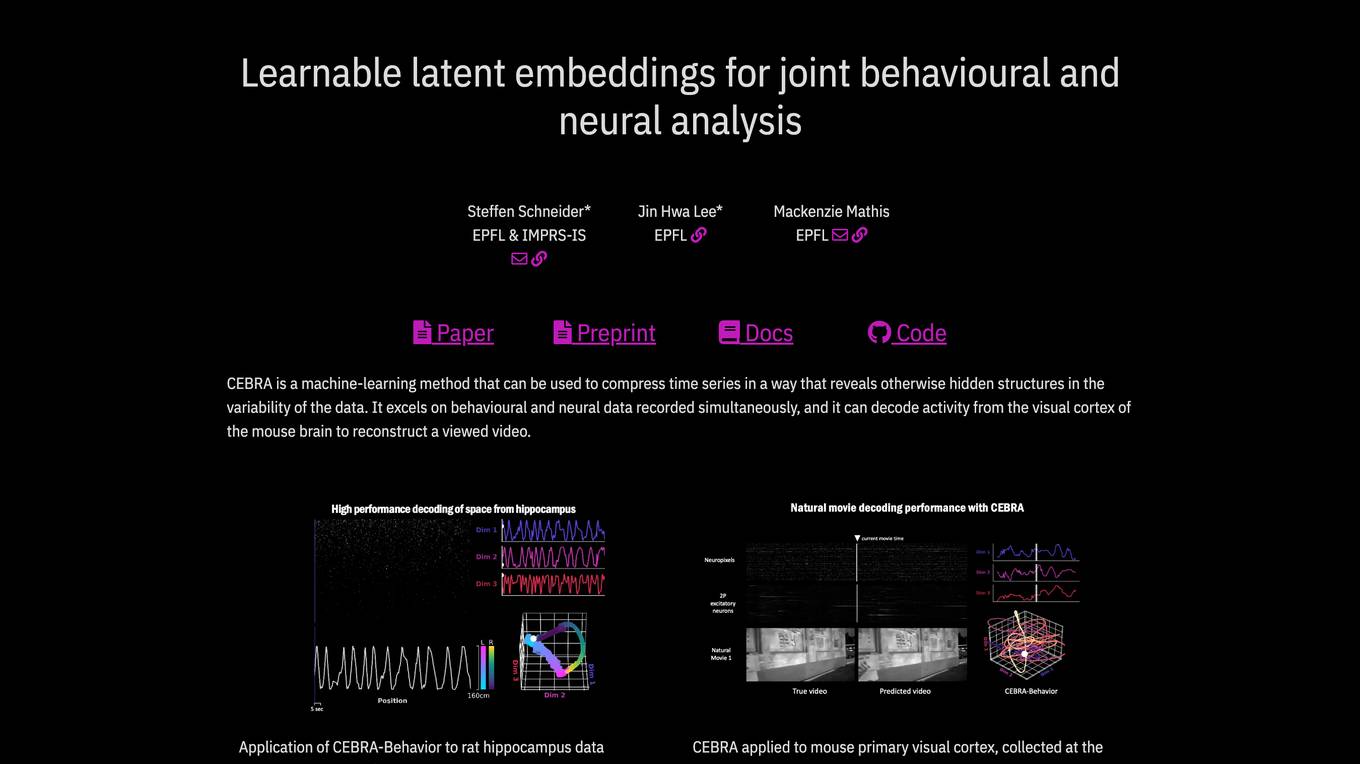
CEBRA
CEBRA is a machine-learning method that compresses time series data to reveal hidden structures in the variability of the data. It excels in analyzing behavioral and neural data simultaneously, decoding activity from the visual cortex of the mouse brain to reconstruct viewed videos. CEBRA fills the gap by leveraging joint behavior and neural data to uncover neural dynamics, providing consistent and high-performance latent spaces for hypothesis testing or label-free analysis across sensory and motor tasks.
20 - Open Source AI Tools

llms-tools
The 'llms-tools' repository is a comprehensive collection of AI tools, open-source projects, and research related to Large Language Models (LLMs) and Chatbots. It covers a wide range of topics such as AI in various domains, open-source models, chats & assistants, visual language models, evaluation tools, libraries, devices, income models, text-to-image, computer vision, audio & speech, code & math, games, robotics, typography, bio & med, military, climate, finance, and presentation. The repository provides valuable resources for researchers, developers, and enthusiasts interested in exploring the capabilities of LLMs and related technologies.


Awesome-LLM-Quantization
Awesome-LLM-Quantization is a curated list of resources related to quantization techniques for Large Language Models (LLMs). Quantization is a crucial step in deploying LLMs on resource-constrained devices, such as mobile phones or edge devices, by reducing the model's size and computational requirements.



Open-Sora-Plan
Open-Sora-Plan is a project that aims to create a simple and scalable repo to reproduce Sora (OpenAI, but we prefer to call it "ClosedAI"). The project is still in its early stages, but the team is working hard to improve it and make it more accessible to the open-source community. The project is currently focused on training an unconditional model on a landscape dataset, but the team plans to expand the scope of the project in the future to include text2video experiments, training on video2text datasets, and controlling the model with more conditions.
awesome-generative-ai
A curated list of Generative AI projects, tools, artworks, and models
hold
This repository contains the code for HOLD, a method that jointly reconstructs hands and objects from monocular videos without assuming a pre-scanned object template. It can reconstruct 3D geometries of novel objects and hands, enabling template-free bimanual hand-object reconstruction, textureless object interaction with hands, and multiple objects interaction with hands. The repository provides instructions to download in-the-wild videos from HOLD, preprocess and train on custom videos, a volumetric rendering framework, a generalized codebase for single and two hand interaction with objects, a viewer to interact with predictions, and code to evaluate and compare with HOLD in HO3D. The repository also includes documentation for setup, training, evaluation, visualization, preprocessing custom sequences, and using HOLD on ARCTIC.
aitom
AITom is an open-source platform for AI-driven cellular electron cryo-tomography analysis. It is developed to process large amounts of Cryo-ET data, reconstruct, detect, classify, recover, and spatially model different cellular components using state-of-the-art machine learning approaches. The platform aims to automate cellular structure discovery and provide new insights into molecular biology and medical applications.
BetterOCR
BetterOCR is a tool that enhances text detection by combining multiple OCR engines with LLM (Language Model). It aims to improve OCR results, especially for languages with limited training data or noisy outputs. The tool combines results from EasyOCR, Tesseract, and Pororo engines, along with LLM support from OpenAI. Users can provide custom context for better accuracy, view performance examples by language, and upcoming features include box detection, improved interface, and async support. The package is under rapid development and contributions are welcomed.

depthai
This repository contains a demo application for DepthAI, a tool that can load different networks, create pipelines, record video, and more. It provides documentation for installation and usage, including running programs through Docker. Users can explore DepthAI features via command line arguments or a clickable QT interface. Supported models include various AI models for tasks like face detection, human pose estimation, and object detection. The tool collects anonymous usage statistics by default, which can be disabled. Users can report issues to the development team for support and troubleshooting.
AnyGPT
AnyGPT is a unified multimodal language model that utilizes discrete representations for processing various modalities like speech, text, images, and music. It aligns the modalities for intermodal conversions and text processing. AnyInstruct dataset is constructed for generative models. The model proposes a generative training scheme using Next Token Prediction task for training on a Large Language Model (LLM). It aims to compress vast multimodal data on the internet into a single model for emerging capabilities. The tool supports tasks like text-to-image, image captioning, ASR, TTS, text-to-music, and music captioning.

CogVideo
CogVideo is an open-source repository that provides pretrained text-to-video models for generating videos based on input text. It includes models like CogVideoX-2B and CogVideo, offering powerful video generation capabilities. The repository offers tools for inference, fine-tuning, and model conversion, along with demos showcasing the model's capabilities through CLI, web UI, and online experiences. CogVideo aims to facilitate the creation of high-quality videos from textual descriptions, catering to a wide range of applications.
VideoTuna
VideoTuna is a codebase for text-to-video applications that integrates multiple AI video generation models for text-to-video, image-to-video, and text-to-image generation. It provides comprehensive pipelines in video generation, including pre-training, continuous training, post-training, and fine-tuning. The models in VideoTuna include U-Net and DiT architectures for visual generation tasks, with upcoming releases of a new 3D video VAE and a controllable facial video generation model.
llms-from-scratch-rs
This project provides Rust code that follows the text 'Build An LLM From Scratch' by Sebastian Raschka. It translates PyTorch code into Rust using the Candle crate, aiming to build a GPT-style LLM. Users can clone the repo, run examples/exercises, and access the same datasets as in the book. The project includes chapters on understanding large language models, working with text data, coding attention mechanisms, implementing a GPT model, pretraining unlabeled data, fine-tuning for classification, and fine-tuning to follow instructions.

matsciml
The Open MatSci ML Toolkit is a flexible framework for machine learning in materials science. It provides a unified interface to a variety of materials science datasets, as well as a set of tools for data preprocessing, model training, and evaluation. The toolkit is designed to be easy to use for both beginners and experienced researchers, and it can be used to train models for a wide range of tasks, including property prediction, materials discovery, and materials design.
4 - OpenAI Gpts
Justice A.I.
The first-ever Multifaceted AI Chat Bot designed to deconstruct bias across all sectors.