Best AI tools for< Partition Databases >
1 - AI tool Sites
Doctrine
Doctrine is an AI-powered application that allows users to add AI-powered Q&A features to their apps in minutes. It leverages knowledge from data or knowledge bases to answer user questions or embed AI features. Doctrine can ingest content from various sources like databases, websites, documents, images, spreadsheets, and powerpoints. It offers a simple but powerful API for easy integration and scalability. With features like ingesting data, asking questions, partitioning for multi-tenant databases, and scaling capabilities, Doctrine is a versatile tool for businesses looking to enhance user interactions and streamline processes.
20 - Open Source AI Tools

sycamore
Sycamore is a conversational search and analytics platform for complex unstructured data, such as documents, presentations, transcripts, embedded tables, and internal knowledge repositories. It retrieves and synthesizes high-quality answers through bringing AI to data preparation, indexing, and retrieval. Sycamore makes it easy to prepare unstructured data for search and analytics, providing a toolkit for data cleaning, information extraction, enrichment, summarization, and generation of vector embeddings that encapsulate the semantics of data. Sycamore uses your choice of generative AI models to make these operations simple and effective, and it enables quick experimentation and iteration. Additionally, Sycamore uses OpenSearch for indexing, enabling hybrid (vector + keyword) search, retrieval-augmented generation (RAG) pipelining, filtering, analytical functions, conversational memory, and other features to improve information retrieval.

kernel-memory
Kernel Memory (KM) is a multi-modal AI Service specialized in the efficient indexing of datasets through custom continuous data hybrid pipelines, with support for Retrieval Augmented Generation (RAG), synthetic memory, prompt engineering, and custom semantic memory processing. KM is available as a Web Service, as a Docker container, a Plugin for ChatGPT/Copilot/Semantic Kernel, and as a .NET library for embedded applications. Utilizing advanced embeddings and LLMs, the system enables Natural Language querying for obtaining answers from the indexed data, complete with citations and links to the original sources. Designed for seamless integration as a Plugin with Semantic Kernel, Microsoft Copilot and ChatGPT, Kernel Memory enhances data-driven features in applications built for most popular AI platforms.
llms-interview-questions
This repository contains a comprehensive collection of 63 must-know Large Language Models (LLMs) interview questions. It covers topics such as the architecture of LLMs, transformer models, attention mechanisms, training processes, encoder-decoder frameworks, differences between LLMs and traditional statistical language models, handling context and long-term dependencies, transformers for parallelization, applications of LLMs, sentiment analysis, language translation, conversation AI, chatbots, and more. The readme provides detailed explanations, code examples, and insights into utilizing LLMs for various tasks.

algernon
Algernon is a web server with built-in support for QUIC, HTTP/2, Lua, Teal, Markdown, Pongo2, HyperApp, Amber, Sass(SCSS), GCSS, JSX, Ollama (LLMs), BoltDB, Redis, PostgreSQL, MariaDB/MySQL, MSSQL, rate limiting, graceful shutdown, plugins, users, and permissions. It is a small self-contained executable that supports various technologies and features for web development.

llm-search
pyLLMSearch is an advanced RAG system that offers a convenient question-answering system with a simple YAML-based configuration. It enables interaction with multiple collections of local documents, with improvements in document parsing, hybrid search, chat history, deep linking, re-ranking, customizable embeddings, and more. The package is designed to work with custom Large Language Models (LLMs) from OpenAI or installed locally. It supports various document formats, incremental embedding updates, dense and sparse embeddings, multiple embedding models, 'Retrieve and Re-rank' strategy, HyDE (Hypothetical Document Embeddings), multi-querying, chat history, and interaction with embedded documents using different models. It also offers simple CLI and web interfaces, deep linking, offline response saving, and an experimental API.

chat-your-doc
Chat Your Doc is an experimental project exploring various applications based on LLM technology. It goes beyond being just a chatbot project, focusing on researching LLM applications using tools like LangChain and LlamaIndex. The project delves into UX, computer vision, and offers a range of examples in the 'Lab Apps' section. It includes links to different apps, descriptions, launch commands, and demos, aiming to showcase the versatility and potential of LLM applications.

LakeSoul
LakeSoul is a cloud-native Lakehouse framework that supports scalable metadata management, ACID transactions, efficient and flexible upsert operation, schema evolution, and unified streaming & batch processing. It supports multiple computing engines like Spark, Flink, Presto, and PyTorch, and computing modes such as batch, stream, MPP, and AI. LakeSoul scales metadata management and achieves ACID control by using PostgreSQL. It provides features like automatic compaction, table lifecycle maintenance, redundant data cleaning, and permission isolation for metadata.

chronon
Chronon is a platform that simplifies and improves ML workflows by providing a central place to define features, ensuring point-in-time correctness for backfills, simplifying orchestration for batch and streaming pipelines, offering easy endpoints for feature fetching, and guaranteeing and measuring consistency. It offers benefits over other approaches by enabling the use of a broad set of data for training, handling large aggregations and other computationally intensive transformations, and abstracting away the infrastructure complexity of data plumbing.
Langchain-Chatchat
LangChain-Chatchat is an open-source, offline-deployable retrieval-enhanced generation (RAG) large model knowledge base project based on large language models such as ChatGLM and application frameworks such as Langchain. It aims to establish a knowledge base Q&A solution that is friendly to Chinese scenarios, supports open-source models, and can run offline.

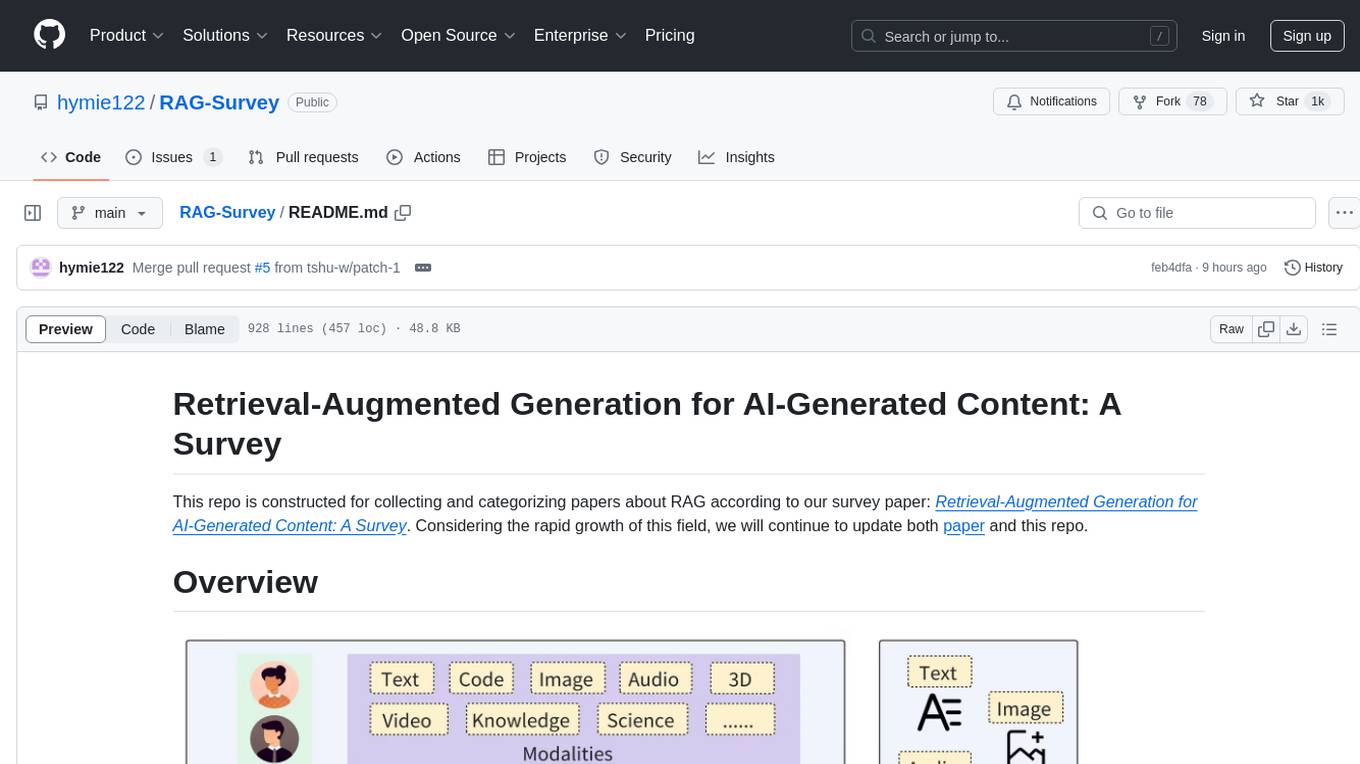
RAG-Survey
This repository is dedicated to collecting and categorizing papers related to Retrieval-Augmented Generation (RAG) for AI-generated content. It serves as a survey repository based on the paper 'Retrieval-Augmented Generation for AI-Generated Content: A Survey'. The repository is continuously updated to keep up with the rapid growth in the field of RAG.
vearch
Vearch is a cloud-native distributed vector database designed for efficient similarity search of embedding vectors in AI applications. It supports hybrid search with vector search and scalar filtering, offers fast vector retrieval from millions of objects in milliseconds, and ensures scalability and reliability through replication and elastic scaling out. Users can deploy Vearch cluster on Kubernetes, add charts from the repository or locally, start with Docker-compose, or compile from source code. The tool includes components like Master for schema management, Router for RESTful API, and PartitionServer for hosting document partitions with raft-based replication. Vearch can be used for building visual search systems for indexing images and offers a Python SDK for easy installation and usage. The tool is suitable for AI developers and researchers looking for efficient vector search capabilities in their applications.
semantic-cache
Semantic Cache is a tool for caching natural text based on semantic similarity. It allows for classifying text into categories, caching AI responses, and reducing API latency by responding to similar queries with cached values. The tool stores cache entries by meaning, handles synonyms, supports multiple languages, understands complex queries, and offers easy integration with Node.js applications. Users can set a custom proximity threshold for filtering results. The tool is ideal for tasks involving querying or retrieving information based on meaning, such as natural language classification or caching AI responses.

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.

aiode
aiode is a Discord bot that plays Spotify tracks and YouTube videos or any URL including Soundcloud links and Twitch streams. It allows users to create cross-platform playlists, customize player commands, create custom command presets, adjust properties for deeper customization, sign in to Spotify to play personal playlists, manage access permissions for commands, customize bot summoning methods, and execute advanced admin commands. The bot also features a scripting sandbox for running and storing custom groovy scripts and modifying command behavior through interceptors.