Best AI tools for< Create Audio Slideshows >
20 - AI tool Sites
imagetomp3.com
imagetomp3.com is a website that allows users to convert images to MP3 audio files. The platform provides a simple and user-friendly interface for converting images to audio, making it easy for users to create audio files from their images. Users can upload their images, select the desired output format, and quickly convert them to MP3 files. imagetomp3.com is a convenient tool for individuals looking to convert images to audio for various purposes, such as creating audio slideshows, converting text to speech, or generating audio content from visual media.
Voicemaker
Voicemaker is a text-to-speech converter that allows users to create audio files for commercial use. It offers a variety of features, including the ability to select from a range of AI-powered voices, adjust the speed, pitch, and volume of the audio, and add background music. Voicemaker's audio files can be shared on any platform worldwide and are trusted by over 1000 well-known brands.
Audyo
Audyo is a text-to-speech tool that allows users to create realistic-sounding audio from text. With over 100 voices to choose from, users can create audio in a variety of languages and accents. Audyo is easy to use, simply type in your text and select a voice. You can then download your audio file or embed it on your website or blog. Audyo is a great tool for creating voiceovers for videos, podcasts, audiobooks, and more.
Guide.AI
Guide.AI is a revolutionary platform that allows users to create and publish audio guides using advanced AI text-to-speech technology. Users can develop high-quality audio guides in 13 different languages without the need for audio recordings. The platform offers a user-friendly experience for both guide authors and users, enabling quick and easy creation of audio guides for free. Guide.AI aims to make locations more accessible for all visitors, including those who are partially sighted, by providing a sustainable and engaging alternative to traditional audio guide hardware.
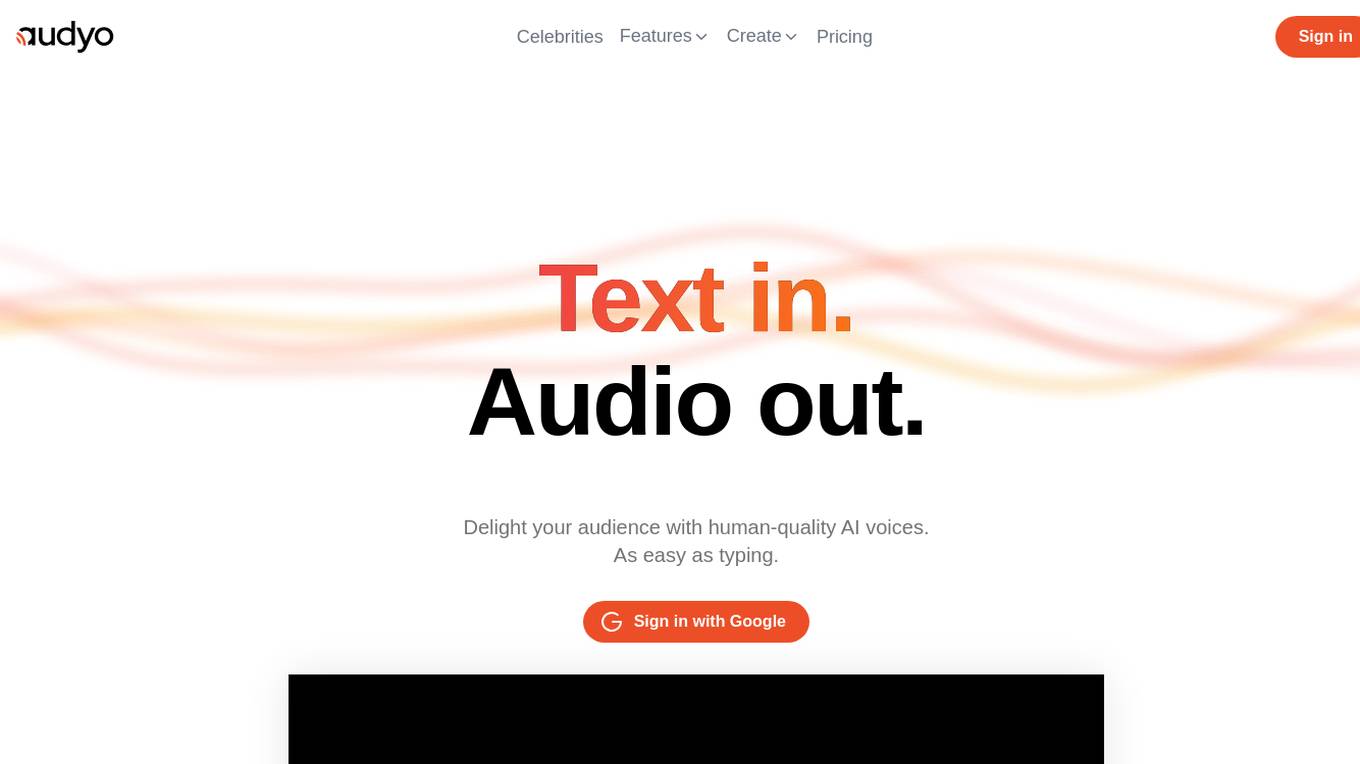
Audyo
Audyo is an AI tool that allows users to create human-quality AI voices easily by simply typing text. With over 100 voices to choose from, users can select speakers in various languages, accents, and even celebrity impersonators. The tool enables users to edit words, not waveforms, and export audio for use in videos, podcasts, presentations, and more. Audyo also offers features like creating conversations, mixing and matching languages, customizing pronunciations, and utilizing an AI assistant for script tweaking. Users can enjoy 15 minutes of audio generation with a free account and earn additional time by inviting friends. Audyo empowers creators to unleash their imagination and enhance their content with lifelike AI voices.
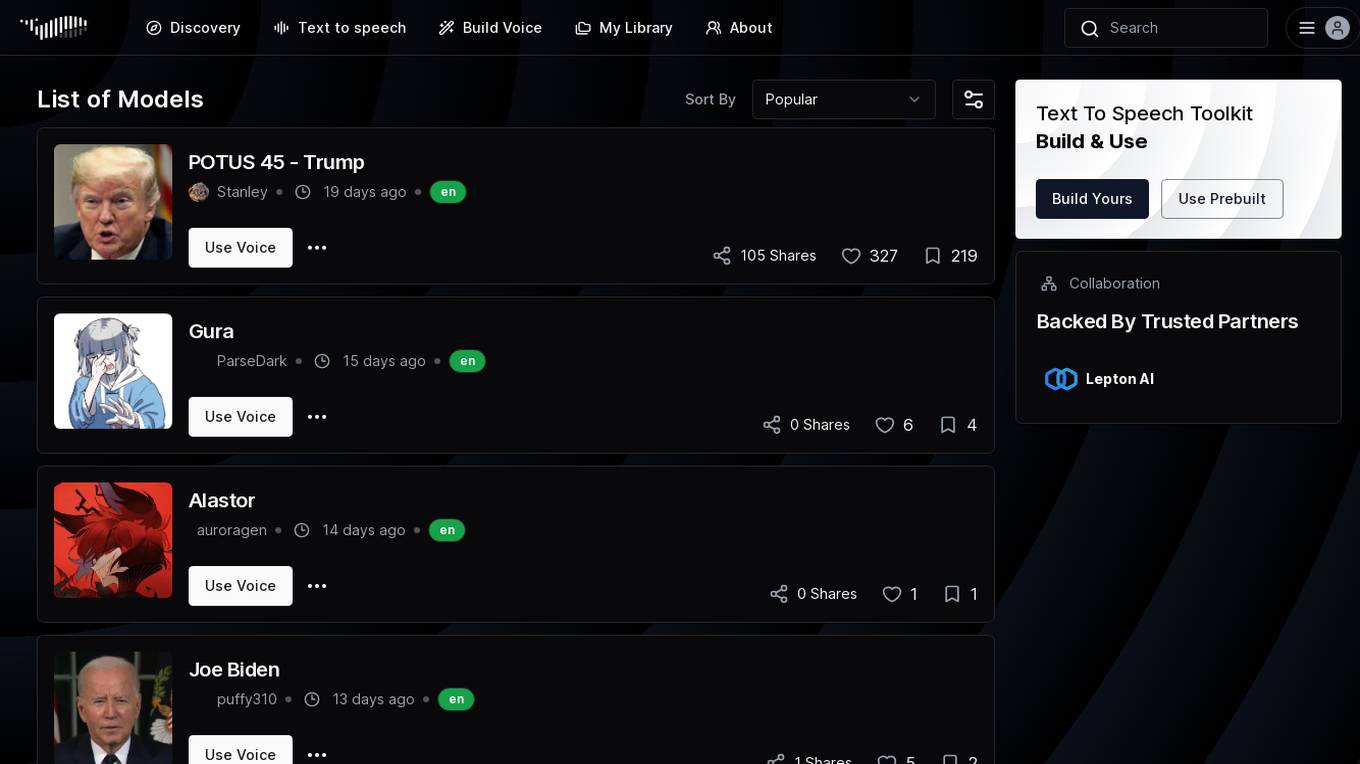
Fish Audio
Fish Audio is an AI-powered audio generation tool that allows users to convert text into speech. With a user-friendly interface, it offers a range of models for generating high-quality voices. Users can build their own voice models or use prebuilt ones, and collaborate with others. Backed by trusted partners, Fish Audio leverages Lepton AI's top models to provide a seamless experience for creating audio content.
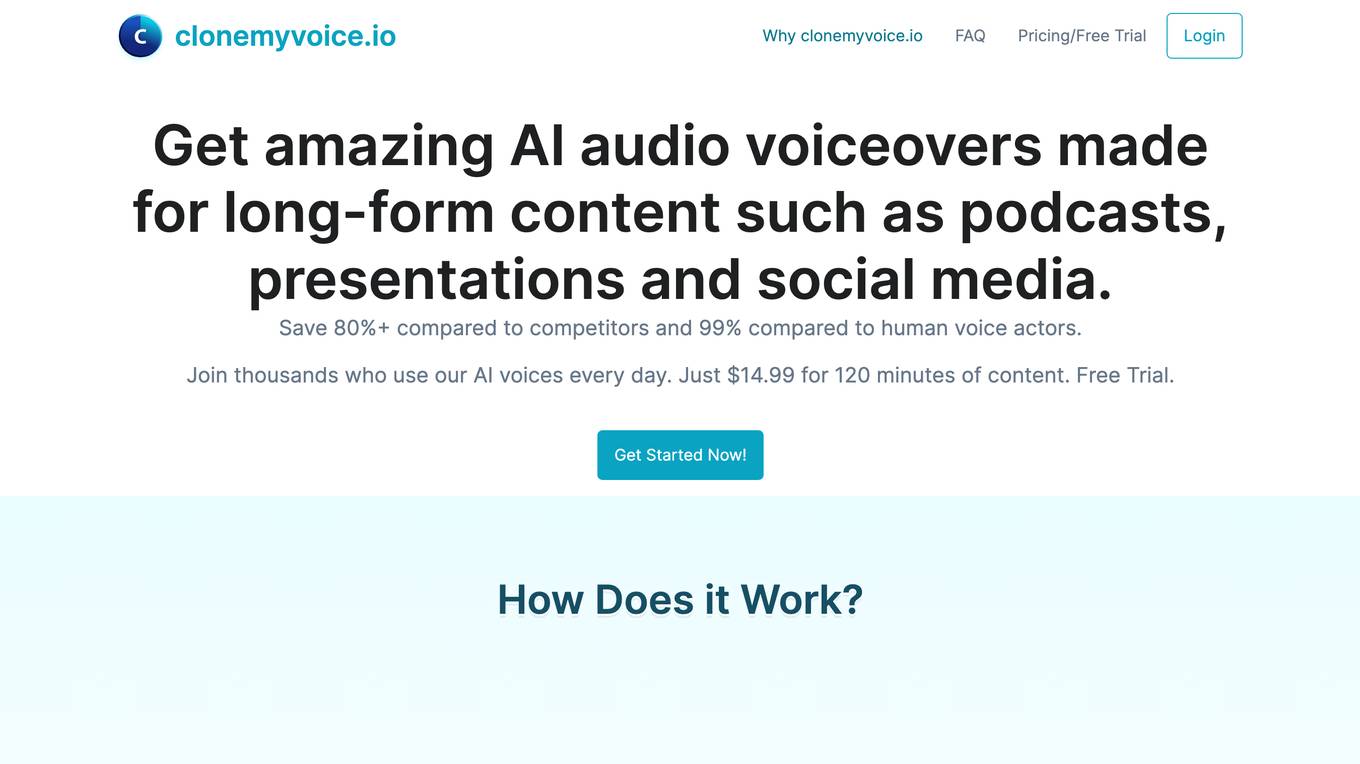
CloneMyVoice
CloneMyVoice is an AI tool that specializes in creating AI audio voiceovers for long-form content such as podcasts, presentations, and social media. Users can save up to 80% compared to competitors and 99% compared to human voice actors. The platform allows users to upload source audio files and text, provide voice samples, and receive processed audio files within one hour. CloneMyVoice offers the ability to create audio presentations, social media content, podcasts, and audio books effortlessly. The AI can generate flawless English voices with British or American accents, capturing the tone and essence of the original voice.
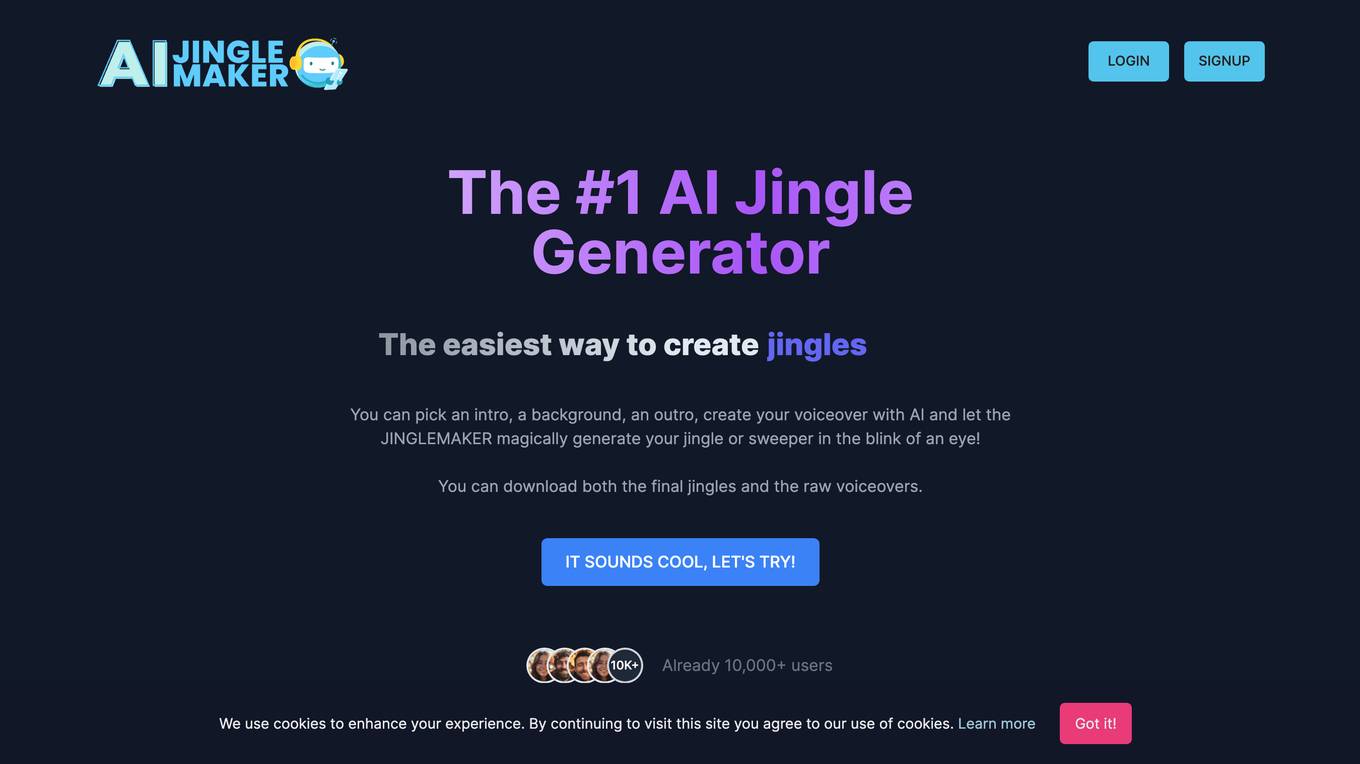
AI JingleMaker
AI JingleMaker is an easy and affordable audio jingle creation tool that leverages generative AI to help users create jingles, DJ drops, sweepers, station IDs, podcast intros, and promos. With over 30,000 users, 35+ voices, 250+ sound effects, and unlimited variations, the tool allows users to pick an intro, background, and outro, create voiceovers with AI, and generate jingles or sweepers instantly. It offers a zero learning curve, instant creation, and the ability to download both final jingles and raw voiceovers in MP3 format.
Adobe Podcast
Adobe Podcast is an AI-powered audio recording and editing tool that allows users to create and edit podcasts entirely on the web. With Adobe Podcast, users can record high-quality audio, add music and sound effects, and edit their recordings with ease. Adobe Podcast also offers a variety of features to help users promote and distribute their podcasts.
Voxify
Voxify is an AI voice generator tool that allows users to effortlessly create immersive audio experiences by converting text to speech. With over 450 voices available in more than 120 languages and accents, users can customize every aspect of the narration, including pitch, speed, and emotion. Ideal for content creators, podcasters, and educators looking to enhance the quality of their voiceovers, Voxify offers a user-friendly interface and a wide range of customization options to bring text to life through realistic and engaging voice generation.

Speakperfect
Speakperfect is an AI tool that enables users to create flawless audio effortlessly. It allows users to transform their speech into perfect scripts and audio with ease. The tool offers features such as creating great flow, removing filler words, selecting appropriate words, outputting to multiple languages, and generating indistinguishable voice clones. Users can record or upload content, transform it, and generate professional voice-overs. Speakperfect is praised for its simplicity, usefulness, and potential in various areas like work communication, marketing, and content creation.
Kubee
Kubee is a platform that allows users to create digital avatars and interact with each other. It uses AI to generate realistic avatars and animate them in real-time. Kubee also allows users to create and share their own virtual worlds, and to mint NFTs of their avatars and creations. The platform is designed to be a social space where users can connect with each other and express themselves creatively.
Woord
Woord is an online text-to-speech (TTS) tool that allows users to convert text into natural-sounding speech. It offers a wide range of voices in over 34 languages, including regional variations. Woord also provides advanced features such as SSML editing, OCR support, and API access. With its user-friendly interface and affordable pricing, Woord is a great choice for individuals and businesses looking to add speech capabilities to their applications.
Audiobox
Audiobox is an AI tool developed by Meta for audio generation. It allows users to create custom audio content by generating voices and sound effects using voice inputs and natural language text prompts. The tool is designed to be user-friendly and versatile, catering to a wide range of use cases. Audiobox offers a series of interactive audio demos to showcase its unique capabilities and provides a platform for users to express their creativity through audio storytelling. The tool is built upon the shared self-supervised model Audiobox SSL, ensuring a safe and reliable AI experience for all users.
ButterReader
ButterReader is an innovative audio widget designed to transform blog texts into engaging, listenable content, making learning and information consumption as smooth as butter. It offers a range of customization options to tailor the widget's appearance and functionality to match your brand's style and audience preferences. With ButterReader, you can add a rich auditory layer to your website and blog posts, making them more accessible and appealing to a diverse audience.
Beepbooply
Beepbooply is a text-to-speech tool that uses artificial intelligence to generate realistic and natural-sounding speech. With over 900 voices to choose from, you can create audio content for any purpose, including videos, podcasts, and customer service. Beepbooply is easy to use and affordable, making it a great option for anyone who needs to create high-quality audio content.
ChatTTS
ChatTTS is a text-to-speech tool optimized for natural, conversational scenarios. It supports both Chinese and English languages, trained on approximately 100,000 hours of data. With features like multi-language support, large data training, dialog task compatibility, open-source plans, control, security, and ease of use, ChatTTS provides high-quality and natural-sounding voice synthesis. It is designed for conversational tasks, dialogue speech generation, video introductions, educational content synthesis, and more. Users can integrate ChatTTS into their applications using provided API and SDKs for a seamless text-to-speech experience.
DeepZen
DeepZen is an AI-powered text-to-speech platform that enables users to create realistic and expressive audio content from written text. It offers a wide range of features and advantages, making it a valuable tool for various industries and applications. DeepZen's AI technology allows users to produce high-quality audio content quickly and efficiently, without the need for expensive recording studios or voice actors. The platform provides access to a library of professional narrator voices, enabling users to create audio content with the desired tone, emotion, and intonation. DeepZen's technology is transforming the way industries such as publishing, marketing, education, healthcare, services, accessibility, and gaming turn text into speech.

Voicera
Voicera is a text-to-speech tool that allows users to convert written content into natural-sounding speech. With Voicera, users can create audio versions of their articles, blog posts, and other written content, making it more accessible to a wider audience. Voicera offers a variety of features to help users create high-quality audio content, including a library of natural-sounding voices, advanced audio editing tools, and the ability to add music and sound effects.
Vocalx
Vocalx is an AI-powered online tool that converts text into natural-sounding speech. It utilizes advanced speech synthesis technology to generate lifelike voices for various applications. Users can easily create audio content from written text, making it ideal for content creators, educators, and businesses looking to enhance their multimedia offerings. With Vocalx, you can customize the voice, tone, and speed of the generated speech to suit your needs. The tool supports multiple languages and accents, providing a versatile solution for voiceover projects, audiobooks, podcasts, and more.
20 - Open Source AI Tools
LLPhant
LLPhant is a comprehensive PHP Generative AI Framework that provides a simple and powerful way to build apps. It supports Symfony and Laravel and offers a wide range of features, including text generation, chatbots, text summarization, and more. LLPhant is compatible with OpenAI and Ollama and can be used to perform a variety of tasks, including creating semantic search, chatbots, personalized content, and text summarization.

Scrapegraph-ai
ScrapeGraphAI is a web scraping Python library that utilizes LLM and direct graph logic to create scraping pipelines for websites and local documents. It offers various standard scraping pipelines like SmartScraperGraph, SearchGraph, SpeechGraph, and ScriptCreatorGraph. Users can extract information by specifying prompts and input sources. The library supports different LLM APIs such as OpenAI, Groq, Azure, and Gemini, as well as local models using Ollama. ScrapeGraphAI is designed for data exploration and research purposes, providing a versatile tool for extracting information from web pages and generating outputs like Python scripts, audio summaries, and search results.

tts-generation-webui
TTS Generation WebUI is a comprehensive tool that provides a user-friendly interface for text-to-speech and voice cloning tasks. It integrates various AI models such as Bark, MusicGen, AudioGen, Tortoise, RVC, Vocos, Demucs, SeamlessM4T, and MAGNeT. The tool offers one-click installers, Google Colab demo, videos for guidance, and extra voices for Bark. Users can generate audio outputs, manage models, caches, and system space for AI projects. The project is open-source and emphasizes ethical and responsible use of AI technology.

OpenDAN-Personal-AI-OS
OpenDAN is an open source Personal AI OS that consolidates various AI modules for personal use. It empowers users to create powerful AI agents like assistants, tutors, and companions. The OS allows agents to collaborate, integrate with services, and control smart devices. OpenDAN offers features like rapid installation, AI agent customization, connectivity via Telegram/Email, building a local knowledge base, distributed AI computing, and more. It aims to simplify life by putting AI in users' hands. The project is in early stages with ongoing development and future plans for user and kernel mode separation, home IoT device control, and an official OpenDAN SDK release.

open-ai
Open AI is a powerful tool for artificial intelligence research and development. It provides a wide range of machine learning models and algorithms, making it easier for developers to create innovative AI applications. With Open AI, users can explore cutting-edge technologies such as natural language processing, computer vision, and reinforcement learning. The platform offers a user-friendly interface and comprehensive documentation to support users in building and deploying AI solutions. Whether you are a beginner or an experienced AI practitioner, Open AI offers the tools and resources you need to accelerate your AI projects and stay ahead in the rapidly evolving field of artificial intelligence.
UltraSinger
UltraSinger is a tool under development that automatically creates UltraStar.txt, midi, and notes from music. It pitches UltraStar files, adds text and tapping, creates separate UltraStar karaoke files, re-pitches current UltraStar files, and calculates in-game score. It uses multiple AI models to extract text from voice and determine pitch. Users should mention UltraSinger in UltraStar.txt files and only use it on Creative Commons licensed songs.
HTFramework
HTFramework is a rapid development framework based on Unity, integrating modular requirements, code reusability, practicality, high cohesion, unified coding standards, extensibility, maintainability, generality, and pluggability. It provides continuous maintenance and upgrades. The framework includes modules for aspect-oriented program code tracking, audio management, controller simplification, coroutine scheduling, custom modules, custom datasets, debugging, entity-component-system, entity management, event handling, exception handling, finite state machines, hotfixing, input management, instruction system, main module access, network client, object pooling, procedures, reference pooling, resource loading, step editing, task editing, UI management, utility tools, web requests, and optional AI, ILRuntime-based hotfixing, XLua integration, and game component modules.
RAVE
RAVE is a variational autoencoder for fast and high-quality neural audio synthesis. It can be used to generate new audio samples from a given dataset, or to modify the style of existing audio samples. RAVE is easy to use and can be trained on a variety of audio datasets. It is also computationally efficient, making it suitable for real-time applications.
MeloTTS
MeloTTS is a high-quality multi-lingual text-to-speech library by MyShell.ai. It supports various languages including English (American, British, Indian, Australian), Spanish, French, Chinese, Japanese, and Korean. The Chinese speaker also supports mixed Chinese and English. The library is fast enough for CPU real-time inference and offers features like using without installation, local installation, and training on custom datasets. The Python API and model cards are available in the repository and on HuggingFace. The community can join the Discord channel for discussions and collaboration opportunities. Contributions are welcome, and the library is under the MIT License. MeloTTS is based on TTS, VITS, VITS2, and Bert-VITS2.
com.openai.unity
com.openai.unity is an OpenAI package for Unity that allows users to interact with OpenAI's API through RESTful requests. It is independently developed and not an official library affiliated with OpenAI. Users can fine-tune models, create assistants, chat completions, and more. The package requires Unity 2021.3 LTS or higher and can be installed via Unity Package Manager or Git URL. Various features like authentication, Azure OpenAI integration, model management, thread creation, chat completions, audio processing, image generation, file management, fine-tuning, batch processing, embeddings, and content moderation are available.

WavCraft
WavCraft is an LLM-driven agent for audio content creation and editing. It applies LLM to connect various audio expert models and DSP function together. With WavCraft, users can edit the content of given audio clip(s) conditioned on text input, create an audio clip given text input, get more inspiration from WavCraft by prompting a script setting and let the model do the scriptwriting and create the sound, and check if your audio file is synthesized by WavCraft.
aiotone
Aiotone is a repository containing audio synthesis and MIDI processing tools in AsyncIO. It includes a work-in-progress polyphonic 4-operator FM synthesizer, tools for performing on Moog Mother 32 synthesizers, sequencing Novation Circuit and Novation Circuit Mono Station, and self-generating sequences for Moog Mother 32 synthesizers and Moog Subharmonicon. The tools are designed for real-time audio processing and MIDI control, with features like polyphony, modulation, and sequencing. The repository provides examples and tutorials for using the tools in music production and live performances.
OpenAI-DotNet
OpenAI-DotNet is a simple C# .NET client library for OpenAI to use through their RESTful API. It is independently developed and not an official library affiliated with OpenAI. Users need an OpenAI API account to utilize this library. The library targets .NET 6.0 and above, working across various platforms like console apps, winforms, wpf, asp.net, etc., and on Windows, Linux, and Mac. It provides functionalities for authentication, interacting with models, assistants, threads, chat, audio, images, files, fine-tuning, embeddings, and moderations.

llms-tools
The 'llms-tools' repository is a comprehensive collection of AI tools, open-source projects, and research related to Large Language Models (LLMs) and Chatbots. It covers a wide range of topics such as AI in various domains, open-source models, chats & assistants, visual language models, evaluation tools, libraries, devices, income models, text-to-image, computer vision, audio & speech, code & math, games, robotics, typography, bio & med, military, climate, finance, and presentation. The repository provides valuable resources for researchers, developers, and enthusiasts interested in exploring the capabilities of LLMs and related technologies.
next-token-prediction
Next-Token Prediction is a language model tool that allows users to create high-quality predictions for the next word, phrase, or pixel based on a body of text. It can be used as an alternative to well-known decoder-only models like GPT and Mistral. The tool provides options for simple usage with built-in data bootstrap or advanced customization by providing training data or creating it from .txt files. It aims to simplify methodologies, provide autocomplete, autocorrect, spell checking, search/lookup functionalities, and create pixel and audio transformers for various prediction formats.
ai-audio-startups
The 'ai-audio-startups' repository is a community list of startups working with AI for audio and music tech. It includes a comprehensive collection of tools and platforms that leverage artificial intelligence to enhance various aspects of music creation, production, source separation, analysis, recommendation, health & wellbeing, radio/podcast, hearing, sound detection, speech transcription, synthesis, enhancement, and manipulation. The repository serves as a valuable resource for individuals interested in exploring innovative AI applications in the audio and music industry.
polyfire-js
Polyfire is an all-in-one managed backend for AI apps that allows users to build AI applications directly from the frontend, eliminating the need for a separate backend. It simplifies the process by providing most backend services in just a few lines of code. With Polyfire, users can easily create chatbots, transcribe audio files, generate simple text, manage long-term memory, and generate images. The tool also offers starter guides and tutorials to help users get started quickly and efficiently.
groqnotes
Groqnotes is a streamlit app that helps users generate organized lecture notes from transcribed audio using Groq's Whisper API. It utilizes Llama3-8b and Llama3-70b models to structure and create content quickly. The app offers markdown styling for aesthetic notes, allows downloading notes as text or PDF files, and strategically switches between models for speed and quality balance. Users can access the hosted version at groqnotes.streamlit.app or run it locally with streamlit by setting up the Groq API key and installing dependencies.
polyfire-js
Polyfire is an all-in-one managed backend for AI apps that allows users to build AI apps directly from the frontend, eliminating the need for a separate backend. It simplifies the process by providing most backend services in just a few lines of code. With Polyfire, users can easily create chatbots, transcribe audio files to text, generate simple text, create a long-term memory, and generate images with Dall-E. The tool also offers starter guides and tutorials to help users get started quickly and efficiently.
mediasoup-client-aiortc
mediasoup-client-aiortc is a handler for the aiortc Python library, allowing Node.js applications to connect to a mediasoup server using WebRTC for real-time audio, video, and DataChannel communication. It facilitates the creation of Worker instances to manage Python subprocesses, obtain audio/video tracks, and create mediasoup-client handlers. The tool supports features like getUserMedia, handlerFactory creation, and event handling for subprocess closure and unexpected termination. It provides custom classes for media stream and track constraints, enabling diverse audio/video sources like devices, files, or URLs. The tool enhances WebRTC capabilities in Node.js applications through seamless Python subprocess communication.
20 - OpenAI Gpts
MUSIC + AI = MUSI.CAI
MUSIC + AI: Your key to original AI music creation. Create hits, explore genres, and tap into global trends. The ultimate tool for artists and producers.


ReaperGPT
Expert for the Reaper DAW with extensive knowledge on Reapack Packages, ReaScript, EEL, Lua, Python, general commands, and audio workflows.

Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.
Mike Russell
Virtual Mike Russell from Music Radio Creative. Ask me your audio, podcasting and AI questions!

JollyDays: Your Festive Daily Adventure
Experience daily Christmas joy! Fun coloring, crafts, recipes, cultural insights with audio guides, and curated videos - perfect for festive creativity with your loved ones!
Able-Nature's Echo.
Guides users through beautiful landscapes with spatial audio for immersion.
ArtGPT
Doing art design and research, including fine arts, audio arts and video arts, designed by Prof. Dr. Fred Y. Ye (Ying Ye)


Ableton Live Mentor
Your personal Ableton Live mentor. Ask me anything about using Live for music production or live performance.
