Best AI tools for< Deploy Llms >
20 - AI tool Sites

Tune AI
Tune AI is an enterprise Gen AI stack that offers custom models to build competitive advantage. It provides a range of features such as accelerating coding, content creation, indexing patent documents, data audit, automatic speech recognition, and more. The application leverages generative AI to help users solve real-world problems and create custom models on top of industry-leading open source models. With enterprise-grade security and flexible infrastructure, Tune AI caters to developers and enterprises looking to harness the power of AI.
Predibase
Predibase is a platform for fine-tuning and serving Large Language Models (LLMs). It provides a cost-effective and efficient way to train and deploy LLMs for a variety of tasks, including classification, information extraction, customer sentiment analysis, customer support, code generation, and named entity recognition. Predibase is built on proven open-source technology, including LoRAX, Ludwig, and Horovod.
Unified DevOps platform to build AI applications
This is a unified DevOps platform to build AI applications. It provides a comprehensive set of tools and services to help developers build, deploy, and manage AI applications. The platform includes a variety of features such as a code editor, a debugger, a profiler, and a deployment manager. It also provides access to a variety of AI services, such as natural language processing, machine learning, and computer vision.
Composio
Composio is an integration platform for AI Agents and LLMs that allows users to access over 150 tools with just one line of code. It offers seamless integrations, managed authentication, a repository of tools, and powerful RPA tools to streamline and optimize the connection and interaction between AI Agents/LLMs and various APIs/services. Composio simplifies JSON structures, improves variable names, and enhances error handling to increase reliability by 30%. The platform is SOC Type II compliant, ensuring maximum security of user data.

Freeplay
Freeplay is a tool that helps product teams experiment, test, monitor, and optimize AI features for customers. It provides a single pane of glass for the entire team, lightweight developer SDKs for Python, Node, and Java, and deployment options to meet compliance needs. Freeplay also offers best practices for the entire AI development lifecycle.
JFrog ML
JFrog ML is an AI platform designed to streamline AI development from prototype to production. It offers a unified MLOps platform to build, train, deploy, and manage AI workflows at scale. With features like Feature Store, LLMOps, and model monitoring, JFrog ML empowers AI teams to collaborate efficiently and optimize AI & ML models in production.

Fireworks
Fireworks is a generative AI platform for product innovation. It provides developers with access to the world's leading generative AI models, at the fastest speeds. With Fireworks, developers can build and deploy AI-powered applications quickly and easily.
Empower
Empower is a serverless fine-tuned LLM hosting platform that offers a developer platform for fine-tuned LLMs. It provides prebuilt task-specific base models with GPT4 level response quality, enabling users to save up to 80% on LLM bills with just 5 lines of code change. Empower allows users to own their models, offers cost-effective serving with no compromise on performance, and charges on a per-token basis. The platform is designed to be user-friendly, efficient, and cost-effective for deploying and serving fine-tuned LLMs.

OpenPlayground
OpenPlayground is a cloud-based platform that provides access to a variety of AI tools and resources. It allows users to train and deploy machine learning models, access pre-trained models, and collaborate on AI projects. OpenPlayground is designed to make AI more accessible and easier to use for everyone, from beginners to experienced data scientists.

Mirage
Mirage is a custom AI platform that builds custom LLMs to accelerate productivity. It is backed by Sequoia and offers a variety of features, including the ability to create custom AI models, train models on your own data, and deploy models to the cloud or on-premises.
ThirdAI
ThirdAI is an AI platform that offers a production-ready solution for building and deploying AI applications quickly and efficiently. It provides advanced AI/GenAI technology that can run on any infrastructure, reducing barriers to delivering production-grade AI solutions. With features like enterprise SSO, built-in models, no-code interface, and more, ThirdAI empowers users to create AI applications without the need for specialized GPU servers or AI skills. The platform covers the entire workflow of building AI applications end-to-end, allowing for easy customization and deployment in various environments.
Arcee AI
Arcee AI is a platform that offers a cost-effective, secure, end-to-end solution for building and deploying Small Language Models (SLMs). It allows users to merge and train custom language models by leveraging open source models and their own data. The platform is known for its Model Merging technique, which combines the power of pre-trained Large Language Models (LLMs) with user-specific data to create high-performing models across various industries.
Cohere
Cohere is the leading AI platform for enterprise, offering generative AI, search and discovery, and advanced retrieval solutions. Their models are designed to enhance the global workforce, empowering businesses to thrive in the AI era. With features like Cohere Command, Cohere Embed, and Cohere Rerank, the platform enables the development of scalable and efficient AI-powered applications. Cohere focuses on optimizing enterprise data through language-based models, supporting over 100 languages for enhanced accuracy and efficiency.
Denvr DataWorks AI Cloud
Denvr DataWorks AI Cloud is a cloud-based AI platform that provides end-to-end AI solutions for businesses. It offers a range of features including high-performance GPUs, scalable infrastructure, ultra-efficient workflows, and cost efficiency. Denvr DataWorks is an NVIDIA Elite Partner for Compute, and its platform is used by leading AI companies to develop and deploy innovative AI solutions.
LangChain
LangChain is a framework for developing applications powered by large language models (LLMs). It simplifies every stage of the LLM application lifecycle, including development, productionization, and deployment. LangChain consists of open-source libraries such as langchain-core, langchain-community, and partner packages. It also includes LangGraph for building stateful agents and LangSmith for debugging and monitoring LLM applications.
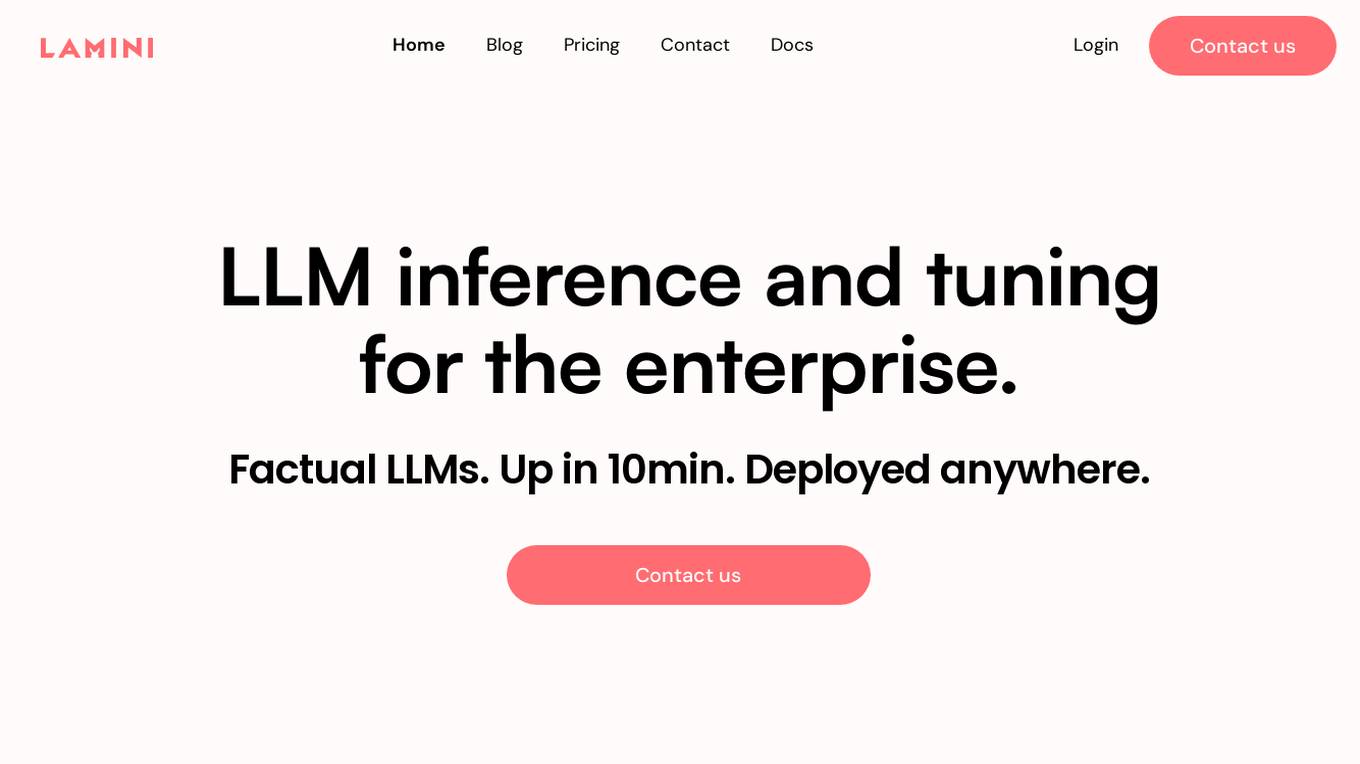
Lamini
Lamini is an enterprise-level LLM platform that offers precise recall with Memory Tuning, enabling teams to achieve over 95% accuracy even with large amounts of specific data. It guarantees JSON output and delivers massive throughput for inference. Lamini is designed to be deployed anywhere, including air-gapped environments, and supports training and inference on Nvidia or AMD GPUs. The platform is known for its factual LLMs and reengineered decoder that ensures 100% schema accuracy in the JSON output.
deepset
deepset is an AI platform that offers enterprise-level products and solutions for AI teams. It provides deepset Cloud, a platform built with Haystack, enabling fast and accurate prototyping, building, and launching of advanced AI applications. The platform streamlines the AI application development lifecycle, offering processes, tools, and expertise to move from prototype to production efficiently. With deepset Cloud, users can optimize solution accuracy, performance, and cost, and deploy AI applications at any scale with one click. The platform also allows users to explore new models and configurations without limits, extending their team with access to world-class AI engineers for guidance and support.
Langtail
Langtail is a platform that helps developers build, test, and deploy AI-powered applications. It provides a suite of tools to help developers debug prompts, run tests, and monitor the performance of their AI models. Langtail also offers a community forum where developers can share tips and tricks, and get help from other users.
Anyscale
Anyscale is a company that provides a scalable compute platform for AI and Python applications. Their platform includes a serverless API for serving and fine-tuning open LLMs, a private cloud solution for data privacy and governance, and an open source framework for training, batch, and real-time workloads. Anyscale's platform is used by companies such as OpenAI, Uber, and Spotify to power their AI workloads.

Dify.AI
Dify.AI is a generative AI application development platform that allows users to create AI agents, chatbots, and other AI-powered applications. It provides a variety of tools and services to help developers build, deploy, and manage their AI applications. Dify.AI is designed to be easy to use, even for those with no prior experience in AI development.
9 - Open Source AI Tools

litgpt
LitGPT is a command-line tool designed to easily finetune, pretrain, evaluate, and deploy 20+ LLMs **on your own data**. It features highly-optimized training recipes for the world's most powerful open-source large-language-models (LLMs).
llm-engine
Scale's LLM Engine is an open-source Python library, CLI, and Helm chart that provides everything you need to serve and fine-tune foundation models, whether you use Scale's hosted infrastructure or do it in your own cloud infrastructure using Kubernetes.

LLaMA-Factory
LLaMA Factory is a unified framework for fine-tuning 100+ large language models (LLMs) with various methods, including pre-training, supervised fine-tuning, reward modeling, PPO, DPO and ORPO. It features integrated algorithms like GaLore, BAdam, DoRA, LongLoRA, LLaMA Pro, LoRA+, LoftQ and Agent tuning, as well as practical tricks like FlashAttention-2, Unsloth, RoPE scaling, NEFTune and rsLoRA. LLaMA Factory provides experiment monitors like LlamaBoard, TensorBoard, Wandb, MLflow, etc., and supports faster inference with OpenAI-style API, Gradio UI and CLI with vLLM worker. Compared to ChatGLM's P-Tuning, LLaMA Factory's LoRA tuning offers up to 3.7 times faster training speed with a better Rouge score on the advertising text generation task. By leveraging 4-bit quantization technique, LLaMA Factory's QLoRA further improves the efficiency regarding the GPU memory.

LLM-PowerHouse-A-Curated-Guide-for-Large-Language-Models-with-Custom-Training-and-Inferencing
LLM-PowerHouse is a comprehensive and curated guide designed to empower developers, researchers, and enthusiasts to harness the true capabilities of Large Language Models (LLMs) and build intelligent applications that push the boundaries of natural language understanding. This GitHub repository provides in-depth articles, codebase mastery, LLM PlayLab, and resources for cost analysis and network visualization. It covers various aspects of LLMs, including NLP, models, training, evaluation metrics, open LLMs, and more. The repository also includes a collection of code examples and tutorials to help users build and deploy LLM-based applications.

llm-foundry
LLM Foundry is a codebase for training, finetuning, evaluating, and deploying LLMs for inference with Composer and the MosaicML platform. It is designed to be easy-to-use, efficient _and_ flexible, enabling rapid experimentation with the latest techniques. You'll find in this repo: * `llmfoundry/` - source code for models, datasets, callbacks, utilities, etc. * `scripts/` - scripts to run LLM workloads * `data_prep/` - convert text data from original sources to StreamingDataset format * `train/` - train or finetune HuggingFace and MPT models from 125M - 70B parameters * `train/benchmarking` - profile training throughput and MFU * `inference/` - convert models to HuggingFace or ONNX format, and generate responses * `inference/benchmarking` - profile inference latency and throughput * `eval/` - evaluate LLMs on academic (or custom) in-context-learning tasks * `mcli/` - launch any of these workloads using MCLI and the MosaicML platform * `TUTORIAL.md` - a deeper dive into the repo, example workflows, and FAQs

EdgeChains
EdgeChains is an open-source chain-of-thought engineering framework tailored for Large Language Models (LLMs)- like OpenAI GPT, LLama2, Falcon, etc. - With a focus on enterprise-grade deployability and scalability. EdgeChains is specifically designed to **orchestrate** such applications. At EdgeChains, we take a unique approach to Generative AI - we think Generative AI is a deployment and configuration management challenge rather than a UI and library design pattern challenge. We build on top of a tech that has solved this problem in a different domain - Kubernetes Config Management - and bring that to Generative AI. Edgechains is built on top of jsonnet, originally built by Google based on their experience managing a vast amount of configuration code in the Borg infrastructure.
llm-action
This repository provides a comprehensive guide to large language models (LLMs), covering various aspects such as training, fine-tuning, compression, and applications. It includes detailed tutorials, code examples, and explanations of key concepts and techniques. The repository is maintained by Liguo Dong, an AI researcher and engineer with expertise in LLM research and development.

llm-on-openshift
This repository provides resources, demos, and recipes for working with Large Language Models (LLMs) on OpenShift using OpenShift AI or Open Data Hub. It includes instructions for deploying inference servers for LLMs, such as vLLM, Hugging Face TGI, Caikit-TGIS-Serving, and Ollama. Additionally, it offers guidance on deploying serving runtimes, such as vLLM Serving Runtime and Hugging Face Text Generation Inference, in the Single-Model Serving stack of Open Data Hub or OpenShift AI. The repository also covers vector databases that can be used as a Vector Store for Retrieval Augmented Generation (RAG) applications, including Milvus, PostgreSQL+pgvector, and Redis. Furthermore, it provides examples of inference and application usage, such as Caikit, Langchain, Langflow, and UI examples.
TensorRT-LLM
TensorRT-LLM is an easy-to-use Python API to define Large Language Models (LLMs) and build TensorRT engines that contain state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorRT-LLM contains components to create Python and C++ runtimes that execute those TensorRT engines. It also includes a backend for integration with the NVIDIA Triton Inference Server; a production-quality system to serve LLMs. Models built with TensorRT-LLM can be executed on a wide range of configurations going from a single GPU to multiple nodes with multiple GPUs (using Tensor Parallelism and/or Pipeline Parallelism).
20 - OpenAI Gpts
Frontend Developer
AI front-end developer expert in coding React, Nextjs, Vue, Svelte, Typescript, Gatsby, Angular, HTML, CSS, JavaScript & advanced in Flexbox, Tailwind & Material Design. Mentors in coding & debugging for junior, intermediate & senior front-end developers alike. Let’s code, build & deploy a SaaS app.





Azure Arc Expert
Azure Arc expert providing guidance on architecture, deployment, and management.


Instructor GCP ML
Formador para la certificación de ML Engineer en GCP, con respuestas y explicaciones detalladas.

Docker and Docker Swarm Assistant
Expert in Docker and Docker Swarm solutions and troubleshooting.



Cloudwise Consultant
Expert in cloud-native solutions, provides tailored tech advice and cost estimates.