Best AI tools for< caption podcasts >
20 - AI tool Sites
Steno
Steno is an AI-powered speech-to-text platform that provides real-time transcription, translation, and closed captioning services. It uses advanced machine learning algorithms to accurately transcribe audio and video content, making it an ideal tool for a wide range of applications, including meetings, interviews, lectures, and more.
Chopcast
Chopcast is a content repurposing platform that uses AI to automatically find, edit, and share key moments in long recordings. This allows users to quickly and easily create short-form video clips, podcasts, and articles from their webinars, livestreams, and other video content. Chopcast is designed to help businesses save time and money on content creation and repurposing, and to reach a wider audience with their content.
Whisper API
Whisper API is an affordable transcription API that can be used to transcribe audio and video files. It is a cloud-based service that is easy to use and can be integrated with a variety of applications. Whisper API is powered by artificial intelligence, which allows it to transcribe audio and video files with high accuracy.
Bibit AI
Bibit AI is a real estate marketing AI designed to enhance the efficiency and effectiveness of real estate marketing and sales. It can help create listings, descriptions, and property content, and offers a host of other features. Bibit AI is the world's first AI for Real Estate. We are transforming the real estate industry by boosting efficiency and simplifying tasks like listing creation and content generation.
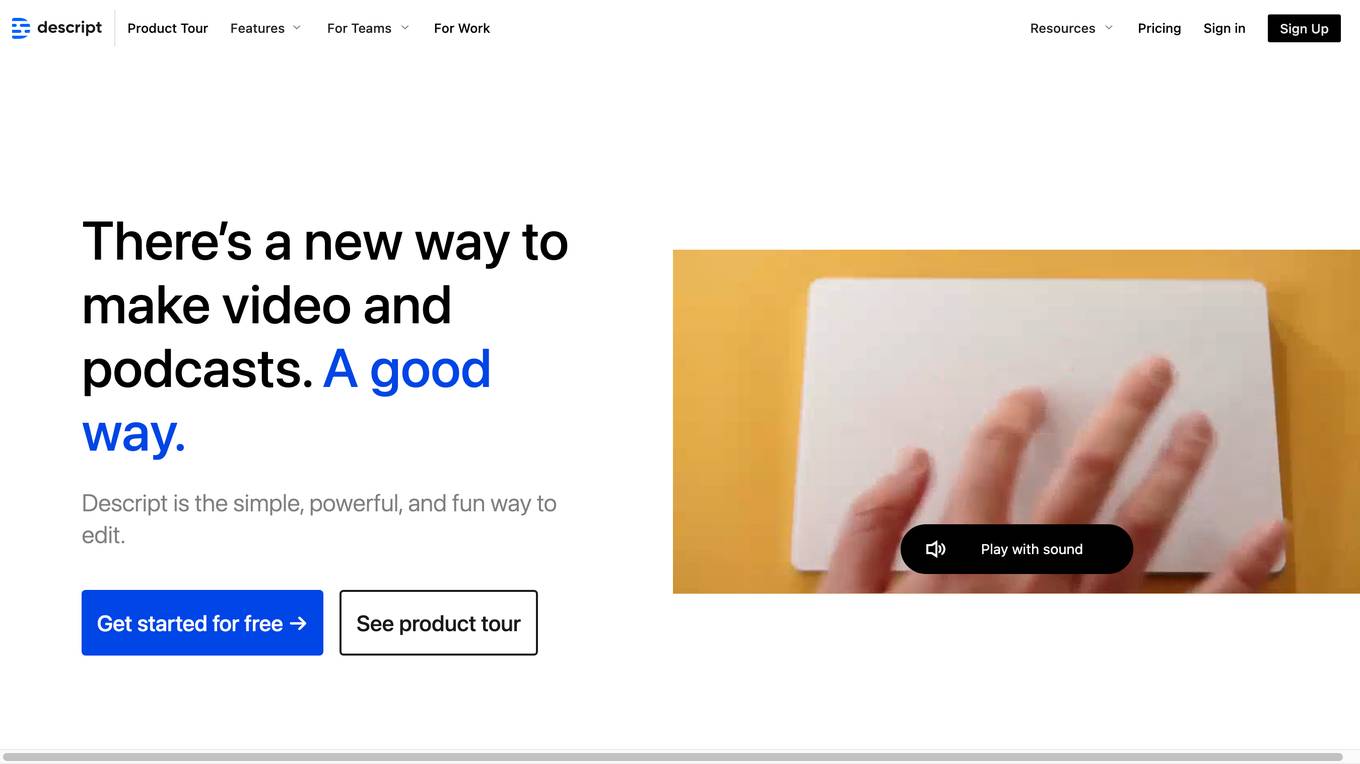
Descript
Descript is an AI-powered editing assistant that allows users to edit videos and podcasts with ease. It offers features such as video editing, multitrack audio editing, clip selection, remote recording, captions, screen recording, transcription, AI speech generation, and more. Descript's AI capabilities help users create high-quality content efficiently. It is designed to streamline the editing process and enhance creativity for individuals and teams. With Descript, users can edit audio and video by editing text, arrange visuals like a slide deck, and utilize AI superpowers at every step. The platform caters to creators of all levels, from aspiring to professional, and provides a seamless workflow for content creation and collaboration.
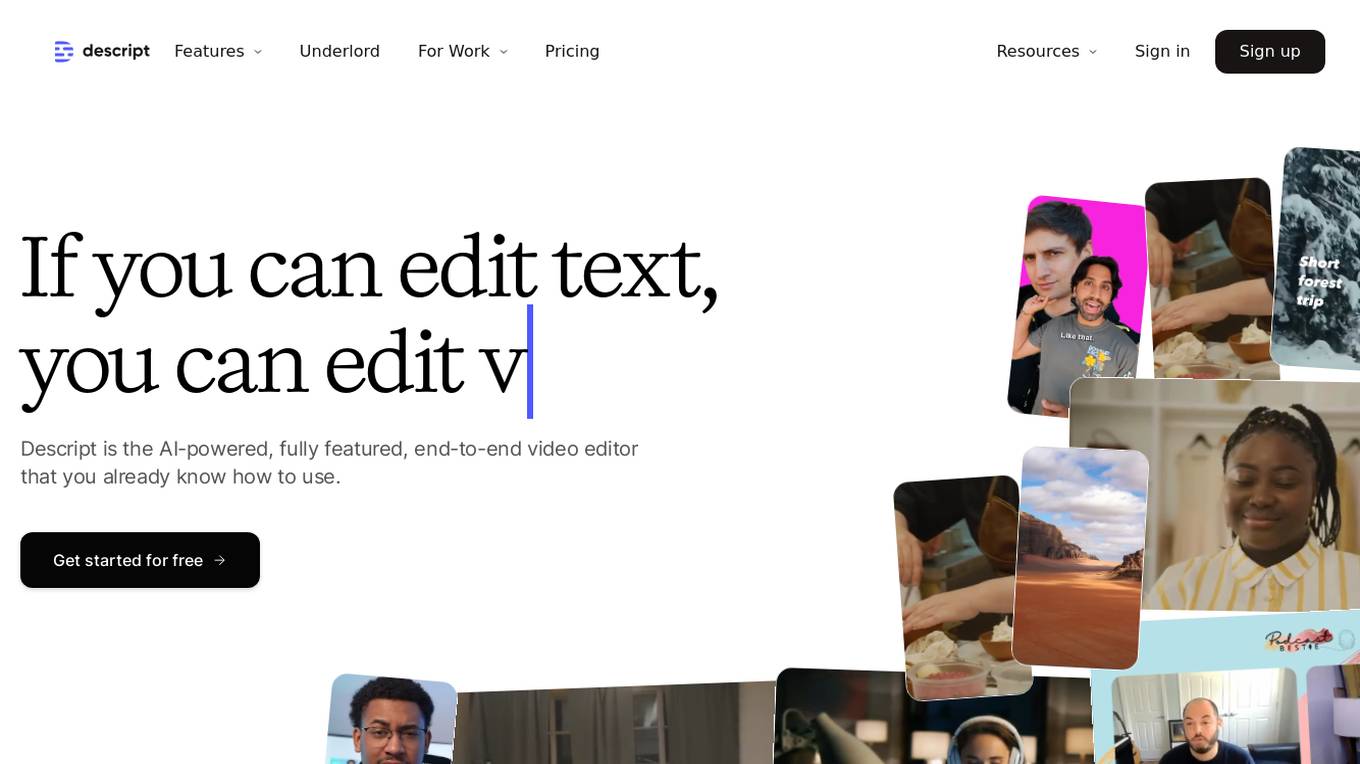
Descript
Descript is an AI-powered editing assistant that allows users to edit videos and podcasts with ease. It offers features such as video editing, multitrack audio editing, clip selection, remote recording, captions, screen recording, transcription, AI speech generation, and more. Descript's AI capabilities help users create high-quality content effortlessly, making it a valuable tool for creators and teams. With a user-friendly interface and advanced AI features, Descript simplifies the video editing process and enhances productivity.
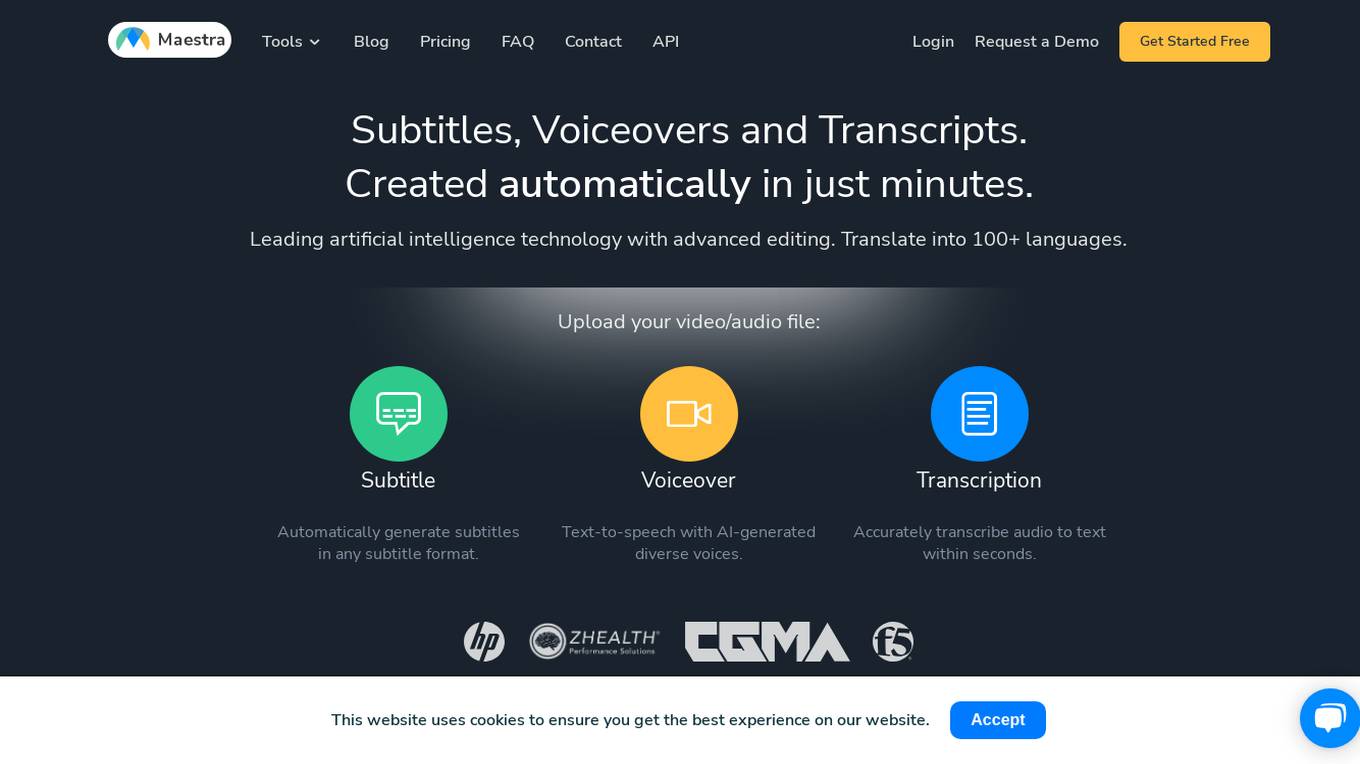
Maestra AI
Maestra AI is an advanced platform offering transcription, subtitling, and voiceover tools powered by artificial intelligence technology. It allows users to automatically transcribe audio and video files, generate subtitles in multiple languages, and create voiceovers with diverse AI-generated voices. Maestra's services are designed to help users save time and easily reach a global audience by providing accurate and efficient transcription, captioning, and voiceover solutions.
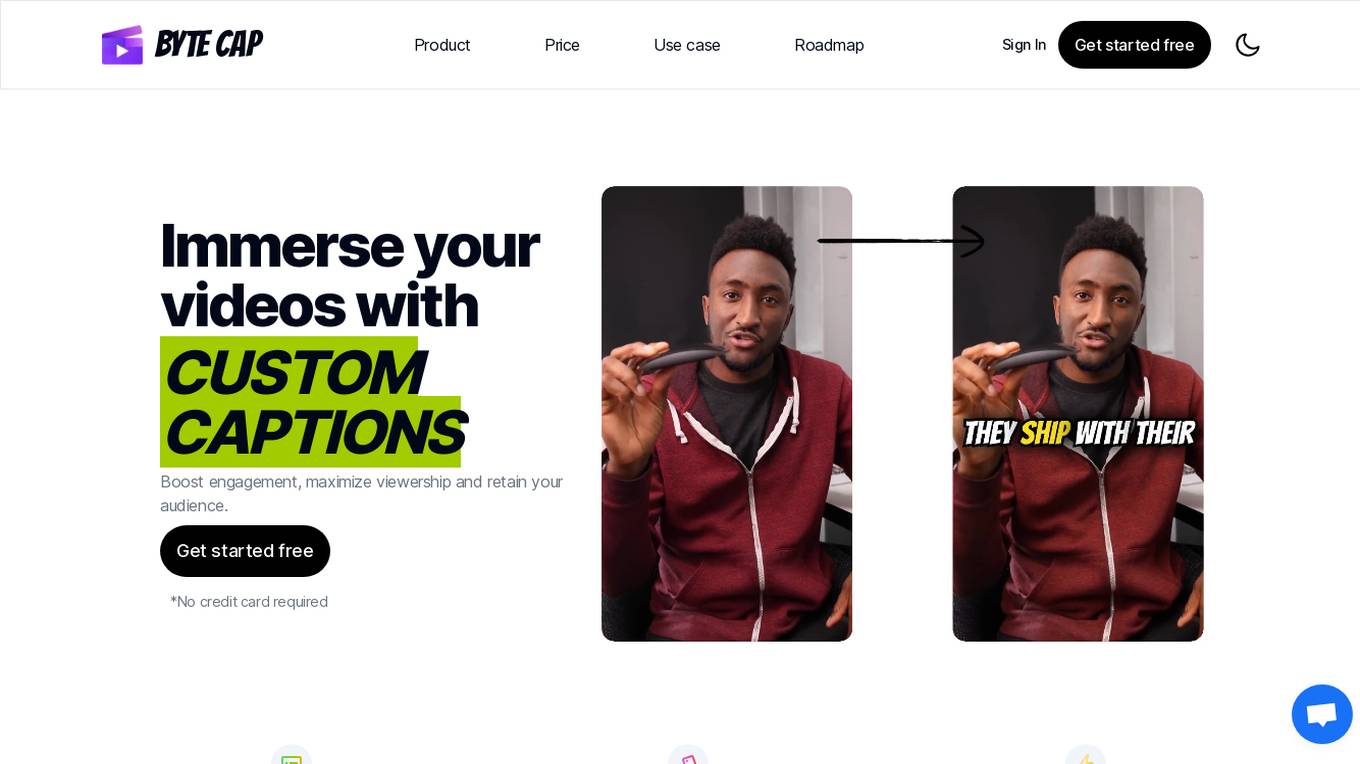
Bytecap
Bytecap is an AI application that allows users to immerse their videos with custom AI captions. It offers features such as auto creation of 99% accurate captions using advanced speech recognition, customization of captions with fonts, colors, emojis, effects, music, and highlights, and AI-generated hook titles and descriptions for boosting engagement. Bytecap supports over 99 languages, provides complete caption control, and offers trendy sounds and background music options. The application caters to video editors, content creators, podcasters, and streamers, enabling them to save time, expand reach, and increase brand awareness. Bytecap ensures privacy and security, offers free trial options, and allows users to edit captions after creation.
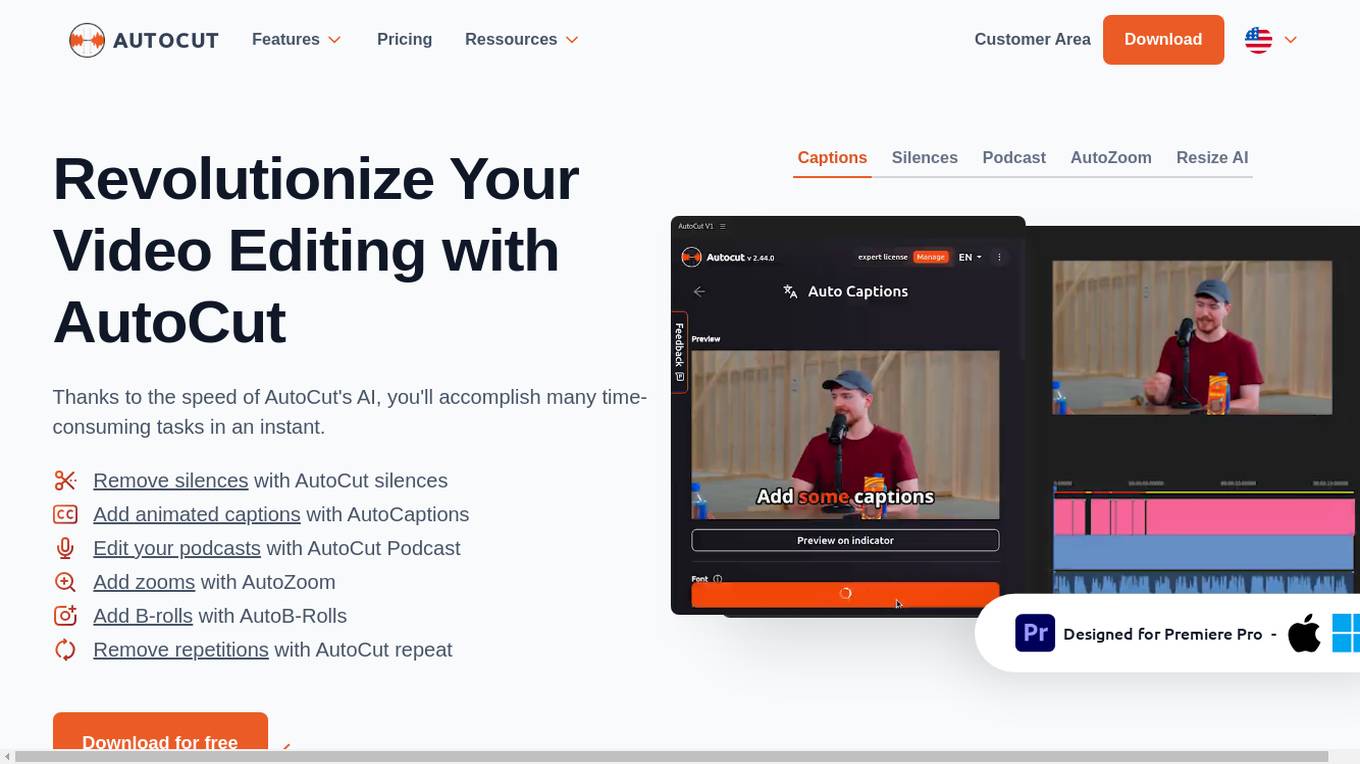
AutoCut
AutoCut is a plugin for Adobe Premiere Pro that uses AI to automate video editing tasks. It can remove silences, add animated captions, edit podcasts, add zooms, add B-rolls, and remove repetitions. AutoCut is designed to save video editors time and effort, and it can be used by both beginners and experienced editors.
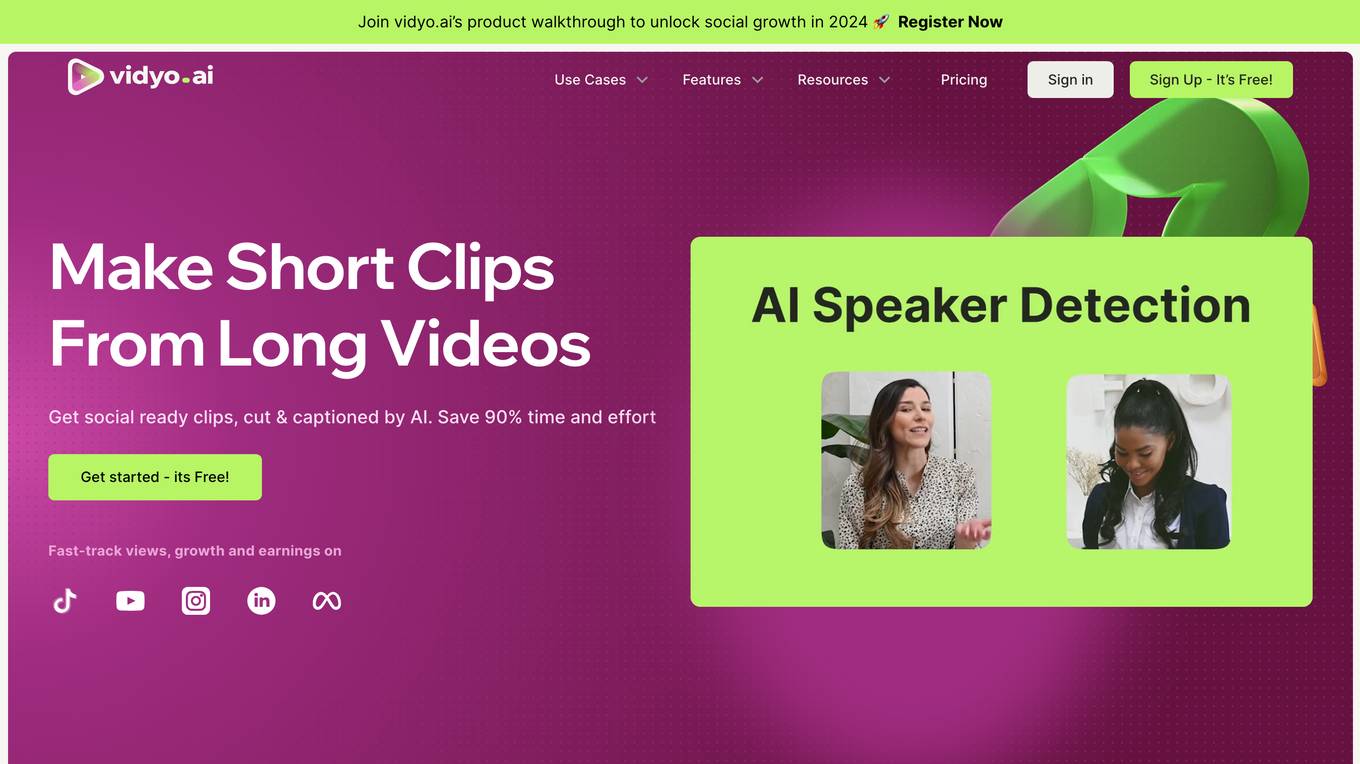
vidyo.ai
vidyo.ai is a cutting-edge AI video editing platform that offers powerful features to help users create and grow their social media presence. The platform allows users to effortlessly handle and edit multi-cam and complex videos, automatically detect sentences that require emojis, generate enhanced clips with AI, create auto video chapters, use brand templates, add AI captions, and analyze AI virality scores. With a user-friendly interface and a wide range of features, vidyo.ai is a must-have tool for content creators and brands looking to produce top-notch video content efficiently and cost-effectively.
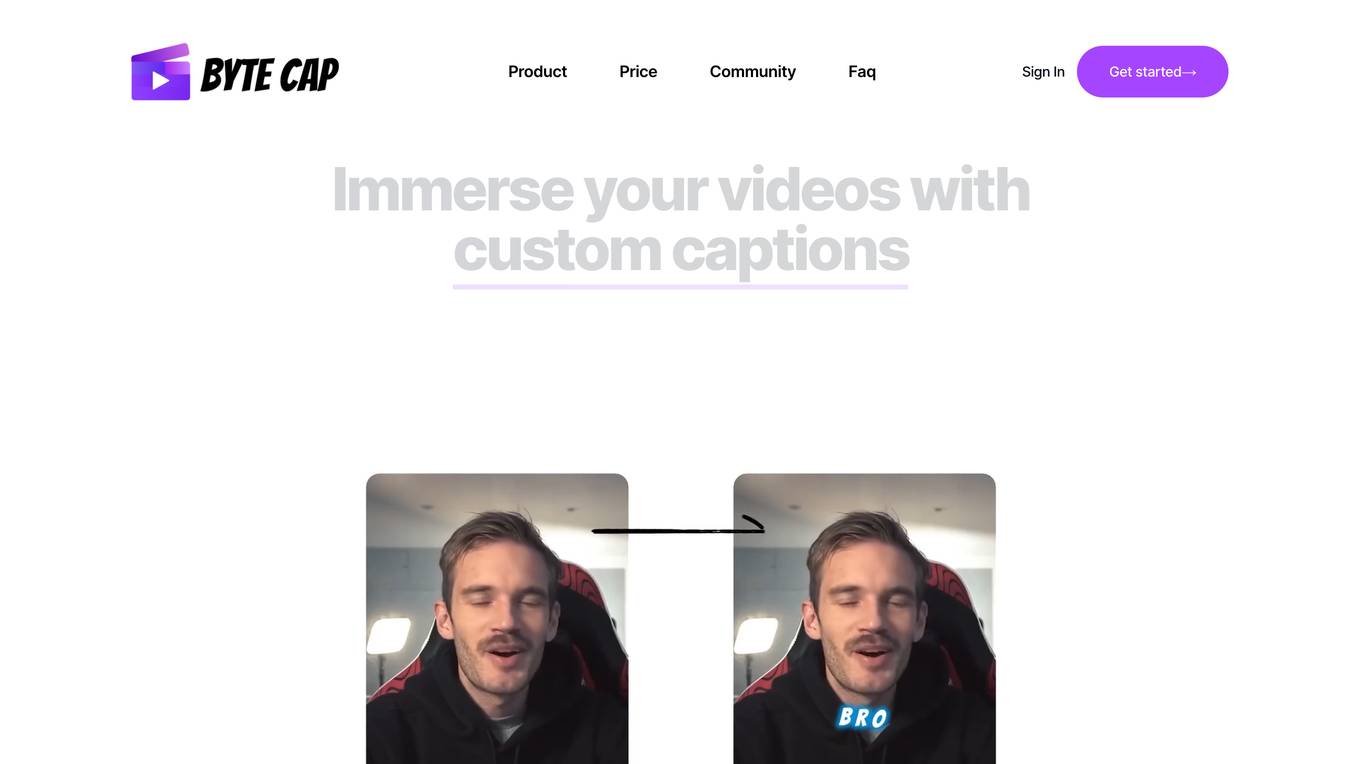
ByteCap
ByteCap is a web-based video captioning tool that uses AI technology to automatically generate accurate and customizable captions for videos. It offers features such as speech recognition, custom fonts and colors, trendy sound effects, and real-time editing. ByteCap is designed to help video creators, content creators, podcasters, and streamers enhance their videos with professional-looking captions, boost engagement, maximize viewership, and retain their audience.
Deciphr
Deciphr is an AI-powered content creation platform that helps podcasters, coaches, agencies, thought leaders, students, and solopreneurs create high-quality content faster and easier. With Deciphr, users can automatically generate transcripts, audiograms, video reels, blog posts, and social media captions from their audio and video files. Deciphr also offers a variety of features to help users edit and refine their content, including an AI assistant, planner, dictionary, and more.
WritePanda
WritePanda is an innovative SaaS solution designed to streamline communication and optimize team collaboration, all while preserving the personal touch that fuels creativity and fosters camaraderie. Its cutting-edge AI technology transforms videos and podcasts into engaging and shareable content across various platforms, including blogs, newsletters, tweets, and viral clips. With WritePanda, users can save time, expand their reach, and captivate new audiences with the help of intelligent algorithms that ensure quality and relevance.

ScriptMe
ScriptMe is a web-based platform that provides automated transcription and subtitling services. It uses artificial intelligence (AI) to convert audio and video files into text, and then allows users to edit and export the transcripts in a variety of formats. ScriptMe is designed to be fast, accurate, and easy to use, and it can be used for a variety of purposes, including: * Transcribing interviews, lectures, and meetings * Creating subtitles for videos * Generating transcripts for podcasts and webinars * Providing closed captions for videos * Translating audio and video files into different languages
GoWhisper
GoWhisper is a privacy-first, cross-platform desktop app for local audio transcription. It offers unlimited transcription on your local machine, eliminating the need for monthly fees. With support for up to 99 languages and various file formats, GoWhisper caters to a wide range of users, including researchers, podcasters, content creators, journalists, small business owners, and legal professionals.
AirCaption
AirCaption is a powerful AI-powered speech-to-text transcription tool that allows users to easily transcribe audio and video files. It features advanced AI models from OpenAI, enabling accurate transcription in up to 60 languages. AirCaption is designed for various professionals, including video editors, podcasters, language learners, legal professionals, marketers, researchers, event organizers, online course creators, and journalists. With its offline capabilities, privacy protection, and user-friendly interface, AirCaption empowers users to create captions and enhance the accessibility and engagement of their content.
TurboScribe
TurboScribe is an AI-powered transcription service that converts audio and video files into text in over 98 languages with high accuracy. It offers unlimited transcriptions, 10-hour uploads, speaker recognition, and translation to 134+ languages. TurboScribe is designed for individuals and businesses looking to transcribe large volumes of audio or video content quickly and efficiently.
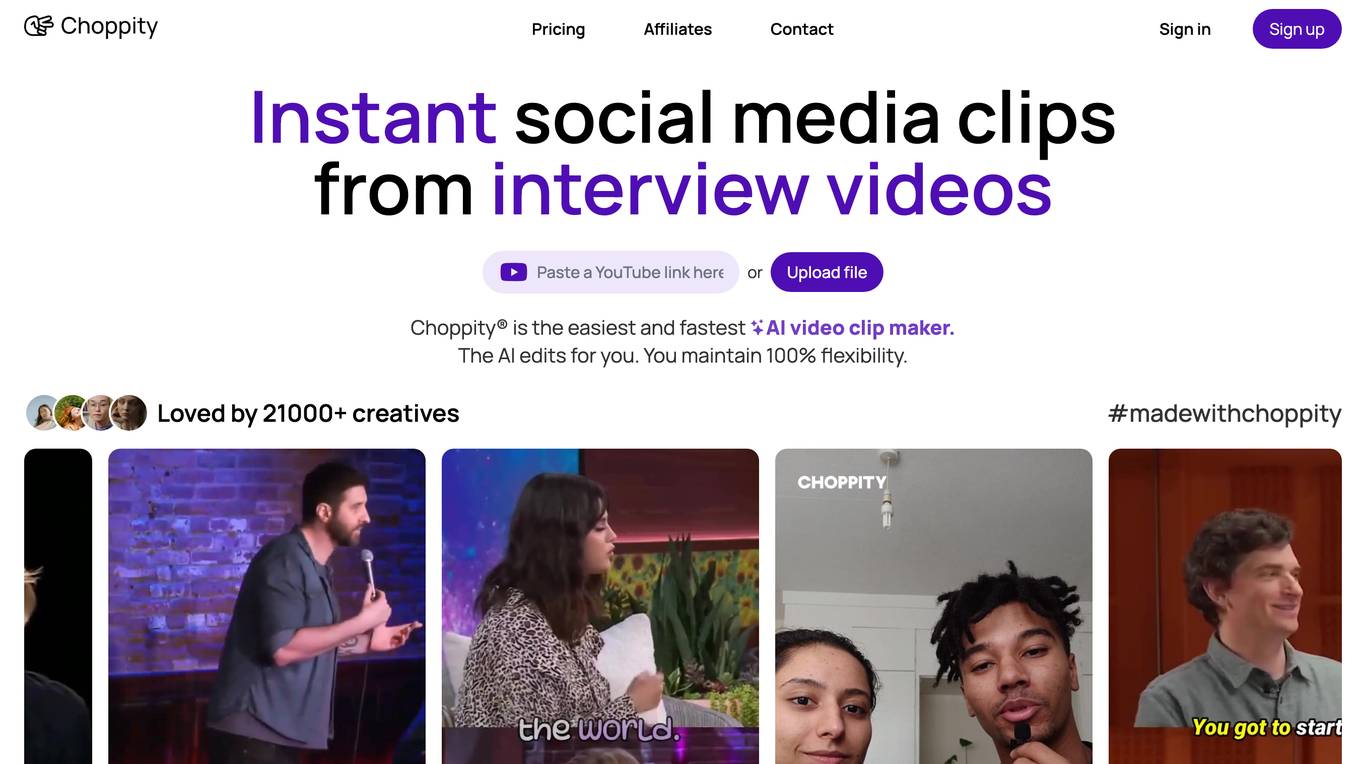
Choppity
Choppity is an AI-powered video clip maker that helps users quickly and easily create social media clips from long videos. It uses advanced AI algorithms to analyze videos and automatically generate viral clips, add animated captions, crop faces, follow speakers, and transcribe videos in 97 languages. Choppity is designed to be user-friendly and intuitive, allowing users to create professional-looking videos without any prior video editing experience.
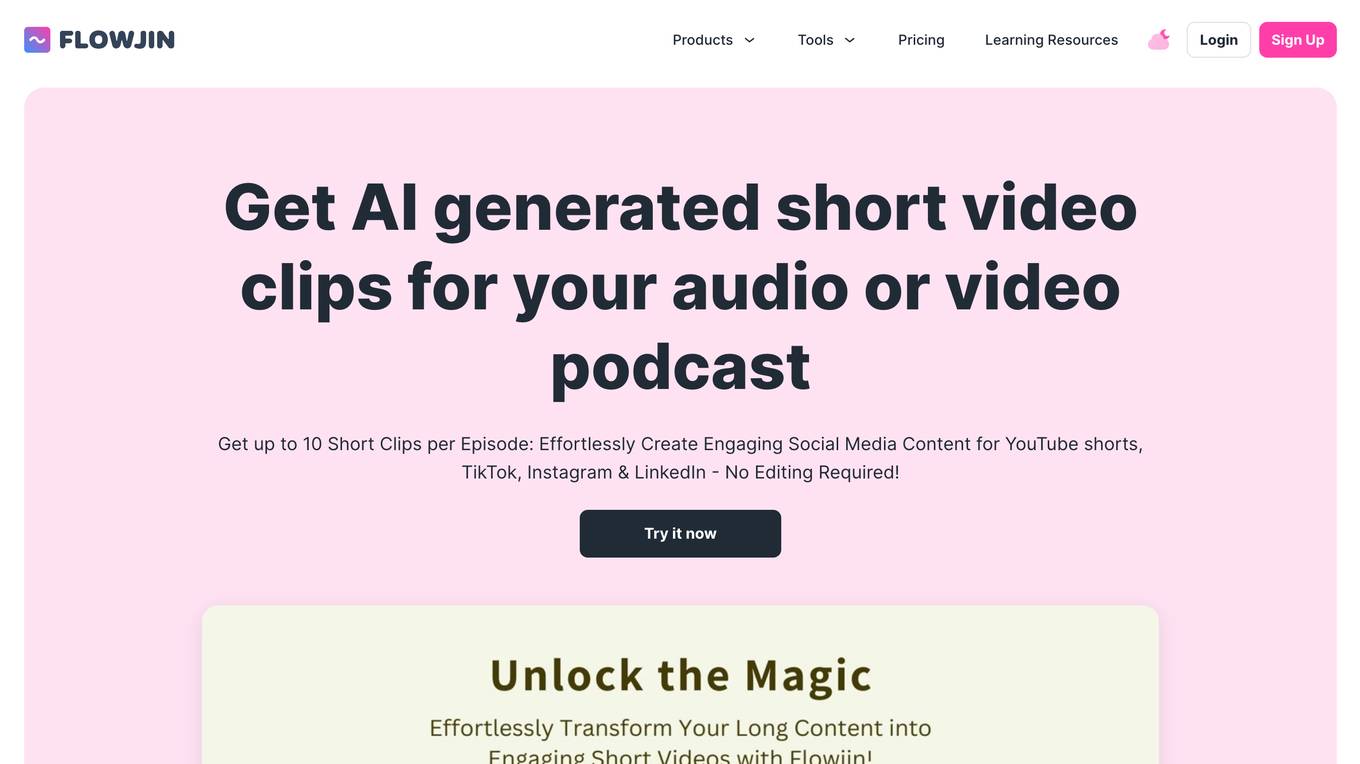
Flowjin
Flowjin is an AI-powered tool that allows users to repurpose long-form videos and audio content into engaging short video clips. The tool offers features such as AI-curated storytelling, AI clipping for auto captions and resizing, and AI-enhanced social video marketing. Users can easily generate snippets, short clips, and guest-specific moments, as well as customize branded templates and auto-generate titles and descriptions. Flowjin helps creators save time, reach a broader audience, and elevate their content creation with advanced video clip generator tools.
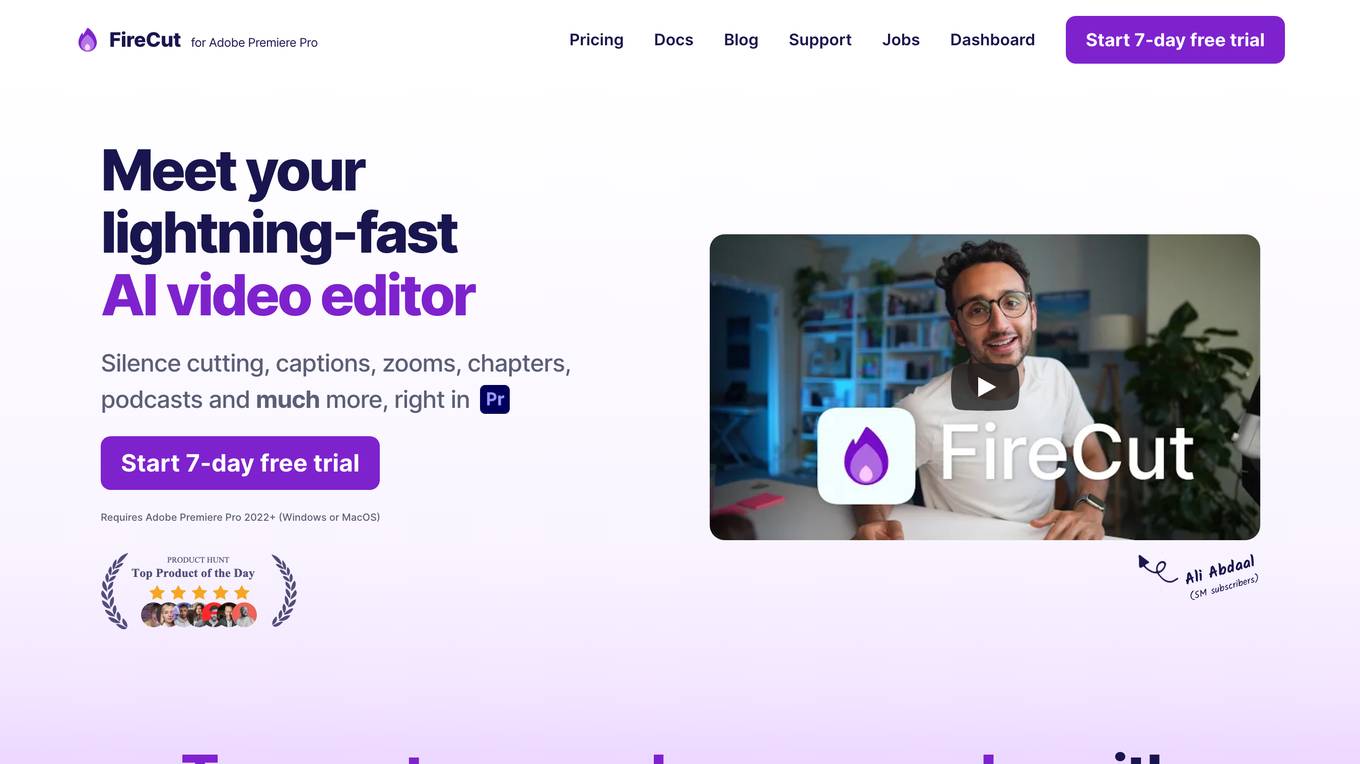
FireCut
FireCut is an AI-powered video editing tool that seamlessly integrates with Adobe Premiere Pro. It automates time-consuming tasks such as cutting silences, adding captions, creating chapters, and more, allowing video creators to save significant time and effort. FireCut's intuitive interface and advanced AI algorithms make it accessible to users of all skill levels, empowering them to produce professional-quality videos with ease.
20 - Open Source AI Tools

metavoice-src
MetaVoice-1B is a 1.2B parameter base model trained on 100K hours of speech for TTS (text-to-speech). It has been built with the following priorities: * Emotional speech rhythm and tone in English. * Zero-shot cloning for American & British voices, with 30s reference audio. * Support for (cross-lingual) voice cloning with finetuning. * We have had success with as little as 1 minute training data for Indian speakers. * Synthesis of arbitrary length text
ai-audio-startups
The 'ai-audio-startups' repository is a community list of startups working with AI for audio and music tech. It includes a comprehensive collection of tools and platforms that leverage artificial intelligence to enhance various aspects of music creation, production, source separation, analysis, recommendation, health & wellbeing, radio/podcast, hearing, sound detection, speech transcription, synthesis, enhancement, and manipulation. The repository serves as a valuable resource for individuals interested in exploring innovative AI applications in the audio and music industry.

nlp-llms-resources
The 'nlp-llms-resources' repository is a comprehensive resource list for Natural Language Processing (NLP) and Large Language Models (LLMs). It covers a wide range of topics including traditional NLP datasets, data acquisition, libraries for NLP, neural networks, sentiment analysis, optical character recognition, information extraction, semantics, topic modeling, multilingual NLP, domain-specific LLMs, vector databases, ethics, costing, books, courses, surveys, aggregators, newsletters, papers, conferences, and societies. The repository provides valuable information and resources for individuals interested in NLP and LLMs.

llms-tools
The 'llms-tools' repository is a comprehensive collection of AI tools, open-source projects, and research related to Large Language Models (LLMs) and Chatbots. It covers a wide range of topics such as AI in various domains, open-source models, chats & assistants, visual language models, evaluation tools, libraries, devices, income models, text-to-image, computer vision, audio & speech, code & math, games, robotics, typography, bio & med, military, climate, finance, and presentation. The repository provides valuable resources for researchers, developers, and enthusiasts interested in exploring the capabilities of LLMs and related technologies.

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.

obs-localvocal
LocalVocal is a live-streaming AI assistant plugin for OBS that allows you to transcribe audio speech into text and perform various language processing functions on the text using AI / LLMs (Large Language Models). It's privacy-first, with all data staying on your machine, and requires no GPU, cloud costs, network, or downtime.

reader
Reader is a tool that converts any URL to an LLM-friendly input with a simple prefix `https://r.jina.ai/`. It improves the output for your agent and RAG systems at no cost. Reader supports image reading, captioning all images at the specified URL and adding `Image [idx]: [caption]` as an alt tag. This enables downstream LLMs to interact with the images in reasoning, summarizing, etc. Reader offers a streaming mode, useful when the standard mode provides an incomplete result. In streaming mode, Reader waits a bit longer until the page is fully rendered, providing more complete information. Reader also supports a JSON mode, which contains three fields: `url`, `title`, and `content`. Reader is backed by Jina AI and licensed under Apache-2.0.
SLAM-LLM
SLAM-LLM is a deep learning toolkit designed for researchers and developers to train custom multimodal large language models (MLLM) focusing on speech, language, audio, and music processing. It provides detailed recipes for training and high-performance checkpoints for inference. The toolkit supports tasks such as automatic speech recognition (ASR), text-to-speech (TTS), visual speech recognition (VSR), automated audio captioning (AAC), spatial audio understanding, and music caption (MC). SLAM-LLM features easy extension to new models and tasks, mixed precision training for faster training with less GPU memory, multi-GPU training with data and model parallelism, and flexible configuration based on Hydra and dataclass.

TempCompass
TempCompass is a benchmark designed to evaluate the temporal perception ability of Video LLMs. It encompasses a diverse set of temporal aspects and task formats to comprehensively assess the capability of Video LLMs in understanding videos. The benchmark includes conflicting videos to prevent models from relying on single-frame bias and language priors. Users can clone the repository, install required packages, prepare data, run inference using examples like Video-LLaVA and Gemini, and evaluate the performance of their models across different tasks such as Multi-Choice QA, Yes/No QA, Caption Matching, and Caption Generation.

CLIPPyX
CLIPPyX is a powerful system-wide image search and management tool that offers versatile search options to find images based on their content, text, and visual similarity. With advanced features, users can effortlessly locate desired images across their entire computer's disk(s), regardless of their location or file names. The tool utilizes OpenAI's CLIP for image embeddings and text-based search, along with OCR for extracting text from images. It also employs Voidtools Everything SDK to list paths of all images on the system. CLIPPyX server receives search queries and queries collections of image embeddings and text embeddings to return relevant images.

Twitter-Insight-LLM
This project enables you to fetch liked tweets from Twitter (using Selenium), save it to JSON and Excel files, and perform initial data analysis and image captions. This is part of the initial steps for a larger personal project involving Large Language Models (LLMs).

InternVL
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM. It is a vision-language foundation model that can perform various tasks, including: **Visual Perception** - Linear-Probe Image Classification - Semantic Segmentation - Zero-Shot Image Classification - Multilingual Zero-Shot Image Classification - Zero-Shot Video Classification **Cross-Modal Retrieval** - English Zero-Shot Image-Text Retrieval - Chinese Zero-Shot Image-Text Retrieval - Multilingual Zero-Shot Image-Text Retrieval on XTD **Multimodal Dialogue** - Zero-Shot Image Captioning - Multimodal Benchmarks with Frozen LLM - Multimodal Benchmarks with Trainable LLM - Tiny LVLM InternVL has been shown to achieve state-of-the-art results on a variety of benchmarks. For example, on the MMMU image classification benchmark, InternVL achieves a top-1 accuracy of 51.6%, which is higher than GPT-4V and Gemini Pro. On the DocVQA question answering benchmark, InternVL achieves a score of 82.2%, which is also higher than GPT-4V and Gemini Pro. InternVL is open-sourced and available on Hugging Face. It can be used for a variety of applications, including image classification, object detection, semantic segmentation, image captioning, and question answering.

long-llms-learning
A repository sharing the panorama of the methodology literature on Transformer architecture upgrades in Large Language Models for handling extensive context windows, with real-time updating the newest published works. It includes a survey on advancing Transformer architecture in long-context large language models, flash-ReRoPE implementation, latest news on data engineering, lightning attention, Kimi AI assistant, chatglm-6b-128k, gpt-4-turbo-preview, benchmarks like InfiniteBench and LongBench, long-LLMs-evals for evaluating methods for enhancing long-context capabilities, and LLMs-learning for learning technologies and applicated tasks about Large Language Models.

Avalonia-Assistant
Avalonia-Assistant is an open-source desktop intelligent assistant that aims to provide a user-friendly interactive experience based on the Avalonia UI framework and the integration of Semantic Kernel with OpenAI or other large LLM models. By utilizing Avalonia-Assistant, you can perform various desktop operations through text or voice commands, enhancing your productivity and daily office experience.

VLMEvalKit
VLMEvalKit is an open-source evaluation toolkit of large vision-language models (LVLMs). It enables one-command evaluation of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt generation-based evaluation for all LVLMs, and provide the evaluation results obtained with both exact matching and LLM-based answer extraction.

GPT4Point
GPT4Point is a unified framework for point-language understanding and generation. It aligns 3D point clouds with language, providing a comprehensive solution for tasks such as 3D captioning and controlled 3D generation. The project includes an automated point-language dataset annotation engine, a novel object-level point cloud benchmark, and a 3D multi-modality model. Users can train and evaluate models using the provided code and datasets, with a focus on improving models' understanding capabilities and facilitating the generation of 3D objects.
mllm
mllm is a fast and lightweight multimodal LLM inference engine for mobile and edge devices. It is a Plain C/C++ implementation without dependencies, optimized for multimodal LLMs like fuyu-8B, and supports ARM NEON and x86 AVX2. The engine offers 4-bit and 6-bit integer quantization, making it suitable for intelligent personal agents, text-based image searching/retrieval, screen VQA, and various mobile applications without compromising user privacy.
AI-Writer
AI-Writer is an AI content generation toolkit called Alwrity that automates and enhances the process of blog creation, optimization, and management. It integrates advanced AI models for text generation, image creation, and data analysis, offering features such as online research integration, long-form content generation, AI content planning, multilingual support, prevention of AI hallucinations, multimodal content generation, SEO optimization, and integration with platforms like Wordpress and Jekyll. The toolkit is designed for automated blog management and requires appropriate API keys and access credentials for full functionality.
ROSGPT_Vision
ROSGPT_Vision is a new robotic framework designed to command robots using only two prompts: a Visual Prompt for visual semantic features and an LLM Prompt to regulate robotic reactions. It is based on the Prompting Robotic Modalities (PRM) design pattern and is used to develop CarMate, a robotic application for monitoring driver distractions and providing real-time vocal notifications. The framework leverages state-of-the-art language models to facilitate advanced reasoning about image data and offers a unified platform for robots to perceive, interpret, and interact with visual data through natural language. LangChain is used for easy customization of prompts, and the implementation includes the CarMate application for driver monitoring and assistance.
20 - OpenAI Gpts

www.captiongenerator.com
Free AI TikTok Caption Generator - Generates catchy TikTok captions from video scripts

OneWord GPT
SuccintBot delivers concise one-word answers, offering a unique twist on language model interactions with brevity at its core.

MELODICA
Give me an image or idea and I will create captions designed for generate images with 'Sable Diffusion'.
小红书文案 Xhs Writer: Mary
✨ 家人们!此助手经过了特定设计优化,可以很好地帮你生成 📕 小红书文化语境的风格文案。👉 例如「家人们」「姐妹们」等友好的「小红书调性」特有网络用语。😉 还能帮你生成一些 # 标签提高笔记流量。如果你正在经营自己的小红书,建议 Pin 📌 在左上角长期使用哦,我直接一整个码住啦~(此 AI 和小红书官方无关,仅为个人文案助手)