Best AI tools for< extract text from pdfs >
20 - AI tool Sites
Scanner Go
Scanner Go is a free and easy-to-use PDF tool that allows users to scan, convert, edit, and share documents. It is a versatile tool that can be used for a variety of purposes, including scanning receipts, documents, books, and images. Scanner Go also has a powerful OCR technology that can extract text from PDFs and images and convert it to editable text formats.

PDF Translator
PDF Translator is a powerful and easy-to-use tool that allows you to translate PDF documents into over 100 languages. With its advanced OCR technology, PDF Translator can accurately extract text from scanned PDFs, making it easy to translate even complex documents. PDF Translator also offers a variety of features to make translation easy and efficient, including batch translation, machine translation, and human translation.
Swiftask
Swiftask is an all-in-one AI Assistant designed to enhance individual and team productivity and creativity. It integrates a range of AI technologies, chatbots, and productivity tools into a cohesive chat interface. Swiftask offers features such as generating text, language translation, creative content writing, answering questions, extracting text from images and PDFs, table and form extraction, audio transcription, speech-to-text conversion, AI-based image generation, and project management capabilities. Users can benefit from Swiftask's comprehensive AI solutions to work smarter and achieve more.
Picture to Text Converter
Picture to Text Converter is an online tool that uses Optical Character Recognition (OCR) technology to extract text from images. It can process various image formats like JPG, PNG, GIF, scanned documents (PDFs), and even photos taken with your phone's camera. The extracted text can be copied to the clipboard or downloaded as a TXT file. Picture to Text Converter is free to use and does not require any registration or installation. It is a convenient and efficient way to convert images into editable text.
GetSearchablePDF
GetSearchablePDF is an online tool that allows users to convert scanned or image-based PDF documents into searchable PDFs. With its advanced OCR (Optical Character Recognition) technology, the tool accurately extracts text from images, making the resulting PDFs easy to search, edit, and share. The process is simple and straightforward: users simply connect their Dropbox or OneDrive account, drag and drop their PDF files into the designated folder, and the tool automatically converts them into searchable PDFs.

Shortify
Shortify is a tool that helps you summarize text from various sources, including articles, YouTube videos, PDFs, and more. It integrates with your existing apps, allowing you to easily summarize content by tapping the Share button and selecting Shortify. The summarized text is presented in a concise and easy-to-read format, saving you time and effort. Shortify also offers additional features such as ultra-short summaries, sharing options, and usage statistics.
ChatPDF
ChatPDF is an AI-powered tool that allows users to interact with PDF documents in a conversational manner. It uses natural language processing (NLP) to understand user queries and provide relevant information or perform actions on the PDF. With ChatPDF, users can ask questions about the content of the PDF, search for specific information, extract data, translate text, and more, all through a simple chat-like interface.
Summarize This
Summarize This is an AI-powered tool that provides instant summaries for text, PDFs, websites, and YouTube videos. It utilizes advanced AI algorithms to extract the most important information from any content, making it easier and faster to gather insights. With Summarize This, you can quickly condense large amounts of text into concise summaries, saving you time and effort. The tool is particularly useful for students, researchers, professionals, and anyone who needs to process large amounts of information efficiently.
iTextMaster
iTextMaster is an AI-powered tool that allows users to analyze, summarize, and chat with text-based documents, including PDFs and web pages. It utilizes ChatGPT technology to provide intelligent answers to questions and extract key information from documents. The tool is designed to simplify text processing, improve understanding efficiency, and save time. iTextMaster supports multiple languages and offers a user-friendly interface for easy navigation and interaction.
FileDrop
FileDrop is a file or document manager that allows you to drag and drop files into a document with automatic linking and save them to Google Drive. It also offers features like OCR, translation, and AI integration. With FileDrop, you can easily insert, save, and link files in Google Sheets cells, Docs, and Slides.
ChatPhoto
ChatPhoto is an AI-powered tool that allows users to convert images into text. It can be used to extract text from photos, translate text into different languages, and ask questions about images. ChatPhoto is free to use, with a premium subscription available for additional features.
PDFChat
PDFChat is an AI-powered tool that allows users to interact with, extract, and understand PDF documents in any language. It uses advanced AI techniques to analyze documents, enabling users to have conversations with their documents and get answers to their questions quickly and easily. PDFChat is designed to boost productivity and save users hours of manual research.
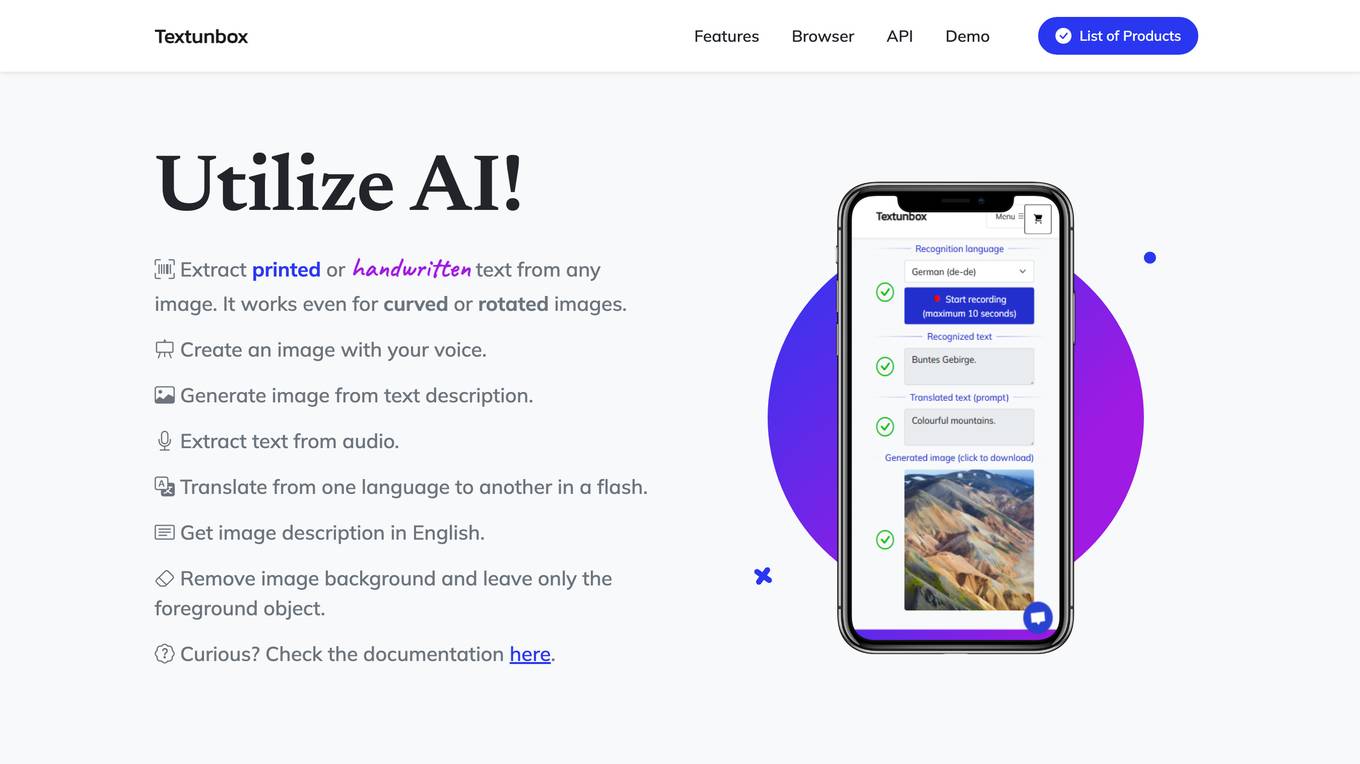
TextUnbox
TextUnbox is an AI-powered tool that allows users to extract text from images, generate images from text descriptions, translate text, remove image backgrounds, and more. It supports over 20 languages and can be used in the browser or integrated into custom solutions using its REST API.
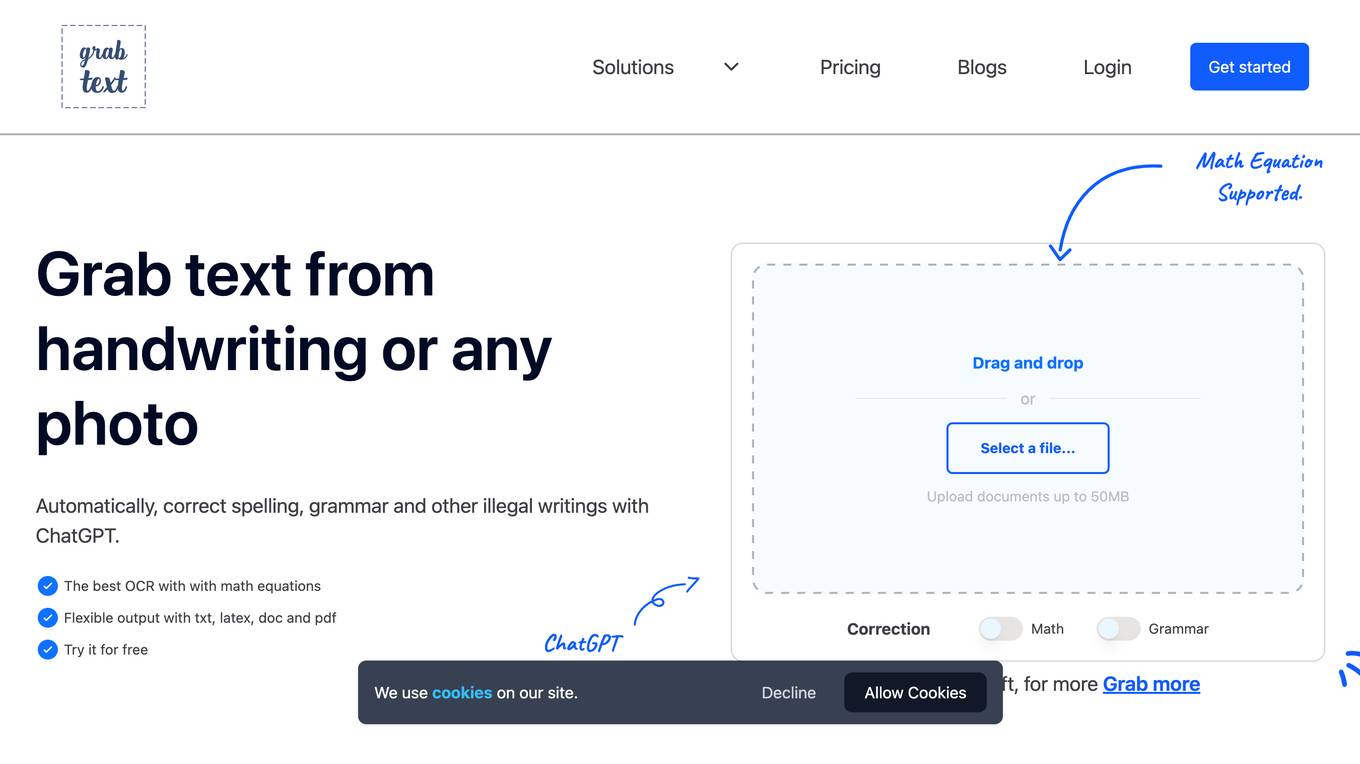
GrabText
GrabText is an online OCR tool that allows users to convert handwritten or printed text from photos, graphics, or documents into editable text. It uses ChatGPT to automatically correct spelling, grammar, and other illegal writings. The tool also supports math equations and offers flexible output options such as txt, latex, doc, and pdf.
Winston AI
Winston AI is a leading AI content detection tool designed to help users identify AI-generated text from ChatGPT, GPT-4, Google Bard, and other large language models. It offers a range of features, including AI content detection, plagiarism checking, readability scoring, and OCR (Optical Character Recognition) technology for extracting text from scanned documents or pictures. Winston AI is committed to providing accurate and reliable AI detection, with a 99.98% accuracy rate and continuous updates to keep up with the latest advancements in AI writing tools.
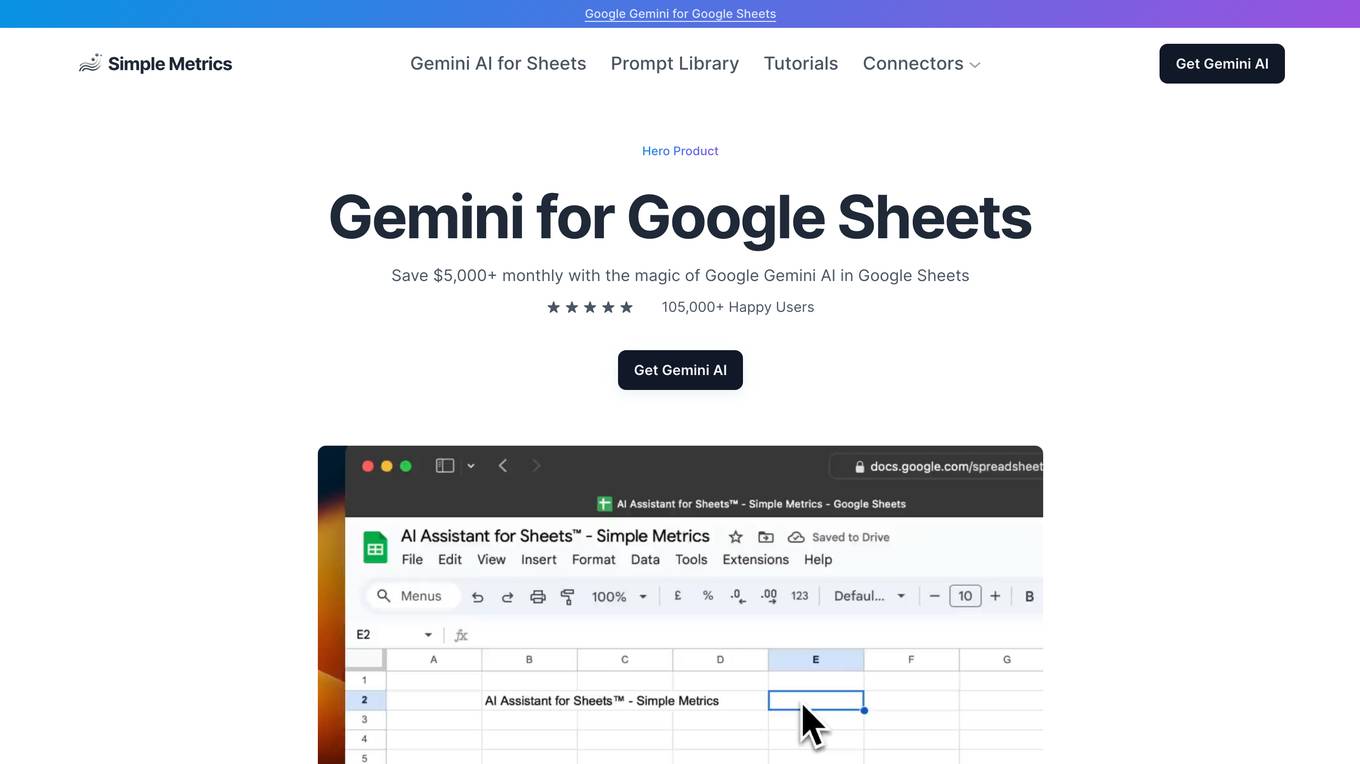
Simple Metrics - Google Gemini AI in Google Sheets
Simple Metrics' Gemini AI for Google Sheets is a powerful tool that allows users to harness the power of AI directly within Google Sheets. With a suite of 10 AI formulas and the ability to perform full sheet analysis, Gemini AI empowers users to automate tasks, gain valuable insights, and streamline their workflows. Its user-friendly interface and customizable settings make it accessible to users of all levels, while its free tier ensures that everyone can experience the benefits of AI in Google Sheets.
Yatter AI
Yatter AI is a powerful AI tool available on WhatsApp and Telegram, designed to enhance productivity, content writing, and career growth. It leverages top AI models and technologies from companies like ChatGPT, Google Gemini, Meta AI, and Groq AI to provide users with advanced features such as voice AI chat messaging, image detection, reminder scheduling, real-time weather updates, multilingual conversation support, and more. Yatter AI revolutionizes communication and information retrieval, offering seamless interactions and personalized experiences for users worldwide.
Docubase.ai
Docubase.ai is a powerful document analysis tool that uses advanced natural language processing and machine learning to extract information and provide relevant answers to your queries. It can automatically extract text content from uploaded documents, generate relevant questions, and extract answers from the document content. Docubase.ai supports a wide range of document formats, including PDF, Word, Excel, PowerPoint, and text documents. It also allows users to ask their own questions and provides options to export answers in different formats for easy sharing and documentation.
Honeybear.ai
Honeybear.ai is an AI tool designed to simplify document reading tasks. It utilizes advanced algorithms to extract and analyze text from various documents, making it easier for users to access and comprehend information. With Honeybear.ai, users can streamline their document processing workflows and enhance productivity.
MVSEP - Music & Voice Separation
MVSEP is an AI-powered application that specializes in music and voice separation. It offers users the ability to separate audio files into voice and music parts using advanced algorithms and models. Users can easily upload files through drag and drop or remote upload features. The application provides various separation types, HQ models, and output encoding options to cater to different user needs. MVSEP aims to enhance the audio editing experience by providing high-quality results and a user-friendly interface.
20 - Open Source AI Tools

deepdoctection
**deep** doctection is a Python library that orchestrates document extraction and document layout analysis tasks using deep learning models. It does not implement models but enables you to build pipelines using highly acknowledged libraries for object detection, OCR and selected NLP tasks and provides an integrated framework for fine-tuning, evaluating and running models. For more specific text processing tasks use one of the many other great NLP libraries. **deep** doctection focuses on applications and is made for those who want to solve real world problems related to document extraction from PDFs or scans in various image formats. **deep** doctection provides model wrappers of supported libraries for various tasks to be integrated into pipelines. Its core function does not depend on any specific deep learning library. Selected models for the following tasks are currently supported: * Document layout analysis including table recognition in Tensorflow with **Tensorpack**, or PyTorch with **Detectron2**, * OCR with support of **Tesseract**, **DocTr** (Tensorflow and PyTorch implementations available) and a wrapper to an API for a commercial solution, * Text mining for native PDFs with **pdfplumber**, * Language detection with **fastText**, * Deskewing and rotating images with **jdeskew**. * Document and token classification with all LayoutLM models provided by the **Transformer library**. (Yes, you can use any LayoutLM-model with any of the provided OCR-or pdfplumber tools straight away!). * Table detection and table structure recognition with **table-transformer**. * There is a small dataset for token classification available and a lot of new tutorials to show, how to train and evaluate this dataset using LayoutLMv1, LayoutLMv2, LayoutXLM and LayoutLMv3. * Comprehensive configuration of **analyzer** like choosing different models, output parsing, OCR selection. Check this notebook or the docs for more infos. * Document layout analysis and table recognition now runs with **Torchscript** (CPU) as well and **Detectron2** is not required anymore for basic inference. * [**new**] More angle predictors for determining the rotation of a document based on **Tesseract** and **DocTr** (not contained in the built-in Analyzer). * [**new**] Token classification with **LiLT** via **transformers**. We have added a model wrapper for token classification with LiLT and added a some LiLT models to the model catalog that seem to look promising, especially if you want to train a model on non-english data. The training script for LayoutLM can be used for LiLT as well and we will be providing a notebook on how to train a model on a custom dataset soon. **deep** doctection provides on top of that methods for pre-processing inputs to models like cropping or resizing and to post-process results, like validating duplicate outputs, relating words to detected layout segments or ordering words into contiguous text. You will get an output in JSON format that you can customize even further by yourself. Have a look at the **introduction notebook** in the notebook repo for an easy start. Check the **release notes** for recent updates. **deep** doctection or its support libraries provide pre-trained models that are in most of the cases available at the **Hugging Face Model Hub** or that will be automatically downloaded once requested. For instance, you can find pre-trained object detection models from the Tensorpack or Detectron2 framework for coarse layout analysis, table cell detection and table recognition. Training is a substantial part to get pipelines ready on some specific domain, let it be document layout analysis, document classification or NER. **deep** doctection provides training scripts for models that are based on trainers developed from the library that hosts the model code. Moreover, **deep** doctection hosts code to some well established datasets like **Publaynet** that makes it easy to experiment. It also contains mappings from widely used data formats like COCO and it has a dataset framework (akin to **datasets** so that setting up training on a custom dataset becomes very easy. **This notebook** shows you how to do this. **deep** doctection comes equipped with a framework that allows you to evaluate predictions of a single or multiple models in a pipeline against some ground truth. Check again **here** how it is done. Having set up a pipeline it takes you a few lines of code to instantiate the pipeline and after a for loop all pages will be processed through the pipeline.
thepipe
The Pipe is a multimodal-first tool for feeding files and web pages into vision-language models such as GPT-4V. It is best for LLM and RAG applications that require a deep understanding of tricky data sources. The Pipe is available as a hosted API at thepi.pe, or it can be set up locally.

HuggingFists
HuggingFists is a low-code data flow tool that enables convenient use of LLM and HuggingFace models. It provides functionalities similar to Langchain, allowing users to design, debug, and manage data processing workflows, create and schedule workflow jobs, manage resources environment, and handle various data artifact resources. The tool also offers account management for users, allowing centralized management of data source accounts and API accounts. Users can access Hugging Face models through the Inference API or locally deployed models, as well as datasets on Hugging Face. HuggingFists supports breakpoint debugging, branch selection, function calls, workflow variables, and more to assist users in developing complex data processing workflows.

extractor
Extractor is an AI-powered data extraction library for Laravel that leverages OpenAI's capabilities to effortlessly extract structured data from various sources, including images, PDFs, and emails. It features a convenient wrapper around OpenAI Chat and Completion endpoints, supports multiple input formats, includes a flexible Field Extractor for arbitrary data extraction, and integrates with Textract for OCR functionality. Extractor utilizes JSON Mode from the latest GPT-3.5 and GPT-4 models, providing accurate and efficient data extraction.
gemini_multipdf_chat
Gemini PDF Chatbot is a Streamlit-based application that allows users to chat with a conversational AI model trained on PDF documents. The chatbot extracts information from uploaded PDF files and answers user questions based on the provided context. It features PDF upload, text extraction, conversational AI using the Gemini model, and a chat interface. Users can deploy the application locally or to the cloud, and the project structure includes main application script, environment variable file, requirements, and documentation. Dependencies include PyPDF2, langchain, Streamlit, google.generativeai, and dotenv.
second-brain-agent
The Second Brain AI Agent Project is a tool designed to empower personal knowledge management by automatically indexing markdown files and links, providing a smart search engine powered by OpenAI, integrating seamlessly with different note-taking methods, and enhancing productivity by accessing information efficiently. The system is built on LangChain framework and ChromaDB vector store, utilizing a pipeline to process markdown files and extract text and links for indexing. It employs a Retrieval-augmented generation (RAG) process to provide context for asking questions to the large language model. The tool is beneficial for professionals, students, researchers, and creatives looking to streamline workflows, improve study sessions, delve deep into research, and organize thoughts and ideas effortlessly.
llmware
LLMWare is a framework for quickly developing LLM-based applications including Retrieval Augmented Generation (RAG) and Multi-Step Orchestration of Agent Workflows. This project provides a comprehensive set of tools that anyone can use - from a beginner to the most sophisticated AI developer - to rapidly build industrial-grade, knowledge-based enterprise LLM applications. Our specific focus is on making it easy to integrate open source small specialized models and connecting enterprise knowledge safely and securely.

phidata
Phidata is a framework for building AI Assistants with memory, knowledge, and tools. It enables LLMs to have long-term conversations by storing chat history in a database, provides them with business context by storing information in a vector database, and enables them to take actions like pulling data from an API, sending emails, or querying a database. Memory and knowledge make LLMs smarter, while tools make them autonomous.

DistiLlama
DistiLlama is a Chrome extension that leverages a locally running Large Language Model (LLM) to perform various tasks, including text summarization, chat, and document analysis. It utilizes Ollama as the locally running LLM instance and LangChain for text summarization. DistiLlama provides a user-friendly interface for interacting with the LLM, allowing users to summarize web pages, chat with documents (including PDFs), and engage in text-based conversations. The extension is easy to install and use, requiring only the installation of Ollama and a few simple steps to set up the environment. DistiLlama offers a range of customization options, including the choice of LLM model and the ability to configure the summarization chain. It also supports multimodal capabilities, allowing users to interact with the LLM through text, voice, and images. DistiLlama is a valuable tool for researchers, students, and professionals who seek to leverage the power of LLMs for various tasks without compromising data privacy.

MegaParse
MegaParse is a powerful and versatile parser designed to handle various types of documents such as text, PDFs, Powerpoint presentations, and Word documents with no information loss. It is fast, efficient, and open source, supporting a wide range of file formats. MegaParse ensures compatibility with tables, table of contents, headers, footers, and images, making it a comprehensive solution for document parsing.
langroid
Langroid is a Python framework that makes it easy to build LLM-powered applications. It uses a multi-agent paradigm inspired by the Actor Framework, where you set up Agents, equip them with optional components (LLM, vector-store and tools/functions), assign them tasks, and have them collaboratively solve a problem by exchanging messages. Langroid is a fresh take on LLM app-development, where considerable thought has gone into simplifying the developer experience; it does not use Langchain.
llm-graph-builder
Knowledge Graph Builder App is a tool designed to convert PDF documents into a structured knowledge graph stored in Neo4j. It utilizes OpenAI's GPT/Diffbot LLM to extract nodes, relationships, and properties from PDF text content. Users can upload files from local machine or S3 bucket, choose LLM model, and create a knowledge graph. The app integrates with Neo4j for easy visualization and querying of extracted information.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.

AIlice
AIlice is a fully autonomous, general-purpose AI agent that aims to create a standalone artificial intelligence assistant, similar to JARVIS, based on the open-source LLM. AIlice achieves this goal by building a "text computer" that uses a Large Language Model (LLM) as its core processor. Currently, AIlice demonstrates proficiency in a range of tasks, including thematic research, coding, system management, literature reviews, and complex hybrid tasks that go beyond these basic capabilities. AIlice has reached near-perfect performance in everyday tasks using GPT-4 and is making strides towards practical application with the latest open-source models. We will ultimately achieve self-evolution of AI agents. That is, AI agents will autonomously build their own feature expansions and new types of agents, unleashing LLM's knowledge and reasoning capabilities into the real world seamlessly.

spring-ai
The Spring AI project provides a Spring-friendly API and abstractions for developing AI applications. It offers a portable client API for interacting with generative AI models, enabling developers to easily swap out implementations and access various models like OpenAI, Azure OpenAI, and HuggingFace. Spring AI also supports prompt engineering, providing classes and interfaces for creating and parsing prompts, as well as incorporating proprietary data into generative AI without retraining the model. This is achieved through Retrieval Augmented Generation (RAG), which involves extracting, transforming, and loading data into a vector database for use by AI models. Spring AI's VectorStore abstraction allows for seamless transitions between different vector database implementations.
awesome-chatgpt
Awesome ChatGPT is an artificial intelligence chatbot developed by OpenAI. It offers a wide range of applications, web apps, browser extensions, CLI tools, bots, integrations, and packages for various platforms. Users can interact with ChatGPT through different interfaces and use it for tasks like generating text, creating presentations, summarizing content, and more. The ecosystem around ChatGPT includes tools for developers, writers, researchers, and individuals looking to leverage AI technology for different purposes.
20 - OpenAI Gpts


PDF Ninja
I extract data and tables from PDFs to CSV, focusing on data privacy and precision.


Spreadsheet Composer
Magically turning text from emails, lists and website content into spreadsheet tables
kz image 2 typescript 2 image
Generate a Structured description in typescript format from the image and generate an image from that description. and OCR

Digest Bot
I provide detailed summaries, critiques, and inferences on articles, papers, transcripts, websites, and more. Just give me text, a URL, or file to digest.
ExtractWisdom
Takes in any text and extracts the wisdom from it like you spent 3 hours taking handwritten notes.
Ringkesan
Nyimpulkeun sareng nimba poin konci tina téks, artikel, video, dokumén sareng seueur deui