Best AI tools for< Vocal Mixer >
Infographic
20 - AI tool Sites

Controlla Voice
Controlla Voice is an AI application that allows users to transform their voice into new voices or instruments, create AI singing voices, generate AI cover songs, blend unlimited voices, and convert singing or rapping recordings into their own voice. Users can create unique voices, sing in different languages, and rap faster than ever before. The application provides a vocal toolkit for sound design, producing, and songwriting, offering endless possibilities for music creation and personalization.
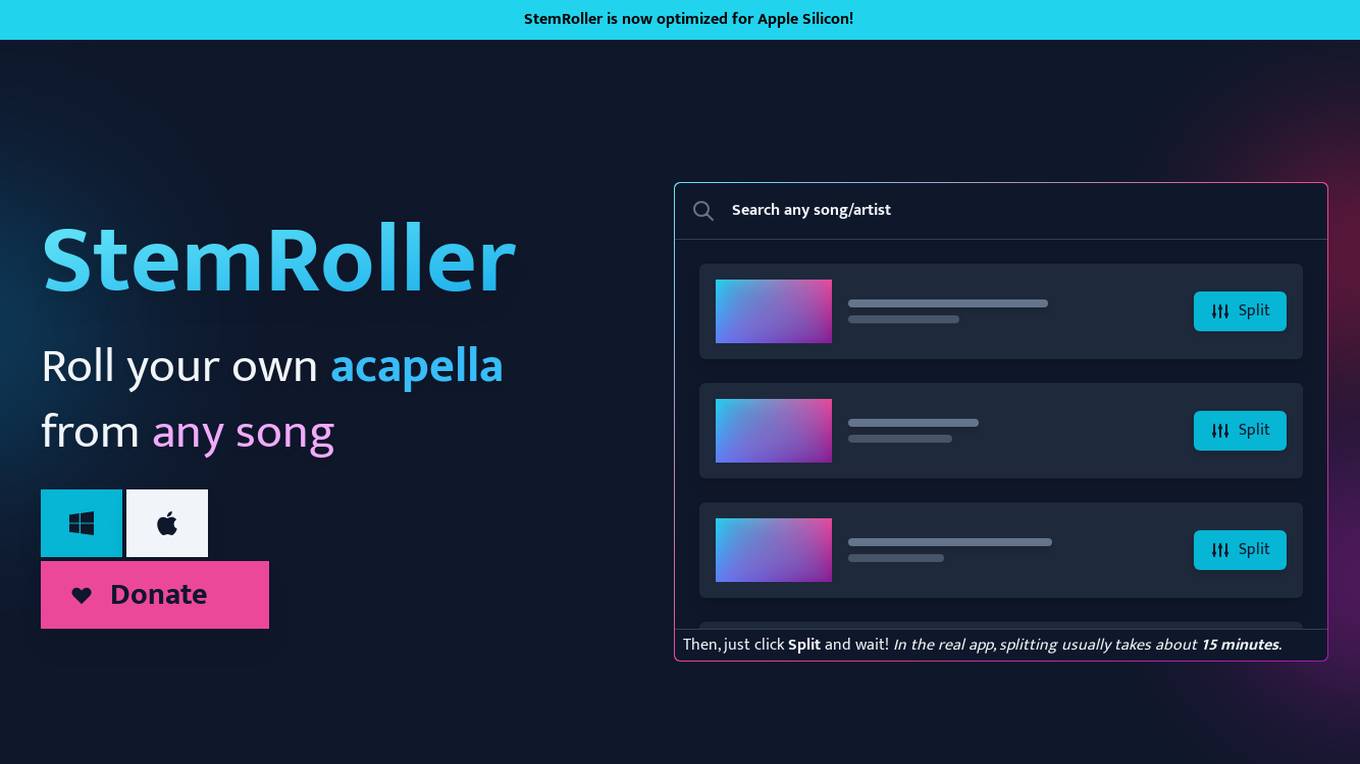
StemRoller
StemRoller is an AI-powered application that allows users to create stems, instrumental, or acapella versions of any song. Users can simply type the name of a song into the search bar, and StemRoller will find the song online and split it into vocals, drums, bass, and other stems. Additionally, an instrumental track is created with all non-vocal stems mixed down into one track. StemRoller is free and open-source, utilizing Facebook's advanced AI and machine learning research project Demucs. Users can also donate to support the app and receive assistance on Discord for any issues or questions.
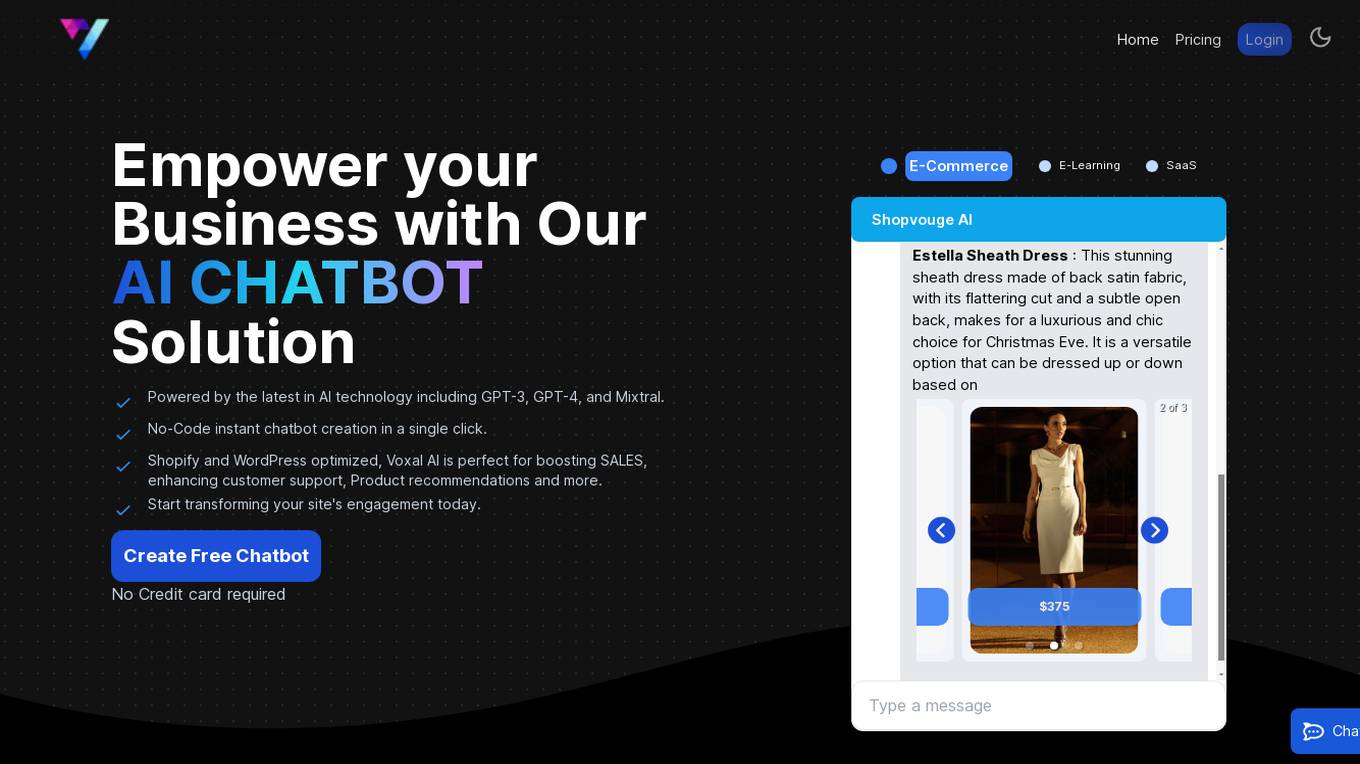
Voxal AI
Voxal AI is an AI-powered chatbot solution designed to enhance sales, customer support, and user engagement on websites. It offers a range of features including multiple AI models, A/B testing, cross-platform compatibility, multilingual support, advanced analytics, customization options, and multi-platform integration. Voxal AI is suitable for various industries such as e-commerce, e-learning, and SaaS, and can be used for tasks such as product recommendations, lead qualification, and automated customer support.
Adminer
Adminer is a comprehensive platform designed to assist e-commerce entrepreneurs in identifying, analyzing, and validating profitable products. It leverages artificial intelligence to provide users with data-driven insights, enabling them to make informed decisions and optimize their product offerings. Adminer's suite of features includes product research, market analysis, supplier evaluation, and automated copywriting, empowering users to streamline their operations and maximize their sales potential.
Vocal Image
Vocal Image is an AI-powered coaching app that offers speech and communication lessons to help speakers and singers boost confidence and enhance the attractiveness of their voice. The app provides voice evaluations, educational content, specialized programs, and challenges designed to improve voice quality and communication skills. Users can record their voice, receive feedback from a community of voice enthusiasts, and engage with AI coach recommendations to achieve their voice goals.
Vocal Remover Oak
Vocal Remover Oak is an advanced AI tool designed for music producers, video makers, and karaoke enthusiasts to easily separate vocals and accompaniment in audio files. The website offers a free online vocal remover service that utilizes deep learning technology to provide fast processing, high-quality output, and support for various audio and video formats. Users can upload local files or provide YouTube links to extract vocals, accompaniment, and original music. The tool ensures lossless audio output quality and compatibility with multiple formats, making it suitable for professional music production and personal entertainment projects.
VocalRemover.org
VocalRemover.org is a website that offers a simple and efficient tool to remove vocals from music tracks. Users can upload their audio files and the tool will process them to create a version with the vocals removed. The site aims to provide a hassle-free experience for users looking to create karaoke tracks or instrumental versions of songs. With a focus on performance and security, VocalRemover.org ensures a smooth process for its users.
AudioStrip
AudioStrip is a free online vocal isolator that allows you to remove vocals from any song. It uses artificial intelligence to separate the vocals from the music, and it does a surprisingly good job. You can use AudioStrip to create a cappella versions of your favorite songs, or you can use it to isolate the vocals from a song so that you can sing along with them. AudioStrip is easy to use. Just upload a song to the website, and then click the "Extract Vocals" button. AudioStrip will then process the song and create a new file that contains only the vocals. You can then download the new file to your computer.
Frettable
Frettable is an AI-powered music transcription tool that allows musicians to convert their instrument recordings into MIDI and sheet music. With Frettable, musicians can play their instruments and have the AI instantly write the sheet music for them, saving them time and effort. Frettable is also polyphonic, meaning it can handle both notes and chords, and it can generate tabs for guitar and other stringed instruments. Frettable is available as a web app and as a mobile app, making it easy for musicians to use wherever they are.
Lamucal
Lamucal is an AI-powered platform that provides tabs and chords for any song. It offers real-time chords, lyrics, tabs, and melody for any song, making it a valuable tool for musicians and music enthusiasts. Users can upload songs or search for any song to access chords and other musical elements. With a user-friendly interface and a wide range of features, Lamucal aims to enhance the music learning and playing experience for its users.
Media.io
Media.io is an online platform offering a wide range of AI tools for video, audio, and image editing. Users can easily enhance their creative projects with features like AI Portrait Generator, AI Video Generator, Video Editor, Image Enhancer, and more. The platform provides a drag-and-drop interface, flexible editing options, a vast template library, and powerful AI tools, all accessible directly from the browser. Media.io aims to redefine video creation by providing smart editing solutions for creators in various fields such as business, marketing, social media, and entertainment.
Narrify AI
Narrify AI is an AI-powered application that transforms your videos by adding sports commentary to them. With Narrify AI, users can upload any video file up to 45 seconds in length and enhance it with personalized commentary, highlighting names and key words. The application allows users to create engaging and fun narrated videos to share with friends and family. Narrify AI is a user-friendly tool that adds a unique touch to your videos, making them more entertaining and memorable.
LALAL.AI
LALAL.AI is a next-generation vocal remover and music source separation service that offers fast, easy, and precise stem extraction. It allows users to remove vocals, instrumental tracks, drums, bass, piano, electric guitar, acoustic guitar, and synthesizer tracks without compromising quality. The service leverages advanced AI technology to provide high-quality stem splitting based on cutting-edge algorithms. Users can also enjoy features like voice cleaning, voice changing, echo and reverb removal, and lead/back vocal splitting. LALAL.AI caters to both individual and business users, offering various pricing packages and enterprise solutions for seamless integration and cross-platform support.

Emvoice
Emvoice is a cutting-edge vocal synthesis platform that empowers users to create realistic and expressive synthetic voices. With its advanced AI algorithms and intuitive interface, Emvoice makes it easy to generate high-quality voiceovers, audiobooks, and other audio content. Whether you're a professional voice actor, a content creator, or simply looking to add a touch of personality to your projects, Emvoice has the tools you need to bring your words to life.
VocalRemover
VocalRemover is an online tool that uses artificial intelligence to remove vocals from any music track. It is easy to use, simply upload your song and the AI will process it to separate the vocals from the instrumentals. You can then download the resulting karaoke version or vocals-only version of your song. VocalRemover is a great tool for musicians, singers, and anyone who wants to create their own karaoke tracks.
Gaudio Studio
Gaudio Studio is an AI music separation tool designed for creators to unleash their creativity with ease. It allows users to extract background music, separate instruments, and remove vocals from any music content. Powered by GSEP (Gaudio source SEParation), a high-quality and easy-to-use AI stem separation model, Gaudio Studio offers a seamless experience for audio separation. Users can upload their songs in various formats, access the tool from desktop or mobile devices, and enjoy Studio Plans for advanced processing. Additionally, Gaudio Studio can be integrated with cloud APIs and On-device SDKs for business applications, offering a versatile solution for music professionals and enthusiasts.
MVSEP - Music & Voice Separation
MVSEP is an AI-powered application that specializes in music and voice separation. It offers users the ability to separate audio files into voice and music parts using advanced algorithms and models. Users can easily upload files through drag and drop or remote upload features. The application provides various separation types, HQ models, and output encoding options to cater to different user needs. MVSEP aims to enhance the audio editing experience by providing high-quality results and a user-friendly interface.
Fadr
Fadr is an AI music maker application that enhances creativity by providing tools for creating music using AI technology. Users can pick from a variety of tools like SynthGPT to create playable instruments with text, Remix to make remixes with Fadr AI, and Stems to extract vocals and instrument types. Fadr aims to amplify musical creativity by developing web apps and plugins that help users in making art and exploring new sounds.
ToneShift
ToneShift is an AI-powered platform that allows users to clone voices, separate music, and join a community of voices. With ToneShift, users can transform recordings into versatile voices for various purposes, separate vocals and instrumentals from songs to create new remixes and mashups, and join a community to discover new tones, contribute their creations, and collaborate with others.
FreeTTS
FreeTTS is a free online text-to-speech tool that allows users to convert text into natural-sounding speech in various languages and voices. It supports a range of features such as text-to-speech conversion, speech-to-text conversion, vocal removal, voice enhancement, audio cutting, and audio joining. FreeTTS is suitable for various applications, including content creation, education, accessibility, and entertainment.
20 - Open Source Tools
Awesome-AITools
This repo collects AI-related utilities. ## All Categories * All Categories * ChatGPT and other closed-source LLMs * AI Search engine * Open Source LLMs * GPT/LLMs Applications * LLM training platform * Applications that integrate multiple LLMs * AI Agent * Writing * Programming Development * Translation * AI Conversation or AI Voice Conversation * Image Creation * Speech Recognition * Text To Speech * Voice Processing * AI generated music or sound effects * Speech translation * Video Creation * Video Content Summary * OCR(Optical Character Recognition)

ai-audio-datasets
AI Audio Datasets List (AI-ADL) is a comprehensive collection of datasets consisting of speech, music, and sound effects, used for Generative AI, AIGC, AI model training, and audio applications. It includes datasets for speech recognition, speech synthesis, music information retrieval, music generation, audio processing, sound synthesis, and more. The repository provides a curated list of diverse datasets suitable for various AI audio tasks.
awesome-generative-ai
A curated list of Generative AI projects, tools, artworks, and models


Chinese-Mixtral-8x7B
Chinese-Mixtral-8x7B is an open-source project based on Mistral's Mixtral-8x7B model for incremental pre-training of Chinese vocabulary, aiming to advance research on MoE models in the Chinese natural language processing community. The expanded vocabulary significantly improves the model's encoding and decoding efficiency for Chinese, and the model is pre-trained incrementally on a large-scale open-source corpus, enabling it with powerful Chinese generation and comprehension capabilities. The project includes a large model with expanded Chinese vocabulary and incremental pre-training code.
worker-vllm
The worker-vLLM repository provides a serverless endpoint for deploying OpenAI-compatible vLLM models with blazing-fast performance. It supports deploying various model architectures, such as Aquila, Baichuan, BLOOM, ChatGLM, Command-R, DBRX, DeciLM, Falcon, Gemma, GPT-2, GPT BigCode, GPT-J, GPT-NeoX, InternLM, Jais, LLaMA, MiniCPM, Mistral, Mixtral, MPT, OLMo, OPT, Orion, Phi, Phi-3, Qwen, Qwen2, Qwen2MoE, StableLM, Starcoder2, Xverse, and Yi. Users can deploy models using pre-built Docker images or build custom images with specified arguments. The repository also supports OpenAI compatibility for chat completions, completions, and models, with customizable input parameters. Users can modify their OpenAI codebase to use the deployed vLLM worker and access a list of available models for deployment.

llm.c
LLM training in simple, pure C/CUDA. There is no need for 245MB of PyTorch or 107MB of cPython. For example, training GPT-2 (CPU, fp32) is ~1,000 lines of clean code in a single file. It compiles and runs instantly, and exactly matches the PyTorch reference implementation. I chose GPT-2 as the first working example because it is the grand-daddy of LLMs, the first time the modern stack was put together.

llama.cpp
llama.cpp is a C++ implementation of LLaMA, a large language model from Meta. It provides a command-line interface for inference and can be used for a variety of tasks, including text generation, translation, and question answering. llama.cpp is highly optimized for performance and can be run on a variety of hardware, including CPUs, GPUs, and TPUs.
MedicalGPT
MedicalGPT is a training medical GPT model with ChatGPT training pipeline, implement of Pretraining, Supervised Finetuning, RLHF(Reward Modeling and Reinforcement Learning) and DPO(Direct Preference Optimization).

llms-tools
The 'llms-tools' repository is a comprehensive collection of AI tools, open-source projects, and research related to Large Language Models (LLMs) and Chatbots. It covers a wide range of topics such as AI in various domains, open-source models, chats & assistants, visual language models, evaluation tools, libraries, devices, income models, text-to-image, computer vision, audio & speech, code & math, games, robotics, typography, bio & med, military, climate, finance, and presentation. The repository provides valuable resources for researchers, developers, and enthusiasts interested in exploring the capabilities of LLMs and related technologies.

openedai-speech
OpenedAI Speech is a free, private text-to-speech server compatible with the OpenAI audio/speech API. It offers custom voice cloning and supports various models like tts-1 and tts-1-hd. Users can map their own piper voices and create custom cloned voices. The server provides multilingual support with XTTS voices and allows fixing incorrect sounds with regex. Recent changes include bug fixes, improved error handling, and updates for multilingual support. Installation can be done via Docker or manual setup, with usage instructions provided. Custom voices can be created using Piper or Coqui XTTS v2, with guidelines for preparing audio files. The tool is suitable for tasks like generating speech from text, creating custom voices, and multilingual text-to-speech applications.


Liger-Kernel
Liger Kernel is a collection of Triton kernels designed for LLM training, increasing training throughput by 20% and reducing memory usage by 60%. It includes Hugging Face Compatible modules like RMSNorm, RoPE, SwiGLU, CrossEntropy, and FusedLinearCrossEntropy. The tool works with Flash Attention, PyTorch FSDP, and Microsoft DeepSpeed, aiming to enhance model efficiency and performance for researchers, ML practitioners, and curious novices.
voice-pro
Voice-Pro is an integrated solution for subtitles, translation, and TTS. It offers features like multilingual subtitles, live translation, vocal remover, and supports OpenAI Whisper and Open-Source Translator. The tool provides a Studio tab for various functions, Whisper Caption tab for subtitle creation, Translate tab for translation, TTS tab for text-to-speech, Live Translation tab for real-time voice recognition, and Batch tab for processing multiple files. Users can download YouTube videos, improve voice recognition accuracy, create automatic subtitles, and produce multilingual videos with ease. The tool is easy to install with one-click and offers a Web-UI for user convenience.
20 - OpenAI Gpts

Academia de Rock
Tutor virtual de rock entusiasta y amigable, adaptando lecciones y ejercicios al nivel del alumno.

SpeechTherapist GPT
Your very own speech therapy assistant. Completely private and confidential.
JLPT Vocab Quiz Master
Drills Japanese students on JLPT vocabulary and tracks progression reinforced via spaced repetition
German Vocab Helper
Provides images, examples, and structured grammar tables for German vocabulary.
GRE Word Tutor
Teaches GRE vocab through personalized stories and thoughtful questions, featuring GregMat


MIXING & MASTERING GPT
Your personal audio mixing and mastering engineer assistant for music production
Studio Wizard
Home studio recording magician, offering equipment, technique, mixing advice, and the occasional spell. Use the Message box at the bottom for your own questions.