Best AI tools for< Control Speech Nuances >
20 - AI tool Sites
Resemble AI
Resemble AI is an all-in-one AI voice platform offering advanced AI voice generation and deepfake audio detection capabilities. The platform enables users to create hyper-realistic AI voices, deploy AI voices in various languages, edit audio with AI assistance, and detect deepfake audio in real-time. Resemble AI caters to enterprises prioritizing security and safety, providing cutting-edge solutions for voice cloning, speech-to-speech conversion, multilingual support, and audio editing. The platform is trusted by millions of teams worldwide and offers a comprehensive audio toolkit for content creation, editing, and protection.
Speechki
Speechki is an AI Realistic Voice Generator and Text-to-Speech Solution offering over 1,100 voices in 80+ languages. It provides a user-friendly platform for converting text into engaging audio with AI-powered voices. The application is designed to cater to various needs such as audiobook production, content creation, podcasting, and more. With features like real-time proof-listening, chapter-like formatting, streamlined role management, precision pause control, and nuanced speech control, Speechki aims to enhance the user experience and deliver lifelike audio output. The tool also offers global reach with multicast and multilanguage support, making it suitable for a diverse audience.
Transgate
Transgate is an AI-powered speech-to-text conversion tool that allows users to convert audio/video files to text with high accuracy and efficiency. It offers a pay-as-you-go model, supports over 50 languages, and guarantees 98%+ accuracy. Transgate is designed to boost productivity by minimizing costs and eliminating manual transcription tasks, catering to industries like AI/ML, medical, legal, education, consulting, and market research.
ChatTTS
ChatTTS is a natural and expressive text-to-speech tool designed for dialogue applications. It supports mixed language input and offers multi-speaker capabilities with precise control over prosodic elements like laughter, pauses, and intonation. Users can explore the unique capabilities of ChatTTS, enjoy conversational TTS optimized for dialogue-based tasks, and benefit from fine-grained control over prosodic features. The tool is multilingual, supporting both English and Chinese languages, and is open-source and customizable with pretrained models available for further research and development.

Columns AI
Columns AI is a platform that enables users to automate data storytelling through AI technology. It offers a user-friendly interface to create visually compelling narratives from various data sources. Users can integrate data from Google Spreadsheet, Notion, Airtable, and more, transform data into visual stories, design professional content with Canva-like tools, and share and automate updates effortlessly. Columns AI leverages advanced AI to deliver smart insights, allowing users to unleash their creativity and share stories across multiple channels. It also provides a chat feature powered by GPT for generating graphs and interactive data analysis.
VoxSigma
Vocapia Research develops leading-edge, multilingual speech processing technologies exploiting AI methods such as machine learning. These technologies enable large vocabulary continuous speech recognition, automatic audio segmentation, language identification, speaker diarization and audio-text synchronization. Vocapia's VoxSigma™ speech-to-text software suite delivers state-of-the-art performance in many languages for a variety of audio data types, including broadcast data, parliamentary hearings and conversational data.
ChatTTS
ChatTTS is a text-to-speech tool optimized for natural, conversational scenarios. It supports both Chinese and English languages, trained on approximately 100,000 hours of data. With features like multi-language support, large data training, dialog task compatibility, open-source plans, control, security, and ease of use, ChatTTS provides high-quality and natural-sounding voice synthesis. It is designed for conversational tasks, dialogue speech generation, video introductions, educational content synthesis, and more. Users can integrate ChatTTS into their applications using provided API and SDKs for a seamless text-to-speech experience.
HeardThat
HeardThat is a smartphone application that leverages AI technology to assist users in hearing speech more clearly in noisy environments. By separating speech from background noise, HeardThat helps individuals with varying degrees of hearing ability to participate in conversations with confidence and ease. The app eliminates the need for additional hardware, making it a convenient and accessible solution for those struggling in social settings. HeardThat aims to combat social isolation by empowering users to engage in conversations without feeling exhausted or frustrated.
Typecast
Typecast is an online AI voice generator and content creation tool that offers advanced AI voice models for creating natural and expressive voiceovers. With over 500 unique voices to choose from, Typecast allows users to create professional voice content instantly with high fidelity and control. The tool uses advanced machine learning to produce lifelike speech with correct intonation, pausing, and breathing, making it sound as human as possible. Typecast also provides features like text-to-speech, voice cloning, voiceover video, and multilingual dubbing, catering to a wide range of content creation needs.
NVIDIA
NVIDIA is a world leader in artificial intelligence computing. The company's products and services are used by businesses and governments around the world to develop and deploy AI applications. NVIDIA's AI platform includes hardware, software, and tools that make it easy to build and train AI models. The company also offers a range of cloud-based AI services that make it easy to deploy and manage AI applications. NVIDIA's AI platform is used in a wide variety of industries, including healthcare, manufacturing, retail, and transportation. The company's AI technology is helping to improve the efficiency and accuracy of a wide range of tasks, from medical diagnosis to product design.
Neuralink
Neuralink is a pioneering brain-computer interface (BCI) application that aims to redefine human capabilities by creating a generalized brain interface to restore autonomy to individuals with unmet medical needs. The application focuses on developing fully implantable BCIs that allow users, particularly those with quadriplegia, to control computers and mobile devices using their thoughts. Neuralink's innovative technology includes advanced chips, biocompatible enclosures, and surgical robots for precise implantation. The application prioritizes safety, accessibility, and reliability in its engineering process, with future goals of restoring vision, motor function, and speech capabilities.
Capacity
Capacity is an AI-powered platform that offers a wide range of tools and solutions to enhance customer support, contact center operations, and overall business productivity. It leverages artificial intelligence to automate various tasks, such as speech recognition, chatbots, voice biometrics, CRM automation, and more. Capacity aims to streamline workflows, improve customer interactions, and boost efficiency by providing intelligent solutions for various industries and use cases.

Frame
Frame is a pair of AI-powered glasses that gives you superpowers. With Frame, you can see the world around you in a whole new way. You can translate text and speech, search the web, and even hack into devices. Frame is open-source, so you can customize it to fit your needs. With Frame, the only limit is your imagination.
Listnr AI
Listnr AI is a leading AI voice generator tool that offers ultra-realistic AI voices indistinguishable from humans. With over 1000 different voices in more than 142 languages, including voice cloning capabilities, Listnr AI is trusted by 2,500,000+ users worldwide. The tool allows users to create voiceovers for various content types such as shorts, TikToks, YouTube videos, gaming, podcasts, sales, social media, and audiobooks. Listnr AI's state-of-the-art generative AI technology ensures that the voiceovers sound extremely natural, providing a seamless experience for content creators. Additionally, Listnr AI offers features like emotion fine-tuning, punctuations, pauses, and a wide range of multi-lingual voices to cater to diverse content needs.
Swift
Swift is an AI-powered voice assistant that utilizes cutting-edge technologies such as Groq, Cartesia, VAD, and Vercel to provide users with a fast and efficient voice interaction experience. With Swift, users can perform various tasks using voice commands, making it a versatile tool for hands-free operation in different settings. The application aims to streamline daily tasks and enhance user productivity through seamless voice recognition capabilities.
Bytecap
Bytecap is an AI application that allows users to immerse their videos with custom AI captions. It offers features such as auto creation of 99% accurate captions using advanced speech recognition, customization of captions with fonts, colors, emojis, effects, music, and highlights, and AI-generated hook titles and descriptions for boosting engagement. Bytecap supports over 99 languages, provides complete caption control, and offers trendy sounds and background music options. The application caters to video editors, content creators, podcasters, and streamers, enabling them to save time, expand reach, and increase brand awareness. Bytecap ensures privacy and security, offers free trial options, and allows users to edit captions after creation.
Corti
Corti is an AI platform that provides advanced capabilities for patient consultations. It offers features such as Co-Pilot, a proactive AI scribe and assistant for clinicians, and Mission Control, an AI-powered conversation recorder. Corti's AI tools support various healthcare tasks, including high precision procedure and diagnosis coding, context-aware assistants for clinicians, and support for multiple languages in speech and text. The platform is trusted by major hospitals and healthcare providers worldwide.
Evolphin
Evolphin is a leading AI-powered platform for Digital Asset Management (DAM) and Media Asset Management (MAM) that caters to creatives, sports professionals, marketers, and IT teams. It offers advanced AI capabilities for fast search, robust version control, and Adobe plugins. Evolphin's AI automation streamlines video workflows, identifies objects, faces, logos, and scenes in media, generates speech-to-text for search and closed captioning, and enables automations based on AI engine identification. The platform allows for editing videos with AI, creating rough cuts instantly. Evolphin's cloud solutions facilitate remote media production pipelines, ensuring speed, security, and simplicity in managing creative assets.
Generador de Voz
Generadordevoz.com is an online tool that allows users to generate voices for any text in seconds using over 409 realistic voices in more than 129 languages and dialects. Users can choose the language, voice, and paste their text to generate voices online. The tool offers advanced features such as extended character limit for audio generation, access to generated audio history, audio control settings, realistic breathing pauses, SSML support for audio customization, and priority support. Users can participate by creating articles or videos showcasing the tool's usage to gain access to the Advanced Panel with premium features. The tool can be used for various purposes such as advertisements, corporate training, IVR greetings, product promotions, podcasts, YouTube monetization, audiobooks, social media videos, news delivery, university lectures, accessibility for people with disabilities, and more.
Dubformer
Dubformer is an AI-powered dubbing and video localization provider that offers a secure and end-to-end solution for the media industry. With a focus on quality and speed, Dubformer's technology enables the creation of realistic and natural-sounding voice-overs in multiple languages, making video content more accessible and engaging for diverse audiences. The platform combines AI-driven processes with human quality control to ensure broadcast-quality results. Dubformer's services include AI dubbing, accurate and culturally sensitive translations, AI mixing for immersive soundscapes, and AI-powered subtitles and closed captions.
20 - Open Source AI Tools

VoiceStreamAI
VoiceStreamAI is a Python 3-based server and JavaScript client solution for near-realtime audio streaming and transcription using WebSocket. It employs Huggingface's Voice Activity Detection (VAD) and OpenAI's Whisper model for accurate speech recognition. The system features real-time audio streaming, modular design for easy integration of VAD and ASR technologies, customizable audio chunk processing strategies, support for multilingual transcription, and secure sockets support. It uses a factory and strategy pattern implementation for flexible component management and provides a unit testing framework for robust development.
rosa
ROSA is an AI Agent designed to interact with ROS-based robotics systems using natural language queries. It can generate system reports, read and parse ROS log files, adapt to new robots, and run various ROS commands using natural language. The tool is versatile for robotics research and development, providing an easy way to interact with robots and the ROS environment.

awesome-generative-ai
A curated list of Generative AI projects, tools, artworks, and models

llms-interview-questions
This repository contains a comprehensive collection of 63 must-know Large Language Models (LLMs) interview questions. It covers topics such as the architecture of LLMs, transformer models, attention mechanisms, training processes, encoder-decoder frameworks, differences between LLMs and traditional statistical language models, handling context and long-term dependencies, transformers for parallelization, applications of LLMs, sentiment analysis, language translation, conversation AI, chatbots, and more. The readme provides detailed explanations, code examples, and insights into utilizing LLMs for various tasks.
Awesome-GenAI-Unlearning
This repository is a collection of papers on Generative AI Machine Unlearning, categorized based on modality and applications. It includes datasets, benchmarks, and surveys related to unlearning scenarios in generative AI. The repository aims to provide a comprehensive overview of research in the field of machine unlearning for generative models.
llm_benchmarks
llm_benchmarks is a collection of benchmarks and datasets for evaluating Large Language Models (LLMs). It includes various tasks and datasets to assess LLMs' knowledge, reasoning, language understanding, and conversational abilities. The repository aims to provide comprehensive evaluation resources for LLMs across different domains and applications, such as education, healthcare, content moderation, coding, and conversational AI. Researchers and developers can leverage these benchmarks to test and improve the performance of LLMs in various real-world scenarios.


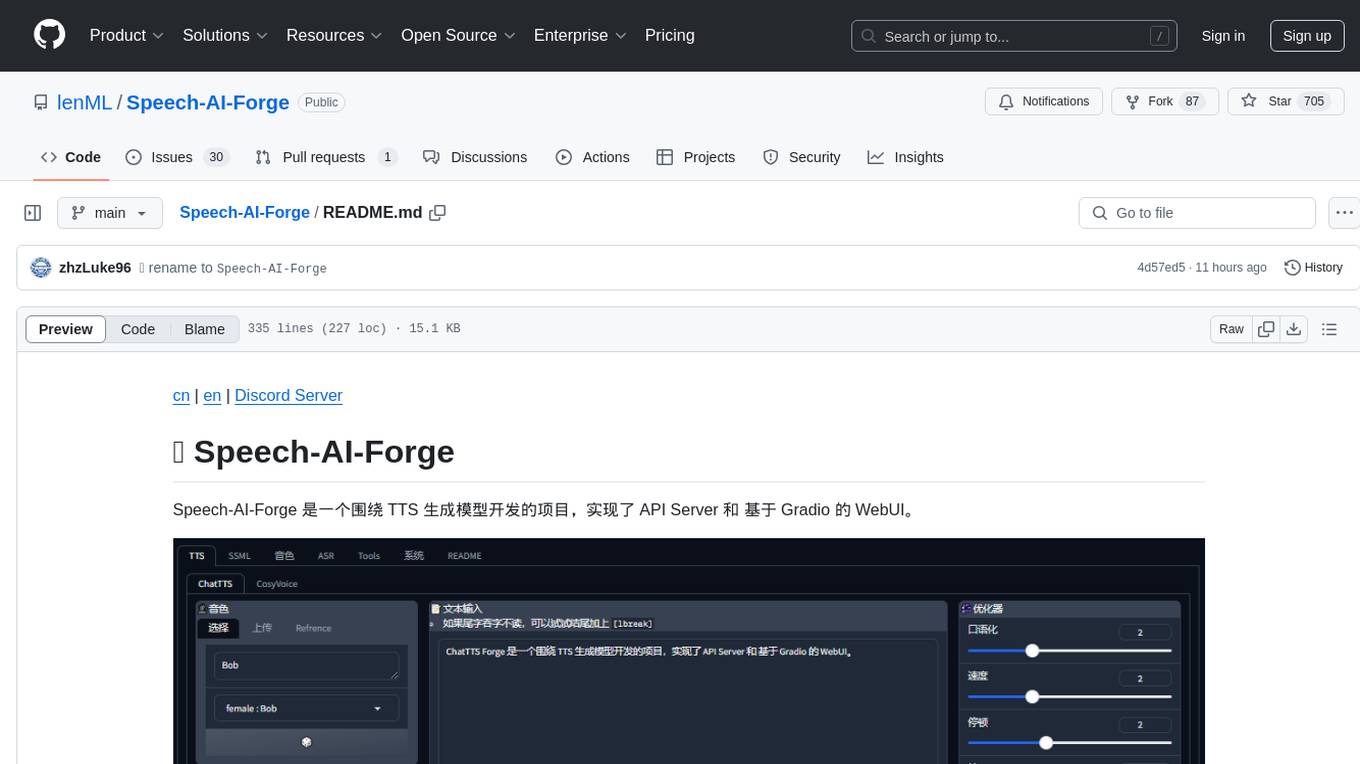
Speech-AI-Forge
Speech-AI-Forge is a project developed around TTS generation models, implementing an API Server and a WebUI based on Gradio. The project offers various ways to experience and deploy Speech-AI-Forge, including online experience on HuggingFace Spaces, one-click launch on Colab, container deployment with Docker, and local deployment. The WebUI features include TTS model functionality, speaker switch for changing voices, style control, long text support with automatic text segmentation, refiner for ChatTTS native text refinement, various tools for voice control and enhancement, support for multiple TTS models, SSML synthesis control, podcast creation tools, voice creation, voice testing, ASR tools, and post-processing tools. The API Server can be launched separately for higher API throughput. The project roadmap includes support for various TTS models, ASR models, voice clone models, and enhancer models. Model downloads can be manually initiated using provided scripts. The project aims to provide inference services and may include training-related functionalities in the future.

ChatTTS
ChatTTS is a generative speech model optimized for dialogue scenarios, providing natural and expressive speech synthesis with fine-grained control over prosodic features. It supports multiple speakers and surpasses most open-source TTS models in terms of prosody. The model is trained with 100,000+ hours of Chinese and English audio data, and the open-source version on HuggingFace is a 40,000-hour pre-trained model without SFT. The roadmap includes open-sourcing additional features like VQ encoder, multi-emotion control, and streaming audio generation. The tool is intended for academic and research use only, with precautions taken to limit potential misuse.
VSP-LLM
VSP-LLM (Visual Speech Processing incorporated with LLMs) is a novel framework that maximizes context modeling ability by leveraging the power of LLMs. It performs multi-tasks of visual speech recognition and translation, where given instructions control the task type. The input video is mapped to the input latent space of a LLM using a self-supervised visual speech model. To address redundant information in input frames, a deduplication method is employed using visual speech units. VSP-LLM utilizes Low Rank Adaptors (LoRA) for computationally efficient training.
ChatGPT-OpenAI-Smart-Speaker
ChatGPT Smart Speaker is a project that enables speech recognition and text-to-speech functionalities using OpenAI and Google Speech Recognition. It provides scripts for running on PC/Mac and Raspberry Pi, allowing users to interact with a smart speaker setup. The project includes detailed instructions for setting up the required hardware and software dependencies, along with customization options for the OpenAI model engine, language settings, and response randomness control. The Raspberry Pi setup involves utilizing the ReSpeaker hardware for voice feedback and light shows. The project aims to offer an advanced smart speaker experience with features like wake word detection and response generation using AI models.
whispering-ui
Whispering Tiger UI is a Native-UI tool designed to control the Whispering Tiger application, a free and Open-Source tool that can listen/watch to audio streams or in-game images on your machine and provide transcription or translation to a web browser using Websockets or over OSC. It features a Native-UI for Windows, easy access to all Whispering Tiger features including transcription, translation, text-to-speech, and in-game image recognition. The tool supports loopback audio device, configuration saving/loading, plugin support for additional features, and auto-update functionality. Users can create profiles, configure audio devices, select A.I. devices for speech-to-text, and install/manage plugins for extended functionality.
20 - OpenAI Gpts
🤖 SmartLink Integrator 🌎
Your AI bridge to the Internet of Things! Easily connect, control, and automate your smart devices with voice or text commands. 🏠💎
TrafficFlow
A specialized AI for optimizing traffic control, predicting bottlenecks, and improving road safety.
Sim-Low
Meal planner with 1)Calories Control 2)Family/Personal Plan 3)Nutritional Summaries 4)Shopping Lists

Addiction Assistant
A mentor for those with struggling with control over their substance use, offering guidance, resources, and support for sobriety. In case of relapse, it provides practical steps and resources, including web links, phone numbers, and emails.

Project Controlling Advisor
Provides financial oversight and project cost control support.
Hierarchical Topic Exploration
Explore any topic with an advanced hierarchical interactive mapping with streamlined control. Begin with !start [topic].
BITE Model Analyzer by Dr. Steven Hassan
Discover if your group, relationship or organization uses specific methods to recruit and maintain control over people

AcousticsAdvisor
An expert in acoustics, providing advice on sound management and noise control.
AI Powerplayed
Navigate the intricate world of corporate politics as Sam Alterman, a visionary tech leader ousted from his CEO role, outmaneuver all and reclaim control of the leading AI company. This interactive game blends strategy, negotiation, and alliances in a high-stakes world of tech. Type Start to begin.